Spaces:
Running

A newer version of the Gradio SDK is available:
5.6.0
在AutoDL平台部署Linly-Talker (0基础小白超详细教程)
快速上手直接使用镜像(以下安装操作全免)
若使用我设定好的镜像,可以直接运行即可,不需要安装环境,直接运行webui.py或者是app_talk.py即可体验,不需要安装任何环境,可直接跳到4.4即可
访问后在自定义设置里面打开端口,默认是6006端口,直接使用运行即可!
python webui.py
python app_talk.py
环境模型都安装好了,直接使用即可,镜像地址在:https://www.codewithgpu.com/i/Kedreamix/Linly-Talker/Kedreamix-Linly-Talker,感谢大家的支持
一、注册AutoDL
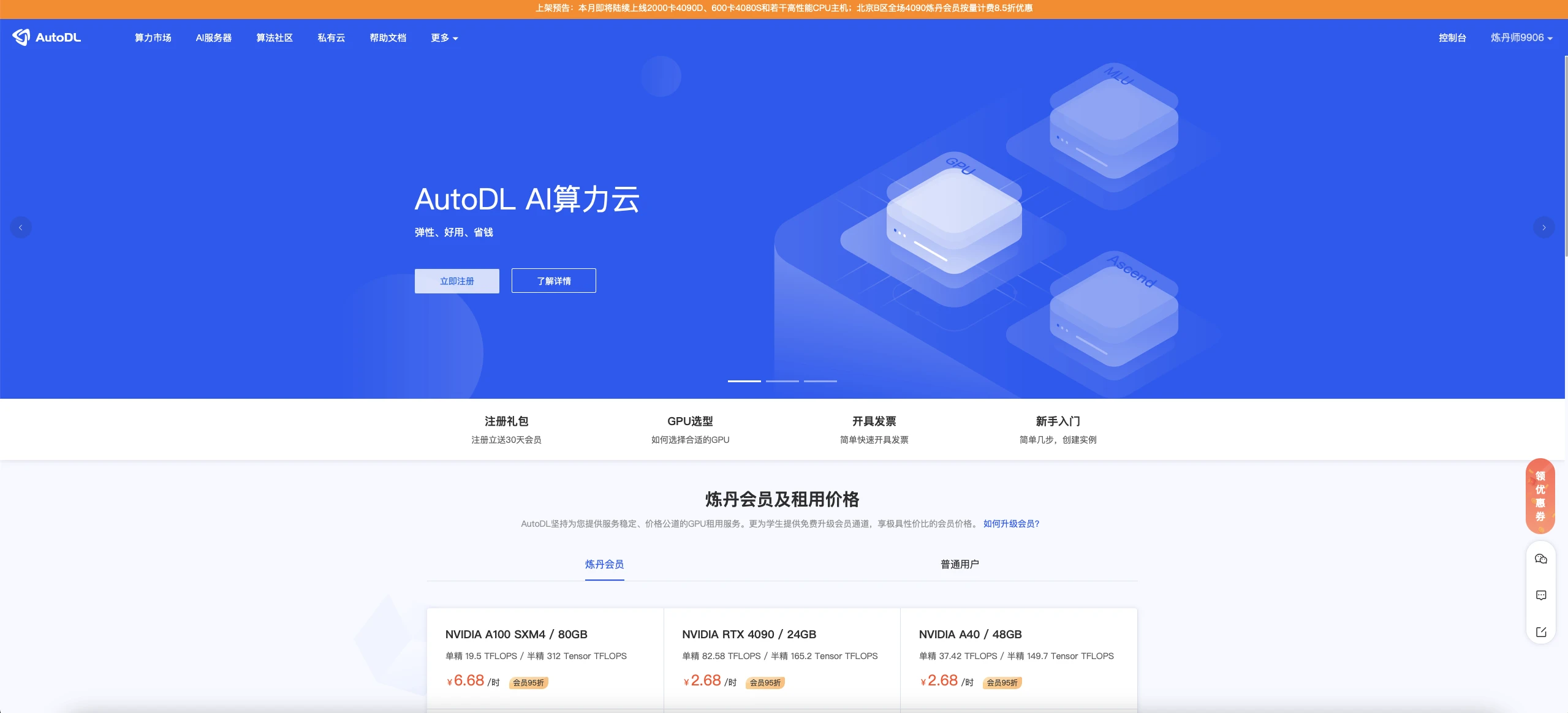
AutoDL官网 注册账户好并充值,自己选择机器,我觉得如果正常跑一下,5元已经够了
二、创建实例
2.1 登录AutoDL,进入算力市场,选择机器
这一部分实际上我觉得12g都OK的,无非是速度问题而已
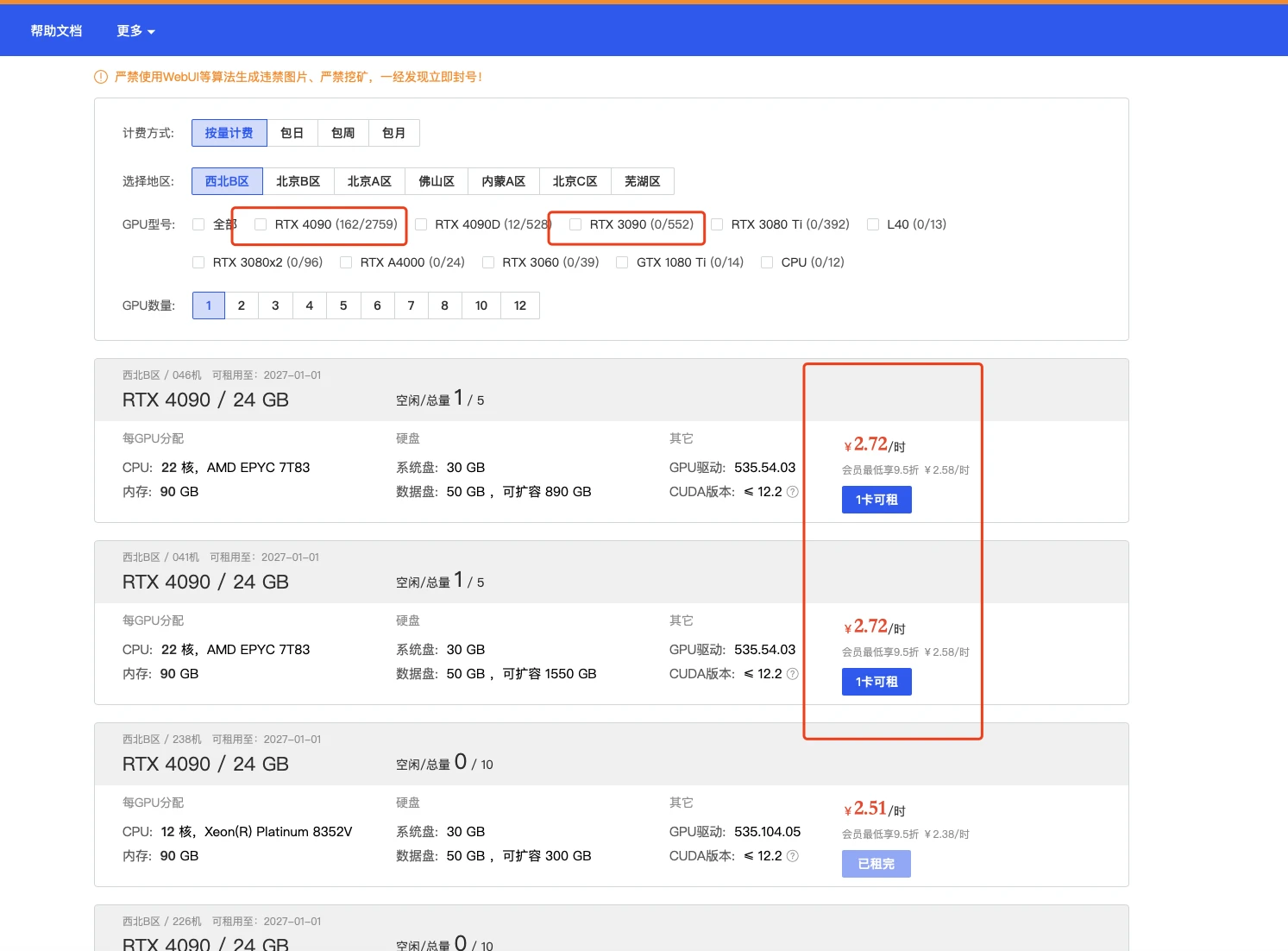
2.2 配置基础镜像
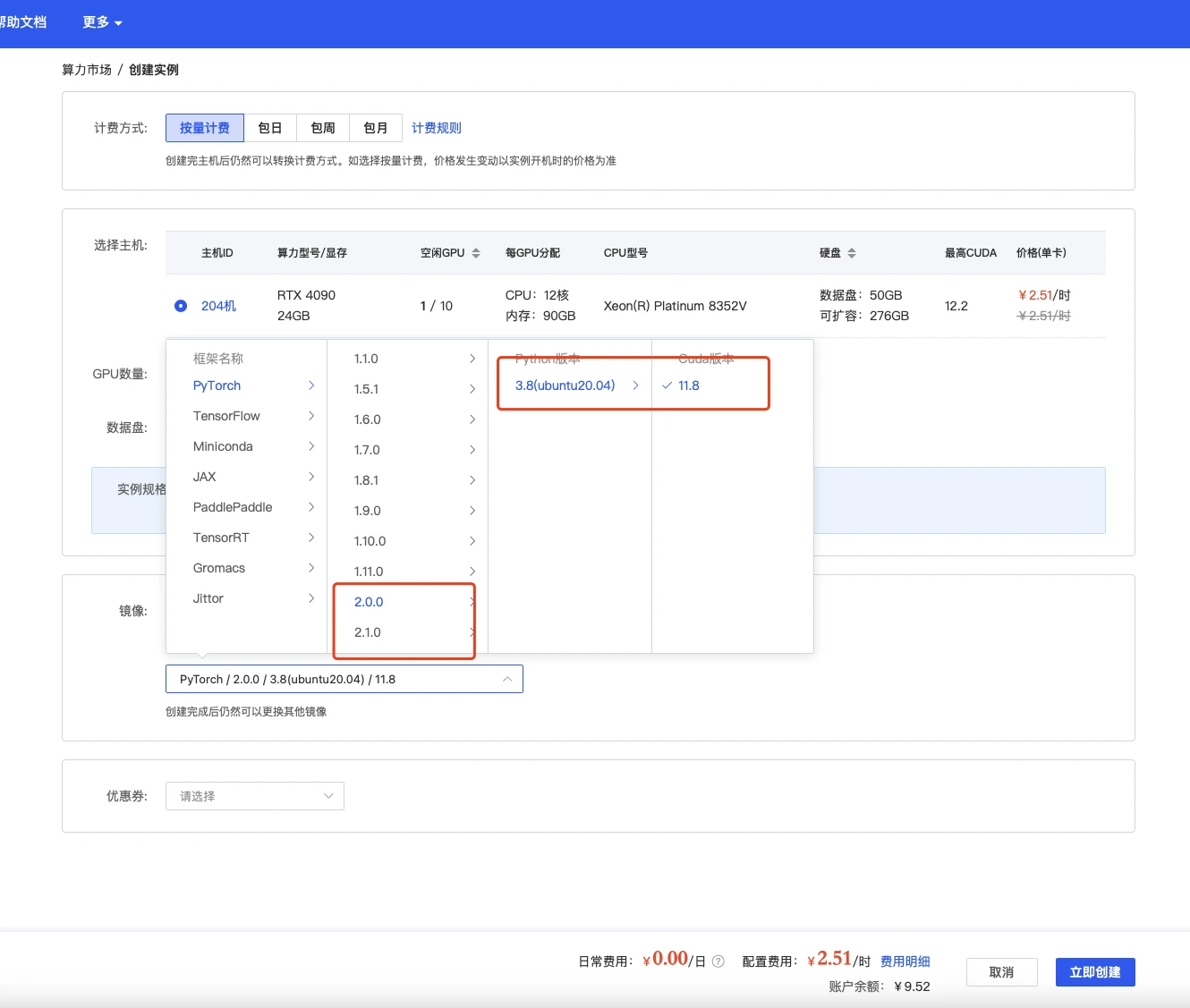
选择镜像,最好选择2.0以上可以体验克隆声音功能,其他无所谓
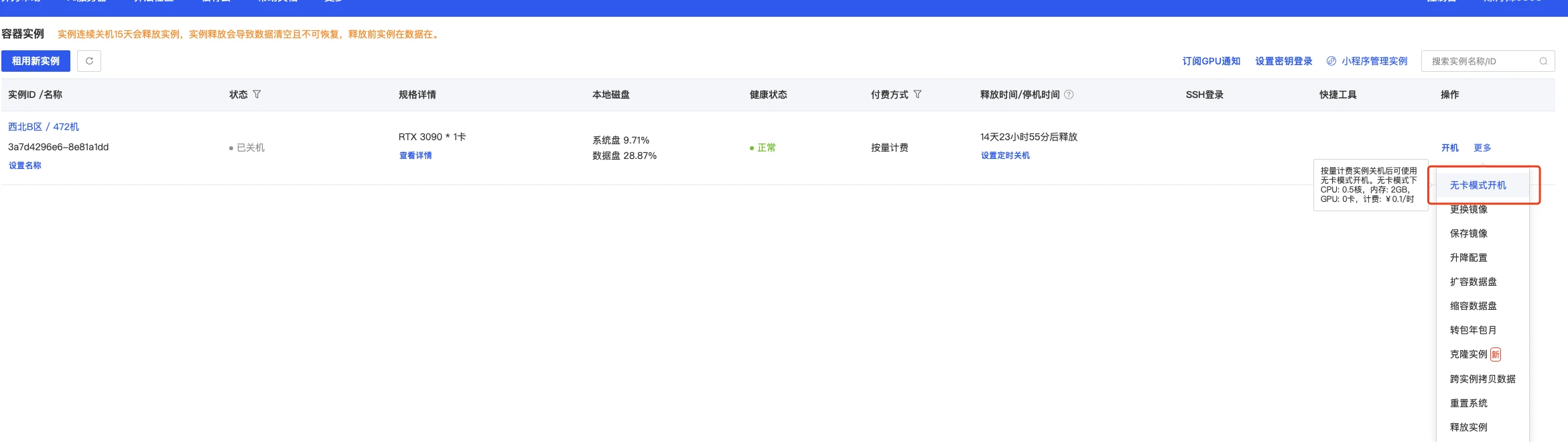
2.3 无卡模式开机
创建成功后为了省钱先关机,然后使用无卡模式开机。 无卡模式一个小时只需要0.1元,比较适合部署环境。
三、部署环境
3.1 进入终端
