Spaces:
Sleeping

title: CIFAR Custom Resnet
emoji: 🐠
colorFrom: gray
colorTo: blue
sdk: gradio
sdk_version: 3.39.0
app_file: app.py
pinned: false
license: mit
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
Problem Statement
- Train CNN on cifar dataset with residual blocks
- Target accuracy -> 90% on the test set
- Use torch_lr_finder for finding LR
- User OneCycleLR as Lr scheduler
Features
GradCAM Image Visualization
Spaces App allows users to visualize GradCAM images generated from the neural network model. GradCAM provides insight into which regions of the input image influenced the model's predictions the most. Users can customize the visualization by specifying:
- The User wants to visualize gradcam output or not
- Opacity levels for better clarity.
Misclassified Image Viewer
With Spaces App, users can explore misclassified images by the neural network model. This feature helps identify cases where the model's predictions did not match the actual labels. Users can:
- Choose if you want to check where model failed to predict correct class
- Choose the number of misclassified images to view.
Image Upload and Examples
Spaces App allows users to upload their own images for analysis. Additionally, it provides ten example images to help users get started quickly and explore the app's capabilities.
Top Classes Display
Users can request the app to show the top predicted classes for an input image. They can specify the number of top classes to be displayed (limited to a maximum of 10), making it easy to focus on the most relevant results.
How to Use Spaces App
- Setting GradCAM Preferences
- Upon launching the app, users will be prompted to choose whether they want to visualize GradCAM images.
- Users can specify the number of GradCAM images to view, the target layer for visualization, and adjust opacity levels for better visualization.
- Misclassified Image Viewer
- If users are interested in exploring misclassified images, they can select the relevant option and specify the number of images they want to see.
- Uploading Images
- To analyze custom images, users can upload their own images through the app's image upload functionality.
- Example Images
- For users who want to quickly explore the app's features, ten example images are provided.
- Top Classes Display
- Users can choose to see the top predicted classes for an input image. They should specify the number of top classes (up to 10) they wish to view.
Model Parameters
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
CustomResnet [512, 10] --
├─Sequential: 1-1 [512, 64, 32, 32] --
│ └─Conv2d: 2-1 [512, 64, 32, 32] 1,728
│ └─BatchNorm2d: 2-2 [512, 64, 32, 32] 128
│ └─ReLU: 2-3 [512, 64, 32, 32] --
