

Commit
•
a55f5e2
1
Parent(s):
ff4ec71
add images and app
Browse files- README.md +13 -26
- app.py +122 -0
- images/logos.png +0 -0
- images/semanticSearchSBert.png +0 -0
- images/sentenceEmbeddingsProcess.png +0 -0
- requirements.txt +4 -0
README.md
CHANGED
|
@@ -1,46 +1,33 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: streamlit
|
| 7 |
app_file: app.py
|
| 8 |
pinned: false
|
| 9 |
-
license: cc
|
| 10 |
---
|
| 11 |
|
| 12 |
# Configuration
|
| 13 |
|
| 14 |
-
`title`: _string_
|
| 15 |
Display title for the Space
|
| 16 |
|
| 17 |
-
`emoji`: _string_
|
| 18 |
Space emoji (emoji-only character allowed)
|
| 19 |
|
| 20 |
-
`colorFrom`: _string_
|
| 21 |
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
|
| 22 |
|
| 23 |
-
`colorTo`: _string_
|
| 24 |
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
|
| 25 |
|
| 26 |
-
`sdk`: _string_
|
| 27 |
-
Can be either `gradio
|
| 28 |
|
| 29 |
-
`
|
| 30 |
-
|
| 31 |
-
See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
|
| 32 |
-
|
| 33 |
-
`app_file`: _string_
|
| 34 |
-
Path to your main application file (which contains either `gradio` or `streamlit` Python code, or `static` html code).
|
| 35 |
Path is relative to the root of the repository.
|
| 36 |
|
| 37 |
-
`
|
| 38 |
-
HF model IDs (like "gpt2" or "deepset/roberta-base-squad2") used in the Space.
|
| 39 |
-
Will be parsed automatically from your code if not specified here.
|
| 40 |
-
|
| 41 |
-
`datasets`: _List[string]_
|
| 42 |
-
HF dataset IDs (like "common_voice" or "oscar-corpus/OSCAR-2109") used in the Space.
|
| 43 |
-
Will be parsed automatically from your code if not specified here.
|
| 44 |
-
|
| 45 |
-
`pinned`: _boolean_
|
| 46 |
Whether the Space stays on top of your list.
|
|
|
|
| 1 |
---
|
| 2 |
+
title: Sentence Embeddings
|
| 3 |
+
emoji: 🔥
|
| 4 |
+
colorFrom: yellow
|
| 5 |
+
colorTo: purple
|
| 6 |
sdk: streamlit
|
| 7 |
app_file: app.py
|
| 8 |
pinned: false
|
|
|
|
| 9 |
---
|
| 10 |
|
| 11 |
# Configuration
|
| 12 |
|
| 13 |
+
`title`: _string_
|
| 14 |
Display title for the Space
|
| 15 |
|
| 16 |
+
`emoji`: _string_
|
| 17 |
Space emoji (emoji-only character allowed)
|
| 18 |
|
| 19 |
+
`colorFrom`: _string_
|
| 20 |
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
|
| 21 |
|
| 22 |
+
`colorTo`: _string_
|
| 23 |
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
|
| 24 |
|
| 25 |
+
`sdk`: _string_
|
| 26 |
+
Can be either `gradio` or `streamlit`
|
| 27 |
|
| 28 |
+
`app_file`: _string_
|
| 29 |
+
Path to your main application file (which contains either `gradio` or `streamlit` Python code).
|
|
|
|
|
|
|
|
|
|
|
|
|
| 30 |
Path is relative to the root of the repository.
|
| 31 |
|
| 32 |
+
`pinned`: _boolean_
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
Whether the Space stays on top of your list.
|
app.py
ADDED
|
@@ -0,0 +1,122 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from PIL import Image
|
| 3 |
+
from backend import inference
|
| 4 |
+
|
| 5 |
+
st.title("Using Sentence Transformers for semantic search")
|
| 6 |
+
|
| 7 |
+
logos_png = Image.open("images/logos.png")
|
| 8 |
+
st.image(
|
| 9 |
+
logos_png,
|
| 10 |
+
caption="The cool kids on the block.",
|
| 11 |
+
)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
st.subheader("Code Query Search: An Introduction to Semantic Search")
|
| 15 |
+
|
| 16 |
+
st.markdown(
|
| 17 |
+
"""
|
| 18 |
+
Suppose you have a database of texts and you want to find which entries best match the meaning of a single text you have. Example, we want to see which query on Stack Overflow best matches a question you have about Python. However, just word-for-word matching will not work due to the complexity of the programming questions. We need to do a "smart" search: that's what semantic search is for.
|
| 19 |
+
|
| 20 |
+
*"**Semantic search seeks to improve search accuracy by understanding the content of the search query. In contrast to traditional search engines which only find documents based on lexical matches, semantic search can also find synonyms.**" - [SBert Documentation](https://www.sbert.net/examples/applications/semantic-search/README.html)*.
