Spaces:
Runtime error


A newer version of the Gradio SDK is available:
4.39.0
tasks:
- text-to-speech
studios:
- damo/personal_tts
domain:
- audio
frameworks:
- pytorch
backbone:
- transformer
metrics:
- MOS
license: Apache License 2.0
tags:
- Alibaba
- tts
- personal
- hifigan
- nsf
- sambert
- text-to-speech
- pretrain
- zhcn
- 16k
widgets:
- task: text-to-speech
inputs:
- type: text
name: input
title: 文本
validator:
max_words: 300
examples:
- name: 1
title: 示例1
inputs:
- name: input
data: 北京今天天气怎么样
inferencespec:
cpu: 4
memory: 8192
gpu: 1
gpu_memory: 8192
SAMBERT个性化语音合成模型介绍
本文将介绍SAMBERT个性化语音合成模型, 包括其模型结构, 如何在ModelScope上体验模型效果, 以及如何使用开源代码训练SAMBERT个性化语音合成模型.
个性化语音合成
语音合成(Text-to-Speech, TTS) 是指将输入文字合成为对应语音信号的功能,即赋予计算机“说”的能力,是人机交互中重要的一环。现代语音合成最早可以追溯到1939年贝尔实验室制造的第一个电子语音合成器,后来历经共振峰合成、PSOLA合成、Unit Selection波形拼接、统计参数合成几代的发展,在2016年随着WaveNet的出现步入了深度学习合成时代,此时语音合成的效果已经表现出了比拟真人的水准。
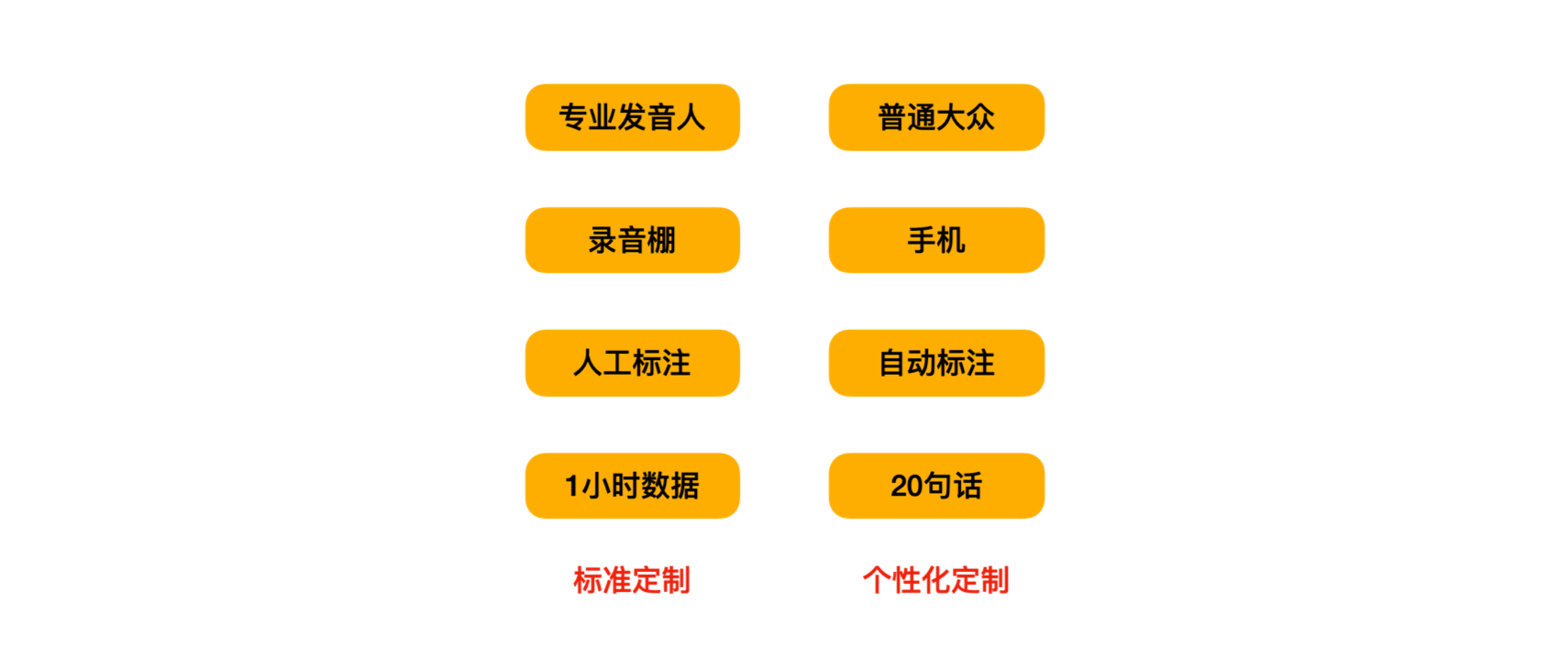
提到个性化定制语音,大家并不陌生,许多平台会选择一些大家耳熟能详的明星,进行声音定制,并普遍应用在语音导航,文字播报,小说阅读等场景中。这项技术来自文本到语音的服务,一般来说,语音合成数据需要专业播音员在录音棚录制,且数据量都是以500-1000句话起步,这种标准定制的流程,无论是对播音员、录制条件、录制数量和成本都提出了较高的要求。
