Spaces:
Runtime error

Runtime error
Commit
•
a5fb347
1
Parent(s):
60330fa
Initial commit
Browse files- .gitignore +23 -0
- Database.py +44 -0
- README.md +43 -13
- app.py +18 -0
- archive/codeBert.py +15 -0
- autoencoder.py +164 -0
- graphCodeBert.py +56 -0
- helpers/SEART.png +0 -0
- mongodb-playground/queries.mongodb +4 -0
- predict.py +45 -0
- refactor_analysis.py +142 -0
- repo_download.py +33 -0
- requirements.txt +11 -0
- results/metrics.json +1 -0
- results/training_graph.png +0 -0
- templates/css/main.css +76 -0
- templates/index.html +29 -0
- train.png +0 -0
.gitignore
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# PyBuilder
|
| 7 |
+
target/
|
| 8 |
+
|
| 9 |
+
# Environments
|
| 10 |
+
.env
|
| 11 |
+
.venv
|
| 12 |
+
env/
|
| 13 |
+
venv/
|
| 14 |
+
ENV/
|
| 15 |
+
env.bak/
|
| 16 |
+
venv.bak/
|
| 17 |
+
|
| 18 |
+
.idea
|
| 19 |
+
*_venv/
|
| 20 |
+
data/
|
| 21 |
+
output*/
|
| 22 |
+
|
| 23 |
+
*.zip
|
Database.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dotenv import dotenv_values
|
| 2 |
+
from pymongo import MongoClient
|
| 3 |
+
from bson.objectid import ObjectId
|
| 4 |
+
|
| 5 |
+
class Database:
|
| 6 |
+
|
| 7 |
+
def __init__(self, collection_name) -> None:
|
| 8 |
+
env_values = dotenv_values(".env")
|
| 9 |
+
self.url = env_values['MONGO_CLIENT']
|
| 10 |
+
self.db_name = env_values['DB_NAME']
|
| 11 |
+
self.collection_name = collection_name
|
| 12 |
+
self.__connect_db()
|
| 13 |
+
|
| 14 |
+
def __connect_db(self):
|
| 15 |
+
client = MongoClient(self.url)
|
| 16 |
+
self.db = client[self.db_name]
|
| 17 |
+
|
| 18 |
+
def __fetch_collection(self, collection_name: str):
|
| 19 |
+
collection = self.db.get_collection(collection_name)
|
| 20 |
+
return collection
|
| 21 |
+
|
| 22 |
+
def insert_docs(self,doc_list):
|
| 23 |
+
collection = self.__fetch_collection(self.collection_name)
|
| 24 |
+
collection.insert_many(doc_list)
|
| 25 |
+
|
| 26 |
+
def find_docs(self, query,projection={}):
|
| 27 |
+
collection = self.__fetch_collection(self.collection_name)
|
| 28 |
+
return collection.find(query,projection)
|
| 29 |
+
|
| 30 |
+
def estimated_doc_count(self):
|
| 31 |
+
collection = self.__fetch_collection(self.collection_name)
|
| 32 |
+
return collection.estimated_document_count()
|
| 33 |
+
|
| 34 |
+
def update_by_id(self, doc_id, col_name: str, col_val):
|
| 35 |
+
collection = self.__fetch_collection(self.collection_name)
|
| 36 |
+
collection.update_one(
|
| 37 |
+
{"_id": ObjectId(doc_id)},
|
| 38 |
+
{"$set": {col_name: col_val}}
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
def update_by_field(self, match, replacement):
|
| 42 |
+
collection = self.__fetch_collection(self.collection_name)
|
| 43 |
+
# collection.update_one(match,{"$set":replacement})
|
| 44 |
+
collection.update_many(match,{"$set":replacement})
|
README.md
CHANGED
|
@@ -1,13 +1,43 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# jRefactoring
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
# Project Overview
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
## Dependencies
|
| 9 |
+
|
| 10 |
+
- keras==2.12.0
|
| 11 |
+
- matplotlib==3.7.1
|
| 12 |
+
- numpy==1.23.5
|
| 13 |
+
- pandas==1.5.3
|
| 14 |
+
- PyDriller==2.4.1
|
| 15 |
+
- pymongo==4.3.3
|
| 16 |
+
- python-dotenv==1.0.0
|
| 17 |
+
- scikit_learn==1.2.2
|
| 18 |
+
- torch==2.0.0
|
| 19 |
+
- transformers==4.27.2
|
| 20 |
+
|
| 21 |
+
## Dataset
|
| 22 |
+
|
| 23 |
+
The dataset used in this project is collected from SEART tool. The parameters used in this tool are as follows:
|
| 24 |
+
|
| 25 |
+

|
| 26 |
+
|
| 27 |
+
It resulted in 146 projects. These projects served as our dataset.
