Spaces:
Runtime error


Runtime error
metadata
license: mit
title: RAM_Tag2Text
sdk: gradio
emoji: 🐠
colorFrom: blue
colorTo: yellow
app_file: app.py
pinned: false
duplicated_from: xinyu1205/Recognize_Anything-Tag2Text
:label: Recognize Anything: A Strong Image Tagging Model & Tag2Text: Guiding Vision-Language Model via Image Tagging
Official PyTorch Implementation of the Recognize Anything Model (RAM) and the Tag2Text Model.
- RAM is a strong image tagging model, which can recognize any common category with high accuracy.
- Tag2Text is an efficient and controllable vision-language model with tagging guidance.
When combined with localization models (Grounded-SAM), Tag2Text and RAM form a strong and general pipeline for visual semantic analysis.

:sun_with_face: Helpful Tutorial
- :apple: [Access RAM Homepage]
- :grapes: [Access Tag2Text Homepage]
- :sunflower: [Read RAM arXiv Paper]
- :rose: [Read Tag2Text arXiv Paper]
- :mushroom: [Try our Tag2Text web Demo! 🤗]
:bulb: Highlight
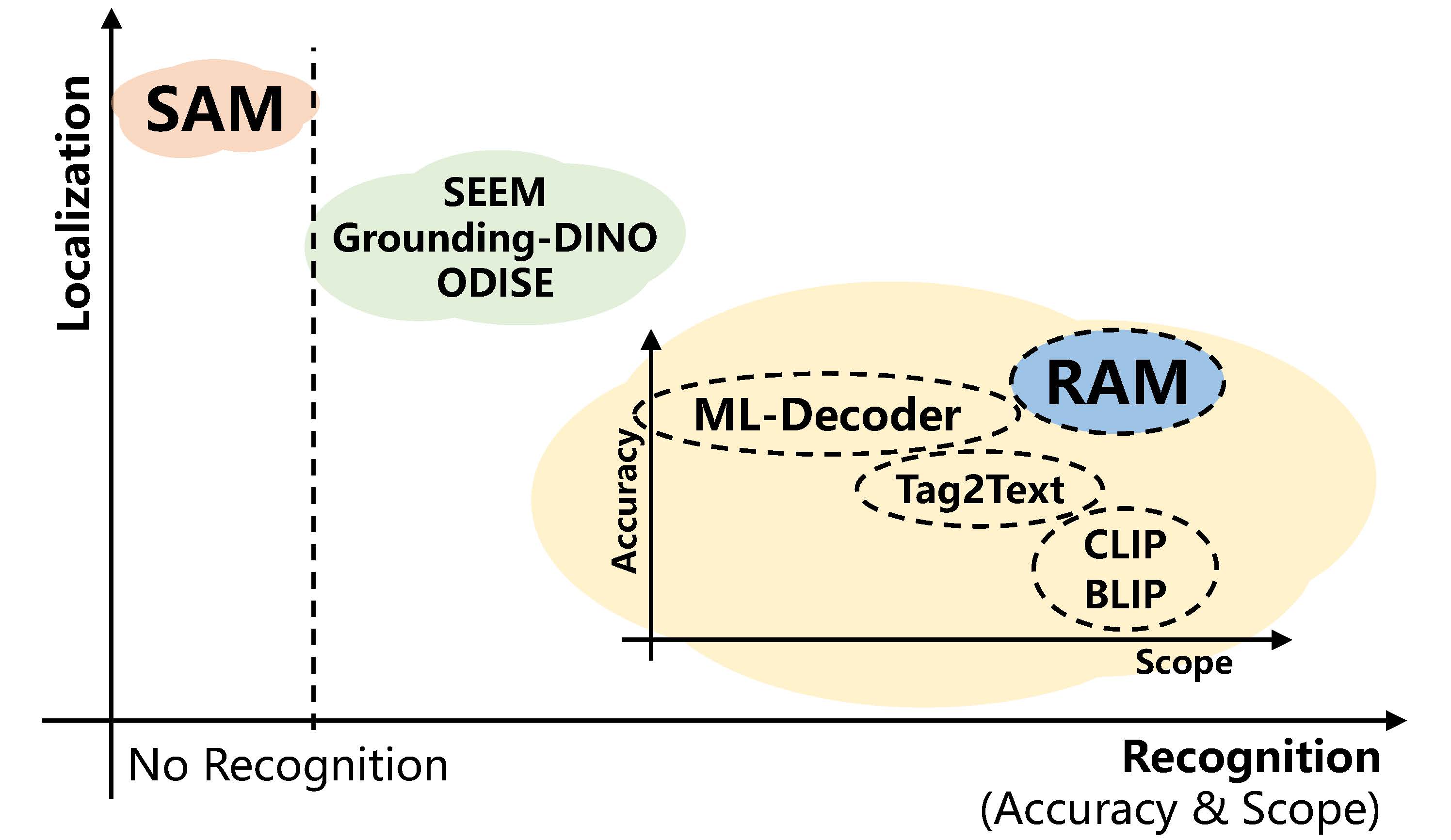
Recognition and localization are two foundation computer vision tasks.