Personal TTS,即个性化语音合成,是通过身边的一些常见录音设备(手机、电脑、录音笔等),录取目标说话人的少量语音片段后,构建出这个人的语音合成系统。相比于标准定制,个性化定制的技术难点在于,数据量有限(20句话)、数据质量不佳和流程全自动化。而它的意义在于进一步降低语音合成的定制门槛,能够将语音合成定制推广到普通用户。
学术界有很多关于声音克隆的工作,论文陈述效果很好。考虑到落地应用场景的效果,达摩院以自研语音合成系统KAN-TTS的迁移学习能力为基础,设计了一套较为完善的个性化语音合成方案。用户只需要录制20句话,经过几分钟的训练,就能够获得一个较好的个性化声音。
模型框架
模型框架主要由三个部分组成:
- 数据自动化处理和标注
- 韵律建模SAMBERT声学模型
- 基于说话人特征信息的个性化语音合成
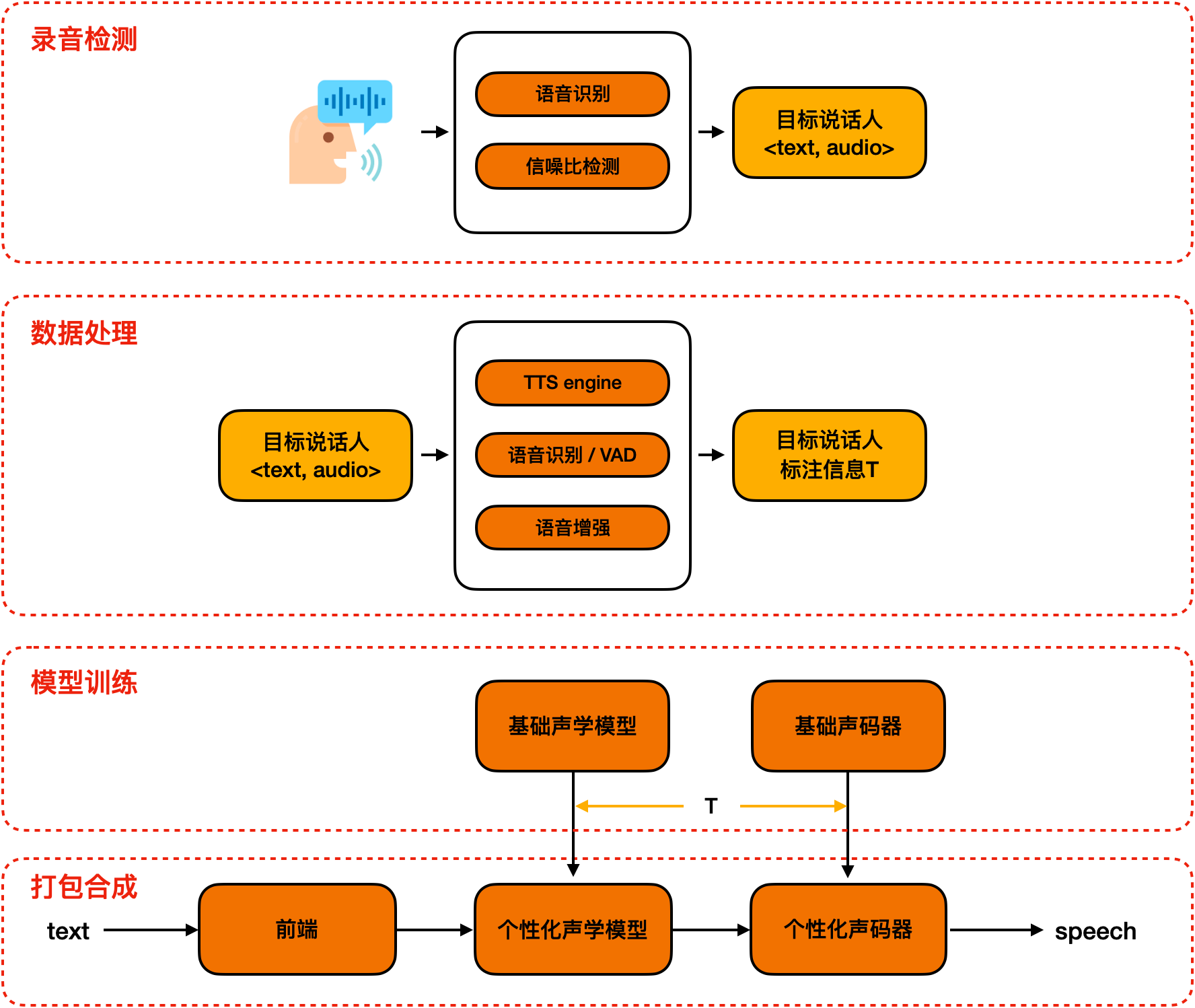
数据自动化处理和标注
在用户录制完音频之后,我们只有<文本,音频>,而语音合成是需要一些额外的标注信息:韵律标注、音素时长标注。为了获得较好的标注信息,我们采用了一种融合了多种原子能力的全自动化处理和标注流程,包括,韵律预测、ASR、VAD和语音增强等。通过测试集测试,该自动化流程产生的标注信息,在准确度能够满足个性化的需求。
此外,我们也在modelscope上发布了TTS-Autolabel自动化数据标注工具,旨在降低TTS数据标注门槛,使开发者更便捷的定制个性化语音合成模型,具体使用方式及相关教程请进入TTS-AutoLabel工具主页获取。
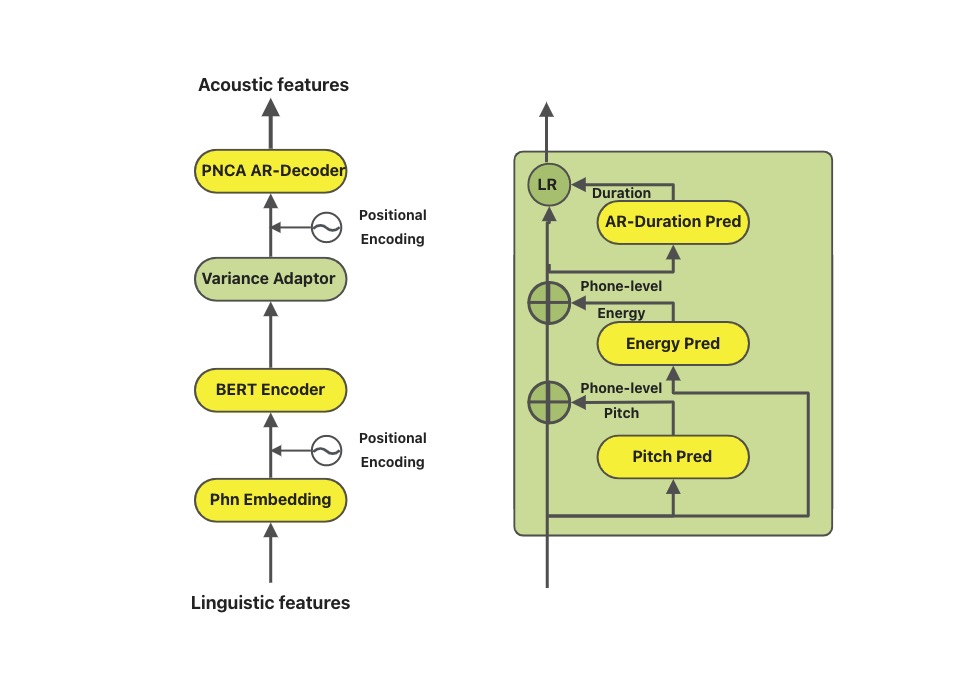
韵律建模SAMBERT声学模型
在整个链路中,和效果最相关的模块就是声学模型。在语音合成领域,类似FastSpeech的Parallel模型是目前的主流,它针对基频(pitch)、能量(energy)和时长(duration)三种韵律表征分别建模。但是,该类模型普遍存在一些效果和性能上的问题,例如,独立建模时长、基频、能量,忽视了其内在联系;完全非自回归的网络结构,无法满足工业级实时合成需求;帧级别基频和能量预测不稳定。 因此达摩院语音实验室设计了SAMBERT,一种基于Parallel结构的改良版TTS模型,它具有以下优点:
1. Backbone采用Self-Attention-Mechanism(SAM),提升模型建模能力。
2. Encoder部分采用BERT进行初始化,引入更多文本信息,提升合成韵律。
3. Variance Adaptor对音素级别的韵律(基频、能量、时长)轮廓进行粗粒度的预测,再通过decoder进行帧级别细粒度的建模;并在时长预测时考虑到其与基频、能量的关联信息,结合自回归结构,进一步提升韵律自然度.
4. Decoder部分采用PNCA AR-Decoder[@li2020robutrans],自然支持流式合成。
