Spaces:
Running

A newer version of the Gradio SDK is available:
5.6.0
数字人智能对话系统 - Linly-Talker — “数字人交互,与虚拟的自己互动”
2023.12 更新 📆
用户可以上传任意图片进行对话
2024.01 更新 📆
- 令人兴奋的消息!我现在已经将强大的GeminiPro和Qwen大模型融入到我们的对话场景中。用户现在可以在对话中上传任何图片,为我们的互动增添了全新的层面。
- 更新了FastAPI的部署调用方法。
- 更新了微软TTS的高级设置选项,增加声音种类的多样性,以及加入视频字幕加强可视化。
- 更新了GPT多轮对话系统,使得对话有上下文联系,提高数字人的交互性和真实感。
2024.02 更新 📆
- 更新了Gradio的版本为最新版本4.16.0,使得界面拥有更多的功能,比如可以摄像头拍摄图片构建数字人等。
- 更新了ASR和THG,其中ASR加入了阿里的FunASR,具体更快的速度;THG部分加入了Wav2Lip模型,ER-NeRF在准备中(Comming Soon)。
- 加入了语音克隆方法GPT-SoVITS模型,能够通过微调一分钟对应人的语料进行克隆,效果还是相当不错的,值得推荐。
- 集成一个WebUI界面,能够更好的运行Linly-Talker。
2024.04 更新 📆
- 更新了除 Edge TTS的 Paddle TTS的离线方式。
- 更新了ER-NeRF作为Avatar生成的选择之一。
- 更新了app_talk.py,在不基于对话场景可自由上传语音和图片视频生成。
2024.05 更新 📆
- 更新零基础小白部署 AutoDL 教程,并且更新了codewithgpu的镜像,可以一键进行体验和学习。
- 更新了WebUI.py,Linly-Talker WebUI支持多模块、多模型和多选项
2024.06 更新 📆
- 更新MuseTalk加入Linly-Talker之中,并且更新了WebUI中,能够基本实现实时对话。
目录
介绍
Linly-Talker是一款创新的数字人对话系统,它融合了最新的人工智能技术,包括大型语言模型(LLM)🤖、自动语音识别(ASR)🎙️、文本到语音转换(TTS)🗣️和语音克隆技术🎤。这个系统通过Gradio平台提供了一个交互式的Web界面,允许用户上传图片📷与AI进行个性化的对话交流💬。
系统的核心特点包括:
- 多模型集成:Linly-Talker整合了Linly、GeminiPro、Qwen等大模型,以及Whisper、SadTalker等视觉模型,实现了高质量的对话和视觉生成。
- 多轮对话能力:通过GPT模型的多轮对话系统,Linly-Talker能够理解并维持上下文相关的连贯对话,极大地提升了交互的真实感。
- 语音克隆:利用GPT-SoVITS等技术,用户可以上传一分钟的语音样本进行微调,系统将克隆用户的声音,使得数字人能够以用户的声音进行对话。
- 实时互动:系统支持实时语音识别和视频字幕,使得用户可以通过语音与数字人进行自然的交流。
- 视觉增强:通过数字人生成等技术,Linly-Talker能够生成逼真的数字人形象,提供更加沉浸式的体验。
Linly-Talker的设计理念是创造一种全新的人机交互方式,不仅仅是简单的问答,而是通过高度集成的技术,提供一个能够理解、响应并模拟人类交流的智能数字人。

查看我们的介绍视频 demo video
在B站上我录了一系列视频,也代表我更新的每一步与使用方法,详细查看数字人智能对话系统 - Linly-Talker合集
TO DO LIST
- 基本完成对话系统流程,能够
语音对话 - 加入了LLM大模型,包括
Linly,Qwen和GeminiPro的使用 - 可上传
任意数字人照片进行对话 - Linly加入
FastAPI调用方式 - 利用微软
TTS加入高级选项,可设置对应人声以及音调等参数,增加声音的多样性 - 视频生成加入
字幕,能够更好的进行可视化 - GPT
多轮对话系统(提高数字人的交互性和真实感,增强数字人的智能) - 优化Gradio界面,加入更多模型,如Wav2Lip,FunASR等
-
语音克隆技术,加入GPT-SoVITS,只需要一分钟的语音简单微调即可(语音克隆合成自己声音,提高数字人分身的真实感和互动体验) - 加入离线TTS以及NeRF-based的方法和模型
- Linly-Talker WebUI支持多模块、多模型和多选项
- 为Linly-Talker添加MuseTalk功能,基本达到实时的速度,交流速度很快
- 集成MuseTalk进入Linly-Talker WebUI
-
实时语音识别(人与数字人之间就可以通过语音进行对话交流)
🔆 该项目 Linly-Talker 正在进行中 - 欢迎提出PR请求!如果您有任何关于新的模型方法、研究、技术或发现运行错误的建议,请随时编辑并提交 PR。您也可以打开一个问题或通过电子邮件直接联系我。📩⭐ 如果您发现这个Github Project有用,请给它点个星!🤩
如果在部署的时候有任何的问题,可以关注常见问题汇总.md部分,我已经整理了可能出现的所有问题,另外交流群也在这里,我会定时更新,感谢大家的关注与使用!!!
