
Tacotron 2
Based on the script train_tacotron2.py.
Training Tacotron-2 from scratch with LJSpeech dataset.
This example code show you how to train Tactron-2 from scratch with Tensorflow 2 based on custom training loop and tf.function. The data used for this example is LJSpeech, you can download the dataset at link.
Step 1: Create Tensorflow based Dataloader (tf.dataset)
First, you need define data loader based on AbstractDataset class (see abstract_dataset.py). On this example, a dataloader read dataset from path. I use suffix to classify what file is a charactor and mel-spectrogram (see tacotron_dataset.py). If you already have preprocessed version of your target dataset, you don't need to use this example dataloader, you just need refer my dataloader and modify generator function to adapt with your case. Normally, a generator function should return [charactor_ids, char_length, mel, mel_length], here i also return guided attention (see DC_TTS) to support training.
Step 2: Training from scratch
After you redefine your dataloader, pls modify an input arguments, train_dataset and valid_dataset from train_tacotron2.py. Here is an example command line to training tacotron-2 from scratch:
CUDA_VISIBLE_DEVICES=0 python examples/tacotron2/train_tacotron2.py \
--train-dir ./dump/train/ \
--dev-dir ./dump/valid/ \
--outdir ./examples/tacotron2/exp/train.tacotron2.v1/ \
--config ./examples/tacotron2/conf/tacotron2.v1.yaml \
--use-norm 1 \
--mixed_precision 0 \
--resume ""
IF you want to use MultiGPU to training you can replace CUDA_VISIBLE_DEVICES=0 by CUDA_VISIBLE_DEVICES=0,1,2,3 for example. You also need to tune the batch_size for each GPU (in config file) by yourself to maximize the performance. Note that MultiGPU now support for Training but not yet support for Decode.
In case you want to resume the training progress, please following below example command line:
--resume ./examples/tacotron2/exp/train.tacotron2.v1/checkpoints/ckpt-100000
If you want to finetune a model, use --pretrained like this with your model filename
--pretrained pretrained.h5
Step 3: Decode mel-spectrogram from folder ids
To running inference on folder ids (charactor), run below command line:
CUDA_VISIBLE_DEVICES=0 python examples/tacotron2/decode_tacotron2.py \
--rootdir ./dump/valid/ \
--outdir ./prediction/tacotron2-120k/ \
--checkpoint ./examples/tacotron2/exp/train.tacotron2.v1/checkpoints/model-120000.h5 \
--config ./examples/tacotron2/conf/tacotron2.v1.yaml \
--batch-size 32
Step 4: Extract duration from alignments for FastSpeech
You may need to extract durations for student models like fastspeech. Here we use teacher forcing with window masking trick to extract durations from alignment maps:
Extract for valid set:
CUDA_VISIBLE_DEVICES=0 python examples/tacotron2/extract_duration.py \
--rootdir ./dump/valid/ \
--outdir ./dump/valid/durations/ \
--checkpoint ./examples/tacotron2/exp/train.tacotron2.v1/checkpoints/model-65000.h5 \
--use-norm 1 \
--config ./examples/tacotron2/conf/tacotron2.v1.yaml \
--batch-size 32
--win-front 3 \
--win-back 3
Extract for training set:
CUDA_VISIBLE_DEVICES=0 python examples/tacotron2/extract_duration.py \
--rootdir ./dump/train/ \
--outdir ./dump/train/durations/ \
--checkpoint ./examples/tacotron2/exp/train.tacotron2.v1/checkpoints/model-65000.h5 \
--use-norm 1 \
--config ./examples/tacotron2/conf/tacotron2.v1.yaml \
--batch-size 32
--win-front 3 \
--win-back 3
To extract postnets for training vocoder, follow above steps but with extract_postnets.py
You also can download my extracted durations at 40k steps at link.
Finetune Tacotron-2 with ljspeech pretrained on other languages
Here is an example show you how to use pretrained ljspeech to training with other languages. This does not guarantee a better model or faster convergence in all cases but it will improve if there is a correlation between target language and pretrained language. The only thing you need to do before finetune on other languages is re-define embedding layers. You can do it by following code:
tacotron_config = Tacotron2Config(**config["tacotron2_params"])
tacotron_config.vocab_size = NEW_VOCAB_SIZE
tacotron2 = TFTacotron2(config=tacotron_config, training=True, name='tacotron2')
tacotron2._build()
tacotron2.summary()
tacotron2.load_weights("./examples/tacotron2/exp/train.tacotron2.v1/checkpoints/model-120000.h5", by_name=True, skip_mismatch=True)
... # training as normal.
You can also define var_train_expr in config file to let model training only on some layers in case you want to fine-tune on your dataset with the same pretrained language and processor. For example, var_train_expr: "embeddings|encoder|decoder" means we just training all variables that embeddings, encoder, decoder exist in its name.
Using Forced Alignment Guided Attention Loss
Instead of regular guided attention loss you can opt for Forced Alignment Guided Attention Loss (FAL), which uses prealignment information from Montreal Forced Aligner to more accurately guide each utterance. This especially helps on harder datasets, like those with long silences.
First see examples/mfa_extraction, and once you have extracted durations, run export_align.py, like this.
python examples/tacotron2/export_align.py --dump-dir dump --looseness 3.5
You can experiment with different looseness values for stricter (lower) or more tolerant masks. Note that this script assumes you are using r = 1
After that, simply pass the argument --fal 1 to the train_tacotron2.py script afterwards.
