

Upload 47 files
Browse files- .gitattributes +4 -0
- DPT/.DS_Store +0 -0
- DPT/EVALUATION.md +60 -0
- DPT/LICENSE +21 -0
- DPT/README.md +97 -0
- DPT/dpt/__init__.py +0 -0
- DPT/dpt/base_model.py +16 -0
- DPT/dpt/blocks.py +383 -0
- DPT/dpt/midas_net.py +77 -0
- DPT/dpt/models.py +153 -0
- DPT/dpt/transforms.py +231 -0
- DPT/dpt/vit.py +576 -0
- DPT/input/.placeholder +0 -0
- DPT/output_monodepth/.placeholder +0 -0
- DPT/output_semseg/.placeholder +0 -0
- DPT/requirements.txt +4 -0
- DPT/run_monodepth.py +238 -0
- DPT/run_segmentation.py +163 -0
- DPT/setup.py +11 -0
- DPT/util/__init__.py +0 -0
- DPT/util/io.py +219 -0
- DPT/util/misc.py +63 -0
- DPT/util/pallete.py +50 -0
- DPT/weights/.placeholder +0 -0
- demo.ipynb +0 -0
- demo_assets/depths/pumpkin.png +3 -0
- demo_assets/input_imgs/pumpkin.png +3 -0
- demo_assets/material_exemplars/cup_glaze.png +3 -0
- demo_gradio.py +170 -0
- fig/gradio_demo.png +3 -0
- fig/method.jpg +0 -0
- ip_adapter/__init__.py +9 -0
- ip_adapter/attention_processor.py +568 -0
- ip_adapter/attention_processor_faceid.py +433 -0
- ip_adapter/custom_pipelines.py +394 -0
- ip_adapter/ip_adapter.py +417 -0
- ip_adapter/ip_adapter_faceid.py +542 -0
- ip_adapter/ip_adapter_faceid_separate.py +547 -0
- ip_adapter/resampler.py +158 -0
- ip_adapter/test_resampler.py +44 -0
- ip_adapter/utils.py +93 -0
- models/.DS_Store +0 -0
- models/image_encoder/config.json +23 -0
- requirements.txt +10 -0
- run_batch.py +93 -0
- sdxl_models/.DS_Store +0 -0
- sdxl_models/image_encoder/config.json +81 -0
- visualization.py +18 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,7 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
demo_assets/depths/pumpkin.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
demo_assets/input_imgs/pumpkin.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
demo_assets/material_exemplars/cup_glaze.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
fig/gradio_demo.png filter=lfs diff=lfs merge=lfs -text
|
DPT/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
DPT/EVALUATION.md
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### Genral-purpose models
|
| 2 |
+
The general-purpose models are affine-invariant and as such need a pre-alignment step before an error can be computed.
|
| 3 |
+
|
| 4 |
+
Sample code for NYUv2 can be found here:
|
| 5 |
+
https://gist.github.com/ranftlr/a1c7a24ebb24ce0e2f2ace5bce917022
|
| 6 |
+
|
| 7 |
+
Sample code for KITTI can be found here:
|
| 8 |
+
https://gist.github.com/ranftlr/45f4c7ddeb1bbb88d606bc600cab6c8d
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
### KITTI
|
| 12 |
+
* Remove images from `/input/` and `/output_monodepth/` folders
|
| 13 |
+
* Download `kitti_eval_dataset.zip` https://drive.google.com/file/d/1GbfMGuwg2VS06Vl75-_tB5FDj9EOrjl0/view?usp=sharing and unzip it in the `/input/` folder (or follow this repository https://github.com/cogaplex-bts/bts to get RGB and Depth images from list [eigen_test_files_with_gt.txt](https://github.com/cogaplex-bts/bts/blob/master/train_test_inputs/eigen_test_files_with_gt.txt) )
|
| 14 |
+
* Download [dpt_hybrid_kitti-cb926ef4.pt](https://github.com/intel-isl/DPT/releases/download/1_0/dpt_hybrid_kitti-cb926ef4.pt) model and place it in the `/weights/` folder
|
| 15 |
+
* Download [eval_with_pngs.py](https://raw.githubusercontent.com/cogaplex-bts/bts/5a55542ebbe849eb85b5ce9592365225b93d8b28/utils/eval_with_pngs.py) in the root folder
|
| 16 |
+
* `python run_monodepth.py --model_type dpt_hybrid_kitti --kitti_crop --absolute_depth`
|
| 17 |
+
* `python ./eval_with_pngs.py --pred_path ./output_monodepth/ --gt_path ./input/gt/ --dataset kitti --min_depth_eval 1e-3 --max_depth_eval 80 --garg_crop --do_kb_crop`
|
| 18 |
+
|
| 19 |
+
Result:
|
| 20 |
+
```
|
| 21 |
+
Evaluating 697 files
|
| 22 |
+
GT files reading done
|
| 23 |
+
45 GT files missing
|
| 24 |
+
Computing errors
|
| 25 |
+
d1, d2, d3, AbsRel, SqRel, RMSE, RMSElog, SILog, log10
|
| 26 |
+
0.959, 0.995, 0.999, 0.062, 0.222, 2.575, 0.092, 8.282, 0.027
|
| 27 |
+
Done.
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
----
|
| 31 |
+
|
| 32 |
+
### NYUv2
|
| 33 |
+
* Remove images from `/input/` and `/output_monodepth/` folders
|
| 34 |
+
* Download `nyu_eval_dataset.zip` https://drive.google.com/file/d/1b37uu-bqTZcSwokGkHIOEXuuBdfo80HI/view?usp=sharing and unzip it in the `/input/` folder (or follow this repository https://github.com/cogaplex-bts/bts to get RGB and Depth images from list [nyudepthv2_test_files_with_gt.txt](https://github.com/cogaplex-bts/bts/blob/master/train_test_inputs/nyudepthv2_test_files_with_gt.txt) )
|
| 35 |
+
* Download [dpt_hybrid_nyu-2ce69ec7.pt](https://github.com/intel-isl/DPT/releases/download/1_0/dpt_hybrid_nyu-2ce69ec7.pt) model (**or a new model** that is fine-tuned with slightly different hyperparameters [dpt_hybrid_nyu_new-217f207d.pt](https://drive.google.com/file/d/1Nxv2OiqhAMosBL2a3pflamTW39dMjaSp/view?usp=sharing) ) and place it in the `/weights/` folder
|
| 36 |
+
* Download [eval_with_pngs.py](https://raw.githubusercontent.com/cogaplex-bts/bts/5a55542ebbe849eb85b5ce9592365225b93d8b28/utils/eval_with_pngs.py) in the root folder
|
| 37 |
+
* `python run_monodepth.py --model_type dpt_hybrid_nyu --absolute_depth`
|
| 38 |
+
(or **for new model** `python run_monodepth.py --model_type dpt_hybrid_nyu --absolute_depth --model_weights weights/dpt_hybrid_nyu_new-217f207d.pt` )
|
| 39 |
+
* `python ./eval_with_pngs.py --pred_path ./output_monodepth/ --gt_path ./input/gt/ --dataset nyu --max_depth_eval 10 --eigen_crop`
|
| 40 |
+
|
| 41 |
+
Result (old model) - **from paper**:
|
| 42 |
+
```
|
| 43 |
+
Evaluating 654 files
|
| 44 |
+
GT files reading done
|
| 45 |
+
0 GT files missing
|
| 46 |
+
Computing errors
|
| 47 |
+
d1, d2, d3, AbsRel, SqRel, RMSE, RMSElog, SILog, log10
|
| 48 |
+
0.904, 0.988, 0.998, 0.109, 0.054, 0.357, 0.129, 9.521, 0.045
|
| 49 |
+
Done.
|
| 50 |
+
```
|
| 51 |
+
|
| 52 |
+
Result (new model):
|
| 53 |
+
```
|
| 54 |
+
GT files reading done
|
| 55 |
+
697 GT files missing
|
| 56 |
+
Computing errors
|
| 57 |
+
d1, d2, d3, AbsRel, SqRel, RMSE, RMSElog, SILog, log10
|
| 58 |
+
0.905, 0.988, 0.998, 0.109, 0.055, 0.357, 0.129, 9.427, 0.045
|
| 59 |
+
Done.
|
| 60 |
+
```
|
DPT/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2021 Intel ISL (Intel Intelligent Systems Lab)
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
DPT/README.md
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Vision Transformers for Dense Prediction
|
| 2 |
+
|
| 3 |
+
This repository contains code and models for our [paper](https://arxiv.org/abs/2103.13413):
|
| 4 |
+
|
| 5 |
+
> Vision Transformers for Dense Prediction
|
| 6 |
+
> René Ranftl, Alexey Bochkovskiy, Vladlen Koltun
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
### Changelog
|
| 10 |
+
* [March 2021] Initial release of inference code and models
|
| 11 |
+
|
| 12 |
+
### Setup
|
| 13 |
+
|
| 14 |
+
1) Download the model weights and place them in the `weights` folder:
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
Monodepth:
|
| 18 |
+
- [dpt_hybrid-midas-501f0c75.pt](https://github.com/intel-isl/DPT/releases/download/1_0/dpt_hybrid-midas-501f0c75.pt), [Mirror](https://drive.google.com/file/d/1dgcJEYYw1F8qirXhZxgNK8dWWz_8gZBD/view?usp=sharing)
|
| 19 |
+
- [dpt_large-midas-2f21e586.pt](https://github.com/intel-isl/DPT/releases/download/1_0/dpt_large-midas-2f21e586.pt), [Mirror](https://drive.google.com/file/d/1vnuhoMc6caF-buQQ4hK0CeiMk9SjwB-G/view?usp=sharing)
|
| 20 |
+
|
| 21 |
+
Segmentation:
|
| 22 |
+
- [dpt_hybrid-ade20k-53898607.pt](https://github.com/intel-isl/DPT/releases/download/1_0/dpt_hybrid-ade20k-53898607.pt), [Mirror](https://drive.google.com/file/d/1zKIAMbltJ3kpGLMh6wjsq65_k5XQ7_9m/view?usp=sharing)
|
| 23 |
+
- [dpt_large-ade20k-b12dca68.pt](https://github.com/intel-isl/DPT/releases/download/1_0/dpt_large-ade20k-b12dca68.pt), [Mirror](https://drive.google.com/file/d/1foDpUM7CdS8Zl6GPdkrJaAOjskb7hHe-/view?usp=sharing)
|
| 24 |
+
|
| 25 |
+
2) Set up dependencies:
|
| 26 |
+
|
| 27 |
+
```shell
|
| 28 |
+
pip install -r requirements.txt
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
The code was tested with Python 3.7, PyTorch 1.8.0, OpenCV 4.5.1, and timm 0.4.5
|
| 32 |
+
|
| 33 |
+
### Usage
|
| 34 |
+
|
| 35 |
+
1) Place one or more input images in the folder `input`.
|
| 36 |
+
|
| 37 |
+
2) Run a monocular depth estimation model:
|
| 38 |
+
|
| 39 |
+
```shell
|
| 40 |
+
python run_monodepth.py
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
Or run a semantic segmentation model:
|
| 44 |
+
|
| 45 |
+
```shell
|
| 46 |
+
python run_segmentation.py
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
3) The results are written to the folder `output_monodepth` and `output_semseg`, respectively.
|
| 50 |
+
|
| 51 |
+
Use the flag `-t` to switch between different models. Possible options are `dpt_hybrid` (default) and `dpt_large`.
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
**Additional models:**
|
| 55 |
+
|
| 56 |
+
- Monodepth finetuned on KITTI: [dpt_hybrid_kitti-cb926ef4.pt](https://github.com/intel-isl/DPT/releases/download/1_0/dpt_hybrid_kitti-cb926ef4.pt) [Mirror](https://drive.google.com/file/d/1-oJpORoJEdxj4LTV-Pc17iB-smp-khcX/view?usp=sharing)
|
| 57 |
+
- Monodepth finetuned on NYUv2: [dpt_hybrid_nyu-2ce69ec7.pt](https://github.com/intel-isl/DPT/releases/download/1_0/dpt_hybrid_nyu-2ce69ec7.pt) [Mirror](https\://drive.google.com/file/d/1NjiFw1Z9lUAfTPZu4uQ9gourVwvmd58O/view?usp=sharing)
|
| 58 |
+
|
| 59 |
+
Run with
|
| 60 |
+
|
| 61 |
+
```shell
|
| 62 |
+
python run_monodepth -t [dpt_hybrid_kitti|dpt_hybrid_nyu]
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
### Evaluation
|
| 66 |
+
|
| 67 |
+
Hints on how to evaluate monodepth models can be found here: https://github.com/intel-isl/DPT/blob/main/EVALUATION.md
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
### Citation
|
| 71 |
+
|
| 72 |
+
Please cite our papers if you use this code or any of the models.
|
| 73 |
+
```
|
| 74 |
+
@article{Ranftl2021,
|
| 75 |
+
author = {Ren\'{e} Ranftl and Alexey Bochkovskiy and Vladlen Koltun},
|
| 76 |
+
title = {Vision Transformers for Dense Prediction},
|
| 77 |
+
journal = {ArXiv preprint},
|
| 78 |
+
year = {2021},
|
| 79 |
+
}
|
| 80 |
+
```
|
| 81 |
+
|
| 82 |
+
```
|
| 83 |
+
@article{Ranftl2020,
|
| 84 |
+
author = {Ren\'{e} Ranftl and Katrin Lasinger and David Hafner and Konrad Schindler and Vladlen Koltun},
|
| 85 |
+
title = {Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer},
|
| 86 |
+
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
|
| 87 |
+
year = {2020},
|
| 88 |
+
}
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
### Acknowledgements
|
| 92 |
+
|
| 93 |
+
Our work builds on and uses code from [timm](https://github.com/rwightman/pytorch-image-models) and [PyTorch-Encoding](https://github.com/zhanghang1989/PyTorch-Encoding). We'd like to thank the authors for making these libraries available.
|
| 94 |
+
|
| 95 |
+
### License
|
| 96 |
+
|
| 97 |
+
MIT License
|
DPT/dpt/__init__.py
ADDED
|
File without changes
|
DPT/dpt/base_model.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class BaseModel(torch.nn.Module):
|
| 5 |
+
def load(self, path):
|
| 6 |
+
"""Load model from file.
|
| 7 |
+
|
| 8 |
+
Args:
|
| 9 |
+
path (str): file path
|
| 10 |
+
"""
|
| 11 |
+
parameters = torch.load(path, map_location=torch.device("cpu"))
|
| 12 |
+
|
| 13 |
+
if "optimizer" in parameters:
|
| 14 |
+
parameters = parameters["model"]
|
| 15 |
+
|
| 16 |
+
self.load_state_dict(parameters)
|
DPT/dpt/blocks.py
ADDED
|
@@ -0,0 +1,383 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
|
| 4 |
+
from .vit import (
|
| 5 |
+
_make_pretrained_vitb_rn50_384,
|
| 6 |
+
_make_pretrained_vitl16_384,
|
| 7 |
+
_make_pretrained_vitb16_384,
|
| 8 |
+
forward_vit,
|
| 9 |
+
)
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def _make_encoder(
|
| 13 |
+
backbone,
|
| 14 |
+
features,
|
| 15 |
+
use_pretrained,
|
| 16 |
+
groups=1,
|
| 17 |
+
expand=False,
|
| 18 |
+
exportable=True,
|
| 19 |
+
hooks=None,
|
| 20 |
+
use_vit_only=False,
|
| 21 |
+
use_readout="ignore",
|
| 22 |
+
enable_attention_hooks=False,
|
| 23 |
+
):
|
| 24 |
+
if backbone == "vitl16_384":
|
| 25 |
+
pretrained = _make_pretrained_vitl16_384(
|
| 26 |
+
use_pretrained,
|
| 27 |
+
hooks=hooks,
|
| 28 |
+
use_readout=use_readout,
|
| 29 |
+
enable_attention_hooks=enable_attention_hooks,
|
| 30 |
+
)
|
| 31 |
+
scratch = _make_scratch(
|
| 32 |
+
[256, 512, 1024, 1024], features, groups=groups, expand=expand
|
| 33 |
+
) # ViT-L/16 - 85.0% Top1 (backbone)
|
| 34 |
+
elif backbone == "vitb_rn50_384":
|
| 35 |
+
pretrained = _make_pretrained_vitb_rn50_384(
|
| 36 |
+
use_pretrained,
|
| 37 |
+
hooks=hooks,
|
| 38 |
+
use_vit_only=use_vit_only,
|
| 39 |
+
use_readout=use_readout,
|
| 40 |
+
enable_attention_hooks=enable_attention_hooks,
|
| 41 |
+
)
|
| 42 |
+
scratch = _make_scratch(
|
| 43 |
+
[256, 512, 768, 768], features, groups=groups, expand=expand
|
| 44 |
+
) # ViT-H/16 - 85.0% Top1 (backbone)
|
| 45 |
+
elif backbone == "vitb16_384":
|
| 46 |
+
pretrained = _make_pretrained_vitb16_384(
|
| 47 |
+
use_pretrained,
|
| 48 |
+
hooks=hooks,
|
| 49 |
+
use_readout=use_readout,
|
| 50 |
+
enable_attention_hooks=enable_attention_hooks,
|
| 51 |
+
)
|
| 52 |
+
scratch = _make_scratch(
|
| 53 |
+
[96, 192, 384, 768], features, groups=groups, expand=expand
|
| 54 |
+
) # ViT-B/16 - 84.6% Top1 (backbone)
|
| 55 |
+
elif backbone == "resnext101_wsl":
|
| 56 |
+
pretrained = _make_pretrained_resnext101_wsl(use_pretrained)
|
| 57 |
+
scratch = _make_scratch(
|
| 58 |
+
[256, 512, 1024, 2048], features, groups=groups, expand=expand
|
| 59 |
+
) # efficientnet_lite3
|
| 60 |
+
else:
|
| 61 |
+
print(f"Backbone '{backbone}' not implemented")
|
| 62 |
+
assert False
|
| 63 |
+
|
| 64 |
+
return pretrained, scratch
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def _make_scratch(in_shape, out_shape, groups=1, expand=False):
|
| 68 |
+
scratch = nn.Module()
|
| 69 |
+
|
| 70 |
+
out_shape1 = out_shape
|
| 71 |
+
out_shape2 = out_shape
|
| 72 |
+
out_shape3 = out_shape
|
| 73 |
+
out_shape4 = out_shape
|
| 74 |
+
if expand == True:
|
| 75 |
+
out_shape1 = out_shape
|
| 76 |
+
out_shape2 = out_shape * 2
|
| 77 |
+
out_shape3 = out_shape * 4
|
| 78 |
+
out_shape4 = out_shape * 8
|
| 79 |
+
|
| 80 |
+
scratch.layer1_rn = nn.Conv2d(
|
| 81 |
+
in_shape[0],
|
| 82 |
+
out_shape1,
|
| 83 |
+
kernel_size=3,
|
| 84 |
+
stride=1,
|
| 85 |
+
padding=1,
|
| 86 |
+
bias=False,
|
| 87 |
+
groups=groups,
|
| 88 |
+
)
|
| 89 |
+
scratch.layer2_rn = nn.Conv2d(
|
| 90 |
+
in_shape[1],
|
| 91 |
+
out_shape2,
|
| 92 |
+
kernel_size=3,
|
| 93 |
+
stride=1,
|
| 94 |
+
padding=1,
|
| 95 |
+
bias=False,
|
| 96 |
+
groups=groups,
|
| 97 |
+
)
|
| 98 |
+
scratch.layer3_rn = nn.Conv2d(
|
| 99 |
+
in_shape[2],
|
| 100 |
+
out_shape3,
|
| 101 |
+
kernel_size=3,
|
| 102 |
+
stride=1,
|
| 103 |
+
padding=1,
|
| 104 |
+
bias=False,
|
| 105 |
+
groups=groups,
|
| 106 |
+
)
|
| 107 |
+
scratch.layer4_rn = nn.Conv2d(
|
| 108 |
+
in_shape[3],
|
| 109 |
+
out_shape4,
|
| 110 |
+
kernel_size=3,
|
| 111 |
+
stride=1,
|
| 112 |
+
padding=1,
|
| 113 |
+
bias=False,
|
| 114 |
+
groups=groups,
|
| 115 |
+
)
|
| 116 |
+
|
| 117 |
+
return scratch
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
def _make_resnet_backbone(resnet):
|
| 121 |
+
pretrained = nn.Module()
|
| 122 |
+
pretrained.layer1 = nn.Sequential(
|
| 123 |
+
resnet.conv1, resnet.bn1, resnet.relu, resnet.maxpool, resnet.layer1
|
| 124 |
+
)
|
| 125 |
+
|
| 126 |
+
pretrained.layer2 = resnet.layer2
|
| 127 |
+
pretrained.layer3 = resnet.layer3
|
| 128 |
+
pretrained.layer4 = resnet.layer4
|
| 129 |
+
|
| 130 |
+
return pretrained
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
def _make_pretrained_resnext101_wsl(use_pretrained):
|
| 134 |
+
resnet = torch.hub.load("facebookresearch/WSL-Images", "resnext101_32x8d_wsl")
|
| 135 |
+
return _make_resnet_backbone(resnet)
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
class Interpolate(nn.Module):
|
| 139 |
+
"""Interpolation module."""
|
| 140 |
+
|
| 141 |
+
def __init__(self, scale_factor, mode, align_corners=False):
|
| 142 |
+
"""Init.
|
| 143 |
+
|
| 144 |
+
Args:
|
| 145 |
+
scale_factor (float): scaling
|
| 146 |
+
mode (str): interpolation mode
|
| 147 |
+
"""
|
| 148 |
+
super(Interpolate, self).__init__()
|
| 149 |
+
|
| 150 |
+
self.interp = nn.functional.interpolate
|
| 151 |
+
self.scale_factor = scale_factor
|
| 152 |
+
self.mode = mode
|
| 153 |
+
self.align_corners = align_corners
|
| 154 |
+
|
| 155 |
+
def forward(self, x):
|
| 156 |
+
"""Forward pass.
|
| 157 |
+
|
| 158 |
+
Args:
|
| 159 |
+
x (tensor): input
|
| 160 |
+
|
| 161 |
+
Returns:
|
| 162 |
+
tensor: interpolated data
|
| 163 |
+
"""
|
| 164 |
+
|
| 165 |
+
x = self.interp(
|
| 166 |
+
x,
|
| 167 |
+
scale_factor=self.scale_factor,
|
| 168 |
+
mode=self.mode,
|
| 169 |
+
align_corners=self.align_corners,
|
| 170 |
+
)
|
| 171 |
+
|
| 172 |
+
return x
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
class ResidualConvUnit(nn.Module):
|
| 176 |
+
"""Residual convolution module."""
|
| 177 |
+
|
| 178 |
+
def __init__(self, features):
|
| 179 |
+
"""Init.
|
| 180 |
+
|
| 181 |
+
Args:
|
| 182 |
+
features (int): number of features
|
| 183 |
+
"""
|
| 184 |
+
super().__init__()
|
| 185 |
+
|
| 186 |
+
self.conv1 = nn.Conv2d(
|
| 187 |
+
features, features, kernel_size=3, stride=1, padding=1, bias=True
|
| 188 |
+
)
|
| 189 |
+
|
| 190 |
+
self.conv2 = nn.Conv2d(
|
| 191 |
+
features, features, kernel_size=3, stride=1, padding=1, bias=True
|
| 192 |
+
)
|
| 193 |
+
|
| 194 |
+
self.relu = nn.ReLU(inplace=True)
|
| 195 |
+
|
| 196 |
+
def forward(self, x):
|
| 197 |
+
"""Forward pass.
|
| 198 |
+
|
| 199 |
+
Args:
|
| 200 |
+
x (tensor): input
|
| 201 |
+
|
| 202 |
+
Returns:
|
| 203 |
+
tensor: output
|
| 204 |
+
"""
|
| 205 |
+
out = self.relu(x)
|
| 206 |
+
out = self.conv1(out)
|
| 207 |
+
out = self.relu(out)
|
| 208 |
+
out = self.conv2(out)
|
| 209 |
+
|
| 210 |
+
return out + x
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
class FeatureFusionBlock(nn.Module):
|
| 214 |
+
"""Feature fusion block."""
|
| 215 |
+
|
| 216 |
+
def __init__(self, features):
|
| 217 |
+
"""Init.
|
| 218 |
+
|
| 219 |
+
Args:
|
| 220 |
+
features (int): number of features
|
| 221 |
+
"""
|
| 222 |
+
super(FeatureFusionBlock, self).__init__()
|
| 223 |
+
|
| 224 |
+
self.resConfUnit1 = ResidualConvUnit(features)
|
| 225 |
+
self.resConfUnit2 = ResidualConvUnit(features)
|
| 226 |
+
|
| 227 |
+
def forward(self, *xs):
|
| 228 |
+
"""Forward pass.
|
| 229 |
+
|
| 230 |
+
Returns:
|
| 231 |
+
tensor: output
|
| 232 |
+
"""
|
| 233 |
+
output = xs[0]
|
| 234 |
+
|
| 235 |
+
if len(xs) == 2:
|
| 236 |
+
output += self.resConfUnit1(xs[1])
|
| 237 |
+
|
| 238 |
+
output = self.resConfUnit2(output)
|
| 239 |
+
|
| 240 |
+
output = nn.functional.interpolate(
|
| 241 |
+
output, scale_factor=2, mode="bilinear", align_corners=True
|
| 242 |
+
)
|
| 243 |
+
|
| 244 |
+
return output
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
class ResidualConvUnit_custom(nn.Module):
|
| 248 |
+
"""Residual convolution module."""
|
| 249 |
+
|
| 250 |
+
def __init__(self, features, activation, bn):
|
| 251 |
+
"""Init.
|
| 252 |
+
|
| 253 |
+
Args:
|
| 254 |
+
features (int): number of features
|
| 255 |
+
"""
|
| 256 |
+
super().__init__()
|
| 257 |
+
|
| 258 |
+
self.bn = bn
|
| 259 |
+
|
| 260 |
+
self.groups = 1
|
| 261 |
+
|
| 262 |
+
self.conv1 = nn.Conv2d(
|
| 263 |
+
features,
|
| 264 |
+
features,
|
| 265 |
+
kernel_size=3,
|
| 266 |
+
stride=1,
|
| 267 |
+
padding=1,
|
| 268 |
+
bias=not self.bn,
|
| 269 |
+
groups=self.groups,
|
| 270 |
+
)
|
| 271 |
+
|
| 272 |
+
self.conv2 = nn.Conv2d(
|
| 273 |
+
features,
|
| 274 |
+
features,
|
| 275 |
+
kernel_size=3,
|
| 276 |
+
stride=1,
|
| 277 |
+
padding=1,
|
| 278 |
+
bias=not self.bn,
|
| 279 |
+
groups=self.groups,
|
| 280 |
+
)
|
| 281 |
+
|
| 282 |
+
if self.bn == True:
|
| 283 |
+
self.bn1 = nn.BatchNorm2d(features)
|
| 284 |
+
self.bn2 = nn.BatchNorm2d(features)
|
| 285 |
+
|
| 286 |
+
self.activation = activation
|
| 287 |
+
|
| 288 |
+
self.skip_add = nn.quantized.FloatFunctional()
|
| 289 |
+
|
| 290 |
+
def forward(self, x):
|
| 291 |
+
"""Forward pass.
|
| 292 |
+
|
| 293 |
+
Args:
|
| 294 |
+
x (tensor): input
|
| 295 |
+
|
| 296 |
+
Returns:
|
| 297 |
+
tensor: output
|
| 298 |
+
"""
|
| 299 |
+
|
| 300 |
+
out = self.activation(x)
|
| 301 |
+
out = self.conv1(out)
|
| 302 |
+
if self.bn == True:
|
| 303 |
+
out = self.bn1(out)
|
| 304 |
+
|
| 305 |
+
out = self.activation(out)
|
| 306 |
+
out = self.conv2(out)
|
| 307 |
+
if self.bn == True:
|
| 308 |
+
out = self.bn2(out)
|
| 309 |
+
|
| 310 |
+
if self.groups > 1:
|
| 311 |
+
out = self.conv_merge(out)
|
| 312 |
+
|
| 313 |
+
return self.skip_add.add(out, x)
|
| 314 |
+
|
| 315 |
+
# return out + x
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
class FeatureFusionBlock_custom(nn.Module):
|
| 319 |
+
"""Feature fusion block."""
|
| 320 |
+
|
| 321 |
+
def __init__(
|
| 322 |
+
self,
|
| 323 |
+
features,
|
| 324 |
+
activation,
|
| 325 |
+
deconv=False,
|
| 326 |
+
bn=False,
|
| 327 |
+
expand=False,
|
| 328 |
+
align_corners=True,
|
| 329 |
+
):
|
| 330 |
+
"""Init.
|
| 331 |
+
|
| 332 |
+
Args:
|
| 333 |
+
features (int): number of features
|
| 334 |
+
"""
|
| 335 |
+
super(FeatureFusionBlock_custom, self).__init__()
|
| 336 |
+
|
| 337 |
+
self.deconv = deconv
|
| 338 |
+
self.align_corners = align_corners
|
| 339 |
+
|
| 340 |
+
self.groups = 1
|
| 341 |
+
|
| 342 |
+
self.expand = expand
|
| 343 |
+
out_features = features
|
| 344 |
+
if self.expand == True:
|
| 345 |
+
out_features = features // 2
|
| 346 |
+
|
| 347 |
+
self.out_conv = nn.Conv2d(
|
| 348 |
+
features,
|
| 349 |
+
out_features,
|
| 350 |
+
kernel_size=1,
|
| 351 |
+
stride=1,
|
| 352 |
+
padding=0,
|
| 353 |
+
bias=True,
|
| 354 |
+
groups=1,
|
| 355 |
+
)
|
| 356 |
+
|
| 357 |
+
self.resConfUnit1 = ResidualConvUnit_custom(features, activation, bn)
|
| 358 |
+
self.resConfUnit2 = ResidualConvUnit_custom(features, activation, bn)
|
| 359 |
+
|
| 360 |
+
self.skip_add = nn.quantized.FloatFunctional()
|
| 361 |
+
|
| 362 |
+
def forward(self, *xs):
|
| 363 |
+
"""Forward pass.
|
| 364 |
+
|
| 365 |
+
Returns:
|
| 366 |
+
tensor: output
|
| 367 |
+
"""
|
| 368 |
+
output = xs[0]
|
| 369 |
+
|
| 370 |
+
if len(xs) == 2:
|
| 371 |
+
res = self.resConfUnit1(xs[1])
|
| 372 |
+
output = self.skip_add.add(output, res)
|
| 373 |
+
# output += res
|
| 374 |
+
|
| 375 |
+
output = self.resConfUnit2(output)
|
| 376 |
+
|
| 377 |
+
output = nn.functional.interpolate(
|
| 378 |
+
output, scale_factor=2, mode="bilinear", align_corners=self.align_corners
|
| 379 |
+
)
|
| 380 |
+
|
| 381 |
+
output = self.out_conv(output)
|
| 382 |
+
|
| 383 |
+
return output
|
DPT/dpt/midas_net.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""MidashNet: Network for monocular depth estimation trained by mixing several datasets.
|
| 2 |
+
This file contains code that is adapted from
|
| 3 |
+
https://github.com/thomasjpfan/pytorch_refinenet/blob/master/pytorch_refinenet/refinenet/refinenet_4cascade.py
|
| 4 |
+
"""
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
|
| 8 |
+
from .base_model import BaseModel
|
| 9 |
+
from .blocks import FeatureFusionBlock, Interpolate, _make_encoder
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class MidasNet_large(BaseModel):
|
| 13 |
+
"""Network for monocular depth estimation."""
|
| 14 |
+
|
| 15 |
+
def __init__(self, path=None, features=256, non_negative=True):
|
| 16 |
+
"""Init.
|
| 17 |
+
|
| 18 |
+
Args:
|
| 19 |
+
path (str, optional): Path to saved model. Defaults to None.
|
| 20 |
+
features (int, optional): Number of features. Defaults to 256.
|
| 21 |
+
backbone (str, optional): Backbone network for encoder. Defaults to resnet50
|
| 22 |
+
"""
|
| 23 |
+
print("Loading weights: ", path)
|
| 24 |
+
|
| 25 |
+
super(MidasNet_large, self).__init__()
|
| 26 |
+
|
| 27 |
+
use_pretrained = False if path is None else True
|
| 28 |
+
|
| 29 |
+
self.pretrained, self.scratch = _make_encoder(
|
| 30 |
+
backbone="resnext101_wsl", features=features, use_pretrained=use_pretrained
|
| 31 |
+
)
|
| 32 |
+
|
| 33 |
+
self.scratch.refinenet4 = FeatureFusionBlock(features)
|
| 34 |
+
self.scratch.refinenet3 = FeatureFusionBlock(features)
|
| 35 |
+
self.scratch.refinenet2 = FeatureFusionBlock(features)
|
| 36 |
+
self.scratch.refinenet1 = FeatureFusionBlock(features)
|
| 37 |
+
|
| 38 |
+
self.scratch.output_conv = nn.Sequential(
|
| 39 |
+
nn.Conv2d(features, 128, kernel_size=3, stride=1, padding=1),
|
| 40 |
+
Interpolate(scale_factor=2, mode="bilinear"),
|
| 41 |
+
nn.Conv2d(128, 32, kernel_size=3, stride=1, padding=1),
|
| 42 |
+
nn.ReLU(True),
|
| 43 |
+
nn.Conv2d(32, 1, kernel_size=1, stride=1, padding=0),
|
| 44 |
+
nn.ReLU(True) if non_negative else nn.Identity(),
|
| 45 |
+
)
|
| 46 |
+
|
| 47 |
+
if path:
|
| 48 |
+
self.load(path)
|
| 49 |
+
|
| 50 |
+
def forward(self, x):
|
| 51 |
+
"""Forward pass.
|
| 52 |
+
|
| 53 |
+
Args:
|
| 54 |
+
x (tensor): input data (image)
|
| 55 |
+
|
| 56 |
+
Returns:
|
| 57 |
+
tensor: depth
|
| 58 |
+
"""
|
| 59 |
+
|
| 60 |
+
layer_1 = self.pretrained.layer1(x)
|
| 61 |
+
layer_2 = self.pretrained.layer2(layer_1)
|
| 62 |
+
layer_3 = self.pretrained.layer3(layer_2)
|
| 63 |
+
layer_4 = self.pretrained.layer4(layer_3)
|
| 64 |
+
|
| 65 |
+
layer_1_rn = self.scratch.layer1_rn(layer_1)
|
| 66 |
+
layer_2_rn = self.scratch.layer2_rn(layer_2)
|
| 67 |
+
layer_3_rn = self.scratch.layer3_rn(layer_3)
|
| 68 |
+
layer_4_rn = self.scratch.layer4_rn(layer_4)
|
| 69 |
+
|
| 70 |
+
path_4 = self.scratch.refinenet4(layer_4_rn)
|
| 71 |
+
path_3 = self.scratch.refinenet3(path_4, layer_3_rn)
|
| 72 |
+
path_2 = self.scratch.refinenet2(path_3, layer_2_rn)
|
| 73 |
+
path_1 = self.scratch.refinenet1(path_2, layer_1_rn)
|
| 74 |
+
|
| 75 |
+
out = self.scratch.output_conv(path_1)
|
| 76 |
+
|
| 77 |
+
return torch.squeeze(out, dim=1)
|
DPT/dpt/models.py
ADDED
|
@@ -0,0 +1,153 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
|
| 5 |
+
from .base_model import BaseModel
|
| 6 |
+
from .blocks import (
|
| 7 |
+
FeatureFusionBlock,
|
| 8 |
+
FeatureFusionBlock_custom,
|
| 9 |
+
Interpolate,
|
| 10 |
+
_make_encoder,
|
| 11 |
+
forward_vit,
|
| 12 |
+
)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def _make_fusion_block(features, use_bn):
|
| 16 |
+
return FeatureFusionBlock_custom(
|
| 17 |
+
features,
|
| 18 |
+
nn.ReLU(False),
|
| 19 |
+
deconv=False,
|
| 20 |
+
bn=use_bn,
|
| 21 |
+
expand=False,
|
| 22 |
+
align_corners=True,
|
| 23 |
+
)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class DPT(BaseModel):
|
| 27 |
+
def __init__(
|
| 28 |
+
self,
|
| 29 |
+
head,
|
| 30 |
+
features=256,
|
| 31 |
+
backbone="vitb_rn50_384",
|
| 32 |
+
readout="project",
|
| 33 |
+
channels_last=False,
|
| 34 |
+
use_bn=False,
|
| 35 |
+
enable_attention_hooks=False,
|
| 36 |
+
):
|
| 37 |
+
|
| 38 |
+
super(DPT, self).__init__()
|
| 39 |
+
|
| 40 |
+
self.channels_last = channels_last
|
| 41 |
+
|
| 42 |
+
hooks = {
|
| 43 |
+
"vitb_rn50_384": [0, 1, 8, 11],
|
| 44 |
+
"vitb16_384": [2, 5, 8, 11],
|
| 45 |
+
"vitl16_384": [5, 11, 17, 23],
|
| 46 |
+
}
|
| 47 |
+
|
| 48 |
+
# Instantiate backbone and reassemble blocks
|
| 49 |
+
self.pretrained, self.scratch = _make_encoder(
|
| 50 |
+
backbone,
|
| 51 |
+
features,
|
| 52 |
+
False, # Set to true of you want to train from scratch, uses ImageNet weights
|
| 53 |
+
groups=1,
|
| 54 |
+
expand=False,
|
| 55 |
+
exportable=False,
|
| 56 |
+
hooks=hooks[backbone],
|
| 57 |
+
use_readout=readout,
|
| 58 |
+
enable_attention_hooks=enable_attention_hooks,
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
self.scratch.refinenet1 = _make_fusion_block(features, use_bn)
|
| 62 |
+
self.scratch.refinenet2 = _make_fusion_block(features, use_bn)
|
| 63 |
+
self.scratch.refinenet3 = _make_fusion_block(features, use_bn)
|
| 64 |
+
self.scratch.refinenet4 = _make_fusion_block(features, use_bn)
|
| 65 |
+
|
| 66 |
+
self.scratch.output_conv = head
|
| 67 |
+
|
| 68 |
+
def forward(self, x):
|
| 69 |
+
if self.channels_last == True:
|
| 70 |
+
x.contiguous(memory_format=torch.channels_last)
|
| 71 |
+
|
| 72 |
+
layer_1, layer_2, layer_3, layer_4 = forward_vit(self.pretrained, x)
|
| 73 |
+
|
| 74 |
+
layer_1_rn = self.scratch.layer1_rn(layer_1)
|
| 75 |
+
layer_2_rn = self.scratch.layer2_rn(layer_2)
|
| 76 |
+
layer_3_rn = self.scratch.layer3_rn(layer_3)
|
| 77 |
+
layer_4_rn = self.scratch.layer4_rn(layer_4)
|
| 78 |
+
|
| 79 |
+
path_4 = self.scratch.refinenet4(layer_4_rn)
|
| 80 |
+
path_3 = self.scratch.refinenet3(path_4, layer_3_rn)
|
| 81 |
+
path_2 = self.scratch.refinenet2(path_3, layer_2_rn)
|
| 82 |
+
path_1 = self.scratch.refinenet1(path_2, layer_1_rn)
|
| 83 |
+
|
| 84 |
+
out = self.scratch.output_conv(path_1)
|
| 85 |
+
|
| 86 |
+
return out
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
class DPTDepthModel(DPT):
|
| 90 |
+
def __init__(
|
| 91 |
+
self, path=None, non_negative=True, scale=1.0, shift=0.0, invert=False, **kwargs
|
| 92 |
+
):
|
| 93 |
+
features = kwargs["features"] if "features" in kwargs else 256
|
| 94 |
+
|
| 95 |
+
self.scale = scale
|
| 96 |
+
self.shift = shift
|
| 97 |
+
self.invert = invert
|
| 98 |
+
|
| 99 |
+
head = nn.Sequential(
|
| 100 |
+
nn.Conv2d(features, features // 2, kernel_size=3, stride=1, padding=1),
|
| 101 |
+
Interpolate(scale_factor=2, mode="bilinear", align_corners=True),
|
| 102 |
+
nn.Conv2d(features // 2, 32, kernel_size=3, stride=1, padding=1),
|
| 103 |
+
nn.ReLU(True),
|
| 104 |
+
nn.Conv2d(32, 1, kernel_size=1, stride=1, padding=0),
|
| 105 |
+
nn.ReLU(True) if non_negative else nn.Identity(),
|
| 106 |
+
nn.Identity(),
|
| 107 |
+
)
|
| 108 |
+
|
| 109 |
+
super().__init__(head, **kwargs)
|
| 110 |
+
|
| 111 |
+
if path is not None:
|
| 112 |
+
self.load(path)
|
| 113 |
+
|
| 114 |
+
def forward(self, x):
|
| 115 |
+
inv_depth = super().forward(x).squeeze(dim=1)
|
| 116 |
+
|
| 117 |
+
if self.invert:
|
| 118 |
+
depth = self.scale * inv_depth + self.shift
|
| 119 |
+
depth[depth < 1e-8] = 1e-8
|
| 120 |
+
depth = 1.0 / depth
|
| 121 |
+
return depth
|
| 122 |
+
else:
|
| 123 |
+
return inv_depth
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
class DPTSegmentationModel(DPT):
|
| 127 |
+
def __init__(self, num_classes, path=None, **kwargs):
|
| 128 |
+
|
| 129 |
+
features = kwargs["features"] if "features" in kwargs else 256
|
| 130 |
+
|
| 131 |
+
kwargs["use_bn"] = True
|
| 132 |
+
|
| 133 |
+
head = nn.Sequential(
|
| 134 |
+
nn.Conv2d(features, features, kernel_size=3, padding=1, bias=False),
|
| 135 |
+
nn.BatchNorm2d(features),
|
| 136 |
+
nn.ReLU(True),
|
| 137 |
+
nn.Dropout(0.1, False),
|
| 138 |
+
nn.Conv2d(features, num_classes, kernel_size=1),
|
| 139 |
+
Interpolate(scale_factor=2, mode="bilinear", align_corners=True),
|
| 140 |
+
)
|
| 141 |
+
|
| 142 |
+
super().__init__(head, **kwargs)
|
| 143 |
+
|
| 144 |
+
self.auxlayer = nn.Sequential(
|
| 145 |
+
nn.Conv2d(features, features, kernel_size=3, padding=1, bias=False),
|
| 146 |
+
nn.BatchNorm2d(features),
|
| 147 |
+
nn.ReLU(True),
|
| 148 |
+
nn.Dropout(0.1, False),
|
| 149 |
+
nn.Conv2d(features, num_classes, kernel_size=1),
|
| 150 |
+
)
|
| 151 |
+
|
| 152 |
+
if path is not None:
|
| 153 |
+
self.load(path)
|
DPT/dpt/transforms.py
ADDED
|
@@ -0,0 +1,231 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import cv2
|
| 3 |
+
import math
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def apply_min_size(sample, size, image_interpolation_method=cv2.INTER_AREA):
|
| 7 |
+
"""Rezise the sample to ensure the given size. Keeps aspect ratio.