示例
| 文字/语音对话 | 数字人回答 |
|---|---|
| 应对压力最有效的方法是什么? | |
| 如何进行时间管理? | |
| 撰写一篇交响乐音乐会评论,讨论乐团的表演和观众的整体体验。 | |
| 翻译成中文:Luck is a dividend of sweat. The more you sweat, the luckier you get. |
创建环境
AutoDL已发布镜像,可以直接使用,https://www.codewithgpu.com/i/Kedreamix/Linly-Talker/Kedreamix-Linly-Talker,也可以使用docker来直接创建环境,我也会持续不断的更新镜像
docker pull registry.cn-beijing.aliyuncs.com/codewithgpu2/kedreamix-linly-talker:3iRyoQb112
Windows我加入了一个python一键整合包,可以按顺序进行运行,按照需求按照相应的依赖,并且下载对应的模型,即可运行,主要按照conda以后从02开始安装pytorch进行运行,如果有问题,请随时与我沟通
下载代码
git clone --recursive https://github.com/Kedreamix/Linly-Talker.git
若使用Linly-Talker,可以直接用anaconda进行安装环境,几乎包括所有的模型所需要的依赖,具体操作如下:
conda create -n linly python=3.10
conda activate linly
# pytorch安装方式1:conda安装
# CUDA 11.7
# conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia
# CUDA 11.8
# conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidia
# pytorch安装方式2:pip 安装
# CUDA 11.7
# pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2
# CUDA 11.8
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
conda install ffmpeg==4.2.2 # ffmpeg==4.2.2
pip install -r requirements_webui.txt
# 安装有关musetalk依赖
pip install --no-cache-dir -U openmim
mim install mmengine
mim install "mmcv>=2.0.1"
mim install "mmdet>=3.1.0"
mim install "mmpose>=1.1.0"
# 安装NeRF-based依赖,可能问题较多,可以先放弃
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
pip install -r TFG/requirements_nerf.txt
# 若pyaudio出现问题,可安装对应依赖
# sudo apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
# 注意以下几个模块,若安装不成功,可以进入路径利用pip install . 或者 python setup.py install编译安装
# NeRF/freqencoder
# NeRF/gridencoder
# NeRF/raymarching
# NeRF/shencoder
以下是旧版本的一些安装方法,可能存在会一些依赖冲突的问题,但是也不会出现太多bug,但是为了更好更方便的安装,我就更新了上述版本,以下版本可以忽略,或者遇到问题可以参考一下
首先使用anaconda安装环境,安装pytorch环境,具体操作如下:
conda create -n linly python=3.10 conda activate linly # pytorch安装方式1:conda安装(推荐) conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch # pytorch安装方式2:pip 安装 pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113 conda install -q ffmpeg # ffmpeg==4.2.2 pip install -r requirements_app.txt若使用语音克隆等模型,需要更高版本的Pytorch,但是功能也会更加丰富,不过需要的驱动版本可能要到cuda11.8,可选择