- The Segment Anything Model (SAM) excels in localization capabilities, while it falls short when it comes to recognition tasks.
- The Recognize Anything Model (RAM) and Tag2Text exhibits exceptional recognition abilities, in terms of both accuracy and scope.
 |
Tag2Text for Vision-Language Tasks.
- Tagging. Without manual annotations, Tag2Text achieves superior image tag recognition ability of 3,429 commonly human-used categories.
- Efficient. Tagging guidance effectively enhances the performance of vision-language models on both generation-based and alignment-based tasks.
- Controllable. Tag2Text permits users to input desired tags, providing the flexibility in composing corresponding texts based on the input tags.
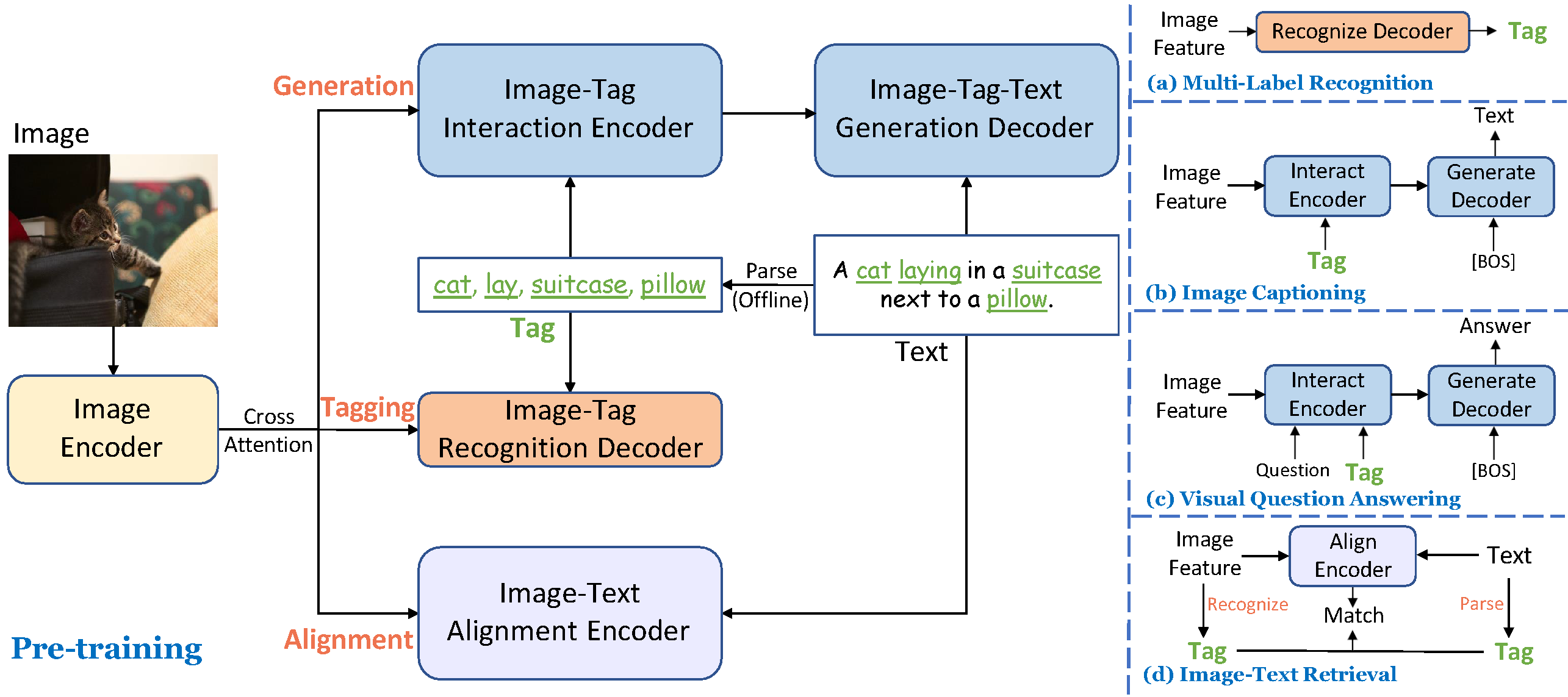 |
Advancements of RAM on Tag2Text.
