Spaces:
Runtime error

Runtime error
Commit
•
f4fac26
1
Parent(s):
dfbdf47
Upload 59 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +1 -0
- .gitignore +27 -0
- LICENSE +201 -0
- README.en.md +457 -0
- README.md +474 -12
- accelerate.yaml +25 -0
- api_demo.py +104 -0
- app.py +37 -0
- cli_demo.py +105 -0
- config.py +139 -0
- data/my_test_dataset_2k.parquet +3 -0
- data/my_train_dataset_3k.parquet +3 -0
- data/my_valid_dataset_1k.parquet +3 -0
- dpo_train.py +203 -0
- eval/.gitignore +5 -0
- eval/c_eavl.ipynb +657 -0
- eval/cmmlu.ipynb +241 -0
- finetune_examples/.gitignore +3 -0
- finetune_examples/info_extract/data_process.py +146 -0
- finetune_examples/info_extract/finetune_IE_task.ipynb +463 -0
- img/api_example.png +0 -0
- img/dpo_loss.png +0 -0
- img/ie_task_chat.png +0 -0
- img/sentence_length.png +0 -0
- img/sft_loss.png +0 -0
- img/show1.png +0 -0
- img/stream_chat.gif +3 -0
- img/train_loss.png +0 -0
- model/__pycache__/chat_model.cpython-310.pyc +0 -0
- model/__pycache__/infer.cpython-310.pyc +0 -0
- model/chat_model.py +74 -0
- model/chat_model_config.py +4 -0
- model/dataset.py +290 -0
- model/infer.py +121 -0
- model/trainer.py +606 -0
- model_save/.gitattributes +35 -0
- model_save/README.md +0 -0
- model_save/config.json +33 -0
- model_save/configuration_chat_model.py +4 -0
- model_save/generation_config.json +7 -0
- model_save/model.safetensors +3 -0
- model_save/modeling_chat_model.py +74 -0
- model_save/put_model_files_here +0 -0
- model_save/special_tokens_map.json +5 -0
- model_save/tokenizer.json +0 -0
- model_save/tokenizer_config.json +66 -0
- pre_train.py +136 -0
- requirements.txt +29 -0
- sft_train.py +134 -0
- train.ipynb +82 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
img/stream_chat.gif filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.vscode/*
|
| 2 |
+
.vscode
|
| 3 |
+
!.vscode/settings.json
|
| 4 |
+
!.vscode/tasks.json
|
| 5 |
+
!.vscode/launch.json
|
| 6 |
+
!.vscode/extensions.json
|
| 7 |
+
*.code-workspace
|
| 8 |
+
|
| 9 |
+
# Local History for Visual Studio Code
|
| 10 |
+
.history/
|
| 11 |
+
.idea/
|
| 12 |
+
|
| 13 |
+
# python cache
|
| 14 |
+
*.pyc
|
| 15 |
+
*.cache
|
| 16 |
+
|
| 17 |
+
logs/*
|
| 18 |
+
|
| 19 |
+
data/*
|
| 20 |
+
!/data/my_train_dataset_3k.parquet
|
| 21 |
+
!/data/my_test_dataset_2k.parquet
|
| 22 |
+
!/data/my_valid_dataset_1k.parquet
|
| 23 |
+
|
| 24 |
+
model_save/*
|
| 25 |
+
!model_save/put_model_files_here
|
| 26 |
+
|
| 27 |
+
wandb/*
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
README.en.md
ADDED
|
@@ -0,0 +1,457 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
|
| 3 |
+
# A Small Chat with Chinese Language Model: ChatLM-Chinese-0.2B
|
| 4 |
+
[中文](./README.md) | English
|
| 5 |
+
|
| 6 |
+
</div>
|
| 7 |
+
|
| 8 |
+
# 1. 👋Introduction
|
| 9 |
+
|
| 10 |
+
Today's large language models tend to have large parameters, and consumer-grade computers are slow to do simple inference, let alone train a model from scratch. The goal of this project is to train a generative language models from scratch, including data cleaning, tokenizer training, model pre-training, SFT instruction fine-tuning, RLHF optimization, etc.
|
| 11 |
+
|
| 12 |
+
ChatLM-mini-Chinese is a small Chinese chat model with only 0.2B (added shared weight is about 210M) parameters. It can be pre-trained on machine with a minimum of 4GB of GPU memory (`batch_size=1`, `fp16` or `bf16`), `float16` loading and inference only require a minimum of 512MB of GPU memory.
|
| 13 |
+
|
| 14 |
+
- Make public all pre-training, SFT instruction fine-tuning, and DPO preference optimization datasets sources.
|
| 15 |
+
- Use the `Huggingface` NLP framework, including `transformers`, `accelerate`, `trl`, `peft`, etc.
|
| 16 |
+
- Self-implemented `trainer`, supporting pre-training and SFT fine-tuning on a single machine with a single card or with multiple cards on a single machine. It supports stopping at any position during training and continuing training at any position.
|
| 17 |
+
- Pre-training: Integrated into end-to-end `Text-to-Text` pre-training, non-`mask` mask prediction pre-training.
|
| 18 |
+
- Open source all data cleaning (such as standardization, document deduplication based on mini_hash, etc.), data set construction, data set loading optimization and other processes;
|
| 19 |
+
- tokenizer multi-process word frequency statistics, supports tokenizer training of `sentencepiece` and `huggingface tokenizers`;
|
| 20 |
+
- Pre-training supports checkpoint at any step, and training can be continued from the breakpoint;
|
| 21 |
+
- Streaming loading of large datasets (GB level), supporting buffer data shuffling, does not use memory or hard disk as cache, effectively reducing memory and disk usage. configuring `batch_size=1, max_len=320`, supporting pre-training on a machine with at least 16GB RAM + 4GB GPU memory;
|
| 22 |
+
- Training log record.
|
| 23 |
+
- SFT fine-tuning: open source SFT dataset and data processing process.
|
| 24 |
+
- The self-implemented `trainer` supports prompt command fine-tuning and supports any breakpoint to continue training;
|
| 25 |
+
- Support `sequence to sequence` fine-tuning of `Huggingface trainer`;
|
| 26 |
+
- Supports traditional low learning rate and only trains fine-tuning of the decoder layer.
|
| 27 |
+
- RLHF Preference optimization: Use DPO to optimize all preferences.
|
| 28 |
+
- Support using `peft lora` for preference optimization;
|
| 29 |
+
- Supports model merging, `Lora adapter` can be merged into the original model.
|
| 30 |
+
- Support downstream task fine-tuning: [finetune_examples](./finetune_examples/info_extract/) gives a fine-tuning example of the **Triple Information Extraction Task**. The model dialogue capability after fine-tuning is still there.
|
| 31 |
+
|
| 32 |
+
If you need to do retrieval augmented generation (RAG) based on small models, you can refer to my other project [Phi2-mini-Chinese](https://github.com/charent/Phi2-mini-Chinese). For the code, see [rag_with_langchain.ipynb](https://github.com/charent/Phi2-mini-Chinese/blob/main/rag_with_langchain.ipynb)
|
| 33 |
+
|
| 34 |
+
🟢**Latest Update**
|
| 35 |
+
|
| 36 |
+
<details open>
|
| 37 |
+
<summary> <b>2024-01-30</b> </summary>
|
| 38 |
+
- The model files are updated to Moda modelscope and can be quickly downloaded through `snapshot_download`. <br/>
|
| 39 |
+
</details>
|
| 40 |
+
|
| 41 |
+
<details close>
|
| 42 |
+
<summary> <b>2024-01-07</b> </summary>
|
| 43 |
+
- Add document deduplication based on mini hash during the data cleaning process (in this project, it's to deduplicated the rows of datasets actually). Prevent the model from spitting out training data during inference after encountering multiple repeated data. <br/>
|
| 44 |
+
- Add the `DropDatasetDuplicate` class to implement deduplication of documents from large data sets. <br/>
|
| 45 |
+
</details>
|
| 46 |
+
|
| 47 |
+
<details close>
|
| 48 |
+
<summary> <b>2023-12-29</b> </summary>
|
| 49 |
+
- Update the model code (weights is NOT changed), you can directly use `AutoModelForSeq2SeqLM.from_pretrained(...)` to load the model for using. <br/>
|
| 50 |
+
- Updated readme documentation. <br/>
|
| 51 |
+
</details>
|
| 52 |
+
|
| 53 |
+
<details close>
|
| 54 |
+
<summary> <b>2023-12-18</b> </summary>
|
| 55 |
+
- Supplementary use of the `ChatLM-mini-0.2B` model to fine-tune the downstream triplet information extraction task code and display the extraction results. <br/>
|
| 56 |
+
- Updated readme documentation. <br/>
|
| 57 |
+
</details>
|
| 58 |
+
|
| 59 |
+
<details close>
|
| 60 |
+
<summary> <b>2023-12-14</b> </summary>
|
| 61 |
+
- Updated model weight files after SFT and DPO. <br/>
|
| 62 |
+
- Updated pre-training, SFT and DPO scripts. <br/>
|
| 63 |
+
- update `tokenizer` to `PreTrainedTokenizerFast`. <br/>
|
| 64 |
+
- Refactor the `dataset` code to support dynamic maximum length. The maximum length of each batch is determined by the longest text in the batch, saving GPU memory. <br/>
|
| 65 |
+
- Added `tokenizer` training details. <br/>
|
| 66 |
+
</details>
|
| 67 |
+
|
| 68 |
+
<details close>
|
| 69 |
+
<summary> <b>2023-12-04</b> </summary>
|
| 70 |
+
- Updated `generate` parameters and model effect display. <br/>
|
| 71 |
+
- Updated readme documentation. <br/>
|
| 72 |
+
</details>
|
| 73 |
+
|
| 74 |
+
<details close>
|
| 75 |
+
<summary> <b>2023-11-28</b> </summary>
|
| 76 |
+
- Updated dpo training code and model weights. <br/>
|
| 77 |
+
</details>
|
| 78 |
+
|
| 79 |
+
<details close>
|
| 80 |
+
<summary> <b>2023-10-19</b> </summary>
|
| 81 |
+
- The project is open source and the model weights are open for download. <br/>
|
| 82 |
+
</details>
|
| 83 |
+
|
| 84 |
+
# 2. 🛠️ChatLM-0.2B-Chinese model training process
|
| 85 |
+
## 2.1 Pre-training dataset
|
| 86 |
+
All datasets come from the **Single Round Conversation** dataset published on the Internet. After data cleaning and formatting, they are saved as parquet files. For the data processing process, see `utils/raw_data_process.py`. Main datasets include:
|
| 87 |
+
|
| 88 |
+
1. Community Q&A json version webtext2019zh-large-scale high-quality dataset, see: [nlp_chinese_corpus](https://github.com/brightmart/nlp_chinese_corpus). A total of 4.1 million, with 2.6 million remaining after cleaning.
|
| 89 |
+
2. baike_qa2019 encyclopedia Q&A, see: <https://aistudio.baidu.com/datasetdetail/107726>, a total of 1.4 million, and the remaining 1.3 million after waking up.
|
| 90 |
+
3. Chinese medical field question and answer dataset, see: [Chinese-medical-dialogue-data](https://github.com/Toyhom/Chinese-medical-dialogue-data), with a total of 790,000, and the remaining 790,000 after cleaning.
|
| 91 |
+
4. ~~Financial industry question and answer data, see: <https://zhuanlan.zhihu.com/p/609821974>, a total of 770,000, and the remaining 520,000 after cleaning. ~~**The data quality is too poor and not used. **
|
| 92 |
+
5. Zhihu question and answer data, see: [Zhihu-KOL](https://huggingface.co/datasets/wangrui6/Zhihu-KOL), with a total of 1 million rows, and 970,000 rows remain after cleaning.
|
| 93 |
+
6. belle open source instruction training data, introduction: [BELLE](https://github.com/LianjiaTech/BELLE), download: [BelleGroup](https://huggingface.co/BelleGroup), only select `Belle_open_source_1M` , `train_2M_CN`, and `train_3.5M_CN` contain some data with short answers, no complex table structure, and translation tasks (no English vocabulary list), totaling 3.7 million rows, and 3.38 million rows remain after cleaning.
|
| 94 |
+
7. Wikipedia entry data, piece together the entries into prompts, the first `N` words of the encyclopedia are the answers, use the encyclopedia data of `202309`, and after cleaning, the remaining 1.19 million entry prompts and answers . Wiki download: [zhwiki](https://dumps.wikimedia.org/zhwiki/), convert the downloaded bz2 file to wiki.txt reference: [WikiExtractor](https://github.com/apertium/WikiExtractor).
|
| 95 |
+
|
| 96 |
+
The total number of datasets is 10.23 million: Text-to-Text pre-training set: 9.3 million, evaluation set: 25,000 (because the decoding is slow, the evaluation set is not set too large). ~~Test set: 900,000~~
|
| 97 |
+
SFT fine-tuning and DPO optimization datasets are shown below.
|
| 98 |
+
|
| 99 |
+
## 2.2 Model
|
| 100 |
+
T5 model (Text-to-Text Transfer Transformer), for details, see the paper: [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683).
|
| 101 |
+
|
| 102 |
+
The model source code comes from huggingface, see: [T5ForConditionalGeneration](https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/modeling_t5.py#L1557).
|
| 103 |
+
|
| 104 |
+
For model configuration, see [model_config.json](https://huggingface.co/charent/ChatLM-mini-Chinese/blob/main/config.json). The official `T5-base`: `encoder layer` and `decoder layer` are both 12 layers. In this project, these two parameters are modified to 10 layers.
|
| 105 |
+
|
| 106 |
+
Model parameters: 0.2B. Word list size: 29298, including only Chinese and a small amount of English.
|
| 107 |
+
|
| 108 |
+
## 2.3 Training process
|
| 109 |
+
hardware:
|
| 110 |
+
```bash
|
| 111 |
+
# Pre-training phase:
|
| 112 |
+
CPU: 28 vCPU Intel(R) Xeon(R) Gold 6330 CPU @ 2.00GHz
|
| 113 |
+
Memory: 60 GB
|
| 114 |
+
GPU: RTX A5000 (24GB) * 2
|
| 115 |
+
|
| 116 |
+
# sft and dpo stages:
|
| 117 |
+
CPU: Intel(R) i5-13600k @ 5.1GHz
|
| 118 |
+
Memory: 32 GB
|
| 119 |
+
GPU: NVIDIA GeForce RTX 4060 Ti 16GB * 1
|
| 120 |
+
```
|
| 121 |
+
|
| 122 |
+
1. **tokenizer training**: The existing `tokenizer` training library has OOM problems when encountering large corpus. Therefore, the full corpus is merged and constructed according to word frequency according to a method similar to `BPE`, and the operation takes half a day.
|
| 123 |
+
|
| 124 |
+
2. **Text-to-Text pre-training**: The learning rate is a dynamic learning rate from `1e-4` to `5e-3`, and the pre-training time is 8 days. Training loss:
|
| 125 |
+

|
| 126 |
+
|
| 127 |
+
3. **prompt supervised fine-tuning (SFT)**: Use the `belle` instruction training dataset (both instruction and answer lengths are below 512), with a dynamic learning rate from `1e-7` to `5e-5` , the fine-tuning time is 2 days. Fine-tuning loss:
|
| 128 |
+

|
| 129 |
+
|
| 130 |
+
4. **dpo direct preference optimization(RLHF)**: dataset [alpaca-gpt4-data-zh](https://huggingface.co/datasets/c-s-ale/alpaca-gpt4-data-zh) as `chosen` text , in step `2`, the SFT model performs batch `generate` on the prompts in the dataset, and obtains the `rejected` text, which takes 1 day, dpo full preference optimization, learning rate `le-5`, half precision `fp16`, total `2` `epoch`, taking 3h. dpo loss:
|
| 131 |
+

|
| 132 |
+
|
| 133 |
+
## 2.4 chat show
|
| 134 |
+
### 2.4.1 stream chat
|
| 135 |
+
By default, `TextIteratorStreamer` of `huggingface transformers` is used to implement streaming dialogue, and only `greedy search` is supported. If you need `beam sample` and other generation methods, please change the `stream_chat` parameter of `cli_demo.py` to `False` .
|
| 136 |
+

