

A newer version of the Gradio SDK is available:
4.39.0
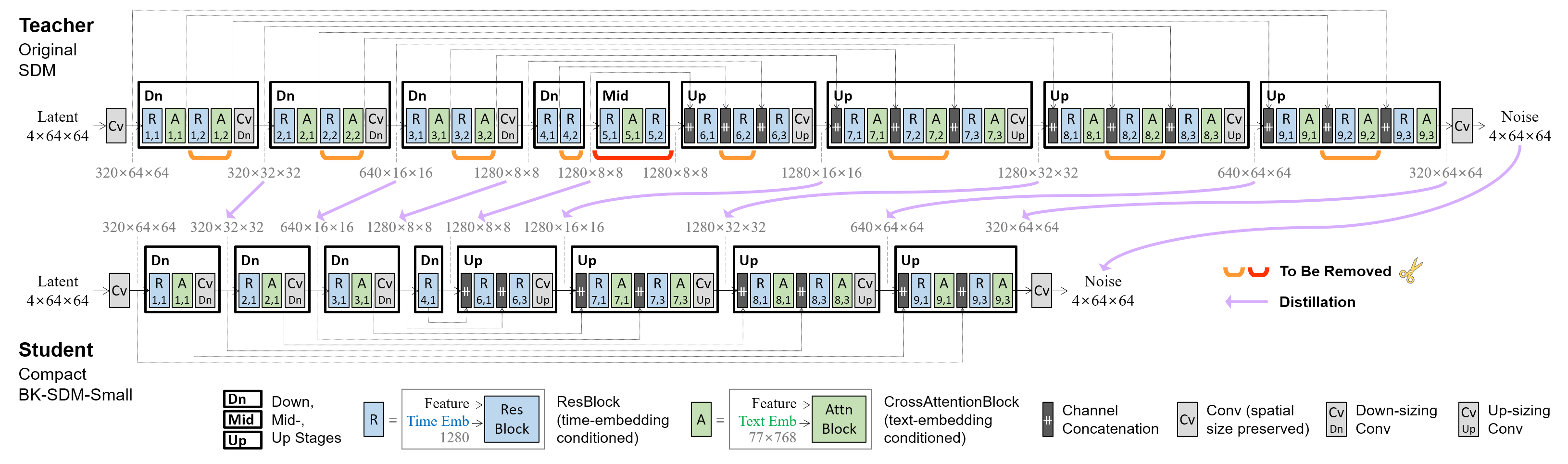
This demo showcases a lightweight Stable Diffusion model (SDM) for general-purpose text-to-image synthesis. Our model BK-SDM-Small achieves 36% reduced parameters and latency. This model is bulit with (i) removing several residual and attention blocks from the U-Net of SDM-v1.4 and (ii) distillation pretraining on only 0.22M LAION pairs (fewer than 0.1% of the full training set). Despite very limited training resources, our model can imitate the original SDM by benefiting from transferred knowledge.
- For more information & acknowledgments, please see Paper, GitHub, BK-SDM-{Base, Small, Tiny} Model Card.
- This research was accepted to ICCV 2023 Demo Track & ICML 2023 Workshop on Efficient Systems for Foundation Models (ES-FoMo).
- Please be aware that your prompts are logged, without any personally identifiable information.
- For different images with the same prompt, please change Random Seed in Advanced Settings (because of using the firstly sampled latent code per seed).
**Demo Environment**: [Oct/08/2023] Free CPU-basic (2 vCPU · 16 GB RAM) — 7~10 min slow inference (for a 512×512 image with 25 denoising steps)
- 🙏 Better to use Hosted inference API in Our Model Card
Previous Env Setup:
[Oct/01/2023] NVIDIA T4-small (4 vCPU · 15 GB RAM · 16GB VRAM) — 5~10 sec inference.[Sept/01/2023] Free CPU-basic (2 vCPU · 16 GB RAM) — 7~10 min slow inference.
[Aug/01/2023] NVIDIA T4-small (4 vCPU · 15 GB RAM · 16GB VRAM) — 5~10 sec inference.
[July/31/2023] Free CPU-basic (2 vCPU · 16 GB RAM) — 7~10 min slow inference.
[July/27/2023] NVIDIA T4-small (4 vCPU · 15 GB RAM · 16GB VRAM) — 5~10 sec inference.
[June/30/2023] Free CPU-basic (2 vCPU · 16 GB RAM) — 7~10 min slow inference.
[May/31/2023] NVIDIA T4-small (4 vCPU · 15 GB RAM · 16GB VRAM) — 5~10 sec inference.