conda create -n linly python=3.10 conda activate linly pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118 conda install -q ffmpeg # ffmpeg==4.2.2 pip install -r requirements_app.txt # 安装语音克隆对应的依赖 pip install -r VITS/requirements_gptsovits.txt若希望使用NeRF-based等模型等话,可能需要安装一下对应的环境
# 安装NeRF对应的依赖 pip install "git+https://github.com/facebookresearch/pytorch3d.git" pip install -r TFG/requirements_nerf.txt # 若pyaudio出现问题,可安装对应依赖 # sudo apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0 # 注意以下几个模块,若安装不成功,可以进入路径利用pip install . 或者 python setup.py install编译安装 # NeRF/freqencoder # NeRF/gridencoder # NeRF/raymarching # NeRF/shencoder若使用PaddleTTS,可安装对应的环境
pip install -r TTS/requirements_paddle.txt若使用FunASR语音识别模型,可安装环境
pip install -r ASR/requirements_funasr.txt若使用MuesTalk模型,可安装环境
pip install --no-cache-dir -U openmim mim install mmengine mim install "mmcv>=2.0.1" mim install "mmdet>=3.1.0" mim install "mmpose>=1.1.0" pip install -r TFG/requirements_musetalk.txt
接下来还需要安装对应的模型,有以下下载方式,下载后安装文件架结构放置,文件夹结构在本文最后有说明,建议从夸克网盘下载,会第一时间更新
- Baidu (百度云盘) (Password:
linl) - huggingface
- modelscope
- Quark(夸克网盘)
我制作一个脚本可以完成下述所有模型的下载,无需用户过多操作。这种方式适合网络稳定的情况,并且特别适合 Linux 用户。对于 Windows 用户,也可以使用 Git 来下载模型。如果网络环境不稳定,用户可以选择使用手动下载方法,或者尝试运行 Shell 脚本来完成下载。脚本具有以下功能。
- 选择下载方式: 用户可以选择从三种不同的源下载模型:ModelScope、Huggingface 或 Huggingface 镜像站点。
- 下载模型: 根据用户的选择,执行相应的下载命令。
- 移动模型文件: 下载完成后,将模型文件移动到指定的目录。
- 错误处理: 在每一步操作中加入了错误检查,如果操作失败,脚本会输出错误信息并停止执行。
sh scripts/download_models.sh
HuggingFace下载
如果速度太慢可以考虑镜像,参考 简便快捷获取 Hugging Face 模型(使用镜像站点)
# 从huggingface下载预训练模型
git lfs install
git clone https://huggingface.co/Kedreamix/Linly-Talker --depth 1
# git lfs clone https://huggingface.co/Kedreamix/Linly-Talker
# pip install -U huggingface_hub
# export HF_ENDPOINT=https://hf-mirror.com # 使用镜像网站
huggingface-cli download --resume-download --local-dir-use-symlinks False Kedreamix/Linly-Talker --local-dir Linly-Talker