|
| 28 |
+
|
| 29 |
+
## Models
|
| 30 |
+
|
| 31 |
+
## Results
|
| 32 |
+
|
| 33 |
+
## Instructions for Replication
|
| 34 |
+
|
| 35 |
+
## Code Structure
|
| 36 |
+
|
| 37 |
+
## Acknowledgments
|
| 38 |
+
|
| 39 |
+
## Contact Information
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
|
app.py
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
from flask import Flask, request, render_template
|
| 3 |
+
from predict import Predict
|
| 4 |
+
|
| 5 |
+
app = Flask(__name__)
|
| 6 |
+
|
| 7 |
+
@app.route('/')
|
| 8 |
+
def home():
|
| 9 |
+
return render_template('index.html')
|
| 10 |
+
|
| 11 |
+
@app.route('/predict', methods=['POST'])
|
| 12 |
+
def predict():
|
| 13 |
+
feature_list = request.form.to_dict()
|
| 14 |
+
result = Predict().predict(feature_list['code'])
|
| 15 |
+
return render_template('index.html', prediction_text=result)
|
| 16 |
+
|
| 17 |
+
if __name__ == "__main__":
|
| 18 |
+
app.run(debug=True, use_reloader=False, port='8080')
|
archive/codeBert.py
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from refactor_analysis import RefactorAnalysis
|
| 2 |
+
from transformers import AutoTokenizer, AutoModel
|
| 3 |
+
import torch
|
| 4 |
+
model_name = "huggingface/CodeBERTa-small-v1"
|
| 5 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 6 |
+
model = AutoModel.from_pretrained(model_name)
|
| 7 |
+
tokenized_inputs =[tokenizer(file_content, return_tensors="pt") for file_content in RefactorAnalysis()._parent_child_commit_map()]
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
with torch.no_grad():
|
| 11 |
+
outputs = [model(**input) for input in tokenized_inputs]
|
| 12 |
+
embeddings = [output.last_hidden_state.mean(dim=1).squeeze() for output in outputs]
|
| 13 |
+
# print(RefactorAnalysis()._parent_child_commit_map())
|
| 14 |
+
|
| 15 |
+
print(embeddings[0].shape)
|
autoencoder.py
ADDED
|
@@ -0,0 +1,164 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from keras.layers import Input, Dense, Flatten
|
| 2 |
+
from keras.models import Model
|
| 3 |
+
from Database import Database
|
| 4 |
+
import numpy as np, json
|
| 5 |
+
import matplotlib.pyplot as plt
|
| 6 |
+
from sklearn.model_selection import train_test_split
|
| 7 |
+
from sklearn.metrics import mean_squared_error
|
| 8 |
+
from dotenv import dotenv_values
|
| 9 |
+
import pandas as pd
|
| 10 |
+
# from tensorflow.python.ops.confusion_matrix import confusion_matrix
|
| 11 |
+
from sklearn.metrics import precision_recall_fscore_support
|
| 12 |
+
|
| 13 |
+
class Autoencoder:
|
| 14 |
+
|
| 15 |
+
def __get_autoencoder(self, input_dim) -> Model:
|
| 16 |
+
input_shape = (input_dim,)
|
| 17 |
+
input_layer = Input(shape=input_shape)
|
| 18 |
+
|
| 19 |
+
# Encoder layers
|
| 20 |
+
encoder = Flatten()(input_layer)
|
| 21 |
+
encoder = Dense(128, activation='relu')(encoder)
|
| 22 |
+
encoder = Dense(64, activation='relu')(encoder)
|
| 23 |
+
# encoder = Dense(32, activation='relu')(encoder)
|
| 24 |
+
|
| 25 |
+
# Decoder layers
|
| 26 |
+
# decoder = Dense(64, activation='relu')(encoder)
|
| 27 |
+
decoder = Dense(128, activation='relu')(encoder) #decoder
|
| 28 |
+
decoder = Dense(input_dim, activation='sigmoid')(decoder)
|
| 29 |
+
|
| 30 |
+
# Autoencoder model
|
| 31 |
+
autoencoder = Model(inputs=input_layer, outputs=decoder)
|
| 32 |
+
# autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
|
| 33 |
+
autoencoder.compile(optimizer='adam', loss='mse')
|
| 34 |
+
|
| 35 |
+
return autoencoder
|
| 36 |
+
|
| 37 |
+
def __print_summary(self, model: Model):
|
| 38 |
+
print(model.summary())
|
| 39 |
+
return
|
| 40 |
+
|
| 41 |
+
def __fit_autoencoder(self,epochs,batch_size,model: Model, train_var,valid_var=None):
|
| 42 |
+
history = model.fit(train_var,train_var,
|
| 43 |
+
# validation_data=(valid_var,valid_var),
|
| 44 |
+
epochs=epochs,batch_size=batch_size)
|
| 45 |
+
return history, model
|
| 46 |
+
|
| 47 |
+
def __split_train_test_val(self, data):
|
| 48 |
+
train_array, test_array = train_test_split(data,test_size=0.2,random_state=42)