├─Sequential: 1-2 [512, 128, 16, 16] --
│ └─Conv2d: 2-4 [512, 128, 32, 32] 73,728
│ └─MaxPool2d: 2-5 [512, 128, 16, 16] --
│ └─BatchNorm2d: 2-6 [512, 128, 16, 16] 256
│ └─ReLU: 2-7 [512, 128, 16, 16] --
├─Sequential: 1-3 [512, 128, 16, 16] --
│ └─Conv2d: 2-8 [512, 128, 16, 16] 147,456
│ └─BatchNorm2d: 2-9 [512, 128, 16, 16] 256
│ └─ReLU: 2-10 [512, 128, 16, 16] --
│ └─Conv2d: 2-11 [512, 128, 16, 16] 147,456
│ └─BatchNorm2d: 2-12 [512, 128, 16, 16] 256
│ └─ReLU: 2-13 [512, 128, 16, 16] --
├─Sequential: 1-4 [512, 256, 8, 8] --
│ └─Conv2d: 2-14 [512, 256, 16, 16] 294,912
│ └─MaxPool2d: 2-15 [512, 256, 8, 8] --
│ └─BatchNorm2d: 2-16 [512, 256, 8, 8] 512
│ └─ReLU: 2-17 [512, 256, 8, 8] --
├─Sequential: 1-5 [512, 512, 4, 4] --
│ └─Conv2d: 2-18 [512, 512, 8, 8] 1,179,648
│ └─MaxPool2d: 2-19 [512, 512, 4, 4] --
│ └─BatchNorm2d: 2-20 [512, 512, 4, 4] 1,024
│ └─ReLU: 2-21 [512, 512, 4, 4] --
├─Sequential: 1-6 [512, 512, 4, 4] --
│ └─Conv2d: 2-22 [512, 512, 4, 4] 2,359,296
│ └─BatchNorm2d: 2-23 [512, 512, 4, 4] 1,024
│ └─ReLU: 2-24 [512, 512, 4, 4] --
│ └─Conv2d: 2-25 [512, 512, 4, 4] 2,359,296
│ └─BatchNorm2d: 2-26 [512, 512, 4, 4] 1,024
│ └─ReLU: 2-27 [512, 512, 4, 4] --
├─MaxPool2d: 1-7 [512, 512, 1, 1] --
├─Linear: 1-8 [512, 10] 5,130
==========================================================================================
Total params: 6,573,130
Trainable params: 6,573,130
Non-trainable params: 0
Total mult-adds (G): 194.18
==========================================================================================
Input size (MB): 6.29
Forward/backward pass size (MB): 2382.41
Params size (MB): 26.29
Estimated Total Size (MB): 2414.99
==========================================================================================
Accuracy Report
| Model Experiments | Found Max LR | Min LR | Best Validation accuracy | Best Training Accuray |
|---|---|---|---|---|
| Exp-1 | 3.31E-02 | 0.023 | 90.91% | 95.88% |
| Exp-2 | 2.63E-02 | 0.02 | 91.32% | 96.95% |
| Exp-3 | 1.19E-02 | 0.01 | 91.72% | 98.77% |
| S10.ipynb | 1.87E-02 | 0.01 | 91.80% | 96.93% |
Final Training Log
Epoch 23: 100%
118/118 [00:57<00:00, 2.06it/s, loss=0.0576, v_num=0, train_loss=0.0511, train_acc=0.988, val_loss=0.268, val_acc=0.922]
Results
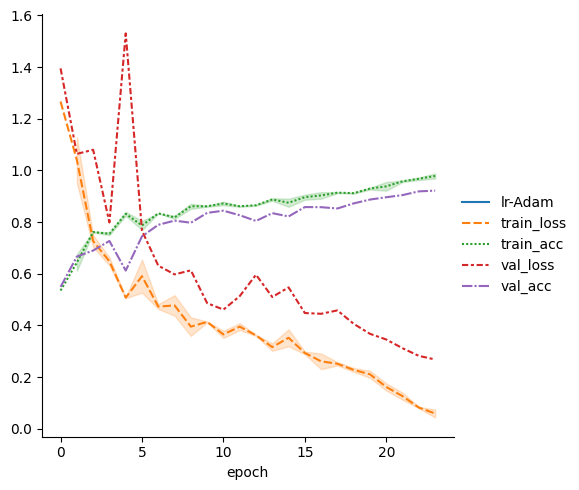
Accuracy Plot
Here is the Accuracy and Loss metric plot for the model
Misclassified Images
Here is the sample result of model miss-classified images

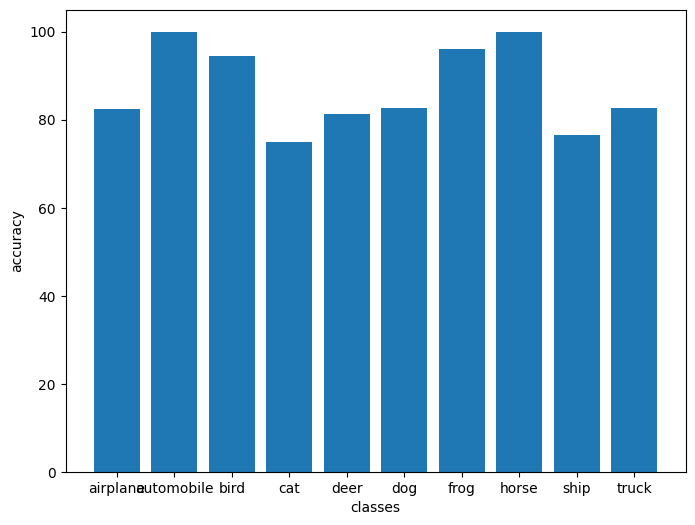
Accuracy Report for Each class
Accuracy of airplane : 82 %
Accuracy of automobile : 100 %
Accuracy of bird : 94 %
Accuracy of cat : 75 %
Accuracy of deer : 81 %
Accuracy of dog : 82 %
Accuracy of frog : 96 %
Accuracy of horse : 100 %
Accuracy of ship : 76 %
Accuracy of truck : 82 %