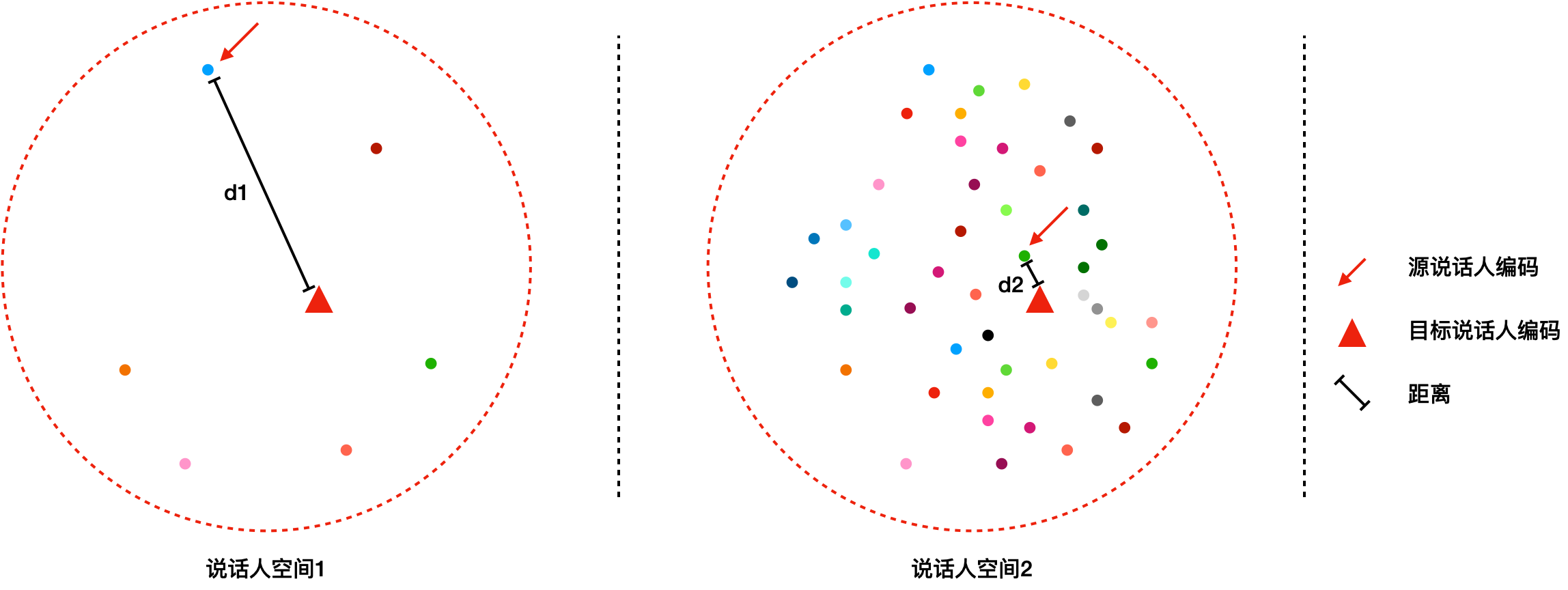
基于说话人特征信息的个性化语音合成
如果需要进行迁移学习,那么需要先构建多说话人的声学模型,不同说话人是通过可训练的说话人编码(speaker embedding)进行区分的。给定新的一个说话人,一般通过随机初始化一个speaker embedding,然后再基于这个说话人的数据进行更新(见下图说话人空间1)。对于个性化语音合成来说,发音人的数据量比较少,学习难度很大,最终合成声音的相似度就无法保证。因此,我们采用说话人特征信息来表示每个说话人,此时,以少量说话人数据初始化的 speaker embedding 距离实际的目标说话人更近得多(见下图说话人空间2),学习难度小,此时合成声音的相似度就比较高。采用基于说话人特征信息的个性化语音合成,使得在20句条件下,依旧能够有较好的相似度。
Notebook最佳实践
首先我们从sample_test_female或者sample_test_male获得示例音频文件, 这里以sample_test_male为例。
解压完成后得到如下文件结构:
test_male
├── 01_000001.wav
├── 01_000002.wav
├── 01_000003.wav
├── 01_000004.wav
├── 01_000005.wav
├── 01_000006.wav
├── 01_000007.wav
├── 01_000008.wav
├── 01_000009.wav
├── 01_000010.wav
├── 01_000011.wav
├── 01_000012.wav
├── 01_000013.wav
├── 01_000014.wav
├── 01_000015.wav
├── 01_000016.wav
├── 01_000017.wav
├── 01_000018.wav
├── 01_000019.wav
└── 01_000020.wav

接着选择这些wav文件上传至Notebook
前置工作
使用AutoLabeling需要用到nltk, 由于国内访问nltk资源较慢,所以我们建议先按下面的步骤手动下载nltk资源。
在Terminal界面下使用wget获取nltk_data并解压至home目录
# 切换至home目录
cd ~
# 安装zip
apt install zip
# 下载并解压nltk_data
wget https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/TTS/download_files/nltk_data.zip