|
| 49 |
+
train_array, valid_array = train_test_split(train_array,test_size=0.1,random_state=42)
|
| 50 |
+
return train_array, valid_array, test_array
|
| 51 |
+
|
| 52 |
+
@staticmethod
|
| 53 |
+
def __compute_metrics(conf_matrix):
|
| 54 |
+
precision = conf_matrix[1][1] / (conf_matrix[1][1] + conf_matrix[0][1])
|
| 55 |
+
|
| 56 |
+
if precision==1:
|
| 57 |
+
print(conf_matrix)
|
| 58 |
+
|
| 59 |
+
recall = conf_matrix[1][1] / (conf_matrix[1][1] + conf_matrix[1][0])
|
| 60 |
+
f1 = (2 * precision * recall) / (precision + recall)
|
| 61 |
+
# print("precision: " + str(precision) + ", recall: " + str(recall) + ", f1: " + str(f1))
|
| 62 |
+
return precision, recall, f1
|
| 63 |
+
|
| 64 |
+
def __find_optimal_modified(self,error_df: pd.DataFrame, steps=50):
|
| 65 |
+
min_error, max_error = error_df["Reconstruction_error"].min(), error_df["Reconstruction_error"].max()
|
| 66 |
+
optimal_threshold = (min_error+max_error)/2
|
| 67 |
+
y_pred = [0 if e > optimal_threshold else 1 for e in error_df.Reconstruction_error.values]
|
| 68 |
+
precision, recall, f1,_=precision_recall_fscore_support(error_df.True_class, y_pred, average='macro')
|
| 69 |
+
|
| 70 |
+
return optimal_threshold, precision, recall, f1
|
| 71 |
+
|
| 72 |
+
def __find_optimal(self,error_df: pd.DataFrame, steps=50):
|
| 73 |
+
min_error, max_error = error_df["Reconstruction_error"].min(), error_df["Reconstruction_error"].max()
|
| 74 |
+
optimal_threshold = min_error
|
| 75 |
+
max_f1 = 0
|
| 76 |
+
max_pr = 0
|
| 77 |
+
max_re = 0
|
| 78 |
+
# step_value = (max_error-min_error)/(steps - 1)
|
| 79 |
+
for threshold in np.arange(min_error, max_error, 0.005):
|
| 80 |
+
# print("Threshold: " + str(threshold))
|
| 81 |
+
# y_pred = [1 if e > threshold else 0 for e in error_df.Reconstruction_error.values]
|
| 82 |
+
y_pred = [0 if e > threshold else 1 for e in error_df.Reconstruction_error.values]
|
| 83 |
+
# conf_matrix = confusion_matrix(error_df.True_class, y_pred)
|
| 84 |
+
# precision, recall, f1 = self.__compute_metrics(conf_matrix)
|
| 85 |
+
# precision, recall, f1,_=precision_recall_fscore_support(error_df.True_class, y_pred, average='macro')
|
| 86 |
+
# precision, recall, f1,_=precision_recall_fscore_support(error_df.True_class, y_pred, average='micro')
|
| 87 |
+
# precision, recall, f1,_=precision_recall_fscore_support(error_df.True_class, y_pred, average='weighted')
|
| 88 |
+
precision, recall, f1,_=precision_recall_fscore_support(error_df.True_class, y_pred, average='binary')
|
| 89 |
+
|
| 90 |
+
if f1 > max_f1:
|
| 91 |
+
max_f1 = f1
|
| 92 |
+
optimal_threshold = threshold
|
| 93 |
+
max_pr = precision
|
| 94 |
+
max_re = recall
|
| 95 |
+
print(f"Result optimal_threshold={optimal_threshold}, max_precision={max_pr}, max_recall={max_re}, max_f1={max_f1}")
|
| 96 |
+
# return optimal_threshold, max_pr.numpy(), max_re.numpy(), max_f1.numpy()
|
| 97 |
+
return optimal_threshold, max_pr, max_re, max_f1
|
| 98 |
+
|
| 99 |
+
@staticmethod
|
| 100 |
+
def __split_by_percent(data,percent):
|
| 101 |
+
return train_test_split(data,test_size=0.3,random_state=42)
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def train_autoencoder(self):
|
| 106 |
+
#GraphCodeBERT
|
| 107 |
+
|
| 108 |
+
autoencoder = self.__get_autoencoder(768)
|
| 109 |
+
self.__print_summary(autoencoder)
|
| 110 |
+
|
| 111 |
+
#Create Dataset df
|
| 112 |
+
df = pd.DataFrame(columns=['Embedding','True_class'])
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
#DB
|
| 116 |
+
db = Database(dotenv_values(".env")['COLLECTION_NAME'])
|
| 117 |
+
# embeddings_list = [emb["embedding"] for emb in list(db.find_docs({"refactoring_type":"Extract Method"}))]
|
| 118 |
+
pos_emb_list, neg_emb_list = [],[]
|
| 119 |
+
for doc in list(db.find_docs({"refactoring_type":"Extract Method"})):
|
| 120 |
+
pos_emb_list.append(doc['embedding_pos'])
|
| 121 |
+
neg_emb_list.append(doc['embedding_neg'])
|
| 122 |
+
|
| 123 |
+
pos_emb_list_train, pos_emb_list_test = self.__split_by_percent(pos_emb_list,0.3)
|
| 124 |