ModelScope下载
# 从modelscope下载预训练模型
# 1. git 方法
git lfs install
git clone https://www.modelscope.cn/Kedreamix/Linly-Talker.git --depth 1
# git lfs clone https://www.modelscope.cn/Kedreamix/Linly-Talker.git --depth 1
# 2. Python 代码下载
pip install modelscope
from modelscope import snapshot_download
model_dir = snapshot_download('Kedreamix/Linly-Talker', resume_download=True, cache_dir='./', revision='master')
移动所有模型到当前目录
如果百度网盘下载后,可以参考文档最后目录结构来移动目录
# 移动所有模型到当前目录
# checkpoint中含有SadTalker和Wav2Lip等权重
mv Linly-Talker/checkpoints/* ./checkpoints
# 若使用GFPGAN增强,安装对应的库
# pip install gfpgan
# mv Linly-Talker/gfpan ./
# 语音克隆模型
mv Linly-Talker/GPT_SoVITS/pretrained_models/* ./GPT_SoVITS/pretrained_models/
# Qwen大模型
mv Linly-Talker/Qwen ./
# MuseTalk模型
mkdir -p ./Musetalk/models
mv Linly-Talker/MuseTalk/* ./Musetalk/models
为了大家的部署使用方便,更新了一个configs.py文件,可以对其进行一些超参数修改即可
# 设备运行端口 (Device running port)
port = 6006
# api运行端口及IP (API running port and IP)
mode = 'api' # api 需要先运行Linly-api-fast.py,暂时仅仅适用于Linly
# 本地端口localhost:127.0.0.1 全局端口转发:"0.0.0.0"
ip = '127.0.0.1'
api_port = 7871
# LLM模型路径 (Linly model path)
mode = 'offline'
model_path = 'Qwen/Qwen-1_8B-Chat'
# ssl证书 (SSL certificate) 麦克风对话需要此参数
# 最好调整为绝对路径
ssl_certfile = "./https_cert/cert.pem"
ssl_keyfile = "./https_cert/key.pem"
ASR - Speech Recognition
详细有关于语音识别的使用介绍与代码实现可见 ASR - 同数字人沟通的桥梁
Whisper
借鉴OpenAI的Whisper实现了ASR的语音识别,具体使用方法参考 https://github.com/openai/whisper
FunASR
阿里的FunASR的语音识别效果也是相当不错,而且时间也是比whisper更快的,对中文实际上是更好的。
同时funasr更能达到实时的效果,所以也将FunASR添加进去了,在ASR文件夹下的FunASR文件里可以进行体验,参考 https://github.com/alibaba-damo-academy/FunASR。
Coming Soon
欢迎大家提出建议,激励我不断更新模型,丰富Linly-Talker的功能。
TTS Text To Speech
详细有关于语音识别的使用介绍与代码实现可见 TTS - 赋予数字人真实的语音交互能力
Edge TTS
借鉴使用微软语音服务,具体使用方法参考https://github.com/rany2/edge-tts
PaddleTTS
在实际使用过程中,可能会遇到需要离线操作的情况。由于Edge TTS需要在线环境才能生成语音,因此我们选择了同样开源的PaddleSpeech作为文本到语音(TTS)的替代方案。虽然效果可能有所不同,但PaddleSpeech支持离线操作。更多信息可参考PaddleSpeech的GitHub页面:PaddleSpeech。
Coming Soon
