Spaces:
Runtime error

Runtime error
VITS for Japanese
VITS: Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
Several recent end-to-end text-to-speech (TTS) models enabling single-stage training and parallel sampling have been proposed, but their sample quality does not match that of two-stage TTS systems. In the repository, I will introduce a VITS model for Japanese on pytorch version 2.0.0 that customed from VITS model.
We also provide the pretrained models.
| VITS at training | VITS at inference |
|---|---|
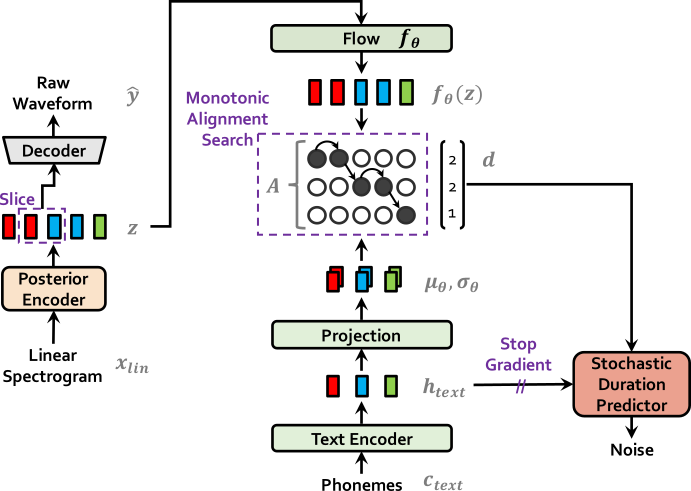 |
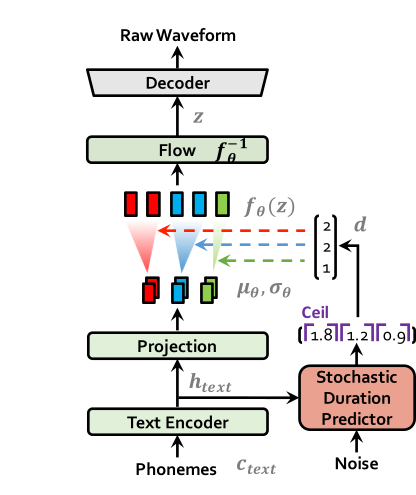 |
Pre-requisites
- Python >= 3.6
- Clone this repository
- Install python requirements. Please refer requirements.txt
- Download datasets
- Download and extract the Japanese Speech dataset, then choose
basic5000dataset and move tojp_datasetfolder.
- Download and extract the Japanese Speech dataset, then choose
- Build Monotonic Alignment Search and run preprocessing if you use your own datasets.
# Cython-version Monotonoic Alignment Search
cd monotonic_align
python setup.py build_ext --inplace
# Preprocessing (g2p) for your own datasets. Preprocessed phonemes for LJ Speech and VCTK have been already provided.
# python preprocess.py --text_index 1 --filelists filelists/jp_audio_text_train_filelist.txt filelists/jp_audio_text_val_filelist.txt filelists/jp_audio_text_test_filelist.txt
Training Example
# JP Speech
python train.py -c configs/jp_base.json -m jp_base
Inference Example
See vits_apply.ipynb