unzip nltk_data.zip

运行TTS-AutoLabel自动标注
首先在Notebook左侧新建TTS-AutoLabel工作文件夹output_training_data, 然后在Notebook code block中输入如下代码并运行, 由于Notebook运行环境已经安装了modelscope和tts-autolabel此处可以直接导入。
from modelscope.tools import run_auto_label
input_wav = "./test_wavs/"
output_data = "./output_training_data/"
ret, report = run_auto_label(input_wav=input_wav, work_dir=output_data, resource_revision="v1.0.4")

基于PTTS-basemodel微调
获得标注好的训练数据后,我们进行模型微调,新建一个Notebook代码块,并输入如下代码运行
from modelscope.metainfo import Trainers
from modelscope.trainers import build_trainer
from modelscope.utils.audio.audio_utils import TtsTrainType
pretrained_model_id = 'damo/speech_personal_sambert-hifigan_nsf_tts_zh-cn_pretrain_16k'
dataset_id = "./output_training_data/"
pretrain_work_dir = "./pretrain_work_dir/"
# 训练信息,用于指定需要训练哪个或哪些模型,这里展示AM和Vocoder模型皆进行训练
# 目前支持训练:TtsTrainType.TRAIN_TYPE_SAMBERT, TtsTrainType.TRAIN_TYPE_VOC
# 训练SAMBERT会以模型最新step作为基础进行finetune
train_info = {
TtsTrainType.TRAIN_TYPE_SAMBERT: { # 配置训练AM(sambert)模型
'train_steps': 202, # 训练多少个step
'save_interval_steps': 200, # 每训练多少个step保存一次checkpoint
'log_interval': 10 # 每训练多少个step打印一次训练日志
}
}
# 配置训练参数,指定数据集,临时工作目录和train_info
kwargs = dict(