+
_, neg_emb_list_test = self.__split_by_percent(neg_emb_list,0.3)
|
| 125 |
+
|
| 126 |
+
x_train = np.array(pos_emb_list_train)
|
| 127 |
+
x_test = np.array(pos_emb_list_test+neg_emb_list_test)
|
| 128 |
+
y_test = np.array([1 for i in range(0,len(pos_emb_list_test))]+[0 for i in range(0,len(neg_emb_list_test))])
|
| 129 |
+
# print(np.array(pos_emb_list_train).shape)
|
| 130 |
+
|
| 131 |
+
epoch = 25
|
| 132 |
+
history, trained_model = self.__fit_autoencoder(epoch,32,autoencoder,x_train)
|
| 133 |
+
trained_model.save('./results/autoencoder_'+str(epoch)+'.hdf5')
|
| 134 |
+
|
| 135 |
+
#Test
|
| 136 |
+
test_predict = trained_model.predict(x_test)
|
| 137 |
+
|
| 138 |
+
mse = np.mean(np.power(x_test - test_predict, 2), axis=1)
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
error_df = pd.DataFrame({'Reconstruction_error': mse,
|
| 142 |
+
'True_class': y_test})
|
| 143 |
+
|
| 144 |
+
print("Max: ", error_df["Reconstruction_error"].max())
|
| 145 |
+
print("Min: ", error_df["Reconstruction_error"].min())
|
| 146 |
+
|
| 147 |
+
# optimal_threshold, precision, recall, f1 = self.__find_optimal(error_df,100)
|
| 148 |
+
optimal_threshold, precision, recall, f1 = self.__find_optimal_modified(error_df,100)
|
| 149 |
+
print(f"Result optimal_threshold={optimal_threshold}, max_precision={precision}, max_recall={recall}, max_f1={f1}")
|
| 150 |
+
metrics = {
|
| 151 |
+
"Threshold":optimal_threshold,
|
| 152 |
+
"Precision": precision,
|
| 153 |
+
"Recall":recall,
|
| 154 |
+
"F1":f1
|
| 155 |
+
}
|
| 156 |
+
with open('./results/metrics.json','w') as fp:
|
| 157 |
+
json.dump(metrics,fp)
|
| 158 |
+
|
| 159 |
+
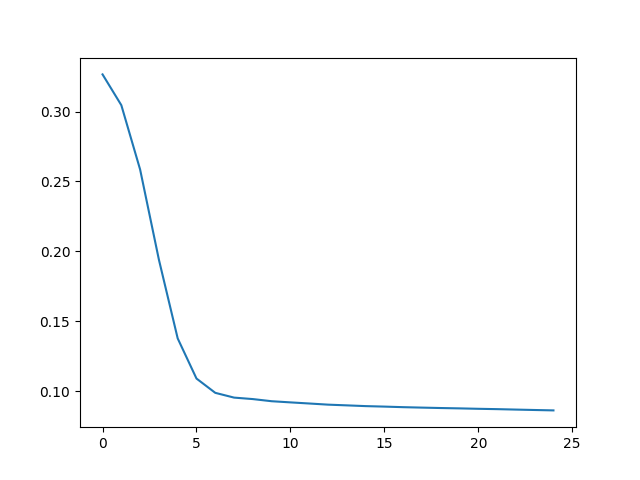
plt.plot(history.history['loss'])
|
| 160 |
+
|
| 161 |
+
plt.savefig("./results/training_graph.png")
|
| 162 |
+
|
| 163 |
+
if __name__=="__main__":
|
| 164 |
+
Autoencoder().train_autoencoder()
|
graphCodeBert.py
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import AutoTokenizer, AutoModel
|
| 2 |
+
|
| 3 |
+
from Database import Database
|
| 4 |
+
|
| 5 |
+
class GraphCodeBert:
|
| 6 |
+
|
| 7 |
+
def __init__(self) -> None:
|
| 8 |
+
model_name = "microsoft/graphcodebert-base"
|
| 9 |
+
self.tokenizer= AutoTokenizer.from_pretrained(model_name)
|
| 10 |
+
self.model=AutoModel.from_pretrained(model_name)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def generate_embeddings(self):
|
| 14 |
+
database = Database("refactoring_details_neg")
|
| 15 |
+
# database.connect_db()
|
| 16 |
+
# collection = database.fetch_collection("refactoring_information")
|
| 17 |
+
# collection_len = collection.estimated_document_count()
|
| 18 |
+
collection_len = database.estimated_doc_count()
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
doc_count = 1
|
| 22 |
+
for doc in database.find_docs({}, {"_id": 1, "method_refactored": 1, "meth_rf_neg":1}):
|
| 23 |
+
doc_id = doc["_id"]
|
| 24 |
+
code_snippet = doc["method_refactored"]
|
| 25 |
+
code_snippet_neg = doc["meth_rf_neg"]
|
| 26 |
+
print(f'Generating embedding for doc_id:{doc_id} | Count-{doc_count}...')
|
| 27 |
+
|
| 28 |
+
# Compute embeddings
|
| 29 |
+
tokenized_input_pos = self.tokenizer(code_snippet, return_tensors="pt", padding=True, truncation=True)
|
| 30 |
+
output = self.model(**tokenized_input_pos)
|
| 31 |
+
embedding_pos = output.last_hidden_state.mean(dim=1).squeeze().tolist()
|
| 32 |
+
|
| 33 |
+
#Neg Embedding
|
| 34 |
+
tokenized_input_neg = self.tokenizer(code_snippet_neg, return_tensors="pt", padding=True, truncation=True)
|
| 35 |
+
output = self.model(**tokenized_input_neg)
|
| 36 |
+
embedding_neg = output.last_hidden_state.mean(dim=1).squeeze().tolist()
|
| 37 |
+
|
| 38 |
+
# Update document in MongoDB with embedding
|
| 39 |
+
database.update_by_id(doc_id, "embedding_pos", embedding_pos)
|
| 40 |
+
database.update_by_id(doc_id,"embedding_neg", embedding_neg)
|
| 41 |
+
|
| 42 |
+
collection_len -= 1
|
| 43 |
+
doc_count += 1
|
| 44 |
+
print(f'Embedding added for doc_id:{doc_id} | Remaining: {collection_len}.')