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
Let's make this interactive and use the power of **[Streamlit](https://docs.streamlit.io/) + [HF Spaces](https://huggingface.co/spaces) + the '[sentence-transformers/all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2)' model by creating the programming question search example right here**:
|
| 24 |
+
"""
|
| 25 |
+
)
|
| 26 |
+
|
| 27 |
+
anchor = st.text_input(
|
| 28 |
+
"Please enter here your query about Python, we will look for similar ones",
|
| 29 |
+
value="How to sort a list",
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
n_texts = st.number_input(
|
| 33 |
+
f"""How many similar queries you want?""", value=2, min_value=1
|
| 34 |
+
)
|
| 35 |
+
if st.button("Find the most similar queries in the Stack Overflow query dataset."):
|
| 36 |
+
|
| 37 |
+
st.markdown(
|
| 38 |
+
"""
|
| 39 |
+
**Amazing! These are the entries in our Stack Overflow dataset that better match the language of our specific query.** The 'Description' column shows the description of the entry in our dataset, and the 'Code' column shows the code of the proposed solution. Sorry for the format of the Code!
|
| 40 |
+
"""
|
| 41 |
+
)
|
| 42 |
+
|
| 43 |
+
st.table(
|
| 44 |
+
inference.query_search(
|
| 45 |
+
anchor, n_texts, "sentence-transformers/all-mpnet-base-v2"
|
| 46 |
+
)
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
st.subheader("What happens underneath? Obtaining embeddings")
|
| 51 |
+
|
| 52 |
+
st.markdown(
|
| 53 |
+
f"""
|
| 54 |
+
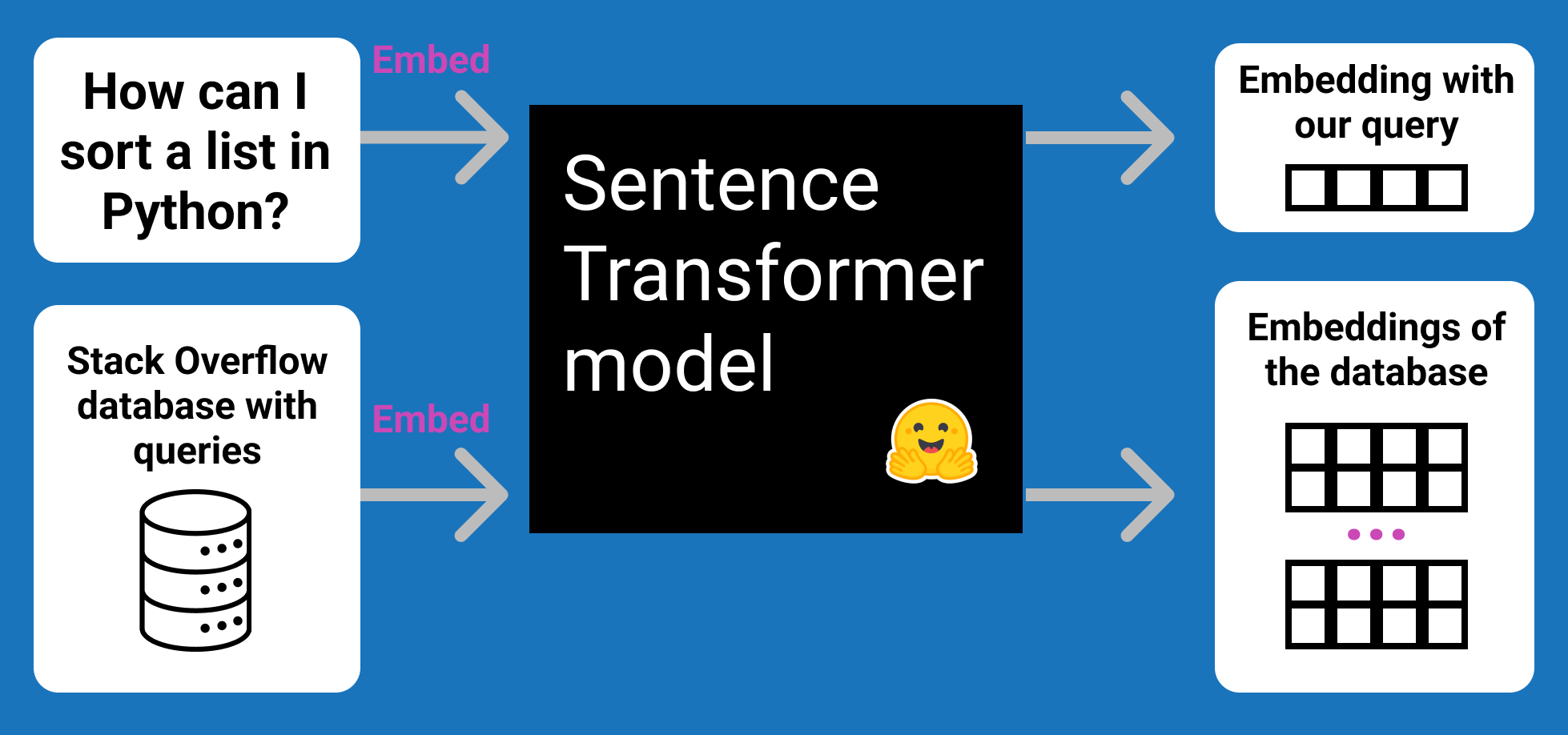
First we embed our database of texts: we convert each of the Stack Overflow queries into a vector space. That is, convert query descriptions from words to numbers that provide an understanding of the language within each query. The understanding of each text will be reflected in a vector called embedding.