|
| 137 |
+
|
| 138 |
+
### 2.4.2 Dialogue show
|
| 139 |
+

|
| 140 |
+
|
| 141 |
+
There are problems: the pre-training dataset only has more than 9 million, and the model parameters are only 0.2B. It cannot cover all aspects, and there will be situations where the answer is wrong and the generator is nonsense.
|
| 142 |
+
|
| 143 |
+
# 3. 📑Instructions for using
|
| 144 |
+
## 3.1 Quick start:
|
| 145 |
+
```python
|
| 146 |
+
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
|
| 147 |
+
import torch
|
| 148 |
+
|
| 149 |
+
model_id = 'charent/ChatLM-mini-Chinese'
|
| 150 |
+
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 151 |
+
|
| 152 |
+
# 如果无法连接huggingface,打开以下两行代码的注释,将从modelscope下载模型文件,模型文件保存到'./model_save'目录
|
| 153 |
+
# from modelscope import snapshot_download
|
| 154 |
+
# model_id = snapshot_download(model_id, cache_dir='./model_save')
|
| 155 |
+
|
| 156 |
+
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
| 157 |
+
model = AutoModelForSeq2SeqLM.from_pretrained(model_id, trust_remote_code=True).to(device)
|
| 158 |
+
|
| 159 |
+
txt = '如何评价Apple这家公司?'
|
| 160 |
+
|
| 161 |
+
encode_ids = tokenizer([txt])
|
| 162 |
+
input_ids, attention_mask = torch.LongTensor(encode_ids['input_ids']), torch.LongTensor(encode_ids['attention_mask'])
|
| 163 |
+
|
| 164 |
+
outs = model.my_generate(
|
| 165 |
+
input_ids=input_ids.to(device),
|
| 166 |
+
attention_mask=attention_mask.to(device),
|
| 167 |
+
max_seq_len=256,
|
| 168 |
+
search_type='beam',
|
| 169 |
+
)
|
| 170 |
+
|
| 171 |
+
outs_txt = tokenizer.batch_decode(outs.cpu().numpy(), skip_special_tokens=True, clean_up_tokenization_spaces=True)
|
| 172 |
+
print(outs_txt[0])
|
| 173 |
+
```
|
| 174 |
+
```txt
|
| 175 |
+
Apple是一家专注于设计和用户体验的公司,其产品在设计上注重简约、流畅和功能性,而在用户体验方面则注重用户的反馈和使用体验。作为一家领先的科技公司,苹果公司一直致力于为用户提供最优质的产品和服务,不断推陈出新,不断创新和改进,以满足不断变化的市场需求。
|
| 176 |
+
在iPhone、iPad和Mac等产品上,苹果公司一直保持着创新的态度,不断推出新的功能和设计,为用户提供更好的使用体验。在iPad上推出的iPad Pro和iPod touch等产品,也一直保持着优秀的用户体验。
|
| 177 |
+
此外,苹果公司还致力于开发和销售软件和服务,例如iTunes、iCloud和App Store等,这些产品在市场上也获得了广泛的认可和好评。
|
| 178 |
+
总的来说,苹果公司在设计、用户体验和产品创新方面都做得非常出色,为用户带来了许多便利和惊喜。
|
| 179 |
+
|
| 180 |
+
```
|
| 181 |
+
|
| 182 |
+
## 3.2 from clone code repository start
|
| 183 |
+
> [!CAUTION]
|
| 184 |
+
> The model of this project is the `TextToText` model. In the `prompt`, `response` and other fields of the pre-training stage, SFT stage, and RLFH stage, please be sure to add the `[EOS]` end-of-sequence mark.
|
| 185 |
+
|
| 186 |
+
### 3.2.1 Clone repository
|
| 187 |
+
```bash
|
| 188 |
+
git clone --depth 1 https://github.com/charent/ChatLM-mini-Chinese.git
|
| 189 |
+
|
| 190 |
+
cd ChatLM-mini-Chinese
|
| 191 |
+
```
|
| 192 |
+
### 3.2.2 Install dependencies
|
| 193 |
+
It is recommended to use `python 3.10` for this project. Older python versions may not be compatible with the third-party libraries it depends on.
|
| 194 |
+
|
| 195 |
+
pip installation:
|
| 196 |
+
```bash
|
| 197 |
+
pip install -r ./requirements.txt
|
| 198 |
+
```
|
| 199 |
+
|
| 200 |
+
If pip installed the CPU version of pytorch, you can install the CUDA version of pytorch with the following command:
|
| 201 |
+
```bash
|
| 202 |
+
# pip install torch + cu118
|
| 203 |
+
pip3 install torch --index-url https://download.pytorch.org/whl/cu118
|
| 204 |
+
```
|
| 205 |
+
|
| 206 |
+
conda installation:
|
| 207 |
+
```bash
|
| 208 |
+
conda install --yes --file ./requirements.txt
|
| 209 |
+
```
|
| 210 |
+
|
| 211 |
+
### 3.2.3 Download the pre-trained model and model configuration file
|
| 212 |
+
|
| 213 |
+
Download model weights and configuration files from `Hugging Face Hub` with `git` command, you need to install [Git LFS](https://docs.github.com/zh/repositories/working-with-files/managing-large-files/installing-git-large -file-storage), then run:
|
| 214 |
+
|
| 215 |
+
```bash
|
| 216 |
+
# Use the git command to download the huggingface model. Install [Git LFS] first, otherwise the downloaded model file will not be available.
|
| 217 |
+
git clone --depth 1 https://huggingface.co/charent/ChatLM-mini-Chinese
|
| 218 |
+
|
| 219 |
+
# If unable to connect huggingface, please download from modelscope
|
| 220 |
+
git clone --depth 1 https://www.modelscope.cn/charent/ChatLM-mini-Chinese.git
|
| 221 |
+
|
| 222 |
+
mv ChatLM-mini-Chinese model_save
|
| 223 |
+
```
|
| 224 |
+
|
| 225 |
+
You can also manually download it directly from the `Hugging Face Hub` warehouse [ChatLM-mini-Chinese](https://huggingface.co/charent/ChatLM-mini-Chinese) and move the downloaded file to the `model_save` directory. .
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
## 3.3 Tokenizer training
|
| 229 |
+
|
| 230 |
+
1. Prepare txt corpus
|
| 231 |
+
|
| 232 |
+
The corpus requirements should be as complete as possible. It is recommended to add multiple corpora, such as encyclopedias, codes, papers, blogs, conversations, etc.
|
| 233 |
+
|
| 234 |
+
This project is mainly based on wiki Chinese encyclopedia. How to obtain Chinese wiki corpus: Chinese Wiki download address: [zhwiki](https://dumps.wikimedia.org/zhwiki/), download the `zhwiki-[archive date]-pages-articles-multistream.xml.bz2` file, About 2.7GB, convert the downloaded bz2 file to wiki.txt reference: [WikiExtractor](https://github.com/apertium/WikiExtractor), then use python's `OpenCC` library to convert to Simplified Chinese, and finally get the Just put `wiki.simple.txt` in the `data` directory of the project root directory. Please merge multiple corpora into one `txt` file yourself.
|
| 235 |
+
|
| 236 |
+
Since training tokenizer consumes a lot of memory, if your corpus is very large (the merged `txt` file exceeds 2G), it is recommended to sample the corpus according to categories and proportions to reduce training time and memory consumption. Training a 1.7GB `txt` file requires about 48GB of memory (estimated, I only have 32GB, triggering swap frequently, computer stuck for a long time T_T), 13600k CPU takes about 1 hour.
|
| 237 |
+
|
| 238 |
+
2. train tokenizer
|
| 239 |
+
|
| 240 |
+
The difference between `char level` and `byte level` is as follows (Please search for information on your own for specific differences in use.). The tokenizer of `char level` is trained by default. If `byte level` is required, just set `token_type='byte'` in `train_tokenizer.py`.
|
| 241 |
+
|
| 242 |
+
```python
|
| 243 |
+
# original text
|
| 244 |
+
txt = '这是一段中英混输的句子, (chinese and English, here are words.)'
|
| 245 |
+
|
| 246 |
+
tokens = charlevel_tokenizer.tokenize(txt)
|
| 247 |
+
print(tokens)
|
| 248 |
+
# char level tokens output
|
| 249 |
+
# ['▁这是', '一段', '中英', '混', '输', '的', '句子', '▁,', '▁(', '▁ch', 'inese', '▁and', '▁Eng', 'lish', '▁,', '▁h', 'ere', '▁', 'are', '▁w', 'ord', 's', '▁.', '▁)']
|
| 250 |
+
|
| 251 |
+
tokens = bytelevel_tokenizer.tokenize(txt)
|
| 252 |
+
print(tokens)
|
| 253 |
+
# byte level tokens output
|
| 254 |
+
# ['Ġè¿Ļæĺ¯', 'ä¸Ģ段', 'ä¸Ńèĭ±', 'æ··', 'è¾ĵ', 'çļĦ', 'åı¥åŃIJ', 'Ġ,', 'Ġ(', 'Ġch', 'inese', 'Ġand', 'ĠEng', 'lish', 'Ġ,', 'Ġh', 'ere', 'Ġare', 'Ġw', 'ord', 's', 'Ġ.', 'Ġ)']
|
| 255 |
+
```
|
| 256 |
+
|
| 257 |
+
Start training:
|
| 258 |
+
|
| 259 |
+
```python
|
| 260 |
+
# Make sure your training corpus `txt` file is in the data directory
|
| 261 |
+
python train_tokenizer.py
|
| 262 |
+
```
|
| 263 |
+
|
| 264 |
+
## 3.4 Text-to-Text pre-training
|
| 265 |
+
1. Pre-training dataset example
|
| 266 |
+
```json
|
| 267 |
+
{
|
| 268 |
+
"prompt": "对于花园街,你有什么了解或看法吗?",
|
| 269 |
+
"response": "花园街(是香港油尖旺区的一条富有特色的街道,位于九龙旺角东部,北至界限街,南至登打士街,与通菜街及洗衣街等街道平行。现时这条街道是香港著名的购物区之一。位于亚皆老街以南的一段花园街,也就是\"波鞋街\"整条街约150米长,有50多间售卖运动鞋和运动用品的店舖。旺角道至太子道西一段则为排档区,售卖成衣、蔬菜和水果等。花园街一共分成三段。明清时代,花园街是芒角村栽种花卉的地方。此外,根据历史专家郑宝鸿的考证:花园街曾是1910年代东方殷琴拿烟厂的花园。纵火案。自2005年起,花园街一带最少发生5宗纵火案,当中4宗涉及排档起火。2010年。2010年12月6日,花园街222号一个卖鞋的排档于凌晨5时许首先起火,浓烟涌往旁边住宅大厦,消防接报4"
|
| 270 |
+
}
|
| 271 |
+
```
|
| 272 |
+
|
| 273 |
+
2. jupyter-lab or jupyter notebook:
|
| 274 |
+
|
| 275 |
+
See the file `train.ipynb`. It is recommended to use jupyter-lab to avoid considering the situation where the terminal process is killed after disconnecting from the server.
|
| 276 |
+
|
| 277 |
+
3. Console:
|
| 278 |
+
|
| 279 |
+
Console training needs to consider that the process will be killed after the connection is disconnected. It is recommended to use the process daemon tool `Supervisor` or `screen` to establish a connection session.
|
| 280 |
+
|
| 281 |
+
First, configure `accelerate`, execute the following command, and select according to the prompts. Refer to `accelerate.yaml`, *Note: DeepSpeed installation in Windows is more troublesome*.
|
| 282 |
+
```bash
|
| 283 |
+
accelerate config
|
| 284 |
+
```
|
| 285 |
+
|
| 286 |
+
Start training. If you want to use the configuration provided by the project, please add the parameter `--config_file ./accelerate.yaml` after the following command `accelerate launch`. *This configuration is based on the single-machine 2xGPU configuration.*
|
| 287 |
+
|
| 288 |
+
*There are two scripts for pre-training. The trainer implemented in this project corresponds to `train.py`, and the trainer implemented by huggingface corresponds to `pre_train.py`. You can use either one and the effect will be the same. The training information display of the trainer implemented in this project is more beautiful, and it is easier to modify the training details (such as loss function, log records, etc.). All support checkpoint to continue training. The trainer implemented in this project supports continuing training after a breakpoint at any position. Press ` ctrl+c` will save the breakpoint information when exiting the script.*
|
| 289 |
+
|
| 290 |
+
Single machine and single card:
|
| 291 |
+
```bash
|
| 292 |
+
# The trainer implemented in this project
|
| 293 |
+
accelerate launch ./train.py train
|
| 294 |
+
|
| 295 |
+
# Or use huggingface trainer
|
| 296 |
+
accelerate launch --multi_gpu --num_processes 2 pre_train.py
|
| 297 |
+
```
|
| 298 |
+
|
| 299 |
+
Single machine with multiple GPUs:
|
| 300 |
+
'2' is the number of gpus, please modify it according to your actual situation.
|
| 301 |
+
```bash
|
| 302 |
+
# The trainer implemented in this project
|
| 303 |
+
accelerate launch --multi_gpu --num_processes 2 ./train.py train
|
| 304 |
+
|
| 305 |
+
# Or use huggingface trainer
|
| 306 |
+
accelerate launch --multi_gpu --num_processes 2 pre_train.py
|
| 307 |
+
```
|
| 308 |
+
|
| 309 |
+
Continue training from the breakpoint:
|
| 310 |
+
```bash
|
| 311 |
+
# The trainer implemented in this project
|
| 312 |
+
accelerate launch --multi_gpu --num_processes 2 ./train.py train --is_keep_training=True
|
| 313 |
+
|
| 314 |
+
# Or use huggingface trainer
|
| 315 |
+
# You need to add `resume_from_checkpoint=True` to the `train` function in `pre_train.py`
|
| 316 |
+
python pre_train.py
|
| 317 |
+
```
|
| 318 |
+
|
| 319 |
+
## 3.5 Supervised Fine-tuning, SFT
|
| 320 |
+
|
| 321 |
+
The SFT dataset all comes from the contribution of [BELLE](https://github.com/LianjiaTech/BELLE). Thank you. The SFT datasets are: [generated_chat_0.4M](https://huggingface.co/datasets/BelleGroup/generated_chat_0.4M), [train_0.5M_CN](https://huggingface.co/datasets/BelleGroup/train_0.5M_CN ) and [train_2M_CN](https://huggingface.co/datasets/BelleGroup/train_2M_CN), about 1.37 million rows remain after cleaning.
|
| 322 |
+
Example of fine-tuning dataset with sft command:
|
| 323 |
+
|
| 324 |
+
```json
|
| 325 |
+
{
|
| 326 |
+
"prompt": "解释什么是欧洲启示录",
|
| 327 |
+
"response": "欧洲启示录(The Book of Revelation)是新约圣经的最后一卷书,也被称为《启示录》、《默示录》或《约翰默示录》。这本书从宗教的角度描述了世界末日的来临,以及上帝对世界的审判和拯救。 书中的主题包括来临的基督的荣耀,上帝对人性的惩罚和拯救,以及魔鬼和邪恶力量的存在。欧洲启示录是一个充满象征和暗示的文本,对于解读和理解有许多不同的方法和观点。"
|
| 328 |
+
}
|
| 329 |
+
```
|
| 330 |
+
Make your own dataset by referring to the sample `parquet` file in the `data` directory. The dataset format is: the `parquet` file is divided into two columns, one column of `prompt` text, representing the prompt, and one column of `response` text, representing the expected model. output.
|
| 331 |
+
For fine-tuning details, see the `train` method under `model/trainer.py`. When `is_finetune` is set to `True`, fine-tuning will be performed. Fine-tuning will freeze the embedding layer and encoder layer by default, and only train the decoder layer. If you need to freeze other parameters, please adjust the code yourself.
|
| 332 |
+
|
| 333 |
+
Run SFT fine-tuning:
|
| 334 |
+
```bash
|
| 335 |
+
# For the trainer implemented in this project, just add the parameter `--is_finetune=True`. The parameter `--is_keep_training=True` can continue training from any breakpoint.
|
| 336 |
+
accelerate launch --multi_gpu --num_processes 2 ./train.py --is_finetune=True
|
| 337 |
+
|
| 338 |
+
# Or use huggingface trainer
|
| 339 |
+
python sft_train.py
|
| 340 |
+
```
|
| 341 |
+
|
| 342 |
+
## 3.6 RLHF (Reinforcement Learning Human Feedback Optimization Method)
|
| 343 |
+
|
| 344 |
+
Here are two common preferred methods: PPO and DPO. Please search papers and blogs for specific implementations.
|
| 345 |
+
|
| 346 |
+
1. PPO method (approximate preference optimization, Proximal Policy Optimization)
|
| 347 |
+
Step 1: Use the fine-tuning dataset to do supervised fine-tuning (SFT, Supervised Finetuning).
|
| 348 |
+
Step 2: Use the preference dataset (a prompt contains at least 2 responses, one wanted response and one unwanted response. Multiple responses can be sorted by score, with the most wanted one having the highest score) to train the reward model (RM, Reward Model). You can use the `peft` library to quickly build the Lora reward model.
|
| 349 |
+
Step 3: Use RM to perform supervised PPO training on the SFT model so that the model meets preferences.
|
| 350 |
+
|
| 351 |
+
2. Use DPO (Direct Preference Optimization) fine-tuning (**This project uses the DPO fine-tuning method, which saves GPU memory**)
|
| 352 |
+
On the basis of obtaining the SFT model, there is no need to train the reward model, and fine-tuning can be started by obtaining the positive answer (chosen) and the negative answer (rejected). The fine-tuned `chosen` text comes from the original dataset [alpaca-gpt4-data-zh](https://huggingface.co/datasets/c-s-ale/alpaca-gpt4-data-zh), and the rejected text `rejected` comes from SFT Model output after fine-tuning 1 epoch, two other datasets: [huozi_rlhf_data_json](https://huggingface.co/datasets/Skepsun/huozi_rlhf_data_json) and [rlhf-reward-single-round-trans_chinese](https:// huggingface.co/datasets/beyond/rlhf-reward-single-round-trans_chinese), a total of 80,000 dpo data after the merger.
|
| 353 |
+
|
| 354 |
+
For the dpo dataset processing process, see `utils/dpo_data_process.py`.
|
| 355 |
+
|
| 356 |
+
DPO preference optimization dataset example:
|
| 357 |
+
```json
|
| 358 |
+
{
|
| 359 |
+
"prompt": "为给定的产品创建一个创意标语。,输入:可重复使用的水瓶。",
|
| 360 |
+
"chosen": "\"保护地球,从拥有可重复使用的水瓶开始!\"",
|
| 361 |
+
"rejected": "\"让你的水瓶成为你的生活伴侣,使用可重复使用的水瓶,让你的水瓶成为你的伙伴\""
|
| 362 |
+
}
|
| 363 |
+
```
|
| 364 |
+
Run preference optimization:
|
| 365 |
+
```bash
|
| 366 |
+
pythondpo_train.py
|
| 367 |
+
```
|
| 368 |
+
|
| 369 |
+
## 3.7 Infering
|
| 370 |
+
Make sure there are the following files in the `model_save` directory, These files can be found in the `Hugging Face Hub` repository [ChatLM-Chinese-0.2B](https://huggingface.co/charent/ChatLM-mini-Chinese)::
|
| 371 |
+
```bash
|
| 372 |
+
ChatLM-mini-Chinese
|
| 373 |
+
├─model_save
|
| 374 |
+
| ├─config.json
|
| 375 |
+
| ├─configuration_chat_model.py
|
| 376 |
+
| ���─generation_config.json
|
| 377 |
+
| ├─model.safetensors
|
| 378 |
+
| ├─modeling_chat_model.py
|
| 379 |
+
| ├─special_tokens_map.json
|
| 380 |
+
| ├─tokenizer.json
|
| 381 |
+
| └─tokenizer_config.json
|
| 382 |
+
```
|
| 383 |
+
|
| 384 |
+
1. Console run:
|
| 385 |
+
```bash
|
| 386 |
+
python cli_demo.py
|
| 387 |
+
```
|
| 388 |
+
|
| 389 |
+
2. API call
|
| 390 |
+
```bash
|
| 391 |
+
python api_demo.py
|
| 392 |
+
```
|
| 393 |
+
|
| 394 |
+
API call example:
|
| 395 |
+
API调用示例:
|
| 396 |
+
```bash
|
| 397 |
+
curl --location '127.0.0.1:8812/api/chat' \
|
| 398 |
+
--header 'Content-Type: application/json' \
|
| 399 |
+
--header 'Authorization: Bearer Bearer' \
|
| 400 |
+
--data '{
|
| 401 |
+
"input_txt": "感冒了要怎么办"
|
| 402 |
+
}'
|
| 403 |
+
```
|
| 404 |
+

|
| 405 |
+
|
| 406 |
+
## 3.8 Fine-tuning of downstream tasks
|
| 407 |
+
|
| 408 |
+
Here we take the triplet information in the text as an example to do downstream fine-tuning. Traditional deep learning extraction methods for this task can be found in the repository [pytorch_IE_model](https://github.com/charent/pytorch_IE_model). Extract all the triples in a piece of text, such as the sentence `"Sketching Essays" is a book published by Metallurgical Industry in 2006, the author is Zhang Lailiang`, extract the triples `(Sketching Essays, author, Zhang Lailiang)` and `( Sketching essays, publishing house, metallurgical industry)`.
|
| 409 |
+
|
| 410 |
+
The original dataset is: [Baidu Triplet Extraction dataset](https://aistudio.baidu.com/datasetdetail/11384). Example of the processed fine-tuned dataset format:
|
| 411 |
+
```json
|
| 412 |
+
{
|
| 413 |
+
"prompt": "请抽取出给定句子中的所有三元组。给定句子:《家乡的月亮》是宋雪莱演唱的一首歌曲,所属专辑是《久违的哥们》",
|
| 414 |
+
"response": "[(家乡的月亮,歌手,宋雪莱),(家乡的月亮,所属专辑,久违的哥们)]"
|
| 415 |
+
}
|
| 416 |
+
```
|
| 417 |
+
|
| 418 |
+
You can directly use the `sft_train.py` script for fine-tuning. The script [finetune_IE_task.ipynb](./finetune_examples/info_extract/finetune_IE_task.ipynb) contains the detailed decoding process. The training dataset is about `17000`, the learning rate is `5e-5`, and the training epoch is `5`. The dialogue capabilities of other tasks have not disappeared after fine-tuning.
|
| 419 |
+
|
| 420 |
+

|
| 421 |
+
|
| 422 |
+
Fine-tuning effects:
|
| 423 |
+
The public `dev` dataset of `Baidu triple extraction dataset` is used as a test set to compare with the traditional method [pytorch_IE_model](https://github.com/charent/pytorch_IE_model).
|
| 424 |
+
|
| 425 |
+
| Model | F1 score | Precision | Recall |
|
| 426 |
+
| :--- | :----: | :---: | :---: |
|
| 427 |
+
| ChatLM-Chinese-0.2B fine-tuning | 0.74 | 0.75 | 0.73 |
|
| 428 |
+
| ChatLM-Chinese-0.2B without pre-training | 0.51 | 0.53 | 0.49 |
|
| 429 |
+
| Traditional deep learning method | 0.80 | 0.79 | 80.1 |
|
| 430 |
+
|
| 431 |
+
Note: `ChatLM-Chinese-0.2B without pre-training` means directly initializing random parameters, starting training, learning rate `1e-4`, and other parameters are consistent with fine-tuning.
|
| 432 |
+
|
| 433 |
+
## 3.9 C-Eval score
|
| 434 |
+
The model itself is not trained with a large dataset and it is no fine-tuning for the instructions for answering multiple-choice questions, and the C-Eval score is basically at the baseline level. If necessary, it can be used as a reference. The C-Eval review code can be found at: 'eval/c_eavl.ipynb'
|
| 435 |
+
|
| 436 |
+
| category | correct | question_count| accuracy |
|
| 437 |
+
| :--- | :----: | :---: | :---: |
|
| 438 |
+
| Humanities | 63 | 257 | 24.51% |
|
| 439 |
+
| Other | 89 | 384 | 23.18% |
|
| 440 |
+
| STEM | 89 | 430 | 20.70% |
|
| 441 |
+
| Social Science | 72 | 275 | 26.18% |
|
| 442 |
+
|
| 443 |
+
# 4. 🎓Citation
|
| 444 |
+
If you think this project is helpful to you, please site it.
|
| 445 |
+
```conf
|
| 446 |
+
@misc{Charent2023,
|
| 447 |
+
author={Charent Chen},
|
| 448 |
+
title={A small chinese chat language model with 0.2B parameters base on T5},
|
| 449 |
+
year={2023},
|
| 450 |
+
publisher = {GitHub},
|
| 451 |
+
journal = {GitHub repository},
|
| 452 |
+
howpublished = {\url{https://github.com/charent/ChatLM-mini-Chinese}},
|
| 453 |
+
}
|
| 454 |
+
```
|
| 455 |
+
|
| 456 |
+
# 5. 🤔Other matters
|
| 457 |
+
This project does not bear any risks and responsibilities arising from data security and public opinion risks caused by open source models and codes, or any model being misled, abused, disseminated, or improperly exploited.
|
README.md
CHANGED
|
@@ -1,12 +1,474 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
|
| 3 |
+
# 中文对话0.2B小模型 ChatLM-Chinese-0.2B
|
| 4 |
+
|
| 5 |
+
中文 | [English](./README.en.md)
|
| 6 |
+
|
| 7 |
+
</div>
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
# 一、👋介绍
|
| 11 |
+
现在的大语言模型的参数往往较大,消费级电脑单纯做推理都比较慢,更别说想自己从头开始训练一个模型了。本项目的目标是从0开始训练一个生成式语言模型,包括数据清洗、tokenizer训练、模型预训练、SFT指令微调、RLHF优化等。
|
| 12 |
+
|
| 13 |
+
ChatLM-mini-Chinese为中文对话小模型,模型参数只有0.2B(算共享权重约210M),可以在最低4GB显存的机器进行预训练(`batch_size=1`,`fp16`或者` bf16`),`float16`加载、推理最少只需要512MB显存。
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
- 公开所有预训练、SFT指令微调、DPO偏好优化数据集来源。
|
| 17 |
+
- 使用`Huggingface`NLP框架,包括`transformers`、`accelerate`、`trl`、`peft`等。
|
| 18 |
+
- 自实现`trainer`,支持单机单卡、单机多卡进行预训练、SFT微调。训练过程中支持在任意位置停止,及在任意位置继续训练。
|
| 19 |
+
- 预训练:整合为端到端的`Text-to-Text`预训练,非`mask`掩码预测预训练。
|
| 20 |
+
- 开源所有数据清洗(如规范化、基于mini_hash的文档去重等)、数据集构造、数据集加载优化等流程;
|
| 21 |
+
- tokenizer多进程词频统计,支持`sentencepiece`、`huggingface tokenizers`的tokenizer训练;
|
| 22 |
+
- 预训练支持任意位置断点,可从断点处继续训练;
|
| 23 |
+
- 大数据集(GB级别)流式加载、支持缓冲区数据打乱,不利用内存、硬盘作为缓存,有效减少内存、磁盘占用。配置`batch_size=1, max_len=320`下,最低支持在16GB内存+4GB显存的机器上进行预训练;
|
| 24 |
+
- 训练日志记录。
|
| 25 |
+
- SFT微调:开源SFT数据集及数据处理过程。
|
| 26 |
+
- 自实现`trainer`支持prompt指令微调, 支持任意断点继续训练;
|
| 27 |
+
- 支持`Huggingface trainer`的`sequence to sequence`微调;
|
| 28 |
+
- 支持传统的低学习率,只训练decoder层的微调。
|
| 29 |
+
- RLHF偏好优化:使用DPO进行全量偏好优化。
|
| 30 |
+
- 支持使用`peft lora`进行偏好优化;
|
| 31 |
+
- 支持模型合并,可将`Lora adapter`合并到原始模型中。
|
| 32 |
+
- 支持下游任务微调:[finetune_examples](./finetune_examples/info_extract/)给出**三元组信息抽取任务**的微调示例,微调后的模型对话能力仍在。
|
| 33 |
+
|
| 34 |
+
如果需要做基于小模型的检索增强生成(RAG),可以参考我的另一个项目[Phi2-mini-Chinese](https://github.com/charent/Phi2-mini-Chinese),代码见[rag_with_langchain.ipynb](https://github.com/charent/Phi2-mini-Chinese/blob/main/rag_with_langchain.ipynb)
|
| 35 |
+
|
| 36 |
+
🟢**最近更新**
|
| 37 |
+
|
| 38 |
+
<details open>
|
| 39 |
+
<summary> <b>2024-01-30</b> </summary>
|
| 40 |
+
- 模型文件更新到魔搭modelscope,可以通过`snapshot_download`快速下载。<br/>
|
| 41 |
+
</details>
|
| 42 |
+
|
| 43 |
+
<details close>
|
| 44 |
+
<summary> <b>2024-01-07</b> </summary>
|
| 45 |
+
- 添加数据清洗过程中基于mini hash实现的文档去重(在本项目中其实是数据集的样本去重),防止模型遇到多次重复数据后,在推理时吐出训练数据。<br/>
|
| 46 |
+
- 添加`DropDatasetDuplicate`类实现对大数据集的文档去重。<br/>
|
| 47 |
+
</details>
|
| 48 |
+
|
| 49 |
+
<details close>
|
| 50 |
+
<summary> <b>2023-12-29</b> </summary>
|
| 51 |
+
- 更新模型代码(权重不变),可以直接使用`AutoModelForSeq2SeqLM.from_pretrained(...)`加载模型使用。<br/>
|
| 52 |
+
- 更新readme文档。<br/>
|
| 53 |
+
</details>
|
| 54 |
+
|
| 55 |
+
<details close>
|
| 56 |
+
<summary> <b>2023-12-18</b> </summary>
|
| 57 |
+
- 补充利用`ChatLM-mini-0.2B`模型微调下游三元组信息抽取任务代码及抽取效果展示 。<br/>
|
| 58 |
+
- 更新readme文档。<br/>
|
| 59 |
+
</details>
|
| 60 |
+
|
| 61 |
+
<details close>
|
| 62 |
+
<summary> <b>2023-12-14</b> </summary>
|
| 63 |
+
- 更新SFT、DPO后的模型权重文件。 <br/>
|
| 64 |
+
- 更新预训练、SFT及DPO脚本。 <br/>
|
| 65 |
+
- 更新`tokenizer`为`PreTrainedTokenizerFast`。 <br/>
|
| 66 |
+
- 重构`dataset`代码,支持动态最大长度,每个批次的最大长度由该批次的最长文本决定,节省显存。 <br/>
|
| 67 |
+
- 补充`tokenizer`训练细节。 <br/>
|
| 68 |
+
</details>
|
| 69 |
+
|
| 70 |
+
<details close>
|
| 71 |
+
<summary> <b>2023-12-04</b> </summary>
|
| 72 |
+
- 更新`generate`参数及模型效果展示。<br/>
|
| 73 |
+
- 更新readme文档。<br/>
|
| 74 |
+
</details>
|
| 75 |
+
|
| 76 |
+
<details close>
|
| 77 |
+
<summary> <b>2023-11-28</b> </summary>
|
| 78 |
+
- 更新dpo训练代码及模型权重。<br/>
|
| 79 |
+
</details>
|
| 80 |
+
|
| 81 |
+
<details close>
|
| 82 |
+
<summary> <b>2023-10-19</b> </summary>
|
| 83 |
+
- 项目开源, 开放模型权重供下载。 <br/>
|
| 84 |
+
</details>
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
# 二、🛠️ChatLM-0.2B-Chinese模型训练过程
|
| 88 |
+
|
| 89 |
+
## 2.1 预训练数据集
|
| 90 |
+
所有数据集均来自互联网公开的**单轮对话**数据集,经过数据清洗、格式化后保存为parquet文件。数据处理过程见`utils/raw_data_process.py`。主要数据集包括:
|
| 91 |
+
|
| 92 |
+
1. 社区问答json版webtext2019zh-大规模高质量数据集,见:[nlp_chinese_corpus](https://github.com/brightmart/nlp_chinese_corpus)。共410万,清洗后剩余260万。
|
| 93 |
+
2. baike_qa2019百科类问答,见:<https://aistudio.baidu.com/datasetdetail/107726>,共140万,清醒后剩余130万。
|
| 94 |
+
3. 中国医药领域问答数据集,见:[Chinese-medical-dialogue-data](https://github.com/Toyhom/Chinese-medical-dialogue-data),共79万,清洗后剩余79万。
|
| 95 |
+
4. ~~金融行业问答数据,见:<https://zhuanlan.zhihu.com/p/609821974>,共77万,清洗后剩余52万。~~**数据质量太差,未采用。**
|
| 96 |
+
5. 知乎问答数据,见:[Zhihu-KOL](https://huggingface.co/datasets/wangrui6/Zhihu-KOL),共100万行,清洗后剩余97万行。
|
| 97 |
+
6. belle开源的指令训练数据,介绍:[BELLE](https://github.com/LianjiaTech/BELLE),下载:[BelleGroup](https://huggingface.co/BelleGroup),仅选取`Belle_open_source_1M`、`train_2M_CN`、及`train_3.5M_CN`中部分回答较短、不含复杂表格结构、翻译任务(没做英文词表)的数据,共370万行,清洗后剩余338万行。
|
| 98 |
+
7. 维基百科(Wikipedia)词条数据,将词条拼凑为提示语,百科的前`N`个词为回答,使用`202309`的百科数据,清洗后剩余119万的词条提示语和回答。Wiki下载:[zhwiki](https://dumps.wikimedia.org/zhwiki/),将下载的bz2文件转换为wiki.txt参考:[WikiExtractor](https://github.com/apertium/WikiExtractor)。
|
| 99 |
+
|
| 100 |
+
数据集总数量1023万:Text-to-Text预训练集:930万,评估集:2.5万(因为解码较慢,所以没有把评估集设置太大)。~~测试集:90万。~~
|
| 101 |
+
SFT微调和DPO优化数据集见下文。
|
| 102 |
+
|
| 103 |
+
## 2.2 模型
|
| 104 |
+
T5模型(Text-to-Text Transfer Transformer),详情见论文: [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683)。
|
| 105 |
+
|
| 106 |
+
模型源码来自huggingface,见:[T5ForConditionalGeneration](https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/modeling_t5.py#L1557)。
|
| 107 |
+
|
| 108 |
+
模型配置见[model_config.json](https://huggingface.co/charent/ChatLM-mini-Chinese/blob/main/config.json),官方的`T5-base`:`encoder layer`和`decoder layer `均为为12层,本项目这两个参数修改为10层。
|
| 109 |
+
|
| 110 |
+
模型参数:0.2B。词表大小:29298,仅包含中文和少量英文。
|
| 111 |
+
|
| 112 |
+
## 2.3 训练过程
|
| 113 |
+
硬件:
|
| 114 |
+
```bash
|
| 115 |
+
# 预训练阶段:
|
| 116 |
+
CPU: 28 vCPU Intel(R) Xeon(R) Gold 6330 CPU @ 2.00GHz
|
| 117 |
+
内存:60 GB
|
| 118 |
+
显卡:RTX A5000(24GB) * 2
|
| 119 |
+
|
| 120 |
+
# sft及dpo阶段:
|
| 121 |
+
CPU: Intel(R) i5-13600k @ 5.1GHz
|
| 122 |
+
内存:32 GB
|
| 123 |
+
显卡:NVIDIA GeForce RTX 4060 Ti 16GB * 1
|
| 124 |
+
```
|
| 125 |
+
1. **tokenizer 训练**: 现有`tokenizer`训练库遇到大语料时存在OOM问题,故全量语料按照类似`BPE`的方法根据词频合并、构造词库,运行耗时半天。
|
| 126 |
+
|
| 127 |
+
2. **Text-to-Text 预训练**:学习率为`1e-4`到`5e-3`的动态学习率,预训练时间为8天。训练损失:
|
| 128 |
+
|
| 129 |
+