欢迎大家提出建议,激励我不断更新模型,丰富Linly-Talker的功能。
Voice Clone
详细有关于语音克隆的使用介绍与代码实现可见 Voice Clone - 在对话时悄悄偷走你的声音
GPT-SoVITS(推荐)
感谢大家的开源贡献,我借鉴了当前开源的语音克隆模型 GPT-SoVITS,我认为效果是相当不错的,项目地址可参考https://github.com/RVC-Boss/GPT-SoVITS
我将一些训练好的克隆权重放在了Quark(夸克网盘)中,大家可以自取权重和参考音频。
XTTS
Coqui XTTS是一个领先的深度学习文本到语音任务(TTS语音生成模型)工具包,通过使用一段5秒钟以上的语音频剪辑就可以完成声音克隆将语音克隆到不同的语言。
🐸TTS 是一个用于高级文本转语音生成的库。
🚀 超过 1100 种语言的预训练模型。
🛠️ 用于以任何语言训练新模型和微调现有模型的工具。
📚 用于数据集分析和管理的实用程序。
- 在线体验XTTS https://huggingface.co/spaces/coqui/xtts
- 官方Github库 https://github.com/coqui-ai/TTS
Coming Soon
欢迎大家提出建议,激励我不断更新模型,丰富Linly-Talker的功能。
THG - Avatar
详细有关于数字人生成的使用介绍与代码实现可见 THG - 构建智能数字人
SadTalker
数字人生成可使用SadTalker(CVPR 2023),详情介绍见 https://sadtalker.github.io
在使用前先下载SadTalker模型:
bash scripts/sadtalker_download_models.sh
Baidu (百度云盘) (Password: linl)
如果百度网盘下载,记住是放在checkpoints文件夹下,百度网盘下载的默认命名为sadtalker,实际应该重命名为checkpoints
Wav2Lip
数字人生成还可使用Wav2Lip(ACM 2020),详情介绍见 https://github.com/Rudrabha/Wav2Lip
在使用前先下载Wav2Lip模型:
| Model | Description | Link to the model |
|---|---|---|
| Wav2Lip | Highly accurate lip-sync | Link |
| Wav2Lip + GAN | Slightly inferior lip-sync, but better visual quality | Link |
| Expert Discriminator | Weights of the expert discriminator | Link |
| Visual Quality Discriminator | Weights of the visual disc trained in a GAN setup | Link |
ER-NeRF
ER-NeRF(ICCV2023)是使用最新的NeRF技术构建的数字人,拥有定制数字人的特性,只需要一个人的五分钟左右到视频即可重建出来,具体可参考 https://github.com/Fictionarry/ER-NeRF
已更新,以奥巴马形象作为参考,若考虑更好的效果,可能考虑克隆定制数字人的声音以得到更好的效果。
MuseTalk
MuseTalk 是一个实时高质量的音频驱动唇形同步模型,能够以30帧每秒以上的速度在NVIDIA Tesla V100显卡上运行。该模型可以与由 MuseV 生成的输入视频结合使用,作为完整的虚拟人解决方案的一部分。具体可参考 https://github.com/TMElyralab/MuseTalk
MuseTalk 是一个实时高质量的音频驱动唇形同步模型,经过训练可以在 ft-mse-vae 的潜在空间中进行工作。它具有以下特性:
- 未见面孔的同步:根据输入的音频对未见过的面孔进行修改,面部区域的大小为 256 x 256。
- 多语言支持:支持多种语言的音频输入,包括中文、英语和日语。
- 高性能实时推理:在 NVIDIA Tesla V100 上可以实现 30帧每秒以上的实时推理。
- 面部中心点调整:支持修改面部区域的中心点位置,这对生成结果有显著影响。
- HDTF 数据集训练:提供在 HDTF 数据集上训练的模型检查点。
- 训练代码即将发布:训练代码即将发布,方便进一步的开发和研究。
MuseTalk 提供了一个高效且灵活的工具,使虚拟人的面部表情能够精确同步于音频,为实现全方位互动的虚拟人迈出了重要一步。