model=pretrained_model_id, # 指定要finetune的模型
model_revision = "v1.0.5",
work_dir=pretrain_work_dir, # 指定临时工作目录
train_dataset=dataset_id, # 指定数据集id
train_type=train_info # 指定要训练类型及参数
)
trainer = build_trainer(Trainers.speech_kantts_trainer,
default_args=kwargs)
trainer.train()

微调过程大概需要5分钟的时间,请耐心等待。
体验模型合成效果
使用上一步微调得到的模型合成音频,新建一个Notebook代码块, 输入以下代码
import os
from modelscope.models.audio.tts import SambertHifigan
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
model_dir = os.path.abspath("./pretrain_work_dir")
custom_infer_abs = {
'voice_name':
'F7',
'am_ckpt':
os.path.join(model_dir, 'tmp_am', 'ckpt'),
'am_config':
os.path.join(model_dir, 'tmp_am', 'config.yaml'),
'voc_ckpt':
os.path.join(model_dir, 'orig_model', 'basemodel_16k', 'hifigan', 'ckpt'),
'voc_config':
os.path.join(model_dir, 'orig_model', 'basemodel_16k', 'hifigan',
'config.yaml'),
'audio_config':
os.path.join(model_dir, 'data', 'audio_config.yaml'),
'se_file':
os.path.join(model_dir, 'data', 'se', 'se.npy')
}
kwargs = {'custom_ckpt': custom_infer_abs}
model_id = SambertHifigan(os.path.join(model_dir, "orig_model"), **kwargs)
inference = pipeline(task=Tasks.text_to_speech, model=model_id)