|
| 130 |
+
|
| 131 |
+
3. **prompt监督微调(SFT)**:使用`belle`指令训练数据集(指令和回答长度都在512以下),学习率为`1e-7`到`5e-5`的动态学习率,微调时间2天。微调损失:
|
| 132 |
+
|
| 133 |
+

|
| 134 |
+
|
| 135 |
+
4. **dpo直接偏好优化(RLHF)**:数据集[alpaca-gpt4-data-zh](https://huggingface.co/datasets/c-s-ale/alpaca-gpt4-data-zh)作为`chosen`文本,步骤`2`中SFT模型对数据集中的prompt做批量`generate`,得到`rejected`文本,耗时1天,dpo全量偏好优化,学习率`le-5`,半精度`fp16`,共`2`个`epoch`,耗时3h。dpo损失:
|
| 136 |
+
|
| 137 |
+

|
| 138 |
+
|
| 139 |
+
## 2.4 对话效果展示
|
| 140 |
+
### 2.4.1 stream chat
|
| 141 |
+
默认使用`huggingface transformers`的 `TextIteratorStreamer`实现流式对话,只支持`greedy search`,如果需要`beam sample`等其他生成方式,请将`cli_demo.py`的`stream_chat`参数修改为`False`。
|
| 142 |
+

|
| 143 |
+
|
| 144 |
+
### 2.4.2 对话展示
|
| 145 |
+

|
| 146 |
+
|
| 147 |
+
存在问题:预训练数据集只有900多万,模型参数也仅0.2B,不能涵盖所有方面,会有答非所问、废话生成器的情况。
|
| 148 |
+
|
| 149 |
+
# 三、📑使用说明
|
| 150 |
+
|
| 151 |
+
## 3.1 快速开始:
|
| 152 |
+
如果无法连接huggingface,请使用`modelscope.snapshot_download`从modelscope下载模型文件。
|
| 153 |
+
```python
|
| 154 |
+
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
|
| 155 |
+
import torch
|
| 156 |
+
|
| 157 |
+
model_id = 'charent/ChatLM-mini-Chinese'
|
| 158 |
+
|
| 159 |
+
# 如果无法连接huggingface,打开以下两行代码的注释,将从modelscope下载模型文件,模型文件保存到'./model_save'目录
|
| 160 |
+
# from modelscope import snapshot_download
|
| 161 |
+
# model_id = snapshot_download(model_id, cache_dir='./model_save')
|
| 162 |
+
|
| 163 |
+
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 164 |
+
|
| 165 |
+
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
| 166 |
+
model = AutoModelForSeq2SeqLM.from_pretrained(model_id, trust_remote_code=True).to(device)
|
| 167 |
+
|
| 168 |
+
txt = '如何评价Apple这家公司?'
|
| 169 |
+
|
| 170 |
+
encode_ids = tokenizer([txt])
|
| 171 |
+
input_ids, attention_mask = torch.LongTensor(encode_ids['input_ids']), torch.LongTensor(encode_ids['attention_mask'])
|
| 172 |
+
|
| 173 |
+
outs = model.my_generate(
|
| 174 |
+
input_ids=input_ids.to(device),
|
| 175 |
+
attention_mask=attention_mask.to(device),
|
| 176 |
+
max_seq_len=256,
|
| 177 |
+
search_type='beam',
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
outs_txt = tokenizer.batch_decode(outs.cpu().numpy(), skip_special_tokens=True, clean_up_tokenization_spaces=True)
|
| 181 |
+
print(outs_txt[0])
|
| 182 |
+
```
|
| 183 |
+
```txt
|
| 184 |
+
Apple是一家专注于设计和用户体验的公司,其产品在设计上注重简约、流畅和功能性,而在用户体验方面则注重用户的反馈和使用体验。作为一家领先的科技公司,苹果公司一直致力于为用户提供最优质的产品和服务,不断推陈出新,不断创新和改进,以满足不断变化的市场需求。
|
| 185 |
+
在iPhone、iPad和Mac等产品上,苹果公司一直保持着创新的态度,不断推出新的功能和设计,为用户提供更好的使用体验。在iPad上推出的iPad Pro和iPod touch等产品,也一直保持着优秀的用户体验。
|
| 186 |
+
此外,苹果公司还致力于开发和销售软件和服务,例如iTunes、iCloud和App Store等,这些产品在市场上也获得了广泛的认可和好评。
|
| 187 |
+
总的来说,苹果公司在设计、用户体验和产品创新方面都做得非常出色,为用户带来了许多便利和惊喜。
|
| 188 |
+
|
| 189 |
+
```
|
| 190 |
+
|
| 191 |
+
## 3.2 从克隆仓库代码开始
|
| 192 |
+
|
| 193 |
+
> [!CAUTION]
|
| 194 |
+
> 本项目模型为`TextToText`模型,在预训练、SFT、RLFH阶段的`prompt`、`response`等字段,请务必加上`[EOS]`序列结束标记。
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
### 3.2.1 克隆项目:
|
| 198 |
+
```bash
|
| 199 |
+
git clone --depth 1 https://github.com/charent/ChatLM-mini-Chinese.git
|
| 200 |
+
|
| 201 |
+
cd ChatLM-mini-Chinese
|
| 202 |
+
```
|
| 203 |
+
### 3.2.2 安装依赖
|
| 204 |
+
|
| 205 |
+
本项目推荐使用`python 3.10`,过老的python版本可能不兼容所依赖的第三方库。
|
| 206 |
+
|
| 207 |
+
pip安装:
|
| 208 |
+
```bash
|
| 209 |
+
pip install -r ./requirements.txt
|
| 210 |
+
```
|
| 211 |
+
|
| 212 |
+
如果pip安装了CPU版本的pytorch,可以通过下面的命令安装CUDA版本的pytorch:
|
| 213 |
+
```bash
|
| 214 |
+
# pip 安装torch + cu118
|
| 215 |
+
pip3 install torch --index-url https://download.pytorch.org/whl/cu118
|
| 216 |
+
```
|
| 217 |
+
|
| 218 |
+
conda安装:
|
| 219 |
+
```bash
|
| 220 |
+
conda install --yes --file ./requirements.txt
|
| 221 |
+
```
|
| 222 |
+
|
| 223 |
+
### 3.2.3 下载预训练模型及模型配置文件
|
| 224 |
+
|
| 225 |
+
用`git`命令从`Hugging Face Hub`下载模型权重及配置文件,需要先安装[Git LFS](https://docs.github.com/zh/repositories/working-with-files/managing-large-files/installing-git-large-file-storage),然后运行:
|
| 226 |
+
|
| 227 |
+
```bash
|
| 228 |
+
# 使用git命令下载huggingface模型,先安装[Git LFS],否则下载的模型文件不可用
|
| 229 |
+
git clone --depth 1 https://huggingface.co/charent/ChatLM-mini-Chinese
|
| 230 |
+
|
| 231 |
+
# 如果无法连接huggingface,请从modelscope下载
|
| 232 |
+
git clone --depth 1 https://www.modelscope.cn/charent/ChatLM-mini-Chinese.git
|
| 233 |
+
|
| 234 |
+
mv ChatLM-mini-Chinese model_save
|
| 235 |
+
```
|
| 236 |
+
|
| 237 |
+
也可以直接从`Hugging Face Hub`仓库[ChatLM-Chinese-0.2B](https://huggingface.co/charent/ChatLM-mini-Chinese)手工下载,将下载的文件移动到`model_save`目录下即可。
|
| 238 |
+
|
| 239 |
+
## 3.3 Tokenizer训练
|
| 240 |
+
|
| 241 |
+
1. 准备txt语料
|
| 242 |
+
|
| 243 |
+
语料要求尽可能全,建议添加多个语料,如百科、代码、论文、博客、对话等。
|
| 244 |
+
|
| 245 |
+
本项目以wiki中文百科为主。获取中文wiki语料方法:中文Wiki下载地址:[zhwiki](https://dumps.wikimedia.org/zhwiki/),下载`zhwiki-[存档日期]-pages-articles-multistream.xml.bz2`文件,大概2.7GB, 将下载的bz2文件转换为wiki.txt参考:[WikiExtractor](https://github.com/apertium/WikiExtractor),再利用python的`OpenCC`库转换为简体中文,最后将得到的`wiki.simple.txt`放到项目根目录的`data`目录下即可。多个语料请自行合并为一个`txt`文件。
|
| 246 |
+
|
| 247 |
+
由于训练tokenizer非常耗内存,如果你的语料非常大(合并后的`txt`文件超过2G),建议对语料按照类别、比例进行采样,以减少训练时间和内存消耗。训练1.7GB的`txt`文件需要消耗48GB左右的内存(预估的,我只有32GB,频繁触发swap,电脑卡了好久T_T),13600k cpu耗时1小时左右。
|
| 248 |
+
|
| 249 |
+
2. 训练tokenizer
|
| 250 |
+
|
| 251 |
+
`char level`和`byte level`的区别如下(具体使用上的区别请自行检索资料)。默认训练`char level`的tokenizer,如果需要`byte level`,在`train_tokenizer.py`中设置`token_type='byte'`即可。
|
| 252 |
+
|
| 253 |
+
```python
|
| 254 |
+
# 原始文本
|
| 255 |
+
txt = '这是一段中英混输的句子, (chinese and English, here are words.)'
|
| 256 |
+
|
| 257 |
+
tokens = charlevel_tokenizer.tokenize(txt)
|
| 258 |
+
print(tokens)
|
| 259 |
+
# char level tokens输出
|
| 260 |
+
# ['▁这是', '一段', '中英', '混', '输', '的', '句子', '▁,', '▁(', '▁ch', 'inese', '▁and', '▁Eng', 'lish', '▁,', '▁h', 'ere', '▁', 'are', '▁w', 'ord', 's', '▁.', '▁)']
|
| 261 |
+
|
| 262 |
+
tokens = bytelevel_tokenizer.tokenize(txt)
|
| 263 |
+
print(tokens)
|
| 264 |
+
# byte level tokens输出
|
| 265 |
+
# ['Ġè¿Ļæĺ¯', 'ä¸Ģ段', 'ä¸Ńèĭ±', 'æ··', 'è¾ĵ', 'çļĦ', 'åı¥åŃIJ', 'Ġ,', 'Ġ(', 'Ġch', 'inese', 'Ġand', 'ĠEng', 'lish', 'Ġ,', 'Ġh', 'ere', 'Ġare', 'Ġw', 'ord', 's', 'Ġ.', 'Ġ)']
|
| 266 |
+
```
|
| 267 |
+
开始训练:
|
| 268 |
+
```python
|
| 269 |
+
# 确保你的训练语料`txt`文件已经data目录下
|
| 270 |
+
python train_tokenizer.py
|
| 271 |
+
```
|
| 272 |
+
|
| 273 |
+
## 3.4 Text-to-Text 预���练
|
| 274 |
+
|
| 275 |
+
1. 预训练数据集示例
|
| 276 |
+
```json
|
| 277 |
+
{
|
| 278 |
+
"prompt": "对于花园街,你有什么了解或看法吗?",
|
| 279 |
+
"response": "花园街(是香港油尖旺区的一条富有特色的街道,位于九龙旺角东部,北至界限街,南至登打士街,与通菜街及洗衣街等街道平行。现时这条街道是香港著名的购物区之一。位于亚皆老街以南的一段花园街,也就是\"波鞋街\"整条街约150米长,有50多间售卖运动鞋和运动用品的店舖。旺角道至太子道西一段则为排档区,售卖成衣、蔬菜和水果等。花园街一共分成三段。明清时代,花园街是芒角村栽种花卉的地方。此外,根据历史专家郑宝鸿的考证:花园街曾是1910年代东方殷琴拿烟厂的花园。纵火案。自2005年起,花园街一带最少发生5宗纵火案,当中4宗涉及排档起火。2010年。2010年12月6日,花园街222号一个卖鞋的排档于凌晨5时许首先起火,浓烟涌往旁边住宅大厦,消防接报4"
|
| 280 |
+
}
|
| 281 |
+
```
|
| 282 |
+
|
| 283 |
+
2. jupyter-lab 或者 jupyter notebook:
|
| 284 |
+
|
| 285 |
+
见文件`train.ipynb`,推荐使用jupyter-lab,避免考虑与服务器断开后终端进程被杀的情况。
|
| 286 |
+
|
| 287 |
+
3. 控制台:
|
| 288 |
+
|
| 289 |
+
控制台训练需要考虑连接断开后进程被杀的,推荐使用进程守护工具`Supervisor`或者`screen`建立连接会话。
|
| 290 |
+
|
| 291 |
+
首先要配置`accelerate`,执行以下命令, 根据提示选择即可,参考`accelerate.yaml`,*注意:DeepSpeed在Windows安装比较麻烦*。
|
| 292 |
+
```bash
|
| 293 |
+
accelerate config
|
| 294 |
+
```
|
| 295 |
+
|
| 296 |
+
开始训练,如果要使用工程提供的配置请在下面的命令`accelerate launch`后加上参数`--config_file ./accelerate.yaml`,*该配置按照单机2xGPU配置。*
|
| 297 |
+
|
| 298 |
+
*预训练有两个脚本,本项目实现的trainer对应`train.py`,huggingface实现的trainer对应`pre_train.py`,用哪个都可以,效果一致。本项目实现的trainer训练信息展示更美观、更容易修改训练细节(如损失函数,日志记录等),均支持断点继续训练,本项目实现的trainer支持在任意位置断点后继续训练,按`ctrl+c`退出脚本时会保存断点信息。*
|
| 299 |
+
|
| 300 |
+
单机单卡:
|
| 301 |
+
```bash
|
| 302 |
+
# 本项目实现的trainer
|
| 303 |
+
accelerate launch ./train.py train
|
| 304 |
+
|
| 305 |
+
# 或者使用 huggingface trainer
|
| 306 |
+
python pre_train.py
|
| 307 |
+
```
|
| 308 |
+
|
| 309 |
+
单机多卡:
|
| 310 |
+
`2`为显卡数量,请根据自己的实际情况修改。
|
| 311 |
+
```bash
|
| 312 |
+
# 本项目实现的trainer
|
| 313 |
+
accelerate launch --multi_gpu --num_processes 2 ./train.py train
|
| 314 |
+
|
| 315 |
+
# 或者使用 huggingface trainer
|
| 316 |
+
accelerate launch --multi_gpu --num_processes 2 pre_train.py
|
| 317 |
+
```
|
| 318 |
+
|
| 319 |
+
从断点处继续训练:
|
| 320 |
+
```bash
|
| 321 |
+
# 本项目实现的trainer
|
| 322 |
+
accelerate launch --multi_gpu --num_processes 2 ./train.py train --is_keep_training=True
|
| 323 |
+
|
| 324 |
+
# 或者使用 huggingface trainer
|
| 325 |
+
# 需要在`pre_train.py`中的`train`函数添加`resume_from_checkpoint=True`
|
| 326 |
+
accelerate launch --multi_gpu --num_processes 2 pre_train.py
|
| 327 |
+
```
|
| 328 |
+
|
| 329 |
+
## 3.5 SFT微调
|
| 330 |
+
SFT数据集全部来自[BELLE](https://github.com/LianjiaTech/BELLE)大佬的贡献,感谢。SFT数据集分别为:[generated_chat_0.4M](https://huggingface.co/datasets/BelleGroup/generated_chat_0.4M)、[train_0.5M_CN](https://huggingface.co/datasets/BelleGroup/train_0.5M_CN)和[train_2M_CN](https://huggingface.co/datasets/BelleGroup/train_2M_CN),清洗后剩余约137万行。
|
| 331 |
+
sft指令微调数据集示例:
|
| 332 |
+
```json
|
| 333 |
+
{
|
| 334 |
+
"prompt": "解释什么是欧洲启示录",
|
| 335 |
+
"response": "欧洲启示录(The Book of Revelation)是新约圣经的最后一卷书,也被称为《启示录》、《默示录》或《约翰默示录》。这本书从宗教的角度描述了世界末日的来临,以及上帝对世界的审判和拯救。 书中的主题包括来临的基督的荣耀,上帝对人性的惩罚和拯救,以及魔鬼和邪恶力量的存在。欧洲启示录是一个充满象征和暗示的文本,对于解读和理解有许多不同的方法和观点。"
|
| 336 |
+
}
|
| 337 |
+
```
|
| 338 |
+
|
| 339 |
+
参考`data`目录下的示例`parquet`文件制作自己的数据集,数据集格式:`parquet`文件分两列,一列`prompt`文本,表示提示语,一列`response`文本,表示期待的模型输出。
|
| 340 |
+
微调细节见`model/trainer.py`下的`train`方法, `is_finetune`设置为`True`时,将进行微调,微调默认会冻结embedding层和encoder层,只训练decoder层。如需要冻结其他参数,请自行调整代码。
|
| 341 |
+
|
| 342 |
+
运行SFT微调:
|
| 343 |
+
``` bash
|
| 344 |
+
# 本项目实现的trainer, 添加参数`--is_finetune=True`即可, 参数`--is_keep_training=True`可从任意断点处继续训练
|
| 345 |
+
accelerate launch --multi_gpu --num_processes 2 ./train.py --is_finetune=True
|
| 346 |
+
|
| 347 |
+
# 或者使用 huggingface trainer, 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 sft_train.py
|
| 348 |
+
python sft_train.py
|
| 349 |
+
```
|
| 350 |
+
|
| 351 |
+
## 3.6 RLHF(强化学习人类反馈优化方法)
|
| 352 |
+
|
| 353 |
+
偏好方法这里介绍常见的两种:PPO和DPO,具体实现请自行搜索论文���博客。
|
| 354 |
+
|
| 355 |
+
1. PPO方法(近似偏好优化,Proximal Policy Optimization)
|
| 356 |
+
步骤1:使用微调数据集做有监督微调(SFT, Supervised Finetuning)。
|
| 357 |
+
步骤2:使用偏好数据集(一个prompt至少包含2个回复,一个想要的回复,一个不想要的回复。多个回复可以按照分数排序,最想要的分数最高)训练奖励模型(RM, Reward Model)。可使用`peft`库快速搭建Lora奖励模型。
|
| 358 |
+
步骤3:利用RM对SFT模型进行有监督PPO训练,使得模型满足偏好。
|
| 359 |
+
|
| 360 |
+
2. 使用DPO(直接偏好优化,Direct Preference Optimization)微调(**本项目采用DPO微调方法,比较节省显存**)
|
| 361 |
+
在获得SFT模型的基础上,无需训练奖励模型,取得正向回答(chosen)和负向回答(rejected)即可开始微调。微调的`chosen`文本来自原数据集[alpaca-gpt4-data-zh](https://huggingface.co/datasets/c-s-ale/alpaca-gpt4-data-zh),拒绝文本`rejected`来自SFT微调1个epoch后的模型输出,另外两个数据集:[huozi_rlhf_data_json](https://huggingface.co/datasets/Skepsun/huozi_rlhf_data_json)和[rlhf-reward-single-round-trans_chinese](https://huggingface.co/datasets/beyond/rlhf-reward-single-round-trans_chinese),合并后共8万条dpo数据。
|
| 362 |
+
|
| 363 |
+
dpo数据集处理过程见`utils/dpo_data_process.py`。
|
| 364 |
+
|
| 365 |
+
DPO偏好优化数据集示例:
|
| 366 |
+
```json
|
| 367 |
+
{
|
| 368 |
+
"prompt": "为给定的产品创建一个创意标语。,输入:可重复使用的水瓶。",
|
| 369 |
+
"chosen": "\"保护地球,从拥有可重复使用的水瓶开始!\"",
|
| 370 |
+
"rejected": "\"让你的水瓶成为你的生活伴侣,使用可重复使用的水瓶,让你的水瓶成为你的伙伴\""
|
| 371 |
+
}
|
| 372 |
+
```
|
| 373 |
+
|
| 374 |
+
运行偏好优化:
|
| 375 |
+
``` bash
|
| 376 |
+
# 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 dpo_train.py
|
| 377 |
+
python dpo_train.py
|
| 378 |
+
```
|
| 379 |
+
|
| 380 |
+
## 3.7 推理
|
| 381 |
+
确保`model_save`目录下有以下文件,这些文件都可以在`Hugging Face Hub`仓库[ChatLM-Chinese-0.2B](https://huggingface.co/charent/ChatLM-mini-Chinese)中找到:
|
| 382 |
+
```bash
|
| 383 |
+
ChatLM-mini-Chinese
|
| 384 |
+
├─model_save
|
| 385 |
+
| ├─config.json
|
| 386 |
+
| ├─configuration_chat_model.py
|
| 387 |
+
| ├─generation_config.json
|
| 388 |
+
| ├─model.safetensors
|
| 389 |
+
| ├─modeling_chat_model.py
|
| 390 |
+
| ├─special_tokens_map.json
|
| 391 |
+
| ├─tokenizer.json
|
| 392 |
+
| └─tokenizer_config.json
|
| 393 |
+
```
|
| 394 |
+
|
| 395 |
+
1. 控制台运行:
|
| 396 |
+
```bash
|
| 397 |
+
python cli_demo.py
|
| 398 |
+
```
|
| 399 |
+
|
| 400 |
+
2. API调用
|
| 401 |
+
```bash
|
| 402 |
+
python api_demo.py
|
| 403 |
+
```
|
| 404 |
+
|
| 405 |
+
API调用示例:
|
| 406 |
+
```bash
|
| 407 |
+
curl --location '127.0.0.1:8812/api/chat' \
|
| 408 |
+
--header 'Content-Type: application/json' \
|
| 409 |
+
--header 'Authorization: Bearer Bearer' \
|
| 410 |
+
--data '{
|
| 411 |
+
"input_txt": "感冒了要怎么办"
|
| 412 |
+
}'
|
| 413 |
+
```
|
| 414 |
+