Results
Here is a result of tacotron2 based on this config tacotron2.v1.yaml but with reduction_factor = 7, we will update learning curves for reduction_factor = 1.
Alignments progress

Learning curves
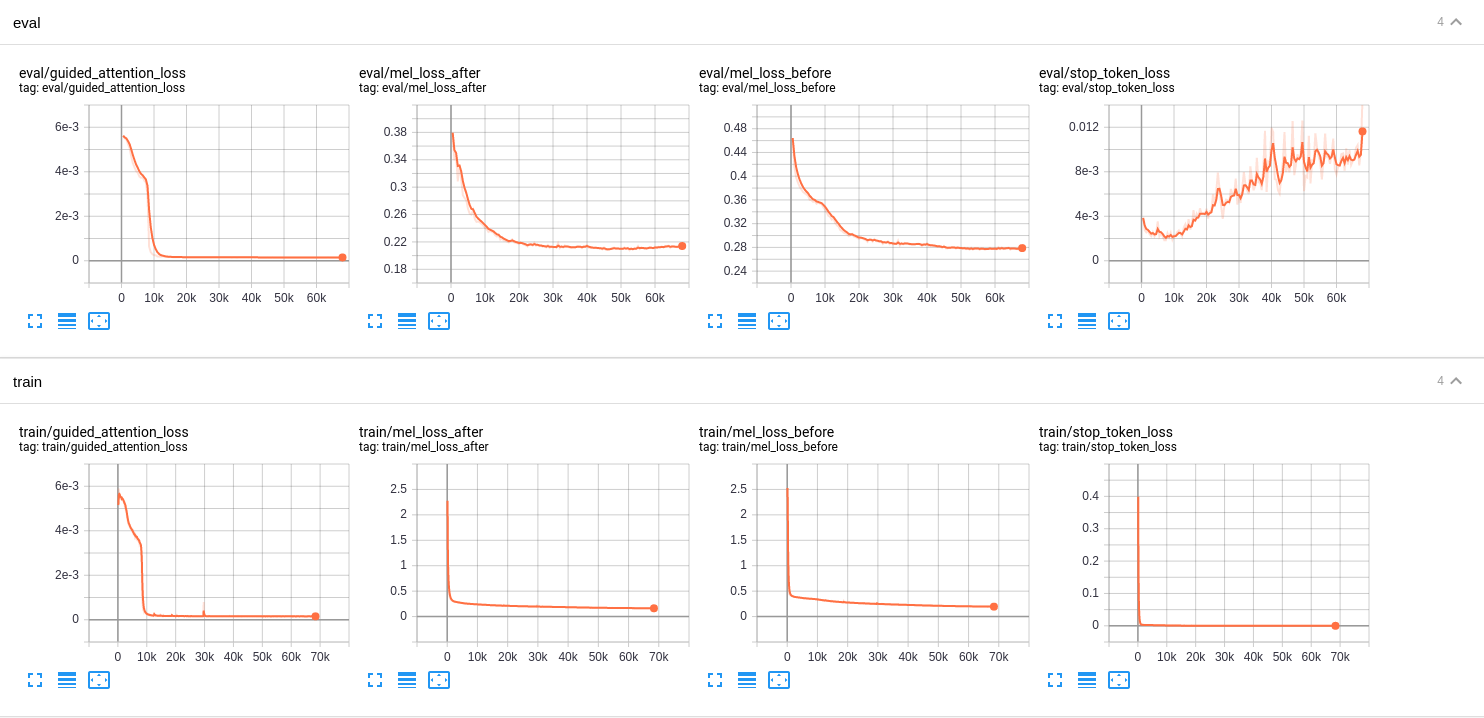
Some important notes
- This implementation use guided attention by default to help a model learn diagonal alignment faster. After 15-20k, you can disble alignment loss.
- Relu activation function is still a best compared with mish and others.
- Support window masking for inference, solve problem with very long sentences.
- The model convergence at around 100k steps.
- Scheduled teacher forcing is supported but training with teacher forcing give a best performance based on my experiments. You need to be aware of the importance of applying high dropout for prenet (both training and inference), this will reduce the effect of prev mel, so in an inference stage, a noise of prev mel prediction won't affect too much to a current decoder.
- If an amplitude levels of synthesis audio is lower compared to original speech, you may need multiply mel predicted to global gain constant (eg 1.2).
- Apply input_signature for tacotron make training slower, don't know why, so only use experimental_relax_shapes = True.
- It's funny but training with fixed char_len (200) and mel_len (870) is 2x faster than dynamic shape even it's redundant. But i'm not sure because there is a man report that dynamic shape is faster, pls refer comment, you may need to try both use_fixed_shapes is True and False to check by yourself 😅.
Pretrained Models and Audio samples
| Model | Conf | Lang | Fs [Hz] | Mel range [Hz] | FFT / Hop / Win [pt] | # iters | reduction factor |
|---|---|---|---|---|---|---|---|
| tacotron2.v1 | link | EN | 22.05k | 80-7600 | 1024 / 256 / None | 65K | 1 |
| tacotron2.v1 | link | KO | 22.05k | 80-7600 | 1024 / 256 / None | 100K | 1 |
| tacotron2.lju.v1 | link | EN | 44.1k | 20-11025 | 2048 / 512 / None | 126K | 1 |