打开jupyterLab,进入数据盘(autodl-tmp),打开终端,将Linly-Talker模型下载到数据盘中。
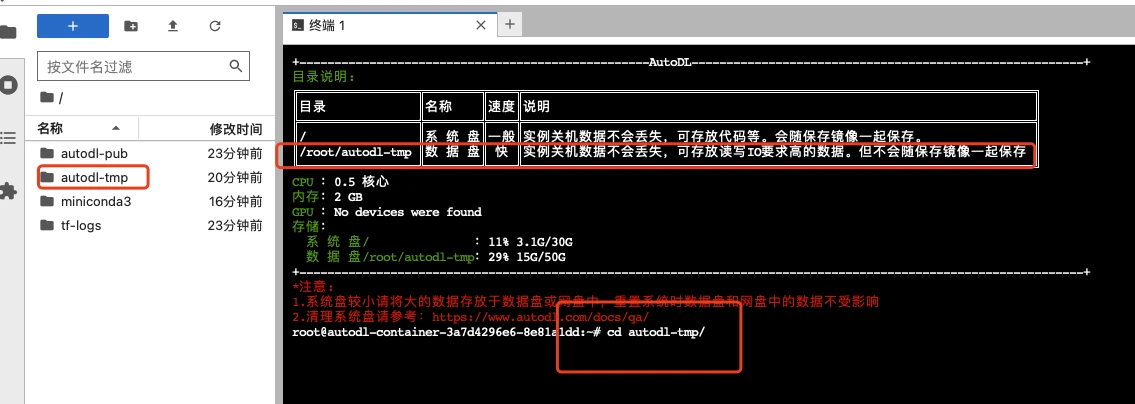
3.2 下载代码文件
根据Github上的说明,使用命令行下载模型文件和代码文件,利用学术加速会快一点
# 开启学术镜像,更快的clone代码 参考 https://www.autodl.com/docs/network_turbo/
source /etc/network_turbo
cd /root/autodl-tmp/
# 下载代码
git clone https://github.com/Kedreamix/Linly-Talker.git
# 取消学术加速
unset http_proxy && unset https_proxy
3.3 下载模型文件
安装git lfs