|
| 8 |
+
|
| 9 |
+
Args:
|
| 10 |
+
sample (dict): sample
|
| 11 |
+
size (tuple): image size
|
| 12 |
+
|
| 13 |
+
Returns:
|
| 14 |
+
tuple: new size
|
| 15 |
+
"""
|
| 16 |
+
shape = list(sample["disparity"].shape)
|
| 17 |
+
|
| 18 |
+
if shape[0] >= size[0] and shape[1] >= size[1]:
|
| 19 |
+
return sample
|
| 20 |
+
|
| 21 |
+
scale = [0, 0]
|
| 22 |
+
scale[0] = size[0] / shape[0]
|
| 23 |
+
scale[1] = size[1] / shape[1]
|
| 24 |
+
|
| 25 |
+
scale = max(scale)
|
| 26 |
+
|
| 27 |
+
shape[0] = math.ceil(scale * shape[0])
|
| 28 |
+
shape[1] = math.ceil(scale * shape[1])
|
| 29 |
+
|
| 30 |
+
# resize
|
| 31 |
+
sample["image"] = cv2.resize(
|
| 32 |
+
sample["image"], tuple(shape[::-1]), interpolation=image_interpolation_method
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
sample["disparity"] = cv2.resize(
|
| 36 |
+
sample["disparity"], tuple(shape[::-1]), interpolation=cv2.INTER_NEAREST
|
| 37 |
+
)
|
| 38 |
+
sample["mask"] = cv2.resize(
|
| 39 |
+
sample["mask"].astype(np.float32),
|
| 40 |
+
tuple(shape[::-1]),
|
| 41 |
+
interpolation=cv2.INTER_NEAREST,
|
| 42 |
+
)
|
| 43 |
+
sample["mask"] = sample["mask"].astype(bool)
|
| 44 |
+
|
| 45 |
+
return tuple(shape)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class Resize(object):
|
| 49 |
+
"""Resize sample to given size (width, height)."""
|
| 50 |
+
|
| 51 |
+
def __init__(
|
| 52 |
+
self,
|
| 53 |
+
width,
|
| 54 |
+
height,
|
| 55 |
+
resize_target=True,
|
| 56 |
+
keep_aspect_ratio=False,
|
| 57 |
+
ensure_multiple_of=1,
|
| 58 |
+
resize_method="lower_bound",
|
| 59 |
+
image_interpolation_method=cv2.INTER_AREA,
|
| 60 |
+
):
|
| 61 |
+
"""Init.
|
| 62 |
+
|
| 63 |
+
Args:
|
| 64 |
+
width (int): desired output width
|
| 65 |
+
height (int): desired output height
|
| 66 |
+
resize_target (bool, optional):
|
| 67 |
+
True: Resize the full sample (image, mask, target).
|
| 68 |
+
False: Resize image only.
|
| 69 |
+
Defaults to True.
|
| 70 |
+
keep_aspect_ratio (bool, optional):
|
| 71 |
+
True: Keep the aspect ratio of the input sample.
|
| 72 |
+
Output sample might not have the given width and height, and
|
| 73 |
+
resize behaviour depends on the parameter 'resize_method'.
|
| 74 |
+
Defaults to False.
|
| 75 |
+
ensure_multiple_of (int, optional):
|
| 76 |
+
Output width and height is constrained to be multiple of this parameter.
|
| 77 |
+
Defaults to 1.
|
| 78 |
+
resize_method (str, optional):
|
| 79 |
+
"lower_bound": Output will be at least as large as the given size.
|
| 80 |
+
"upper_bound": Output will be at max as large as the given size. (Output size might be smaller than given size.)
|
| 81 |
+
"minimal": Scale as least as possible. (Output size might be smaller than given size.)
|
| 82 |
+
Defaults to "lower_bound".
|
| 83 |
+
"""
|
| 84 |
+
self.__width = width
|
| 85 |
+
self.__height = height
|
| 86 |
+
|
| 87 |
+
self.__resize_target = resize_target
|
| 88 |
+
self.__keep_aspect_ratio = keep_aspect_ratio
|
| 89 |
+
self.__multiple_of = ensure_multiple_of
|
| 90 |
+
self.__resize_method = resize_method
|
| 91 |
+
self.__image_interpolation_method = image_interpolation_method
|
| 92 |
+
|
| 93 |
+
def constrain_to_multiple_of(self, x, min_val=0, max_val=None):
|
| 94 |
+
y = (np.round(x / self.__multiple_of) * self.__multiple_of).astype(int)
|
| 95 |
+
|
| 96 |
+
if max_val is not None and y > max_val:
|
| 97 |
+
y = (np.floor(x / self.__multiple_of) * self.__multiple_of).astype(int)
|
| 98 |
+
|
| 99 |
+
if y < min_val:
|
| 100 |
+
y = (np.ceil(x / self.__multiple_of) * self.__multiple_of).astype(int)
|
| 101 |
+
|
| 102 |
+
return y
|
| 103 |
+
|
| 104 |
+
def get_size(self, width, height):
|
| 105 |
+
# determine new height and width
|
| 106 |
+
scale_height = self.__height / height
|
| 107 |
+
scale_width = self.__width / width
|
| 108 |
+
|
| 109 |
+
if self.__keep_aspect_ratio:
|
| 110 |
+
if self.__resize_method == "lower_bound":
|
| 111 |
+
# scale such that output size is lower bound
|
| 112 |
+
if scale_width > scale_height:
|
| 113 |
+
# fit width
|
| 114 |
+
scale_height = scale_width
|
| 115 |
+
else:
|
| 116 |
+
# fit height
|
| 117 |
+
scale_width = scale_height
|
| 118 |
+
elif self.__resize_method == "upper_bound":
|
| 119 |
+
# scale such that output size is upper bound
|
| 120 |
+
if scale_width < scale_height:
|
| 121 |
+
# fit width
|
| 122 |
+
scale_height = scale_width
|
| 123 |
+
else:
|
| 124 |
+
# fit height
|
| 125 |
+
scale_width = scale_height
|
| 126 |
+
elif self.__resize_method == "minimal":
|
| 127 |
+
# scale as least as possbile
|
| 128 |
+
if abs(1 - scale_width) < abs(1 - scale_height):
|
| 129 |
+
# fit width
|
| 130 |
+
scale_height = scale_width
|
| 131 |
+
else:
|
| 132 |
+
# fit height
|
| 133 |
+
scale_width = scale_height
|
| 134 |
+
else:
|
| 135 |
+
raise ValueError(
|
| 136 |
+
f"resize_method {self.__resize_method} not implemented"
|
| 137 |
+
)
|
| 138 |
+
|
| 139 |
+
if self.__resize_method == "lower_bound":
|
| 140 |
+
new_height = self.constrain_to_multiple_of(
|
| 141 |
+
scale_height * height, min_val=self.__height
|
| 142 |
+
)
|
| 143 |
+
new_width = self.constrain_to_multiple_of(
|
| 144 |
+
scale_width * width, min_val=self.__width
|
| 145 |
+
)
|
| 146 |
+
elif self.__resize_method == "upper_bound":
|
| 147 |
+
new_height = self.constrain_to_multiple_of(
|
| 148 |
+
scale_height * height, max_val=self.__height
|
| 149 |
+
)
|
| 150 |
+
new_width = self.constrain_to_multiple_of(
|
| 151 |
+
scale_width * width, max_val=self.__width
|
| 152 |
+
)
|
| 153 |
+
elif self.__resize_method == "minimal":
|
| 154 |
+
new_height = self.constrain_to_multiple_of(scale_height * height)
|
| 155 |
+
new_width = self.constrain_to_multiple_of(scale_width * width)
|
| 156 |
+
else:
|
| 157 |
+
raise ValueError(f"resize_method {self.__resize_method} not implemented")
|
| 158 |
+
|
| 159 |
+
return (new_width, new_height)
|
| 160 |
+
|
| 161 |
+
def __call__(self, sample):
|
| 162 |
+
width, height = self.get_size(
|
| 163 |
+
sample["image"].shape[1], sample["image"].shape[0]
|
| 164 |
+
)
|
| 165 |
+
|
| 166 |
+
# resize sample
|
| 167 |
+
sample["image"] = cv2.resize(
|
| 168 |
+
sample["image"],
|
| 169 |
+
(width, height),
|
| 170 |
+
interpolation=self.__image_interpolation_method,
|
| 171 |
+
)
|
| 172 |
+
|
| 173 |
+
if self.__resize_target:
|
| 174 |
+
if "disparity" in sample:
|
| 175 |
+
sample["disparity"] = cv2.resize(
|
| 176 |
+
sample["disparity"],
|
| 177 |
+
(width, height),
|
| 178 |
+
interpolation=cv2.INTER_NEAREST,
|
| 179 |
+
)
|
| 180 |
+
|
| 181 |
+
if "depth" in sample:
|
| 182 |
+
sample["depth"] = cv2.resize(
|
| 183 |
+
sample["depth"], (width, height), interpolation=cv2.INTER_NEAREST
|
| 184 |
+
)
|
| 185 |
+
|
| 186 |
+
sample["mask"] = cv2.resize(
|
| 187 |
+
sample["mask"].astype(np.float32),
|
| 188 |
+
(width, height),
|
| 189 |
+
interpolation=cv2.INTER_NEAREST,
|
| 190 |
+
)
|
| 191 |
+
sample["mask"] = sample["mask"].astype(bool)
|
| 192 |
+
|
| 193 |
+
return sample
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
class NormalizeImage(object):
|
| 197 |
+
"""Normlize image by given mean and std."""
|
| 198 |
+
|
| 199 |
+
def __init__(self, mean, std):
|
| 200 |
+
self.__mean = mean
|
| 201 |
+
self.__std = std
|
| 202 |
+
|
| 203 |
+
def __call__(self, sample):
|
| 204 |
+
sample["image"] = (sample["image"] - self.__mean) / self.__std
|
| 205 |
+
|
| 206 |
+
return sample
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
class PrepareForNet(object):
|
| 210 |
+
"""Prepare sample for usage as network input."""
|
| 211 |
+
|
| 212 |
+
def __init__(self):
|
| 213 |
+
pass
|
| 214 |
+
|
| 215 |
+
def __call__(self, sample):
|
| 216 |
+
image = np.transpose(sample["image"], (2, 0, 1))
|
| 217 |
+
sample["image"] = np.ascontiguousarray(image).astype(np.float32)
|
| 218 |
+
|
| 219 |
+
if "mask" in sample:
|
| 220 |
+
sample["mask"] = sample["mask"].astype(np.float32)
|
| 221 |
+
sample["mask"] = np.ascontiguousarray(sample["mask"])
|
| 222 |
+
|
| 223 |
+
if "disparity" in sample:
|
| 224 |
+
disparity = sample["disparity"].astype(np.float32)
|
| 225 |
+
sample["disparity"] = np.ascontiguousarray(disparity)
|
| 226 |
+
|
| 227 |
+
if "depth" in sample:
|
| 228 |
+
depth = sample["depth"].astype(np.float32)
|
| 229 |
+
sample["depth"] = np.ascontiguousarray(depth)
|
| 230 |
+
|
| 231 |
+
return sample
|
DPT/dpt/vit.py
ADDED
|
@@ -0,0 +1,576 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import timm
|
| 4 |
+
import types
|
| 5 |
+
import math
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
activations = {}
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def get_activation(name):
|
| 13 |
+
def hook(model, input, output):
|
| 14 |
+
activations[name] = output
|
| 15 |
+
|
| 16 |
+
return hook
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
attention = {}
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def get_attention(name):
|
| 23 |
+
def hook(module, input, output):
|
| 24 |
+
x = input[0]
|
| 25 |
+
B, N, C = x.shape
|
| 26 |
+
qkv = (
|
| 27 |
+
module.qkv(x)
|
| 28 |
+
.reshape(B, N, 3, module.num_heads, C // module.num_heads)
|
| 29 |
+
.permute(2, 0, 3, 1, 4)
|
| 30 |
+
)
|
| 31 |
+
q, k, v = (
|
| 32 |
+
qkv[0],
|
| 33 |
+
qkv[1],
|
| 34 |
+
qkv[2],
|
| 35 |
+
) # make torchscript happy (cannot use tensor as tuple)
|
| 36 |
+
|
| 37 |
+
attn = (q @ k.transpose(-2, -1)) * module.scale
|
| 38 |
+
|
| 39 |
+
attn = attn.softmax(dim=-1) # [:,:,1,1:]
|
| 40 |
+
attention[name] = attn
|
| 41 |
+
|
| 42 |
+
return hook
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def get_mean_attention_map(attn, token, shape):
|
| 46 |
+
attn = attn[:, :, token, 1:]
|
| 47 |
+
attn = attn.unflatten(2, torch.Size([shape[2] // 16, shape[3] // 16])).float()
|
| 48 |
+
attn = torch.nn.functional.interpolate(
|
| 49 |
+
attn, size=shape[2:], mode="bicubic", align_corners=False
|
| 50 |
+
).squeeze(0)
|
| 51 |
+
|
| 52 |
+
all_attn = torch.mean(attn, 0)
|
| 53 |
+
|
| 54 |
+
return all_attn
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class Slice(nn.Module):
|
| 58 |
+
def __init__(self, start_index=1):
|
| 59 |
+
super(Slice, self).__init__()
|
| 60 |
+
self.start_index = start_index
|
| 61 |
+
|
| 62 |
+
def forward(self, x):
|
| 63 |
+
return x[:, self.start_index :]
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
class AddReadout(nn.Module):
|
| 67 |
+
def __init__(self, start_index=1):
|
| 68 |
+
super(AddReadout, self).__init__()
|
| 69 |
+
self.start_index = start_index
|
| 70 |
+
|
| 71 |
+
def forward(self, x):
|
| 72 |
+
if self.start_index == 2:
|
| 73 |
+
readout = (x[:, 0] + x[:, 1]) / 2
|
| 74 |
+
else:
|
| 75 |
+
readout = x[:, 0]
|
| 76 |
+
return x[:, self.start_index :] + readout.unsqueeze(1)
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
class ProjectReadout(nn.Module):
|
| 80 |
+
def __init__(self, in_features, start_index=1):
|
| 81 |
+
super(ProjectReadout, self).__init__()
|
| 82 |
+
self.start_index = start_index
|
| 83 |
+
|
| 84 |
+
self.project = nn.Sequential(nn.Linear(2 * in_features, in_features), nn.GELU())
|
| 85 |
+
|
| 86 |
+
def forward(self, x):
|
| 87 |
+
readout = x[:, 0].unsqueeze(1).expand_as(x[:, self.start_index :])
|
| 88 |
+
features = torch.cat((x[:, self.start_index :], readout), -1)
|
| 89 |
+
|
| 90 |
+
return self.project(features)
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
class Transpose(nn.Module):
|
| 94 |
+
def __init__(self, dim0, dim1):
|
| 95 |
+
super(Transpose, self).__init__()
|
| 96 |
+
self.dim0 = dim0
|
| 97 |
+
self.dim1 = dim1
|
| 98 |
+
|
| 99 |
+
def forward(self, x):
|
| 100 |
+
x = x.transpose(self.dim0, self.dim1)
|
| 101 |
+
return x
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
def forward_vit(pretrained, x):
|
| 105 |
+
b, c, h, w = x.shape
|
| 106 |
+
|
| 107 |
+
glob = pretrained.model.forward_flex(x)
|
| 108 |
+
|
| 109 |
+
layer_1 = pretrained.activations["1"]
|
| 110 |
+
layer_2 = pretrained.activations["2"]
|
| 111 |
+
layer_3 = pretrained.activations["3"]
|
| 112 |
+
layer_4 = pretrained.activations["4"]
|
| 113 |
+
|
| 114 |
+
layer_1 = pretrained.act_postprocess1[0:2](layer_1)
|
| 115 |
+
layer_2 = pretrained.act_postprocess2[0:2](layer_2)
|
| 116 |
+
layer_3 = pretrained.act_postprocess3[0:2](layer_3)
|
| 117 |
+
layer_4 = pretrained.act_postprocess4[0:2](layer_4)
|
| 118 |
+
|
| 119 |
+
unflatten = nn.Sequential(
|
| 120 |
+
nn.Unflatten(
|
| 121 |
+
2,
|
| 122 |
+
torch.Size(
|
| 123 |
+
[
|
| 124 |
+
h // pretrained.model.patch_size[1],
|
| 125 |
+
w // pretrained.model.patch_size[0],
|
| 126 |
+
]
|
| 127 |
+
),
|
| 128 |
+
)
|
| 129 |
+
)
|
| 130 |
+
|
| 131 |
+
if layer_1.ndim == 3:
|
| 132 |
+
layer_1 = unflatten(layer_1)
|
| 133 |
+
if layer_2.ndim == 3:
|
| 134 |
+
layer_2 = unflatten(layer_2)
|
| 135 |
+
if layer_3.ndim == 3:
|
| 136 |
+
layer_3 = unflatten(layer_3)
|
| 137 |
+
if layer_4.ndim == 3:
|
| 138 |
+
layer_4 = unflatten(layer_4)
|
| 139 |
+
|
| 140 |
+
layer_1 = pretrained.act_postprocess1[3 : len(pretrained.act_postprocess1)](layer_1)
|
| 141 |
+
layer_2 = pretrained.act_postprocess2[3 : len(pretrained.act_postprocess2)](layer_2)
|
| 142 |
+
layer_3 = pretrained.act_postprocess3[3 : len(pretrained.act_postprocess3)](layer_3)
|
| 143 |
+
layer_4 = pretrained.act_postprocess4[3 : len(pretrained.act_postprocess4)](layer_4)
|
| 144 |
+
|
| 145 |
+
return layer_1, layer_2, layer_3, layer_4
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
def _resize_pos_embed(self, posemb, gs_h, gs_w):
|
| 149 |
+
posemb_tok, posemb_grid = (
|
| 150 |
+
posemb[:, : self.start_index],
|
| 151 |
+
posemb[0, self.start_index :],
|
| 152 |
+
)
|
| 153 |
+
|
| 154 |
+
gs_old = int(math.sqrt(len(posemb_grid)))
|
| 155 |
+
|
| 156 |
+
posemb_grid = posemb_grid.reshape(1, gs_old, gs_old, -1).permute(0, 3, 1, 2)
|
| 157 |
+
posemb_grid = F.interpolate(posemb_grid, size=(gs_h, gs_w), mode="bilinear")
|
| 158 |
+
posemb_grid = posemb_grid.permute(0, 2, 3, 1).reshape(1, gs_h * gs_w, -1)
|
| 159 |
+
|
| 160 |
+
posemb = torch.cat([posemb_tok, posemb_grid], dim=1)
|
| 161 |
+
|
| 162 |
+
return posemb
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
def forward_flex(self, x):
|
| 166 |
+
b, c, h, w = x.shape
|
| 167 |
+
|
| 168 |
+
pos_embed = self._resize_pos_embed(
|
| 169 |
+
self.pos_embed, h // self.patch_size[1], w // self.patch_size[0]
|
| 170 |
+
)
|
| 171 |
+
|
| 172 |
+
B = x.shape[0]
|
| 173 |
+
|
| 174 |
+
if hasattr(self.patch_embed, "backbone"):
|
| 175 |
+
x = self.patch_embed.backbone(x)
|
| 176 |
+
if isinstance(x, (list, tuple)):
|
| 177 |
+
x = x[-1] # last feature if backbone outputs list/tuple of features
|
| 178 |
+
|
| 179 |
+
x = self.patch_embed.proj(x).flatten(2).transpose(1, 2)
|
| 180 |
+
|
| 181 |
+
if getattr(self, "dist_token", None) is not None:
|
| 182 |
+
cls_tokens = self.cls_token.expand(
|
| 183 |
+
B, -1, -1
|
| 184 |
+
) # stole cls_tokens impl from Phil Wang, thanks
|
| 185 |
+
dist_token = self.dist_token.expand(B, -1, -1)
|
| 186 |
+
x = torch.cat((cls_tokens, dist_token, x), dim=1)
|
| 187 |
+
else:
|
| 188 |
+
cls_tokens = self.cls_token.expand(
|
| 189 |
+
B, -1, -1
|
| 190 |
+
) # stole cls_tokens impl from Phil Wang, thanks
|
| 191 |
+
x = torch.cat((cls_tokens, x), dim=1)
|
| 192 |
+
|
| 193 |
+
x = x + pos_embed
|
| 194 |
+
x = self.pos_drop(x)
|
| 195 |
+
|
| 196 |
+
for blk in self.blocks:
|
| 197 |
+
x = blk(x)
|
| 198 |
+
|
| 199 |
+
x = self.norm(x)
|
| 200 |
+
|
| 201 |
+
return x
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
def get_readout_oper(vit_features, features, use_readout, start_index=1):
|
| 205 |
+
if use_readout == "ignore":
|
| 206 |
+
readout_oper = [Slice(start_index)] * len(features)
|
| 207 |
+
elif use_readout == "add":
|
| 208 |
+
readout_oper = [AddReadout(start_index)] * len(features)
|
| 209 |
+
elif use_readout == "project":
|
| 210 |
+
readout_oper = [
|
| 211 |
+
ProjectReadout(vit_features, start_index) for out_feat in features
|
| 212 |
+
]
|
| 213 |
+
else:
|
| 214 |
+
assert (
|
| 215 |
+
False
|
| 216 |
+
), "wrong operation for readout token, use_readout can be 'ignore', 'add', or 'project'"
|
| 217 |
+
|
| 218 |
+
return readout_oper
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
def _make_vit_b16_backbone(
|
| 222 |
+
model,
|
| 223 |
+
features=[96, 192, 384, 768],
|
| 224 |
+
size=[384, 384],
|
| 225 |
+
hooks=[2, 5, 8, 11],
|
| 226 |
+
vit_features=768,
|
| 227 |
+
use_readout="ignore",
|
| 228 |
+
start_index=1,
|
| 229 |
+
enable_attention_hooks=False,
|
| 230 |
+
):
|
| 231 |
+
pretrained = nn.Module()
|
| 232 |
+
|
| 233 |
+
pretrained.model = model
|
| 234 |
+
pretrained.model.blocks[hooks[0]].register_forward_hook(get_activation("1"))
|
| 235 |
+
pretrained.model.blocks[hooks[1]].register_forward_hook(get_activation("2"))
|
| 236 |
+
pretrained.model.blocks[hooks[2]].register_forward_hook(get_activation("3"))
|
| 237 |
+
pretrained.model.blocks[hooks[3]].register_forward_hook(get_activation("4"))
|
| 238 |
+
|
| 239 |
+
pretrained.activations = activations
|
| 240 |
+
|
| 241 |
+
if enable_attention_hooks:
|
| 242 |
+
pretrained.model.blocks[hooks[0]].attn.register_forward_hook(
|
| 243 |
+
get_attention("attn_1")
|
| 244 |
+
)
|
| 245 |
+
pretrained.model.blocks[hooks[1]].attn.register_forward_hook(
|
| 246 |
+
get_attention("attn_2")
|
| 247 |
+
)
|
| 248 |
+
pretrained.model.blocks[hooks[2]].attn.register_forward_hook(
|
| 249 |
+
get_attention("attn_3")
|
| 250 |
+
)
|
| 251 |
+
pretrained.model.blocks[hooks[3]].attn.register_forward_hook(
|
| 252 |
+
get_attention("attn_4")
|
| 253 |
+
)
|
| 254 |
+
pretrained.attention = attention
|
| 255 |
+
|
| 256 |
+
readout_oper = get_readout_oper(vit_features, features, use_readout, start_index)
|
| 257 |
+
|
| 258 |
+
# 32, 48, 136, 384
|
| 259 |
+
pretrained.act_postprocess1 = nn.Sequential(
|
| 260 |
+
readout_oper[0],
|
| 261 |
+
Transpose(1, 2),
|
| 262 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 263 |
+
nn.Conv2d(
|
| 264 |
+
in_channels=vit_features,
|
| 265 |
+
out_channels=features[0],
|
| 266 |
+
kernel_size=1,
|
| 267 |
+
stride=1,
|
| 268 |
+
padding=0,
|
| 269 |
+
),
|
| 270 |
+
nn.ConvTranspose2d(
|
| 271 |
+
in_channels=features[0],
|
| 272 |
+
out_channels=features[0],
|
| 273 |
+
kernel_size=4,
|
| 274 |
+
stride=4,
|
| 275 |
+
padding=0,
|
| 276 |
+
bias=True,
|
| 277 |
+
dilation=1,
|
| 278 |
+
groups=1,
|
| 279 |
+
),
|
| 280 |
+
)
|
| 281 |
+
|
| 282 |
+
pretrained.act_postprocess2 = nn.Sequential(
|
| 283 |
+
readout_oper[1],
|
| 284 |
+
Transpose(1, 2),
|
| 285 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 286 |
+
nn.Conv2d(
|
| 287 |
+
in_channels=vit_features,
|
| 288 |
+
out_channels=features[1],
|
| 289 |
+
kernel_size=1,
|
| 290 |
+
stride=1,
|
| 291 |
+
padding=0,
|
| 292 |
+
),
|
| 293 |
+
nn.ConvTranspose2d(
|
| 294 |
+
in_channels=features[1],
|
| 295 |
+
out_channels=features[1],
|
| 296 |
+
kernel_size=2,
|
| 297 |
+
stride=2,
|
| 298 |
+
padding=0,
|
| 299 |
+
bias=True,
|
| 300 |
+
dilation=1,
|
| 301 |
+
groups=1,
|
| 302 |
+
),
|
| 303 |
+
)
|
| 304 |
+
|
| 305 |
+
pretrained.act_postprocess3 = nn.Sequential(
|
| 306 |
+
readout_oper[2],
|
| 307 |
+
Transpose(1, 2),
|
| 308 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 309 |
+
nn.Conv2d(
|
| 310 |
+
in_channels=vit_features,
|
| 311 |
+
out_channels=features[2],
|
| 312 |
+
kernel_size=1,
|
| 313 |
+
stride=1,
|
| 314 |
+
padding=0,
|
| 315 |
+
),
|
| 316 |
+
)
|
| 317 |
+
|
| 318 |
+
pretrained.act_postprocess4 = nn.Sequential(
|
| 319 |
+
readout_oper[3],
|
| 320 |
+
Transpose(1, 2),
|
| 321 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 322 |
+
nn.Conv2d(
|
| 323 |
+
in_channels=vit_features,
|
| 324 |
+
out_channels=features[3],
|
| 325 |
+
kernel_size=1,
|
| 326 |
+
stride=1,
|
| 327 |
+
padding=0,
|
| 328 |
+
),
|
| 329 |
+
nn.Conv2d(
|
| 330 |
+
in_channels=features[3],
|
| 331 |
+
out_channels=features[3],
|
| 332 |
+
kernel_size=3,
|
| 333 |
+
stride=2,
|
| 334 |
+
padding=1,
|
| 335 |
+
),
|
| 336 |
+
)
|
| 337 |
+
|
| 338 |
+
pretrained.model.start_index = start_index
|
| 339 |
+
pretrained.model.patch_size = [16, 16]
|
| 340 |
+
|
| 341 |
+
# We inject this function into the VisionTransformer instances so that
|
| 342 |
+
# we can use it with interpolated position embeddings without modifying the library source.
|
| 343 |
+
pretrained.model.forward_flex = types.MethodType(forward_flex, pretrained.model)
|
| 344 |
+
pretrained.model._resize_pos_embed = types.MethodType(
|
| 345 |
+
_resize_pos_embed, pretrained.model
|
| 346 |
+
)
|
| 347 |
+
|
| 348 |
+
return pretrained
|
| 349 |
+
|
| 350 |
+
|
| 351 |
+
def _make_vit_b_rn50_backbone(
|
| 352 |
+
model,
|
| 353 |
+
features=[256, 512, 768, 768],
|
| 354 |
+
size=[384, 384],
|
| 355 |
+
hooks=[0, 1, 8, 11],
|
| 356 |
+
vit_features=768,
|
| 357 |
+
use_vit_only=False,
|
| 358 |
+
use_readout="ignore",
|
| 359 |
+
start_index=1,
|
| 360 |
+
enable_attention_hooks=False,
|
| 361 |
+
):
|
| 362 |
+
pretrained = nn.Module()
|
| 363 |
+
|
| 364 |
+
pretrained.model = model
|
| 365 |
+
|
| 366 |
+
if use_vit_only == True:
|
| 367 |
+
pretrained.model.blocks[hooks[0]].register_forward_hook(get_activation("1"))
|
| 368 |
+
pretrained.model.blocks[hooks[1]].register_forward_hook(get_activation("2"))
|
| 369 |
+
else:
|
| 370 |
+
pretrained.model.patch_embed.backbone.stages[0].register_forward_hook(
|
| 371 |
+
get_activation("1")
|
| 372 |
+
)
|
| 373 |
+
pretrained.model.patch_embed.backbone.stages[1].register_forward_hook(
|
| 374 |
+
get_activation("2")
|
| 375 |
+
)
|
| 376 |
+
|
| 377 |
+
pretrained.model.blocks[hooks[2]].register_forward_hook(get_activation("3"))
|
| 378 |
+
pretrained.model.blocks[hooks[3]].register_forward_hook(get_activation("4"))
|
| 379 |
+
|
| 380 |
+
if enable_attention_hooks:
|
| 381 |
+
pretrained.model.blocks[2].attn.register_forward_hook(get_attention("attn_1"))
|
| 382 |
+
pretrained.model.blocks[5].attn.register_forward_hook(get_attention("attn_2"))
|
| 383 |
+
pretrained.model.blocks[8].attn.register_forward_hook(get_attention("attn_3"))
|
| 384 |
+
pretrained.model.blocks[11].attn.register_forward_hook(get_attention("attn_4"))
|
| 385 |
+
pretrained.attention = attention
|
| 386 |
+
|
| 387 |
+
pretrained.activations = activations
|
| 388 |
+
|
| 389 |
+
readout_oper = get_readout_oper(vit_features, features, use_readout, start_index)
|
| 390 |
+
|
| 391 |
+
if use_vit_only == True:
|
| 392 |
+
pretrained.act_postprocess1 = nn.Sequential(
|
| 393 |
+
readout_oper[0],
|
| 394 |
+
Transpose(1, 2),
|
| 395 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 396 |
+
nn.Conv2d(
|
| 397 |
+
in_channels=vit_features,
|
| 398 |
+
out_channels=features[0],
|
| 399 |
+
kernel_size=1,
|
| 400 |
+
stride=1,
|
| 401 |
+
padding=0,
|
| 402 |
+
),
|
| 403 |
+
nn.ConvTranspose2d(
|
| 404 |
+
in_channels=features[0],
|
| 405 |
+
out_channels=features[0],
|
| 406 |
+
kernel_size=4,
|
| 407 |
+
stride=4,
|
| 408 |
+
padding=0,
|
| 409 |
+
bias=True,
|
| 410 |
+
dilation=1,
|
| 411 |
+
groups=1,
|
| 412 |
+
),
|
| 413 |
+
)
|
| 414 |
+
|
| 415 |
+
pretrained.act_postprocess2 = nn.Sequential(
|
| 416 |
+
readout_oper[1],
|
| 417 |
+
Transpose(1, 2),
|
| 418 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 419 |
+
nn.Conv2d(
|
| 420 |
+
in_channels=vit_features,
|
| 421 |
+
out_channels=features[1],
|
| 422 |
+
kernel_size=1,
|
| 423 |
+
stride=1,
|
| 424 |
+
padding=0,
|
| 425 |
+
),
|
| 426 |
+
nn.ConvTranspose2d(
|
| 427 |
+
in_channels=features[1],
|
| 428 |
+
out_channels=features[1],
|
| 429 |
+
kernel_size=2,
|
| 430 |
+
stride=2,
|
| 431 |
+
padding=0,
|
| 432 |
+
bias=True,
|
| 433 |
+
dilation=1,
|
| 434 |
+
groups=1,
|
| 435 |
+
),
|
| 436 |
+
)
|
| 437 |
+
else:
|
| 438 |
+
pretrained.act_postprocess1 = nn.Sequential(
|
| 439 |
+
nn.Identity(), nn.Identity(), nn.Identity()
|
| 440 |
+
)
|
| 441 |
+
pretrained.act_postprocess2 = nn.Sequential(
|
| 442 |
+
nn.Identity(), nn.Identity(), nn.Identity()
|
| 443 |
+
)
|
| 444 |
+
|
| 445 |
+
pretrained.act_postprocess3 = nn.Sequential(
|
| 446 |
+
readout_oper[2],
|
| 447 |
+
Transpose(1, 2),
|
| 448 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 449 |
+
nn.Conv2d(
|
| 450 |
+
in_channels=vit_features,
|
| 451 |
+
out_channels=features[2],
|
| 452 |
+
kernel_size=1,
|
| 453 |
+
stride=1,
|
| 454 |
+
padding=0,
|
| 455 |
+
),
|
| 456 |
+
)
|
| 457 |
+
|
| 458 |
+
pretrained.act_postprocess4 = nn.Sequential(
|
| 459 |
+
readout_oper[3],
|
| 460 |
+
Transpose(1, 2),
|
| 461 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 462 |
+
nn.Conv2d(
|
| 463 |
+
in_channels=vit_features,
|
| 464 |
+
out_channels=features[3],
|
| 465 |
+
kernel_size=1,
|
| 466 |
+
stride=1,
|
| 467 |
+
padding=0,
|
| 468 |
+
),
|
| 469 |
+
nn.Conv2d(
|
| 470 |
+
in_channels=features[3],
|
| 471 |
+
out_channels=features[3],
|
| 472 |
+
kernel_size=3,
|
| 473 |
+
stride=2,
|
| 474 |
+
padding=1,
|
| 475 |
+
),
|
| 476 |
+
)
|
| 477 |
+
|
| 478 |
+
pretrained.model.start_index = start_index
|
| 479 |
+
pretrained.model.patch_size = [16, 16]
|
| 480 |
+
|
| 481 |
+
# We inject this function into the VisionTransformer instances so that
|
| 482 |
+
# we can use it with interpolated position embeddings without modifying the library source.
|
| 483 |
+
pretrained.model.forward_flex = types.MethodType(forward_flex, pretrained.model)
|
| 484 |
+
|
| 485 |
+
# We inject this function into the VisionTransformer instances so that
|
| 486 |
+
# we can use it with interpolated position embeddings without modifying the library source.
|
| 487 |
+
pretrained.model._resize_pos_embed = types.MethodType(
|
| 488 |
+
_resize_pos_embed, pretrained.model
|
| 489 |
+
)
|
| 490 |
+
|
| 491 |
+
return pretrained
|
| 492 |
+
|
| 493 |
+
|
| 494 |
+
def _make_pretrained_vitb_rn50_384(
|
| 495 |
+
pretrained,
|
| 496 |
+
use_readout="ignore",
|
| 497 |
+
hooks=None,
|
| 498 |
+
use_vit_only=False,
|
| 499 |
+
enable_attention_hooks=False,
|
| 500 |
+
):
|
| 501 |
+
model = timm.create_model("vit_base_resnet50_384", pretrained=pretrained)
|
| 502 |
+
|
| 503 |
+
hooks = [0, 1, 8, 11] if hooks == None else hooks
|
| 504 |
+
return _make_vit_b_rn50_backbone(
|
| 505 |
+
model,
|
| 506 |
+
features=[256, 512, 768, 768],
|
| 507 |
+
size=[384, 384],
|
| 508 |
+
hooks=hooks,
|
| 509 |
+
use_vit_only=use_vit_only,
|
| 510 |
+
use_readout=use_readout,
|
| 511 |
+
enable_attention_hooks=enable_attention_hooks,
|
| 512 |
+
)
|
| 513 |
+
|
| 514 |
+
|
| 515 |
+
def _make_pretrained_vitl16_384(
|
| 516 |
+
pretrained, use_readout="ignore", hooks=None, enable_attention_hooks=False
|
| 517 |
+
):
|
| 518 |
+
model = timm.create_model("vit_large_patch16_384", pretrained=pretrained)
|
| 519 |
+
|
| 520 |
+
hooks = [5, 11, 17, 23] if hooks == None else hooks
|
| 521 |
+
return _make_vit_b16_backbone(
|
| 522 |
+
model,
|
| 523 |
+
features=[256, 512, 1024, 1024],
|
| 524 |
+
hooks=hooks,
|
| 525 |
+
vit_features=1024,
|
| 526 |
+
use_readout=use_readout,
|
| 527 |
+
enable_attention_hooks=enable_attention_hooks,
|
| 528 |
+
)
|
| 529 |
+
|
| 530 |
+
|
| 531 |
+
def _make_pretrained_vitb16_384(
|
| 532 |
+
pretrained, use_readout="ignore", hooks=None, enable_attention_hooks=False
|
| 533 |
+
):
|
| 534 |
+
model = timm.create_model("vit_base_patch16_384", pretrained=pretrained)
|
| 535 |
+
|
| 536 |
+
hooks = [2, 5, 8, 11] if hooks == None else hooks
|
| 537 |
+
return _make_vit_b16_backbone(
|
| 538 |
+
model,
|
| 539 |
+
features=[96, 192, 384, 768],
|
| 540 |
+
hooks=hooks,
|
| 541 |
+
use_readout=use_readout,
|
| 542 |
+
enable_attention_hooks=enable_attention_hooks,
|
| 543 |
+
)
|
| 544 |
+
|
| 545 |
+
|
| 546 |
+
def _make_pretrained_deitb16_384(
|
| 547 |
+
pretrained, use_readout="ignore", hooks=None, enable_attention_hooks=False
|
| 548 |
+
):
|
| 549 |
+
model = timm.create_model("vit_deit_base_patch16_384", pretrained=pretrained)
|
| 550 |
+
|
| 551 |
+
hooks = [2, 5, 8, 11] if hooks == None else hooks
|
| 552 |
+
return _make_vit_b16_backbone(
|
| 553 |
+
model,
|
| 554 |
+
features=[96, 192, 384, 768],
|
| 555 |
+
hooks=hooks,
|
| 556 |
+
use_readout=use_readout,
|
| 557 |
+
enable_attention_hooks=enable_attention_hooks,
|
| 558 |
+
)
|
| 559 |
+
|
| 560 |
+
|
| 561 |
+
def _make_pretrained_deitb16_distil_384(
|
| 562 |
+
pretrained, use_readout="ignore", hooks=None, enable_attention_hooks=False
|
| 563 |
+
):
|
| 564 |
+
model = timm.create_model(
|
| 565 |
+
"vit_deit_base_distilled_patch16_384", pretrained=pretrained
|
| 566 |
+
)
|
| 567 |
+
|
| 568 |
+
hooks = [2, 5, 8, 11] if hooks == None else hooks
|
| 569 |
+
return _make_vit_b16_backbone(
|
| 570 |
+
model,
|
| 571 |
+
features=[96, 192, 384, 768],
|
| 572 |
+
hooks=hooks,
|
| 573 |
+
use_readout=use_readout,
|
| 574 |
+
start_index=2,
|
| 575 |
+
enable_attention_hooks=enable_attention_hooks,
|
| 576 |
+
)
|
DPT/input/.placeholder
ADDED
|
File without changes
|
DPT/output_monodepth/.placeholder
ADDED
|
File without changes
|
DPT/output_semseg/.placeholder
ADDED
|
File without changes
|
DPT/requirements.txt
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch==1.8.1
|
| 2 |
+
torchvision==0.9.1
|
| 3 |
+
opencv-python==4.5.2.54
|
| 4 |
+
timm==0.4.5
|
DPT/run_monodepth.py
ADDED
|
@@ -0,0 +1,238 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Compute depth maps for images in the input folder.