|
| 55 |
+
|
| 56 |
+
The system would look like the following figure. We embed (1) our texts database (in this case, the Stack Overflow set of queries), and (2) our own query (in this case: '{anchor}') **with the same model**. Notice that our query could be a matrix of several elements.
|
| 57 |
+
|
| 58 |
+
"""
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
sentenceEmbeddingsProcess_png = Image.open("images/sentenceEmbeddingsProcess.png")
|
| 63 |
+
st.image(
|
| 64 |
+
sentenceEmbeddingsProcess_png,
|
| 65 |
+
caption="Embed the database and your query with the same Sentence Transformers model.",
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
st.subheader("Obtaining the closest observations in the vector space")
|
| 70 |
+
|
| 71 |
+
st.markdown(
|
| 72 |
+
f"""
|
| 73 |
+
We now have two numerical representations of texts (embeddings): one for our original text database and one for our own query. Our goal: get the texts in the database that have the closest meaning to our query.
|
| 74 |
+
|
| 75 |
+
Queries that are most similar to each other will be closer together in the vector space, and queries that differ most will be farther apart.
|
| 76 |
+
|
| 77 |
+
The following figure (obtained from the [Sentence Transformers documentation](https://www.sbert.net/examples/applications/semantic-search/README.html)) shows in blue how we would represent the Stack Overflow query database, and in orange your '**{anchor}**' query which is outside the original database. The blue dot with the annotation 'Relevant Document' would be the most similar Stack Overflow query to our search.
|
| 78 |
+
|
| 79 |
+
"""
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
semanticSearchSBert_png = Image.open("images/semanticSearchSBert.png")
|
| 83 |
+
st.image(
|
| 84 |
+
semanticSearchSBert_png,
|
| 85 |
+
caption="Representation of embeddings in a 2D vector space. Obtained from the Sentence Transformers documentation.",
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
st.markdown(
|
| 89 |
+
"""
|
| 90 |
+
|
| 91 |
+
We compare the embedding of our query with the embeddings of each of the texts in the database (there are easier ways to do it but in this case it won't be necessary) using the cosine similarity function, better explained in the [Pytorch documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.cosine_similarity.html). The results of the cosine similarity function will detect which of the texts in the database are closest to our query in vector space.
|
| 92 |
+
|
| 93 |
+
This is what we did un the dynamic example above!
|
| 94 |
+
"""
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
st.subheader("Check this cool resources!")
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
st.markdown(
|
| 102 |
+
"""
|
| 103 |
+
If you want to know more about the Sentence Transformers library:
|
| 104 |
+
- **The [Hugging Face Organization](https://huggingface.co/sentence-transformers)** for all the new models and instructions on how to download models.
|
| 105 |
+
- The **[Nils Reimers tweet](https://twitter.com/Nils_Reimers/status/1487014195568775173) comparing Sentence Transformer models with GPT-3 Embeddings**. Spoiler alert: the Sentence Transformers are awesome!
|
| 106 |
+
- The **[Sentence Transformers documentation](https://www.sbert.net/)**,
|
| 107 |
+
"""
|
| 108 |
+
)
|
| 109 |
+
|
| 110 |
+
separator = """
|
| 111 |
+
---
|
| 112 |
+
"""
|
| 113 |
+
|
| 114 |
+
st.markdown(separator)
|
| 115 |
+
|
| 116 |
+
st.markdown(
|
| 117 |
+
"""
|
| 118 |
+
Thanks for reading!
|
| 119 |
+
|
| 120 |
+
- Omar Espejel ([@espejelomar](https://twitter.com/espejelomar))
|
| 121 |
+
"""
|
| 122 |
+
)
|
images/logos.png
ADDED

|
images/semanticSearchSBert.png
ADDED

|
images/sentenceEmbeddingsProcess.png
ADDED
|
requirements.txt
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
sentence_transformers
|
| 2 |
+
pandas
|
| 3 |
+
streamlit
|
| 4 |
+
torch
|