
A newer version of the Streamlit SDK is available:
1.40.1
# Multi-band MelGAN: Faster Waveform Generation for High-Quality Text-to-Speech
Based on the script train_multiband_melgan.py.
Training Multi-band MelGAN from scratch with LJSpeech dataset.
This example code show you how to train MelGAN from scratch with Tensorflow 2 based on custom training loop and tf.function. The data used for this example is LJSpeech, you can download the dataset at link.
Step 1: Create Tensorflow based Dataloader (tf.dataset)
Please see detail at examples/melgan/
Step 2: Training from scratch
After you re-define your dataloader, pls modify an input arguments, train_dataset and valid_dataset from train_multiband_melgan.py. Here is an example command line to training melgan-stft from scratch:
First, you need training generator with only stft loss:
CUDA_VISIBLE_DEVICES=0 python examples/multiband_melgan/train_multiband_melgan.py \
--train-dir ./dump/train/ \
--dev-dir ./dump/valid/ \
--outdir ./examples/multiband_melgan/exp/train.multiband_melgan.v1/ \
--config ./examples/multiband_melgan/conf/multiband_melgan.v1.yaml \
--use-norm 1 \
--generator_mixed_precision 1 \
--resume ""
Then resume and start training generator + discriminator:
CUDA_VISIBLE_DEVICES=0 python examples/multiband_melgan/train_multiband_melgan.py \
--train-dir ./dump/train/ \
--dev-dir ./dump/valid/ \
--outdir ./examples/multiband_melgan/exp/train.multiband_melgan.v1/ \
--config ./examples/multiband_melgan/conf/multiband_melgan.v1.yaml \
--use-norm 1 \
--resume ./examples/multiband_melgan/exp/train.multiband_melgan.v1/checkpoints/ckpt-200000
IF you want to use MultiGPU to training you can replace CUDA_VISIBLE_DEVICES=0 by CUDA_VISIBLE_DEVICES=0,1,2,3 for example. You also need to tune the batch_size for each GPU (in config file) by yourself to maximize the performance. Note that MultiGPU now support for Training but not yet support for Decode.
In case you want to resume the training progress, please following below example command line:
--resume ./examples/multiband_melgan/exp/train.multiband_melgan.v1/checkpoints/ckpt-100000
If you want to finetune a model, use --pretrained like this with the filename of the generator
--pretrained ptgenerator.h5
IMPORTANT NOTES:
- If Your Dataset is 16K, upsample_scales = [2, 4, 8] worked.
- If Your Dataset is > 16K (22K, 24K, ...), upsample_scales = [2, 4, 8] didn't worked, used [8, 4, 2] instead.
- Mixed precision make Group Convolution training slower on Discriminator, both pytorch (apex) and tensorflow also has this problems. So, DO NOT USE mixed precision when discriminator enable.
Step 3: Decode audio from folder mel-spectrogram
To running inference on folder mel-spectrogram (eg valid folder), run below command line:
CUDA_VISIBLE_DEVICES=0 python examples/multiband_melgan/decode_mb_melgan.py \
--rootdir ./dump/valid/ \
--outdir ./prediction/multiband_melgan.v1/ \
--checkpoint ./examples/multiband_melgan/exp/train.multiband_melgan.v1/checkpoints/generator-940000.h5 \
--config ./examples/multiband_melgan/conf/multiband_melgan.v1.yaml \
--batch-size 32 \
--use-norm 1
Finetune MelGAN STFT with ljspeech pretrained on other languages
Just load pretrained model and training from scratch with other languages. DO NOT FORGET re-preprocessing on your dataset if needed. A hop_size should be 256 if you want to use our pretrained.