|
| 2 |
+
"""
|
| 3 |
+
import os
|
| 4 |
+
import glob
|
| 5 |
+
import torch
|
| 6 |
+
import cv2
|
| 7 |
+
import argparse
|
| 8 |
+
|
| 9 |
+
import util.io
|
| 10 |
+
|
| 11 |
+
from torchvision.transforms import Compose
|
| 12 |
+
|
| 13 |
+
from dpt.models import DPTDepthModel
|
| 14 |
+
from dpt.midas_net import MidasNet_large
|
| 15 |
+
from dpt.transforms import Resize, NormalizeImage, PrepareForNet
|
| 16 |
+
|
| 17 |
+
#from util.misc import visualize_attention
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def run(input_path, output_path, model_path, model_type="dpt_hybrid", optimize=True):
|
| 21 |
+
"""Run MonoDepthNN to compute depth maps.
|
| 22 |
+
|
| 23 |
+
Args:
|
| 24 |
+
input_path (str): path to input folder
|
| 25 |
+
output_path (str): path to output folder
|
| 26 |
+
model_path (str): path to saved model
|
| 27 |
+
"""
|
| 28 |
+
print("initialize")
|
| 29 |
+
|
| 30 |
+
# select device
|
| 31 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 32 |
+
print("device: %s" % device)
|
| 33 |
+
|
| 34 |
+
# load network
|
| 35 |
+
if model_type == "dpt_large": # DPT-Large
|
| 36 |
+
net_w = net_h = 384
|
| 37 |
+
model = DPTDepthModel(
|
| 38 |
+
path=model_path,
|
| 39 |
+
backbone="vitl16_384",
|
| 40 |
+
non_negative=True,
|
| 41 |
+
enable_attention_hooks=False,
|
| 42 |
+
)
|
| 43 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 44 |
+
elif model_type == "dpt_hybrid": # DPT-Hybrid
|
| 45 |
+
net_w = net_h = 384
|
| 46 |
+
model = DPTDepthModel(
|
| 47 |
+
path=model_path,
|
| 48 |
+
backbone="vitb_rn50_384",
|
| 49 |
+
non_negative=True,
|
| 50 |
+
enable_attention_hooks=False,
|
| 51 |
+
)
|
| 52 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 53 |
+
elif model_type == "dpt_hybrid_kitti":
|
| 54 |
+
net_w = 1216
|
| 55 |
+
net_h = 352
|
| 56 |
+
|
| 57 |
+
model = DPTDepthModel(
|
| 58 |
+
path=model_path,
|
| 59 |
+
scale=0.00006016,
|
| 60 |
+
shift=0.00579,
|
| 61 |
+
invert=True,
|
| 62 |
+
backbone="vitb_rn50_384",
|
| 63 |
+
non_negative=True,
|
| 64 |
+
enable_attention_hooks=False,
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 68 |
+
elif model_type == "dpt_hybrid_nyu":
|
| 69 |
+
net_w = 640
|
| 70 |
+
net_h = 480
|
| 71 |
+
|
| 72 |
+
model = DPTDepthModel(
|
| 73 |
+
path=model_path,
|
| 74 |
+
scale=0.000305,
|
| 75 |
+
shift=0.1378,
|
| 76 |
+
invert=True,
|
| 77 |
+
backbone="vitb_rn50_384",
|
| 78 |
+
non_negative=True,
|
| 79 |
+
enable_attention_hooks=False,
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 83 |
+
elif model_type == "midas_v21": # Convolutional model
|
| 84 |
+
net_w = net_h = 384
|
| 85 |
+
|
| 86 |
+
model = MidasNet_large(model_path, non_negative=True)
|
| 87 |
+
normalization = NormalizeImage(
|
| 88 |
+
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
|
| 89 |
+
)
|
| 90 |
+
else:
|
| 91 |
+
assert (
|
| 92 |
+
False
|
| 93 |
+
), f"model_type '{model_type}' not implemented, use: --model_type [dpt_large|dpt_hybrid|dpt_hybrid_kitti|dpt_hybrid_nyu|midas_v21]"
|
| 94 |
+
|
| 95 |
+
transform = Compose(
|
| 96 |
+
[
|
| 97 |
+
Resize(
|
| 98 |
+
net_w,
|
| 99 |
+
net_h,
|
| 100 |
+
resize_target=None,
|
| 101 |
+
keep_aspect_ratio=True,
|
| 102 |
+
ensure_multiple_of=32,
|
| 103 |
+
resize_method="minimal",
|
| 104 |
+
image_interpolation_method=cv2.INTER_CUBIC,
|
| 105 |
+
),
|
| 106 |
+
normalization,
|
| 107 |
+
PrepareForNet(),
|
| 108 |
+
]
|
| 109 |
+
)
|
| 110 |
+
|
| 111 |
+
model.eval()
|
| 112 |
+
|
| 113 |
+
if optimize == True and device == torch.device("cuda"):
|
| 114 |
+
model = model.to(memory_format=torch.channels_last)
|
| 115 |
+
model = model.half()
|
| 116 |
+
|
| 117 |
+
model.to(device)
|
| 118 |
+
|
| 119 |
+
# get input
|
| 120 |
+
img_names = glob.glob(os.path.join(input_path, "*"))
|
| 121 |
+
num_images = len(img_names)
|
| 122 |
+
|
| 123 |
+
# create output folder
|
| 124 |
+
os.makedirs(output_path, exist_ok=True)
|
| 125 |
+
|
| 126 |
+
print("start processing")
|
| 127 |
+
for ind, img_name in enumerate(img_names):
|
| 128 |
+
if os.path.isdir(img_name):
|
| 129 |
+
continue
|
| 130 |
+
|
| 131 |
+
print(" processing {} ({}/{})".format(img_name, ind + 1, num_images))
|
| 132 |
+
# input
|
| 133 |
+
|
| 134 |
+
img = util.io.read_image(img_name)
|
| 135 |
+
|
| 136 |
+
if args.kitti_crop is True:
|
| 137 |
+
height, width, _ = img.shape
|
| 138 |
+
top = height - 352
|
| 139 |
+
left = (width - 1216) // 2
|
| 140 |
+
img = img[top : top + 352, left : left + 1216, :]
|
| 141 |
+
|
| 142 |
+
img_input = transform({"image": img})["image"]
|
| 143 |
+
|
| 144 |
+
# compute
|
| 145 |
+
with torch.no_grad():
|
| 146 |
+
sample = torch.from_numpy(img_input).to(device).unsqueeze(0)
|
| 147 |
+
|
| 148 |
+
if optimize == True and device == torch.device("cuda"):
|
| 149 |
+
sample = sample.to(memory_format=torch.channels_last)
|
| 150 |
+
sample = sample.half()
|
| 151 |
+
|
| 152 |
+
prediction = model.forward(sample)
|
| 153 |
+
prediction = (
|
| 154 |
+
torch.nn.functional.interpolate(
|
| 155 |
+
prediction.unsqueeze(1),
|
| 156 |
+
size=img.shape[:2],
|
| 157 |
+
mode="bicubic",
|
| 158 |
+
align_corners=False,
|
| 159 |
+
)
|
| 160 |
+
.squeeze()
|
| 161 |
+
.cpu()
|
| 162 |
+
.numpy()
|
| 163 |
+
)
|
| 164 |
+
|
| 165 |
+
if model_type == "dpt_hybrid_kitti":
|
| 166 |
+
prediction *= 256
|
| 167 |
+
|
| 168 |
+
if model_type == "dpt_hybrid_nyu":
|
| 169 |
+
prediction *= 1000.0
|
| 170 |
+
|
| 171 |
+
filename = os.path.join(
|
| 172 |
+
output_path, os.path.splitext(os.path.basename(img_name))[0]
|
| 173 |
+
)
|
| 174 |
+
util.io.write_depth(filename, prediction, bits=2, absolute_depth=args.absolute_depth)
|
| 175 |
+
|
| 176 |
+
print("finished")
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
if __name__ == "__main__":
|
| 180 |
+
parser = argparse.ArgumentParser()
|
| 181 |
+
|
| 182 |
+
parser.add_argument(
|
| 183 |
+
"-i", "--input_path", default="input", help="folder with input images"
|
| 184 |
+
)
|
| 185 |
+
|
| 186 |
+
parser.add_argument(
|
| 187 |
+
"-o",
|
| 188 |
+
"--output_path",
|
| 189 |
+
default="output_monodepth",
|
| 190 |
+
help="folder for output images",
|
| 191 |
+
)
|
| 192 |
+
|
| 193 |
+
parser.add_argument(
|
| 194 |
+
"-m", "--model_weights", default=None, help="path to model weights"
|
| 195 |
+
)
|
| 196 |
+
|
| 197 |
+
parser.add_argument(
|
| 198 |
+
"-t",
|
| 199 |
+
"--model_type",
|
| 200 |
+
default="dpt_hybrid",
|
| 201 |
+
help="model type [dpt_large|dpt_hybrid|midas_v21]",
|
| 202 |
+
)
|
| 203 |
+
|
| 204 |
+
parser.add_argument("--kitti_crop", dest="kitti_crop", action="store_true")
|
| 205 |
+
parser.add_argument("--absolute_depth", dest="absolute_depth", action="store_true")
|
| 206 |
+
|
| 207 |
+
parser.add_argument("--optimize", dest="optimize", action="store_true")
|
| 208 |
+
parser.add_argument("--no-optimize", dest="optimize", action="store_false")
|
| 209 |
+
|
| 210 |
+
parser.set_defaults(optimize=True)
|
| 211 |
+
parser.set_defaults(kitti_crop=False)
|
| 212 |
+
parser.set_defaults(absolute_depth=False)
|
| 213 |
+
|
| 214 |
+
args = parser.parse_args()
|
| 215 |
+
|
| 216 |
+
default_models = {
|
| 217 |
+
"midas_v21": "weights/midas_v21-f6b98070.pt",
|
| 218 |
+
"dpt_large": "weights/dpt_large-midas-2f21e586.pt",
|
| 219 |
+
"dpt_hybrid": "weights/dpt_hybrid-midas-501f0c75.pt",
|
| 220 |
+
"dpt_hybrid_kitti": "weights/dpt_hybrid_kitti-cb926ef4.pt",
|
| 221 |
+
"dpt_hybrid_nyu": "weights/dpt_hybrid_nyu-2ce69ec7.pt",
|
| 222 |
+
}
|
| 223 |
+
|
| 224 |
+
if args.model_weights is None:
|
| 225 |
+
args.model_weights = default_models[args.model_type]
|
| 226 |
+
|
| 227 |
+
# set torch options
|
| 228 |
+
torch.backends.cudnn.enabled = True
|
| 229 |
+
torch.backends.cudnn.benchmark = True
|
| 230 |
+
|
| 231 |
+
# compute depth maps
|
| 232 |
+
run(
|
| 233 |
+
args.input_path,
|
| 234 |
+
args.output_path,
|
| 235 |
+
args.model_weights,
|
| 236 |
+
args.model_type,
|
| 237 |
+
args.optimize,
|
| 238 |
+
)
|
DPT/run_segmentation.py
ADDED
|
@@ -0,0 +1,163 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Compute segmentation maps for images in the input folder.
|
| 2 |
+
"""
|
| 3 |
+
import os
|
| 4 |
+
import glob
|
| 5 |
+
import cv2
|
| 6 |
+
import argparse
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
|
| 11 |
+
import util.io
|
| 12 |
+
|
| 13 |
+
from torchvision.transforms import Compose
|
| 14 |
+
from dpt.models import DPTSegmentationModel
|
| 15 |
+
from dpt.transforms import Resize, NormalizeImage, PrepareForNet
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def run(input_path, output_path, model_path, model_type="dpt_hybrid", optimize=True):
|
| 19 |
+
"""Run segmentation network
|
| 20 |
+
|
| 21 |
+
Args:
|
| 22 |
+
input_path (str): path to input folder
|
| 23 |
+
output_path (str): path to output folder
|
| 24 |
+
model_path (str): path to saved model
|
| 25 |
+
"""
|
| 26 |
+
print("initialize")
|
| 27 |
+
|
| 28 |
+
# select device
|
| 29 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 30 |
+
print("device: %s" % device)
|
| 31 |
+
|
| 32 |
+
net_w = net_h = 480
|
| 33 |
+
|
| 34 |
+
# load network
|
| 35 |
+
if model_type == "dpt_large":
|
| 36 |
+
model = DPTSegmentationModel(
|
| 37 |
+
150,
|
| 38 |
+
path=model_path,
|
| 39 |
+
backbone="vitl16_384",
|
| 40 |
+
)
|
| 41 |
+
elif model_type == "dpt_hybrid":
|
| 42 |
+
model = DPTSegmentationModel(
|
| 43 |
+
150,
|
| 44 |
+
path=model_path,
|
| 45 |
+
backbone="vitb_rn50_384",
|
| 46 |
+
)
|
| 47 |
+
else:
|
| 48 |
+
assert (
|
| 49 |
+
False
|
| 50 |
+
), f"model_type '{model_type}' not implemented, use: --model_type [dpt_large|dpt_hybrid]"
|
| 51 |
+
|
| 52 |
+
transform = Compose(
|
| 53 |
+
[
|
| 54 |
+
Resize(
|
| 55 |
+
net_w,
|
| 56 |
+
net_h,
|
| 57 |
+
resize_target=None,
|
| 58 |
+
keep_aspect_ratio=True,
|
| 59 |
+
ensure_multiple_of=32,
|
| 60 |
+
resize_method="minimal",
|
| 61 |
+
image_interpolation_method=cv2.INTER_CUBIC,
|
| 62 |
+
),
|
| 63 |
+
NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
|
| 64 |
+
PrepareForNet(),
|
| 65 |
+
]
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
model.eval()
|
| 69 |
+
|
| 70 |
+
if optimize == True and device == torch.device("cuda"):
|
| 71 |
+
model = model.to(memory_format=torch.channels_last)
|
| 72 |
+
model = model.half()
|
| 73 |
+
|
| 74 |
+
model.to(device)
|
| 75 |
+
|
| 76 |
+
# get input
|
| 77 |
+
img_names = glob.glob(os.path.join(input_path, "*"))
|
| 78 |
+
num_images = len(img_names)
|
| 79 |
+
|
| 80 |
+
# create output folder
|
| 81 |
+
os.makedirs(output_path, exist_ok=True)
|
| 82 |
+
|
| 83 |
+
print("start processing")
|
| 84 |
+
|
| 85 |
+
for ind, img_name in enumerate(img_names):
|
| 86 |
+
|
| 87 |
+
print(" processing {} ({}/{})".format(img_name, ind + 1, num_images))
|
| 88 |
+
|
| 89 |
+
# input
|
| 90 |
+
img = util.io.read_image(img_name)
|
| 91 |
+
img_input = transform({"image": img})["image"]
|
| 92 |
+
|
| 93 |
+
# compute
|
| 94 |
+
with torch.no_grad():
|
| 95 |
+
sample = torch.from_numpy(img_input).to(device).unsqueeze(0)
|
| 96 |
+
if optimize == True and device == torch.device("cuda"):
|
| 97 |
+
sample = sample.to(memory_format=torch.channels_last)
|
| 98 |
+
sample = sample.half()
|
| 99 |
+
|
| 100 |
+
out = model.forward(sample)
|
| 101 |
+
|
| 102 |
+
prediction = torch.nn.functional.interpolate(
|
| 103 |
+
out, size=img.shape[:2], mode="bicubic", align_corners=False
|
| 104 |
+
)
|
| 105 |
+
prediction = torch.argmax(prediction, dim=1) + 1
|
| 106 |
+
prediction = prediction.squeeze().cpu().numpy()
|
| 107 |
+
|
| 108 |
+
# output
|
| 109 |
+
filename = os.path.join(
|
| 110 |
+
output_path, os.path.splitext(os.path.basename(img_name))[0]
|
| 111 |
+
)
|
| 112 |
+
util.io.write_segm_img(filename, img, prediction, alpha=0.5)
|
| 113 |
+
|
| 114 |
+
print("finished")
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
if __name__ == "__main__":
|
| 118 |
+
parser = argparse.ArgumentParser()
|
| 119 |
+
|
| 120 |
+
parser.add_argument(
|
| 121 |
+
"-i", "--input_path", default="input", help="folder with input images"
|
| 122 |
+
)
|
| 123 |
+
|
| 124 |
+
parser.add_argument(
|
| 125 |
+
"-o", "--output_path", default="output_semseg", help="folder for output images"
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
parser.add_argument(
|
| 129 |
+
"-m",
|
| 130 |
+
"--model_weights",
|
| 131 |
+
default=None,
|
| 132 |
+
help="path to the trained weights of model",
|
| 133 |
+
)
|
| 134 |
+
|
| 135 |
+
# 'vit_large', 'vit_hybrid'
|
| 136 |
+
parser.add_argument("-t", "--model_type", default="dpt_hybrid", help="model type")
|
| 137 |
+
|
| 138 |
+
parser.add_argument("--optimize", dest="optimize", action="store_true")
|
| 139 |
+
parser.add_argument("--no-optimize", dest="optimize", action="store_false")
|
| 140 |
+
parser.set_defaults(optimize=True)
|
| 141 |
+
|
| 142 |
+
args = parser.parse_args()
|
| 143 |
+
|
| 144 |
+
default_models = {
|
| 145 |
+
"dpt_large": "weights/dpt_large-ade20k-b12dca68.pt",
|
| 146 |
+
"dpt_hybrid": "weights/dpt_hybrid-ade20k-53898607.pt",
|
| 147 |
+
}
|
| 148 |
+
|
| 149 |
+
if args.model_weights is None:
|
| 150 |
+
args.model_weights = default_models[args.model_type]
|
| 151 |
+
|
| 152 |
+
# set torch options
|
| 153 |
+
torch.backends.cudnn.enabled = True
|
| 154 |
+
torch.backends.cudnn.benchmark = True
|
| 155 |
+
|
| 156 |
+
# compute segmentation maps
|
| 157 |
+
run(
|
| 158 |
+
args.input_path,
|
| 159 |
+
args.output_path,
|
| 160 |
+
args.model_weights,
|
| 161 |
+
args.model_type,
|
| 162 |
+
args.optimize,
|
| 163 |
+
)
|
DPT/setup.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import setuptools
|
| 2 |
+
|
| 3 |
+
__version__ = '0.0.1dev1'
|
| 4 |
+
|
| 5 |
+
setuptools.setup(
|
| 6 |
+
name='dpt',
|
| 7 |
+
version=__version__,
|
| 8 |
+
packages=setuptools.find_packages(),
|
| 9 |
+
# Only put dependencies that's not depends on cuda directly.
|
| 10 |
+
install_requires=['timm']
|
| 11 |
+
)
|
DPT/util/__init__.py
ADDED
|
File without changes
|
DPT/util/io.py
ADDED
|
@@ -0,0 +1,219 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Utils for monoDepth.
|
| 2 |
+
"""
|
| 3 |
+
import sys
|
| 4 |
+
import re
|
| 5 |
+
import numpy as np
|
| 6 |
+
import cv2
|
| 7 |
+
import torch
|
| 8 |
+
|
| 9 |
+
from PIL import Image
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
from .pallete import get_mask_pallete
|
| 13 |
+
|
| 14 |
+
def read_pfm(path):
|
| 15 |
+
"""Read pfm file.
|
| 16 |
+
|
| 17 |
+
Args:
|
| 18 |
+
path (str): path to file
|
| 19 |
+
|
| 20 |
+
Returns:
|
| 21 |
+
tuple: (data, scale)
|
| 22 |
+
"""
|
| 23 |
+
with open(path, "rb") as file:
|
| 24 |
+
|
| 25 |
+
color = None
|
| 26 |
+
width = None
|
| 27 |
+
height = None
|
| 28 |
+
scale = None
|
| 29 |
+
endian = None
|
| 30 |
+
|
| 31 |
+
header = file.readline().rstrip()
|
| 32 |
+
if header.decode("ascii") == "PF":
|
| 33 |
+
color = True
|
| 34 |
+
elif header.decode("ascii") == "Pf":
|
| 35 |
+
color = False
|
| 36 |
+
else:
|
| 37 |
+
raise Exception("Not a PFM file: " + path)
|
| 38 |
+
|
| 39 |
+
dim_match = re.match(r"^(\d+)\s(\d+)\s$", file.readline().decode("ascii"))
|
| 40 |
+
if dim_match:
|
| 41 |
+
width, height = list(map(int, dim_match.groups()))
|
| 42 |
+
else:
|
| 43 |
+
raise Exception("Malformed PFM header.")
|
| 44 |
+
|
| 45 |
+
scale = float(file.readline().decode("ascii").rstrip())
|
| 46 |
+
if scale < 0:
|
| 47 |
+
# little-endian
|
| 48 |
+
endian = "<"
|
| 49 |
+
scale = -scale
|
| 50 |
+
else:
|
| 51 |
+
# big-endian
|
| 52 |
+
endian = ">"
|
| 53 |
+
|
| 54 |
+
data = np.fromfile(file, endian + "f")
|
| 55 |
+
shape = (height, width, 3) if color else (height, width)
|
| 56 |
+
|
| 57 |
+
data = np.reshape(data, shape)
|
| 58 |
+
data = np.flipud(data)
|
| 59 |
+
|
| 60 |
+
return data, scale
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def write_pfm(path, image, scale=1):
|
| 64 |
+
"""Write pfm file.
|
| 65 |
+
|
| 66 |
+
Args:
|
| 67 |
+
path (str): pathto file
|
| 68 |
+
image (array): data
|
| 69 |
+
scale (int, optional): Scale. Defaults to 1.
|
| 70 |
+
"""
|
| 71 |
+
|
| 72 |
+
with open(path, "wb") as file:
|
| 73 |
+
color = None
|
| 74 |
+
|
| 75 |
+
if image.dtype.name != "float32":
|
| 76 |
+
raise Exception("Image dtype must be float32.")
|
| 77 |
+
|
| 78 |
+
image = np.flipud(image)
|
| 79 |
+
|
| 80 |
+
if len(image.shape) == 3 and image.shape[2] == 3: # color image
|
| 81 |
+
color = True
|
| 82 |
+
elif (
|
| 83 |
+
len(image.shape) == 2 or len(image.shape) == 3 and image.shape[2] == 1
|
| 84 |
+
): # greyscale
|
| 85 |
+
color = False
|
| 86 |
+
else:
|
| 87 |
+
raise Exception("Image must have H x W x 3, H x W x 1 or H x W dimensions.")
|
| 88 |
+
|
| 89 |
+
file.write("PF\n" if color else "Pf\n".encode())
|
| 90 |
+
file.write("%d %d\n".encode() % (image.shape[1], image.shape[0]))
|
| 91 |
+
|
| 92 |
+
endian = image.dtype.byteorder
|
| 93 |
+
|
| 94 |
+
if endian == "<" or endian == "=" and sys.byteorder == "little":
|
| 95 |
+
scale = -scale
|
| 96 |
+
|
| 97 |
+
file.write("%f\n".encode() % scale)
|
| 98 |
+
|
| 99 |
+
image.tofile(file)
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def read_image(path):
|
| 103 |
+
"""Read image and output RGB image (0-1).
|
| 104 |
+
|
| 105 |
+
Args:
|
| 106 |
+
path (str): path to file
|
| 107 |
+
|
| 108 |
+
Returns:
|
| 109 |
+
array: RGB image (0-1)
|
| 110 |
+
"""
|
| 111 |
+
img = cv2.imread(path)
|
| 112 |
+
|
| 113 |
+
if img.ndim == 2:
|
| 114 |
+
img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
|
| 115 |
+
|
| 116 |
+
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) / 255.0
|
| 117 |
+
|
| 118 |
+
return img
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def resize_image(img):
|
| 122 |
+
"""Resize image and make it fit for network.
|
| 123 |
+
|
| 124 |
+
Args:
|
| 125 |
+
img (array): image
|
| 126 |
+
|
| 127 |
+
Returns:
|
| 128 |
+
tensor: data ready for network
|
| 129 |
+
"""
|
| 130 |
+
height_orig = img.shape[0]
|
| 131 |
+
width_orig = img.shape[1]
|
| 132 |
+
|
| 133 |
+
if width_orig > height_orig:
|
| 134 |
+
scale = width_orig / 384
|
| 135 |
+
else:
|
| 136 |
+
scale = height_orig / 384
|
| 137 |
+
|
| 138 |
+
height = (np.ceil(height_orig / scale / 32) * 32).astype(int)
|
| 139 |
+
width = (np.ceil(width_orig / scale / 32) * 32).astype(int)
|
| 140 |
+
|
| 141 |
+
img_resized = cv2.resize(img, (width, height), interpolation=cv2.INTER_AREA)
|
| 142 |
+
|
| 143 |
+
img_resized = (
|
| 144 |
+
torch.from_numpy(np.transpose(img_resized, (2, 0, 1))).contiguous().float()
|
| 145 |
+
)
|
| 146 |
+
img_resized = img_resized.unsqueeze(0)
|
| 147 |
+
|
| 148 |
+
return img_resized
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
def resize_depth(depth, width, height):
|
| 152 |
+
"""Resize depth map and bring to CPU (numpy).
|
| 153 |
+
|
| 154 |
+
Args:
|
| 155 |
+
depth (tensor): depth
|
| 156 |
+
width (int): image width
|
| 157 |
+
height (int): image height
|
| 158 |
+
|
| 159 |
+
Returns:
|
| 160 |
+
array: processed depth
|
| 161 |
+
"""
|
| 162 |
+
depth = torch.squeeze(depth[0, :, :, :]).to("cpu")
|
| 163 |
+
|
| 164 |
+
depth_resized = cv2.resize(
|
| 165 |
+
depth.numpy(), (width, height), interpolation=cv2.INTER_CUBIC
|
| 166 |
+
)
|
| 167 |
+
|
| 168 |
+
return depth_resized
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
def write_depth(path, depth, bits=1, absolute_depth=False):
|
| 172 |
+
"""Write depth map to pfm and png file.
|
| 173 |
+
|
| 174 |
+
Args:
|
| 175 |
+
path (str): filepath without extension
|
| 176 |
+
depth (array): depth
|
| 177 |
+
"""
|
| 178 |
+
write_pfm(path + ".pfm", depth.astype(np.float32))
|
| 179 |
+
|
| 180 |
+
if absolute_depth:
|
| 181 |
+
out = depth
|
| 182 |
+
else:
|
| 183 |
+
depth_min = depth.min()
|
| 184 |
+
depth_max = depth.max()
|
| 185 |
+
|
| 186 |
+
max_val = (2 ** (8 * bits)) - 1
|
| 187 |
+
|
| 188 |
+
if depth_max - depth_min > np.finfo("float").eps:
|
| 189 |
+
out = max_val * (depth - depth_min) / (depth_max - depth_min)
|
| 190 |
+
else:
|
| 191 |
+
out = np.zeros(depth.shape, dtype=depth.dtype)
|
| 192 |
+
|
| 193 |
+
if bits == 1:
|
| 194 |
+
cv2.imwrite(path + ".png", out.astype("uint8"), [cv2.IMWRITE_PNG_COMPRESSION, 0])
|
| 195 |
+
elif bits == 2:
|
| 196 |
+
cv2.imwrite(path + ".png", out.astype("uint16"), [cv2.IMWRITE_PNG_COMPRESSION, 0])
|
| 197 |
+
|
| 198 |
+
return
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
def write_segm_img(path, image, labels, palette="detail", alpha=0.5):
|
| 202 |
+
"""Write depth map to pfm and png file.