在Linly-Talker中已经加入了MuseTalk,基于MuseV的视频进行推理,得到了比较理想的速度进行对话,基本达到实时的效果,还是非常不错的,也是可以基于流式进行推理的。
Coming Soon
欢迎大家提出建议,激励我不断更新模型,丰富Linly-Talker的功能。
LLM - Conversation
详细有关于大模型的使用介绍与代码实现可见 LLM - 大语言模型为数字人赋能
Linly-AI
Linly来自深圳大学数据工程国家重点实验室,参考 https://github.com/CVI-SZU/Linly
Qwen
来自阿里云的Qwen,查看 https://github.com/QwenLM/Qwen
如果想要快速使用,可以选1.8B的模型,参数比较少,在较小的显存也可以正常使用,当然这一部分可以替换
下载 Qwen1.8B 模型: https://huggingface.co/Qwen/Qwen-1_8B-Chat
Gemini-Pro
来自 Google 的 Gemini-Pro,了解更多请访问 https://deepmind.google/technologies/gemini/
请求 API 密钥: https://makersuite.google.com/
ChatGPT
来自OpenAI的,需要申请API,了解更多请访问 https://platform.openai.com/docs/introduction
ChatGLM
来自清华的,了解更多请访问 https://github.com/THUDM/ChatGLM3
GPT4Free
可参考https://github.com/xtekky/gpt4free,免费白嫖使用GPT4等模型
LLM 多模型选择
在 webui.py 文件中,轻松选择您需要的模型,⚠️第一次运行要先下载模型,参考Qwen1.8B
Coming Soon
欢迎大家提出建议,激励我不断更新模型,丰富Linly-Talker的功能。
优化
一些优化:
使用固定的输入人脸图像,提前提取特征,避免每次读取
移除不必要的库,缩短总时间
只保存最终视频输出,不保存中间结果,提高性能
使用OpenCV生成最终视频,比mimwrite更快
Gradio
Gradio是一个Python库,提供了一种简单的方式将机器学习模型作为交互式Web应用程序来部署。
对Linly-Talker而言,使用Gradio有两个主要目的:
可视化与演示:Gradio为模型提供一个简单的Web GUI,上传图片和文本后可以直观地看到结果。这是展示系统能力的有效方式。
用户交互:Gradio的GUI可以作为前端,允许用户与Linly-Talker进行交互对话。用户可以上传自己的图片并输入问题,实时获取回答。这提供了更自然的语音交互方式。
具体来说,我们在app.py中创建了一个Gradio的Interface,接收图片和文本输入,调用函数生成回应视频,在GUI中显示出来。这样就实现了浏览器交互而不需要编写复杂的前端。
总之,Gradio为Linly-Talker提供了可视化和用户交互的接口,是展示系统功能和让最终用户使用系统的有效途径。
若考虑实时对话,可能需要换个框架,或者对Gradio进行魔改,希望和大家一起努力
启动WebUI
之前我将很多个版本都是分开来的,实际上运行多个会比较麻烦,所以后续我增加了变成WebUI一个界面即可体验,后续也会不断更新
WebUI
现在已加入WebUI的功能如下
文本/语音数字人对话(固定数字人,分男女角色)
任意图片数字人对话(可上传任意图片数字人)
多轮GPT对话(加入历史对话数据,链接上下文)
语音克隆对话(基于GPT-SoVITS设置进行语音克隆,也可根据语音对话的声音进行克隆)
数字人文本/语音播报(根据输入的文字/语音进行播报)
多模块➕多模型➕多选择
- 角色多选择:女性角色/男性角色/自定义角色(每一部分都可以自动上传图片)/Comming Soon
- TTS模型多选择:EdgeTTS / PaddleTTS/ GPT-SoVITS/Comming Soon
- LLM模型多选择: Linly/ Qwen / ChatGLM/ GeminiPro/ ChatGPT/Comming Soon
- Talker模型多选择:Wav2Lip/ SadTalker/ ERNeRF/ MuseTalk/Comming Soon
- ASR模型多选择:Whisper/ FunASR/Comming Soon
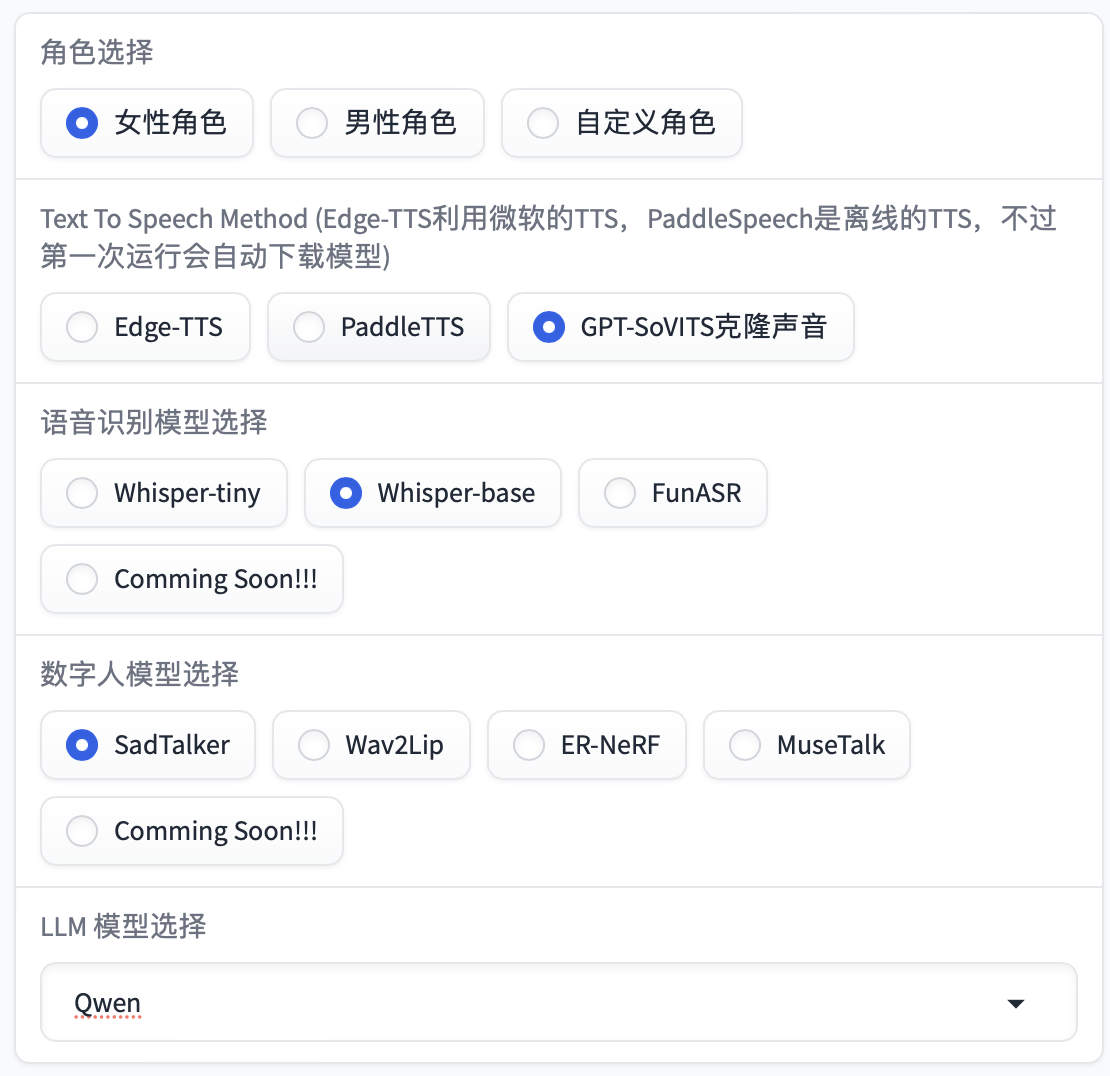

可以直接运行webui来得到结果,可以看到的页面如下