- Accuracy. RAM utilizes a data engine to generate additional annotations and clean incorrect ones, resulting higher accuracy compared to Tag2Text.
- Scope. Tag2Text recognizes 3,400+ fixed tags. RAM upgrades the number to 6,400+, covering more valuable categories. With open-set capability, RAM is feasible to recognize any common category.
:sparkles: Highlight Projects with other Models
- Tag2Text/RAM with Grounded-SAM is trong and general pipeline for visual semantic analysis, which can automatically recognize, detect, and segment for an image!
- Ask-Anything is a multifunctional video question answering tool. Tag2Text provides powerful tagging and captioning capabilities as a fundamental component.
- Prompt-can-anything is a gradio web library that integrates SOTA multimodal large models, including Tag2text as the core model for graphic understanding
:fire: News
2023/06/07: We release the Recognize Anything Model (RAM), a strong image tagging model!2023/06/05: Tag2Text is combined with Prompt-can-anything.2023/05/20: Tag2Text is combined with VideoChat.2023/04/20: We marry Tag2Text with with Grounded-SAM.2023/04/10: Code and checkpoint is available Now!2023/03/14: Tag2Text web demo 🤗 is available on Hugging Face Space!
:writing_hand: TODO
- Release Tag2Text demo.
- Release checkpoints.
- Release inference code.
- Release RAM demo and checkpoints (until June 14th at the latest).
- Release training codes (until August 1st at the latest).
- Release training datasets (until August 1st at the latest).
:toolbox: Checkpoints
| name | backbone | Data | Illustration | Checkpoint | |
|---|---|---|---|---|---|
| 1 | Tag2Text-Swin | Swin-Base | COCO, VG, SBU, CC-3M, CC-12M | Demo version with comprehensive captions. | Download link |
:running: Tag2Text Inference
- Install the dependencies, run:
pip install -r requirements.txt
Download Tag2Text pretrained checkpoints.
Get the tagging and captioning results:
python inference.py --image images/1641173_2291260800.jpg
Or get the tagging and sepcifed captioning results (optional):
--pretrained pretrained/tag2text_swin_14m.pthpython inference.py --image images/1641173_2291260800.jpg
--pretrained pretrained/tag2text_swin_14m.pth
--specified-tags "cloud,sky"
:black_nib: Citation
If you find our work to be useful for your research, please consider citing.
@misc{zhang2023recognize,
title={Recognize Anything: A Strong Image Tagging Model},
author={Youcai Zhang and Xinyu Huang and Jinyu Ma and Zhaoyang Li and Zhaochuan Luo and Yanchun Xie and Yuzhuo Qin and Tong Luo and Yaqian Li and Shilong Liu and Yandong Guo and Lei Zhang},
year={2023},
eprint={2306.03514},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@article{huang2023tag2text,
title={Tag2Text: Guiding Vision-Language Model via Image Tagging},
author={Huang, Xinyu and Zhang, Youcai and Ma, Jinyu and Tian, Weiwei and Feng, Rui and Zhang, Yuejie and Li, Yaqian and Guo, Yandong and Zhang, Lei},
journal={arXiv preprint arXiv:2303.05657},
year={2023}
}
:hearts: Acknowledgements
This work is done with the help of the amazing code base of BLIP, thanks very much!
We also want to thank @Cheng Rui @Shilong Liu @Ren Tianhe for their help in marrying Tag2Text with Grounded-SAM.