|
| 203 |
+
|
| 204 |
+
Args:
|
| 205 |
+
path (str): filepath without extension
|
| 206 |
+
image (array): input image
|
| 207 |
+
labels (array): labeling of the image
|
| 208 |
+
"""
|
| 209 |
+
|
| 210 |
+
mask = get_mask_pallete(labels, "ade20k")
|
| 211 |
+
|
| 212 |
+
img = Image.fromarray(np.uint8(255*image)).convert("RGBA")
|
| 213 |
+
seg = mask.convert("RGBA")
|
| 214 |
+
|
| 215 |
+
out = Image.blend(img, seg, alpha)
|
| 216 |
+
|
| 217 |
+
out.save(path + ".png")
|
| 218 |
+
|
| 219 |
+
return
|
DPT/util/misc.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import matplotlib.pyplot as plt
|
| 2 |
+
|
| 3 |
+
from dpt.vit import get_mean_attention_map
|
| 4 |
+
|
| 5 |
+
def visualize_attention(input, model, prediction, model_type):
|
| 6 |
+
input = (input + 1.0)/2.0
|
| 7 |
+
|
| 8 |
+
attn1 = model.pretrained.attention["attn_1"]
|
| 9 |
+
attn2 = model.pretrained.attention["attn_2"]
|
| 10 |
+
attn3 = model.pretrained.attention["attn_3"]
|
| 11 |
+
attn4 = model.pretrained.attention["attn_4"]
|
| 12 |
+
|
| 13 |
+
plt.subplot(3,4,1), plt.imshow(input.squeeze().permute(1,2,0)), plt.title("Input", fontsize=8), plt.axis("off")
|
| 14 |
+
plt.subplot(3,4,2), plt.imshow(prediction), plt.set_cmap("inferno"), plt.title("Prediction", fontsize=8), plt.axis("off")
|
| 15 |
+
|
| 16 |
+
if model_type == "dpt_hybrid":
|
| 17 |
+
h = [3,6,9,12]
|
| 18 |
+
else:
|
| 19 |
+
h = [6,12,18,24]
|
| 20 |
+
|
| 21 |
+
# upper left
|
| 22 |
+
plt.subplot(345),
|
| 23 |
+
ax1 = plt.imshow(get_mean_attention_map(attn1, 1, input.shape))
|
| 24 |
+
plt.ylabel("Upper left corner", fontsize=8)
|
| 25 |
+
plt.title(f"Layer {h[0]}", fontsize=8)
|
| 26 |
+
gc = plt.gca()
|
| 27 |
+
gc.axes.xaxis.set_ticklabels([])
|
| 28 |
+
gc.axes.yaxis.set_ticklabels([])
|
| 29 |
+
gc.axes.xaxis.set_ticks([])
|
| 30 |
+
gc.axes.yaxis.set_ticks([])
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
plt.subplot(346),
|
| 34 |
+
plt.imshow(get_mean_attention_map(attn2, 1, input.shape))
|
| 35 |
+
plt.title(f"Layer {h[1]}", fontsize=8)
|
| 36 |
+
plt.axis("off"),
|
| 37 |
+
|
| 38 |
+
plt.subplot(347),
|
| 39 |
+
plt.imshow(get_mean_attention_map(attn3, 1, input.shape))
|
| 40 |
+
plt.title(f"Layer {h[2]}", fontsize=8)
|
| 41 |
+
plt.axis("off"),
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
plt.subplot(348),
|
| 45 |
+
plt.imshow(get_mean_attention_map(attn4, 1, input.shape))
|
| 46 |
+
plt.title(f"Layer {h[3]}", fontsize=8)
|
| 47 |
+
plt.axis("off"),
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
# lower right
|
| 51 |
+
plt.subplot(3,4,9), plt.imshow(get_mean_attention_map(attn1, -1, input.shape))
|
| 52 |
+
plt.ylabel("Lower right corner", fontsize=8)
|
| 53 |
+
gc = plt.gca()
|
| 54 |
+
gc.axes.xaxis.set_ticklabels([])
|
| 55 |
+
gc.axes.yaxis.set_ticklabels([])
|
| 56 |
+
gc.axes.xaxis.set_ticks([])
|
| 57 |
+
gc.axes.yaxis.set_ticks([])
|
| 58 |
+
|
| 59 |
+
plt.subplot(3,4,10), plt.imshow(get_mean_attention_map(attn2, -1, input.shape)), plt.axis("off")
|
| 60 |
+
plt.subplot(3,4,11), plt.imshow(get_mean_attention_map(attn3, -1, input.shape)), plt.axis("off")
|
| 61 |
+
plt.subplot(3,4,12), plt.imshow(get_mean_attention_map(attn4, -1, input.shape)), plt.axis("off")
|
| 62 |
+
plt.tight_layout()
|
| 63 |
+
plt.show()
|
DPT/util/pallete.py
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
##+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
|
| 2 |
+
## Created by: Hang Zhang
|
| 3 |
+
## ECE Department, Rutgers University
|
| 4 |
+
## Email: zhang.hang@rutgers.edu
|
| 5 |
+
## Copyright (c) 2017
|
| 6 |
+
##
|
| 7 |
+
## This source code is licensed under the MIT-style license found in the
|
| 8 |
+
## LICENSE file in the root directory of this source tree
|
| 9 |
+
##+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
|
| 10 |
+
|
| 11 |
+
from PIL import Image
|
| 12 |
+
|
| 13 |
+
def get_mask_pallete(npimg, dataset='detail'):
|
| 14 |
+
"""Get image color pallete for visualizing masks"""
|
| 15 |
+
# recovery boundary
|
| 16 |
+
if dataset == 'pascal_voc':
|
| 17 |
+
npimg[npimg==21] = 255
|
| 18 |
+
# put colormap
|
| 19 |
+
out_img = Image.fromarray(npimg.squeeze().astype('uint8'))
|
| 20 |
+
if dataset == 'ade20k':
|
| 21 |
+
out_img.putpalette(adepallete)
|
| 22 |
+
elif dataset == 'citys':
|
| 23 |
+
out_img.putpalette(citypallete)
|
| 24 |
+
elif dataset in ('detail', 'pascal_voc', 'pascal_aug'):
|
| 25 |
+
out_img.putpalette(vocpallete)
|
| 26 |
+
return out_img
|
| 27 |
+
|
| 28 |
+
def _get_voc_pallete(num_cls):
|
| 29 |
+
n = num_cls
|
| 30 |
+
pallete = [0]*(n*3)
|
| 31 |
+
for j in range(0,n):
|
| 32 |
+
lab = j
|
| 33 |
+
pallete[j*3+0] = 0
|
| 34 |
+
pallete[j*3+1] = 0
|
| 35 |
+
pallete[j*3+2] = 0
|
| 36 |
+
i = 0
|
| 37 |
+
while (lab > 0):
|
| 38 |
+
pallete[j*3+0] |= (((lab >> 0) & 1) << (7-i))
|
| 39 |
+
pallete[j*3+1] |= (((lab >> 1) & 1) << (7-i))
|
| 40 |
+
pallete[j*3+2] |= (((lab >> 2) & 1) << (7-i))
|
| 41 |
+
i = i + 1
|
| 42 |
+
lab >>= 3
|
| 43 |
+
return pallete
|
| 44 |
+
|
| 45 |
+
vocpallete = _get_voc_pallete(256)
|
| 46 |
+
|
| 47 |
+
adepallete = [0,0,0,120,120,120,180,120,120,6,230,230,80,50,50,4,200,3,120,120,80,140,140,140,204,5,255,230,230,230,4,250,7,224,5,255,235,255,7,150,5,61,120,120,70,8,255,51,255,6,82,143,255,140,204,255,4,255,51,7,204,70,3,0,102,200,61,230,250,255,6,51,11,102,255,255,7,71,255,9,224,9,7,230,220,220,220,255,9,92,112,9,255,8,255,214,7,255,224,255,184,6,10,255,71,255,41,10,7,255,255,224,255,8,102,8,255,255,61,6,255,194,7,255,122,8,0,255,20,255,8,41,255,5,153,6,51,255,235,12,255,160,150,20,0,163,255,140,140,140,250,10,15,20,255,0,31,255,0,255,31,0,255,224,0,153,255,0,0,0,255,255,71,0,0,235,255,0,173,255,31,0,255,11,200,200,255,82,0,0,255,245,0,61,255,0,255,112,0,255,133,255,0,0,255,163,0,255,102,0,194,255,0,0,143,255,51,255,0,0,82,255,0,255,41,0,255,173,10,0,255,173,255,0,0,255,153,255,92,0,255,0,255,255,0,245,255,0,102,255,173,0,255,0,20,255,184,184,0,31,255,0,255,61,0,71,255,255,0,204,0,255,194,0,255,82,0,10,255,0,112,255,51,0,255,0,194,255,0,122,255,0,255,163,255,153,0,0,255,10,255,112,0,143,255,0,82,0,255,163,255,0,255,235,0,8,184,170,133,0,255,0,255,92,184,0,255,255,0,31,0,184,255,0,214,255,255,0,112,92,255,0,0,224,255,112,224,255,70,184,160,163,0,255,153,0,255,71,255,0,255,0,163,255,204,0,255,0,143,0,255,235,133,255,0,255,0,235,245,0,255,255,0,122,255,245,0,10,190,212,214,255,0,0,204,255,20,0,255,255,255,0,0,153,255,0,41,255,0,255,204,41,0,255,41,255,0,173,0,255,0,245,255,71,0,255,122,0,255,0,255,184,0,92,255,184,255,0,0,133,255,255,214,0,25,194,194,102,255,0,92,0,255]
|
| 48 |
+
|
| 49 |
+
citypallete = [
|
| 50 |
+
128,64,128,244,35,232,70,70,70,102,102,156,190,153,153,153,153,153,250,170,30,220,220,0,107,142,35,152,251,152,70,130,180,220,20,60,255,0,0,0,0,142,0,0,70,0,60,100,0,80,100,0,0,230,119,11,32,128,192,0,0,64,128,128,64,128,0,192,128,128,192,128,64,64,0,192,64,0,64,192,0,192,192,0,64,64,128,192,64,128,64,192,128,192,192,128,0,0,64,128,0,64,0,128,64,128,128,64,0,0,192,128,0,192,0,128,192,128,128,192,64,0,64,192,0,64,64,128,64,192,128,64,64,0,192,192,0,192,64,128,192,192,128,192,0,64,64,128,64,64,0,192,64,128,192,64,0,64,192,128,64,192,0,192,192,128,192,192,64,64,64,192,64,64,64,192,64,192,192,64,64,64,192,192,64,192,64,192,192,192,192,192,32,0,0,160,0,0,32,128,0,160,128,0,32,0,128,160,0,128,32,128,128,160,128,128,96,0,0,224,0,0,96,128,0,224,128,0,96,0,128,224,0,128,96,128,128,224,128,128,32,64,0,160,64,0,32,192,0,160,192,0,32,64,128,160,64,128,32,192,128,160,192,128,96,64,0,224,64,0,96,192,0,224,192,0,96,64,128,224,64,128,96,192,128,224,192,128,32,0,64,160,0,64,32,128,64,160,128,64,32,0,192,160,0,192,32,128,192,160,128,192,96,0,64,224,0,64,96,128,64,224,128,64,96,0,192,224,0,192,96,128,192,224,128,192,32,64,64,160,64,64,32,192,64,160,192,64,32,64,192,160,64,192,32,192,192,160,192,192,96,64,64,224,64,64,96,192,64,224,192,64,96,64,192,224,64,192,96,192,192,224,192,192,0,32,0,128,32,0,0,160,0,128,160,0,0,32,128,128,32,128,0,160,128,128,160,128,64,32,0,192,32,0,64,160,0,192,160,0,64,32,128,192,32,128,64,160,128,192,160,128,0,96,0,128,96,0,0,224,0,128,224,0,0,96,128,128,96,128,0,224,128,128,224,128,64,96,0,192,96,0,64,224,0,192,224,0,64,96,128,192,96,128,64,224,128,192,224,128,0,32,64,128,32,64,0,160,64,128,160,64,0,32,192,128,32,192,0,160,192,128,160,192,64,32,64,192,32,64,64,160,64,192,160,64,64,32,192,192,32,192,64,160,192,192,160,192,0,96,64,128,96,64,0,224,64,128,224,64,0,96,192,128,96,192,0,224,192,128,224,192,64,96,64,192,96,64,64,224,64,192,224,64,64,96,192,192,96,192,64,224,192,192,224,192,32,32,0,160,32,0,32,160,0,160,160,0,32,32,128,160,32,128,32,160,128,160,160,128,96,32,0,224,32,0,96,160,0,224,160,0,96,32,128,224,32,128,96,160,128,224,160,128,32,96,0,160,96,0,32,224,0,160,224,0,32,96,128,160,96,128,32,224,128,160,224,128,96,96,0,224,96,0,96,224,0,224,224,0,96,96,128,224,96,128,96,224,128,224,224,128,32,32,64,160,32,64,32,160,64,160,160,64,32,32,192,160,32,192,32,160,192,160,160,192,96,32,64,224,32,64,96,160,64,224,160,64,96,32,192,224,32,192,96,160,192,224,160,192,32,96,64,160,96,64,32,224,64,160,224,64,32,96,192,160,96,192,32,224,192,160,224,192,96,96,64,224,96,64,96,224,64,224,224,64,96,96,192,224,96,192,96,224,192,0,0,0]
|
DPT/weights/.placeholder
ADDED
|
File without changes
|
demo.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
demo_assets/depths/pumpkin.png
ADDED

|
Git LFS Details
|
demo_assets/input_imgs/pumpkin.png
ADDED

|
Git LFS Details
|
demo_assets/material_exemplars/cup_glaze.png
ADDED

|
Git LFS Details
|
demo_gradio.py
ADDED
|
@@ -0,0 +1,170 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
from diffusers import StableDiffusionXLControlNetInpaintPipeline, ControlNetModel
|
| 3 |
+
from rembg import remove
|
| 4 |
+
from PIL import Image
|
| 5 |
+
import torch
|
| 6 |
+
from ip_adapter import IPAdapterXL
|
| 7 |
+
from ip_adapter.utils import register_cross_attention_hook, get_net_attn_map, attnmaps2images
|
| 8 |
+
from PIL import Image, ImageChops, ImageEnhance
|
| 9 |
+
import numpy as np
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
import glob
|
| 13 |
+
import torch
|
| 14 |
+
import cv2
|
| 15 |
+
import argparse
|
| 16 |
+
|
| 17 |
+
import DPT.util.io
|
| 18 |
+
|
| 19 |
+
from torchvision.transforms import Compose
|
| 20 |
+
|
| 21 |
+
from DPT.dpt.models import DPTDepthModel
|
| 22 |
+
from DPT.dpt.midas_net import MidasNet_large
|
| 23 |
+
from DPT.dpt.transforms import Resize, NormalizeImage, PrepareForNet
|
| 24 |
+
|
| 25 |
+
"""
|
| 26 |
+
Get ZeST Ready
|
| 27 |
+
"""
|
| 28 |
+
base_model_path = "stabilityai/stable-diffusion-xl-base-1.0"
|
| 29 |
+
image_encoder_path = "models/image_encoder"
|
| 30 |
+
ip_ckpt = "sdxl_models/ip-adapter_sdxl_vit-h.bin"
|
| 31 |
+
controlnet_path = "diffusers/controlnet-depth-sdxl-1.0"
|
| 32 |
+
device = "cuda"
|
| 33 |
+
torch.cuda.empty_cache()
|
| 34 |
+
|
| 35 |
+
# load SDXL pipeline
|
| 36 |
+
controlnet = ControlNetModel.from_pretrained(controlnet_path, variant="fp16", use_safetensors=True, torch_dtype=torch.float16).to(device)
|
| 37 |
+
pipe = StableDiffusionXLControlNetInpaintPipeline.from_pretrained(
|
| 38 |
+
base_model_path,
|
| 39 |
+
controlnet=controlnet,
|
| 40 |
+
use_safetensors=True,
|
| 41 |
+
torch_dtype=torch.float16,
|
| 42 |
+
add_watermarker=False,
|
| 43 |
+
).to(device)
|
| 44 |
+
pipe.unet = register_cross_attention_hook(pipe.unet)
|
| 45 |
+
|
| 46 |
+
ip_model = IPAdapterXL(pipe, image_encoder_path, ip_ckpt, device)
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
"""
|
| 50 |
+
Get Depth Model Ready
|
| 51 |
+
"""
|
| 52 |
+
model_path = "DPT/weights/dpt_hybrid-midas-501f0c75.pt"
|
| 53 |
+
net_w = net_h = 384
|
| 54 |
+
model = DPTDepthModel(
|
| 55 |
+
path=model_path,
|
| 56 |
+
backbone="vitb_rn50_384",
|
| 57 |
+
non_negative=True,
|
| 58 |
+
enable_attention_hooks=False,
|
| 59 |
+
)
|
| 60 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 61 |
+
|
| 62 |
+
transform = Compose(
|
| 63 |
+
[
|
| 64 |
+
Resize(
|
| 65 |
+
net_w,
|
| 66 |
+
net_h,
|
| 67 |
+
resize_target=None,
|
| 68 |
+
keep_aspect_ratio=True,
|
| 69 |
+
ensure_multiple_of=32,
|
| 70 |
+
resize_method="minimal",
|
| 71 |
+
image_interpolation_method=cv2.INTER_CUBIC,
|
| 72 |
+
),
|
| 73 |
+
normalization,
|
| 74 |
+
PrepareForNet(),
|
| 75 |
+
]
|
| 76 |
+
)
|
| 77 |
+
|
| 78 |
+
model.eval()
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def greet(input_image, material_exemplar):
|
| 82 |
+
|
| 83 |
+
"""
|
| 84 |
+
Compute depth map from input_image
|
| 85 |
+
"""
|
| 86 |
+
|
| 87 |
+
img = np.array(input_image)
|
| 88 |
+
|
| 89 |
+
img_input = transform({"image": img})["image"]
|
| 90 |
+
|
| 91 |
+
# compute
|
| 92 |
+
with torch.no_grad():
|
| 93 |
+
sample = torch.from_numpy(img_input).unsqueeze(0)
|
| 94 |
+
|
| 95 |
+
# if optimize == True and device == torch.device("cuda"):
|
| 96 |
+
# sample = sample.to(memory_format=torch.channels_last)
|
| 97 |
+
# sample = sample.half()
|
| 98 |
+
|
| 99 |
+
prediction = model.forward(sample)
|
| 100 |
+
prediction = (
|
| 101 |
+
torch.nn.functional.interpolate(
|
| 102 |
+
prediction.unsqueeze(1),
|
| 103 |
+
size=img.shape[:2],
|
| 104 |
+
mode="bicubic",
|
| 105 |
+
align_corners=False,
|
| 106 |
+
)
|
| 107 |
+
.squeeze()
|
| 108 |
+
.cpu()
|
| 109 |
+
.numpy()
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
depth_min = prediction.min()
|
| 113 |
+
depth_max = prediction.max()
|
| 114 |
+
bits = 2
|
| 115 |
+
max_val = (2 ** (8 * bits)) - 1
|
| 116 |
+
|
| 117 |
+
if depth_max - depth_min > np.finfo("float").eps:
|
| 118 |
+
out = max_val * (prediction - depth_min) / (depth_max - depth_min)
|
| 119 |
+
else:
|
| 120 |
+
out = np.zeros(prediction.shape, dtype=depth.dtype)
|
| 121 |
+
|
| 122 |
+
out = (out / 256).astype('uint8')
|
| 123 |
+
depth_map = Image.fromarray(out).resize((1024, 1024))
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
"""
|
| 127 |
+
Process foreground decolored image
|
| 128 |
+
"""
|
| 129 |
+
rm_bg = remove(input_image)
|
| 130 |
+
target_mask = rm_bg.convert("RGB").point(lambda x: 0 if x < 1 else 255).convert('L').convert('RGB')
|
| 131 |
+
mask_target_img = ImageChops.lighter(input_image, target_mask)
|
| 132 |
+
invert_target_mask = ImageChops.invert(target_mask)
|
| 133 |
+
gray_target_image = input_image.convert('L').convert('RGB')
|
| 134 |
+
gray_target_image = ImageEnhance.Brightness(gray_target_image)
|
| 135 |
+
factor = 1.0 # Try adjusting this to get the desired brightness
|
| 136 |
+
gray_target_image = gray_target_image.enhance(factor)
|
| 137 |
+
grayscale_img = ImageChops.darker(gray_target_image, target_mask)
|
| 138 |
+
img_black_mask = ImageChops.darker(input_image, invert_target_mask)
|
| 139 |
+
grayscale_init_img = ImageChops.lighter(img_black_mask, grayscale_img)
|
| 140 |
+
init_img = grayscale_init_img
|
| 141 |
+
|
| 142 |
+
"""
|
| 143 |
+
Process material exemplar and resize all images
|
| 144 |
+
"""
|
| 145 |
+
ip_image = material_exemplar.resize((1024, 1024))
|
| 146 |
+
init_img = init_img.resize((1024,1024))
|
| 147 |
+
mask = target_mask.resize((1024, 1024))
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
num_samples = 1
|
| 151 |
+
images = ip_model.generate(pil_image=ip_image, image=init_img, control_image=depth_map, mask_image=mask, controlnet_conditioning_scale=0.9, num_samples=num_samples, num_inference_steps=30, seed=42)
|
| 152 |
+
|
| 153 |
+
return images[0]
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
input_image = gr.Image(type="pil")
|
| 158 |
+
input_image2 = gr.Image(type="pil")
|
| 159 |
+
|
| 160 |
+
demo = gr.Interface(
|
| 161 |
+
fn=greet,
|
| 162 |
+
inputs=[input_image, input_image2],
|
| 163 |
+
title="ZeST: Zero-Shot Material Transfer from a Single Image",
|
| 164 |
+
description="Upload two images -- input image and material exemplar. ZeST extracts the material from the exemplar and cast it onto the input image following the original lighting cues.",
|
| 165 |
+
outputs=["image"],
|
| 166 |
+
allow_flagging='never'
|
| 167 |
+
|
| 168 |
+
)
|
| 169 |
+
|
| 170 |
+
demo.launch()
|
fig/gradio_demo.png
ADDED

|
Git LFS Details
|
fig/method.jpg
ADDED
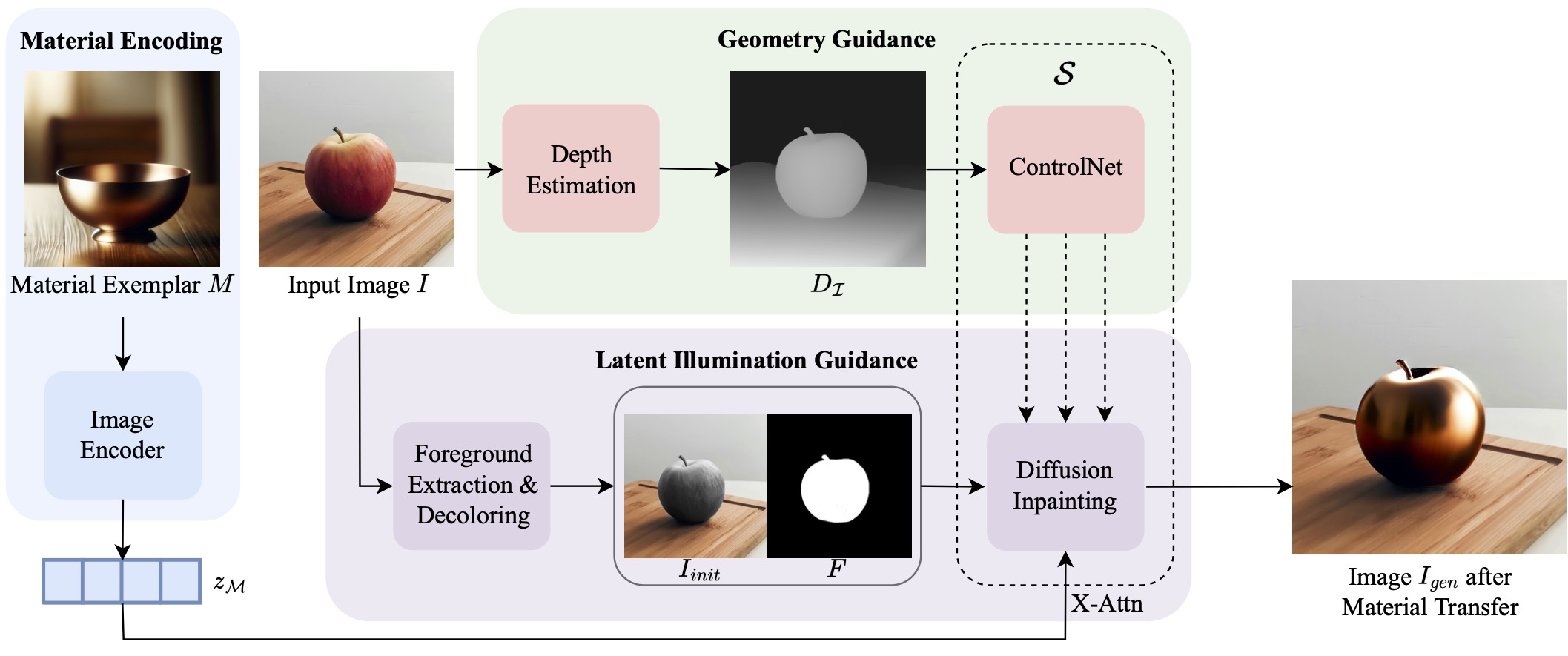
|
ip_adapter/__init__.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .ip_adapter import IPAdapter, IPAdapterPlus, IPAdapterPlusXL, IPAdapterXL, IPAdapterFull
|
| 2 |
+
|
| 3 |
+
__all__ = [
|
| 4 |
+
"IPAdapter",
|
| 5 |
+
"IPAdapterPlus",
|
| 6 |
+
"IPAdapterPlusXL",
|
| 7 |
+
"IPAdapterXL",
|
| 8 |
+
"IPAdapterFull",
|
| 9 |
+
]
|
ip_adapter/attention_processor.py
ADDED
|
@@ -0,0 +1,568 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class AttnProcessor(nn.Module):
|
| 8 |
+
r"""
|
| 9 |
+
Default processor for performing attention-related computations.
|
| 10 |
+
"""
|
| 11 |
+
|
| 12 |
+
def __init__(
|
| 13 |
+
self,
|
| 14 |
+
hidden_size=None,
|
| 15 |
+
cross_attention_dim=None,
|
| 16 |
+
):
|
| 17 |
+
super().__init__()
|
| 18 |
+
|
| 19 |
+
def __call__(
|
| 20 |
+
self,
|
| 21 |
+
attn,
|
| 22 |
+
hidden_states,
|
| 23 |
+
encoder_hidden_states=None,
|
| 24 |
+
attention_mask=None,
|
| 25 |
+
temb=None,
|
| 26 |
+
*args,
|
| 27 |
+
**kwargs,
|
| 28 |
+
):
|
| 29 |
+
residual = hidden_states
|
| 30 |
+
|
| 31 |
+
if attn.spatial_norm is not None:
|
| 32 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 33 |
+
|
| 34 |
+
input_ndim = hidden_states.ndim
|
| 35 |
+
|
| 36 |
+
if input_ndim == 4:
|
| 37 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 38 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 39 |
+
|
| 40 |
+
batch_size, sequence_length, _ = (
|
| 41 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 42 |
+
)
|
| 43 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 44 |
+
|
| 45 |
+
if attn.group_norm is not None:
|
| 46 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 47 |
+
|
| 48 |
+
query = attn.to_q(hidden_states)
|
| 49 |
+
|
| 50 |
+
if encoder_hidden_states is None:
|
| 51 |
+
encoder_hidden_states = hidden_states
|
| 52 |
+
elif attn.norm_cross:
|
| 53 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 54 |
+
|
| 55 |
+
key = attn.to_k(encoder_hidden_states)
|
| 56 |
+
value = attn.to_v(encoder_hidden_states)
|
| 57 |
+
|
| 58 |
+
query = attn.head_to_batch_dim(query)
|
| 59 |
+
key = attn.head_to_batch_dim(key)
|
| 60 |
+
value = attn.head_to_batch_dim(value)
|
| 61 |
+
|
| 62 |
+
attention_probs = attn.get_attention_scores(query, key, attention_mask)
|
| 63 |
+
hidden_states = torch.bmm(attention_probs, value)
|
| 64 |
+
hidden_states = attn.batch_to_head_dim(hidden_states)
|
| 65 |
+
|
| 66 |
+
# linear proj
|
| 67 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 68 |
+
# dropout
|
| 69 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 70 |
+
|
| 71 |
+
if input_ndim == 4:
|
| 72 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 73 |
+
|
| 74 |
+
if attn.residual_connection:
|
| 75 |
+
hidden_states = hidden_states + residual
|
| 76 |
+
|
| 77 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 78 |
+
|
| 79 |
+
return hidden_states
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
class IPAttnProcessor(nn.Module):
|
| 83 |
+
r"""
|
| 84 |
+
Attention processor for IP-Adapater.
|
| 85 |
+
Args:
|
| 86 |
+
hidden_size (`int`):
|
| 87 |
+
The hidden size of the attention layer.
|
| 88 |
+
cross_attention_dim (`int`):
|
| 89 |
+
The number of channels in the `encoder_hidden_states`.
|
| 90 |
+
scale (`float`, defaults to 1.0):
|
| 91 |
+
the weight scale of image prompt.
|
| 92 |
+
num_tokens (`int`, defaults to 4 when do ip_adapter_plus it should be 16):
|
| 93 |
+
The context length of the image features.
|
| 94 |
+
"""
|
| 95 |
+
|
| 96 |
+
def __init__(self, hidden_size, cross_attention_dim=None, scale=1.0, num_tokens=4):
|
| 97 |
+
super().__init__()
|
| 98 |
+
|
| 99 |
+
self.hidden_size = hidden_size
|
| 100 |
+
self.cross_attention_dim = cross_attention_dim
|
| 101 |
+
self.scale = scale
|
| 102 |
+
self.num_tokens = num_tokens
|
| 103 |
+
|
| 104 |
+
self.to_k_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
| 105 |
+
self.to_v_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
| 106 |
+
|
| 107 |
+
def __call__(
|
| 108 |
+
self,
|
| 109 |
+
attn,
|
| 110 |
+
hidden_states,
|
| 111 |
+
encoder_hidden_states=None,
|
| 112 |
+
attention_mask=None,
|
| 113 |
+
temb=None,
|
| 114 |
+
*args,
|
| 115 |
+
**kwargs,
|
| 116 |
+
):
|
| 117 |
+
residual = hidden_states
|
| 118 |
+
|
| 119 |
+
if attn.spatial_norm is not None:
|
| 120 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 121 |
+
|
| 122 |
+
input_ndim = hidden_states.ndim
|
| 123 |
+
|
| 124 |
+
if input_ndim == 4:
|
| 125 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 126 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 127 |
+
|
| 128 |
+
batch_size, sequence_length, _ = (
|
| 129 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 130 |
+
)
|
| 131 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 132 |
+
|
| 133 |
+
if attn.group_norm is not None:
|
| 134 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 135 |
+
|
| 136 |
+
query = attn.to_q(hidden_states)
|
| 137 |
+
|
| 138 |
+
if encoder_hidden_states is None:
|
| 139 |
+
encoder_hidden_states = hidden_states
|
| 140 |
+
else:
|
| 141 |
+
# get encoder_hidden_states, ip_hidden_states
|
| 142 |
+
end_pos = encoder_hidden_states.shape[1] - self.num_tokens
|
| 143 |
+
encoder_hidden_states, ip_hidden_states = (
|
| 144 |
+
encoder_hidden_states[:, :end_pos, :],
|
| 145 |
+
encoder_hidden_states[:, end_pos:, :],
|
| 146 |
+
)
|
| 147 |
+
if attn.norm_cross:
|
| 148 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 149 |
+
|
| 150 |
+
key = attn.to_k(encoder_hidden_states)
|
| 151 |
+
value = attn.to_v(encoder_hidden_states)
|
| 152 |
+
|
| 153 |
+
query = attn.head_to_batch_dim(query)
|
| 154 |
+
key = attn.head_to_batch_dim(key)
|
| 155 |
+
value = attn.head_to_batch_dim(value)
|
| 156 |
+
|
| 157 |
+
attention_probs = attn.get_attention_scores(query, key, attention_mask)
|
| 158 |
+
hidden_states = torch.bmm(attention_probs, value)
|
| 159 |
+
hidden_states = attn.batch_to_head_dim(hidden_states)
|
| 160 |
+
|
| 161 |
+
# for ip-adapter
|
| 162 |
+
ip_key = self.to_k_ip(ip_hidden_states)
|
| 163 |
+
ip_value = self.to_v_ip(ip_hidden_states)
|
| 164 |
+
|
| 165 |
+
ip_key = attn.head_to_batch_dim(ip_key)
|
| 166 |
+
ip_value = attn.head_to_batch_dim(ip_value)
|
| 167 |
+
|
| 168 |
+
ip_attention_probs = attn.get_attention_scores(query, ip_key, None)
|
| 169 |
+
self.attn_map = ip_attention_probs
|
| 170 |
+
ip_hidden_states = torch.bmm(ip_attention_probs, ip_value)
|
| 171 |
+
ip_hidden_states = attn.batch_to_head_dim(ip_hidden_states)
|
| 172 |
+
|
| 173 |
+
hidden_states = hidden_states + self.scale * ip_hidden_states
|
| 174 |
+
|
| 175 |
+
# linear proj
|
| 176 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 177 |
+
# dropout
|
| 178 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 179 |
+
|
| 180 |
+
if input_ndim == 4:
|
| 181 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 182 |
+
|
| 183 |
+
if attn.residual_connection:
|
| 184 |
+
hidden_states = hidden_states + residual
|
| 185 |
+
|
| 186 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 187 |
+
|
| 188 |
+
return hidden_states
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
class AttnProcessor2_0(torch.nn.Module):
|
| 192 |
+
r"""
|
| 193 |
+
Processor for implementing scaled dot-product attention (enabled by default if you're using PyTorch 2.0).
|
| 194 |
+
"""
|
| 195 |
+
|
| 196 |
+
def __init__(
|
| 197 |
+
self,
|
| 198 |
+
hidden_size=None,
|
| 199 |
+
cross_attention_dim=None,
|
| 200 |
+
):
|
| 201 |
+
super().__init__()
|
| 202 |
+
if not hasattr(F, "scaled_dot_product_attention"):
|
| 203 |
+
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
| 204 |
+
|
| 205 |
+
def __call__(
|
| 206 |
+
self,
|
| 207 |
+
attn,
|
| 208 |
+
hidden_states,
|
| 209 |
+
encoder_hidden_states=None,
|
| 210 |
+
attention_mask=None,
|
| 211 |
+
temb=None,
|
| 212 |
+
*args,
|
| 213 |
+
**kwargs,
|
| 214 |
+
):
|
| 215 |
+
residual = hidden_states
|
| 216 |
+
|
| 217 |
+
if attn.spatial_norm is not None:
|
| 218 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 219 |
+
|
| 220 |
+
input_ndim = hidden_states.ndim
|
| 221 |
+
|
| 222 |
+
if input_ndim == 4:
|
| 223 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 224 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 225 |
+
|
| 226 |
+
batch_size, sequence_length, _ = (
|
| 227 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 228 |
+
)
|
| 229 |
+
|
| 230 |
+
if attention_mask is not None:
|
| 231 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 232 |
+
# scaled_dot_product_attention expects attention_mask shape to be
|
| 233 |
+
# (batch, heads, source_length, target_length)
|
| 234 |
+
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
|
| 235 |
+
|
| 236 |
+
if attn.group_norm is not None:
|
| 237 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 238 |
+
|
| 239 |
+
query = attn.to_q(hidden_states)
|
| 240 |
+
|
| 241 |
+
if encoder_hidden_states is None:
|
| 242 |
+
encoder_hidden_states = hidden_states
|
| 243 |
+
elif attn.norm_cross:
|
| 244 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 245 |
+
|
| 246 |
+
key = attn.to_k(encoder_hidden_states)
|
| 247 |
+
value = attn.to_v(encoder_hidden_states)
|
| 248 |
+
|
| 249 |
+
inner_dim = key.shape[-1]
|
| 250 |
+
head_dim = inner_dim // attn.heads
|
| 251 |
+
|
| 252 |
+
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 253 |
+
|
| 254 |
+
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 255 |
+
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 256 |
+
|
| 257 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 258 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 259 |
+
hidden_states = F.scaled_dot_product_attention(
|
| 260 |
+
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
| 261 |
+
)
|
| 262 |
+
|
| 263 |
+
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
| 264 |
+
hidden_states = hidden_states.to(query.dtype)
|
| 265 |
+
|
| 266 |
+
# linear proj
|
| 267 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 268 |
+
# dropout
|
| 269 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 270 |
+
|
| 271 |
+
if input_ndim == 4:
|
| 272 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 273 |
+
|
| 274 |
+
if attn.residual_connection:
|
| 275 |
+
hidden_states = hidden_states + residual
|
| 276 |
+
|
| 277 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 278 |
+
|
| 279 |
+
return hidden_states
|
| 280 |
+
|
| 281 |
+
|
| 282 |
+
class IPAttnProcessor2_0(torch.nn.Module):
|
| 283 |
+
r"""
|
| 284 |
+
Attention processor for IP-Adapater for PyTorch 2.0.
|
| 285 |
+
Args:
|
| 286 |
+
hidden_size (`int`):
|
| 287 |
+
The hidden size of the attention layer.
|
| 288 |
+
cross_attention_dim (`int`):
|
| 289 |
+
The number of channels in the `encoder_hidden_states`.
|
| 290 |
+
scale (`float`, defaults to 1.0):
|
| 291 |
+
the weight scale of image prompt.
|
| 292 |
+
num_tokens (`int`, defaults to 4 when do ip_adapter_plus it should be 16):
|
| 293 |
+
The context length of the image features.
|
| 294 |
+
"""
|
| 295 |
+
|
| 296 |
+
def __init__(self, hidden_size, cross_attention_dim=None, scale=1.0, num_tokens=4):
|
| 297 |
+
super().__init__()
|
| 298 |
+
|
| 299 |
+
if not hasattr(F, "scaled_dot_product_attention"):
|
| 300 |
+
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
| 301 |
+
|
| 302 |
+
self.hidden_size = hidden_size
|
| 303 |
+
self.cross_attention_dim = cross_attention_dim
|
| 304 |
+
self.scale = scale
|
| 305 |
+
self.num_tokens = num_tokens
|
| 306 |
+
|
| 307 |
+
self.to_k_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
| 308 |
+
self.to_v_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
| 309 |
+
|
| 310 |
+
def __call__(
|
| 311 |
+
self,
|
| 312 |
+
attn,
|
| 313 |
+
hidden_states,
|
| 314 |
+
encoder_hidden_states=None,
|
| 315 |
+
attention_mask=None,
|
| 316 |
+
temb=None,
|
| 317 |
+
*args,
|
| 318 |
+
**kwargs,
|
| 319 |
+
):
|
| 320 |
+
residual = hidden_states
|
| 321 |
+
|
| 322 |
+
if attn.spatial_norm is not None:
|
| 323 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 324 |
+
|
| 325 |
+
input_ndim = hidden_states.ndim
|
| 326 |
+
|
| 327 |
+
if input_ndim == 4:
|
| 328 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 329 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 330 |
+
|
| 331 |
+
batch_size, sequence_length, _ = (
|
| 332 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 333 |
+
)
|
| 334 |
+
|
| 335 |
+
if attention_mask is not None:
|
| 336 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 337 |
+
# scaled_dot_product_attention expects attention_mask shape to be
|
| 338 |
+
# (batch, heads, source_length, target_length)
|
| 339 |
+
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
|
| 340 |
+
|
| 341 |
+
if attn.group_norm is not None:
|
| 342 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 343 |
+
|
| 344 |
+
query = attn.to_q(hidden_states)
|
| 345 |
+
|
| 346 |
+
if encoder_hidden_states is None:
|
| 347 |
+
encoder_hidden_states = hidden_states
|
| 348 |
+
else:
|
| 349 |
+
# get encoder_hidden_states, ip_hidden_states
|
| 350 |
+
end_pos = encoder_hidden_states.shape[1] - self.num_tokens
|
| 351 |
+
encoder_hidden_states, ip_hidden_states = (
|
| 352 |
+
encoder_hidden_states[:, :end_pos, :],
|
| 353 |
+
encoder_hidden_states[:, end_pos:, :],
|
| 354 |
+
)
|
| 355 |
+
if attn.norm_cross:
|
| 356 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 357 |
+
|
| 358 |
+
key = attn.to_k(encoder_hidden_states)
|
| 359 |
+
value = attn.to_v(encoder_hidden_states)
|
| 360 |
+
|
| 361 |
+
inner_dim = key.shape[-1]
|
| 362 |
+
head_dim = inner_dim // attn.heads
|
| 363 |
+
|
| 364 |
+
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 365 |
+
|
| 366 |
+
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 367 |
+
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 368 |
+
|
| 369 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 370 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 371 |
+
hidden_states = F.scaled_dot_product_attention(
|
| 372 |
+
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
| 373 |
+
)
|
| 374 |
+
|
| 375 |
+
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
| 376 |
+
hidden_states = hidden_states.to(query.dtype)
|
| 377 |
+
|
| 378 |
+
# for ip-adapter
|
| 379 |
+
ip_key = self.to_k_ip(ip_hidden_states)
|
| 380 |
+
ip_value = self.to_v_ip(ip_hidden_states)
|
| 381 |
+
|
| 382 |
+
ip_key = ip_key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 383 |
+
ip_value = ip_value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 384 |
+
|
| 385 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 386 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 387 |
+
ip_hidden_states = F.scaled_dot_product_attention(
|
| 388 |
+
query, ip_key, ip_value, attn_mask=None, dropout_p=0.0, is_causal=False
|
| 389 |
+
)
|
| 390 |
+
with torch.no_grad():
|
| 391 |
+
self.attn_map = query @ ip_key.transpose(-2, -1).softmax(dim=-1)
|
| 392 |
+
#print(self.attn_map.shape)
|
| 393 |
+
|
| 394 |
+
ip_hidden_states = ip_hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
| 395 |
+
ip_hidden_states = ip_hidden_states.to(query.dtype)
|
| 396 |
+
|
| 397 |
+
hidden_states = hidden_states + self.scale * ip_hidden_states
|
| 398 |
+
|
| 399 |
+
# linear proj
|
| 400 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 401 |
+
# dropout
|
| 402 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 403 |
+
|
| 404 |
+
if input_ndim == 4:
|
| 405 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 406 |
+
|
| 407 |
+
if attn.residual_connection:
|
| 408 |
+
hidden_states = hidden_states + residual
|
| 409 |
+
|
| 410 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 411 |
+
|
| 412 |
+
return hidden_states
|
| 413 |
+
|
| 414 |
+
|
| 415 |
+
## for controlnet
|
| 416 |
+
class CNAttnProcessor:
|
| 417 |
+
r"""
|
| 418 |
+
Default processor for performing attention-related computations.
|
| 419 |
+
"""
|
| 420 |
+
|
| 421 |
+
def __init__(self, num_tokens=4):
|
| 422 |
+
self.num_tokens = num_tokens
|
| 423 |
+
|
| 424 |
+
def __call__(self, attn, hidden_states, encoder_hidden_states=None, attention_mask=None, temb=None, *args, **kwargs,):
|
| 425 |
+
residual = hidden_states
|
| 426 |
+
|
| 427 |
+
if attn.spatial_norm is not None:
|
| 428 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 429 |
+
|
| 430 |
+
input_ndim = hidden_states.ndim
|
| 431 |
+
|
| 432 |
+
if input_ndim == 4:
|
| 433 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 434 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 435 |
+
|
| 436 |
+
batch_size, sequence_length, _ = (
|
| 437 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 438 |
+
)
|
| 439 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 440 |
+
|
| 441 |
+
if attn.group_norm is not None:
|
| 442 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 443 |
+
|
| 444 |
+
query = attn.to_q(hidden_states)
|
| 445 |
+
|
| 446 |
+
if encoder_hidden_states is None:
|
| 447 |
+
encoder_hidden_states = hidden_states
|
| 448 |
+
else:
|
| 449 |
+
end_pos = encoder_hidden_states.shape[1] - self.num_tokens
|
| 450 |
+
encoder_hidden_states = encoder_hidden_states[:, :end_pos] # only use text
|
| 451 |
+
if attn.norm_cross:
|
| 452 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 453 |
+
|
| 454 |
+
key = attn.to_k(encoder_hidden_states)
|
| 455 |
+
value = attn.to_v(encoder_hidden_states)
|
| 456 |
+
|
| 457 |
+
query = attn.head_to_batch_dim(query)
|
| 458 |
+
key = attn.head_to_batch_dim(key)
|
| 459 |
+
value = attn.head_to_batch_dim(value)
|
| 460 |
+
|
| 461 |
+
attention_probs = attn.get_attention_scores(query, key, attention_mask)
|
| 462 |
+
hidden_states = torch.bmm(attention_probs, value)
|
| 463 |
+
hidden_states = attn.batch_to_head_dim(hidden_states)
|
| 464 |
+
|
| 465 |
+
# linear proj
|
| 466 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 467 |
+
# dropout
|
| 468 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 469 |
+
|
| 470 |
+
if input_ndim == 4:
|
| 471 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 472 |
+
|
| 473 |
+
if attn.residual_connection:
|
| 474 |
+
hidden_states = hidden_states + residual
|
| 475 |
+
|
| 476 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 477 |
+
|
| 478 |
+
return hidden_states
|
| 479 |
+
|
| 480 |
+
|
| 481 |
+
class CNAttnProcessor2_0:
|
| 482 |
+
r"""
|
| 483 |
+
Processor for implementing scaled dot-product attention (enabled by default if you're using PyTorch 2.0).
|
| 484 |
+
"""
|
| 485 |
+
|
| 486 |
+
def __init__(self, num_tokens=4):
|
| 487 |
+
if not hasattr(F, "scaled_dot_product_attention"):
|
| 488 |
+
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
| 489 |
+
self.num_tokens = num_tokens
|
| 490 |
+
|
| 491 |
+
def __call__(
|
| 492 |
+
self,
|
| 493 |
+
attn,
|
| 494 |
+
hidden_states,
|
| 495 |
+
encoder_hidden_states=None,
|
| 496 |
+
attention_mask=None,
|
| 497 |
+
temb=None,
|
| 498 |
+
*args,
|
| 499 |
+
**kwargs,
|
| 500 |
+
):
|
| 501 |
+
residual = hidden_states
|
| 502 |
+
|
| 503 |
+
if attn.spatial_norm is not None:
|
| 504 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 505 |
+
|
| 506 |
+
input_ndim = hidden_states.ndim
|
| 507 |
+
|
| 508 |
+
if input_ndim == 4:
|
| 509 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 510 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 511 |
+
|
| 512 |
+
batch_size, sequence_length, _ = (
|
| 513 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 514 |
+
)
|
| 515 |
+
|
| 516 |
+
if attention_mask is not None:
|
| 517 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 518 |
+
# scaled_dot_product_attention expects attention_mask shape to be
|
| 519 |
+
# (batch, heads, source_length, target_length)
|
| 520 |
+
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
|
| 521 |
+
|
| 522 |
+
if attn.group_norm is not None:
|
| 523 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 524 |
+
|
| 525 |
+
query = attn.to_q(hidden_states)
|
| 526 |
+
|
| 527 |
+
if encoder_hidden_states is None:
|
| 528 |
+
encoder_hidden_states = hidden_states
|
| 529 |
+
else:
|
| 530 |
+
end_pos = encoder_hidden_states.shape[1] - self.num_tokens
|
| 531 |
+
encoder_hidden_states = encoder_hidden_states[:, :end_pos] # only use text
|
| 532 |
+
if attn.norm_cross:
|
| 533 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 534 |
+
|
| 535 |
+
key = attn.to_k(encoder_hidden_states)
|
| 536 |
+
value = attn.to_v(encoder_hidden_states)
|
| 537 |
+
|
| 538 |
+
inner_dim = key.shape[-1]
|
| 539 |
+
head_dim = inner_dim // attn.heads
|
| 540 |
+
|
| 541 |
+
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 542 |
+
|
| 543 |
+
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 544 |
+
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 545 |
+
|
| 546 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 547 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 548 |
+
hidden_states = F.scaled_dot_product_attention(
|
| 549 |
+
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
| 550 |
+
)
|
| 551 |
+
|
| 552 |
+
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
| 553 |
+
hidden_states = hidden_states.to(query.dtype)
|
| 554 |
+
|
| 555 |
+
# linear proj
|
| 556 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 557 |
+
# dropout
|
| 558 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 559 |
+
|
| 560 |
+
if input_ndim == 4:
|
| 561 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 562 |
+
|
| 563 |
+
if attn.residual_connection:
|
| 564 |
+
hidden_states = hidden_states + residual
|
| 565 |
+
|
| 566 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 567 |
+
|
| 568 |
+
return hidden_states
|
ip_adapter/attention_processor_faceid.py
ADDED
|
@@ -0,0 +1,433 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
|
| 6 |
+
from diffusers.models.lora import LoRALinearLayer
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class LoRAAttnProcessor(nn.Module):
|
| 10 |
+
r"""
|
| 11 |
+
Default processor for performing attention-related computations.