|
| 45 |
+
|
| 46 |
+
def generate_individual_embedding(self,code_snippet):
|
| 47 |
+
tokenized_input_pos = self.tokenizer(code_snippet, return_tensors="pt", padding=True, truncation=True)
|
| 48 |
+
output = self.model(**tokenized_input_pos)
|
| 49 |
+
embedding = output.last_hidden_state.mean(dim=1).squeeze().tolist()
|
| 50 |
+
|
| 51 |
+
return embedding
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
if __name__=="__main__":
|
| 56 |
+
GraphCodeBert().generate_embeddings()
|
helpers/SEART.png
ADDED
|
mongodb-playground/queries.mongodb
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
use('jrefactoring');
|
| 2 |
+
|
| 3 |
+
db.refactoring_information.count({})
|
| 4 |
+
// db.refactoring_information.drop()
|
predict.py
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from graphCodeBert import GraphCodeBert
|
| 2 |
+
from keras.models import load_model, Model
|
| 3 |
+
import numpy as np, json
|
| 4 |
+
|
| 5 |
+
class Predict:
|
| 6 |
+
|
| 7 |
+
def __generate_code_embedding(self,code_snippet):
|
| 8 |
+
embedding = np.array(GraphCodeBert().generate_individual_embedding(code_snippet)).reshape((1,768))
|
| 9 |
+
return embedding
|
| 10 |
+
def __calculate_loss(self,code_embedding,model_name):
|
| 11 |
+
model:Model = load_model(f'results/{model_name}.hdf5')
|
| 12 |
+
return model.evaluate(code_embedding,code_embedding)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def predict(self,code_snippet):
|
| 16 |
+
model_name="autoencoder_25"
|
| 17 |
+
|
| 18 |
+
code_embedding = self.__generate_code_embedding(code_snippet)
|
| 19 |
+
print("Input code snippet shape: ",code_embedding.shape)
|
| 20 |
+
loss = self.__calculate_loss(code_embedding,model_name)
|
| 21 |
+
print("Reconstruction Loss: ",loss)
|
| 22 |
+
|
| 23 |
+
with open('./results/metrics.json',"r") as fp:
|
| 24 |
+
metric_json = json.loads(fp.read())
|
| 25 |
+
|
| 26 |
+
threshold = metric_json["Threshold"]
|
| 27 |
+
|
| 28 |
+
return "Not a candidate for refactoring" if loss>threshold else "Is a candidate for refactoring"
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
if __name__=="__main__":
|
| 34 |
+
Predict().predict(""" public void sleep(){
|
| 35 |
+
int s1 = 1;
|
| 36 |
+
int s2 = 2;
|
| 37 |
+
int s3 = 3;
|
| 38 |
+
int s4 = 4;
|
| 39 |
+
int s5 = 5;
|
| 40 |
+
int s6 = 6;
|
| 41 |
+
int s7 = 7;
|
| 42 |
+
int s8 = 8;
|
| 43 |
+
|
| 44 |
+
}""")
|
| 45 |
+
|
refactor_analysis.py
ADDED
|
@@ -0,0 +1,142 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os, subprocess, pydriller,json, pandas as pd
|
| 2 |
+
import sys
|
| 3 |
+
from dotenv import dotenv_values
|
| 4 |
+
|
| 5 |
+
from Database import Database
|
| 6 |
+
|
| 7 |
+
class RefactorAnalysis:
|
| 8 |
+
|
| 9 |
+
def __init__(self,input_path="",output_path=""):
|
| 10 |
+
if input_path=="":
|
| 11 |
+
self.input_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),"data","refactoring-toy-example")
|
| 12 |
+
else:
|
| 13 |
+
self.input_path=input_path
|
| 14 |
+
if output_path=="":
|
| 15 |
+
self.output_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),"output_ref","output.json")
|
| 16 |
+
else:
|
| 17 |
+
self.output_path=output_path
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def generate_refactor_details(self):
|
| 21 |
+
# ref_miner_bin = os.path.join(os.path.dirname(os.path.abspath(__file__)),"executable","RefactoringMiner","bin")
|
| 22 |
+
ref_miner_bin = os.path.abspath("executable/RefactoringMiner/bin")
|
| 23 |
+
# command = ["cd",ref_miner_bin,"&&","sh","RefactoringMiner","-a",self.input_path,"-json",self.output_path]
|
| 24 |
+
command = ["sh","RefactoringMiner","-a",self.input_path,"-json",self.output_path]
|
| 25 |
+
try:
|
| 26 |
+
os.chdir(ref_miner_bin)
|
| 27 |
+