|
| 415 |
+
|
| 416 |
+
## 3.8 下游任务微调
|
| 417 |
+
|
| 418 |
+
这里以文本中三元组信息为例,做下游微调。该任务的传统深度学习抽取方法见仓库[pytorch_IE_model](https://github.com/charent/pytorch_IE_model)。抽取出一段文本中所有的三元组,如句子`《写生随笔》是冶金工业2006年出版的图书,作者是张来亮`,抽取出三元组`(写生随笔,作者,张来亮)`和`(写生随笔,出版社,冶金工业)`。
|
| 419 |
+
|
| 420 |
+
原始数据集为:[百度三元组抽取数据集](https://aistudio.baidu.com/datasetdetail/11384)。加工得到的微调数据集格式示例:
|
| 421 |
+
```json
|
| 422 |
+
{
|
| 423 |
+
"prompt": "请抽取出给定句子中的所有三元组。给定句子:《家乡的月亮》是宋雪莱演唱的一首歌曲,所属专辑是《久违的哥们》",
|
| 424 |
+
"response": "[(家乡的月亮,歌手,宋雪莱),(家乡的月亮,所属专辑,久违的哥们)]"
|
| 425 |
+
}
|
| 426 |
+
```
|
| 427 |
+
|
| 428 |
+
可以直接使用`sft_train.py`脚本进行微调,脚本[finetune_IE_task.ipynb](./finetune_examples/info_extract/finetune_IE_task.ipynb)里面包含详细的解码过程。训练数据集约`17000`条,学习率`5e-5`,训练epoch`5`。微调后其他任务的对话能力也没有消失。
|
| 429 |
+
|
| 430 |
+