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
def __init__(
|
| 15 |
+
self,
|
| 16 |
+
hidden_size=None,
|
| 17 |
+
cross_attention_dim=None,
|
| 18 |
+
rank=4,
|
| 19 |
+
network_alpha=None,
|
| 20 |
+
lora_scale=1.0,
|
| 21 |
+
):
|
| 22 |
+
super().__init__()
|
| 23 |
+
|
| 24 |
+
self.rank = rank
|
| 25 |
+
self.lora_scale = lora_scale
|
| 26 |
+
|
| 27 |
+
self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
|
| 28 |
+
self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
|
| 29 |
+
self.to_v_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
|
| 30 |
+
self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
|
| 31 |
+
|
| 32 |
+
def __call__(
|
| 33 |
+
self,
|
| 34 |
+
attn,
|
| 35 |
+
hidden_states,
|
| 36 |
+
encoder_hidden_states=None,
|
| 37 |
+
attention_mask=None,
|
| 38 |
+
temb=None,
|
| 39 |
+
*args,
|
| 40 |
+
**kwargs,
|
| 41 |
+
):
|
| 42 |
+
residual = hidden_states
|
| 43 |
+
|
| 44 |
+
if attn.spatial_norm is not None:
|
| 45 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 46 |
+
|
| 47 |
+
input_ndim = hidden_states.ndim
|
| 48 |
+
|
| 49 |
+
if input_ndim == 4:
|
| 50 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 51 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 52 |
+
|
| 53 |
+
batch_size, sequence_length, _ = (
|
| 54 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 55 |
+
)
|
| 56 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 57 |
+
|
| 58 |
+
if attn.group_norm is not None:
|
| 59 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 60 |
+
|
| 61 |
+
query = attn.to_q(hidden_states) + self.lora_scale * self.to_q_lora(hidden_states)
|
| 62 |
+
|
| 63 |
+
if encoder_hidden_states is None:
|
| 64 |
+
encoder_hidden_states = hidden_states
|
| 65 |
+
elif attn.norm_cross:
|
| 66 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 67 |
+
|
| 68 |
+
key = attn.to_k(encoder_hidden_states) + self.lora_scale * self.to_k_lora(encoder_hidden_states)
|
| 69 |
+
value = attn.to_v(encoder_hidden_states) + self.lora_scale * self.to_v_lora(encoder_hidden_states)
|
| 70 |
+
|
| 71 |
+
query = attn.head_to_batch_dim(query)
|
| 72 |
+
key = attn.head_to_batch_dim(key)
|
| 73 |
+
value = attn.head_to_batch_dim(value)
|
| 74 |
+
|
| 75 |
+
attention_probs = attn.get_attention_scores(query, key, attention_mask)
|
| 76 |
+
hidden_states = torch.bmm(attention_probs, value)
|
| 77 |
+
hidden_states = attn.batch_to_head_dim(hidden_states)
|
| 78 |
+
|
| 79 |
+
# linear proj
|
| 80 |
+
hidden_states = attn.to_out[0](hidden_states) + self.lora_scale * self.to_out_lora(hidden_states)
|
| 81 |
+
# dropout
|
| 82 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 83 |
+
|
| 84 |
+
if input_ndim == 4:
|
| 85 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 86 |
+
|
| 87 |
+
if attn.residual_connection:
|
| 88 |
+
hidden_states = hidden_states + residual
|
| 89 |
+
|
| 90 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 91 |
+
|
| 92 |
+
return hidden_states
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
class LoRAIPAttnProcessor(nn.Module):
|
| 96 |
+
r"""
|
| 97 |
+
Attention processor for IP-Adapater.
|
| 98 |
+
Args:
|
| 99 |
+
hidden_size (`int`):
|
| 100 |
+
The hidden size of the attention layer.
|
| 101 |
+
cross_attention_dim (`int`):
|
| 102 |
+
The number of channels in the `encoder_hidden_states`.
|
| 103 |
+
scale (`float`, defaults to 1.0):
|
| 104 |
+
the weight scale of image prompt.
|
| 105 |
+
num_tokens (`int`, defaults to 4 when do ip_adapter_plus it should be 16):
|
| 106 |
+
The context length of the image features.
|
| 107 |
+
"""
|
| 108 |
+
|
| 109 |
+
def __init__(self, hidden_size, cross_attention_dim=None, rank=4, network_alpha=None, lora_scale=1.0, scale=1.0, num_tokens=4):
|
| 110 |
+
super().__init__()
|
| 111 |
+
|
| 112 |
+
self.rank = rank
|
| 113 |
+
self.lora_scale = lora_scale
|
| 114 |
+
|
| 115 |
+
self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
|
| 116 |
+
self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
|
| 117 |
+
self.to_v_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
|
| 118 |
+
self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
|
| 119 |
+
|
| 120 |
+
self.hidden_size = hidden_size
|
| 121 |
+
self.cross_attention_dim = cross_attention_dim
|
| 122 |
+
self.scale = scale
|
| 123 |
+
self.num_tokens = num_tokens
|
| 124 |
+
|
| 125 |
+
self.to_k_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
| 126 |
+
self.to_v_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
| 127 |
+
|
| 128 |
+
def __call__(
|
| 129 |
+
self,
|
| 130 |
+
attn,
|
| 131 |
+
hidden_states,
|
| 132 |
+
encoder_hidden_states=None,
|
| 133 |
+
attention_mask=None,
|
| 134 |
+
temb=None,
|
| 135 |
+
*args,
|
| 136 |
+
**kwargs,
|
| 137 |
+
):
|
| 138 |
+
residual = hidden_states
|
| 139 |
+
|
| 140 |
+
if attn.spatial_norm is not None:
|
| 141 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 142 |
+
|
| 143 |
+
input_ndim = hidden_states.ndim
|
| 144 |
+
|
| 145 |
+
if input_ndim == 4:
|
| 146 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 147 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 148 |
+
|
| 149 |
+
batch_size, sequence_length, _ = (
|
| 150 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 151 |
+
)
|
| 152 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 153 |
+
|
| 154 |
+
if attn.group_norm is not None:
|
| 155 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 156 |
+
|
| 157 |
+
query = attn.to_q(hidden_states) + self.lora_scale * self.to_q_lora(hidden_states)
|
| 158 |
+
|
| 159 |
+
if encoder_hidden_states is None:
|
| 160 |
+
encoder_hidden_states = hidden_states
|
| 161 |
+
else:
|
| 162 |
+
# get encoder_hidden_states, ip_hidden_states
|
| 163 |
+
end_pos = encoder_hidden_states.shape[1] - self.num_tokens
|
| 164 |
+
encoder_hidden_states, ip_hidden_states = (
|
| 165 |
+
encoder_hidden_states[:, :end_pos, :],
|
| 166 |
+
encoder_hidden_states[:, end_pos:, :],
|
| 167 |
+
)
|
| 168 |
+
if attn.norm_cross:
|
| 169 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 170 |
+
|
| 171 |
+
key = attn.to_k(encoder_hidden_states) + self.lora_scale * self.to_k_lora(encoder_hidden_states)
|
| 172 |
+
value = attn.to_v(encoder_hidden_states) + self.lora_scale * self.to_v_lora(encoder_hidden_states)
|
| 173 |
+
|
| 174 |
+
query = attn.head_to_batch_dim(query)
|
| 175 |
+
key = attn.head_to_batch_dim(key)
|
| 176 |
+
value = attn.head_to_batch_dim(value)
|
| 177 |
+
|
| 178 |
+
attention_probs = attn.get_attention_scores(query, key, attention_mask)
|
| 179 |
+
hidden_states = torch.bmm(attention_probs, value)
|
| 180 |
+
hidden_states = attn.batch_to_head_dim(hidden_states)
|
| 181 |
+
|
| 182 |
+
# for ip-adapter
|
| 183 |
+
ip_key = self.to_k_ip(ip_hidden_states)
|
| 184 |
+
ip_value = self.to_v_ip(ip_hidden_states)
|
| 185 |
+
|
| 186 |
+
ip_key = attn.head_to_batch_dim(ip_key)
|
| 187 |
+
ip_value = attn.head_to_batch_dim(ip_value)
|
| 188 |
+
|
| 189 |
+
ip_attention_probs = attn.get_attention_scores(query, ip_key, None)
|
| 190 |
+
self.attn_map = ip_attention_probs
|
| 191 |
+
ip_hidden_states = torch.bmm(ip_attention_probs, ip_value)
|
| 192 |
+
ip_hidden_states = attn.batch_to_head_dim(ip_hidden_states)
|
| 193 |
+
|
| 194 |
+
hidden_states = hidden_states + self.scale * ip_hidden_states
|
| 195 |
+
|
| 196 |
+
# linear proj
|
| 197 |
+
hidden_states = attn.to_out[0](hidden_states) + self.lora_scale * self.to_out_lora(hidden_states)
|
| 198 |
+
# dropout
|
| 199 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 200 |
+
|
| 201 |
+
if input_ndim == 4:
|
| 202 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 203 |
+
|
| 204 |
+
if attn.residual_connection:
|
| 205 |
+
hidden_states = hidden_states + residual
|
| 206 |
+
|
| 207 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 208 |
+
|
| 209 |
+
return hidden_states
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
class LoRAAttnProcessor2_0(nn.Module):
|
| 213 |
+
|
| 214 |
+
r"""
|
| 215 |
+
Default processor for performing attention-related computations.
|
| 216 |
+
"""
|
| 217 |
+
|
| 218 |
+
def __init__(
|
| 219 |
+
self,
|
| 220 |
+
hidden_size=None,
|
| 221 |
+
cross_attention_dim=None,
|
| 222 |
+
rank=4,
|
| 223 |
+
network_alpha=None,
|
| 224 |
+
lora_scale=1.0,
|
| 225 |
+
):
|
| 226 |
+
super().__init__()
|
| 227 |
+
|
| 228 |
+
self.rank = rank
|
| 229 |
+
self.lora_scale = lora_scale
|
| 230 |
+
|
| 231 |
+
self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
|
| 232 |
+
self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
|
| 233 |
+
self.to_v_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
|
| 234 |
+
self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
|
| 235 |
+
|
| 236 |
+
def __call__(
|
| 237 |
+
self,
|
| 238 |
+
attn,
|
| 239 |
+
hidden_states,
|
| 240 |
+
encoder_hidden_states=None,
|
| 241 |
+
attention_mask=None,
|
| 242 |
+
temb=None,
|
| 243 |
+
*args,
|
| 244 |
+
**kwargs,
|
| 245 |
+
):
|
| 246 |
+
residual = hidden_states
|
| 247 |
+
|
| 248 |
+
if attn.spatial_norm is not None:
|
| 249 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 250 |
+
|
| 251 |
+
input_ndim = hidden_states.ndim
|
| 252 |
+
|
| 253 |
+
if input_ndim == 4:
|
| 254 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 255 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 256 |
+
|
| 257 |
+
batch_size, sequence_length, _ = (
|
| 258 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 259 |
+
)
|
| 260 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 261 |
+
|
| 262 |
+
if attn.group_norm is not None:
|
| 263 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 264 |
+
|
| 265 |
+
query = attn.to_q(hidden_states) + self.lora_scale * self.to_q_lora(hidden_states)
|
| 266 |
+
|
| 267 |
+
if encoder_hidden_states is None:
|
| 268 |
+
encoder_hidden_states = hidden_states
|
| 269 |
+
elif attn.norm_cross:
|
| 270 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 271 |
+
|
| 272 |
+
key = attn.to_k(encoder_hidden_states) + self.lora_scale * self.to_k_lora(encoder_hidden_states)
|
| 273 |
+
value = attn.to_v(encoder_hidden_states) + self.lora_scale * self.to_v_lora(encoder_hidden_states)
|
| 274 |
+
|
| 275 |
+
inner_dim = key.shape[-1]
|
| 276 |
+
head_dim = inner_dim // attn.heads
|
| 277 |
+
|
| 278 |
+
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 279 |
+
|
| 280 |
+
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 281 |
+
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 282 |
+
|
| 283 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 284 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 285 |
+
hidden_states = F.scaled_dot_product_attention(
|
| 286 |
+
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
| 287 |
+
)
|
| 288 |
+
|
| 289 |
+
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
| 290 |
+
hidden_states = hidden_states.to(query.dtype)
|
| 291 |
+
|
| 292 |
+
# linear proj
|
| 293 |
+
hidden_states = attn.to_out[0](hidden_states) + self.lora_scale * self.to_out_lora(hidden_states)
|
| 294 |
+
# dropout
|
| 295 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 296 |
+
|
| 297 |
+
if input_ndim == 4:
|
| 298 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 299 |
+
|
| 300 |
+
if attn.residual_connection:
|
| 301 |
+
hidden_states = hidden_states + residual
|
| 302 |
+
|
| 303 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 304 |
+
|
| 305 |
+
return hidden_states
|
| 306 |
+
|
| 307 |
+
|
| 308 |
+
class LoRAIPAttnProcessor2_0(nn.Module):
|
| 309 |
+
r"""
|
| 310 |
+
Processor for implementing the LoRA attention mechanism.
|
| 311 |
+
|
| 312 |
+
Args:
|
| 313 |
+
hidden_size (`int`, *optional*):
|
| 314 |
+
The hidden size of the attention layer.
|
| 315 |
+
cross_attention_dim (`int`, *optional*):
|
| 316 |
+
The number of channels in the `encoder_hidden_states`.
|
| 317 |
+
rank (`int`, defaults to 4):
|
| 318 |
+
The dimension of the LoRA update matrices.
|
| 319 |
+
network_alpha (`int`, *optional*):
|
| 320 |
+
Equivalent to `alpha` but it's usage is specific to Kohya (A1111) style LoRAs.
|
| 321 |
+
"""
|
| 322 |
+
|
| 323 |
+
def __init__(self, hidden_size, cross_attention_dim=None, rank=4, network_alpha=None, lora_scale=1.0, scale=1.0, num_tokens=4):
|
| 324 |
+
super().__init__()
|
| 325 |
+
|
| 326 |
+
self.rank = rank
|
| 327 |
+
self.lora_scale = lora_scale
|
| 328 |
+
self.num_tokens = num_tokens
|
| 329 |
+
|
| 330 |
+
self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
|
| 331 |
+
self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
|
| 332 |
+
self.to_v_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
|
| 333 |
+
self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
|
| 334 |
+
|
| 335 |
+
|
| 336 |
+
self.hidden_size = hidden_size
|
| 337 |
+
self.cross_attention_dim = cross_attention_dim
|
| 338 |
+
self.scale = scale
|
| 339 |
+
|
| 340 |
+
self.to_k_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
| 341 |
+
self.to_v_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
| 342 |
+
|
| 343 |
+
def __call__(
|
| 344 |
+
self, attn, hidden_states, encoder_hidden_states=None, attention_mask=None, scale=1.0, temb=None, *args, **kwargs,
|
| 345 |
+
):
|
| 346 |
+
residual = hidden_states
|
| 347 |
+
|
| 348 |
+
if attn.spatial_norm is not None:
|
| 349 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 350 |
+
|
| 351 |
+
input_ndim = hidden_states.ndim
|
| 352 |
+
|
| 353 |
+
if input_ndim == 4:
|
| 354 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 355 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 356 |
+
|
| 357 |
+
batch_size, sequence_length, _ = (
|
| 358 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 359 |
+
)
|
| 360 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 361 |
+
|
| 362 |
+
if attn.group_norm is not None:
|
| 363 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 364 |
+
|
| 365 |
+
query = attn.to_q(hidden_states) + self.lora_scale * self.to_q_lora(hidden_states)
|
| 366 |
+
#query = attn.head_to_batch_dim(query)
|
| 367 |
+
|
| 368 |
+
if encoder_hidden_states is None:
|
| 369 |
+
encoder_hidden_states = hidden_states
|
| 370 |
+
else:
|
| 371 |
+
# get encoder_hidden_states, ip_hidden_states
|
| 372 |
+
end_pos = encoder_hidden_states.shape[1] - self.num_tokens
|
| 373 |
+
encoder_hidden_states, ip_hidden_states = (
|
| 374 |
+
encoder_hidden_states[:, :end_pos, :],
|
| 375 |
+
encoder_hidden_states[:, end_pos:, :],
|
| 376 |
+
)
|
| 377 |
+
if attn.norm_cross:
|
| 378 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 379 |
+
|
| 380 |
+
# for text
|
| 381 |
+
key = attn.to_k(encoder_hidden_states) + self.lora_scale * self.to_k_lora(encoder_hidden_states)
|
| 382 |
+
value = attn.to_v(encoder_hidden_states) + self.lora_scale * self.to_v_lora(encoder_hidden_states)
|
| 383 |
+
|
| 384 |
+
inner_dim = key.shape[-1]
|
| 385 |
+
head_dim = inner_dim // attn.heads
|
| 386 |
+
|
| 387 |
+
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 388 |
+
|
| 389 |
+
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 390 |
+
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 391 |
+
|
| 392 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 393 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 394 |
+
hidden_states = F.scaled_dot_product_attention(
|
| 395 |
+
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
| 396 |
+
)
|
| 397 |
+
|
| 398 |
+
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
| 399 |
+
hidden_states = hidden_states.to(query.dtype)
|
| 400 |
+
|
| 401 |
+
# for ip
|
| 402 |
+
ip_key = self.to_k_ip(ip_hidden_states)
|
| 403 |
+
ip_value = self.to_v_ip(ip_hidden_states)
|
| 404 |
+
|
| 405 |
+
ip_key = ip_key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 406 |
+
ip_value = ip_value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 407 |
+
|
| 408 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 409 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 410 |
+
ip_hidden_states = F.scaled_dot_product_attention(
|
| 411 |
+
query, ip_key, ip_value, attn_mask=None, dropout_p=0.0, is_causal=False
|
| 412 |
+
)
|
| 413 |
+
|
| 414 |
+
|
| 415 |
+
ip_hidden_states = ip_hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
| 416 |
+
ip_hidden_states = ip_hidden_states.to(query.dtype)
|
| 417 |
+
|
| 418 |
+
hidden_states = hidden_states + self.scale * ip_hidden_states
|
| 419 |
+
|
| 420 |
+
# linear proj
|
| 421 |
+
hidden_states = attn.to_out[0](hidden_states) + self.lora_scale * self.to_out_lora(hidden_states)
|
| 422 |
+
# dropout
|
| 423 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 424 |
+
|
| 425 |
+
if input_ndim == 4:
|
| 426 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 427 |
+
|
| 428 |
+
if attn.residual_connection:
|
| 429 |
+
hidden_states = hidden_states + residual
|
| 430 |
+
|
| 431 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 432 |
+
|
| 433 |
+
return hidden_states
|
ip_adapter/custom_pipelines.py
ADDED
|
@@ -0,0 +1,394 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from diffusers import StableDiffusionXLPipeline
|
| 5 |
+
from diffusers.pipelines.stable_diffusion_xl import StableDiffusionXLPipelineOutput
|
| 6 |
+
from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl import rescale_noise_cfg
|
| 7 |
+
|
| 8 |
+
from .utils import is_torch2_available
|
| 9 |
+
|
| 10 |
+
if is_torch2_available():
|
| 11 |
+
from .attention_processor import IPAttnProcessor2_0 as IPAttnProcessor
|
| 12 |
+
else:
|
| 13 |
+
from .attention_processor import IPAttnProcessor
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class StableDiffusionXLCustomPipeline(StableDiffusionXLPipeline):
|
| 17 |
+
def set_scale(self, scale):
|
| 18 |
+
for attn_processor in self.unet.attn_processors.values():
|
| 19 |
+
if isinstance(attn_processor, IPAttnProcessor):
|
| 20 |
+
attn_processor.scale = scale
|
| 21 |
+
|
| 22 |
+
@torch.no_grad()
|
| 23 |
+
def __call__( # noqa: C901
|
| 24 |
+
self,
|
| 25 |
+
prompt: Optional[Union[str, List[str]]] = None,
|
| 26 |
+
prompt_2: Optional[Union[str, List[str]]] = None,
|
| 27 |
+
height: Optional[int] = None,
|
| 28 |
+
width: Optional[int] = None,
|
| 29 |
+
num_inference_steps: int = 50,
|
| 30 |
+
denoising_end: Optional[float] = None,
|
| 31 |
+
guidance_scale: float = 5.0,
|
| 32 |
+
negative_prompt: Optional[Union[str, List[str]]] = None,
|
| 33 |
+
negative_prompt_2: Optional[Union[str, List[str]]] = None,
|
| 34 |
+
num_images_per_prompt: Optional[int] = 1,
|
| 35 |
+
eta: float = 0.0,
|
| 36 |
+
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
| 37 |
+
latents: Optional[torch.FloatTensor] = None,
|
| 38 |
+
prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 39 |
+
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 40 |
+
pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 41 |
+
negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 42 |
+
output_type: Optional[str] = "pil",
|
| 43 |
+
return_dict: bool = True,
|
| 44 |
+
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
|
| 45 |
+
callback_steps: int = 1,
|
| 46 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 47 |
+
guidance_rescale: float = 0.0,
|
| 48 |
+
original_size: Optional[Tuple[int, int]] = None,
|
| 49 |
+
crops_coords_top_left: Tuple[int, int] = (0, 0),
|
| 50 |
+
target_size: Optional[Tuple[int, int]] = None,
|
| 51 |
+
negative_original_size: Optional[Tuple[int, int]] = None,
|
| 52 |
+
negative_crops_coords_top_left: Tuple[int, int] = (0, 0),
|
| 53 |
+
negative_target_size: Optional[Tuple[int, int]] = None,
|
| 54 |
+
control_guidance_start: float = 0.0,
|
| 55 |
+
control_guidance_end: float = 1.0,
|
| 56 |
+
):
|
| 57 |
+
r"""
|
| 58 |
+
Function invoked when calling the pipeline for generation.
|
| 59 |
+
|
| 60 |
+
Args:
|
| 61 |
+
prompt (`str` or `List[str]`, *optional*):
|
| 62 |
+
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
|
| 63 |
+
instead.
|
| 64 |
+
prompt_2 (`str` or `List[str]`, *optional*):
|
| 65 |
+
The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
|
| 66 |
+
used in both text-encoders
|
| 67 |
+
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
|
| 68 |
+
The height in pixels of the generated image. This is set to 1024 by default for the best results.
|
| 69 |
+
Anything below 512 pixels won't work well for
|
| 70 |
+
[stabilityai/stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0)
|
| 71 |
+
and checkpoints that are not specifically fine-tuned on low resolutions.
|
| 72 |
+
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
|
| 73 |
+
The width in pixels of the generated image. This is set to 1024 by default for the best results.
|
| 74 |
+
Anything below 512 pixels won't work well for
|
| 75 |
+
[stabilityai/stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0)
|
| 76 |
+
and checkpoints that are not specifically fine-tuned on low resolutions.
|
| 77 |
+
num_inference_steps (`int`, *optional*, defaults to 50):
|
| 78 |
+
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
| 79 |
+
expense of slower inference.
|
| 80 |
+
denoising_end (`float`, *optional*):
|
| 81 |
+
When specified, determines the fraction (between 0.0 and 1.0) of the total denoising process to be
|
| 82 |
+
completed before it is intentionally prematurely terminated. As a result, the returned sample will
|
| 83 |
+
still retain a substantial amount of noise as determined by the discrete timesteps selected by the
|
| 84 |
+
scheduler. The denoising_end parameter should ideally be utilized when this pipeline forms a part of a
|
| 85 |
+
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
|
| 86 |
+
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
|
| 87 |
+
guidance_scale (`float`, *optional*, defaults to 5.0):
|
| 88 |
+
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
|
| 89 |
+
`guidance_scale` is defined as `w` of equation 2. of [Imagen
|
| 90 |
+
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
|
| 91 |
+
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
|
| 92 |
+
usually at the expense of lower image quality.
|
| 93 |
+
negative_prompt (`str` or `List[str]`, *optional*):
|
| 94 |
+
The prompt or prompts not to guide the image generation. If not defined, one has to pass
|
| 95 |
+
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
|
| 96 |
+
less than `1`).
|
| 97 |
+
negative_prompt_2 (`str` or `List[str]`, *optional*):
|
| 98 |
+
The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
|
| 99 |
+
`text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
|
| 100 |
+
num_images_per_prompt (`int`, *optional*, defaults to 1):
|
| 101 |
+
The number of images to generate per prompt.
|
| 102 |
+
eta (`float`, *optional*, defaults to 0.0):
|
| 103 |
+
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
|
| 104 |
+
[`schedulers.DDIMScheduler`], will be ignored for others.
|
| 105 |
+
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
|
| 106 |
+
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
|
| 107 |
+
to make generation deterministic.
|
| 108 |
+
latents (`torch.FloatTensor`, *optional*):
|
| 109 |
+
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
|
| 110 |
+
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
|
| 111 |
+
tensor will ge generated by sampling using the supplied random `generator`.
|
| 112 |
+
prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 113 |
+
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
|
| 114 |
+
provided, text embeddings will be generated from `prompt` input argument.
|
| 115 |
+
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 116 |
+
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
|
| 117 |
+
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
|
| 118 |
+
argument.
|
| 119 |
+
pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 120 |
+
Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
|
| 121 |
+
If not provided, pooled text embeddings will be generated from `prompt` input argument.
|
| 122 |
+
negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 123 |
+
Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
|
| 124 |
+
weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
|
| 125 |
+
input argument.
|
| 126 |
+
output_type (`str`, *optional*, defaults to `"pil"`):
|
| 127 |
+
The output format of the generate image. Choose between
|
| 128 |
+
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
|
| 129 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 130 |
+
Whether or not to return a [`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] instead
|
| 131 |
+
of a plain tuple.
|
| 132 |
+
callback (`Callable`, *optional*):
|
| 133 |
+
A function that will be called every `callback_steps` steps during inference. The function will be
|
| 134 |
+
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
|
| 135 |
+
callback_steps (`int`, *optional*, defaults to 1):
|
| 136 |
+
The frequency at which the `callback` function will be called. If not specified, the callback will be
|
| 137 |
+
called at every step.
|
| 138 |
+
cross_attention_kwargs (`dict`, *optional*):
|
| 139 |
+
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
| 140 |
+
`self.processor` in
|
| 141 |
+
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
|
| 142 |
+
guidance_rescale (`float`, *optional*, defaults to 0.7):
|
| 143 |
+
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
|
| 144 |
+
Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
|
| 145 |
+
[Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
|
| 146 |
+
Guidance rescale factor should fix overexposure when using zero terminal SNR.
|
| 147 |
+
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
|
| 148 |
+
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
|
| 149 |
+
`original_size` defaults to `(width, height)` if not specified. Part of SDXL's micro-conditioning as
|
| 150 |
+
explained in section 2.2 of
|
| 151 |
+
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
|
| 152 |
+
crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
|
| 153 |
+
`crops_coords_top_left` can be used to generate an image that appears to be "cropped" from the position
|
| 154 |
+
`crops_coords_top_left` downwards. Favorable, well-centered images are usually achieved by setting
|
| 155 |
+
`crops_coords_top_left` to (0, 0). Part of SDXL's micro-conditioning as explained in section 2.2 of
|
| 156 |
+
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
|
| 157 |
+
target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
|
| 158 |
+
For most cases, `target_size` should be set to the desired height and width of the generated image. If
|
| 159 |
+
not specified it will default to `(width, height)`. Part of SDXL's micro-conditioning as explained in
|
| 160 |
+
section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
|
| 161 |
+
negative_original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
|
| 162 |
+
To negatively condition the generation process based on a specific image resolution. Part of SDXL's
|
| 163 |
+
micro-conditioning as explained in section 2.2 of
|
| 164 |
+
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
|
| 165 |
+
information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
|
| 166 |
+
negative_crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
|
| 167 |
+
To negatively condition the generation process based on a specific crop coordinates. Part of SDXL's
|
| 168 |
+
micro-conditioning as explained in section 2.2 of
|
| 169 |
+
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
|
| 170 |
+
information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
|
| 171 |
+
negative_target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
|
| 172 |
+
To negatively condition the generation process based on a target image resolution. It should be as same
|
| 173 |
+
as the `target_size` for most cases. Part of SDXL's micro-conditioning as explained in section 2.2 of
|
| 174 |
+
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
|
| 175 |
+
information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
|
| 176 |
+
control_guidance_start (`float`, *optional*, defaults to 0.0):
|
| 177 |
+
The percentage of total steps at which the ControlNet starts applying.
|
| 178 |
+
control_guidance_end (`float`, *optional*, defaults to 1.0):
|
| 179 |
+
The percentage of total steps at which the ControlNet stops applying.
|
| 180 |
+
|
| 181 |
+
Examples:
|
| 182 |
+
|
| 183 |
+
Returns:
|
| 184 |
+
[`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] or `tuple`:
|
| 185 |
+
[`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] if `return_dict` is True, otherwise a
|
| 186 |
+
`tuple`. When returning a tuple, the first element is a list with the generated images.