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
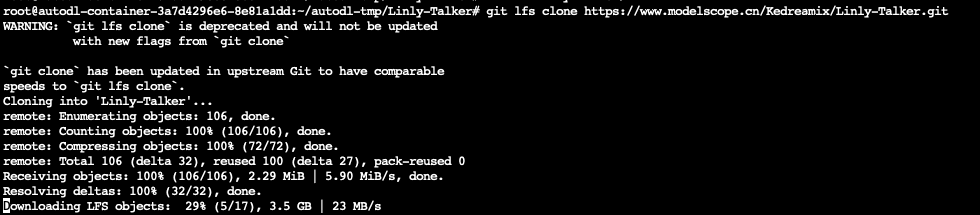
根据 https://www.modelscope.cn/Kedreamix/Linly-Talker 下载模型文件,走modelscope还是很快的,不过文件有点多,还是得等一下,记住是在Linly-Talker代码路径下执行这个文件
cd /root/autodl-tmp/Linly-Talker/
git lfs install
git lfs clone https://www.modelscope.cn/Kedreamix/Linly-Talker.git
等待一段时间下载完以后,利用命令将模型移动到指定目录,直接复制即可
# 移动所有模型到当前目录
# checkpoint中含有SadTalker和Wav2Lip
mv Linly-Talker/checkpoints/* ./checkpoints
# SadTalker的增强GFPGAN
# pip install gfpgan
# mv Linly-Talker/gfpan ./
# 语音克隆模型
mv Linly-Talker/GPT_SoVITS/pretrained_models/* ./GPT_SoVITS/pretrained_models/
# Qwen大模型
mv Linly-Talker/Qwen ./
四、Linly-Talker项目
4.1 环境安装
进入代码路径,进行安装环境,由于选了镜像是含有pytorch的,所以只需要进行安装其他依赖即可
cd /root/autodl-tmp/Linly-Talker
conda install -q ffmpeg # ffmpeg==4.2.2