shell_result = subprocess.run(command,capture_output=True,text=True)
|
| 28 |
+
shell_result.check_returncode()
|
| 29 |
+
# if shell_result!=0:
|
| 30 |
+
# raise Exception("Couldn't analyze repository - "+self.input_path+" with RefactorMiner")
|
| 31 |
+
# return 0
|
| 32 |
+
except subprocess.CalledProcessError as error:
|
| 33 |
+
print(error)
|
| 34 |
+
sys.exit()
|
| 35 |
+
|
| 36 |
+
except Exception as e:
|
| 37 |
+
print(e)
|
| 38 |
+
return 1
|
| 39 |
+
|
| 40 |
+
def parse_json_output(self):
|
| 41 |
+
#TODO
|
| 42 |
+
#Filter for Method Refs
|
| 43 |
+
with open(self.output_path) as f:
|
| 44 |
+
json_output = json.load(f)
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
dict_output = {}
|
| 48 |
+
for obj in json_output["commits"]:
|
| 49 |
+
if len(obj["refactorings"])==0:
|
| 50 |
+
continue
|
| 51 |
+
changes = []
|
| 52 |
+
se_lines = []
|
| 53 |
+
for ref in obj["refactorings"]:
|
| 54 |
+
if not "Method" in ref["type"]:
|
| 55 |
+
continue
|
| 56 |
+
for parent_refs in ref["leftSideLocations"]:
|
| 57 |
+
|
| 58 |
+
changes.append(parent_refs["filePath"])
|
| 59 |
+
se_lines.append((parent_refs["startLine"],parent_refs["endLine"]))
|
| 60 |
+
# list_output.append(dict_output)
|
| 61 |
+
dict_output[obj["sha1"]]={
|
| 62 |
+
"paths":changes,
|
| 63 |
+
"ref_start_end":se_lines,
|
| 64 |
+
"ref_type":ref["type"]
|
| 65 |
+
}
|
| 66 |
+
|
| 67 |
+
return dict_output
|
| 68 |
+
|
| 69 |
+
def create_project_dataframe(self):
|
| 70 |
+
|
| 71 |
+
df = pd.DataFrame(columns=['commit','refactoring_type','filename','meth_rf_neg','method_refactored'])
|
| 72 |
+
|
| 73 |
+
parse_output_dict = self.parse_json_output()
|
| 74 |
+
commits_to_analyze = list(parse_output_dict.keys())
|
| 75 |
+
for commit in pydriller.Repository(self.input_path, only_commits=commits_to_analyze).traverse_commits():
|
| 76 |
+
ref_list = parse_output_dict.get(commit.hash)
|
| 77 |
+
ref_path_name = list(map(lambda x: str(x).split("/")[len(str(x).split("/"))-1],ref_list["paths"]))
|
| 78 |
+
for cf in commit.modified_files:
|
| 79 |
+
try:
|
| 80 |
+
index_ref = ref_path_name.index(cf.filename)
|
| 81 |
+
except ValueError as ve:
|
| 82 |
+
continue
|
| 83 |
+
if len(cf.changed_methods)==0:
|
| 84 |
+
continue
|
| 85 |
+
#Diff between methods_changed and methods_before - does methods_changed reduces loop else we have to loop for all methods
|
| 86 |
+
for cm in cf.changed_methods:
|
| 87 |
+
|
| 88 |
+
if cm.start_line<=ref_list["ref_start_end"][index_ref][0] and cm.end_line>=ref_list["ref_start_end"][index_ref][1]:
|
| 89 |
+
method_source_code = self.__split_and_extract_methods(cf.source_code_before,cm.start_line,cm.end_line)
|
| 90 |
+
method_source_code_neg = self.__split_and_extract_methods(cf.source_code,cm.start_line,cm.end_line)
|
| 91 |
+
class_source_code = cf.source_code_before
|
| 92 |
+
|
| 93 |
+
# df_row = {"commit":commit.hash,"refactoring_type":ref_list["ref_type"],"filename":cf.filename, "meth_rf_neg":class_source_code,"method_refactored":method_source_code}
|
| 94 |
+
df_row = {"commit":commit.hash,"refactoring_type":ref_list["ref_type"],"filename":cf.filename, "meth_rf_neg":method_source_code_neg,"method_refactored":method_source_code}
|
| 95 |
+
df.loc[len(df)] = df_row
|
| 96 |
+
return df
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def __split_and_extract_methods(self, source_code,start_line, end_line):
|
| 100 |
+
source_code_lines = str(source_code).splitlines()
|
| 101 |
+
return "\n".join(source_code_lines[start_line-1:end_line])
|
| 102 |
+
|
| 103 |
+
def main():
|
| 104 |
+
if not os.path.exists("data/repos/"):
|
| 105 |
+
try:
|
| 106 |
+
print("Starting repo download")
|
| 107 |
+
repo_script = subprocess.run(["python","repo_download.py"], capture_output=True, text=True)
|
| 108 |
+