|
| 187 |
+
"""
|
| 188 |
+
# 0. Default height and width to unet
|
| 189 |
+
height = height or self.default_sample_size * self.vae_scale_factor
|
| 190 |
+
width = width or self.default_sample_size * self.vae_scale_factor
|
| 191 |
+
|
| 192 |
+
original_size = original_size or (height, width)
|
| 193 |
+
target_size = target_size or (height, width)
|
| 194 |
+
|
| 195 |
+
# 1. Check inputs. Raise error if not correct
|
| 196 |
+
self.check_inputs(
|
| 197 |
+
prompt,
|
| 198 |
+
prompt_2,
|
| 199 |
+
height,
|
| 200 |
+
width,
|
| 201 |
+
callback_steps,
|
| 202 |
+
negative_prompt,
|
| 203 |
+
negative_prompt_2,
|
| 204 |
+
prompt_embeds,
|
| 205 |
+
negative_prompt_embeds,
|
| 206 |
+
pooled_prompt_embeds,
|
| 207 |
+
negative_pooled_prompt_embeds,
|
| 208 |
+
)
|
| 209 |
+
|
| 210 |
+
# 2. Define call parameters
|
| 211 |
+
if prompt is not None and isinstance(prompt, str):
|
| 212 |
+
batch_size = 1
|
| 213 |
+
elif prompt is not None and isinstance(prompt, list):
|
| 214 |
+
batch_size = len(prompt)
|
| 215 |
+
else:
|
| 216 |
+
batch_size = prompt_embeds.shape[0]
|
| 217 |
+
|
| 218 |
+
device = self._execution_device
|
| 219 |
+
|
| 220 |
+
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
|
| 221 |
+
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
|
| 222 |
+
# corresponds to doing no classifier free guidance.
|
| 223 |
+
do_classifier_free_guidance = guidance_scale > 1.0
|
| 224 |
+
|
| 225 |
+
# 3. Encode input prompt
|
| 226 |
+
text_encoder_lora_scale = (
|
| 227 |
+
cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
|
| 228 |
+
)
|
| 229 |
+
(
|
| 230 |
+
prompt_embeds,
|
| 231 |
+
negative_prompt_embeds,
|
| 232 |
+
pooled_prompt_embeds,
|
| 233 |
+
negative_pooled_prompt_embeds,
|
| 234 |
+
) = self.encode_prompt(
|
| 235 |
+
prompt=prompt,
|
| 236 |
+
prompt_2=prompt_2,
|
| 237 |
+
device=device,
|
| 238 |
+
num_images_per_prompt=num_images_per_prompt,
|
| 239 |
+
do_classifier_free_guidance=do_classifier_free_guidance,
|
| 240 |
+
negative_prompt=negative_prompt,
|
| 241 |
+
negative_prompt_2=negative_prompt_2,
|
| 242 |
+
prompt_embeds=prompt_embeds,
|
| 243 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 244 |
+
pooled_prompt_embeds=pooled_prompt_embeds,
|
| 245 |
+
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
|
| 246 |
+
lora_scale=text_encoder_lora_scale,
|
| 247 |
+
)
|
| 248 |
+
|
| 249 |
+
# 4. Prepare timesteps
|
| 250 |
+
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
| 251 |
+
|
| 252 |
+
timesteps = self.scheduler.timesteps
|
| 253 |
+
|
| 254 |
+
# 5. Prepare latent variables
|
| 255 |
+
num_channels_latents = self.unet.config.in_channels
|
| 256 |
+
latents = self.prepare_latents(
|
| 257 |
+
batch_size * num_images_per_prompt,
|
| 258 |
+
num_channels_latents,
|
| 259 |
+
height,
|
| 260 |
+
width,
|
| 261 |
+
prompt_embeds.dtype,
|
| 262 |
+
device,
|
| 263 |
+
generator,
|
| 264 |
+
latents,
|
| 265 |
+
)
|
| 266 |
+
|
| 267 |
+
# 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
|
| 268 |
+
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
|
| 269 |
+
|
| 270 |
+
# 7. Prepare added time ids & embeddings
|
| 271 |
+
add_text_embeds = pooled_prompt_embeds
|
| 272 |
+
if self.text_encoder_2 is None:
|
| 273 |
+
text_encoder_projection_dim = int(pooled_prompt_embeds.shape[-1])
|
| 274 |
+
else:
|
| 275 |
+
text_encoder_projection_dim = self.text_encoder_2.config.projection_dim
|
| 276 |
+
|
| 277 |
+
add_time_ids = self._get_add_time_ids(
|
| 278 |
+
original_size,
|
| 279 |
+
crops_coords_top_left,
|
| 280 |
+
target_size,
|
| 281 |
+
dtype=prompt_embeds.dtype,
|
| 282 |
+
text_encoder_projection_dim=text_encoder_projection_dim,
|
| 283 |
+
)
|
| 284 |
+
if negative_original_size is not None and negative_target_size is not None:
|
| 285 |
+
negative_add_time_ids = self._get_add_time_ids(
|
| 286 |
+
negative_original_size,
|
| 287 |
+
negative_crops_coords_top_left,
|
| 288 |
+
negative_target_size,
|
| 289 |
+
dtype=prompt_embeds.dtype,
|
| 290 |
+
text_encoder_projection_dim=text_encoder_projection_dim,
|
| 291 |
+
)
|
| 292 |
+
else:
|
| 293 |
+
negative_add_time_ids = add_time_ids
|
| 294 |
+
|
| 295 |
+
if do_classifier_free_guidance:
|
| 296 |
+
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
|
| 297 |
+
add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
|
| 298 |
+
add_time_ids = torch.cat([negative_add_time_ids, add_time_ids], dim=0)
|
| 299 |
+
|
| 300 |
+
prompt_embeds = prompt_embeds.to(device)
|
| 301 |
+
add_text_embeds = add_text_embeds.to(device)
|
| 302 |
+
add_time_ids = add_time_ids.to(device).repeat(batch_size * num_images_per_prompt, 1)
|
| 303 |
+
|
| 304 |
+
# 8. Denoising loop
|
| 305 |
+
num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
|
| 306 |
+
|
| 307 |
+
# 7.1 Apply denoising_end
|
| 308 |
+
if denoising_end is not None and isinstance(denoising_end, float) and denoising_end > 0 and denoising_end < 1:
|
| 309 |
+
discrete_timestep_cutoff = int(
|
| 310 |
+
round(
|
| 311 |
+
self.scheduler.config.num_train_timesteps
|
| 312 |
+
- (denoising_end * self.scheduler.config.num_train_timesteps)
|
| 313 |
+
)
|
| 314 |
+
)
|
| 315 |
+
num_inference_steps = len(list(filter(lambda ts: ts >= discrete_timestep_cutoff, timesteps)))
|
| 316 |
+
timesteps = timesteps[:num_inference_steps]
|
| 317 |
+
|
| 318 |
+
# get init conditioning scale
|
| 319 |
+
for attn_processor in self.unet.attn_processors.values():
|
| 320 |
+
if isinstance(attn_processor, IPAttnProcessor):
|
| 321 |
+
conditioning_scale = attn_processor.scale
|
| 322 |
+
break
|
| 323 |
+
|
| 324 |
+
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
| 325 |
+
for i, t in enumerate(timesteps):
|
| 326 |
+
if (i / len(timesteps) < control_guidance_start) or ((i + 1) / len(timesteps) > control_guidance_end):
|
| 327 |
+
self.set_scale(0.0)
|
| 328 |
+
else:
|
| 329 |
+
self.set_scale(conditioning_scale)
|
| 330 |
+
|
| 331 |
+
# expand the latents if we are doing classifier free guidance
|
| 332 |
+
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
| 333 |
+
|
| 334 |
+
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
| 335 |
+
|
| 336 |
+
# predict the noise residual
|
| 337 |
+
added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
|
| 338 |
+
noise_pred = self.unet(
|
| 339 |
+
latent_model_input,
|
| 340 |
+
t,
|
| 341 |
+
encoder_hidden_states=prompt_embeds,
|
| 342 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 343 |
+
added_cond_kwargs=added_cond_kwargs,
|
| 344 |
+
return_dict=False,
|
| 345 |
+
)[0]
|
| 346 |
+
|
| 347 |
+
# perform guidance
|
| 348 |
+
if do_classifier_free_guidance:
|
| 349 |
+
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
| 350 |
+
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
| 351 |
+
|
| 352 |
+
if do_classifier_free_guidance and guidance_rescale > 0.0:
|
| 353 |
+
# Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
|
| 354 |
+
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
|
| 355 |
+
|
| 356 |
+
# compute the previous noisy sample x_t -> x_t-1
|
| 357 |
+
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
|
| 358 |
+
|
| 359 |
+
# call the callback, if provided
|
| 360 |
+
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
|
| 361 |
+
progress_bar.update()
|
| 362 |
+
if callback is not None and i % callback_steps == 0:
|
| 363 |
+
callback(i, t, latents)
|
| 364 |
+
|
| 365 |
+
if not output_type == "latent":
|
| 366 |
+
# make sure the VAE is in float32 mode, as it overflows in float16
|
| 367 |
+
needs_upcasting = self.vae.dtype == torch.float16 and self.vae.config.force_upcast
|
| 368 |
+
|
| 369 |
+
if needs_upcasting:
|
| 370 |
+
self.upcast_vae()
|
| 371 |
+
latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
|
| 372 |
+
|
| 373 |
+
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
|
| 374 |
+
|
| 375 |
+
# cast back to fp16 if needed
|
| 376 |
+
if needs_upcasting:
|
| 377 |
+
self.vae.to(dtype=torch.float16)
|
| 378 |
+
else:
|
| 379 |
+
image = latents
|
| 380 |
+
|
| 381 |
+
if output_type != "latent":
|
| 382 |
+
# apply watermark if available
|
| 383 |
+
if self.watermark is not None:
|
| 384 |
+
image = self.watermark.apply_watermark(image)
|
| 385 |
+
|
| 386 |
+
image = self.image_processor.postprocess(image, output_type=output_type)
|
| 387 |
+
|
| 388 |
+
# Offload all models
|
| 389 |
+
self.maybe_free_model_hooks()
|
| 390 |
+
|
| 391 |
+
if not return_dict:
|
| 392 |
+
return (image,)
|
| 393 |
+
|
| 394 |
+
return StableDiffusionXLPipelineOutput(images=image)
|
ip_adapter/ip_adapter.py
ADDED
|
@@ -0,0 +1,417 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from typing import List
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from diffusers import StableDiffusionPipeline
|
| 6 |
+
from diffusers.pipelines.controlnet import MultiControlNetModel
|
| 7 |
+
from PIL import Image
|
| 8 |
+
from safetensors import safe_open
|
| 9 |
+
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
|
| 10 |
+
|
| 11 |
+
from .utils import is_torch2_available, get_generator
|
| 12 |
+
|
| 13 |
+
if is_torch2_available():
|
| 14 |
+
from .attention_processor import (
|
| 15 |
+
AttnProcessor2_0 as AttnProcessor,
|
| 16 |
+
)
|
| 17 |
+
from .attention_processor import (
|
| 18 |
+
CNAttnProcessor2_0 as CNAttnProcessor,
|
| 19 |
+
)
|
| 20 |
+
from .attention_processor import (
|
| 21 |
+
IPAttnProcessor2_0 as IPAttnProcessor,
|
| 22 |
+
)
|
| 23 |
+
else:
|
| 24 |
+
from .attention_processor import AttnProcessor, CNAttnProcessor, IPAttnProcessor
|
| 25 |
+
from .resampler import Resampler
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class ImageProjModel(torch.nn.Module):
|
| 29 |
+
"""Projection Model"""
|
| 30 |
+
|
| 31 |
+
def __init__(self, cross_attention_dim=1024, clip_embeddings_dim=1024, clip_extra_context_tokens=4):
|
| 32 |
+
super().__init__()
|
| 33 |
+
|
| 34 |
+
self.generator = None
|
| 35 |
+
self.cross_attention_dim = cross_attention_dim
|
| 36 |
+
self.clip_extra_context_tokens = clip_extra_context_tokens
|
| 37 |
+
self.proj = torch.nn.Linear(clip_embeddings_dim, self.clip_extra_context_tokens * cross_attention_dim)
|
| 38 |
+
self.norm = torch.nn.LayerNorm(cross_attention_dim)
|
| 39 |
+
|
| 40 |
+
def forward(self, image_embeds):
|
| 41 |
+
embeds = image_embeds
|
| 42 |
+
clip_extra_context_tokens = self.proj(embeds).reshape(
|
| 43 |
+
-1, self.clip_extra_context_tokens, self.cross_attention_dim
|
| 44 |
+
)
|
| 45 |
+
clip_extra_context_tokens = self.norm(clip_extra_context_tokens)
|
| 46 |
+
return clip_extra_context_tokens
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
class MLPProjModel(torch.nn.Module):
|
| 50 |
+
"""SD model with image prompt"""
|
| 51 |
+
def __init__(self, cross_attention_dim=1024, clip_embeddings_dim=1024):
|
| 52 |
+
super().__init__()
|
| 53 |
+
|
| 54 |
+
self.proj = torch.nn.Sequential(
|
| 55 |
+
torch.nn.Linear(clip_embeddings_dim, clip_embeddings_dim),
|
| 56 |
+
torch.nn.GELU(),
|
| 57 |
+
torch.nn.Linear(clip_embeddings_dim, cross_attention_dim),
|
| 58 |
+
torch.nn.LayerNorm(cross_attention_dim)
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
def forward(self, image_embeds):
|
| 62 |
+
clip_extra_context_tokens = self.proj(image_embeds)
|
| 63 |
+
return clip_extra_context_tokens
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
class IPAdapter:
|
| 67 |
+
def __init__(self, sd_pipe, image_encoder_path, ip_ckpt, device, num_tokens=4):
|
| 68 |
+
self.device = device
|
| 69 |
+
self.image_encoder_path = image_encoder_path
|
| 70 |
+
self.ip_ckpt = ip_ckpt
|
| 71 |
+
self.num_tokens = num_tokens
|
| 72 |
+
|
| 73 |
+
self.pipe = sd_pipe.to(self.device)
|
| 74 |
+
self.set_ip_adapter()
|
| 75 |
+
|
| 76 |
+
# load image encoder
|
| 77 |
+
self.image_encoder = CLIPVisionModelWithProjection.from_pretrained(self.image_encoder_path).to(
|
| 78 |
+
self.device, dtype=torch.float16
|
| 79 |
+
)
|
| 80 |
+
self.clip_image_processor = CLIPImageProcessor()
|
| 81 |
+
# image proj model
|
| 82 |
+
self.image_proj_model = self.init_proj()
|
| 83 |
+
|
| 84 |
+
self.load_ip_adapter()
|
| 85 |
+
|
| 86 |
+
def init_proj(self):
|
| 87 |
+
image_proj_model = ImageProjModel(
|
| 88 |
+
cross_attention_dim=self.pipe.unet.config.cross_attention_dim,
|
| 89 |
+
clip_embeddings_dim=self.image_encoder.config.projection_dim,
|
| 90 |
+
clip_extra_context_tokens=self.num_tokens,
|
| 91 |
+
).to(self.device, dtype=torch.float16)
|
| 92 |
+
return image_proj_model
|
| 93 |
+
|
| 94 |
+
def set_ip_adapter(self):
|
| 95 |
+
unet = self.pipe.unet
|
| 96 |
+
attn_procs = {}
|
| 97 |
+
for name in unet.attn_processors.keys():
|
| 98 |
+
cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
|
| 99 |
+
if name.startswith("mid_block"):
|
| 100 |
+
hidden_size = unet.config.block_out_channels[-1]
|
| 101 |
+
elif name.startswith("up_blocks"):
|
| 102 |
+
block_id = int(name[len("up_blocks.")])
|
| 103 |
+
hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
|
| 104 |
+
elif name.startswith("down_blocks"):
|
| 105 |
+
block_id = int(name[len("down_blocks.")])
|
| 106 |
+
hidden_size = unet.config.block_out_channels[block_id]
|
| 107 |
+
if cross_attention_dim is None:
|
| 108 |
+
attn_procs[name] = AttnProcessor()
|
| 109 |
+
else:
|
| 110 |
+
attn_procs[name] = IPAttnProcessor(
|
| 111 |
+
hidden_size=hidden_size,
|
| 112 |
+
cross_attention_dim=cross_attention_dim,
|
| 113 |
+
scale=1.0,
|
| 114 |
+
num_tokens=self.num_tokens,
|
| 115 |
+
).to(self.device, dtype=torch.float16)
|
| 116 |
+
unet.set_attn_processor(attn_procs)
|
| 117 |
+
if hasattr(self.pipe, "controlnet"):
|
| 118 |
+
if isinstance(self.pipe.controlnet, MultiControlNetModel):
|
| 119 |
+
for controlnet in self.pipe.controlnet.nets:
|
| 120 |
+
controlnet.set_attn_processor(CNAttnProcessor(num_tokens=self.num_tokens))
|
| 121 |
+
else:
|
| 122 |
+
self.pipe.controlnet.set_attn_processor(CNAttnProcessor(num_tokens=self.num_tokens))
|
| 123 |
+
|
| 124 |
+
def load_ip_adapter(self):
|
| 125 |
+
if os.path.splitext(self.ip_ckpt)[-1] == ".safetensors":
|
| 126 |
+
state_dict = {"image_proj": {}, "ip_adapter": {}}
|
| 127 |
+
with safe_open(self.ip_ckpt, framework="pt", device="cpu") as f:
|
| 128 |
+
for key in f.keys():
|
| 129 |
+
if key.startswith("image_proj."):
|
| 130 |
+
state_dict["image_proj"][key.replace("image_proj.", "")] = f.get_tensor(key)
|
| 131 |
+
elif key.startswith("ip_adapter."):
|
| 132 |
+
state_dict["ip_adapter"][key.replace("ip_adapter.", "")] = f.get_tensor(key)
|
| 133 |
+
else:
|
| 134 |
+
state_dict = torch.load(self.ip_ckpt, map_location="cpu")
|
| 135 |
+
self.image_proj_model.load_state_dict(state_dict["image_proj"])
|
| 136 |
+
ip_layers = torch.nn.ModuleList(self.pipe.unet.attn_processors.values())
|
| 137 |
+
ip_layers.load_state_dict(state_dict["ip_adapter"])
|
| 138 |
+
|
| 139 |
+
@torch.inference_mode()
|
| 140 |
+
def get_image_embeds(self, pil_image=None, clip_image_embeds=None):
|
| 141 |
+
if pil_image is not None:
|
| 142 |
+
if isinstance(pil_image, Image.Image):
|
| 143 |
+
pil_image = [pil_image]
|
| 144 |
+
clip_image = self.clip_image_processor(images=pil_image, return_tensors="pt").pixel_values
|
| 145 |
+
clip_image_embeds = self.image_encoder(clip_image.to(self.device, dtype=torch.float16)).image_embeds
|
| 146 |
+
else:
|
| 147 |
+
clip_image_embeds = clip_image_embeds.to(self.device, dtype=torch.float16)
|
| 148 |
+
image_prompt_embeds = self.image_proj_model(clip_image_embeds)
|
| 149 |
+
uncond_image_prompt_embeds = self.image_proj_model(torch.zeros_like(clip_image_embeds))
|
| 150 |
+
return image_prompt_embeds, uncond_image_prompt_embeds
|
| 151 |
+
|
| 152 |
+
def set_scale(self, scale):
|
| 153 |
+
for attn_processor in self.pipe.unet.attn_processors.values():
|
| 154 |
+
if isinstance(attn_processor, IPAttnProcessor):
|
| 155 |
+
attn_processor.scale = scale
|
| 156 |
+
|
| 157 |
+
def generate(
|
| 158 |
+
self,
|
| 159 |
+
pil_image=None,
|
| 160 |
+
clip_image_embeds=None,
|
| 161 |
+
prompt=None,
|
| 162 |
+
negative_prompt=None,
|
| 163 |
+
scale=1.0,
|
| 164 |
+
num_samples=4,
|
| 165 |
+
seed=None,
|
| 166 |
+
guidance_scale=7.5,
|
| 167 |
+
num_inference_steps=30,
|
| 168 |
+
**kwargs,
|
| 169 |
+
):
|
| 170 |
+
self.set_scale(scale)
|
| 171 |
+
|
| 172 |
+
if pil_image is not None:
|
| 173 |
+
num_prompts = 1 if isinstance(pil_image, Image.Image) else len(pil_image)
|
| 174 |
+
else:
|
| 175 |
+
num_prompts = clip_image_embeds.size(0)
|
| 176 |
+
|
| 177 |
+
if prompt is None:
|
| 178 |
+
prompt = "best quality, high quality"
|
| 179 |
+
if negative_prompt is None:
|
| 180 |
+
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
|
| 181 |
+
|
| 182 |
+
if not isinstance(prompt, List):
|
| 183 |
+
prompt = [prompt] * num_prompts
|
| 184 |
+
if not isinstance(negative_prompt, List):
|
| 185 |
+
negative_prompt = [negative_prompt] * num_prompts
|
| 186 |
+
|
| 187 |
+
image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(
|
| 188 |
+
pil_image=pil_image, clip_image_embeds=clip_image_embeds
|
| 189 |
+
)
|
| 190 |
+
bs_embed, seq_len, _ = image_prompt_embeds.shape
|
| 191 |
+
image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
|
| 192 |
+
image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 193 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
|
| 194 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 195 |
+
|
| 196 |
+
with torch.inference_mode():
|
| 197 |
+
prompt_embeds_, negative_prompt_embeds_ = self.pipe.encode_prompt(
|
| 198 |
+
prompt,
|
| 199 |
+
device=self.device,
|
| 200 |
+
num_images_per_prompt=num_samples,
|
| 201 |
+
do_classifier_free_guidance=True,
|
| 202 |
+
negative_prompt=negative_prompt,
|
| 203 |
+
)
|
| 204 |
+
prompt_embeds = torch.cat([prompt_embeds_, image_prompt_embeds], dim=1)
|
| 205 |
+
negative_prompt_embeds = torch.cat([negative_prompt_embeds_, uncond_image_prompt_embeds], dim=1)
|
| 206 |
+
|
| 207 |
+
generator = get_generator(seed, self.device)
|
| 208 |
+
|
| 209 |
+
images = self.pipe(
|
| 210 |
+
prompt_embeds=prompt_embeds,
|
| 211 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 212 |
+
guidance_scale=guidance_scale,
|
| 213 |
+
num_inference_steps=num_inference_steps,
|
| 214 |
+
generator=generator,
|
| 215 |
+
**kwargs,
|
| 216 |
+
).images
|
| 217 |
+
|
| 218 |
+
return images
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
class IPAdapterXL(IPAdapter):
|
| 222 |
+
"""SDXL"""
|
| 223 |
+
|
| 224 |
+
def generate(
|
| 225 |
+
self,
|
| 226 |
+
pil_image,
|
| 227 |
+
prompt=None,
|
| 228 |
+
negative_prompt=None,
|
| 229 |
+
scale=1.0,
|
| 230 |
+
num_samples=4,
|
| 231 |
+
seed=None,
|
| 232 |
+
num_inference_steps=30,
|
| 233 |
+
**kwargs,
|
| 234 |
+
):
|
| 235 |
+
self.set_scale(scale)
|
| 236 |
+
|
| 237 |
+
num_prompts = 1 if isinstance(pil_image, Image.Image) else len(pil_image)
|
| 238 |
+
|
| 239 |
+
if prompt is None:
|
| 240 |
+
prompt = "best quality, high quality"
|
| 241 |
+
if negative_prompt is None:
|
| 242 |
+
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
|
| 243 |
+
|
| 244 |
+
if not isinstance(prompt, List):
|
| 245 |
+
prompt = [prompt] * num_prompts
|
| 246 |
+
if not isinstance(negative_prompt, List):
|
| 247 |
+
negative_prompt = [negative_prompt] * num_prompts
|
| 248 |
+
|
| 249 |
+
image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(pil_image)
|
| 250 |
+
bs_embed, seq_len, _ = image_prompt_embeds.shape
|
| 251 |
+
image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
|
| 252 |
+
image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 253 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
|
| 254 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 255 |
+
|
| 256 |
+
with torch.inference_mode():
|
| 257 |
+
(
|
| 258 |
+
prompt_embeds,
|
| 259 |
+
negative_prompt_embeds,
|
| 260 |
+
pooled_prompt_embeds,
|
| 261 |
+
negative_pooled_prompt_embeds,
|
| 262 |
+
) = self.pipe.encode_prompt(
|
| 263 |
+
prompt,
|
| 264 |
+
num_images_per_prompt=num_samples,
|
| 265 |
+
do_classifier_free_guidance=True,
|
| 266 |
+
negative_prompt=negative_prompt,
|
| 267 |
+
)
|
| 268 |
+
prompt_embeds = torch.cat([prompt_embeds, image_prompt_embeds], dim=1)
|
| 269 |
+
negative_prompt_embeds = torch.cat([negative_prompt_embeds, uncond_image_prompt_embeds], dim=1)
|
| 270 |
+
|
| 271 |
+
self.generator = get_generator(seed, self.device)
|
| 272 |
+
|
| 273 |
+
images = self.pipe(
|
| 274 |
+
prompt_embeds=prompt_embeds,
|
| 275 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 276 |
+
pooled_prompt_embeds=pooled_prompt_embeds,
|
| 277 |
+
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
|
| 278 |
+
num_inference_steps=num_inference_steps,
|
| 279 |
+
generator=self.generator,
|
| 280 |
+
**kwargs,
|
| 281 |
+
).images
|
| 282 |
+
|
| 283 |
+
return images
|
| 284 |
+
|
| 285 |
+
|
| 286 |
+
class IPAdapterPlus(IPAdapter):
|
| 287 |
+
"""IP-Adapter with fine-grained features"""
|
| 288 |
+
|
| 289 |
+
def init_proj(self):
|
| 290 |
+
image_proj_model = Resampler(
|
| 291 |
+
dim=self.pipe.unet.config.cross_attention_dim,
|
| 292 |
+
depth=4,
|
| 293 |
+
dim_head=64,
|
| 294 |
+
heads=12,
|
| 295 |
+
num_queries=self.num_tokens,
|
| 296 |
+
embedding_dim=self.image_encoder.config.hidden_size,
|
| 297 |
+
output_dim=self.pipe.unet.config.cross_attention_dim,
|
| 298 |
+
ff_mult=4,
|
| 299 |
+
).to(self.device, dtype=torch.float16)
|
| 300 |
+
return image_proj_model
|
| 301 |
+
|
| 302 |
+
@torch.inference_mode()
|
| 303 |
+
def get_image_embeds(self, pil_image=None, clip_image_embeds=None):
|
| 304 |
+
if isinstance(pil_image, Image.Image):
|
| 305 |
+
pil_image = [pil_image]
|
| 306 |
+
clip_image = self.clip_image_processor(images=pil_image, return_tensors="pt").pixel_values
|
| 307 |
+
clip_image = clip_image.to(self.device, dtype=torch.float16)
|
| 308 |
+
clip_image_embeds = self.image_encoder(clip_image, output_hidden_states=True).hidden_states[-2]
|
| 309 |
+
image_prompt_embeds = self.image_proj_model(clip_image_embeds)
|
| 310 |
+
uncond_clip_image_embeds = self.image_encoder(
|
| 311 |
+
torch.zeros_like(clip_image), output_hidden_states=True
|
| 312 |
+
).hidden_states[-2]
|
| 313 |
+
uncond_image_prompt_embeds = self.image_proj_model(uncond_clip_image_embeds)
|
| 314 |
+
return image_prompt_embeds, uncond_image_prompt_embeds
|
| 315 |
+
|
| 316 |
+
|
| 317 |
+
class IPAdapterFull(IPAdapterPlus):
|
| 318 |
+
"""IP-Adapter with full features"""
|
| 319 |
+
|
| 320 |
+
def init_proj(self):
|
| 321 |
+
image_proj_model = MLPProjModel(
|
| 322 |
+
cross_attention_dim=self.pipe.unet.config.cross_attention_dim,
|
| 323 |
+
clip_embeddings_dim=self.image_encoder.config.hidden_size,
|
| 324 |
+
).to(self.device, dtype=torch.float16)
|
| 325 |
+
return image_proj_model
|
| 326 |
+
|
| 327 |
+
|
| 328 |
+
class IPAdapterPlusXL(IPAdapter):
|
| 329 |
+
"""SDXL"""
|
| 330 |
+
|
| 331 |
+
def init_proj(self):
|
| 332 |
+
image_proj_model = Resampler(
|
| 333 |
+
dim=1280,
|
| 334 |
+
depth=4,
|
| 335 |
+
dim_head=64,
|
| 336 |
+
heads=20,
|
| 337 |
+
num_queries=self.num_tokens,
|
| 338 |
+
embedding_dim=self.image_encoder.config.hidden_size,
|
| 339 |
+
output_dim=self.pipe.unet.config.cross_attention_dim,
|
| 340 |
+
ff_mult=4,
|
| 341 |
+
).to(self.device, dtype=torch.float16)
|
| 342 |
+
return image_proj_model
|
| 343 |
+
|
| 344 |
+
@torch.inference_mode()
|
| 345 |
+
def get_image_embeds(self, pil_image):
|
| 346 |
+
if isinstance(pil_image, Image.Image):
|
| 347 |
+
pil_image = [pil_image]
|
| 348 |
+
clip_image = self.clip_image_processor(images=pil_image, return_tensors="pt").pixel_values
|
| 349 |
+
clip_image = clip_image.to(self.device, dtype=torch.float16)
|
| 350 |
+
clip_image_embeds = self.image_encoder(clip_image, output_hidden_states=True).hidden_states[-2]
|
| 351 |
+
image_prompt_embeds = self.image_proj_model(clip_image_embeds)
|
| 352 |
+
uncond_clip_image_embeds = self.image_encoder(
|
| 353 |
+
torch.zeros_like(clip_image), output_hidden_states=True
|
| 354 |
+
).hidden_states[-2]
|
| 355 |
+
uncond_image_prompt_embeds = self.image_proj_model(uncond_clip_image_embeds)
|
| 356 |
+
return image_prompt_embeds, uncond_image_prompt_embeds
|
| 357 |
+
|
| 358 |
+
def generate(
|
| 359 |
+
self,
|
| 360 |
+
pil_image,
|
| 361 |
+
prompt=None,
|
| 362 |
+
negative_prompt=None,
|
| 363 |
+
scale=1.0,
|
| 364 |
+
num_samples=4,
|
| 365 |
+
seed=None,
|
| 366 |
+
num_inference_steps=30,
|
| 367 |
+
**kwargs,
|
| 368 |
+
):
|
| 369 |
+
self.set_scale(scale)
|
| 370 |
+
|
| 371 |
+
num_prompts = 1 if isinstance(pil_image, Image.Image) else len(pil_image)
|
| 372 |
+
|
| 373 |
+
if prompt is None:
|
| 374 |
+
prompt = "best quality, high quality"
|
| 375 |
+
if negative_prompt is None:
|
| 376 |
+
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
|
| 377 |
+
|
| 378 |
+
if not isinstance(prompt, List):
|
| 379 |
+
prompt = [prompt] * num_prompts
|
| 380 |
+
if not isinstance(negative_prompt, List):
|
| 381 |
+
negative_prompt = [negative_prompt] * num_prompts
|
| 382 |
+
|
| 383 |
+
image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(pil_image)
|
| 384 |
+
bs_embed, seq_len, _ = image_prompt_embeds.shape
|
| 385 |
+
image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
|
| 386 |
+
image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 387 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
|
| 388 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 389 |
+
|
| 390 |
+
with torch.inference_mode():
|
| 391 |
+
(
|
| 392 |
+
prompt_embeds,
|
| 393 |
+
negative_prompt_embeds,
|
| 394 |
+
pooled_prompt_embeds,
|
| 395 |
+
negative_pooled_prompt_embeds,
|
| 396 |
+
) = self.pipe.encode_prompt(
|
| 397 |
+
prompt,
|
| 398 |
+
num_images_per_prompt=num_samples,
|
| 399 |
+
do_classifier_free_guidance=True,
|
| 400 |
+
negative_prompt=negative_prompt,
|
| 401 |
+
)
|
| 402 |
+
prompt_embeds = torch.cat([prompt_embeds, image_prompt_embeds], dim=1)
|
| 403 |
+
negative_prompt_embeds = torch.cat([negative_prompt_embeds, uncond_image_prompt_embeds], dim=1)
|
| 404 |
+
|
| 405 |
+
generator = get_generator(seed, self.device)
|
| 406 |
+
|
| 407 |
+
images = self.pipe(
|
| 408 |
+
prompt_embeds=prompt_embeds,
|
| 409 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 410 |
+
pooled_prompt_embeds=pooled_prompt_embeds,
|
| 411 |
+
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
|
| 412 |
+
num_inference_steps=num_inference_steps,
|
| 413 |
+
generator=generator,
|
| 414 |
+
**kwargs,
|
| 415 |
+
).images
|
| 416 |
+
|
| 417 |
+
return images
|
ip_adapter/ip_adapter_faceid.py
ADDED
|
@@ -0,0 +1,542 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from typing import List
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from diffusers import StableDiffusionPipeline
|
| 6 |
+
from diffusers.pipelines.controlnet import MultiControlNetModel
|
| 7 |
+
from PIL import Image
|
| 8 |
+
from safetensors import safe_open
|
| 9 |
+
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
|
| 10 |
+
|
| 11 |
+
from .attention_processor_faceid import LoRAAttnProcessor, LoRAIPAttnProcessor
|
| 12 |
+
from .utils import is_torch2_available, get_generator
|
| 13 |
+
|
| 14 |
+
USE_DAFAULT_ATTN = False # should be True for visualization_attnmap
|
| 15 |
+
if is_torch2_available() and (not USE_DAFAULT_ATTN):
|
| 16 |
+
from .attention_processor_faceid import (
|
| 17 |
+
LoRAAttnProcessor2_0 as LoRAAttnProcessor,
|
| 18 |
+
)
|
| 19 |
+
from .attention_processor_faceid import (
|
| 20 |
+
LoRAIPAttnProcessor2_0 as LoRAIPAttnProcessor,
|
| 21 |
+
)
|
| 22 |
+
else:
|
| 23 |
+
from .attention_processor_faceid import LoRAAttnProcessor, LoRAIPAttnProcessor
|
| 24 |
+
from .resampler import PerceiverAttention, FeedForward
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class FacePerceiverResampler(torch.nn.Module):
|
| 28 |
+
def __init__(
|
| 29 |
+
self,
|
| 30 |
+
*,
|
| 31 |
+
dim=768,
|
| 32 |
+
depth=4,
|
| 33 |
+
dim_head=64,
|
| 34 |
+
heads=16,
|
| 35 |
+
embedding_dim=1280,
|
| 36 |
+
output_dim=768,
|
| 37 |
+
ff_mult=4,
|
| 38 |
+
):
|
| 39 |
+
super().__init__()
|
| 40 |
+
|
| 41 |
+
self.proj_in = torch.nn.Linear(embedding_dim, dim)
|
| 42 |
+
self.proj_out = torch.nn.Linear(dim, output_dim)
|
| 43 |
+
self.norm_out = torch.nn.LayerNorm(output_dim)
|
| 44 |
+
self.layers = torch.nn.ModuleList([])
|
| 45 |
+
for _ in range(depth):
|
| 46 |
+
self.layers.append(
|
| 47 |
+
torch.nn.ModuleList(
|
| 48 |
+
[
|
| 49 |
+
PerceiverAttention(dim=dim, dim_head=dim_head, heads=heads),
|
| 50 |
+
FeedForward(dim=dim, mult=ff_mult),
|
| 51 |
+
]
|
| 52 |
+
)
|
| 53 |
+
)
|
| 54 |
+
|
| 55 |
+
def forward(self, latents, x):
|
| 56 |
+
x = self.proj_in(x)
|
| 57 |
+
for attn, ff in self.layers:
|
| 58 |
+
latents = attn(x, latents) + latents
|
| 59 |
+
latents = ff(latents) + latents
|
| 60 |
+
latents = self.proj_out(latents)
|
| 61 |
+
return self.norm_out(latents)
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
class MLPProjModel(torch.nn.Module):
|
| 65 |
+
def __init__(self, cross_attention_dim=768, id_embeddings_dim=512, num_tokens=4):
|
| 66 |
+
super().__init__()
|
| 67 |
+
|
| 68 |
+
self.cross_attention_dim = cross_attention_dim
|
| 69 |
+
self.num_tokens = num_tokens
|
| 70 |
+
|
| 71 |
+
self.proj = torch.nn.Sequential(
|
| 72 |
+
torch.nn.Linear(id_embeddings_dim, id_embeddings_dim*2),
|
| 73 |
+
torch.nn.GELU(),
|
| 74 |
+
torch.nn.Linear(id_embeddings_dim*2, cross_attention_dim*num_tokens),
|
| 75 |
+
)
|
| 76 |
+
self.norm = torch.nn.LayerNorm(cross_attention_dim)
|
| 77 |
+
|
| 78 |
+
def forward(self, id_embeds):
|
| 79 |
+
x = self.proj(id_embeds)
|
| 80 |
+
x = x.reshape(-1, self.num_tokens, self.cross_attention_dim)
|
| 81 |
+
x = self.norm(x)
|
| 82 |
+
return x
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
class ProjPlusModel(torch.nn.Module):
|
| 86 |
+
def __init__(self, cross_attention_dim=768, id_embeddings_dim=512, clip_embeddings_dim=1280, num_tokens=4):
|
| 87 |
+
super().__init__()
|
| 88 |
+
|
| 89 |
+
self.cross_attention_dim = cross_attention_dim
|
| 90 |
+
self.num_tokens = num_tokens
|
| 91 |
+
|
| 92 |
+
self.proj = torch.nn.Sequential(
|
| 93 |
+
torch.nn.Linear(id_embeddings_dim, id_embeddings_dim*2),
|
| 94 |
+
torch.nn.GELU(),
|
| 95 |
+
torch.nn.Linear(id_embeddings_dim*2, cross_attention_dim*num_tokens),
|
| 96 |
+
)
|
| 97 |
+
self.norm = torch.nn.LayerNorm(cross_attention_dim)
|
| 98 |
+
|
| 99 |
+
self.perceiver_resampler = FacePerceiverResampler(
|
| 100 |
+
dim=cross_attention_dim,
|
| 101 |
+
depth=4,
|
| 102 |
+
dim_head=64,
|
| 103 |
+
heads=cross_attention_dim // 64,
|
| 104 |
+
embedding_dim=clip_embeddings_dim,
|
| 105 |
+
output_dim=cross_attention_dim,
|
| 106 |
+
ff_mult=4,
|
| 107 |
+
)
|
| 108 |
+
|
| 109 |
+
def forward(self, id_embeds, clip_embeds, shortcut=False, scale=1.0):
|
| 110 |
+
|
| 111 |
+
x = self.proj(id_embeds)
|
| 112 |
+
x = x.reshape(-1, self.num_tokens, self.cross_attention_dim)
|
| 113 |
+
x = self.norm(x)
|
| 114 |
+
out = self.perceiver_resampler(x, clip_embeds)
|
| 115 |
+
if shortcut:
|
| 116 |
+
out = x + scale * out
|
| 117 |
+
return out
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
class IPAdapterFaceID:
|
| 121 |
+
def __init__(self, sd_pipe, ip_ckpt, device, lora_rank=128, num_tokens=4, torch_dtype=torch.float16):
|
| 122 |
+
self.device = device
|
| 123 |
+
self.ip_ckpt = ip_ckpt
|
| 124 |
+
self.lora_rank = lora_rank
|
| 125 |
+
self.num_tokens = num_tokens
|
| 126 |
+
self.torch_dtype = torch_dtype
|
| 127 |
+
|
| 128 |
+
self.pipe = sd_pipe.to(self.device)
|
| 129 |
+
self.set_ip_adapter()
|
| 130 |
+
|
| 131 |
+
# image proj model
|
| 132 |
+
self.image_proj_model = self.init_proj()
|
| 133 |
+
|
| 134 |
+
self.load_ip_adapter()
|
| 135 |
+
|
| 136 |
+
def init_proj(self):
|
| 137 |
+
image_proj_model = MLPProjModel(
|
| 138 |
+
cross_attention_dim=self.pipe.unet.config.cross_attention_dim,
|
| 139 |
+
id_embeddings_dim=512,
|
| 140 |
+
num_tokens=self.num_tokens,
|
| 141 |
+
).to(self.device, dtype=self.torch_dtype)
|
| 142 |
+
return image_proj_model
|
| 143 |
+
|
| 144 |
+
def set_ip_adapter(self):
|
| 145 |
+
unet = self.pipe.unet
|
| 146 |
+
attn_procs = {}
|
| 147 |
+
for name in unet.attn_processors.keys():
|
| 148 |
+
cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
|
| 149 |
+
if name.startswith("mid_block"):
|
| 150 |
+
hidden_size = unet.config.block_out_channels[-1]
|
| 151 |
+
elif name.startswith("up_blocks"):
|
| 152 |
+
block_id = int(name[len("up_blocks.")])
|
| 153 |
+
hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
|
| 154 |
+
elif name.startswith("down_blocks"):
|
| 155 |
+
block_id = int(name[len("down_blocks.")])