output = inference(input="今天的天气真不错")
import IPython.display as ipd
ipd.Audio(output["output_wav"], rate=16000)

点击播放控件即可体验合成音频。
KAN-TTS最佳实践
环境搭建
获取KAN-TTS源码, 后续操作默认在代码库根目录下执行
git clone -b develop https://github.com/alibaba-damo-academy/KAN-TTS.git
cd KAN-TTS
我们推荐使用Anaconda来搭建Python虚拟环境,使用以下命令创建(目前只兼容Linux x86系统):
# 防止使用pip安装时出现网络问题,建议切换国内pip源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 创建虚拟环境
conda env create -f environment.yaml
# 激活虚拟环境
conda activate maas
拉取预训练模型
ModelScope中文个性化语音合成模型是达摩院语音实验室在1000多小时4000多人数据集上训练产出的预训练模型,我们以此为basemodel做后续微调。 使用git命令拉取模型,在拉取前,首先你需要安装git-lfs, 具体的安装教程见Git Large File Storage,安装完成后执行以下命令:
# 克隆预训练模型
git clone https://www.modelscope.cn/damo/speech_personal_sambert-hifigan_nsf_tts_zh-cn_pretrain_16k.git
数据获取与自动标注
目前KAN-TTS个性化语音合成支持达摩院TTS标准数据格式和普通音频格式。 其中达摩院TTS标准数据格式,wav文件夹下存放了音频文件,prosody文件夹下的.txt文件对应的是音频文件的文本标注,interval文件夹下存放的是音素级别的时间戳标注,如下:
.
├── interval
│ ├── 500001.interval
│ ├── 500002.interval
│ ├── 500003.interval
│ ├── ...
│ └── 500020.interval
├── prosody
│ └── prosody.txt
└── wav
├── 500001.wav
├── 500002.wav
├── ...
└── 500020.wav
普通音频数据,不携带时间戳标注和prosody标注,如下:
.
└── wav
├── 1.wav
├── 2.wav
├── ...