# 安装Linly-Talker对应依赖
pip install -r requirements_app.txt
# 安装语音克隆对应的依赖
pip install -r VITS/requirements_gptsovits.txt
4.2 端口设置
由于似乎autodl开放的是6006端口,所以这里面的端口映射也可以改一下成6006,这里吗只需要修改configs.py文件里面的port为6006即可
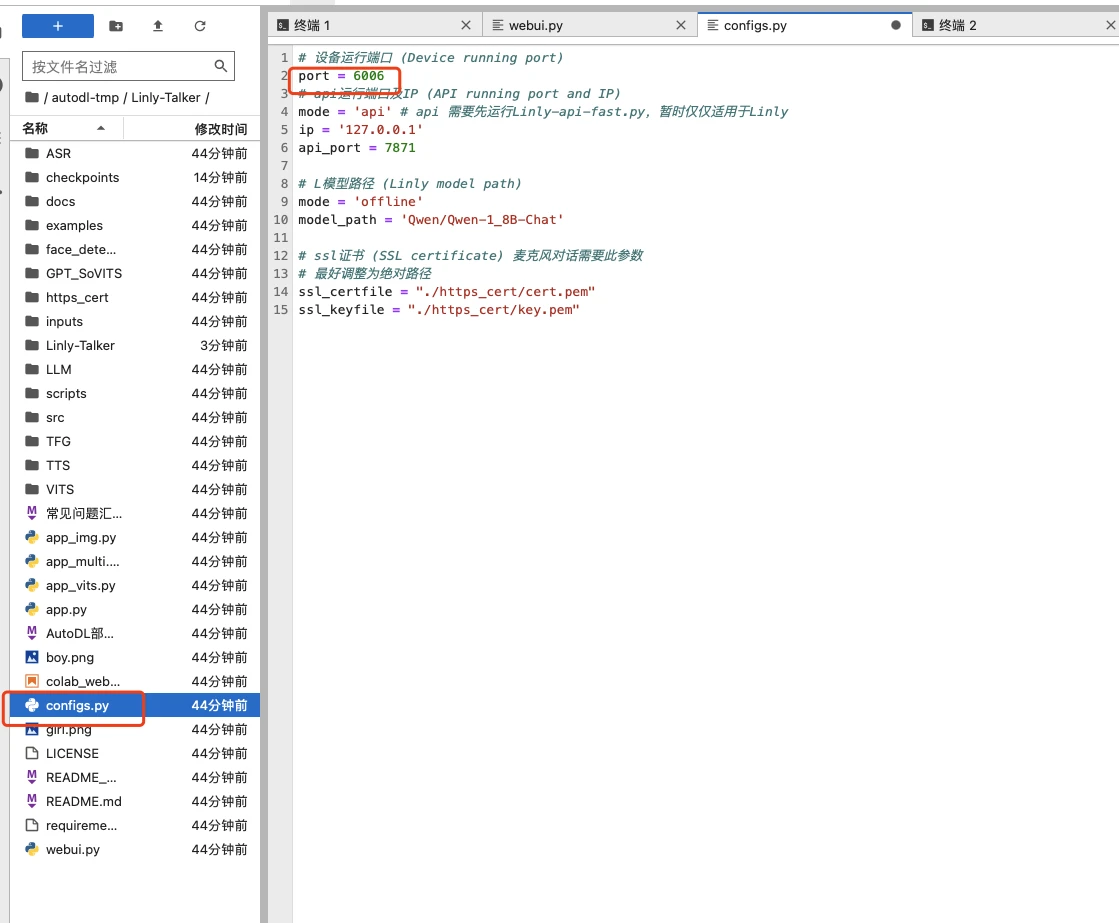
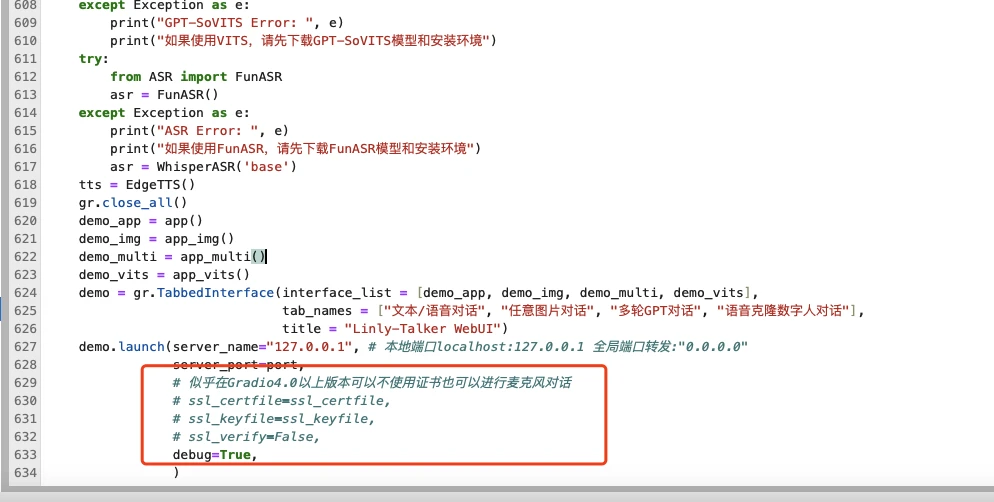
除此之外,我发现其实对于autodl来说,不是很支持https的端口映射,所以需要注释掉几行代码即可,在webui.py的最后几行注释掉代码ssl相关代码