repo_script.check_returncode()
|
| 109 |
+
except subprocess.CalledProcessError as err:
|
| 110 |
+
print(err)
|
| 111 |
+
sys.exit(1)
|
| 112 |
+
print("Repo Download Completed")
|
| 113 |
+
lst_repos = next(os.walk("data/repos/"))[1]
|
| 114 |
+
print(len(lst_repos))
|
| 115 |
+
|
| 116 |
+
cwd = os.path.dirname(os.path.abspath(__file__))
|
| 117 |
+
final_df = pd.DataFrame(columns=['commit','refactoring_type','filename','meth_rf_neg','method_refactored'])
|
| 118 |
+
database = Database(dotenv_values(".env")['COLLECTION_NAME'])
|
| 119 |
+
# database.connect_db()
|
| 120 |
+
count=1
|
| 121 |
+
batch_size = 5
|
| 122 |
+
for idx,repo in enumerate(lst_repos):
|
| 123 |
+
os.chdir(cwd)
|
| 124 |
+
try:
|
| 125 |
+
ref_obj = RefactorAnalysis(os.path.abspath(os.path.join("data/repos",repo)),os.path.abspath(os.path.join("output_ref",repo+".json")))
|
| 126 |
+
# ref_miner = ref_obj.generate_refactor_details() #Modify
|
| 127 |
+
df = ref_obj.create_project_dataframe()
|
| 128 |
+
except Exception as e:
|
| 129 |
+
print(e)
|
| 130 |
+
continue
|
| 131 |
+
|
| 132 |
+
final_df = pd.concat([final_df,df], ignore_index=True)
|
| 133 |
+
if count==batch_size or idx==len(lst_repos)-1:
|
| 134 |
+
print("Inserting into DB", idx)
|
| 135 |
+
database.insert_docs(final_df.to_dict(orient="records"))
|
| 136 |
+
final_df = pd.DataFrame(columns=['commit','refactoring_type','filename','meth_rf_neg','method_refactored'])
|
| 137 |
+
count=1
|
| 138 |
+
else:
|
| 139 |
+
count+=1
|
| 140 |
+
|
| 141 |
+
if __name__=="__main__":
|
| 142 |
+
main()
|
repo_download.py
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os, subprocess, csv
|
| 2 |
+
|
| 3 |
+
def download_repo(repo_name, repos_base_path):
|
| 4 |
+
repo_fullname = repo_name.strip('\n')
|
| 5 |
+
if not repo_fullname == "":
|
| 6 |
+
project_url = "https://github.com/" + repo_fullname + ".git"
|
| 7 |
+
folder_name = repo_fullname.replace("/", "_")
|
| 8 |
+
folder_path_new = os.path.join(repos_base_path, folder_name)
|
| 9 |
+
|
| 10 |
+
if not os.path.exists(folder_path_new):
|
| 11 |
+
_download_with_url(project_url, folder_path_new)
|
| 12 |
+
else:
|
| 13 |
+
print(folder_name + " already exists. skipping ...")
|
| 14 |
+
|
| 15 |
+
def _download_with_url(project_url, folder_path):
|
| 16 |
+
if not os.path.exists(folder_path):
|
| 17 |
+
os.makedirs(folder_path)
|
| 18 |
+
print("cloning... " + project_url)
|
| 19 |
+
try:
|
| 20 |
+
# depth=1 is only to get the current snapshot (rather than all commits)
|
| 21 |
+
subprocess.call(["git", "clone", project_url, folder_path])
|
| 22 |
+
except Exception as ex:
|
| 23 |
+
print("Exception occurred!!" + str(ex))
|
| 24 |
+
return
|
| 25 |
+
print("cloning done.")
|
| 26 |
+
|
| 27 |
+
if __name__=='__main__':
|
| 28 |
+
print("Starting repo download")
|
| 29 |
+
with open("data/repos.csv") as repo_file:
|
| 30 |
+
reader = csv.reader(repo_file, delimiter=',')
|
| 31 |
+
next(reader)
|
| 32 |
+
for line in reader:
|
| 33 |
+
download_repo(line[0], 'data/repos')
|
requirements.txt
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Flask==2.2.3
|
| 2 |
+
keras==2.12.0
|
| 3 |
+
matplotlib==3.7.1
|
| 4 |
+
numpy==1.23.5
|
| 5 |
+
pandas==1.5.3
|
| 6 |
+
PyDriller==2.4.1
|
| 7 |
+
pymongo==4.3.3
|
| 8 |
+
python-dotenv==1.0.0
|
| 9 |
+
scikit_learn==1.2.2
|
| 10 |
+
torch==2.0.0
|
| 11 |
+
transformers==4.27.2
|
results/metrics.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"Threshold": 0.11413681637927062, "Precision": 0.7785714285714286, "Recall": 0.6025641025641025, "F1": 0.5280109310950615}
|
results/training_graph.png
ADDED
|
templates/css/main.css
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
body {
|
| 2 |
+
margin: 0;
|
| 3 |
+
padding: 0;
|
| 4 |
+
font-family: "Helvetica Neue", Helvetica, Arial, sans-serif;