└── 20.wav
快速开始:你可以从ModelScope下载经过阿里标准格式处理的AISHELL-3开源语音合成数据集,用来进行后续操作。如果你只有普通音频格式的数据,那么可以采用PTTS Autolabel自动化标注工具进行格式转换,下面介绍使用Notebook 进行PTTS Autolable自动化标注的方式。
PTTS Autolable自动化标注
打开右上角的Notebook,上传sample_test_male的20条音频文件到目录如/mnt/workspace/Data/ptts_spk0_wav下面
ptts_spk0_wav
├── 01_000001.wav
├── 01_000002.wav
├── 01_000003.wav
├── 01_000004.wav
├── 01_000005.wav
├── 01_000006.wav
├── 01_000007.wav
├── 01_000008.wav
├── 01_000009.wav
├── 01_000010.wav
├── 01_000011.wav
├── 01_000012.wav
├── 01_000013.wav
├── 01_000014.wav
├── 01_000015.wav
├── 01_000016.wav
├── 01_000017.wav
├── 01_000018.wav
├── 01_000019.wav
└── 01_000020.wav
在Notebook的Jupyter中安装tts-autolabel
# 运行此代码块安装tts-autolabel
import sys
!{sys.executable} -m pip install tts-autolabel -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
# 导入run_auto_label工具, 初次运行会下载相关库文件
from modelscope.tools import run_auto_label
# 运行 autolabel进行自动标注,20句音频的自动标注约4分钟
import os
input_wav = '/mnt/workspace/Data/ptts_spk0_wav' # wav audio path
work_dir = '/mnt/workspace/Data/ptts_spk0_autolabel' # output path
os.makedirs(work_dir, exist_ok=True)
ret, report = run_auto_label(input_wav = input_wav,
work_dir = work_dir,
resource_revision='v1.0.4')
print(report)
完成数据标注后,下载对应文件夹/mnt/workspace/Data/ptts_spk0_autolabel, 使用KAN-TTS的数据前处理脚本做训练前数据准备。
我们选择个性化语音合成配置文件进行特征提取操作,这里我们以提供的16k采样率为例kantts/configs/audio_config_se_16k.yaml 运行以下命令来进行特征提取,其中--speaker代表该数据集对应发音人的名称,用户可以随意命名。
# 特征提取
python kantts/preprocess/data_process.py --voice_input_dir ptts_spk0_autolabel --voice_output_dir training_stage/test_male_ptts_feats --audio_config kantts/configs/audio_config_se_16k.yaml --speaker F7 --se_model speech_personal_sambert-hifigan_nsf_tts_zh-cn_pretrain_16k/basemodel_16k/speaker_embedding/se.*
# 扩充epoch
stage0=training_stage
voice=test_male_ptts_feats
cat $stage0/$voice/am_valid.lst >> $stage0/$voice/am_train.lst
lines=0
while [ $lines -lt 400 ]
do
shuf $stage0/$voice/am_train.lst >> $stage0/$voice/am_train.lst.tmp
lines=$(wc -l < "$stage0/$voice/am_train.lst.tmp")
done
mv $stage0/$voice/am_train.lst.tmp $stage0/$voice/am_train.lst
个性化语音合成只需要20句目标说话人的语音,特征提取只需要运行一小段时间,提取完毕后你会在training_stage/test_male_ptts_feats目录下得到如下结构的文件:
# 基于阿里标准格式数据所提取出的特征目录
├── am_train.lst
├── am_valid.lst
├── audio_config.yaml
├── badlist.txt
├── data_process_stdout.log
├── duration
├── energy
├── f0
├── frame_energy
├── frame_f0
├── frame_uv
├── mel
├── raw_duration
├── raw_metafile.txt
├── Script.xml
├── se
├── train.lst
├── valid.lst
└── wav
至此数据准备工作就算完成了。
微调声学模型 KAN-TTS的训练脚本是配置驱动的,我们使用预训练模型中的speech_personal_sambert-hifigan_nsf_tts_zh-cn_pretrain_16k/basemodel_16k/sambert/config.yaml作为训练配置文件。 我们提供默认的PTTS 默认使用的finetune参数值,希望在basemodel的基础上继续微调一定步数并保存,即train_max_steps配置项。
# 将train_max_steps改为 2400301
...
train_max_steps: 2400301
...