|
| 431 |
+
|
| 432 |
+
微调效果:
|
| 433 |
+
将`百度三元组抽取数据集`公开的`dev`数据集作为测试集,对比传统方法[pytorch_IE_model](https://github.com/charent/pytorch_IE_model)。
|
| 434 |
+
|
| 435 |
+
| 模型 | F1分数 | 精确率P | 召回率R |
|
| 436 |
+
| :--- | :----: | :---: | :---: |
|
| 437 |
+
| ChatLM-Chinese-0.2B微调 | 0.74 | 0.75 | 0.73 |
|
| 438 |
+
| ChatLM-Chinese-0.2B无预训练| 0.51 | 0.53 | 0.49 |
|
| 439 |
+
| 传统深度学习方法 | 0.80 | 0.79 | 80.1 |
|
| 440 |
+
|
| 441 |
+
备注:`ChatLM-Chinese-0.2B无预训练`指直接初始化随机参数,开始训练,学习率`1e-4`,其他参数和微调一致。
|
| 442 |
+
|
| 443 |
+
## 3.9 C-Eval分数
|
| 444 |
+
模型本身没有使用较大的数据集训练,也没有针对回答选择题的指令做微调,C-Eval分数基本上是baseline水平,有需要的可以当个参考。C-Eval评测代码见:`eval/c_eavl.ipynb`
|
| 445 |
+
|
| 446 |
+
| category | correct | question_count| accuracy |
|
| 447 |
+
| :--- | :----: | :---: | :---: |
|
| 448 |
+
| Humanities | 63 | 257 | 24.51% |
|
| 449 |
+
| Other | 89 | 384 | 23.18% |
|
| 450 |
+
| STEM | 89 | 430 | 20.70% |
|
| 451 |
+
| Social Science | 72 | 275 | 26.18% |
|
| 452 |
+
|
| 453 |
+
# 四、🎓引用
|
| 454 |
+
如果你觉得本项目对你有所帮助,欢迎引用。
|
| 455 |
+
```conf
|
| 456 |
+
@misc{Charent2023,
|
| 457 |
+
author={Charent Chen},
|
| 458 |
+
title={A small chinese chat language model with 0.2B parameters base on T5},
|
| 459 |
+
year={2023},
|
| 460 |
+
publisher = {GitHub},
|
| 461 |
+
journal = {GitHub repository},
|
| 462 |
+
howpublished = {\url{https://github.com/charent/ChatLM-mini-Chinese}},
|
| 463 |
+
}
|
| 464 |
+
```
|
| 465 |
+
|
| 466 |
+
# 五、🤔其他事项
|
| 467 |
+
本项目不承担开源模型和代码导致的数据安全、舆情风险或发生任何模型被误导、滥用、传播、不当利用而产生的风险和责任。
|
| 468 |
+
|
| 469 |
+
<!-- # 提示
|
| 470 |
+
```bash
|
| 471 |
+
# 导出项目依赖的包:
|
| 472 |
+
pipreqs --encoding "utf-8" --force
|
| 473 |
+
``` -->
|
| 474 |
+
|
accelerate.yaml
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
compute_environment: LOCAL_MACHINE
|
| 2 |
+
debug: false
|
| 3 |
+
deepspeed_config:
|
| 4 |
+
gradient_accumulation_steps: 8
|
| 5 |
+
gradient_clipping: 1.0
|
| 6 |
+
offload_optimizer_device: cpu
|
| 7 |
+
offload_param_device: cpu
|
| 8 |
+
zero3_init_flag: false
|
| 9 |
+
zero3_save_16bit_model: false
|
| 10 |
+
zero_stage: 2
|
| 11 |
+
distributed_type: DEEPSPEED
|
| 12 |
+
downcast_bf16: 'no'
|
| 13 |
+
dynamo_config:
|
| 14 |
+
dynamo_backend: EAGER
|
| 15 |
+
machine_rank: 0
|
| 16 |
+
main_training_function: main
|
| 17 |
+
mixed_precision: bf16
|
| 18 |
+
num_machines: 1
|
| 19 |
+
num_processes: 2
|
| 20 |
+
rdzv_backend: static
|
| 21 |
+
same_network: true
|
| 22 |
+
tpu_env: []
|
| 23 |
+
tpu_use_cluster: false
|
| 24 |
+
tpu_use_sudo: false
|
| 25 |
+
use_cpu: false
|
api_demo.py
ADDED
|
@@ -0,0 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import dataclass
|
| 2 |
+
from typing import Union
|
| 3 |
+
|
| 4 |
+
import uvicorn
|
| 5 |
+
from fastapi import FastAPI, Depends, status
|
| 6 |
+
from fastapi.security import OAuth2PasswordBearer
|
| 7 |
+
from fastapi.exceptions import HTTPException
|
| 8 |
+
from pydantic import BaseModel
|
| 9 |
+
|
| 10 |
+
from model.infer import ChatBot
|
| 11 |
+
from config import InferConfig
|
| 12 |
+
|
| 13 |
+
CONFIG = InferConfig()
|
| 14 |
+
chat_bot = ChatBot(infer_config=CONFIG)
|
| 15 |
+
|
| 16 |
+
#==============================================================
|
| 17 |
+
# api 配置
|
| 18 |
+
|
| 19 |
+
# api根目录
|
| 20 |
+
ROOT = '/api'
|
| 21 |
+
|
| 22 |
+
# api key
|
| 23 |
+
USE_AUTH = False if len(CONFIG.api_key) == 0 else True
|
| 24 |
+
SECRET_KEY = CONFIG.api_key
|
| 25 |
+
|
| 26 |
+
app = FastAPI()
|
| 27 |
+
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="/token")
|
| 28 |
+
|
| 29 |
+
#==============================================================
|
| 30 |
+
|
| 31 |
+
"""
|
| 32 |
+
post请求地址:http://127.0.0.1:8812/api/chat
|
| 33 |
+
需要添加Authorization头,bodyjson格式,示例:
|
| 34 |
+
{
|
| 35 |
+
"input_txt": "感冒了要怎么办"
|
| 36 |
+
}
|
| 37 |
+
"""
|
| 38 |
+
|
| 39 |
+
async def api_key_auth(token: str = Depends(oauth2_scheme)) -> Union[None, bool]:
|
| 40 |
+
"""
|
| 41 |
+
验证post请求的key是否和服务器的key一致
|
| 42 |
+
需要在请求头加上 Authorization: Bearer SECRET_KEY
|
| 43 |
+
"""
|
| 44 |
+
if not USE_AUTH:
|
| 45 |
+
return None # return None if not auth
|
| 46 |
+
|
| 47 |
+
if token == SECRET_KEY:
|
| 48 |
+
return None # return None if auth success
|
| 49 |
+
|
| 50 |
+
# 验证出错
|
| 51 |
+
raise HTTPException(
|
| 52 |
+
status_code=status.HTTP_401_UNAUTHORIZED,
|
| 53 |
+
detail="api认证未通过,请检查认证方式和token!",
|
| 54 |
+
headers={"WWW-Authenticate": "Bearer"},
|
| 55 |
+
)
|
| 56 |
+
|
| 57 |
+
# pos请求json
|
| 58 |
+
class ChatInput(BaseModel):
|
| 59 |
+
input_txt: str
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
@app.post(ROOT + "/chat")
|
| 63 |
+
async def chat(post_data: ChatInput, authority: str = Depends(api_key_auth)) -> dict:
|
| 64 |
+
"""
|
| 65 |
+
post 输入: {'input_txt': '输入的文本'}
|
| 66 |
+
response: {'response': 'chatbot文本'}
|
| 67 |
+
"""
|
| 68 |
+
input_txt = post_data.input_txt
|
| 69 |
+
if len(input_txt) == 0:
|
| 70 |
+
raise HTTPException(
|
| 71 |
+
status_code=status.HTTP_406_NOT_ACCEPTABLE,
|
| 72 |
+
detail="input_txt length = 0 is not allow!",
|
| 73 |
+
headers={"WWW-Authenticate": "Bearer"},
|
| 74 |
+
)
|
| 75 |
+
|
| 76 |
+
outs = chat_bot.chat(input_txt)
|
| 77 |
+
|
| 78 |
+
if len(outs) == 0:
|
| 79 |
+
outs = "我是一个参数很少的AI模型🥺,知识库较少,无法直接回答您的问题,换个问题试试吧👋"
|
| 80 |
+
|
| 81 |
+
return {'response': outs}
|
| 82 |
+
|
| 83 |
+
if __name__ == '__main__':
|
| 84 |
+
|
| 85 |
+
# 加上reload参数(reload=True)时,多进程设置无效
|
| 86 |
+
# workers = max(multiprocessing.cpu_count() * CONFIG.getint('uvicorn','process_worker'), 1)
|
| 87 |
+
workers = max(CONFIG.workers, 1)
|
| 88 |
+
print('启动的进程个数:{}'.format(workers))
|
| 89 |
+
|
| 90 |
+
uvicorn.run(
|
| 91 |
+
'api_demo:app',
|
| 92 |
+
host=CONFIG.host,
|
| 93 |
+
port=CONFIG.port,
|
| 94 |
+
reload=CONFIG.reload,
|
| 95 |
+
workers=workers,
|
| 96 |
+
log_level='info'
|
| 97 |
+
)
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
# 服务方式启动:
|
| 101 |
+
# 命令行输入:uvicorn api_demo:app --host 0.0.0.0 --port 8094 --workers 8
|
| 102 |
+
# api_demo:api_demo.py文件
|
| 103 |
+
# app:app = FastAPI() 在main.py内创建的对象。
|
| 104 |
+
# --reload:在代码更改后重新启动服务器。 只有在开发时才使用这个参数,此时多进程设置会无效
|
app.py
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import gradio as gr
|
| 3 |
+
import platform
|
| 4 |
+
import os
|
| 5 |
+
import time
|
| 6 |
+
from threading import Thread
|
| 7 |
+
|
| 8 |
+
from rich.text import Text
|
| 9 |
+
from rich.live import Live
|
| 10 |
+
|
| 11 |
+
from model.infer import ChatBot
|
| 12 |
+
from config import InferConfig
|
| 13 |
+
|
| 14 |
+
infer_config = InferConfig()
|
| 15 |
+
chat_bot = ChatBot(infer_config=infer_config)
|
| 16 |
+
# streamer = chat_bot.chat("你好")
|
| 17 |
+
# print(streamer)
|
| 18 |
+
# streamer = chat_bot.stream_chat("你好")
|
| 19 |
+
# welcome_txt = '欢迎使用ChatBot,输入`exit`退出,输入`cls`清屏。\n'
|
| 20 |
+
# def build_prompt(history: list[list[str]]) -> str:
|
| 21 |
+
# prompt = welcome_txt
|
| 22 |
+
# for query, response in history:
|
| 23 |
+
# prompt += '\n\033[0;33;40m用户:\033[0m{}'.format(query)
|
| 24 |
+
# prompt += '\n\033[0;32;40mChatBot:\033[0m\n{}\n'.format(response)
|
| 25 |
+
# return prompt
|
| 26 |
+
# print(build_prompt(streamer))
|
| 27 |
+
|
| 28 |
+
def greet(name):
|
| 29 |
+
streamer = chat_bot.chat("你好")
|
| 30 |
+
return streamer
|
| 31 |
+
# return "Hello " + name + "!!"
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
iface = gr.Interface(fn=greet, inputs="text", outputs="text")
|
| 36 |
+
|
| 37 |
+
iface.launch()
|
cli_demo.py
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import platform
|
| 2 |
+
import os
|
| 3 |
+
import time
|
| 4 |
+
from threading import Thread
|
| 5 |
+
|
| 6 |
+
from rich.text import Text
|
| 7 |
+
from rich.live import Live
|
| 8 |
+
|
| 9 |
+
from model.infer import ChatBot
|
| 10 |
+
from config import InferConfig
|
| 11 |
+
|
| 12 |
+
infer_config = InferConfig()
|
| 13 |
+
chat_bot = ChatBot(infer_config=infer_config)
|
| 14 |
+
|
| 15 |
+
clear_cmd = 'cls' if platform.system().lower() == 'windows' else 'clear'
|
| 16 |
+
|
| 17 |
+
welcome_txt = '欢迎使用ChatBot,输入`exit`退出,输入`cls`清屏。\n'
|
| 18 |
+
print(welcome_txt)
|
| 19 |
+
|
| 20 |
+
def build_prompt(history: list[list[str]]) -> str:
|
| 21 |
+
prompt = welcome_txt
|
| 22 |
+
for query, response in history:
|
| 23 |
+
prompt += '\n\033[0;33;40m用户:\033[0m{}'.format(query)
|
| 24 |
+
prompt += '\n\033[0;32;40mChatBot:\033[0m\n{}\n'.format(response)
|
| 25 |
+
return prompt
|
| 26 |
+
|
| 27 |
+
STOP_CIRCLE: bool=False
|
| 28 |
+
def circle_print(total_time: int=60) -> None:
|
| 29 |
+
global STOP_CIRCLE
|
| 30 |
+
'''非stream chat打印忙碌状态
|
| 31 |
+
'''
|
| 32 |
+
list_circle = ["\\", "|", "/", "—"]
|
| 33 |
+
for i in range(total_time * 4):
|
| 34 |
+
time.sleep(0.25)
|
| 35 |
+
print("\r{}".format(list_circle[i % 4]), end="", flush=True)
|
| 36 |
+
|
| 37 |
+
if STOP_CIRCLE: break
|
| 38 |
+
|
| 39 |
+
print("\r", end='', flush=True)
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def chat(stream: bool=True) -> None:
|
| 43 |
+
global STOP_CIRCLE
|
| 44 |
+
history = []
|
| 45 |
+
turn_count = 0
|
| 46 |
+
|
| 47 |
+
while True:
|
| 48 |
+
print('\r\033[0;33;40m用户:\033[0m', end='', flush=True)
|
| 49 |
+
input_txt = input()
|
| 50 |
+
|
| 51 |
+
if len(input_txt) == 0:
|
| 52 |
+
print('请输入问题')
|
| 53 |
+
continue
|
| 54 |
+
|
| 55 |
+
# 退出
|
| 56 |
+
if input_txt.lower() == 'exit':
|
| 57 |
+
break
|
| 58 |
+
|
| 59 |
+
# 清屏
|
| 60 |
+
if input_txt.lower() == 'cls':
|
| 61 |
+
history = []
|
| 62 |
+
turn_count = 0
|
| 63 |
+
os.system(clear_cmd)
|
| 64 |
+
print(welcome_txt)
|
| 65 |
+
continue
|
| 66 |
+
|
| 67 |
+
if not stream:
|
| 68 |
+
STOP_CIRCLE = False
|
| 69 |
+
thread = Thread(target=circle_print)
|
| 70 |
+
thread.start()
|
| 71 |
+
|
| 72 |
+
outs = chat_bot.chat(input_txt)
|
| 73 |
+
|
| 74 |
+
STOP_CIRCLE = True
|
| 75 |
+
thread.join()
|
| 76 |
+
|
| 77 |
+
print("\r\033[0;32;40mChatBot:\033[0m\n{}\n\n".format(outs), end='')
|
| 78 |
+
|
| 79 |
+
continue
|
| 80 |
+
|
| 81 |
+
history.append([input_txt, ''])
|
| 82 |
+
stream_txt = []
|
| 83 |
+
streamer = chat_bot.stream_chat(input_txt)
|
| 84 |
+
rich_text = Text()
|
| 85 |
+
|
| 86 |
+
print("\r\033[0;32;40mChatBot:\033[0m\n", end='')
|
| 87 |
+
|
| 88 |
+
with Live(rich_text, refresh_per_second=15) as live:
|
| 89 |
+
for i, word in enumerate(streamer):
|
| 90 |
+
rich_text.append(word)
|
| 91 |
+
stream_txt.append(word)
|
| 92 |
+
|
| 93 |
+
stream_txt = ''.join(stream_txt)
|
| 94 |
+
|
| 95 |
+
if len(stream_txt) == 0:
|
| 96 |
+
stream_txt = "我是一个参数很少的AI模型🥺,知识库较少,无法直接回答您的问题,换个问题试试吧👋"
|
| 97 |
+
|
| 98 |
+
history[turn_count][1] = stream_txt
|
| 99 |
+
|
| 100 |
+
os.system(clear_cmd)
|
| 101 |
+
print(build_prompt(history), flush=True)
|
| 102 |
+
turn_count += 1
|
| 103 |
+
|
| 104 |
+
if __name__ == '__main__':
|
| 105 |
+
chat(stream=True)
|
config.py
ADDED
|
@@ -0,0 +1,139 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import dataclass
|
| 2 |
+
from os.path import dirname, abspath
|
| 3 |
+
|
| 4 |
+
# replace '\' on windows to '/'
|
| 5 |
+
PROJECT_ROOT: str = '/'.join(abspath(dirname(__file__)).split('\\')) if '\\' in abspath(dirname(__file__)) else abspath(dirname(__file__))
|
| 6 |
+
|
| 7 |
+
# ===================================================================================
|
| 8 |
+
# 以下为推断的配置
|
| 9 |
+
@dataclass
|
| 10 |
+
class InferConfig:
|
| 11 |
+
max_seq_len: int = 320 # 回答的最大长度
|
| 12 |
+
mixed_precision: str = "bf16" # 混合精度 ''no','fp16','bf16' or 'fp8'
|
| 13 |
+
|
| 14 |
+
# 全量DPO模型文件, tokenizer文件和model权重放在同一个文件夹
|
| 15 |
+
model_dir: str = PROJECT_ROOT + '/model_save/'
|
| 16 |
+
|
| 17 |
+
# lora PDO 合并后的模型文件
|
| 18 |
+
# model_file: str = PROJECT_ROOT + '/model_save/chat_small_t5.best.dpo.lora_merged.bin'
|
| 19 |
+
|
| 20 |
+
# this confing for api demo:
|
| 21 |
+
api_key: str = ""
|
| 22 |
+
host: str = '127.0.0.1'
|
| 23 |
+
port: int = 8812
|
| 24 |
+
reload: bool = True
|
| 25 |
+
workers: int = 1
|
| 26 |
+
log_level: str = 'info'
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
#===================================================================================
|
| 30 |
+
# 以下为dpo训练配置
|
| 31 |
+
@dataclass
|
| 32 |
+
class DpoConfig:
|
| 33 |
+
max_seq_len: int = 512 + 8 # 8 for eos token
|
| 34 |
+
sft_model_file: str = PROJECT_ROOT + '/model_save/'
|
| 35 |
+
|
| 36 |
+
tokenizer_dir: str = PROJECT_ROOT + '/model_save/' # tokenizer一般和model权重放在同一个文件夹
|
| 37 |
+
|
| 38 |
+
dpo_train_file: str = PROJECT_ROOT + '/data/my_dpo_data.json'
|
| 39 |
+
dpo_eval_file: str = PROJECT_ROOT + '/data/my_dpo_eval.json'
|
| 40 |
+
|
| 41 |
+
adapter_file: str = PROJECT_ROOT + '/data/dpo/adapter_model.safetensors'
|
| 42 |
+
log_dir: str = PROJECT_ROOT + '/logs/'
|
| 43 |
+
|
| 44 |
+
per_device_train_batch_size: int = 4
|
| 45 |
+
num_train_epochs: int = 4
|
| 46 |
+
gradient_accumulation_steps: int = 8
|
| 47 |
+
learning_rate: float = 1e-5
|
| 48 |
+
logging_first_step: bool = True
|
| 49 |
+
logging_steps: int = 20
|
| 50 |
+
save_steps: int = 2000
|
| 51 |
+
output_dir: str = PROJECT_ROOT + '/model_save/dpo'
|
| 52 |
+
warmup_steps: int = 1000
|
| 53 |
+
fp16: bool = True
|
| 54 |
+
seed: int = 23333
|
| 55 |
+
beta: float = 0.1
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
# 以下为sft配置
|
| 60 |
+
@dataclass
|
| 61 |
+
class SFTconfig:
|
| 62 |
+
max_seq_len: int = 384 + 8 # 8 for eos token
|
| 63 |
+
|
| 64 |
+
finetune_from_ckp_file = PROJECT_ROOT + '/model_save/'
|
| 65 |
+
|
| 66 |
+
tokenizer_dir: str = PROJECT_ROOT + '/model_save/' # tokenizer一般和model权重放在同一个文件夹
|
| 67 |
+
sft_train_file: str = PROJECT_ROOT + '/data/sft_train.json'
|
| 68 |
+
|
| 69 |
+
batch_size: int = 12
|
| 70 |
+
num_train_epochs: int = 4
|
| 71 |
+
save_steps: int = 5000
|
| 72 |
+
gradient_accumulation_steps: int = 4
|
| 73 |
+
learning_rate: float = 1e-5
|
| 74 |
+
logging_first_step: bool = True
|
| 75 |
+
logging_steps: int = 100
|
| 76 |
+
output_dir: str = PROJECT_ROOT + '/model_save/sft'
|
| 77 |
+
warmup_steps: int = 100
|
| 78 |
+
fp16: bool = True
|
| 79 |
+
seed: int = 23333
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
# ===================================================================================
|
| 83 |
+
# 以下为训练的配置
|
| 84 |
+
@dataclass
|
| 85 |
+
class TrainConfig:
|
| 86 |
+
epochs: int = 8
|
| 87 |
+
batch_size_per_gpu: int = 16
|
| 88 |
+
|
| 89 |
+
learn_rate: float = 0.0001 # 最大 div_factor * learn_rate
|
| 90 |
+
div_factor: int = 50
|
| 91 |
+
|
| 92 |
+
mixed_precision: str = "bf16" # 混合精度 ''no','fp16','bf16' or 'fp8'
|
| 93 |
+
|
| 94 |
+
# 注意:计算梯度时相当于batch_size * gradient_accumulation_steps,说人话就是梯度累积步数>1时,等于增大n倍的batch_size
|
| 95 |
+
gradient_accumulation_steps: int = 8 # 累积梯度更新步数
|
| 96 |
+
|
| 97 |
+
warmup_steps: int = 1024 # 模型参数预热步数,预热样本数=warmup_steps * batch_size * gradient_accumulation_steps
|
| 98 |
+
|
| 99 |
+
tokenizer_dir: str = PROJECT_ROOT + '/model_save/' # tokenizer一般和model权重放在同一个文件夹
|
| 100 |
+
model_file: str = PROJECT_ROOT + '/model_save/chat_small_t5.{}.bin'
|
| 101 |
+
model_config_file: str = PROJECT_ROOT + '/model_save/model_config.json'
|
| 102 |
+
train_file: str = PROJECT_ROOT + '/data/my_train_dataset.parquet'
|
| 103 |
+
validation_file: str = PROJECT_ROOT + '/data/my_valid_dataset.parquet'
|
| 104 |
+
test_file: str = PROJECT_ROOT + '/data/my_test_dataset.parquet'
|
| 105 |
+
|
| 106 |
+
# 从哪个模型开始微调,仅当traing 函数 is_finetune = True时生效
|
| 107 |
+
# 微调记得冻结某些层或者调低学习率
|
| 108 |
+
finetune_from_ckp_file = PROJECT_ROOT + '/model_save/chat_small_t5.best.bin'
|
| 109 |
+
|
| 110 |
+
# 训练状态保存,中断后可以从此处继续训练
|
| 111 |
+
train_state_dir: str = PROJECT_ROOT + '/model_save/train_latest_state'
|
| 112 |
+
output_dir: str = PROJECT_ROOT + '/model_save/pretrain'
|
| 113 |
+
|
| 114 |
+
logging_steps: int = 50
|
| 115 |
+
save_steps: int = 10000
|
| 116 |
+
|
| 117 |
+
# dataset_cache_dir: str = PROJECT_ROOT + '/data/.cache'
|
| 118 |
+
# trainer_log_file: str = PROJECT_ROOT + '/logs/trainer.log'
|
| 119 |
+
|
| 120 |
+
keep_latest_n_ckp: int = 8 # 训练过程中,最多保留多少个分数最好的模型文件
|
| 121 |
+
|
| 122 |
+
seed: int = 23333
|
| 123 |
+
dataloader_buffer_size: int = 50000
|
| 124 |
+
max_seq_len: int = 256 # 最大句子长度,默认:256
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
#======================================================================================
|
| 128 |
+
# 以下为模型的配置
|
| 129 |
+
@dataclass
|
| 130 |
+
class T5ModelConfig:
|
| 131 |
+
|
| 132 |
+
d_ff: int = 3072 # 全连接层维度
|
| 133 |
+
|
| 134 |
+
d_model: int = 768 # 词向量维度
|
| 135 |
+
num_heads: int = 12 # 注意力头数 d_model // num_heads == d_kv
|
| 136 |
+
d_kv: int = 64 # d_model // num_heads
|
| 137 |
+
|
| 138 |
+
num_decoder_layers: int = 10 # Transformer decoder 隐藏层层数
|
| 139 |
+
num_layers: int = 10 # Transformer encoder 隐藏层层数
|
data/my_test_dataset_2k.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f8a99f671c9bf8dfbddf8a1aaf13decbf7eea440c07a2631e2c634ee6cd5dded
|
| 3 |
+
size 575315
|
data/my_train_dataset_3k.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cbe91a996f659e77d1047453686a6872ff5a5ce5a9f5026028d3edb6def6f4f9
|
| 3 |
+
size 855994
|
data/my_valid_dataset_1k.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dfdd45edb8aeaf49089795cf208f04d9baea0922883e87c4fdd33af350029092
|
| 3 |
+
size 286692
|
dpo_train.py
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
from typing import Dict, Optional
|
| 3 |
+
import time
|
| 4 |
+
import os
|
| 5 |
+
|
| 6 |
+
import pandas as pd
|
| 7 |
+
import torch
|
| 8 |
+
from datasets import Dataset, load_dataset
|
| 9 |
+
from transformers import PreTrainedTokenizerFast, TrainingArguments
|
| 10 |
+
from trl import DPOTrainer
|
| 11 |
+
from tokenizers import Tokenizer
|
| 12 |
+
from peft import LoraConfig, TaskType, PeftModel
|
| 13 |
+
|
| 14 |
+
from config import DpoConfig, T5ModelConfig
|
| 15 |
+
from model.chat_model import TextToTextModel
|
| 16 |
+
from utils.functions import get_T5_config
|
| 17 |
+
|
| 18 |
+
os.environ['TF_ENABLE_ONEDNN_OPTS'] = '0'
|
| 19 |
+
|
| 20 |
+
def get_dataset(split: str, file: str, cache_dir: str = '.cache') -> Dataset:
|
| 21 |
+
"""Load the Anthropic Helpful-Harmless dataset from Hugging Face and convert it to the necessary format.
|
| 22 |
+
|
| 23 |
+
The dataset is converted to a dictionary with the following structure:
|
| 24 |
+
{
|
| 25 |
+
'prompt': List[str],
|
| 26 |
+
'chosen': List[str],
|
| 27 |
+
'rejected': List[str],
|
| 28 |
+
}
|
| 29 |
+
"""
|
| 30 |
+
dataset = load_dataset('json', data_files=file, split=split, cache_dir=cache_dir)
|
| 31 |
+
|
| 32 |
+
def split_prompt_and_responses(sample: dict) -> Dict[str, str]:
|
| 33 |
+
return {
|
| 34 |
+
# add an eos token for signal that end of sentence, using in generate.
|
| 35 |
+
"prompt": f"{sample['prompt']}[EOS]",
|
| 36 |
+
"chosen": f"{sample['chosen']}[EOS]",
|
| 37 |
+
"rejected": f"{sample['rejected']}[EOS]",
|
| 38 |
+
}
|
| 39 |
+
|
| 40 |
+
return dataset.map(split_prompt_and_responses).shuffle(2333)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def train_dpo(config: DpoConfig, peft_config: LoraConfig=None) -> None:
|
| 44 |
+
|
| 45 |
+
# step 1. 加载tokenizer
|
| 46 |
+
tokenizer = PreTrainedTokenizerFast.from_pretrained(config.tokenizer_dir)
|
| 47 |
+
|
| 48 |
+
# step 2. 加载预训练模型
|
| 49 |
+
model_train, model_ref = None, None
|
| 50 |
+
if os.path.isdir(config.sft_model_file):
|
| 51 |
+
# 传入文件夹则 from_pretrained
|
| 52 |
+
model_train = TextToTextModel.from_pretrained(config.sft_model_file)
|
| 53 |
+
model_ref = TextToTextModel.from_pretrained(config.sft_model_file)
|
| 54 |
+
else:
|
| 55 |
+
# load_state_dict
|
| 56 |
+