|
| 5 |
+
color: #444;
|
| 6 |
+
}
|
| 7 |
+
/*
|
| 8 |
+
* Formatting the header area
|
| 9 |
+
*/
|
| 10 |
+
header {
|
| 11 |
+
background-color: #DFB887;
|
| 12 |
+
height: 35px;
|
| 13 |
+
width: 100%;
|
| 14 |
+
opacity: .9;
|
| 15 |
+
margin-bottom: 10px;
|
| 16 |
+
}
|
| 17 |
+
header h1.logo {
|
| 18 |
+
margin: 0;
|
| 19 |
+
font-size: 1.7em;
|
| 20 |
+
color: #fff;
|
| 21 |
+
text-transform: uppercase;
|
| 22 |
+
float: left;
|
| 23 |
+
}
|
| 24 |
+
header h1.logo:hover {
|
| 25 |
+
color: #fff;
|
| 26 |
+
text-decoration: none;
|
| 27 |
+
}
|
| 28 |
+
/*
|
| 29 |
+
* Centering the body content
|
| 30 |
+
*/
|
| 31 |
+
.container {
|
| 32 |
+
width: 1200px;
|
| 33 |
+
margin: 0 auto;
|
| 34 |
+
}
|
| 35 |
+
div.home {
|
| 36 |
+
padding: 10px 0 30px 0;
|
| 37 |
+
background-color: #E6E6FA;
|
| 38 |
+
-webkit-border-radius: 6px;
|
| 39 |
+
-moz-border-radius: 6px;
|
| 40 |
+
border-radius: 6px;
|
| 41 |
+
}
|
| 42 |
+
div.about {
|
| 43 |
+
padding: 10px 0 30px 0;
|
| 44 |
+
background-color: #E6E6FA;
|
| 45 |
+
-webkit-border-radius: 6px;
|
| 46 |
+
-moz-border-radius: 6px;
|
| 47 |
+
border-radius: 6px;
|
| 48 |
+
}
|
| 49 |
+
h2 {
|
| 50 |
+
font-size: 3em;
|
| 51 |
+
margin-top: 40px;
|
| 52 |
+
text-align: center;
|
| 53 |
+
letter-spacing: -2px;
|
| 54 |
+
}
|
| 55 |
+
h3 {
|
| 56 |
+
font-size: 1.7em;
|
| 57 |
+
font-weight: 100;
|
| 58 |
+
margin-top: 30px;
|
| 59 |
+
text-align: center;
|
| 60 |
+
letter-spacing: -1px;
|
| 61 |
+
color: #999;
|
| 62 |
+
}
|
| 63 |
+
.menu {
|
| 64 |
+
float: right;
|
| 65 |
+
margin-top: 8px;
|
| 66 |
+
}
|
| 67 |
+
.menu li {
|
| 68 |
+
display: inline;
|
| 69 |
+
}
|
| 70 |
+
.menu li + li {
|
| 71 |
+
margin-left: 35px;
|
| 72 |
+
}
|
| 73 |
+
.menu li a {
|
| 74 |
+
color: #444;
|
| 75 |
+
text-decoration: none;
|
| 76 |
+
}
|
templates/index.html
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!DOCTYPE html>
|
| 2 |
+
<html >
|
| 3 |
+
<head>
|
| 4 |
+
<meta charset="UTF-8">
|
| 5 |
+
<title>jRefactoring</title>
|
| 6 |
+
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
| 7 |
+
<link rel="stylesheet" href="{{ url_for('static', filename='css/main.css') }}">
|
| 8 |
+
<script src="https://code.jquery.com/jquery-3.3.1.slim.min.js" integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo" crossorigin="anonymous"></script>
|
| 9 |
+
<script src="https://cdn.jsdelivr.net/npm/popper.js@1.14.7/dist/umd/popper.min.js" integrity="sha384-UO2eT0CpHqdSJQ6hJty5KVphtPhzWj9WO1clHTMGa3JDZwrnQq4sF86dIHNDz0W1" crossorigin="anonymous"></script>
|
| 10 |
+
<script src="https://cdn.jsdelivr.net/npm/bootstrap@4.3.1/dist/js/bootstrap.min.js" integrity="sha384-JjSmVgyd0p3pXB1rRibZUAYoIIy6OrQ6VrjIEaFf/nJGzIxFDsf4x0xIM+B07jRM" crossorigin="anonymous"></script>
|
| 11 |
+
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bootstrap@4.3.1/dist/css/bootstrap.min.css" integrity="sha384-ggOyR0iXCbMQv3Xipma34MD+dH/1fQ784/j6cY/iJTQUOhcWr7x9JvoRxT2MZw1T" crossorigin="anonymous">
|
| 12 |
+
</head>
|
| 13 |
+
|
| 14 |
+
<body>
|
| 15 |
+
<div class="container">
|
| 16 |
+
<div class="prediction">
|
| 17 |
+
<h1><a href="https://git.cs.dal.ca/gshetty/jrefactoring.git">jRefactoring</a></h1>
|
| 18 |
+
<form action="{{ url_for('predict')}}"method="post">
|
| 19 |
+
<p>Source Code:</p>
|
| 20 |
+
<p>Enter your code snippet (Java)</p>
|
| 21 |
+
<code><textarea type="textbox" id="code" name="code" required="required" rows="10" cols="100" autofocus autocomplete="off"></textarea></code><br>
|
| 22 |
+
<button type="submit" class="btn btn-primary btn-large">Predict</button>
|
| 23 |
+
</form>
|
| 24 |
+
<br>
|
| 25 |
+
<b>{{ prediction_text }}</b>
|
| 26 |
+
</div>
|
| 27 |
+
</div>
|
| 28 |
+
</body>
|
| 29 |
+
</html>
|
train.png
ADDED
|