# WebUI
python webui.py

这次更新了一下界面,我们可以自由选择GPT-SoVITS微调后的模型来实现,上传参考音频即可很好的克隆声音

Old Verison
这一部分是为了保证每部份代码都是正确的,所以会先对每一个模块都进行测试和改进
启动一共有几种模式,可以选择特定的场景进行设置
第一种只有固定了人物问答,设置好了人物,省去了预处理时间
python app.py

最近更新了第一种模式,加入了Wav2Lip模型进行对话
python appv2.py
第二种是可以任意上传图片进行对话
python app_img.py

第三种是在第一种的基础上加入了大语言模型,加入了多轮的GPT对话
python app_multi.py

现在加入了语音克隆的部分,可以自由切换自己克隆的声音模型和对应的人图片进行实现,这里我选择了一个烟嗓音和男生图片
python app_vits.py
加入了第四种方式,不固定场景进行对话,直接输入语音或者生成语音进行数字人生成,内置了Sadtalker,Wav2Lip,ER-NeRF等方式
ER-NeRF是针对单独一个人的视频进行训练的,所以需要替换特定的模型才能进行渲染得到正确的结果,内置了Obama的权重,可直接用
python app_talk.py

加入了MuseTalk的方式,能够将MuseV的视频进行预处理,预处理后进行对话,速度基本能够达到实时的要求,速度非常快,MuseTalk已加入在WebUI中。
python app_musetalk.py

文件夹结构
所有的权重部分可以从这下载,百度网盘可能有时候会更新慢一点,建议从夸克网盘下载,会第一时间更新
- Baidu (百度云盘) (Password:
linl) - huggingface
- modelscope
- Quark(夸克网盘)
权重文件夹结构如下
Linly-Talker/
├── checkpoints
│ ├── audio_visual_encoder.pth
│ ├── hub
│ │ └── checkpoints
│ │ └── s3fd-619a316812.pth
│ ├── lipsync_expert.pth
│ ├── mapping_00109-model.pth.tar
│ ├── mapping_00229-model.pth.tar
│ ├── May.json
│ ├── May.pth
│ ├── Obama_ave.pth
│ ├── Obama.json
│ ├── Obama.pth
│ ├── ref_eo.npy
│ ├── ref.npy
│ ├── ref.wav
│ ├── SadTalker_V0.0.2_256.safetensors
│ ├── visual_quality_disc.pth
│ ├── wav2lip_gan.pth
│ └── wav2lip.pth
├── gfpgan
│ └── weights
│ ├── alignment_WFLW_4HG.pth
│ └── detection_Resnet50_Final.pth
├── GPT_SoVITS
│ └── pretrained_models
│ ├── chinese-hubert-base
│ │ ├── config.json
│ │ ├── preprocessor_config.json
│ │ └── pytorch_model.bin
│ ├── chinese-roberta-wwm-ext-large
│ │ ├── config.json
│ │ ├── pytorch_model.bin
│ │ └── tokenizer.json
│ ├── README.md
│ ├── s1bert25hz-2kh-longer-epoch=68e-step=50232.ckpt
│ ├── s2D488k.pth
│ ├── s2G488k.pth
│ └── speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch
├── MuseTalk
│ ├── models
│ │ ├── dwpose
│ │ │ └── dw-ll_ucoco_384.pth
│ │ ├── face-parse-bisent
│ │ │ ├── 79999_iter.pth
│ │ │ └── resnet18-5c106cde.pth
│ │ ├── musetalk
│ │ │ ├── musetalk.json
│ │ │ └── pytorch_model.bin
