Spaces:
Runtime error


Description
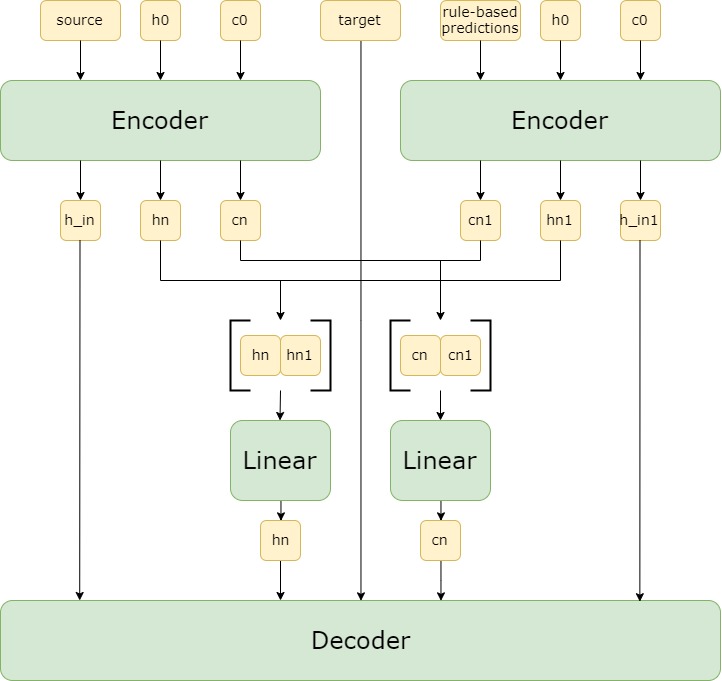
The idea of lexicon-enhanced lemmatization is to utilize the output of an external resource such as
a rule-based analyzer (a lexicon — Vabamorf morphological analyzer in this particular case) as an additional input to
improve the results of a neural lemmatization model. Said additional input is a concatenation of one or more
lemma candidates provided by Vabamorf. A second encoder is used to process this input. See the scheme below.
The lexicon-enhanced lemmatizer itself is a modification on an older version of Stanza, which is a neural model that takes morphological features and parts of speech as input in addition to surface forms to predict a lemma. In this demo morphological features and the part of speech are provided by a more recent version of Stanza, although it's possible to use native Vabamorf features as well (the results, however, are going to be slightly worse). Additional lexicon input is processed by a separate encoder.
The models were trained on version 2.7 of the Estonian Dependency Treebank.
Two variants of lemmatization are provided in the demo: regular lemmatization and lemmatization with
special symbols. Special symbols are = and _, denoting morphological derivation and separating parts of
compound words respectively. The latter was trained on the original data with Vabamorf set to output
these special symbols, while the latter was trained with = and _ removed from the data and
vabamorf output. See the results on dev set in the table below (models trained on vabamorf features are
not included in the demo).
| Model | Token-wise accuracy |
|---|---|
| Stanza features | 98.13 |
| Stanza features and special symbols | 97.28 |
| Vabamorf features | 97.32 |
| Vabamorf features and special symbols | 96.34 |