t5_config = get_T5_config(T5ModelConfig(), vocab_size=len(tokenizer), decoder_start_token_id=tokenizer.pad_token_id, eos_token_id=tokenizer.eos_token_id)
|
| 57 |
+
|
| 58 |
+
model_train = TextToTextModel(t5_config)
|
| 59 |
+
model_train.load_state_dict(torch.load(config.sft_model_file, map_location='cpu')) # set cpu for no exception
|
| 60 |
+
|
| 61 |
+
model_ref = TextToTextModel(t5_config)
|
| 62 |
+
model_ref.load_state_dict(torch.load(config.sft_model_file, map_location='cpu'))
|
| 63 |
+
|
| 64 |
+
# 4. 加载训练数据集
|
| 65 |
+
train_dataset = get_dataset("train", file=config.dpo_train_file)
|
| 66 |
+
|
| 67 |
+
# 5. 加载评估数据集
|
| 68 |
+
# eval_dataset = get_dataset("train", file=config.dpo_eval_file)
|
| 69 |
+
eval_dataset = None
|
| 70 |
+
|
| 71 |
+
# 6. 初始化训练参数
|
| 72 |
+
training_args = TrainingArguments(
|
| 73 |
+
per_device_train_batch_size=config.per_device_train_batch_size,
|
| 74 |
+
num_train_epochs=config.num_train_epochs,
|
| 75 |
+
auto_find_batch_size=True,
|
| 76 |
+
remove_unused_columns=False,
|
| 77 |
+
gradient_accumulation_steps=config.gradient_accumulation_steps,
|
| 78 |
+
learning_rate=config.learning_rate,
|
| 79 |
+
logging_first_step=True,
|
| 80 |
+
logging_steps=config.logging_steps,
|
| 81 |
+
save_steps=config.save_steps,
|
| 82 |
+
output_dir=config.output_dir,
|
| 83 |
+
optim="adafactor",
|
| 84 |
+
report_to="tensorboard",
|
| 85 |
+
log_level='info',
|
| 86 |
+
warmup_steps=config.warmup_steps,
|
| 87 |
+
bf16=False,
|
| 88 |
+
fp16=config.fp16,
|
| 89 |
+
seed=config.seed,
|
| 90 |
+
logging_dir=config.log_dir,
|
| 91 |
+
)
|
| 92 |
+
|
| 93 |
+
# 7. 初始化 DPO trainer
|
| 94 |
+
dpo_trainer = DPOTrainer(
|
| 95 |
+
model_train,
|
| 96 |
+
model_ref,
|
| 97 |
+
peft_config=peft_config,
|
| 98 |
+
args=training_args,
|
| 99 |
+
beta=config.beta,
|
| 100 |
+
train_dataset=train_dataset,
|
| 101 |
+
eval_dataset=eval_dataset,
|
| 102 |
+
tokenizer=tokenizer,
|
| 103 |
+
max_length=config.max_seq_len,
|
| 104 |
+
max_target_length=config.max_seq_len,
|
| 105 |
+
max_prompt_length=config.max_seq_len,
|
| 106 |
+
generate_during_eval=True,
|
| 107 |
+
is_encoder_decoder=True,
|
| 108 |
+
)
|
| 109 |
+
|
| 110 |
+
# 8. 训练
|
| 111 |
+
dpo_trainer.train(
|
| 112 |
+
# resume_from_checkpoint=True
|
| 113 |
+
)
|
| 114 |
+
|
| 115 |
+
# 9. save log
|
| 116 |
+
loss_log = pd.DataFrame(dpo_trainer.state.log_history)
|
| 117 |
+
log_dir = './logs'
|
| 118 |
+
if not os.path.exists(log_dir):
|
| 119 |
+
os.mkdir(log_dir)
|
| 120 |
+
loss_log.to_csv(f"{log_dir}/dpo_train_log_{time.strftime('%Y%m%d-%H%M')}.csv")
|
| 121 |
+
|
| 122 |
+
# 10. 保存模型/lora
|
| 123 |
+
suffixe = '/lora/' if peft_config is not None else '/dpo'
|
| 124 |
+
model_save_dir = '/'.join(config.sft_model_file.split('/')[0: -1]) + suffixe
|
| 125 |
+
|
| 126 |
+
dpo_trainer.save_model(model_save_dir)
|
| 127 |
+
print('save model or lora adapter to: {}'.format(model_save_dir))
|
| 128 |
+
|
| 129 |
+
def merge_lora_weight_into_model(config: DpoConfig, peft_config: LoraConfig) -> None:
|
| 130 |
+
|
| 131 |
+
# step 1. 加载tokenizer
|
| 132 |
+
tokenizer = PreTrainedTokenizerFast.from_pretrained(config.tokenizer_dir)
|
| 133 |
+
|
| 134 |
+
# step 2. 加载预训练模型
|
| 135 |
+
sft_model = None
|
| 136 |
+
if os.path.isdir(config.sft_model_file):
|
| 137 |
+
# 传入文件夹则 from_pretrained
|
| 138 |
+
sft_model = TextToTextModel.from_pretrained(config.sft_model_file)
|
| 139 |
+
else:
|
| 140 |
+
# load_state_dict
|
| 141 |
+
t5_config = get_T5_config(T5ModelConfig(), vocab_size=len(tokenizer), decoder_start_token_id=tokenizer.pad_token_id, eos_token_id=tokenizer.eos_token_id)
|
| 142 |
+
sft_model = TextToTextModel(t5_config)
|
| 143 |
+
sft_model.load_state_dict(torch.load(config.sft_model_file, map_location='cpu')) # set cpu for no exception
|
| 144 |
+
|
| 145 |
+
# 注意这个路径要和上面的model_save_dir一致
|
| 146 |
+
# train_dpo函数代码
|
| 147 |
+
# 9. 保存模型/lora
|
| 148 |
+
# suffixe = '/lora/' if peft_config is not None else '/dpo'
|
| 149 |
+
# model_save_dir = '/'.join(config.sft_model_file.split('/')[0: -1]) + suffixe
|
| 150 |
+
|
| 151 |
+
adapter_save_dir = '/'.join(config.sft_model_file.split('/')[0: -1]) + '/lora'
|
| 152 |
+
|
| 153 |
+
peft_model = PeftModel.from_pretrained(
|
| 154 |
+
model=sft_model,
|
| 155 |
+
model_id=adapter_save_dir,
|
| 156 |
+
config=peft_config,
|
| 157 |
+
adapter_name='adapter',
|
| 158 |
+
)
|
| 159 |
+
|
| 160 |
+
# peft_model = PeftModel(
|
| 161 |
+
# model=sft_model,
|
| 162 |
+
# peft_config=peft_config,
|
| 163 |
+
# adapter_name='adapter',
|
| 164 |
+
# )
|
| 165 |
+
|
| 166 |
+
# 3. load adapter
|
| 167 |
+
|
| 168 |
+
print('load adapter from dir: {}'.format(adapter_save_dir))
|
| 169 |
+
|
| 170 |
+
peft_model.load_adapter(model_id=adapter_save_dir, adapter_name='adapter',)
|
| 171 |
+
|
| 172 |
+
# 4. merge
|
| 173 |
+
peft_model = peft_model.merge_and_unload()
|
| 174 |
+
|
| 175 |
+
# 5. save
|
| 176 |
+
save_merge_file = config.sft_model_file + '.dpo_lora_merged'
|
| 177 |
+
sft_model.save_pretrained(save_merge_file)
|
| 178 |
+
print('save merge model file to: {}'.format(save_merge_file))
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
if __name__ == "__main__":
|
| 182 |
+
|
| 183 |
+
peft_config = LoraConfig(
|
| 184 |
+
task_type=TaskType.SEQ_2_SEQ_LM, # text 2 text lora model
|
| 185 |
+
inference_mode=False,
|
| 186 |
+
r=16,
|
| 187 |
+
lora_alpha=16,
|
| 188 |
+
lora_dropout=0.1,
|
| 189 |
+
bias="all",
|
| 190 |
+
)
|
| 191 |
+
|
| 192 |
+
dpo_config = DpoConfig()
|
| 193 |
+
|
| 194 |
+
# 1. train
|
| 195 |
+
train_dpo(dpo_config, peft_config=None)
|
| 196 |
+
|
| 197 |
+
# 2. merge lora adapter into model
|
| 198 |
+
# merge_lora_weight_into_model(dpo_config, peft_config)
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
|
eval/.gitignore
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ceval-exam
|
| 2 |
+
data
|
| 3 |
+
result
|
| 4 |
+
CMMLU
|
| 5 |
+
result_0_shot
|
eval/c_eavl.ipynb
ADDED
|
@@ -0,0 +1,657 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {},
|
| 6 |
+
"source": [
|
| 7 |
+
"## 下载c-eavl数据集\n",
|
| 8 |
+
"\n",
|
| 9 |
+
"```bash\n",
|
| 10 |
+
"mkdir ceval-data\n",
|
| 11 |
+
"cd ceval-data\n",
|
| 12 |
+
"wget https://huggingface.co/datasets/ceval/ceval-exam/resolve/main/ceval-exam.zip \n",
|
| 13 |
+
"unzip ceval-exam.zip -d ceval-exam\n",
|
| 14 |
+
"wget https://github.com/hkust-nlp/ceval/blob/main/subject_mapping.json\n",
|
| 15 |
+
"```"
|
| 16 |
+
]
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"cell_type": "code",
|
| 20 |
+
"execution_count": 1,
|
| 21 |
+
"metadata": {},
|
| 22 |
+
"outputs": [
|
| 23 |
+
{
|
| 24 |
+
"name": "stdout",
|
| 25 |
+
"output_type": "stream",
|
| 26 |
+
"text": [
|
| 27 |
+
"dev\n",
|
| 28 |
+
"subject_mapping.json\n",
|
| 29 |
+
"test\n",
|
| 30 |
+
"val\n"
|
| 31 |
+
]
|
| 32 |
+
}
|
| 33 |
+
],
|
| 34 |
+
"source": [
|
| 35 |
+
"! ls ceval-exam"
|
| 36 |
+
]
|
| 37 |
+
},
|
| 38 |
+
{
|
| 39 |
+
"cell_type": "code",
|
| 40 |
+
"execution_count": 2,
|
| 41 |
+
"metadata": {},
|
| 42 |
+
"outputs": [],
|
| 43 |
+
"source": [
|
| 44 |
+
"import os, re\n",
|
| 45 |
+
"import ujson\n",
|
| 46 |
+
"import torch\n",
|
| 47 |
+
"import pandas as pd\n",
|
| 48 |
+
"from tqdm import tqdm\n",
|
| 49 |
+
"from transformers import AutoModelForSeq2SeqLM, AutoTokenizer\n",
|
| 50 |
+
"from transformers.generation.configuration_utils import GenerationConfig\n",
|
| 51 |
+
"from transformers.generation.utils import LogitsProcessorList, InfNanRemoveLogitsProcessor"
|
| 52 |
+
]
|
| 53 |
+
},
|
| 54 |
+
{
|
| 55 |
+
"cell_type": "code",
|
| 56 |
+
"execution_count": 3,
|
| 57 |
+
"metadata": {},
|
| 58 |
+
"outputs": [],
|
| 59 |
+
"source": [
|
| 60 |
+
"ceval_dir = './ceval-exam'\n",
|
| 61 |
+
"result_save_dir = './result'\n",
|
| 62 |
+
"model_dir = '../model_save/dpo' # 模型文件在上一层目录,使用dpo后的模型\n",
|
| 63 |
+
"\n",
|
| 64 |
+
"if not os.path.exists(result_save_dir):\n",
|
| 65 |
+
" os.mkdir(result_save_dir)"
|
| 66 |
+
]
|
| 67 |
+
},
|
| 68 |
+
{
|
| 69 |
+
"cell_type": "code",
|
| 70 |
+
"execution_count": 4,
|
| 71 |
+
"metadata": {},
|
| 72 |
+
"outputs": [],
|
| 73 |
+
"source": [
|
| 74 |
+
"subject_files = os.listdir(f\"{ceval_dir}/val\")\n",
|
| 75 |
+
"subjects = [subjetc.replace('_val.csv', '') for subjetc in subject_files]\n",
|
| 76 |
+
"\n",
|
| 77 |
+
"subject_mapping = {}\n",
|
| 78 |
+
"with open('./ceval-exam/subject_mapping.json', 'r', encoding='utf-8') as f:\n",
|
| 79 |
+
" subject_mapping = ujson.load(f)"
|
| 80 |
+
]
|
| 81 |
+
},
|
| 82 |
+
{
|
| 83 |
+
"cell_type": "markdown",
|
| 84 |
+
"metadata": {},
|
| 85 |
+
"source": [
|
| 86 |
+
"由于本项目的模型在sft阶段删除了很多带input的数据,且没有针对问题回答做微调,直接输入问题会解释问题中提到的关键词。所以c-eval测试使用预测 'A'、'B'、'C'、'D' token的方式。\n",
|
| 87 |
+
"> 然而有时候,特别是零样本测试和面对没有做过指令微调的模型时,模型可能无法很好的理解指令,甚至有时不会回答问题。这种情况下我们推荐直接计算下一个预测token等于\"A\", \"B\", \"C\", \"D\"的概率,然后以概率最大的选项作为答案 \n",
|
| 88 |
+
"> -- 这是一种受限解码生成的方法,MMLU的官方测试代码中是使用了这种方法进行测试。注意这种概率方法对思维链的测试不适用。\n",
|
| 89 |
+
"\n",
|
| 90 |
+
"见: [如何在C-Eval上测试](https://github.com/hkust-nlp/ceval/blob/main/README_zh.md#如何在C-Eval上测试)\n",
|
| 91 |
+
"\n",
|
| 92 |
+
"评测模式:zero-shot模式(chatbot/对话机器人模式) \n",
|
| 93 |
+
"dev数据集用来做few-shot,暂时不用"
|
| 94 |
+
]
|
| 95 |
+
},
|
| 96 |
+
{
|
| 97 |
+
"cell_type": "code",
|
| 98 |
+
"execution_count": 5,
|
| 99 |
+
"metadata": {},
|
| 100 |
+
"outputs": [],
|
| 101 |
+
"source": [
|
| 102 |
+
"def format_prompt(df: pd.Series) -> str:\n",
|
| 103 |
+
" '''\n",
|
| 104 |
+
" 将df中的 'question', 'A', 'B', 'C', 'D',格式化为问题\n",
|
| 105 |
+
" '''\n",
|
| 106 |
+
" prompt = f\"请回答单选题,回答字母A、B、C、D即可。问题:\\n{df['question']}\\n答案选项:\\n\"\n",
|
| 107 |
+
" for col in ['A', 'B', 'C', 'D']:\n",
|
| 108 |
+
" prompt += f\"{col}:{df[col]}\\n\"\n",
|
| 109 |
+
" \n",
|
| 110 |
+
" return prompt"
|
| 111 |
+
]
|
| 112 |
+
},
|
| 113 |
+
{
|
| 114 |
+
"cell_type": "code",
|
| 115 |
+
"execution_count": 6,
|
| 116 |
+
"metadata": {},
|
| 117 |
+
"outputs": [
|
| 118 |
+
{
|
| 119 |
+
"data": {
|
| 120 |
+
"text/plain": [
|
| 121 |
+
"['Accountant', '注册会计师', 'Other']"
|
| 122 |
+
]
|
| 123 |
+
},
|
| 124 |
+
"execution_count": 6,
|
| 125 |
+
"metadata": {},
|
| 126 |
+
"output_type": "execute_result"
|
| 127 |
+
}
|
| 128 |
+
],
|
| 129 |
+
"source": [
|
| 130 |
+
"subject_mapping['accountant']"
|
| 131 |
+
]
|
| 132 |
+
},
|
| 133 |
+
{
|
| 134 |
+
"cell_type": "code",
|
| 135 |
+
"execution_count": 7,
|
| 136 |
+
"metadata": {},
|
| 137 |
+
"outputs": [
|
| 138 |
+
{
|
| 139 |
+
"name": "stderr",
|
| 140 |
+
"output_type": "stream",
|
| 141 |
+
"text": [
|
| 142 |
+
"100%|██████████| 52/52 [00:00<00:00, 617.74it/s]\n"
|
| 143 |
+
]
|
| 144 |
+
}
|
| 145 |
+
],
|
| 146 |
+
"source": [
|
| 147 |
+
"do_test = False\n",
|
| 148 |
+
"all_eval_items = []\n",
|
| 149 |
+
"for i, subject_name in tqdm(enumerate(subjects), total=len(subjects)):\n",
|
| 150 |
+
" val_file = f\"{ceval_dir}/val/{subject_name}_val.csv\"\n",
|
| 151 |
+
" test_file = f\"{ceval_dir}/test/{subject_name}_test.csv\"\n",
|
| 152 |
+
"\n",
|
| 153 |
+
" val_df = pd.read_csv(test_file) if do_test else pd.read_csv(val_file)\n",
|
| 154 |
+
" \n",
|
| 155 |
+
" for idx, row in val_df.iterrows():\n",
|
| 156 |
+
" quesuton = format_prompt(row)\n",
|
| 157 |
+
" answer = row['answer'] if 'answer' in val_df.columns else '' \n",
|
| 158 |
+
"\n",
|
| 159 |
+
" item = {\n",
|
| 160 |
+
" 'subject_en': subject_mapping[subject_name][0],\n",
|
| 161 |
+
" 'subject_zh': subject_mapping[subject_name][1],\n",
|
| 162 |
+
" 'category': subject_mapping[subject_name][2], # 类别(STEM,Social Science,Humanities,Other四选一)\n",
|
| 163 |
+
" 'question': quesuton,\n",
|
| 164 |
+
" 'answer':answer,\n",
|
| 165 |
+
" }\n",
|
| 166 |
+
" \n",
|
| 167 |
+
" all_eval_items.append(item)"
|
| 168 |
+
]
|
| 169 |
+
},
|
| 170 |
+
{
|
| 171 |
+
"cell_type": "code",
|
| 172 |
+
"execution_count": 8,
|
| 173 |
+
"metadata": {},
|
| 174 |
+
"outputs": [
|
| 175 |
+
{
|
| 176 |
+
"data": {
|
| 177 |
+
"text/html": [
|
| 178 |
+
"<div>\n",
|
| 179 |
+
"<style scoped>\n",
|
| 180 |
+
" .dataframe tbody tr th:only-of-type {\n",
|
| 181 |
+
" vertical-align: middle;\n",
|
| 182 |
+
" }\n",
|
| 183 |
+
"\n",
|
| 184 |
+
" .dataframe tbody tr th {\n",
|
| 185 |
+
" vertical-align: top;\n",
|
| 186 |
+
" }\n",
|
| 187 |
+
"\n",
|
| 188 |
+
" .dataframe thead th {\n",
|
| 189 |
+
" text-align: right;\n",
|
| 190 |
+
" }\n",
|
| 191 |
+
"</style>\n",
|
| 192 |
+
"<table border=\"1\" class=\"dataframe\">\n",
|
| 193 |
+
" <thead>\n",
|
| 194 |
+
" <tr style=\"text-align: right;\">\n",
|
| 195 |
+
" <th></th>\n",
|
| 196 |
+
" <th>subject_en</th>\n",
|
| 197 |
+
" <th>subject_zh</th>\n",
|
| 198 |
+
" <th>category</th>\n",
|
| 199 |
+
" <th>question</th>\n",
|
| 200 |
+
" <th>answer</th>\n",
|
| 201 |
+
" </tr>\n",
|
| 202 |
+
" </thead>\n",
|
| 203 |
+
" <tbody>\n",
|
| 204 |
+
" <tr>\n",
|
| 205 |
+
" <th>0</th>\n",
|
| 206 |
+
" <td>Accountant</td>\n",
|
| 207 |
+
" <td>注册会计师</td>\n",
|
| 208 |
+
" <td>Other</td>\n",
|
| 209 |
+
" <td>请回答单选题,回答字母A、B、C、D即可。问题:\\n下列关于税法基本原则的表述中,不正确的是...</td>\n",
|
| 210 |
+
" <td>D</td>\n",
|
| 211 |
+
" </tr>\n",
|
| 212 |
+
" <tr>\n",
|
| 213 |
+
" <th>1</th>\n",
|
| 214 |
+
" <td>Accountant</td>\n",
|
| 215 |
+
" <td>注册会计师</td>\n",
|
| 216 |
+
" <td>Other</td>\n",
|
| 217 |
+
" <td>请回答单选题,回答字母A、B、C、D即可。问题:\\n甲公司是国内一家领先的新媒体、通信及移动...</td>\n",
|
| 218 |
+
" <td>C</td>\n",
|
| 219 |
+
" </tr>\n",
|
| 220 |
+
" <tr>\n",
|
| 221 |
+
" <th>2</th>\n",
|
| 222 |
+
" <td>Accountant</td>\n",
|
| 223 |
+
" <td>注册会计师</td>\n",
|
| 224 |
+
" <td>Other</td>\n",
|
| 225 |
+
" <td>请回答单选题,回答字母A、B、C、D即可。问题:\\n根据我国《印花税暂行条例》的规定,下列各...</td>\n",
|
| 226 |
+
" <td>D</td>\n",
|
| 227 |
+
" </tr>\n",
|
| 228 |
+
" <tr>\n",
|
| 229 |
+
" <th>3</th>\n",
|
| 230 |
+
" <td>Accountant</td>\n",
|
| 231 |
+
" <td>注册会计师</td>\n",
|
| 232 |
+
" <td>Other</td>\n",
|
| 233 |
+
" <td>请回答单选题,回答字母A、B、C、D即可。问题:\\n税务行政复议的申请人可以在得知税务机关作...</td>\n",
|
| 234 |
+
" <td>A</td>\n",
|
| 235 |
+
" </tr>\n",
|
| 236 |
+
" <tr>\n",
|
| 237 |
+
" <th>4</th>\n",
|
| 238 |
+
" <td>Accountant</td>\n",
|
| 239 |
+
" <td>注册会计师</td>\n",
|
| 240 |
+
" <td>Other</td>\n",
|
| 241 |
+
" <td>请回答单选题,回答字母A、B、C、D即可。问题:\\n关于战略管理表述错误的是____。\\n答...</td>\n",
|
| 242 |
+
" <td>C</td>\n",
|
| 243 |
+
" </tr>\n",
|
| 244 |
+
" </tbody>\n",
|
| 245 |
+
"</table>\n",
|
| 246 |
+
"</div>"
|
| 247 |
+
],
|
| 248 |
+
"text/plain": [
|
| 249 |
+
" subject_en subject_zh category \\\n",
|
| 250 |
+
"0 Accountant 注册会计师 Other \n",
|
| 251 |
+
"1 Accountant 注册会计师 Other \n",
|
| 252 |
+
"2 Accountant 注册会计师 Other \n",
|
| 253 |
+
"3 Accountant 注册会计师 Other \n",
|
| 254 |
+
"4 Accountant 注册会计师 Other \n",
|
| 255 |
+
"\n",
|
| 256 |
+
" question answer \n",
|
| 257 |
+
"0 请回答单选题,回答字母A、B、C、D即可。问题:\\n下列关于税法基本原则的表述中,不正确的是... D \n",
|
| 258 |
+
"1 请回答单选题,回答字母A、B、C、D即可。问题:\\n甲公司是国内一家领先的新媒体、通信及移动... C \n",
|
| 259 |
+
"2 请回答单选题,回答字母A、B、C、D即可。问题:\\n根据我国《印花税暂行条例》的规定,下列各... D \n",
|
| 260 |
+
"3 请回答单选题,回答字母A、B、C、D即可。问题:\\n税务行政复议的申请人可以在得知税务机关作... A \n",
|
| 261 |
+
"4 请回答单选题,回答字母A、B、C、D即可。问题:\\n关于战略管理表述错误的是____。\\n答... C "
|
| 262 |
+
]
|
| 263 |
+
},
|
| 264 |
+
"execution_count": 8,
|
| 265 |
+
"metadata": {},
|
| 266 |
+
"output_type": "execute_result"
|
| 267 |
+
}
|
| 268 |
+
],
|
| 269 |
+
"source": [
|
| 270 |
+
"eval_df = pd.DataFrame(all_eval_items)\n",
|
| 271 |
+
"eval_df.head(5)"
|
| 272 |
+
]
|
| 273 |
+
},
|
| 274 |
+
{
|
| 275 |
+
"cell_type": "code",
|
| 276 |
+
"execution_count": 9,
|
| 277 |
+
"metadata": {},
|
| 278 |
+
"outputs": [
|
| 279 |
+
{
|
| 280 |
+
"data": {
|
| 281 |
+
"text/plain": [
|
| 282 |
+
"[872, 873, 884, 886]"
|
| 283 |
+
]
|
| 284 |
+
},
|
| 285 |
+
"execution_count": 9,
|
| 286 |
+
"metadata": {},
|
| 287 |
+
"output_type": "execute_result"
|
| 288 |
+
}
|
| 289 |
+
],
|
| 290 |
+
"source": [
|
| 291 |
+
"# 加载模型\n",
|
| 292 |
+
"tokenizer = AutoTokenizer.from_pretrained(model_dir)\n",
|
| 293 |
+
"model = AutoModelForSeq2SeqLM.from_pretrained(model_dir)\n",
|
| 294 |
+
"\n",
|
| 295 |
+
"generation_config = GenerationConfig()\n",
|
| 296 |
+
"generation_config.remove_invalid_values = True # 自动添加InfNanRemoveLogitsProcessor\n",
|
| 297 |
+
"generation_config.eos_token_id = tokenizer.eos_token_id\n",
|
| 298 |
+
"generation_config.pad_token_id = tokenizer.pad_token_id\n",
|
| 299 |
+
"# for t5, set decoder_start_token_id = pad_token_id\n",
|
| 300 |
+
"generation_config.decoder_start_token_id = tokenizer.pad_token_id \n",
|
| 301 |
+
"generation_config.max_new_tokens = 16\n",
|
| 302 |
+
"generation_config.num_beams = 1\n",
|
| 303 |
+
"generation_config.do_sample = False # greedy search\n",
|
| 304 |
+
"\n",
|
| 305 |
+
"choices = ['A', 'B', 'C', 'D']\n",
|
| 306 |
+
"choices_ids = [tokenizer.convert_tokens_to_ids(c) for c in choices]\n",
|
| 307 |
+
"choices_ids"
|
| 308 |
+
]
|
| 309 |
+
},
|
| 310 |
+
{
|
| 311 |
+
"cell_type": "code",
|
| 312 |
+
"execution_count": 10,
|
| 313 |
+
"metadata": {},
|
| 314 |
+
"outputs": [
|
| 315 |
+
{
|
| 316 |
+
"name": "stderr",
|
| 317 |
+
"output_type": "stream",
|
| 318 |
+
"text": [
|
| 319 |
+
"100%|██████████| 1346/1346 [00:20<00:00, 64.11it/s]\n"
|
| 320 |
+
]
|
| 321 |
+
}
|
| 322 |
+
],
|
| 323 |
+
"source": [
|
| 324 |
+
"batch_size = 32\n",
|
| 325 |
+
"batch_data, batch_answers = [], []\n",
|
| 326 |
+
"n = len(eval_df)\n",
|
| 327 |
+
"device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')\n",
|
| 328 |
+
"model.to(device)\n",
|
| 329 |
+
"model.eval()\n",
|
| 330 |
+
"\n",
|
| 331 |
+
"for idx, row in tqdm(eval_df.iterrows(), total=n):\n",
|
| 332 |
+
" batch_data.append(row['question'])\n",
|
| 333 |
+
" \n",
|
| 334 |
+
" if len(batch_data) == batch_size or idx == n - 1:\n",
|
| 335 |
+
" torch.cuda.empty_cache()\n",
|
| 336 |
+
" \n",
|
| 337 |
+
" encode_ids = tokenizer(batch_data, padding=True)\n",
|
| 338 |
+
" input_ids, attention_mask = torch.LongTensor(encode_ids['input_ids']), torch.LongTensor(encode_ids['attention_mask'])\n",
|
| 339 |
+
" \n",
|
| 340 |
+
" outputs = model.generate(\n",
|
| 341 |
+
" input_ids=input_ids.to(device),\n",
|
| 342 |
+
" attention_mask=attention_mask.to(device),\n",
|
| 343 |
+
" generation_config=generation_config,\n",
|
| 344 |
+
" return_dict_in_generate=True,\n",
|
| 345 |
+
" output_scores=True,\n",
|
| 346 |
+
" )\n",
|
| 347 |
+
"\n",
|
| 348 |
+
" scores = torch.stack(outputs['scores'], dim=1)\n",
|
| 349 |
+
" scores = torch.softmax(scores, dim=2)\n",
|
| 350 |
+
" scores = scores[..., 0, choices_ids] #取第一个字符的ABCD概率\n",
|
| 351 |
+
" choices_index = torch.argmax(scores, dim=1)\n",
|
| 352 |
+
" \n",
|
| 353 |
+
" for i in choices_index:\n",
|
| 354 |
+
" batch_answers.append(choices[i])\n",
|
| 355 |
+
"\n",
|
| 356 |
+
" batch_data = []"
|
| 357 |
+
]
|
| 358 |
+
},
|
| 359 |
+
{
|
| 360 |
+
"cell_type": "code",
|
| 361 |
+
"execution_count": 11,
|
| 362 |
+
"metadata": {},
|
| 363 |
+
"outputs": [],
|
| 364 |
+
"source": [
|
| 365 |
+
"eval_df.insert(loc=5, column='model_predict', value=batch_answers)\n",
|
| 366 |
+
"val_df = eval_df.copy(deep=True)"
|
| 367 |
+
]
|
| 368 |
+
},
|
| 369 |
+
{
|
| 370 |
+
"cell_type": "code",
|
| 371 |
+
"execution_count": 12,
|
| 372 |
+
"metadata": {},
|
| 373 |
+
"outputs": [],
|
| 374 |
+
"source": [
|
| 375 |
+
"val_df['is_correct'] = val_df['model_predict'] == val_df['answer']\n",
|
| 376 |
+
"val_df['is_correct'] = val_df['is_correct'].astype(pd.Int16Dtype())"
|
| 377 |
+
]
|
| 378 |
+
},
|
| 379 |
+
{
|
| 380 |
+
"cell_type": "code",
|
| 381 |
+
"execution_count": 13,
|
| 382 |
+
"metadata": {},
|
| 383 |
+
"outputs": [
|
| 384 |
+
{
|
| 385 |
+
"data": {
|
| 386 |
+
"text/html": [
|
| 387 |
+
"<div>\n",
|
| 388 |
+
"<style scoped>\n",