│ │ ├── README.md
│ │ ├── sd-vae-ft-mse
│ │ │ ├── config.json
│ │ │ └── diffusion_pytorch_model.bin
│ │ └── whisper
│ │ └── tiny.pt
├── Qwen
│ └── Qwen-1_8B-Chat
│ ├── assets
│ │ ├── logo.jpg
│ │ ├── qwen_tokenizer.png
│ │ ├── react_showcase_001.png
│ │ ├── react_showcase_002.png
│ │ └── wechat.png
│ ├── cache_autogptq_cuda_256.cpp
│ ├── cache_autogptq_cuda_kernel_256.cu
│ ├── config.json
│ ├── configuration_qwen.py
│ ├── cpp_kernels.py
│ ├── examples
│ │ └── react_prompt.md
│ ├── generation_config.json
│ ├── LICENSE
│ ├── model-00001-of-00002.safetensors
│ ├── model-00002-of-00002.safetensors
│ ├── modeling_qwen.py
│ ├── model.safetensors.index.json
│ ├── NOTICE
│ ├── qwen_generation_utils.py
│ ├── qwen.tiktoken
│ ├── README.md
│ ├── tokenization_qwen.py
│ └── tokenizer_config.json
├── Whisper
│ ├── base.pt
│ └── tiny.pt
├── FunASR
│ ├── punc_ct-transformer_zh-cn-common-vocab272727-pytorch
│ │ ├── configuration.json
│ │ ├── config.yaml
│ │ ├── example
│ │ │ └── punc_example.txt
│ │ ├── fig
│ │ │ └── struct.png
│ │ ├── model.pt
│ │ ├── README.md
│ │ └── tokens.json
│ ├── speech_fsmn_vad_zh-cn-16k-common-pytorch
│ │ ├── am.mvn
│ │ ├── configuration.json
│ │ ├── config.yaml
│ │ ├── example
│ │ │ └── vad_example.wav
│ │ ├── fig
│ │ │ └── struct.png
│ │ ├── model.pt
│ │ └── README.md
│ └── speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch
│ ├── am.mvn
│ ├── asr_example_hotword.wav
│ ├── configuration.json
│ ├── config.yaml
│ ├── example
│ │ ├── asr_example.wav
│ │ └── hotword.txt
│ ├── fig
│ │ ├── res.png
│ │ └── seaco.png
│ ├── model.pt
│ ├── README.md
│ ├── seg_dict
│ └── tokens.json
└── README.md
赞助
| 支付宝 | 微信 |
|---|---|
 |
 |
参考
ASR
TTS
LLM
- https://github.com/CVI-SZU/Linly
- https://github.com/QwenLM/Qwen
- https://deepmind.google/technologies/gemini/
- https://github.com/THUDM/ChatGLM3
- https://openai.com
THG
- https://github.com/OpenTalker/SadTalker
- https://github.com/Rudrabha/Wav2Lip
- https://github.com/Fictionarry/ER-NeRF
Voice Clone