demo.launch(server_name="127.0.0.1", # 本地端口localhost:127.0.0.1 全局端口转发:"0.0.0.0"
server_port=port,
# 似乎在Gradio4.0以上版本可以不使用证书也可以进行麦克风对话
# ssl_certfile=ssl_certfile,
# ssl_keyfile=ssl_keyfile,
# ssl_verify=False,
debug=True,
)
如果使用app.py同理
4.3 有卡开机
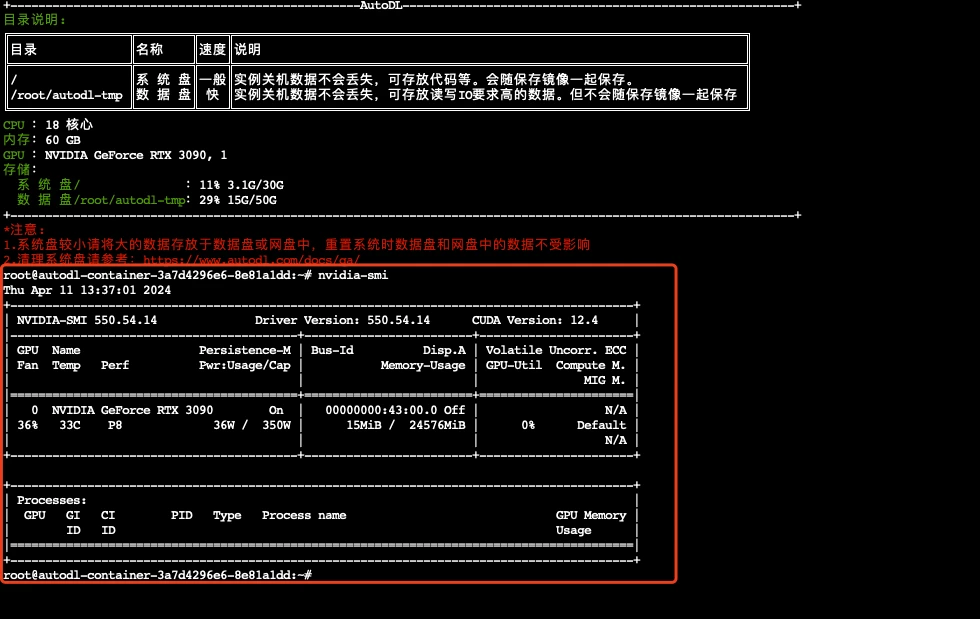
进入autodl容器实例界面,执行关机操作,然后进行有卡开机,开机后打开jupyterLab。
查看配置
nvidia-smi
4.4 运行网页版对话webui
需要有卡模式开机,执行下边命令,这里面就跟代码是一模一样的了
python webui.py