|
| 389 |
+
" .dataframe tbody tr th:only-of-type {\n",
|
| 390 |
+
" vertical-align: middle;\n",
|
| 391 |
+
" }\n",
|
| 392 |
+
"\n",
|
| 393 |
+
" .dataframe tbody tr th {\n",
|
| 394 |
+
" vertical-align: top;\n",
|
| 395 |
+
" }\n",
|
| 396 |
+
"\n",
|
| 397 |
+
" .dataframe thead th {\n",
|
| 398 |
+
" text-align: right;\n",
|
| 399 |
+
" }\n",
|
| 400 |
+
"</style>\n",
|
| 401 |
+
"<table border=\"1\" class=\"dataframe\">\n",
|
| 402 |
+
" <thead>\n",
|
| 403 |
+
" <tr style=\"text-align: right;\">\n",
|
| 404 |
+
" <th></th>\n",
|
| 405 |
+
" <th>subject_en</th>\n",
|
| 406 |
+
" <th>subject_zh</th>\n",
|
| 407 |
+
" <th>category</th>\n",
|
| 408 |
+
" <th>question</th>\n",
|
| 409 |
+
" <th>answer</th>\n",
|
| 410 |
+
" <th>model_predict</th>\n",
|
| 411 |
+
" <th>is_correct</th>\n",
|
| 412 |
+
" </tr>\n",
|
| 413 |
+
" </thead>\n",
|
| 414 |
+
" <tbody>\n",
|
| 415 |
+
" <tr>\n",
|
| 416 |
+
" <th>0</th>\n",
|
| 417 |
+
" <td>Accountant</td>\n",
|
| 418 |
+
" <td>注册会计师</td>\n",
|
| 419 |
+
" <td>Other</td>\n",
|
| 420 |
+
" <td>请回答单选题,回答字母A、B、C、D即可。问题:\\n下列关于税法基本原则的表述中,不正确的是...</td>\n",
|
| 421 |
+
" <td>D</td>\n",
|
| 422 |
+
" <td>A</td>\n",
|
| 423 |
+
" <td>0</td>\n",
|
| 424 |
+
" </tr>\n",
|
| 425 |
+
" <tr>\n",
|
| 426 |
+
" <th>1</th>\n",
|
| 427 |
+
" <td>Accountant</td>\n",
|
| 428 |
+
" <td>注册会计师</td>\n",
|
| 429 |
+
" <td>Other</td>\n",
|
| 430 |
+
" <td>请回答单选题,回答字母A、B、C、D即可。问题:\\n甲公司是国内一家领先的新媒体、通信及移动...</td>\n",
|
| 431 |
+
" <td>C</td>\n",
|
| 432 |
+
" <td>A</td>\n",
|
| 433 |
+
" <td>0</td>\n",
|
| 434 |
+
" </tr>\n",
|
| 435 |
+
" <tr>\n",
|
| 436 |
+
" <th>2</th>\n",
|
| 437 |
+
" <td>Accountant</td>\n",
|
| 438 |
+
" <td>注册会计师</td>\n",
|
| 439 |
+
" <td>Other</td>\n",
|
| 440 |
+
" <td>请回答单选题,回答字母A、B、C、D即可。问题:\\n根据我国《印花税暂行条例》的规定,下列各...</td>\n",
|
| 441 |
+
" <td>D</td>\n",
|
| 442 |
+
" <td>A</td>\n",
|
| 443 |
+
" <td>0</td>\n",
|
| 444 |
+
" </tr>\n",
|
| 445 |
+
" </tbody>\n",
|
| 446 |
+
"</table>\n",
|
| 447 |
+
"</div>"
|
| 448 |
+
],
|
| 449 |
+
"text/plain": [
|
| 450 |
+
" subject_en subject_zh category \\\n",
|
| 451 |
+
"0 Accountant 注册会计师 Other \n",
|
| 452 |
+
"1 Accountant 注册会计师 Other \n",
|
| 453 |
+
"2 Accountant 注册会计师 Other \n",
|
| 454 |
+
"\n",
|
| 455 |
+
" question answer model_predict \\\n",
|
| 456 |
+
"0 请回答单选题,回答字母A、B、C、D即可。问题:\\n下列关于税法基本原则的表述中,不正确的是... D A \n",
|
| 457 |
+
"1 请回答单选题,回答字母A、B、C、D即可。问题:\\n甲公司是国内一家领先的新媒体、通信及移动... C A \n",
|
| 458 |
+
"2 请回答单选题,回答字母A、B、C、D即可。问题:\\n根据我国《印花税暂行条例》的规定,下列各... D A \n",
|
| 459 |
+
"\n",
|
| 460 |
+
" is_correct \n",
|
| 461 |
+
"0 0 \n",
|
| 462 |
+
"1 0 \n",
|
| 463 |
+
"2 0 "
|
| 464 |
+
]
|
| 465 |
+
},
|
| 466 |
+
"execution_count": 13,
|
| 467 |
+
"metadata": {},
|
| 468 |
+
"output_type": "execute_result"
|
| 469 |
+
}
|
| 470 |
+
],
|
| 471 |
+
"source": [
|
| 472 |
+
"val_df.head(3)"
|
| 473 |
+
]
|
| 474 |
+
},
|
| 475 |
+
{
|
| 476 |
+
"cell_type": "code",
|
| 477 |
+
"execution_count": 14,
|
| 478 |
+
"metadata": {},
|
| 479 |
+
"outputs": [
|
| 480 |
+
{
|
| 481 |
+
"data": {
|
| 482 |
+
"text/html": [
|
| 483 |
+
"<div>\n",
|
| 484 |
+
"<style scoped>\n",
|
| 485 |
+
" .dataframe tbody tr th:only-of-type {\n",
|
| 486 |
+
" vertical-align: middle;\n",
|
| 487 |
+
" }\n",
|
| 488 |
+
"\n",
|
| 489 |
+
" .dataframe tbody tr th {\n",
|
| 490 |
+
" vertical-align: top;\n",
|
| 491 |
+
" }\n",
|
| 492 |
+
"\n",
|
| 493 |
+
" .dataframe thead th {\n",
|
| 494 |
+
" text-align: right;\n",
|
| 495 |
+
" }\n",
|
| 496 |
+
"</style>\n",
|
| 497 |
+
"<table border=\"1\" class=\"dataframe\">\n",
|
| 498 |
+
" <thead>\n",
|
| 499 |
+
" <tr style=\"text-align: right;\">\n",
|
| 500 |
+
" <th></th>\n",
|
| 501 |
+
" <th>is_correct</th>\n",
|
| 502 |
+
" </tr>\n",
|
| 503 |
+
" <tr>\n",
|
| 504 |
+
" <th>category</th>\n",
|
| 505 |
+
" <th></th>\n",
|
| 506 |
+
" </tr>\n",
|
| 507 |
+
" </thead>\n",
|
| 508 |
+
" <tbody>\n",
|
| 509 |
+
" <tr>\n",
|
| 510 |
+
" <th>Humanities</th>\n",
|
| 511 |
+
" <td>63</td>\n",
|
| 512 |
+
" </tr>\n",
|
| 513 |
+
" <tr>\n",
|
| 514 |
+
" <th>Other</th>\n",
|
| 515 |
+
" <td>89</td>\n",
|
| 516 |
+
" </tr>\n",
|
| 517 |
+
" <tr>\n",
|
| 518 |
+
" <th>STEM</th>\n",
|
| 519 |
+
" <td>89</td>\n",
|
| 520 |
+
" </tr>\n",
|
| 521 |
+
" <tr>\n",
|
| 522 |
+
" <th>Social Science</th>\n",
|
| 523 |
+
" <td>72</td>\n",
|
| 524 |
+
" </tr>\n",
|
| 525 |
+
" </tbody>\n",
|
| 526 |
+
"</table>\n",
|
| 527 |
+
"</div>"
|
| 528 |
+
],
|
| 529 |
+
"text/plain": [
|
| 530 |
+
" is_correct\n",
|
| 531 |
+
"category \n",
|
| 532 |
+
"Humanities 63\n",
|
| 533 |
+
"Other 89\n",
|
| 534 |
+
"STEM 89\n",
|
| 535 |
+
"Social Science 72"
|
| 536 |
+
]
|
| 537 |
+
},
|
| 538 |
+
"execution_count": 14,
|
| 539 |
+
"metadata": {},
|
| 540 |
+
"output_type": "execute_result"
|
| 541 |
+
}
|
| 542 |
+
],
|
| 543 |
+
"source": [
|
| 544 |
+
"final_df = val_df.groupby('category').sum('is_correct')\n",
|
| 545 |
+
"final_df"
|
| 546 |
+
]
|
| 547 |
+
},
|
| 548 |
+
{
|
| 549 |
+
"cell_type": "code",
|
| 550 |
+
"execution_count": 15,
|
| 551 |
+
"metadata": {},
|
| 552 |
+
"outputs": [
|
| 553 |
+
{
|
| 554 |
+
"data": {
|
| 555 |
+
"text/html": [
|
| 556 |
+
"<div>\n",
|
| 557 |
+
"<style scoped>\n",
|
| 558 |
+
" .dataframe tbody tr th:only-of-type {\n",
|
| 559 |
+
" vertical-align: middle;\n",
|
| 560 |
+
" }\n",
|
| 561 |
+
"\n",
|
| 562 |
+
" .dataframe tbody tr th {\n",
|
| 563 |
+
" vertical-align: top;\n",
|
| 564 |
+
" }\n",
|
| 565 |
+
"\n",
|
| 566 |
+
" .dataframe thead th {\n",
|
| 567 |
+
" text-align: right;\n",
|
| 568 |
+
" }\n",
|
| 569 |
+
"</style>\n",
|
| 570 |
+
"<table border=\"1\" class=\"dataframe\">\n",
|
| 571 |
+
" <thead>\n",
|
| 572 |
+
" <tr style=\"text-align: right;\">\n",
|
| 573 |
+
" <th></th>\n",
|
| 574 |
+
" <th>is_correct</th>\n",
|
| 575 |
+
" <th>question_count</th>\n",
|
| 576 |
+
" <th>accuracy</th>\n",
|
| 577 |
+
" </tr>\n",
|
| 578 |
+
" <tr>\n",
|
| 579 |
+
" <th>category</th>\n",
|
| 580 |
+
" <th></th>\n",
|
| 581 |
+
" <th></th>\n",
|
| 582 |
+
" <th></th>\n",
|
| 583 |
+
" </tr>\n",
|
| 584 |
+
" </thead>\n",
|
| 585 |
+
" <tbody>\n",
|
| 586 |
+
" <tr>\n",
|
| 587 |
+
" <th>Humanities</th>\n",
|
| 588 |
+
" <td>63</td>\n",
|
| 589 |
+
" <td>257</td>\n",
|
| 590 |
+
" <td>24.51%</td>\n",
|
| 591 |
+
" </tr>\n",
|
| 592 |
+
" <tr>\n",
|
| 593 |
+
" <th>Other</th>\n",
|
| 594 |
+
" <td>89</td>\n",
|
| 595 |
+
" <td>384</td>\n",
|
| 596 |
+
" <td>23.18%</td>\n",
|
| 597 |
+
" </tr>\n",
|
| 598 |
+
" <tr>\n",
|
| 599 |
+
" <th>STEM</th>\n",
|
| 600 |
+
" <td>89</td>\n",
|
| 601 |
+
" <td>430</td>\n",
|
| 602 |
+
" <td>20.70%</td>\n",
|
| 603 |
+
" </tr>\n",
|
| 604 |
+
" <tr>\n",
|
| 605 |
+
" <th>Social Science</th>\n",
|
| 606 |
+
" <td>72</td>\n",
|
| 607 |
+
" <td>275</td>\n",
|
| 608 |
+
" <td>26.18%</td>\n",
|
| 609 |
+
" </tr>\n",
|
| 610 |
+
" </tbody>\n",
|
| 611 |
+
"</table>\n",
|
| 612 |
+
"</div>"
|
| 613 |
+
],
|
| 614 |
+
"text/plain": [
|
| 615 |
+
" is_correct question_count accuracy\n",
|
| 616 |
+
"category \n",
|
| 617 |
+
"Humanities 63 257 24.51%\n",
|
| 618 |
+
"Other 89 384 23.18%\n",
|
| 619 |
+
"STEM 89 430 20.70%\n",
|
| 620 |
+
"Social Science 72 275 26.18%"
|
| 621 |
+
]
|
| 622 |
+
},
|
| 623 |
+
"execution_count": 15,
|
| 624 |
+
"metadata": {},
|
| 625 |
+
"output_type": "execute_result"
|
| 626 |
+
}
|
| 627 |
+
],
|
| 628 |
+
"source": [
|
| 629 |
+
"final_df['question_count'] = val_df.groupby('category').count()['question']\n",
|
| 630 |
+
"final_df['accuracy'] = final_df['is_correct'] / final_df['question_count']\n",
|
| 631 |
+
"final_df['accuracy'] = final_df['accuracy'] .apply(lambda x: format(x, '.2%'))\n",
|
| 632 |
+
"final_df"
|
| 633 |
+
]
|
| 634 |
+
}
|
| 635 |
+
],
|
| 636 |
+
"metadata": {
|
| 637 |
+
"kernelspec": {
|
| 638 |
+
"display_name": "py310",
|
| 639 |
+
"language": "python",
|
| 640 |
+
"name": "python3"
|
| 641 |
+
},
|
| 642 |
+
"language_info": {
|
| 643 |
+
"codemirror_mode": {
|
| 644 |
+
"name": "ipython",
|
| 645 |
+
"version": 3
|
| 646 |
+
},
|
| 647 |
+
"file_extension": ".py",
|
| 648 |
+
"mimetype": "text/x-python",
|
| 649 |
+
"name": "python",
|
| 650 |
+
"nbconvert_exporter": "python",
|
| 651 |
+
"pygments_lexer": "ipython3",
|
| 652 |
+
"version": "3.10.12"
|
| 653 |
+
}
|
| 654 |
+
},
|
| 655 |
+
"nbformat": 4,
|
| 656 |
+
"nbformat_minor": 2
|
| 657 |
+
}
|
eval/cmmlu.ipynb
ADDED
|
@@ -0,0 +1,241 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": null,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [],
|
| 8 |
+
"source": [
|
| 9 |
+
"import os\n",
|
| 10 |
+
"import torch\n",
|
| 11 |
+
"import numpy as np\n",
|
| 12 |
+
"import sys\n",
|
| 13 |
+
"root = '/'.join(os.path.realpath('.').replace('\\\\','/').split('/'))\n",
|
| 14 |
+
"p = root + '/CMMLU/src'\n",
|
| 15 |
+
"if p not in sys.path:\n",
|
| 16 |
+
" sys.path.append(p)\n",
|
| 17 |
+
"import argparse\n",
|
| 18 |
+
"from CMMLU.src.mp_utils import choices, format_example, gen_prompt, softmax, run_eval\n",
|
| 19 |
+
"from transformers import AutoModelForSeq2SeqLM, AutoTokenizer\n",
|
| 20 |
+
"from transformers.generation.configuration_utils import GenerationConfig"
|
| 21 |
+
]
|
| 22 |
+
},
|
| 23 |
+
{
|
| 24 |
+
"cell_type": "markdown",
|
| 25 |
+
"metadata": {},
|
| 26 |
+
"source": [
|
| 27 |
+
"```bash\n",
|
| 28 |
+
"git clone -- depth 1 https://github.com/haonan-li/CMMLU.git\n",
|
| 29 |
+
"```\n",
|
| 30 |
+
"\n",
|
| 31 |
+
"cpoied from https://github.com/haonan-li/CMMLU/blob/master/src/hf_causal_model.py"
|
| 32 |
+
]
|
| 33 |
+
},
|
| 34 |
+
{
|
| 35 |
+
"cell_type": "code",
|
| 36 |
+
"execution_count": null,
|
| 37 |
+
"metadata": {},
|
| 38 |
+
"outputs": [],
|
| 39 |
+
"source": [
|
| 40 |
+
"model_dir = '../model_save/dpo' # 模型文件在上一层目录,使用dpo后的模型\n",
|
| 41 |
+
"device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')\n",
|
| 42 |
+
"# 加载模型\n",
|
| 43 |
+
"tokenizer = AutoTokenizer.from_pretrained(model_dir)\n",
|
| 44 |
+
"model = AutoModelForSeq2SeqLM.from_pretrained(model_dir).to(device)\n",
|
| 45 |
+
"generation_config = GenerationConfig()\n",
|
| 46 |
+
"generation_config.remove_invalid_values = True # 自动添加InfNanRemoveLogitsProcessor\n",
|
| 47 |
+
"generation_config.eos_token_id = tokenizer.eos_token_id\n",
|
| 48 |
+
"generation_config.pad_token_id = tokenizer.pad_token_id\n",
|
| 49 |
+
"# for t5, set decoder_start_token_id = pad_token_id\n",
|
| 50 |
+
"generation_config.decoder_start_token_id = tokenizer.pad_token_id \n",
|
| 51 |
+
"generation_config.max_new_tokens = 1\n",
|
| 52 |
+
"generation_config.num_beams = 1\n",
|
| 53 |
+
"generation_config.do_sample = False # greedy search\n",
|
| 54 |
+
"\n",
|
| 55 |
+
"choices = ['A', 'B', 'C', 'D']\n",
|
| 56 |
+
"choices_ids = [tokenizer.convert_tokens_to_ids(c) for c in choices]\n",
|
| 57 |
+
"choices_ids"
|
| 58 |
+
]
|
| 59 |
+
},
|
| 60 |
+
{
|
| 61 |
+
"cell_type": "code",
|
| 62 |
+
"execution_count": 3,
|
| 63 |
+
"metadata": {},
|
| 64 |
+
"outputs": [],
|
| 65 |
+
"source": [
|
| 66 |
+
"def eval(model, tokenizer, subject, dev_df, test_df, num_few_shot, max_length, cot):\n",
|
| 67 |
+
" choice_ids = [tokenizer.convert_tokens_to_ids(choice) for choice in choices]\n",
|
| 68 |
+
" cors = []\n",
|
| 69 |
+
" all_conf = []\n",
|
| 70 |
+
" all_preds = []\n",
|
| 71 |
+
" answers = choices[: test_df.shape[1] - 2]\n",
|
| 72 |
+
"\n",
|
| 73 |
+
" for i in range(test_df.shape[0]):\n",
|
| 74 |
+
" prompt_end = format_example(test_df, i, subject, include_answer=False)\n",
|
| 75 |
+
" prompt = gen_prompt(dev_df=dev_df,\n",
|
| 76 |
+
" subject=subject,\n",
|
| 77 |
+
" prompt_end=prompt_end,\n",
|
| 78 |
+
" num_few_shot=num_few_shot,\n",
|
| 79 |
+
" tokenizer=tokenizer,\n",
|
| 80 |
+
" max_length=max_length)\n",
|
| 81 |
+
" inputs = tokenizer([prompt])\n",
|
| 82 |
+
" if \"token_type_ids\" in inputs: # For Falcon\n",
|
| 83 |
+
" inputs.pop(\"token_type_ids\")\n",
|
| 84 |
+
" label = test_df.iloc[i, test_df.shape[1] - 1]\n",
|
| 85 |
+
" torch.cuda.empty_cache()\n",
|
| 86 |
+
" \n",
|
| 87 |
+
" input_ids, attention_mask = torch.LongTensor(inputs['input_ids']), torch.LongTensor(inputs['attention_mask'])\n",
|
| 88 |
+
" \n",
|
| 89 |
+
" with torch.no_grad():\n",
|
| 90 |
+
" outputs = model.generate(\n",
|
| 91 |
+
" input_ids=input_ids.to(device),\n",
|
| 92 |
+
" attention_mask=attention_mask.to(device),\n",
|
| 93 |
+
" generation_config=generation_config,\n",
|
| 94 |
+
" return_dict_in_generate=True,\n",
|
| 95 |
+
" output_scores=True,\n",
|
| 96 |
+
" )\n",
|
| 97 |
+
" \n",
|
| 98 |
+
" scores = torch.stack(outputs['scores'], dim=1).to('cpu')\n",
|
| 99 |
+
" scores = torch.softmax(scores, dim=2)\n",
|
| 100 |
+
" scores = scores[..., 0, choices_ids] #取第一个字符的ABCD概率\n",
|
| 101 |
+
" conf = scores[0][choices.index(label)]\n",
|
| 102 |
+
" choices_index = torch.argmax(scores)\n",
|
| 103 |
+
" \n",
|
| 104 |
+
" pred = choices[choices_index]\n",
|
| 105 |
+
"\n",
|
| 106 |
+
" all_preds += pred\n",
|
| 107 |
+
" all_conf.append(conf)\n",
|
| 108 |
+
" cors.append(pred == label)\n",
|
| 109 |
+
"\n",
|
| 110 |
+
" acc = np.mean(cors)\n",
|
| 111 |
+
" print(\"Average accuracy {:.3f} - {}\".format(acc, subject))\n",
|
| 112 |
+
" return acc, all_preds, conf"
|
| 113 |
+
]
|
| 114 |
+
},
|
| 115 |
+
{
|
| 116 |
+
"cell_type": "code",
|
| 117 |
+
"execution_count": 4,
|
| 118 |
+
"metadata": {},
|
| 119 |
+
"outputs": [
|
| 120 |
+
{
|
| 121 |
+
"name": "stdout",
|
| 122 |
+
"output_type": "stream",
|
| 123 |
+
"text": [
|
| 124 |
+
"Average accuracy 0.243 - agronomy\n",
|
| 125 |
+
"Average accuracy 0.243 - anatomy\n",
|
| 126 |
+
"Average accuracy 0.256 - ancient_chinese\n",
|
| 127 |
+
"Average accuracy 0.256 - arts\n",
|
| 128 |
+
"Average accuracy 0.248 - astronomy\n",
|
| 129 |
+
"Average accuracy 0.234 - business_ethics\n",
|
| 130 |
+
"Average accuracy 0.256 - chinese_civil_service_exam\n",
|
| 131 |
+
"Average accuracy 0.260 - chinese_driving_rule\n",
|
| 132 |
+
"Average accuracy 0.235 - chinese_food_culture\n",
|
| 133 |
+
"Average accuracy 0.252 - chinese_foreign_policy\n",
|
| 134 |
+
"Average accuracy 0.251 - chinese_history\n",
|
| 135 |
+
"Average accuracy 0.250 - chinese_literature\n",
|
| 136 |
+
"Average accuracy 0.246 - chinese_teacher_qualification\n",
|
| 137 |
+
"Average accuracy 0.253 - clinical_knowledge\n",
|
| 138 |
+
"Average accuracy 0.245 - college_actuarial_science\n",
|
| 139 |
+
"Average accuracy 0.318 - college_education\n",
|
| 140 |
+
"Average accuracy 0.302 - college_engineering_hydrology\n",
|
| 141 |
+
"Average accuracy 0.213 - college_law\n",
|
| 142 |
+
"Average accuracy 0.219 - college_mathematics\n",
|
| 143 |
+
"Average accuracy 0.264 - college_medical_statistics\n",
|
| 144 |
+
"Average accuracy 0.234 - college_medicine\n",
|
| 145 |
+
"Average accuracy 0.240 - computer_science\n",
|
| 146 |
+
"Average accuracy 0.263 - computer_security\n",
|
| 147 |
+
"Average accuracy 0.252 - conceptual_physics\n",
|
| 148 |
+
"Average accuracy 0.252 - construction_project_management\n",
|
| 149 |
+
"Average accuracy 0.239 - economics\n",
|
| 150 |
+
"Average accuracy 0.258 - education\n",
|
| 151 |
+
"Average accuracy 0.250 - electrical_engineering\n",
|
| 152 |
+
"Average accuracy 0.282 - elementary_chinese\n",
|
| 153 |
+
"Average accuracy 0.242 - elementary_commonsense\n",
|
| 154 |
+
"Average accuracy 0.282 - elementary_information_and_technology\n",
|
| 155 |
+
"Average accuracy 0.283 - elementary_mathematics\n",
|
| 156 |
+
"Average accuracy 0.252 - ethnology\n",
|
| 157 |
+
"Average accuracy 0.252 - food_science\n",
|
| 158 |
+
"Average accuracy 0.239 - genetics\n",
|
| 159 |
+
"Average accuracy 0.242 - global_facts\n",
|
| 160 |
+
"Average accuracy 0.272 - high_school_biology\n",
|
| 161 |
+
"Average accuracy 0.235 - high_school_chemistry\n",
|
| 162 |
+
"Average accuracy 0.271 - high_school_geography\n",
|
| 163 |
+
"Average accuracy 0.250 - high_school_mathematics\n",
|
| 164 |
+
"Average accuracy 0.255 - high_school_physics\n",
|
| 165 |
+
"Average accuracy 0.252 - high_school_politics\n",
|
| 166 |
+
"Average accuracy 0.254 - human_sexuality\n",
|
| 167 |
+
"Average accuracy 0.249 - international_law\n",
|
| 168 |
+
"Average accuracy 0.250 - journalism\n",
|
| 169 |
+
"Average accuracy 0.253 - jurisprudence\n",
|
| 170 |
+
"Average accuracy 0.252 - legal_and_moral_basis\n",
|
| 171 |
+
"Average accuracy 0.252 - logical\n",
|
| 172 |
+
"Average accuracy 0.238 - machine_learning\n",
|
| 173 |
+
"Average accuracy 0.243 - management\n",
|
| 174 |
+
"Average accuracy 0.250 - marketing\n",
|
| 175 |
+
"Average accuracy 0.249 - marxist_theory\n",
|
| 176 |
+
"Average accuracy 0.250 - modern_chinese\n",
|
| 177 |
+
"Average accuracy 0.241 - nutrition\n",
|
| 178 |
+
"Average accuracy 0.257 - philosophy\n",
|
| 179 |
+
"Average accuracy 0.251 - professional_accounting\n",
|
| 180 |
+
"Average accuracy 0.251 - professional_law\n",
|
| 181 |
+
"Average accuracy 0.242 - professional_medicine\n",
|
| 182 |
+
"Average accuracy 0.246 - professional_psychology\n",
|
| 183 |
+
"Average accuracy 0.247 - public_relations\n",
|
| 184 |
+
"Average accuracy 0.252 - security_study\n",
|
| 185 |
+
"Average accuracy 0.252 - sociology\n",
|
| 186 |
+
"Average accuracy 0.248 - sports_science\n",
|
| 187 |
+
"Average accuracy 0.254 - traditional_chinese_medicine\n",
|
| 188 |
+
"Average accuracy 0.243 - virology\n",
|
| 189 |
+
"Average accuracy 0.242 - world_history\n",
|
| 190 |
+
"Average accuracy 0.256 - world_religions\n",
|
| 191 |
+
"STEM 25.16\n",
|
| 192 |
+
"Humanities 24.78\n",
|
| 193 |
+
"Social Science 25.42\n",
|
| 194 |
+
"Other 25.15\n",
|
| 195 |
+
"China specific 25.26\n",
|
| 196 |
+
"Overall 25.17\n"
|
| 197 |
+
]
|
| 198 |
+
}
|
| 199 |
+
],
|
| 200 |
+
"source": [
|
| 201 |
+
"from dataclasses import dataclass\n",
|
| 202 |
+
"@dataclass\n",
|
| 203 |
+
"class Args:\n",
|
| 204 |
+
" data_dir: str = './CMMLU/data'\n",
|
| 205 |
+
" save_dir: str = './result'\n",
|
| 206 |
+
" num_few_shot: int = 0\n",
|
| 207 |
+
" max_length: int = 512\n",
|
| 208 |
+
"\n",
|
| 209 |
+
"run_eval(model, tokenizer, eval, Args())"
|
| 210 |
+
]
|
| 211 |
+
},
|
| 212 |
+
{
|
| 213 |
+
"cell_type": "code",
|
| 214 |
+
"execution_count": null,
|
| 215 |
+
"metadata": {},
|
| 216 |
+
"outputs": [],
|
| 217 |
+
"source": []
|
| 218 |
+
}
|
| 219 |
+
],
|
| 220 |
+
"metadata": {
|
| 221 |
+
"kernelspec": {
|
| 222 |
+
"display_name": "py310",
|
| 223 |
+
"language": "python",
|
| 224 |
+
"name": "python3"
|
| 225 |
+
},
|
| 226 |
+
"language_info": {
|
| 227 |
+
"codemirror_mode": {
|
| 228 |
+
"name": "ipython",
|
| 229 |
+
"version": 3
|
| 230 |
+
},
|
| 231 |
+
"file_extension": ".py",
|
| 232 |
+
"mimetype": "text/x-python",
|
| 233 |
+
"name": "python",
|
| 234 |
+
"nbconvert_exporter": "python",
|
| 235 |
+
"pygments_lexer": "ipython3",
|
| 236 |
+
"version": "3.10.12"
|
| 237 |
+
}
|
| 238 |
+
},
|
| 239 |
+
"nbformat": 4,
|
| 240 |
+
"nbformat_minor": 2
|
| 241 |
+
}
|
finetune_examples/.gitignore
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
data
|
| 2 |
+
model_save
|
| 3 |
+
logs
|
finetune_examples/info_extract/data_process.py
ADDED
|
@@ -0,0 +1,146 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ujson
|
| 2 |
+
import codecs
|
| 3 |
+
import re
|
| 4 |
+
from rich import progress
|
| 5 |
+
import numpy as np
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def process_all_50_schemas(raw_schemas_file: str='./data/all_50_schemas', save_schemas_file: str=None) -> list[str]:
|
| 9 |
+
'''
|
| 10 |
+
获取prompt的关系列表
|
| 11 |
+
'''
|
| 12 |
+
lines = []
|
| 13 |
+