|
| 156 |
+
hidden_size = unet.config.block_out_channels[block_id]
|
| 157 |
+
if cross_attention_dim is None:
|
| 158 |
+
attn_procs[name] = LoRAAttnProcessor(
|
| 159 |
+
hidden_size=hidden_size, cross_attention_dim=cross_attention_dim, rank=self.lora_rank,
|
| 160 |
+
).to(self.device, dtype=self.torch_dtype)
|
| 161 |
+
else:
|
| 162 |
+
attn_procs[name] = LoRAIPAttnProcessor(
|
| 163 |
+
hidden_size=hidden_size, cross_attention_dim=cross_attention_dim, scale=1.0, rank=self.lora_rank, num_tokens=self.num_tokens,
|
| 164 |
+
).to(self.device, dtype=self.torch_dtype)
|
| 165 |
+
unet.set_attn_processor(attn_procs)
|
| 166 |
+
|
| 167 |
+
def load_ip_adapter(self):
|
| 168 |
+
if os.path.splitext(self.ip_ckpt)[-1] == ".safetensors":
|
| 169 |
+
state_dict = {"image_proj": {}, "ip_adapter": {}}
|
| 170 |
+
with safe_open(self.ip_ckpt, framework="pt", device="cpu") as f:
|
| 171 |
+
for key in f.keys():
|
| 172 |
+
if key.startswith("image_proj."):
|
| 173 |
+
state_dict["image_proj"][key.replace("image_proj.", "")] = f.get_tensor(key)
|
| 174 |
+
elif key.startswith("ip_adapter."):
|
| 175 |
+
state_dict["ip_adapter"][key.replace("ip_adapter.", "")] = f.get_tensor(key)
|
| 176 |
+
else:
|
| 177 |
+
state_dict = torch.load(self.ip_ckpt, map_location="cpu")
|
| 178 |
+
self.image_proj_model.load_state_dict(state_dict["image_proj"])
|
| 179 |
+
ip_layers = torch.nn.ModuleList(self.pipe.unet.attn_processors.values())
|
| 180 |
+
ip_layers.load_state_dict(state_dict["ip_adapter"])
|
| 181 |
+
|
| 182 |
+
@torch.inference_mode()
|
| 183 |
+
def get_image_embeds(self, faceid_embeds):
|
| 184 |
+
|
| 185 |
+
faceid_embeds = faceid_embeds.to(self.device, dtype=self.torch_dtype)
|
| 186 |
+
image_prompt_embeds = self.image_proj_model(faceid_embeds)
|
| 187 |
+
uncond_image_prompt_embeds = self.image_proj_model(torch.zeros_like(faceid_embeds))
|
| 188 |
+
return image_prompt_embeds, uncond_image_prompt_embeds
|
| 189 |
+
|
| 190 |
+
def set_scale(self, scale):
|
| 191 |
+
for attn_processor in self.pipe.unet.attn_processors.values():
|
| 192 |
+
if isinstance(attn_processor, LoRAIPAttnProcessor):
|
| 193 |
+
attn_processor.scale = scale
|
| 194 |
+
|
| 195 |
+
def generate(
|
| 196 |
+
self,
|
| 197 |
+
faceid_embeds=None,
|
| 198 |
+
prompt=None,
|
| 199 |
+
negative_prompt=None,
|
| 200 |
+
scale=1.0,
|
| 201 |
+
num_samples=4,
|
| 202 |
+
seed=None,
|
| 203 |
+
guidance_scale=7.5,
|
| 204 |
+
num_inference_steps=30,
|
| 205 |
+
**kwargs,
|
| 206 |
+
):
|
| 207 |
+
self.set_scale(scale)
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
num_prompts = faceid_embeds.size(0)
|
| 211 |
+
|
| 212 |
+
if prompt is None:
|
| 213 |
+
prompt = "best quality, high quality"
|
| 214 |
+
if negative_prompt is None:
|
| 215 |
+
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
|
| 216 |
+
|
| 217 |
+
if not isinstance(prompt, List):
|
| 218 |
+
prompt = [prompt] * num_prompts
|
| 219 |
+
if not isinstance(negative_prompt, List):
|
| 220 |
+
negative_prompt = [negative_prompt] * num_prompts
|
| 221 |
+
|
| 222 |
+
image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(faceid_embeds)
|
| 223 |
+
|
| 224 |
+
bs_embed, seq_len, _ = image_prompt_embeds.shape
|
| 225 |
+
image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
|
| 226 |
+
image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 227 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
|
| 228 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 229 |
+
|
| 230 |
+
with torch.inference_mode():
|
| 231 |
+
prompt_embeds_, negative_prompt_embeds_ = self.pipe.encode_prompt(
|
| 232 |
+
prompt,
|
| 233 |
+
device=self.device,
|
| 234 |
+
num_images_per_prompt=num_samples,
|
| 235 |
+
do_classifier_free_guidance=True,
|
| 236 |
+
negative_prompt=negative_prompt,
|
| 237 |
+
)
|
| 238 |
+
prompt_embeds = torch.cat([prompt_embeds_, image_prompt_embeds], dim=1)
|
| 239 |
+
negative_prompt_embeds = torch.cat([negative_prompt_embeds_, uncond_image_prompt_embeds], dim=1)
|
| 240 |
+
|
| 241 |
+
generator = get_generator(seed, self.device)
|
| 242 |
+
|
| 243 |
+
images = self.pipe(
|
| 244 |
+
prompt_embeds=prompt_embeds,
|
| 245 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 246 |
+
guidance_scale=guidance_scale,
|
| 247 |
+
num_inference_steps=num_inference_steps,
|
| 248 |
+
generator=generator,
|
| 249 |
+
**kwargs,
|
| 250 |
+
).images
|
| 251 |
+
|
| 252 |
+
return images
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
class IPAdapterFaceIDPlus:
|
| 256 |
+
def __init__(self, sd_pipe, image_encoder_path, ip_ckpt, device, lora_rank=128, num_tokens=4, torch_dtype=torch.float16):
|
| 257 |
+
self.device = device
|
| 258 |
+
self.image_encoder_path = image_encoder_path
|
| 259 |
+
self.ip_ckpt = ip_ckpt
|
| 260 |
+
self.lora_rank = lora_rank
|
| 261 |
+
self.num_tokens = num_tokens
|
| 262 |
+
self.torch_dtype = torch_dtype
|
| 263 |
+
|
| 264 |
+
self.pipe = sd_pipe.to(self.device)
|
| 265 |
+
self.set_ip_adapter()
|
| 266 |
+
|
| 267 |
+
# load image encoder
|
| 268 |
+
self.image_encoder = CLIPVisionModelWithProjection.from_pretrained(self.image_encoder_path).to(
|
| 269 |
+
self.device, dtype=self.torch_dtype
|
| 270 |
+
)
|
| 271 |
+
self.clip_image_processor = CLIPImageProcessor()
|
| 272 |
+
# image proj model
|
| 273 |
+
self.image_proj_model = self.init_proj()
|
| 274 |
+
|
| 275 |
+
self.load_ip_adapter()
|
| 276 |
+
|
| 277 |
+
def init_proj(self):
|
| 278 |
+
image_proj_model = ProjPlusModel(
|
| 279 |
+
cross_attention_dim=self.pipe.unet.config.cross_attention_dim,
|
| 280 |
+
id_embeddings_dim=512,
|
| 281 |
+
clip_embeddings_dim=self.image_encoder.config.hidden_size,
|
| 282 |
+
num_tokens=self.num_tokens,
|
| 283 |
+
).to(self.device, dtype=self.torch_dtype)
|
| 284 |
+
return image_proj_model
|
| 285 |
+
|
| 286 |
+
def set_ip_adapter(self):
|
| 287 |
+
unet = self.pipe.unet
|
| 288 |
+
attn_procs = {}
|
| 289 |
+
for name in unet.attn_processors.keys():
|
| 290 |
+
cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
|
| 291 |
+
if name.startswith("mid_block"):
|
| 292 |
+
hidden_size = unet.config.block_out_channels[-1]
|
| 293 |
+
elif name.startswith("up_blocks"):
|
| 294 |
+
block_id = int(name[len("up_blocks.")])
|
| 295 |
+
hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
|
| 296 |
+
elif name.startswith("down_blocks"):
|
| 297 |
+
block_id = int(name[len("down_blocks.")])
|
| 298 |
+
hidden_size = unet.config.block_out_channels[block_id]
|
| 299 |
+
if cross_attention_dim is None:
|
| 300 |
+
attn_procs[name] = LoRAAttnProcessor(
|
| 301 |
+
hidden_size=hidden_size, cross_attention_dim=cross_attention_dim, rank=self.lora_rank,
|
| 302 |
+
).to(self.device, dtype=self.torch_dtype)
|
| 303 |
+
else:
|
| 304 |
+
attn_procs[name] = LoRAIPAttnProcessor(
|
| 305 |
+
hidden_size=hidden_size, cross_attention_dim=cross_attention_dim, scale=1.0, rank=self.lora_rank, num_tokens=self.num_tokens,
|
| 306 |
+
).to(self.device, dtype=self.torch_dtype)
|
| 307 |
+
unet.set_attn_processor(attn_procs)
|
| 308 |
+
|
| 309 |
+
def load_ip_adapter(self):
|
| 310 |
+
if os.path.splitext(self.ip_ckpt)[-1] == ".safetensors":
|
| 311 |
+
state_dict = {"image_proj": {}, "ip_adapter": {}}
|
| 312 |
+
with safe_open(self.ip_ckpt, framework="pt", device="cpu") as f:
|
| 313 |
+
for key in f.keys():
|
| 314 |
+
if key.startswith("image_proj."):
|
| 315 |
+
state_dict["image_proj"][key.replace("image_proj.", "")] = f.get_tensor(key)
|
| 316 |
+
elif key.startswith("ip_adapter."):
|
| 317 |
+
state_dict["ip_adapter"][key.replace("ip_adapter.", "")] = f.get_tensor(key)
|
| 318 |
+
else:
|
| 319 |
+
state_dict = torch.load(self.ip_ckpt, map_location="cpu")
|
| 320 |
+
self.image_proj_model.load_state_dict(state_dict["image_proj"])
|
| 321 |
+
ip_layers = torch.nn.ModuleList(self.pipe.unet.attn_processors.values())
|
| 322 |
+
ip_layers.load_state_dict(state_dict["ip_adapter"])
|
| 323 |
+
|
| 324 |
+
@torch.inference_mode()
|
| 325 |
+
def get_image_embeds(self, faceid_embeds, face_image, s_scale, shortcut):
|
| 326 |
+
if isinstance(face_image, Image.Image):
|
| 327 |
+
pil_image = [face_image]
|
| 328 |
+
clip_image = self.clip_image_processor(images=face_image, return_tensors="pt").pixel_values
|
| 329 |
+
clip_image = clip_image.to(self.device, dtype=self.torch_dtype)
|
| 330 |
+
clip_image_embeds = self.image_encoder(clip_image, output_hidden_states=True).hidden_states[-2]
|
| 331 |
+
uncond_clip_image_embeds = self.image_encoder(
|
| 332 |
+
torch.zeros_like(clip_image), output_hidden_states=True
|
| 333 |
+
).hidden_states[-2]
|
| 334 |
+
|
| 335 |
+
faceid_embeds = faceid_embeds.to(self.device, dtype=self.torch_dtype)
|
| 336 |
+
image_prompt_embeds = self.image_proj_model(faceid_embeds, clip_image_embeds, shortcut=shortcut, scale=s_scale)
|
| 337 |
+
uncond_image_prompt_embeds = self.image_proj_model(torch.zeros_like(faceid_embeds), uncond_clip_image_embeds, shortcut=shortcut, scale=s_scale)
|
| 338 |
+
return image_prompt_embeds, uncond_image_prompt_embeds
|
| 339 |
+
|
| 340 |
+
def set_scale(self, scale):
|
| 341 |
+
for attn_processor in self.pipe.unet.attn_processors.values():
|
| 342 |
+
if isinstance(attn_processor, LoRAIPAttnProcessor):
|
| 343 |
+
attn_processor.scale = scale
|
| 344 |
+
|
| 345 |
+
def generate(
|
| 346 |
+
self,
|
| 347 |
+
face_image=None,
|
| 348 |
+
faceid_embeds=None,
|
| 349 |
+
prompt=None,
|
| 350 |
+
negative_prompt=None,
|
| 351 |
+
scale=1.0,
|
| 352 |
+
num_samples=4,
|
| 353 |
+
seed=None,
|
| 354 |
+
guidance_scale=7.5,
|
| 355 |
+
num_inference_steps=30,
|
| 356 |
+
s_scale=1.0,
|
| 357 |
+
shortcut=False,
|
| 358 |
+
**kwargs,
|
| 359 |
+
):
|
| 360 |
+
self.set_scale(scale)
|
| 361 |
+
|
| 362 |
+
|
| 363 |
+
num_prompts = faceid_embeds.size(0)
|
| 364 |
+
|
| 365 |
+
if prompt is None:
|
| 366 |
+
prompt = "best quality, high quality"
|
| 367 |
+
if negative_prompt is None:
|
| 368 |
+
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
|
| 369 |
+
|
| 370 |
+
if not isinstance(prompt, List):
|
| 371 |
+
prompt = [prompt] * num_prompts
|
| 372 |
+
if not isinstance(negative_prompt, List):
|
| 373 |
+
negative_prompt = [negative_prompt] * num_prompts
|
| 374 |
+
|
| 375 |
+
image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(faceid_embeds, face_image, s_scale, shortcut)
|
| 376 |
+
|
| 377 |
+
bs_embed, seq_len, _ = image_prompt_embeds.shape
|
| 378 |
+
image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
|
| 379 |
+
image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 380 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
|
| 381 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 382 |
+
|
| 383 |
+
with torch.inference_mode():
|
| 384 |
+
prompt_embeds_, negative_prompt_embeds_ = self.pipe.encode_prompt(
|
| 385 |
+
prompt,
|
| 386 |
+
device=self.device,
|
| 387 |
+
num_images_per_prompt=num_samples,
|
| 388 |
+
do_classifier_free_guidance=True,
|
| 389 |
+
negative_prompt=negative_prompt,
|
| 390 |
+
)
|
| 391 |
+
prompt_embeds = torch.cat([prompt_embeds_, image_prompt_embeds], dim=1)
|
| 392 |
+
negative_prompt_embeds = torch.cat([negative_prompt_embeds_, uncond_image_prompt_embeds], dim=1)
|
| 393 |
+
|
| 394 |
+
generator = get_generator(seed, self.device)
|
| 395 |
+
|
| 396 |
+
images = self.pipe(
|
| 397 |
+
prompt_embeds=prompt_embeds,
|
| 398 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 399 |
+
guidance_scale=guidance_scale,
|
| 400 |
+
num_inference_steps=num_inference_steps,
|
| 401 |
+
generator=generator,
|
| 402 |
+
**kwargs,
|
| 403 |
+
).images
|
| 404 |
+
|
| 405 |
+
return images
|
| 406 |
+
|
| 407 |
+
|
| 408 |
+
class IPAdapterFaceIDXL(IPAdapterFaceID):
|
| 409 |
+
"""SDXL"""
|
| 410 |
+
|
| 411 |
+
def generate(
|
| 412 |
+
self,
|
| 413 |
+
faceid_embeds=None,
|
| 414 |
+
prompt=None,
|
| 415 |
+
negative_prompt=None,
|
| 416 |
+
scale=1.0,
|
| 417 |
+
num_samples=4,
|
| 418 |
+
seed=None,
|
| 419 |
+
num_inference_steps=30,
|
| 420 |
+
**kwargs,
|
| 421 |
+
):
|
| 422 |
+
self.set_scale(scale)
|
| 423 |
+
|
| 424 |
+
num_prompts = faceid_embeds.size(0)
|
| 425 |
+
|
| 426 |
+
if prompt is None:
|
| 427 |
+
prompt = "best quality, high quality"
|
| 428 |
+
if negative_prompt is None:
|
| 429 |
+
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
|
| 430 |
+
|
| 431 |
+
if not isinstance(prompt, List):
|
| 432 |
+
prompt = [prompt] * num_prompts
|
| 433 |
+
if not isinstance(negative_prompt, List):
|
| 434 |
+
negative_prompt = [negative_prompt] * num_prompts
|
| 435 |
+
|
| 436 |
+
image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(faceid_embeds)
|
| 437 |
+
|
| 438 |
+
bs_embed, seq_len, _ = image_prompt_embeds.shape
|
| 439 |
+
image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
|
| 440 |
+
image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 441 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
|
| 442 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 443 |
+
|
| 444 |
+
with torch.inference_mode():
|
| 445 |
+
(
|
| 446 |
+
prompt_embeds,
|
| 447 |
+
negative_prompt_embeds,
|
| 448 |
+
pooled_prompt_embeds,
|
| 449 |
+
negative_pooled_prompt_embeds,
|
| 450 |
+
) = self.pipe.encode_prompt(
|
| 451 |
+
prompt,
|
| 452 |
+
num_images_per_prompt=num_samples,
|
| 453 |
+
do_classifier_free_guidance=True,
|
| 454 |
+
negative_prompt=negative_prompt,
|
| 455 |
+
)
|
| 456 |
+
prompt_embeds = torch.cat([prompt_embeds, image_prompt_embeds], dim=1)
|
| 457 |
+
negative_prompt_embeds = torch.cat([negative_prompt_embeds, uncond_image_prompt_embeds], dim=1)
|
| 458 |
+
|
| 459 |
+
generator = get_generator(seed, self.device)
|
| 460 |
+
|
| 461 |
+
images = self.pipe(
|
| 462 |
+
prompt_embeds=prompt_embeds,
|
| 463 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 464 |
+
pooled_prompt_embeds=pooled_prompt_embeds,
|
| 465 |
+
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
|
| 466 |
+
num_inference_steps=num_inference_steps,
|
| 467 |
+
generator=generator,
|
| 468 |
+
**kwargs,
|
| 469 |
+
).images
|
| 470 |
+
|
| 471 |
+
return images
|
| 472 |
+
|
| 473 |
+
|
| 474 |
+
class IPAdapterFaceIDPlusXL(IPAdapterFaceIDPlus):
|
| 475 |
+
"""SDXL"""
|
| 476 |
+
|
| 477 |
+
def generate(
|
| 478 |
+
self,
|
| 479 |
+
face_image=None,
|
| 480 |
+
faceid_embeds=None,
|
| 481 |
+
prompt=None,
|
| 482 |
+
negative_prompt=None,
|
| 483 |
+
scale=1.0,
|
| 484 |
+
num_samples=4,
|
| 485 |
+
seed=None,
|
| 486 |
+
guidance_scale=7.5,
|
| 487 |
+
num_inference_steps=30,
|
| 488 |
+
s_scale=1.0,
|
| 489 |
+
shortcut=True,
|
| 490 |
+
**kwargs,
|
| 491 |
+
):
|
| 492 |
+
self.set_scale(scale)
|
| 493 |
+
|
| 494 |
+
num_prompts = faceid_embeds.size(0)
|
| 495 |
+
|
| 496 |
+
if prompt is None:
|
| 497 |
+
prompt = "best quality, high quality"
|
| 498 |
+
if negative_prompt is None:
|
| 499 |
+
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
|
| 500 |
+
|
| 501 |
+
if not isinstance(prompt, List):
|
| 502 |
+
prompt = [prompt] * num_prompts
|
| 503 |
+
if not isinstance(negative_prompt, List):
|
| 504 |
+
negative_prompt = [negative_prompt] * num_prompts
|
| 505 |
+
|
| 506 |
+
image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(faceid_embeds, face_image, s_scale, shortcut)
|
| 507 |
+
|
| 508 |
+
bs_embed, seq_len, _ = image_prompt_embeds.shape
|
| 509 |
+
image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
|
| 510 |
+
image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 511 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
|
| 512 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 513 |
+
|
| 514 |
+
with torch.inference_mode():
|
| 515 |
+
(
|
| 516 |
+
prompt_embeds,
|
| 517 |
+
negative_prompt_embeds,
|
| 518 |
+
pooled_prompt_embeds,
|
| 519 |
+
negative_pooled_prompt_embeds,
|
| 520 |
+
) = self.pipe.encode_prompt(
|
| 521 |
+
prompt,
|
| 522 |
+
num_images_per_prompt=num_samples,
|
| 523 |
+
do_classifier_free_guidance=True,
|
| 524 |
+
negative_prompt=negative_prompt,
|
| 525 |
+
)
|
| 526 |
+
prompt_embeds = torch.cat([prompt_embeds, image_prompt_embeds], dim=1)
|
| 527 |
+
negative_prompt_embeds = torch.cat([negative_prompt_embeds, uncond_image_prompt_embeds], dim=1)
|
| 528 |
+
|
| 529 |
+
generator = get_generator(seed, self.device)
|
| 530 |
+
|
| 531 |
+
images = self.pipe(
|
| 532 |
+
prompt_embeds=prompt_embeds,
|
| 533 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 534 |
+
pooled_prompt_embeds=pooled_prompt_embeds,
|
| 535 |
+
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
|
| 536 |
+
num_inference_steps=num_inference_steps,
|
| 537 |
+
generator=generator,
|
| 538 |
+
guidance_scale=guidance_scale,
|
| 539 |
+
**kwargs,
|
| 540 |
+
).images
|
| 541 |
+
|
| 542 |
+
return images
|
ip_adapter/ip_adapter_faceid_separate.py
ADDED
|
@@ -0,0 +1,547 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from typing import List
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from diffusers import StableDiffusionPipeline
|
| 6 |
+
from diffusers.pipelines.controlnet import MultiControlNetModel
|
| 7 |
+
from PIL import Image
|
| 8 |
+
from safetensors import safe_open
|
| 9 |
+
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
|
| 10 |
+
|
| 11 |
+
from .utils import is_torch2_available, get_generator
|
| 12 |
+
|
| 13 |
+
USE_DAFAULT_ATTN = False # should be True for visualization_attnmap
|
| 14 |
+
if is_torch2_available() and (not USE_DAFAULT_ATTN):
|
| 15 |
+
from .attention_processor import (
|
| 16 |
+
AttnProcessor2_0 as AttnProcessor,
|
| 17 |
+
)
|
| 18 |
+
from .attention_processor import (
|
| 19 |
+
IPAttnProcessor2_0 as IPAttnProcessor,
|
| 20 |
+
)
|
| 21 |
+
else:
|
| 22 |
+
from .attention_processor import AttnProcessor, IPAttnProcessor
|
| 23 |
+
from .resampler import PerceiverAttention, FeedForward
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class FacePerceiverResampler(torch.nn.Module):
|
| 27 |
+
def __init__(
|
| 28 |
+
self,
|
| 29 |
+
*,
|
| 30 |
+
dim=768,
|
| 31 |
+
depth=4,
|
| 32 |
+
dim_head=64,
|
| 33 |
+
heads=16,
|
| 34 |
+
embedding_dim=1280,
|
| 35 |
+
output_dim=768,
|
| 36 |
+
ff_mult=4,
|
| 37 |
+
):
|
| 38 |
+
super().__init__()
|
| 39 |
+
|
| 40 |
+
self.proj_in = torch.nn.Linear(embedding_dim, dim)
|
| 41 |
+
self.proj_out = torch.nn.Linear(dim, output_dim)
|
| 42 |
+
self.norm_out = torch.nn.LayerNorm(output_dim)
|
| 43 |
+
self.layers = torch.nn.ModuleList([])
|
| 44 |
+
for _ in range(depth):
|
| 45 |
+
self.layers.append(
|
| 46 |
+
torch.nn.ModuleList(
|
| 47 |
+
[
|
| 48 |
+
PerceiverAttention(dim=dim, dim_head=dim_head, heads=heads),
|
| 49 |
+
FeedForward(dim=dim, mult=ff_mult),
|
| 50 |
+
]
|
| 51 |
+
)
|
| 52 |
+
)
|
| 53 |
+
|
| 54 |
+
def forward(self, latents, x):
|
| 55 |
+
x = self.proj_in(x)
|
| 56 |
+
for attn, ff in self.layers:
|
| 57 |
+
latents = attn(x, latents) + latents
|
| 58 |
+
latents = ff(latents) + latents
|
| 59 |
+
latents = self.proj_out(latents)
|
| 60 |
+
return self.norm_out(latents)
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
class MLPProjModel(torch.nn.Module):
|
| 64 |
+
def __init__(self, cross_attention_dim=768, id_embeddings_dim=512, num_tokens=4):
|
| 65 |
+
super().__init__()
|
| 66 |
+
|
| 67 |
+
self.cross_attention_dim = cross_attention_dim
|
| 68 |
+
self.num_tokens = num_tokens
|
| 69 |
+
|
| 70 |
+
self.proj = torch.nn.Sequential(
|
| 71 |
+
torch.nn.Linear(id_embeddings_dim, id_embeddings_dim*2),
|
| 72 |
+
torch.nn.GELU(),
|
| 73 |
+
torch.nn.Linear(id_embeddings_dim*2, cross_attention_dim*num_tokens),
|
| 74 |
+
)
|
| 75 |
+
self.norm = torch.nn.LayerNorm(cross_attention_dim)
|
| 76 |
+
|
| 77 |
+
def forward(self, id_embeds):
|
| 78 |
+
x = self.proj(id_embeds)
|
| 79 |
+
x = x.reshape(-1, self.num_tokens, self.cross_attention_dim)
|
| 80 |
+
x = self.norm(x)
|
| 81 |
+
return x
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
class ProjPlusModel(torch.nn.Module):
|
| 85 |
+
def __init__(self, cross_attention_dim=768, id_embeddings_dim=512, clip_embeddings_dim=1280, num_tokens=4):
|
| 86 |
+
super().__init__()
|
| 87 |
+
|
| 88 |
+
self.cross_attention_dim = cross_attention_dim
|
| 89 |
+
self.num_tokens = num_tokens
|
| 90 |
+
|
| 91 |
+
self.proj = torch.nn.Sequential(
|
| 92 |
+
torch.nn.Linear(id_embeddings_dim, id_embeddings_dim*2),
|
| 93 |
+
torch.nn.GELU(),
|
| 94 |
+
torch.nn.Linear(id_embeddings_dim*2, cross_attention_dim*num_tokens),
|
| 95 |
+
)
|
| 96 |
+
self.norm = torch.nn.LayerNorm(cross_attention_dim)
|
| 97 |
+
|
| 98 |
+
self.perceiver_resampler = FacePerceiverResampler(
|
| 99 |
+
dim=cross_attention_dim,
|
| 100 |
+
depth=4,
|
| 101 |
+
dim_head=64,
|
| 102 |
+
heads=cross_attention_dim // 64,
|
| 103 |
+
embedding_dim=clip_embeddings_dim,
|
| 104 |
+
output_dim=cross_attention_dim,
|
| 105 |
+
ff_mult=4,
|
| 106 |
+
)
|
| 107 |
+
|
| 108 |
+
def forward(self, id_embeds, clip_embeds, shortcut=False, scale=1.0):
|
| 109 |
+
|
| 110 |
+
x = self.proj(id_embeds)
|
| 111 |
+
x = x.reshape(-1, self.num_tokens, self.cross_attention_dim)
|
| 112 |
+
x = self.norm(x)
|
| 113 |
+
out = self.perceiver_resampler(x, clip_embeds)
|
| 114 |
+
if shortcut:
|
| 115 |
+
out = x + scale * out
|
| 116 |
+
return out
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
class IPAdapterFaceID:
|
| 120 |
+
def __init__(self, sd_pipe, ip_ckpt, device, num_tokens=4, n_cond=1, torch_dtype=torch.float16):
|
| 121 |
+
self.device = device
|
| 122 |
+
self.ip_ckpt = ip_ckpt
|
| 123 |
+
self.num_tokens = num_tokens
|
| 124 |
+
self.n_cond = n_cond
|
| 125 |
+
self.torch_dtype = torch_dtype
|
| 126 |
+
|
| 127 |
+
self.pipe = sd_pipe.to(self.device)
|
| 128 |
+
self.set_ip_adapter()
|
| 129 |
+
|
| 130 |
+
# image proj model
|
| 131 |
+
self.image_proj_model = self.init_proj()
|
| 132 |
+
|
| 133 |
+
self.load_ip_adapter()
|
| 134 |
+
|
| 135 |
+
def init_proj(self):
|
| 136 |
+
image_proj_model = MLPProjModel(
|
| 137 |
+
cross_attention_dim=self.pipe.unet.config.cross_attention_dim,
|
| 138 |
+
id_embeddings_dim=512,
|
| 139 |
+
num_tokens=self.num_tokens,
|
| 140 |
+
).to(self.device, dtype=self.torch_dtype)
|
| 141 |
+
return image_proj_model
|
| 142 |
+
|
| 143 |
+
def set_ip_adapter(self):
|
| 144 |
+
unet = self.pipe.unet
|
| 145 |
+
attn_procs = {}
|
| 146 |
+
for name in unet.attn_processors.keys():
|
| 147 |
+
cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
|
| 148 |
+
if name.startswith("mid_block"):
|
| 149 |
+
hidden_size = unet.config.block_out_channels[-1]
|
| 150 |
+
elif name.startswith("up_blocks"):
|
| 151 |
+
block_id = int(name[len("up_blocks.")])
|
| 152 |
+
hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
|
| 153 |
+
elif name.startswith("down_blocks"):
|
| 154 |
+
block_id = int(name[len("down_blocks.")])
|
| 155 |
+
hidden_size = unet.config.block_out_channels[block_id]
|
| 156 |
+
if cross_attention_dim is None:
|
| 157 |
+
attn_procs[name] = AttnProcessor()
|
| 158 |
+
else:
|
| 159 |
+
attn_procs[name] = IPAttnProcessor(
|
| 160 |
+
hidden_size=hidden_size, cross_attention_dim=cross_attention_dim, scale=1.0, num_tokens=self.num_tokens*self.n_cond,
|
| 161 |
+
).to(self.device, dtype=self.torch_dtype)
|
| 162 |
+
unet.set_attn_processor(attn_procs)
|
| 163 |
+
|
| 164 |
+
def load_ip_adapter(self):
|
| 165 |
+
if os.path.splitext(self.ip_ckpt)[-1] == ".safetensors":
|
| 166 |
+
state_dict = {"image_proj": {}, "ip_adapter": {}}
|
| 167 |
+
with safe_open(self.ip_ckpt, framework="pt", device="cpu") as f:
|
| 168 |
+
for key in f.keys():
|
| 169 |
+
if key.startswith("image_proj."):
|
| 170 |
+
state_dict["image_proj"][key.replace("image_proj.", "")] = f.get_tensor(key)
|
| 171 |
+
elif key.startswith("ip_adapter."):
|
| 172 |
+
state_dict["ip_adapter"][key.replace("ip_adapter.", "")] = f.get_tensor(key)
|
| 173 |
+
else:
|
| 174 |
+
state_dict = torch.load(self.ip_ckpt, map_location="cpu")
|
| 175 |
+
self.image_proj_model.load_state_dict(state_dict["image_proj"])
|
| 176 |
+
ip_layers = torch.nn.ModuleList(self.pipe.unet.attn_processors.values())
|
| 177 |
+
ip_layers.load_state_dict(state_dict["ip_adapter"], strict=False)
|
| 178 |
+
|
| 179 |
+
@torch.inference_mode()
|
| 180 |
+
def get_image_embeds(self, faceid_embeds):
|
| 181 |
+
|
| 182 |
+
multi_face = False
|
| 183 |
+
if faceid_embeds.dim() == 3:
|
| 184 |
+
multi_face = True
|
| 185 |
+
b, n, c = faceid_embeds.shape
|
| 186 |
+
faceid_embeds = faceid_embeds.reshape(b*n, c)
|
| 187 |
+
|
| 188 |
+
faceid_embeds = faceid_embeds.to(self.device, dtype=self.torch_dtype)
|
| 189 |
+
image_prompt_embeds = self.image_proj_model(faceid_embeds)
|
| 190 |
+
uncond_image_prompt_embeds = self.image_proj_model(torch.zeros_like(faceid_embeds))
|
| 191 |
+
if multi_face:
|
| 192 |
+
c = image_prompt_embeds.size(-1)
|
| 193 |
+
image_prompt_embeds = image_prompt_embeds.reshape(b, -1, c)
|
| 194 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.reshape(b, -1, c)
|
| 195 |
+
|
| 196 |
+
return image_prompt_embeds, uncond_image_prompt_embeds
|
| 197 |
+
|
| 198 |
+
def set_scale(self, scale):
|
| 199 |
+
for attn_processor in self.pipe.unet.attn_processors.values():
|
| 200 |
+
if isinstance(attn_processor, IPAttnProcessor):
|
| 201 |
+
attn_processor.scale = scale
|
| 202 |
+
|
| 203 |
+
def generate(
|
| 204 |
+
self,
|
| 205 |
+
faceid_embeds=None,
|
| 206 |
+
prompt=None,
|
| 207 |
+
negative_prompt=None,
|
| 208 |
+
scale=1.0,
|
| 209 |
+
num_samples=4,
|
| 210 |
+
seed=None,
|
| 211 |
+
guidance_scale=7.5,
|
| 212 |
+
num_inference_steps=30,
|
| 213 |
+
**kwargs,
|
| 214 |
+
):
|
| 215 |
+
self.set_scale(scale)
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
num_prompts = faceid_embeds.size(0)
|
| 219 |
+
|
| 220 |
+
if prompt is None:
|
| 221 |
+
prompt = "best quality, high quality"
|
| 222 |
+
if negative_prompt is None:
|
| 223 |
+
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
|
| 224 |
+
|
| 225 |
+
if not isinstance(prompt, List):
|
| 226 |
+
prompt = [prompt] * num_prompts
|
| 227 |
+
if not isinstance(negative_prompt, List):
|
| 228 |
+
negative_prompt = [negative_prompt] * num_prompts
|
| 229 |
+
|
| 230 |
+
image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(faceid_embeds)
|
| 231 |
+
|
| 232 |
+
bs_embed, seq_len, _ = image_prompt_embeds.shape
|
| 233 |
+
image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
|
| 234 |
+
image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 235 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
|
| 236 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 237 |
+
|
| 238 |
+
with torch.inference_mode():
|
| 239 |
+
prompt_embeds_, negative_prompt_embeds_ = self.pipe.encode_prompt(
|
| 240 |
+
prompt,
|
| 241 |
+
device=self.device,
|
| 242 |
+
num_images_per_prompt=num_samples,
|
| 243 |
+
do_classifier_free_guidance=True,
|
| 244 |
+
negative_prompt=negative_prompt,
|
| 245 |
+
)
|
| 246 |
+
prompt_embeds = torch.cat([prompt_embeds_, image_prompt_embeds], dim=1)
|
| 247 |
+
negative_prompt_embeds = torch.cat([negative_prompt_embeds_, uncond_image_prompt_embeds], dim=1)
|
| 248 |
+
|
| 249 |
+
generator = get_generator(seed, self.device)
|
| 250 |
+
|
| 251 |
+
images = self.pipe(
|
| 252 |
+
prompt_embeds=prompt_embeds,
|
| 253 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 254 |
+
guidance_scale=guidance_scale,
|
| 255 |
+
num_inference_steps=num_inference_steps,
|
| 256 |
+
generator=generator,
|
| 257 |
+
**kwargs,
|
| 258 |
+
).images
|
| 259 |
+
|
| 260 |
+
return images
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
class IPAdapterFaceIDPlus:
|
| 264 |
+
def __init__(self, sd_pipe, image_encoder_path, ip_ckpt, device, num_tokens=4, torch_dtype=torch.float16):
|
| 265 |
+
self.device = device
|
| 266 |
+
self.image_encoder_path = image_encoder_path
|
| 267 |
+
self.ip_ckpt = ip_ckpt
|
| 268 |
+
self.num_tokens = num_tokens
|
| 269 |
+
self.torch_dtype = torch_dtype
|
| 270 |
+
|
| 271 |
+
self.pipe = sd_pipe.to(self.device)
|
| 272 |
+
self.set_ip_adapter()
|
| 273 |
+
|
| 274 |
+
# load image encoder
|
| 275 |
+
self.image_encoder = CLIPVisionModelWithProjection.from_pretrained(self.image_encoder_path).to(
|
| 276 |
+
self.device, dtype=self.torch_dtype
|
| 277 |
+
)
|
| 278 |
+
self.clip_image_processor = CLIPImageProcessor()
|
| 279 |
+
# image proj model
|
| 280 |
+
self.image_proj_model = self.init_proj()
|
| 281 |
+
|
| 282 |
+
self.load_ip_adapter()
|
| 283 |
+
|
| 284 |
+
def init_proj(self):
|
| 285 |
+
image_proj_model = ProjPlusModel(
|
| 286 |
+
cross_attention_dim=self.pipe.unet.config.cross_attention_dim,
|
| 287 |
+
id_embeddings_dim=512,
|
| 288 |
+
clip_embeddings_dim=self.image_encoder.config.hidden_size,
|
| 289 |
+
num_tokens=self.num_tokens,
|
| 290 |
+
).to(self.device, dtype=self.torch_dtype)
|
| 291 |
+
return image_proj_model
|
| 292 |
+
|
| 293 |
+
def set_ip_adapter(self):
|
| 294 |
+
unet = self.pipe.unet
|
| 295 |
+
attn_procs = {}
|
| 296 |
+
for name in unet.attn_processors.keys():
|
| 297 |
+
cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
|
| 298 |
+
if name.startswith("mid_block"):
|
| 299 |
+
hidden_size = unet.config.block_out_channels[-1]
|
| 300 |
+
elif name.startswith("up_blocks"):
|
| 301 |
+
block_id = int(name[len("up_blocks.")])
|
| 302 |
+
hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
|
| 303 |
+
elif name.startswith("down_blocks"):
|
| 304 |
+
block_id = int(name[len("down_blocks.")])