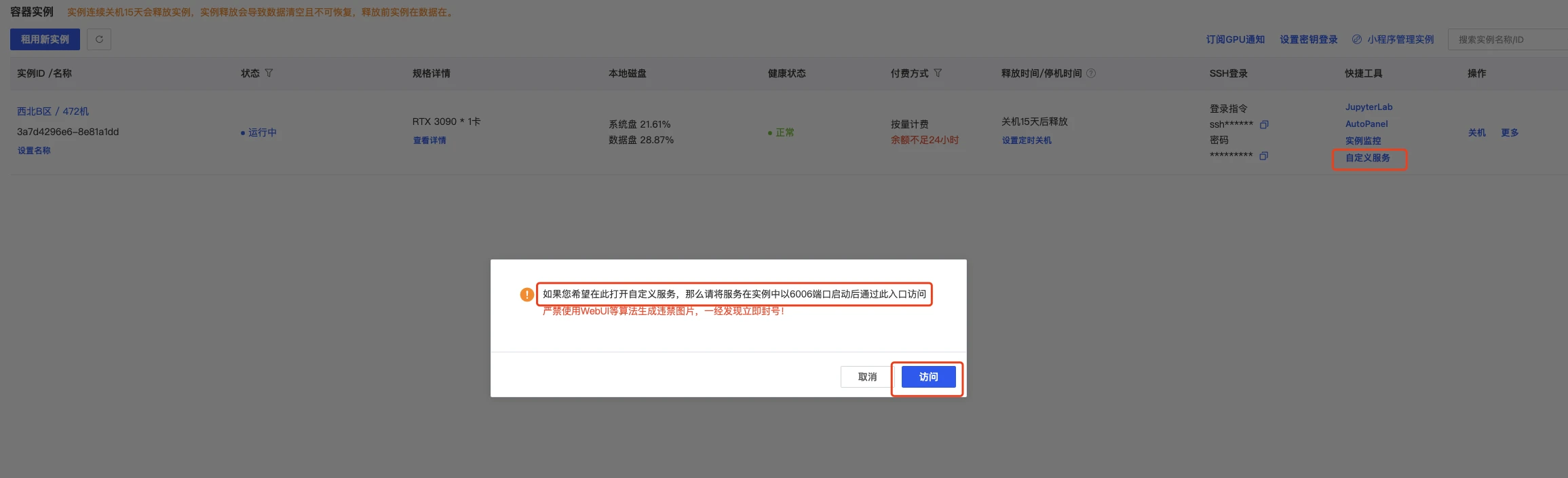
4.4 端口映射
这可以直接打开autodl的自定义服务,默认是6006端口,我们已经设置了,所以直接使用即可
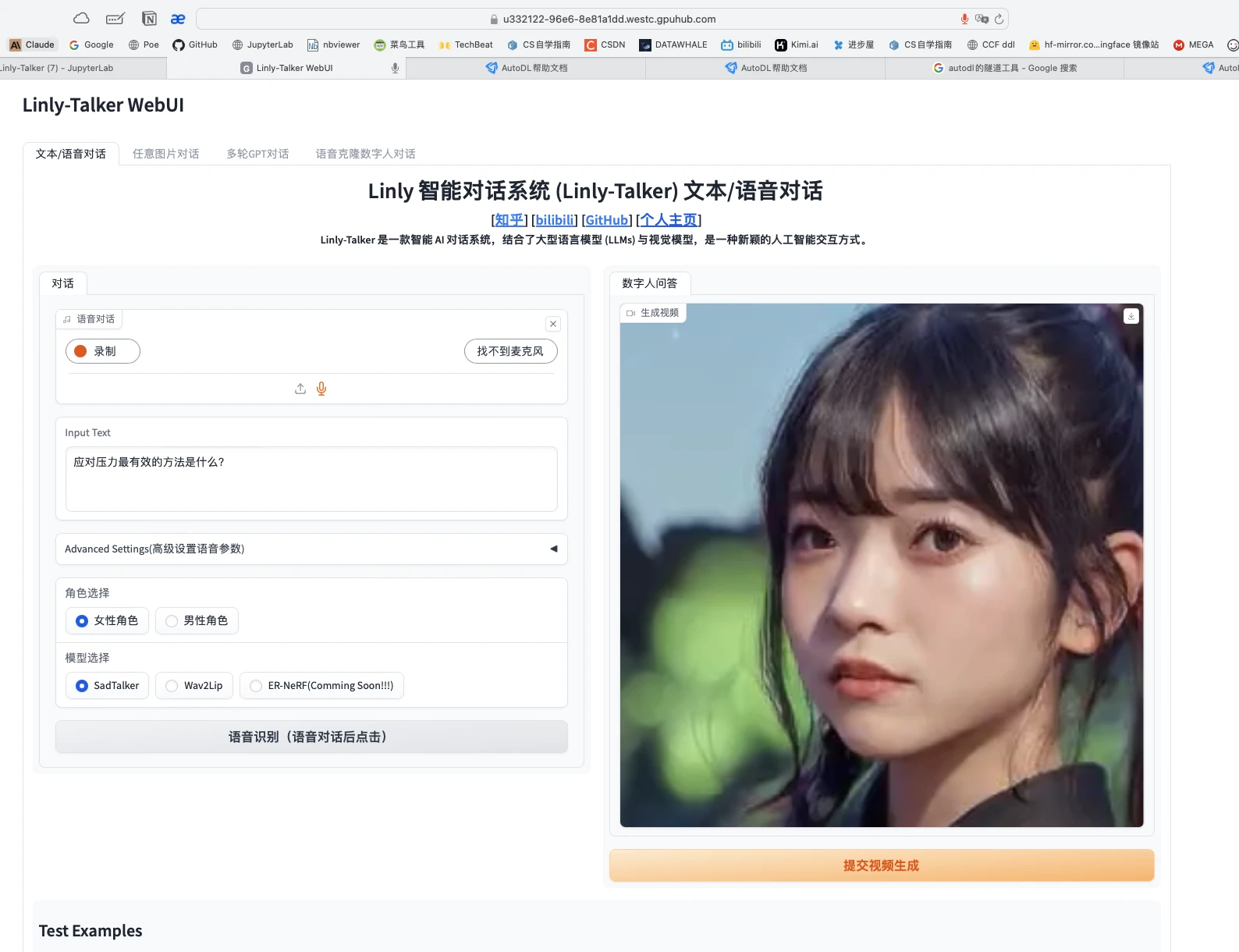
4.5 体验Linly-Talker(成功)
点开网页,即可正确执行Linly-Talker,这一部分就跟视频一模一样了
ssh端口映射工具:windows:https://autodl-public.ks3-cn-beijing.ksyuncs.com/tool/AutoDL-SSH-Tools.zip
!!!注意:不用了,一定要去控制台=》容器实例,把镜像实例关机,它是按时收费的,不关机会一直扣费的。
建议选北京区的,稍微便宜一些。可以晚上部署,网速快,便宜的GPU也充足。白天部署,北京区的GPU容易没有。