完成上述必要的配置项修改后,我们就可以使用以下命令训练声学模型了:
# 训练声学模型
CUDA_VISIBLE_DEVICES=0 python kantts/bin/train_sambert.py --model_config speech_personal_sambert-hifigan_nsf_tts_zh-cn_pretrain_16k/basemodel_16k/sambert/config.yaml --root_dir training_stage/test_male_ptts_feats --stage_dir training_stage/test_male_ptts_sambert_ckpt --resume_path speech_personal_sambert-hifigan_nsf_tts_zh-cn_pretrain_16k/basemodel_16k/sambert/ckpt/checkpoint_*.pth
体验微调模型效果 在声学模型微调完毕后,我们就可以使用产出的模型文件和预训练的声码器来合成语音了,在此之前需要做一些准备工作。
将我们想要合成的文本写入一个文件test.txt,每句话按行分隔,如下所示
徐玠诡谲多智,善揣摩,知道徐知询不可辅佐,掌握着他的短处以归附徐知诰。
许乐夫生于山东省临朐县杨善镇大辛庄,毕业于抗大一分校。
宣统元年(1909年),顺德绅士冯国材在香山大黄圃成立安洲农务分会,管辖东海十六沙,冯国材任总理。
学生们大多住在校区宿舍,通过参加不同的体育文化俱乐部及社交活动,形成一个友谊长存的社会圈。
学校的“三节一会”(艺术节、社团节、科技节、运动会)是显示青春才华的盛大活动。
雪是先天自闭症患者,不懂与人沟通,却拥有灵敏听觉,而且对复杂动作过目不忘。
勋章通过一柱状螺孔和螺钉附着在衣物上。
雅恩雷根斯堡足球俱乐部()是一家位于德国雷根斯堡的足球俱乐部,处于德国足球丙级联赛。
亚历山大·格罗滕迪克于1957年证明了一个深远的推广,现在叫做格罗滕迪克–黎曼–罗赫定理。
运行以下命令进行合成,其中se_file为特征提取环节抽取的speaker embedding,voc_ckpt为basemodel_16k中的预训练模型:
# 运行合成语音
CUDA_VISIBLE_DEVICES=0 python kantts/bin/text_to_wav.py --txt test.txt --output_dir res/test_male_ptts_syn --res_zip speech_sambert-hifigan_tts_zh-cn_multisp_pretrain_16k/resource.zip --am_ckpt training_stage/test_male_ptts_sambert_ckpt/ckpt/checkpoint_2400300.pth --voc_ckpt speech_sambert-hifigan_tts_zh-cn_multisp_pretrain_16k/hifigan/ckpt/checkpoint_2400000.pth --se_file training_stage/test_male_ptts_feats/se/se.npy
完成后在res/test_male_ptts_syn/res_wavs文件夹下就可以获得合成结果
.
├── 0.wav
├── 1.wav
├── 2.wav
├── 3.wav
├── 4.wav
├── 5.wav
├── 6.wav
├── 7.wav
└── 8.wav
合成样音
原始录音
模型局限性以及可能的偏差
- 该发音人支持中文及英文混合,TN规则为中文
训练数据介绍
使用约4000个不同发音人,共计约1000小时数据训练, 主要为中文语料, 包含少量英文语料。
模型训练流程
模型所需训练数据格式为:音频(.wav), 文本标注(.txt), 音素时长标注(.interval), 个性化语音合成模型微调训练时间需要2~5分钟。
预处理
模型训练需对音频文件提取声学特征(梅尔频谱);音素时长根据配置项中的帧长将时间单位转换成帧数;文本标注,根据配置项中的音素集、音调分类、边界分类转换成对应的one-hot编号;
引用
如果你觉得这个该模型对有所帮助,请考虑引用下面的相关的论文:
@inproceedings{li2020robutrans,
title={Robutrans: A robust transformer-based text-to-speech model},
author={Li, Naihan and Liu, Yanqing and Wu, Yu and Liu, Shujie and Zhao, Sheng and Liu, Ming},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={34},
number={05},
pages={8228--8235},
year={2020}
}
@article{devlin2018bert,
title={Bert: Pre-training of deep bidirectional transformers for language understanding},
author={Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1810.04805},
year={2018}
}
@article{kong2020hifi,
title={Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis},
author={Kong, Jungil and Kim, Jaehyeon and Bae, Jaekyoung},
journal={Advances in Neural Information Processing Systems},
volume={33},
pages={17022--17033},
year={2020}
}
本模型参考了以下实现