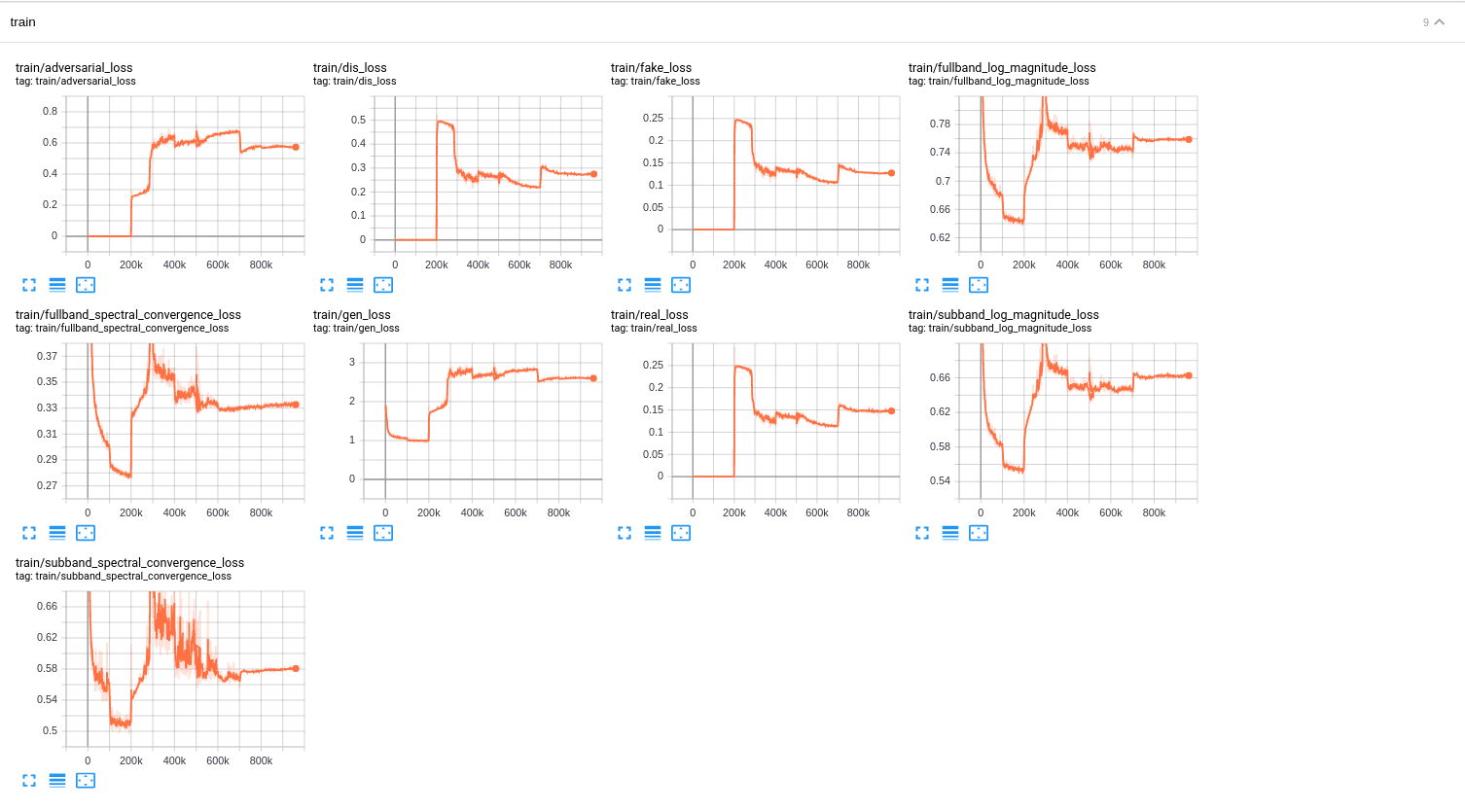
Learning Curves
Here is a learning curves of melgan based on this config multiband_melgan.v1.yaml

Pretrained Models and Audio samples
| Model | Conf | Lang | Fs [Hz] | Mel range [Hz] | FFT / Hop / Win [pt] | # iters | Notes |
|---|---|---|---|---|---|---|---|
| multiband_melgan.v1 | link | EN | 22.05k | 80-7600 | 1024 / 256 / None | 940K | - |
| multiband_melgan.v1 | link | KO | 22.05k | 80-7600 | 1024 / 256 / None | 1000K | - |
| multiband_melgan.v1_24k | link | EN | 24k | 80-7600 | 2048 / 300 / 1200 | 1000K | Converted from kan-bayashi's model; good universal vocoder |