|
| 305 |
+
hidden_size = unet.config.block_out_channels[block_id]
|
| 306 |
+
if cross_attention_dim is None:
|
| 307 |
+
attn_procs[name] = AttnProcessor()
|
| 308 |
+
else:
|
| 309 |
+
attn_procs[name] = IPAttnProcessor(
|
| 310 |
+
hidden_size=hidden_size, cross_attention_dim=cross_attention_dim, scale=1.0, num_tokens=self.num_tokens,
|
| 311 |
+
).to(self.device, dtype=self.torch_dtype)
|
| 312 |
+
unet.set_attn_processor(attn_procs)
|
| 313 |
+
|
| 314 |
+
def load_ip_adapter(self):
|
| 315 |
+
if os.path.splitext(self.ip_ckpt)[-1] == ".safetensors":
|
| 316 |
+
state_dict = {"image_proj": {}, "ip_adapter": {}}
|
| 317 |
+
with safe_open(self.ip_ckpt, framework="pt", device="cpu") as f:
|
| 318 |
+
for key in f.keys():
|
| 319 |
+
if key.startswith("image_proj."):
|
| 320 |
+
state_dict["image_proj"][key.replace("image_proj.", "")] = f.get_tensor(key)
|
| 321 |
+
elif key.startswith("ip_adapter."):
|
| 322 |
+
state_dict["ip_adapter"][key.replace("ip_adapter.", "")] = f.get_tensor(key)
|
| 323 |
+
else:
|
| 324 |
+
state_dict = torch.load(self.ip_ckpt, map_location="cpu")
|
| 325 |
+
self.image_proj_model.load_state_dict(state_dict["image_proj"])
|
| 326 |
+
ip_layers = torch.nn.ModuleList(self.pipe.unet.attn_processors.values())
|
| 327 |
+
ip_layers.load_state_dict(state_dict["ip_adapter"], strict=False)
|
| 328 |
+
|
| 329 |
+
@torch.inference_mode()
|
| 330 |
+
def get_image_embeds(self, faceid_embeds, face_image, s_scale, shortcut):
|
| 331 |
+
if isinstance(face_image, Image.Image):
|
| 332 |
+
pil_image = [face_image]
|
| 333 |
+
clip_image = self.clip_image_processor(images=face_image, return_tensors="pt").pixel_values
|
| 334 |
+
clip_image = clip_image.to(self.device, dtype=self.torch_dtype)
|
| 335 |
+
clip_image_embeds = self.image_encoder(clip_image, output_hidden_states=True).hidden_states[-2]
|
| 336 |
+
uncond_clip_image_embeds = self.image_encoder(
|
| 337 |
+
torch.zeros_like(clip_image), output_hidden_states=True
|
| 338 |
+
).hidden_states[-2]
|
| 339 |
+
|
| 340 |
+
faceid_embeds = faceid_embeds.to(self.device, dtype=self.torch_dtype)
|
| 341 |
+
image_prompt_embeds = self.image_proj_model(faceid_embeds, clip_image_embeds, shortcut=shortcut, scale=s_scale)
|
| 342 |
+
uncond_image_prompt_embeds = self.image_proj_model(torch.zeros_like(faceid_embeds), uncond_clip_image_embeds, shortcut=shortcut, scale=s_scale)
|
| 343 |
+
return image_prompt_embeds, uncond_image_prompt_embeds
|
| 344 |
+
|
| 345 |
+
def set_scale(self, scale):
|
| 346 |
+
for attn_processor in self.pipe.unet.attn_processors.values():
|
| 347 |
+
if isinstance(attn_processor, LoRAIPAttnProcessor):
|
| 348 |
+
attn_processor.scale = scale
|
| 349 |
+
|
| 350 |
+
def generate(
|
| 351 |
+
self,
|
| 352 |
+
face_image=None,
|
| 353 |
+
faceid_embeds=None,
|
| 354 |
+
prompt=None,
|
| 355 |
+
negative_prompt=None,
|
| 356 |
+
scale=1.0,
|
| 357 |
+
num_samples=4,
|
| 358 |
+
seed=None,
|
| 359 |
+
guidance_scale=7.5,
|
| 360 |
+
num_inference_steps=30,
|
| 361 |
+
s_scale=1.0,
|
| 362 |
+
shortcut=False,
|
| 363 |
+
**kwargs,
|
| 364 |
+
):
|
| 365 |
+
self.set_scale(scale)
|
| 366 |
+
|
| 367 |
+
|
| 368 |
+
num_prompts = faceid_embeds.size(0)
|
| 369 |
+
|
| 370 |
+
if prompt is None:
|
| 371 |
+
prompt = "best quality, high quality"
|
| 372 |
+
if negative_prompt is None:
|
| 373 |
+
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
|
| 374 |
+
|
| 375 |
+
if not isinstance(prompt, List):
|
| 376 |
+
prompt = [prompt] * num_prompts
|
| 377 |
+
if not isinstance(negative_prompt, List):
|
| 378 |
+
negative_prompt = [negative_prompt] * num_prompts
|
| 379 |
+
|
| 380 |
+
image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(faceid_embeds, face_image, s_scale, shortcut)
|
| 381 |
+
|
| 382 |
+
bs_embed, seq_len, _ = image_prompt_embeds.shape
|
| 383 |
+
image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
|
| 384 |
+
image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 385 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
|
| 386 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 387 |
+
|
| 388 |
+
with torch.inference_mode():
|
| 389 |
+
prompt_embeds_, negative_prompt_embeds_ = self.pipe.encode_prompt(
|
| 390 |
+
prompt,
|
| 391 |
+
device=self.device,
|
| 392 |
+
num_images_per_prompt=num_samples,
|
| 393 |
+
do_classifier_free_guidance=True,
|
| 394 |
+
negative_prompt=negative_prompt,
|
| 395 |
+
)
|
| 396 |
+
prompt_embeds = torch.cat([prompt_embeds_, image_prompt_embeds], dim=1)
|
| 397 |
+
negative_prompt_embeds = torch.cat([negative_prompt_embeds_, uncond_image_prompt_embeds], dim=1)
|
| 398 |
+
|
| 399 |
+
generator = get_generator(seed, self.device)
|
| 400 |
+
|
| 401 |
+
images = self.pipe(
|
| 402 |
+
prompt_embeds=prompt_embeds,
|
| 403 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 404 |
+
guidance_scale=guidance_scale,
|
| 405 |
+
num_inference_steps=num_inference_steps,
|
| 406 |
+
generator=generator,
|
| 407 |
+
**kwargs,
|
| 408 |
+
).images
|
| 409 |
+
|
| 410 |
+
return images
|
| 411 |
+
|
| 412 |
+
|
| 413 |
+
class IPAdapterFaceIDXL(IPAdapterFaceID):
|
| 414 |
+
"""SDXL"""
|
| 415 |
+
|
| 416 |
+
def generate(
|
| 417 |
+
self,
|
| 418 |
+
faceid_embeds=None,
|
| 419 |
+
prompt=None,
|
| 420 |
+
negative_prompt=None,
|
| 421 |
+
scale=1.0,
|
| 422 |
+
num_samples=4,
|
| 423 |
+
seed=None,
|
| 424 |
+
num_inference_steps=30,
|
| 425 |
+
**kwargs,
|
| 426 |
+
):
|
| 427 |
+
self.set_scale(scale)
|
| 428 |
+
|
| 429 |
+
num_prompts = faceid_embeds.size(0)
|
| 430 |
+
|
| 431 |
+
if prompt is None:
|
| 432 |
+
prompt = "best quality, high quality"
|
| 433 |
+
if negative_prompt is None:
|
| 434 |
+
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
|
| 435 |
+
|
| 436 |
+
if not isinstance(prompt, List):
|
| 437 |
+
prompt = [prompt] * num_prompts
|
| 438 |
+
if not isinstance(negative_prompt, List):
|
| 439 |
+
negative_prompt = [negative_prompt] * num_prompts
|
| 440 |
+
|
| 441 |
+
image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(faceid_embeds)
|
| 442 |
+
|
| 443 |
+
bs_embed, seq_len, _ = image_prompt_embeds.shape
|
| 444 |
+
image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
|
| 445 |
+
image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 446 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
|
| 447 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 448 |
+
|
| 449 |
+
with torch.inference_mode():
|
| 450 |
+
(
|
| 451 |
+
prompt_embeds,
|
| 452 |
+
negative_prompt_embeds,
|
| 453 |
+
pooled_prompt_embeds,
|
| 454 |
+
negative_pooled_prompt_embeds,
|
| 455 |
+
) = self.pipe.encode_prompt(
|
| 456 |
+
prompt,
|
| 457 |
+
num_images_per_prompt=num_samples,
|
| 458 |
+
do_classifier_free_guidance=True,
|
| 459 |
+
negative_prompt=negative_prompt,
|
| 460 |
+
)
|
| 461 |
+
prompt_embeds = torch.cat([prompt_embeds, image_prompt_embeds], dim=1)
|
| 462 |
+
negative_prompt_embeds = torch.cat([negative_prompt_embeds, uncond_image_prompt_embeds], dim=1)
|
| 463 |
+
|
| 464 |
+
generator = get_generator(seed, self.device)
|
| 465 |
+
|
| 466 |
+
images = self.pipe(
|
| 467 |
+
prompt_embeds=prompt_embeds,
|
| 468 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 469 |
+
pooled_prompt_embeds=pooled_prompt_embeds,
|
| 470 |
+
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
|
| 471 |
+
num_inference_steps=num_inference_steps,
|
| 472 |
+
generator=generator,
|
| 473 |
+
**kwargs,
|
| 474 |
+
).images
|
| 475 |
+
|
| 476 |
+
return images
|
| 477 |
+
|
| 478 |
+
|
| 479 |
+
class IPAdapterFaceIDPlusXL(IPAdapterFaceIDPlus):
|
| 480 |
+
"""SDXL"""
|
| 481 |
+
|
| 482 |
+
def generate(
|
| 483 |
+
self,
|
| 484 |
+
face_image=None,
|
| 485 |
+
faceid_embeds=None,
|
| 486 |
+
prompt=None,
|
| 487 |
+
negative_prompt=None,
|
| 488 |
+
scale=1.0,
|
| 489 |
+
num_samples=4,
|
| 490 |
+
seed=None,
|
| 491 |
+
guidance_scale=7.5,
|
| 492 |
+
num_inference_steps=30,
|
| 493 |
+
s_scale=1.0,
|
| 494 |
+
shortcut=True,
|
| 495 |
+
**kwargs,
|
| 496 |
+
):
|
| 497 |
+
self.set_scale(scale)
|
| 498 |
+
|
| 499 |
+
num_prompts = faceid_embeds.size(0)
|
| 500 |
+
|
| 501 |
+
if prompt is None:
|
| 502 |
+
prompt = "best quality, high quality"
|
| 503 |
+
if negative_prompt is None:
|
| 504 |
+
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
|
| 505 |
+
|
| 506 |
+
if not isinstance(prompt, List):
|
| 507 |
+
prompt = [prompt] * num_prompts
|
| 508 |
+
if not isinstance(negative_prompt, List):
|
| 509 |
+
negative_prompt = [negative_prompt] * num_prompts
|
| 510 |
+
|
| 511 |
+
image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(faceid_embeds, face_image, s_scale, shortcut)
|
| 512 |
+
|
| 513 |
+
bs_embed, seq_len, _ = image_prompt_embeds.shape
|
| 514 |
+
image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
|
| 515 |
+
image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 516 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
|
| 517 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 518 |
+
|
| 519 |
+
with torch.inference_mode():
|
| 520 |
+
(
|
| 521 |
+
prompt_embeds,
|
| 522 |
+
negative_prompt_embeds,
|
| 523 |
+
pooled_prompt_embeds,
|
| 524 |
+
negative_pooled_prompt_embeds,
|
| 525 |
+
) = self.pipe.encode_prompt(
|
| 526 |
+
prompt,
|
| 527 |
+
num_images_per_prompt=num_samples,
|
| 528 |
+
do_classifier_free_guidance=True,
|
| 529 |
+
negative_prompt=negative_prompt,
|
| 530 |
+
)
|
| 531 |
+
prompt_embeds = torch.cat([prompt_embeds, image_prompt_embeds], dim=1)
|
| 532 |
+
negative_prompt_embeds = torch.cat([negative_prompt_embeds, uncond_image_prompt_embeds], dim=1)
|
| 533 |
+
|
| 534 |
+
generator = get_generator(seed, self.device)
|
| 535 |
+
|
| 536 |
+
images = self.pipe(
|
| 537 |
+
prompt_embeds=prompt_embeds,
|
| 538 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 539 |
+
pooled_prompt_embeds=pooled_prompt_embeds,
|
| 540 |
+
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
|
| 541 |
+
num_inference_steps=num_inference_steps,
|
| 542 |
+
generator=generator,
|
| 543 |
+
guidance_scale=guidance_scale,
|
| 544 |
+
**kwargs,
|
| 545 |
+
).images
|
| 546 |
+
|
| 547 |
+
return images
|
ip_adapter/resampler.py
ADDED
|
@@ -0,0 +1,158 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/mlfoundations/open_flamingo/blob/main/open_flamingo/src/helpers.py
|
| 2 |
+
# and https://github.com/lucidrains/imagen-pytorch/blob/main/imagen_pytorch/imagen_pytorch.py
|
| 3 |
+
|
| 4 |
+
import math
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
from einops import rearrange
|
| 9 |
+
from einops.layers.torch import Rearrange
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
# FFN
|
| 13 |
+
def FeedForward(dim, mult=4):
|
| 14 |
+
inner_dim = int(dim * mult)
|
| 15 |
+
return nn.Sequential(
|
| 16 |
+
nn.LayerNorm(dim),
|
| 17 |
+
nn.Linear(dim, inner_dim, bias=False),
|
| 18 |
+
nn.GELU(),
|
| 19 |
+
nn.Linear(inner_dim, dim, bias=False),
|
| 20 |
+
)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def reshape_tensor(x, heads):
|
| 24 |
+
bs, length, width = x.shape
|
| 25 |
+
# (bs, length, width) --> (bs, length, n_heads, dim_per_head)
|
| 26 |
+
x = x.view(bs, length, heads, -1)
|
| 27 |
+
# (bs, length, n_heads, dim_per_head) --> (bs, n_heads, length, dim_per_head)
|
| 28 |
+
x = x.transpose(1, 2)
|
| 29 |
+
# (bs, n_heads, length, dim_per_head) --> (bs*n_heads, length, dim_per_head)
|
| 30 |
+
x = x.reshape(bs, heads, length, -1)
|
| 31 |
+
return x
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class PerceiverAttention(nn.Module):
|
| 35 |
+
def __init__(self, *, dim, dim_head=64, heads=8):
|
| 36 |
+
super().__init__()
|
| 37 |
+
self.scale = dim_head**-0.5
|
| 38 |
+
self.dim_head = dim_head
|
| 39 |
+
self.heads = heads
|
| 40 |
+
inner_dim = dim_head * heads
|
| 41 |
+
|
| 42 |
+
self.norm1 = nn.LayerNorm(dim)
|
| 43 |
+
self.norm2 = nn.LayerNorm(dim)
|
| 44 |
+
|
| 45 |
+
self.to_q = nn.Linear(dim, inner_dim, bias=False)
|
| 46 |
+
self.to_kv = nn.Linear(dim, inner_dim * 2, bias=False)
|
| 47 |
+
self.to_out = nn.Linear(inner_dim, dim, bias=False)
|
| 48 |
+
|
| 49 |
+
def forward(self, x, latents):
|
| 50 |
+
"""
|
| 51 |
+
Args:
|
| 52 |
+
x (torch.Tensor): image features
|
| 53 |
+
shape (b, n1, D)
|
| 54 |
+
latent (torch.Tensor): latent features
|
| 55 |
+
shape (b, n2, D)
|
| 56 |
+
"""
|
| 57 |
+
x = self.norm1(x)
|
| 58 |
+
latents = self.norm2(latents)
|
| 59 |
+
|
| 60 |
+
b, l, _ = latents.shape
|
| 61 |
+
|
| 62 |
+
q = self.to_q(latents)
|
| 63 |
+
kv_input = torch.cat((x, latents), dim=-2)
|
| 64 |
+
k, v = self.to_kv(kv_input).chunk(2, dim=-1)
|
| 65 |
+
|
| 66 |
+
q = reshape_tensor(q, self.heads)
|
| 67 |
+
k = reshape_tensor(k, self.heads)
|
| 68 |
+
v = reshape_tensor(v, self.heads)
|
| 69 |
+
|
| 70 |
+
# attention
|
| 71 |
+
scale = 1 / math.sqrt(math.sqrt(self.dim_head))
|
| 72 |
+
weight = (q * scale) @ (k * scale).transpose(-2, -1) # More stable with f16 than dividing afterwards
|
| 73 |
+
weight = torch.softmax(weight.float(), dim=-1).type(weight.dtype)
|
| 74 |
+
out = weight @ v
|
| 75 |
+
|
| 76 |
+
out = out.permute(0, 2, 1, 3).reshape(b, l, -1)
|
| 77 |
+
|
| 78 |
+
return self.to_out(out)
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
class Resampler(nn.Module):
|
| 82 |
+
def __init__(
|
| 83 |
+
self,
|
| 84 |
+
dim=1024,
|
| 85 |
+
depth=8,
|
| 86 |
+
dim_head=64,
|
| 87 |
+
heads=16,
|
| 88 |
+
num_queries=8,
|
| 89 |
+
embedding_dim=768,
|
| 90 |
+
output_dim=1024,
|
| 91 |
+
ff_mult=4,
|
| 92 |
+
max_seq_len: int = 257, # CLIP tokens + CLS token
|
| 93 |
+
apply_pos_emb: bool = False,
|
| 94 |
+
num_latents_mean_pooled: int = 0, # number of latents derived from mean pooled representation of the sequence
|
| 95 |
+
):
|
| 96 |
+
super().__init__()
|
| 97 |
+
self.pos_emb = nn.Embedding(max_seq_len, embedding_dim) if apply_pos_emb else None
|
| 98 |
+
|
| 99 |
+
self.latents = nn.Parameter(torch.randn(1, num_queries, dim) / dim**0.5)
|
| 100 |
+
|
| 101 |
+
self.proj_in = nn.Linear(embedding_dim, dim)
|
| 102 |
+
|
| 103 |
+
self.proj_out = nn.Linear(dim, output_dim)
|
| 104 |
+
self.norm_out = nn.LayerNorm(output_dim)
|
| 105 |
+
|
| 106 |
+
self.to_latents_from_mean_pooled_seq = (
|
| 107 |
+
nn.Sequential(
|
| 108 |
+
nn.LayerNorm(dim),
|
| 109 |
+
nn.Linear(dim, dim * num_latents_mean_pooled),
|
| 110 |
+
Rearrange("b (n d) -> b n d", n=num_latents_mean_pooled),
|
| 111 |
+
)
|
| 112 |
+
if num_latents_mean_pooled > 0
|
| 113 |
+
else None
|
| 114 |
+
)
|
| 115 |
+
|
| 116 |
+
self.layers = nn.ModuleList([])
|
| 117 |
+
for _ in range(depth):
|
| 118 |
+
self.layers.append(
|
| 119 |
+
nn.ModuleList(
|
| 120 |
+
[
|
| 121 |
+
PerceiverAttention(dim=dim, dim_head=dim_head, heads=heads),
|
| 122 |
+
FeedForward(dim=dim, mult=ff_mult),
|
| 123 |
+
]
|
| 124 |
+
)
|
| 125 |
+
)
|
| 126 |
+
|
| 127 |
+
def forward(self, x):
|
| 128 |
+
if self.pos_emb is not None:
|
| 129 |
+
n, device = x.shape[1], x.device
|
| 130 |
+
pos_emb = self.pos_emb(torch.arange(n, device=device))
|
| 131 |
+
x = x + pos_emb
|
| 132 |
+
|
| 133 |
+
latents = self.latents.repeat(x.size(0), 1, 1)
|
| 134 |
+
|
| 135 |
+
x = self.proj_in(x)
|
| 136 |
+
|
| 137 |
+
if self.to_latents_from_mean_pooled_seq:
|
| 138 |
+
meanpooled_seq = masked_mean(x, dim=1, mask=torch.ones(x.shape[:2], device=x.device, dtype=torch.bool))
|
| 139 |
+
meanpooled_latents = self.to_latents_from_mean_pooled_seq(meanpooled_seq)
|
| 140 |
+
latents = torch.cat((meanpooled_latents, latents), dim=-2)
|
| 141 |
+
|
| 142 |
+
for attn, ff in self.layers:
|
| 143 |
+
latents = attn(x, latents) + latents
|
| 144 |
+
latents = ff(latents) + latents
|
| 145 |
+
|
| 146 |
+
latents = self.proj_out(latents)
|
| 147 |
+
return self.norm_out(latents)
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
def masked_mean(t, *, dim, mask=None):
|
| 151 |
+
if mask is None:
|
| 152 |
+
return t.mean(dim=dim)
|
| 153 |
+
|
| 154 |
+
denom = mask.sum(dim=dim, keepdim=True)
|
| 155 |
+
mask = rearrange(mask, "b n -> b n 1")
|
| 156 |
+
masked_t = t.masked_fill(~mask, 0.0)
|
| 157 |
+
|
| 158 |
+
return masked_t.sum(dim=dim) / denom.clamp(min=1e-5)
|
ip_adapter/test_resampler.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from resampler import Resampler
|
| 3 |
+
from transformers import CLIPVisionModel
|
| 4 |
+
|
| 5 |
+
BATCH_SIZE = 2
|
| 6 |
+
OUTPUT_DIM = 1280
|
| 7 |
+
NUM_QUERIES = 8
|
| 8 |
+
NUM_LATENTS_MEAN_POOLED = 4 # 0 for no mean pooling (previous behavior)
|
| 9 |
+
APPLY_POS_EMB = True # False for no positional embeddings (previous behavior)
|
| 10 |
+
IMAGE_ENCODER_NAME_OR_PATH = "laion/CLIP-ViT-H-14-laion2B-s32B-b79K"
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def main():
|
| 14 |
+
image_encoder = CLIPVisionModel.from_pretrained(IMAGE_ENCODER_NAME_OR_PATH)
|
| 15 |
+
embedding_dim = image_encoder.config.hidden_size
|
| 16 |
+
print(f"image_encoder hidden size: ", embedding_dim)
|
| 17 |
+
|
| 18 |
+
image_proj_model = Resampler(
|
| 19 |
+
dim=1024,
|
| 20 |
+
depth=2,
|
| 21 |
+
dim_head=64,
|
| 22 |
+
heads=16,
|
| 23 |
+
num_queries=NUM_QUERIES,
|
| 24 |
+
embedding_dim=embedding_dim,
|
| 25 |
+
output_dim=OUTPUT_DIM,
|
| 26 |
+
ff_mult=2,
|
| 27 |
+
max_seq_len=257,
|
| 28 |
+
apply_pos_emb=APPLY_POS_EMB,
|
| 29 |
+
num_latents_mean_pooled=NUM_LATENTS_MEAN_POOLED,
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
dummy_images = torch.randn(BATCH_SIZE, 3, 224, 224)
|
| 33 |
+
with torch.no_grad():
|
| 34 |
+
image_embeds = image_encoder(dummy_images, output_hidden_states=True).hidden_states[-2]
|
| 35 |
+
print("image_embds shape: ", image_embeds.shape)
|
| 36 |
+
|
| 37 |
+
with torch.no_grad():
|
| 38 |
+
ip_tokens = image_proj_model(image_embeds)
|
| 39 |
+
print("ip_tokens shape:", ip_tokens.shape)
|
| 40 |
+
assert ip_tokens.shape == (BATCH_SIZE, NUM_QUERIES + NUM_LATENTS_MEAN_POOLED, OUTPUT_DIM)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
if __name__ == "__main__":
|
| 44 |
+
main()
|
ip_adapter/utils.py
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn.functional as F
|
| 3 |
+
import numpy as np
|
| 4 |
+
from PIL import Image
|
| 5 |
+
|
| 6 |
+
attn_maps = {}
|
| 7 |
+
def hook_fn(name):
|
| 8 |
+
def forward_hook(module, input, output):
|
| 9 |
+
if hasattr(module.processor, "attn_map"):
|
| 10 |
+
attn_maps[name] = module.processor.attn_map
|
| 11 |
+
del module.processor.attn_map
|
| 12 |
+
|
| 13 |
+
return forward_hook
|
| 14 |
+
|
| 15 |
+
def register_cross_attention_hook(unet):
|
| 16 |
+
for name, module in unet.named_modules():
|
| 17 |
+
if name.split('.')[-1].startswith('attn2'):
|
| 18 |
+
module.register_forward_hook(hook_fn(name))
|
| 19 |
+
|
| 20 |
+
return unet
|
| 21 |
+
|
| 22 |
+
def upscale(attn_map, target_size):
|
| 23 |
+
attn_map = torch.mean(attn_map, dim=0)
|
| 24 |
+
attn_map = attn_map.permute(1,0)
|
| 25 |
+
temp_size = None
|
| 26 |
+
|
| 27 |
+
for i in range(0,5):
|
| 28 |
+
scale = 2 ** i
|
| 29 |
+
if ( target_size[0] // scale ) * ( target_size[1] // scale) == attn_map.shape[1]*64:
|
| 30 |
+
temp_size = (target_size[0]//(scale*8), target_size[1]//(scale*8))
|
| 31 |
+
break
|
| 32 |
+
|
| 33 |
+
assert temp_size is not None, "temp_size cannot is None"
|
| 34 |
+
|
| 35 |
+
attn_map = attn_map.view(attn_map.shape[0], *temp_size)
|
| 36 |
+
|
| 37 |
+
attn_map = F.interpolate(
|
| 38 |
+
attn_map.unsqueeze(0).to(dtype=torch.float32),
|
| 39 |
+
size=target_size,
|
| 40 |
+
mode='bilinear',
|
| 41 |
+
align_corners=False
|
| 42 |
+
)[0]
|
| 43 |
+
|
| 44 |
+
attn_map = torch.softmax(attn_map, dim=0)
|
| 45 |
+
return attn_map
|
| 46 |
+
def get_net_attn_map(image_size, batch_size=2, instance_or_negative=False, detach=True):
|
| 47 |
+
|
| 48 |
+
idx = 0 if instance_or_negative else 1
|
| 49 |
+
net_attn_maps = []
|
| 50 |
+
|
| 51 |
+
for name, attn_map in attn_maps.items():
|
| 52 |
+
attn_map = attn_map.cpu() if detach else attn_map
|
| 53 |
+
attn_map = torch.chunk(attn_map, batch_size)[idx].squeeze()
|
| 54 |
+
attn_map = upscale(attn_map, image_size)
|
| 55 |
+
net_attn_maps.append(attn_map)
|
| 56 |
+
|
| 57 |
+
net_attn_maps = torch.mean(torch.stack(net_attn_maps,dim=0),dim=0)
|
| 58 |
+
|
| 59 |
+
return net_attn_maps
|
| 60 |
+
|
| 61 |
+
def attnmaps2images(net_attn_maps):
|
| 62 |
+
|
| 63 |
+
#total_attn_scores = 0
|
| 64 |
+
images = []
|
| 65 |
+
|
| 66 |
+
for attn_map in net_attn_maps:
|
| 67 |
+
attn_map = attn_map.cpu().numpy()
|
| 68 |
+
#total_attn_scores += attn_map.mean().item()
|
| 69 |
+
|
| 70 |
+
normalized_attn_map = (attn_map - np.min(attn_map)) / (np.max(attn_map) - np.min(attn_map)) * 255
|
| 71 |
+
normalized_attn_map = normalized_attn_map.astype(np.uint8)
|
| 72 |
+
#print("norm: ", normalized_attn_map.shape)
|
| 73 |
+
image = Image.fromarray(normalized_attn_map)
|
| 74 |
+
|
| 75 |
+
#image = fix_save_attn_map(attn_map)
|
| 76 |
+
images.append(image)
|
| 77 |
+
|
| 78 |
+
#print(total_attn_scores)
|
| 79 |
+
return images
|
| 80 |
+
def is_torch2_available():
|
| 81 |
+
return hasattr(F, "scaled_dot_product_attention")
|
| 82 |
+
|
| 83 |
+
def get_generator(seed, device):
|
| 84 |
+
|
| 85 |
+
if seed is not None:
|
| 86 |
+
if isinstance(seed, list):
|
| 87 |
+
generator = [torch.Generator(device).manual_seed(seed_item) for seed_item in seed]
|
| 88 |
+
else:
|
| 89 |
+
generator = torch.Generator(device).manual_seed(seed)
|
| 90 |
+
else:
|
| 91 |
+
generator = None
|
| 92 |
+
|
| 93 |
+
return generator
|
models/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
models/image_encoder/config.json
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "./image_encoder",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"CLIPVisionModelWithProjection"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"dropout": 0.0,
|
| 8 |
+
"hidden_act": "gelu",
|
| 9 |
+
"hidden_size": 1280,
|
| 10 |
+
"image_size": 224,
|
| 11 |
+
"initializer_factor": 1.0,
|
| 12 |
+
"initializer_range": 0.02,
|
| 13 |
+
"intermediate_size": 5120,
|
| 14 |
+
"layer_norm_eps": 1e-05,
|
| 15 |
+
"model_type": "clip_vision_model",
|
| 16 |
+
"num_attention_heads": 16,
|
| 17 |
+
"num_channels": 3,
|
| 18 |
+
"num_hidden_layers": 32,
|
| 19 |
+
"patch_size": 14,
|
| 20 |
+
"projection_dim": 1024,
|
| 21 |
+
"torch_dtype": "float16",
|
| 22 |
+
"transformers_version": "4.28.0.dev0"
|
| 23 |
+
}
|
requirements.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
diffusers
|
| 2 |
+
rembg
|
| 3 |
+
einops==0.7.0
|
| 4 |
+
transformers==4.27.4
|
| 5 |
+
opencv-python==4.7.0.68
|
| 6 |
+
gradio==4.15.0
|
| 7 |
+
accelerate==0.26.1
|
| 8 |
+
timm==0.6.12
|
| 9 |
+
torch==2.0.1
|
| 10 |
+
torchvision==0.15.2
|
run_batch.py
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from diffusers import StableDiffusionXLControlNetInpaintPipeline, ControlNetModel
|
| 2 |
+
from rembg import remove
|
| 3 |
+
from PIL import Image
|
| 4 |
+
import torch
|
| 5 |
+
from ip_adapter import IPAdapterXL
|
| 6 |
+
from ip_adapter.utils import register_cross_attention_hook, get_net_attn_map, attnmaps2images
|
| 7 |
+
from PIL import Image, ImageChops
|
| 8 |
+
from PIL import ImageEnhance
|
| 9 |
+
import numpy as np
|
| 10 |
+
import glob
|
| 11 |
+
|
| 12 |
+
def image_grid(imgs, rows, cols):
|
| 13 |
+
assert len(imgs) == rows*cols
|
| 14 |
+
|
| 15 |
+
w, h = imgs[0].size
|
| 16 |
+
grid = Image.new('RGB', size=(cols*w, rows*h))
|
| 17 |
+
grid_w, grid_h = grid.size
|
| 18 |
+
|
| 19 |
+
for i, img in enumerate(imgs):
|
| 20 |
+
grid.paste(img, box=(i%cols*w, i//cols*h))
|
| 21 |
+
return grid
|
| 22 |
+
|
| 23 |
+
base_model_path = "stabilityai/stable-diffusion-xl-base-1.0"
|
| 24 |
+
image_encoder_path = "models/image_encoder"
|
| 25 |
+
ip_ckpt = "sdxl_models/ip-adapter_sdxl_vit-h.bin"
|
| 26 |
+
controlnet_path = "diffusers/controlnet-depth-sdxl-1.0"
|
| 27 |
+
device = "cuda"
|
| 28 |
+
|
| 29 |
+
torch.cuda.empty_cache()
|
| 30 |
+
|
| 31 |
+
# load SDXL pipeline
|
| 32 |
+
controlnet = ControlNetModel.from_pretrained(controlnet_path, variant="fp16", use_safetensors=True, torch_dtype=torch.float16).to(device)
|
| 33 |
+
pipe = StableDiffusionXLControlNetInpaintPipeline.from_pretrained(
|
| 34 |
+
base_model_path,
|
| 35 |
+
controlnet=controlnet,
|
| 36 |
+
use_safetensors=True,
|
| 37 |
+
torch_dtype=torch.float16,
|
| 38 |
+
add_watermarker=False,
|
| 39 |
+
).to(device)
|
| 40 |
+
pipe.unet = register_cross_attention_hook(pipe.unet)
|
| 41 |
+
|
| 42 |
+
ip_model = IPAdapterXL(pipe, image_encoder_path, ip_ckpt, device)
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
textures = [tex.split('/')[-1].replace('.png', '') for tex in glob.glob('demo_assets/material_exemplars/*.png')]
|
| 47 |
+
objs = [obj.split('/')[-1].replace('.png', '') for obj in glob.glob('demo_assets/input_imgs/*.png')]
|
| 48 |
+
|
| 49 |
+
for texture in textures:
|
| 50 |
+
for obj in objs:
|
| 51 |
+
target_image_path = 'demo_assets/input_imgs/' + obj + '.png' # Replace with your image path
|
| 52 |
+
target_image = Image.open(target_image_path).convert('RGB')
|
| 53 |
+
rm_bg = remove(target_image)
|
| 54 |
+
# output.save(output_path)
|
| 55 |
+
target_mask = rm_bg.convert("RGB").point(lambda x: 0 if x < 1 else 255).convert('L').convert('RGB')# Convert mask to grayscale
|
| 56 |
+
|
| 57 |
+
# Ensure mask is the same size as image
|
| 58 |
+
|
| 59 |
+
# mask = ImageChops.invert(mask)
|
| 60 |
+
# Generate random noise for the size of the image
|
| 61 |
+
noise = np.random.randint(0, 256, target_image.size + (3,), dtype=np.uint8)
|
| 62 |
+
noise_image = Image.fromarray(noise)
|
| 63 |
+
mask_target_img = ImageChops.lighter(target_image, target_mask)
|
| 64 |
+
invert_target_mask = ImageChops.invert(target_mask)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
gray_target_image = target_image.convert('L').convert('RGB')
|
| 68 |
+
gray_target_image = ImageEnhance.Brightness(gray_target_image)
|
| 69 |
+
|
| 70 |
+
# Adjust brightness
|
| 71 |
+
# The factor 1.0 means original brightness, greater than 1.0 makes the image brighter. Adjust this if the image is too dim
|
| 72 |
+
factor = 1.0 # Try adjusting this to get the desired brightness
|
| 73 |
+
|
| 74 |
+
gray_target_image = gray_target_image.enhance(factor)
|
| 75 |
+
grayscale_img = ImageChops.darker(gray_target_image, target_mask)
|
| 76 |
+
img_black_mask = ImageChops.darker(target_image, invert_target_mask)
|
| 77 |
+
grayscale_init_img = ImageChops.lighter(img_black_mask, grayscale_img)
|
| 78 |
+
init_img = grayscale_init_img
|
| 79 |
+
|
| 80 |
+
ip_image = Image.open("demo_assets/material_exemplars/" + texture + ".png")
|
| 81 |
+
np_image = np.array(Image.open('demo_assets/depths/' + obj + '.png'))
|
| 82 |
+
|
| 83 |
+
np_image = (np_image / 256).astype('uint8')
|
| 84 |
+
|
| 85 |
+
depth_map = Image.fromarray(np_image).resize((1024,1024))
|
| 86 |
+
|
| 87 |
+
init_img = init_img.resize((1024,1024))
|
| 88 |
+
mask = target_mask.resize((1024, 1024))
|
| 89 |
+
|
| 90 |
+
num_samples = 1
|
| 91 |
+
images = ip_model.generate(pil_image=ip_image, image=init_img, control_image=depth_map, mask_image=mask, controlnet_conditioning_scale=0.9, num_samples=num_samples, num_inference_steps=30, seed=42)
|
| 92 |
+
images[0].save('demo_assets/output_images/' + obj + '_' + texture + '.png' )
|
| 93 |
+
|
sdxl_models/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
sdxl_models/image_encoder/config.json
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"CLIPVisionModelWithProjection"
|
| 4 |
+
],
|
| 5 |
+
"_name_or_path": "",
|
| 6 |
+
"add_cross_attention": false,
|
| 7 |
+
"architectures": null,
|
| 8 |
+
"attention_dropout": 0.0,
|
| 9 |
+
"bad_words_ids": null,
|
| 10 |
+
"begin_suppress_tokens": null,
|
| 11 |
+
"bos_token_id": null,
|
| 12 |
+
"chunk_size_feed_forward": 0,
|
| 13 |
+
"cross_attention_hidden_size": null,
|
| 14 |
+
"decoder_start_token_id": null,
|
| 15 |
+
"diversity_penalty": 0.0,
|
| 16 |
+
"do_sample": false,
|
| 17 |
+
"dropout": 0.0,
|
| 18 |
+
"early_stopping": false,
|
| 19 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 20 |
+
"eos_token_id": null,
|
| 21 |
+
"exponential_decay_length_penalty": null,
|
| 22 |
+
"finetuning_task": null,
|
| 23 |
+
"forced_bos_token_id": null,
|
| 24 |
+
"forced_eos_token_id": null,
|
| 25 |
+
"hidden_act": "gelu",
|
| 26 |
+
"hidden_size": 1664,
|
| 27 |
+
"id2label": {
|
| 28 |
+
"0": "LABEL_0",
|
| 29 |
+
"1": "LABEL_1"
|
| 30 |
+
},
|
| 31 |
+
"image_size": 224,
|
| 32 |
+
"initializer_factor": 1.0,
|
| 33 |
+
"initializer_range": 0.02,
|
| 34 |
+
"intermediate_size": 8192,
|
| 35 |
+
"is_decoder": false,
|
| 36 |
+
"is_encoder_decoder": false,
|
| 37 |
+
"label2id": {
|
| 38 |
+
"LABEL_0": 0,
|
| 39 |
+
"LABEL_1": 1
|
| 40 |
+
},
|
| 41 |
+
"layer_norm_eps": 1e-05,
|
| 42 |
+
"length_penalty": 1.0,
|
| 43 |
+
"max_length": 20,
|
| 44 |
+
"min_length": 0,
|
| 45 |
+
"model_type": "clip_vision_model",
|
| 46 |
+
"no_repeat_ngram_size": 0,
|
| 47 |
+
"num_attention_heads": 16,
|
| 48 |
+
"num_beam_groups": 1,
|
| 49 |
+
"num_beams": 1,
|
| 50 |
+
"num_channels": 3,
|
| 51 |
+
"num_hidden_layers": 48,
|
| 52 |
+
"num_return_sequences": 1,
|
| 53 |
+
"output_attentions": false,
|
| 54 |
+
"output_hidden_states": false,
|
| 55 |
+
"output_scores": false,
|
| 56 |
+
"pad_token_id": null,
|
| 57 |
+
"patch_size": 14,
|
| 58 |
+
"prefix": null,
|
| 59 |
+
"problem_type": null,
|
| 60 |
+
"pruned_heads": {},
|
| 61 |
+
"remove_invalid_values": false,
|
| 62 |
+
"repetition_penalty": 1.0,
|
| 63 |
+
"return_dict": true,
|
| 64 |
+
"return_dict_in_generate": false,
|
| 65 |
+
"sep_token_id": null,
|
| 66 |
+
"suppress_tokens": null,
|
| 67 |
+
"task_specific_params": null,
|
| 68 |
+
"temperature": 1.0,
|
| 69 |
+
"tf_legacy_loss": false,
|
| 70 |
+
"tie_encoder_decoder": false,
|
| 71 |
+
"tie_word_embeddings": true,
|
| 72 |
+
"tokenizer_class": null,
|
| 73 |
+
"top_k": 50,
|
| 74 |
+
"top_p": 1.0,
|
| 75 |
+
"torch_dtype": null,
|
| 76 |
+
"torchscript": false,
|
| 77 |
+
"transformers_version": "4.24.0",
|
| 78 |
+
"typical_p": 1.0,
|
| 79 |
+
"use_bfloat16": false,
|
| 80 |
+
"projection_dim": 1280
|
| 81 |
+
}
|
visualization.py
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import glob
|
| 2 |
+
from html4vision import Col, imagetable
|
| 3 |
+
|
| 4 |
+
textures = [tex.split('/')[-1].replace('.png', '') for tex in glob.glob('demo_assets/material_exemplars/*.png')]
|
| 5 |
+
objs = [obj.split('/')[-1].replace('.png', '') for obj in glob.glob('demo_assets/input_imgs/*.png')]
|
| 6 |
+
|
| 7 |
+
# Generate first column as input images for reference
|
| 8 |
+
cols = []
|
| 9 |
+
cols.append(Col('img', '',[''] + ['demo_assets/input_imgs/' + obj + '.png' for obj in objs ] ))
|
| 10 |
+
|
| 11 |
+
# Generate each column of results
|
| 12 |
+
for texture in textures:
|
| 13 |
+
cur_col =['demo_assets/material_exemplars/' + texture + '.png']
|
| 14 |
+
for obj in objs:
|
| 15 |
+
cur_col.append('demo_assets/output_images/' + texture + '_' + obj + '.png')
|
| 16 |
+
cols.append(Col('img', texture, cur_col))
|
| 17 |
+
|
| 18 |
+
imagetable(cols)
|