with codecs.open(raw_schemas_file, 'r', encoding='utf-8') as f:
|
| 14 |
+
lines = f.readlines()
|
| 15 |
+
|
| 16 |
+
scheme_list = []
|
| 17 |
+
for line in lines:
|
| 18 |
+
item = ujson.loads(line)
|
| 19 |
+
scheme_list.append(
|
| 20 |
+
item['predicate']
|
| 21 |
+
)
|
| 22 |
+
|
| 23 |
+
scheme_list = list(set(scheme_list))
|
| 24 |
+
|
| 25 |
+
if save_schemas_file:
|
| 26 |
+
with codecs.open(save_schemas_file, 'w', encoding='utf-8') as f:
|
| 27 |
+
ujson.dump(f"{scheme_list}", f, indent=4, ensure_ascii=False)
|
| 28 |
+
|
| 29 |
+
return scheme_list
|
| 30 |
+
|
| 31 |
+
def process_spo_list(text: str, spo_list: list, repair_song: bool=False):
|
| 32 |
+
'''
|
| 33 |
+
处理spo_list,处理成{subject: 'subject', subject_start: 0, subject_end:3, predicate: 'predicate', object: 'object', object_start: 5, object_end = 7}
|
| 34 |
+
'''
|
| 35 |
+
new_spo_list = []
|
| 36 |
+
|
| 37 |
+
# 找出所有用书名号隔开的名字
|
| 38 |
+
some_name = re.findall('《([^《》]*?)》', text)
|
| 39 |
+
some_name = [n.strip() for n in some_name]
|
| 40 |
+
|
| 41 |
+
# 歌曲和专辑
|
| 42 |
+
song = []
|
| 43 |
+
album = []
|
| 44 |
+
for spo in spo_list:
|
| 45 |
+
|
| 46 |
+
# 修正so的错误,删除前后的书名号
|
| 47 |
+
s = spo['subject'].strip('《》').strip().lower()
|
| 48 |
+
o = spo['object'].strip('《》').strip().lower()
|
| 49 |
+
p = spo['predicate']
|
| 50 |
+
|
| 51 |
+
# 如果s在找到的名字中,以正则找到的s为准,用in判等,
|
| 52 |
+
# 如text: '《造梦者---dreamer》',但是标注的s是'造梦者'
|
| 53 |
+
for name in some_name:
|
| 54 |
+
if s in name and text.count(s) == 1:
|
| 55 |
+
s = name
|
| 56 |
+
|
| 57 |
+
if repair_song:
|
| 58 |
+
if p == '所属专辑':
|
| 59 |
+
song.append(s)
|
| 60 |
+
album.append(o)
|
| 61 |
+
|
| 62 |
+
temp = dict()
|
| 63 |
+
temp['s'] = s
|
| 64 |
+
temp['p'] = spo['predicate']
|
| 65 |
+
temp['o'] = o
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
# 在text中找不到subject 或者 object,不要这条数据了
|
| 69 |
+
if text.find(s) == -1 or text.find(o) == -1:
|
| 70 |
+
continue
|
| 71 |
+
|
| 72 |
+
new_spo_list.append(temp)
|
| 73 |
+
|
| 74 |
+
if repair_song:
|
| 75 |
+
ret_spo_list = []
|
| 76 |
+
ps = ['歌手', '作词', '作曲']
|
| 77 |
+
|
| 78 |
+
for spo in new_spo_list:
|
| 79 |
+
s, p, o = spo['s'], spo['p'], spo['o']
|
| 80 |
+
if p in ps and s in album and s not in song:
|
| 81 |
+
continue
|
| 82 |
+
ret_spo_list.append(spo)
|
| 83 |
+
|
| 84 |
+
return ret_spo_list
|
| 85 |
+
|
| 86 |
+
return new_spo_list
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def process_data(raw_data_file: str, train_file_name: str, dev_file_name: str, keep_max_length: int=512, repair_song: bool=True, dev_size: int=1000) -> None:
|
| 90 |
+
'''
|
| 91 |
+
将原始的格式处理为prompt:resopnse的格式
|
| 92 |
+
'''
|
| 93 |
+
lines = []
|
| 94 |
+
with codecs.open(raw_data_file, 'r', encoding='utf-8') as f:
|
| 95 |
+
lines = f.readlines()
|
| 96 |
+
my_raw_data = []
|
| 97 |
+
|
| 98 |
+
schemas = process_all_50_schemas('./data/all_50_schemas')
|
| 99 |
+
schemas = f"[{','.join(schemas)}]"
|
| 100 |
+
for i, line in progress.track(enumerate(lines), total=len(lines)):
|
| 101 |
+
|
| 102 |
+
tmp = ujson.decode(line)
|
| 103 |
+
text = f"请抽取出给定句子中的所有三元组。给定句子:{tmp['text'].lower()}"
|
| 104 |
+
|
| 105 |
+
spo_list = process_spo_list(tmp['text'].lower(), tmp['spo_list'], repair_song=repair_song)
|
| 106 |
+
spo = f"{[(item['s'], item['p'], item['o']) for item in spo_list]}"
|
| 107 |
+
# 删除长度过长、没有找到实体信息的句子
|
| 108 |
+
if len(text) > keep_max_length or len(spo) > keep_max_length or len(spo_list) == 0:
|
| 109 |
+
continue
|
| 110 |
+
|
| 111 |
+
my_raw_data.append({
|
| 112 |
+
'prompt': text,
|
| 113 |
+
'response':spo.replace('\'','').replace(' ', ''),
|
| 114 |
+
})
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
dev_date = []
|
| 118 |
+
if dev_file_name is not None:
|
| 119 |
+
dev_index = np.random.choice(range(0, len(my_raw_data)), size=dev_size, replace=False)
|
| 120 |
+
dev_index = set(dev_index)
|
| 121 |
+
assert len(dev_index) == dev_size
|
| 122 |
+
|
| 123 |
+
train_data = [x for i, x in enumerate(my_raw_data) if i not in dev_index]
|
| 124 |
+
dev_date = [x for i, x in enumerate(my_raw_data) if i in dev_index]
|
| 125 |
+
|
| 126 |
+
with codecs.open(dev_file_name, 'w', encoding='utf-8') as f:
|
| 127 |
+
ujson.dump(dev_date, f, indent=4, ensure_ascii=False)
|
| 128 |
+
|
| 129 |
+
my_raw_data = train_data
|
| 130 |
+
|
| 131 |
+
print(f'length of train data {len(my_raw_data)}, length of eval data {len(dev_date)}')
|
| 132 |
+
|
| 133 |
+
with codecs.open(train_file_name, 'w', encoding='utf-8') as f:
|
| 134 |
+
ujson.dump(my_raw_data, f, indent=4, ensure_ascii=False)
|
| 135 |
+
|
| 136 |
+
if __name__ == '__main__':
|
| 137 |
+
raw_data_file = './data/train_data.json'
|
| 138 |
+
train_file = './data/my_train.json'
|
| 139 |
+
dev_file = './data/my_eval.json'
|
| 140 |
+
|
| 141 |
+
process_all_50_schemas('./data/all_50_schemas', './data/my_schemas.txt')
|
| 142 |
+
|
| 143 |
+
process_data(raw_data_file, train_file, dev_file, keep_max_length=512, dev_size=1000)
|
| 144 |
+
|
| 145 |
+
# 使用该数据集公开的dev_data作为测试集
|
| 146 |
+
process_data('./data/dev_data.json', train_file_name='./data/test.json', dev_file_name=None, keep_max_length=512, dev_size=1000)
|
finetune_examples/info_extract/finetune_IE_task.ipynb
ADDED
|
@@ -0,0 +1,463 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 1,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [],
|
| 8 |
+
"source": [
|
| 9 |
+
"# coding=utf-8\n",
|
| 10 |
+
"from typing import Dict\n",
|
| 11 |
+
"import time \n",
|
| 12 |
+
"import pandas as pd \n",
|
| 13 |
+
"\n",
|
| 14 |
+
"import torch\n",
|
| 15 |
+
"from datasets import Dataset, load_dataset\n",
|
| 16 |
+
"from transformers import PreTrainedTokenizerFast, Seq2SeqTrainer, DataCollatorForSeq2Seq,Seq2SeqTrainingArguments\n",
|
| 17 |
+
"from transformers.generation.configuration_utils import GenerationConfig"
|
| 18 |
+
]
|
| 19 |
+
},
|
| 20 |
+
{
|
| 21 |
+
"cell_type": "code",
|
| 22 |
+
"execution_count": 2,
|
| 23 |
+
"metadata": {},
|
| 24 |
+
"outputs": [],
|
| 25 |
+
"source": [
|
| 26 |
+
"import sys, os\n",
|
| 27 |
+
"root = os.path.realpath('.').replace('\\\\','/').split('/')[0: -2]\n",
|
| 28 |
+
"root = '/'.join(root)\n",
|
| 29 |
+
"if root not in sys.path:\n",
|
| 30 |
+
" sys.path.append(root)\n",
|
| 31 |
+
"\n",
|
| 32 |
+
"from model.chat_model import TextToTextModel\n",
|
| 33 |
+
"from config import SFTconfig, InferConfig, T5ModelConfig\n",
|
| 34 |
+
"from utils.functions import get_T5_config\n",
|
| 35 |
+
"\n",
|
| 36 |
+
"os.environ['TF_ENABLE_ONEDNN_OPTS'] = '0'"
|
| 37 |
+
]
|
| 38 |
+
},
|
| 39 |
+
{
|
| 40 |
+
"cell_type": "code",
|
| 41 |
+
"execution_count": 3,
|
| 42 |
+
"metadata": {},
|
| 43 |
+
"outputs": [],
|
| 44 |
+
"source": [
|
| 45 |
+
"def get_dataset(file: str, split: str, encode_fn: callable, encode_args: dict, cache_dir: str='.cache') -> Dataset:\n",
|
| 46 |
+
" \"\"\"\n",
|
| 47 |
+
" Load a dataset\n",
|
| 48 |
+
" \"\"\"\n",
|
| 49 |
+
" dataset = load_dataset('json', data_files=file, split=split, cache_dir=cache_dir)\n",
|
| 50 |
+
"\n",
|
| 51 |
+
" def merge_prompt_and_responses(sample: dict) -> Dict[str, str]:\n",
|
| 52 |
+
" # add an eos token note that end of sentence, using in generate.\n",
|
| 53 |
+
" prompt = encode_fn(f\"{sample['prompt']}[EOS]\", **encode_args)\n",
|
| 54 |
+
" response = encode_fn(f\"{sample['response']}[EOS]\", **encode_args)\n",
|
| 55 |
+
" return {\n",
|
| 56 |
+
" 'input_ids': prompt.input_ids,\n",
|
| 57 |
+
" 'labels': response.input_ids,\n",
|
| 58 |
+
" }\n",
|
| 59 |
+
"\n",
|
| 60 |
+
" dataset = dataset.map(merge_prompt_and_responses)\n",
|
| 61 |
+
" return dataset"
|
| 62 |
+
]
|
| 63 |
+
},
|
| 64 |
+
{
|
| 65 |
+
"cell_type": "code",
|
| 66 |
+
"execution_count": 4,
|
| 67 |
+
"metadata": {},
|
| 68 |
+
"outputs": [],
|
| 69 |
+
"source": [
|
| 70 |
+
"def sft_train(config: SFTconfig) -> None:\n",
|
| 71 |
+
"\n",
|
| 72 |
+
" # step 1. 加载tokenizer\n",
|
| 73 |
+
" tokenizer = PreTrainedTokenizerFast.from_pretrained(config.tokenizer_dir)\n",
|
| 74 |
+
" \n",
|
| 75 |
+
" # step 2. 加载预训练模型\n",
|
| 76 |
+
" model = None\n",
|
| 77 |
+
" if os.path.isdir(config.finetune_from_ckp_file):\n",
|
| 78 |
+
" # 传入文件夹则 from_pretrained\n",
|
| 79 |
+
" model = TextToTextModel.from_pretrained(config.finetune_from_ckp_file)\n",
|
| 80 |
+
" else:\n",
|
| 81 |
+
" # load_state_dict\n",
|
| 82 |
+
" t5_config = get_T5_config(T5ModelConfig(), vocab_size=len(tokenizer), decoder_start_token_id=tokenizer.pad_token_id, eos_token_id=tokenizer.eos_token_id)\n",
|
| 83 |
+
" model = TextToTextModel(t5_config)\n",
|
| 84 |
+
" model.load_state_dict(torch.load(config.finetune_from_ckp_file, map_location='cpu')) # set cpu for no exception\n",
|
| 85 |
+
" \n",
|
| 86 |
+
" # Step 4: Load the dataset\n",
|
| 87 |
+
" encode_args = {\n",
|
| 88 |
+
" 'truncation': False,\n",
|
| 89 |
+
" 'padding': 'max_length',\n",
|
| 90 |
+
" }\n",
|
| 91 |
+
"\n",
|
| 92 |
+
" dataset = get_dataset(file=config.sft_train_file, encode_fn=tokenizer.encode_plus, encode_args=encode_args, split=\"train\")\n",
|
| 93 |
+
"\n",
|
| 94 |
+
" # Step 5: Define the training arguments\n",
|
| 95 |
+
" # T5属于sequence to sequence模型,故要使用Seq2SeqTrainingArguments、DataCollatorForSeq2Seq、Seq2SeqTrainer\n",
|
| 96 |
+
" # huggingface官网的sft工具适用于language model/LM模型\n",
|
| 97 |
+
" generation_config = GenerationConfig()\n",
|
| 98 |
+
" generation_config.remove_invalid_values = True\n",
|
| 99 |
+
" generation_config.eos_token_id = tokenizer.eos_token_id\n",
|
| 100 |
+
" generation_config.pad_token_id = tokenizer.pad_token_id\n",
|
| 101 |
+
" generation_config.decoder_start_token_id = tokenizer.pad_token_id\n",
|
| 102 |
+
" generation_config.max_new_tokens = 320\n",
|
| 103 |
+
" generation_config.repetition_penalty = 1.5\n",
|
| 104 |
+
" generation_config.num_beams = 1 # greedy search\n",
|
| 105 |
+
" generation_config.do_sample = False # greedy search\n",
|
| 106 |
+
"\n",
|
| 107 |
+
" training_args = Seq2SeqTrainingArguments(\n",
|
| 108 |
+
" output_dir=config.output_dir,\n",
|
| 109 |
+
" per_device_train_batch_size=config.batch_size,\n",
|
| 110 |
+
" auto_find_batch_size=True, # 防止OOM\n",
|
| 111 |
+
" gradient_accumulation_steps=config.gradient_accumulation_steps,\n",
|
| 112 |
+
" learning_rate=config.learning_rate,\n",
|
| 113 |
+
" logging_steps=config.logging_steps,\n",
|
| 114 |
+
" num_train_epochs=config.num_train_epochs,\n",
|
| 115 |
+
" optim=\"adafactor\",\n",
|
| 116 |
+
" report_to='tensorboard',\n",
|
| 117 |
+
" log_level='info',\n",
|
| 118 |
+
" save_steps=config.save_steps,\n",
|
| 119 |
+
" save_total_limit=3,\n",
|
| 120 |
+
" fp16=config.fp16,\n",
|
| 121 |
+
" logging_first_step=config.logging_first_step,\n",
|
| 122 |
+
" warmup_steps=config.warmup_steps,\n",
|
| 123 |
+
" seed=config.seed,\n",
|
| 124 |
+
" generation_config=generation_config,\n",
|
| 125 |
+
" )\n",
|
| 126 |
+
"\n",
|
| 127 |
+
" # step 6: init a collator\n",
|
| 128 |
+
" collator = DataCollatorForSeq2Seq(tokenizer, max_length=config.max_seq_len)\n",
|
| 129 |
+
" \n",
|
| 130 |
+
" # Step 7: Define the Trainer\n",
|
| 131 |
+
" trainer = Seq2SeqTrainer(\n",
|
| 132 |
+
" model=model,\n",
|
| 133 |
+
" args=training_args,\n",
|
| 134 |
+
" train_dataset=dataset,\n",
|
| 135 |
+
" eval_dataset=dataset,\n",
|
| 136 |
+
" tokenizer=tokenizer,\n",
|
| 137 |
+
" data_collator=collator,\n",
|
| 138 |
+
" )\n",
|
| 139 |
+
"\n",
|
| 140 |
+
" # step 8: train\n",
|
| 141 |
+
" trainer.train(\n",
|
| 142 |
+
" # resume_from_checkpoint=True\n",
|
| 143 |
+
" )\n",
|
| 144 |
+
"\n",
|
| 145 |
+
" loss_log = pd.DataFrame(trainer.state.log_history)\n",
|
| 146 |
+
" log_dir = './logs'\n",
|
| 147 |
+
" if not os.path.exists(log_dir):\n",
|
| 148 |
+
" os.mkdir(log_dir)\n",
|
| 149 |
+
" loss_log.to_csv(f\"{log_dir}/ie_task_finetune_log_{time.strftime('%Y%m%d-%H%M')}.csv\")\n",
|
| 150 |
+
"\n",
|
| 151 |
+
" # Step 9: Save the model\n",
|
| 152 |
+
" trainer.save_model(config.output_dir)\n",
|
| 153 |
+
"\n",
|
| 154 |
+
" return trainer\n",
|
| 155 |
+
" "
|
| 156 |
+
]
|
| 157 |
+
},
|
| 158 |
+
{
|
| 159 |
+
"cell_type": "code",
|
| 160 |
+
"execution_count": null,
|
| 161 |
+
"metadata": {},
|
| 162 |
+
"outputs": [],
|
| 163 |
+
"source": [
|
| 164 |
+
"config = SFTconfig()\n",
|
| 165 |
+
"config.finetune_from_ckp_file = InferConfig().model_dir\n",
|
| 166 |
+
"config.sft_train_file = './data/my_train.json'\n",
|
| 167 |
+
"config.output_dir = './model_save/ie_task'\n",
|
| 168 |
+
"config.max_seq_len = 512\n",
|
| 169 |
+
"config.batch_size = 16\n",
|
| 170 |
+
"config.gradient_accumulation_steps = 4\n",
|
| 171 |
+
"config.logging_steps = 20\n",
|
| 172 |
+
"config.learning_rate = 5e-5\n",
|
| 173 |
+
"config.num_train_epochs = 6\n",
|
| 174 |
+
"config.save_steps = 3000\n",
|
| 175 |
+
"config.warmup_steps = 1000\n",
|
| 176 |
+
"print(config)"
|
| 177 |
+
]
|
| 178 |
+
},
|
| 179 |
+
{
|
| 180 |
+
"cell_type": "code",
|
| 181 |
+
"execution_count": null,
|
| 182 |
+
"metadata": {},
|
| 183 |
+
"outputs": [],
|
| 184 |
+
"source": [
|
| 185 |
+
"trainer = sft_train(config)"
|
| 186 |
+
]
|
| 187 |
+
},
|
| 188 |
+
{
|
| 189 |
+
"cell_type": "code",
|
| 190 |
+
"execution_count": 1,
|
| 191 |
+
"metadata": {},
|
| 192 |
+
"outputs": [],
|
| 193 |
+
"source": [
|
| 194 |
+
"import sys, os\n",
|
| 195 |
+
"root = os.path.realpath('.').replace('\\\\','/').split('/')[0: -2]\n",
|
| 196 |
+
"root = '/'.join(root)\n",
|
| 197 |
+
"if root not in sys.path:\n",
|
| 198 |
+
" sys.path.append(root)\n",
|
| 199 |
+
"import ujson, torch\n",
|
| 200 |
+
"from rich import progress\n",
|
| 201 |
+
"\n",
|
| 202 |
+
"from model.infer import ChatBot\n",
|
| 203 |
+
"from config import InferConfig\n",
|
| 204 |
+
"from utils.functions import f1_p_r_compute\n",
|
| 205 |
+
"inf_conf = InferConfig()\n",
|
| 206 |
+
"inf_conf.model_dir = './model_save/ie_task/'\n",
|
| 207 |
+
"bot = ChatBot(infer_config=inf_conf)\n"
|
| 208 |
+
]
|
| 209 |
+
},
|
| 210 |
+
{
|
| 211 |
+
"cell_type": "code",
|
| 212 |
+
"execution_count": 2,
|
| 213 |
+
"metadata": {},
|
| 214 |
+
"outputs": [
|
| 215 |
+
{
|
| 216 |
+
"name": "stdout",
|
| 217 |
+
"output_type": "stream",
|
| 218 |
+
"text": [
|
| 219 |
+
"[(傅淑云,民族,汉族),(傅淑云,出生地,上海),(傅淑云,出生日期,1915年)]\n"
|
| 220 |
+
]
|
| 221 |
+
}
|
| 222 |
+
],
|
| 223 |
+
"source": [
|
| 224 |
+
"ret = bot.chat('请抽取出给定句子中的所有三元组。给定句子:傅淑云,女,汉族,1915年出生,上海人')\n",
|
| 225 |
+
"print(ret)"
|
| 226 |
+
]
|
| 227 |
+
},
|
| 228 |
+
{
|
| 229 |
+
"cell_type": "code",
|
| 230 |
+
"execution_count": 3,
|
| 231 |
+
"metadata": {},
|
| 232 |
+
"outputs": [
|
| 233 |
+
{
|
| 234 |
+
"name": "stdout",
|
| 235 |
+
"output_type": "stream",
|
| 236 |
+
"text": [
|
| 237 |
+
"[('傅淑云', '民族', '汉族'), ('傅淑云', '出生地', '上海'), ('傅淑云', '出生日期', '1915年')]\n"
|
| 238 |
+
]
|
| 239 |
+
}
|
| 240 |
+
],
|
| 241 |
+
"source": [
|
| 242 |
+
"def text_to_spo_list(sentence: str) -> str:\n",
|
| 243 |
+
" '''\n",
|
| 244 |
+
" 将输出转换为SPO列表,时间复杂度: O(n)\n",
|
| 245 |
+
" '''\n",
|
| 246 |
+
" spo_list = []\n",
|
| 247 |
+
" sentence = sentence.replace(',',',').replace('(','(').replace(')', ')') # 符号标准化\n",
|
| 248 |
+
"\n",
|
| 249 |
+
" cur_txt, cur_spo, started = '', [], False\n",
|
| 250 |
+
" for i, char in enumerate(sentence):\n",
|
| 251 |
+
" if char not in '[](),':\n",
|
| 252 |
+
" cur_txt += char\n",
|
| 253 |
+
" elif char == '(':\n",
|
| 254 |
+
" started = True\n",
|
| 255 |
+
" cur_txt, cur_spo = '' , []\n",
|
| 256 |
+
" elif char == ',' and started and len(cur_txt) > 0 and len(cur_spo) < 3:\n",
|
| 257 |
+
" cur_spo.append(cur_txt)\n",
|
| 258 |
+
" cur_txt = ''\n",
|
| 259 |
+
" elif char == ')' and started and len(cur_txt) > 0 and len(cur_spo) == 2:\n",
|
| 260 |
+
" cur_spo.append(cur_txt)\n",
|
| 261 |
+
" spo_list.append(tuple(cur_spo))\n",
|
| 262 |
+
" cur_spo = []\n",
|
| 263 |
+
" cur_txt = ''\n",
|
| 264 |
+
" started = False\n",
|
| 265 |
+
" return spo_list\n",
|
| 266 |
+
"print(text_to_spo_list(ret))"
|
| 267 |
+
]
|
| 268 |
+
},
|
| 269 |
+
{
|
| 270 |
+
"cell_type": "code",
|
| 271 |
+
"execution_count": 4,
|
| 272 |
+
"metadata": {},
|
| 273 |
+
"outputs": [],
|
| 274 |
+
"source": [
|
| 275 |
+
"test_data = []\n",
|
| 276 |
+
"with open('./data/test.json', 'r', encoding='utf-8') as f:\n",
|
| 277 |
+
" test_data = ujson.load(f)"
|
| 278 |
+
]
|
| 279 |
+
},
|
| 280 |
+
{
|
| 281 |
+
"cell_type": "code",
|
| 282 |
+
"execution_count": 5,
|
| 283 |
+
"metadata": {},
|
| 284 |
+
"outputs": [
|
| 285 |
+
{
|
| 286 |
+
"data": {
|
| 287 |
+
"text/plain": [
|
| 288 |
+
"[{'prompt': '请抽取出给定句子中的所有三元组。给定句子:查尔斯·阿兰基斯(charles aránguiz),1989年4月17日出生于智利圣地亚哥,智利职业足球运动员,司职中场,效力于德国足球甲级联赛勒沃库森足球俱乐部',\n",
|
| 289 |
+
" 'response': '[(查尔斯·阿兰基斯,出生地,圣地亚哥),(查尔斯·阿兰基斯,出生日期,1989年4月17日)]'},\n",
|
| 290 |
+
" {'prompt': '请抽取出给定句子中的所有三元组。给定句子:《离开》是由张宇谱曲,演唱',\n",
|
| 291 |
+
" 'response': '[(离开,歌手,张宇),(离开,作曲,张宇)]'}]"
|
| 292 |
+
]
|
| 293 |
+
},
|
| 294 |
+
"execution_count": 5,
|
| 295 |
+
"metadata": {},
|
| 296 |
+
"output_type": "execute_result"
|
| 297 |
+
}
|
| 298 |
+
],
|
| 299 |
+
"source": [
|
| 300 |
+
"test_data[0:2]"
|
| 301 |
+
]
|
| 302 |
+
},
|
| 303 |
+
{
|
| 304 |
+
"cell_type": "code",
|
| 305 |
+
"execution_count": 6,
|
| 306 |
+
"metadata": {},
|
| 307 |
+
"outputs": [
|
| 308 |
+
{
|
| 309 |
+
"data": {
|
| 310 |
+
"application/vnd.jupyter.widget-view+json": {
|
| 311 |
+
"model_id": "bca40f71fcc34dda95eb97a6f48fea0c",
|
| 312 |
+
"version_major": 2,
|
| 313 |
+
"version_minor": 0
|
| 314 |
+
},
|
| 315 |
+
"text/plain": [
|
| 316 |
+
"Output()"
|
| 317 |
+
]
|
| 318 |
+
},
|
| 319 |
+
"metadata": {},
|
| 320 |
+
"output_type": "display_data"
|
| 321 |
+
},
|
| 322 |
+
{
|
| 323 |
+
"data": {
|
| 324 |
+
"text/html": [
|
| 325 |
+
"<pre style=\"white-space:pre;overflow-x:auto;line-height:normal;font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace\"></pre>\n"
|
| 326 |
+
],
|
| 327 |
+
"text/plain": []
|
| 328 |
+
},
|
| 329 |
+
"metadata": {},
|
| 330 |
+
"output_type": "display_data"
|
| 331 |
+
},
|
| 332 |
+
{
|
| 333 |
+
"data": {
|
| 334 |
+
"text/html": [
|
| 335 |
+
"<pre style=\"white-space:pre;overflow-x:auto;line-height:normal;font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace\">\n",
|
| 336 |
+
"</pre>\n"
|
| 337 |
+
],
|
| 338 |
+
"text/plain": [
|
| 339 |
+
"\n"
|
| 340 |
+
]
|
| 341 |
+
},
|
| 342 |
+
"metadata": {},
|
| 343 |
+
"output_type": "display_data"
|
| 344 |
+
}
|
| 345 |
+
],
|
| 346 |
+
"source": [
|
| 347 |
+
"prompt_buffer, batch_size, n = [], 32, len(test_data)\n",
|
| 348 |
+
"traget_spo_list, predict_spo_list = [], []\n",
|
| 349 |
+
"for i, item in progress.track(enumerate(test_data), total=n):\n",
|
| 350 |
+
" prompt_buffer.append(item['prompt'])\n",
|
| 351 |
+
" traget_spo_list.append(\n",
|
| 352 |
+
" text_to_spo_list(item['response'])\n",
|
| 353 |
+
" )\n",
|
| 354 |
+
"\n",
|
| 355 |
+
" if len(prompt_buffer) == batch_size or i == n - 1:\n",
|
| 356 |
+
" torch.cuda.empty_cache()\n",
|
| 357 |
+
" model_pred = bot.chat(prompt_buffer)\n",
|
| 358 |
+
" model_pred = [text_to_spo_list(item) for item in model_pred]\n",
|
| 359 |
+
" predict_spo_list.extend(model_pred)\n",
|
| 360 |
+
" prompt_buffer = []"
|
| 361 |
+
]
|
| 362 |
+
},
|
| 363 |
+
{
|
| 364 |
+
"cell_type": "code",
|
| 365 |
+
"execution_count": 7,
|
| 366 |
+
"metadata": {},
|
| 367 |
+
"outputs": [
|
| 368 |
+
{
|
| 369 |
+
"name": "stdout",
|
| 370 |
+
"output_type": "stream",
|
| 371 |
+
"text": [
|
| 372 |
+
"[[('查尔斯·阿兰基斯', '出生地', '圣地亚哥'), ('查尔斯·阿兰基斯', '出生日期', '1989年4月17日')], [('离开', '歌手', '张宇'), ('离开', '作曲', '张宇')]] \n",
|
| 373 |
+
"\n",
|
| 374 |
+
"\n",
|
| 375 |
+
" [[('查尔斯·阿兰基斯', '国籍', '智利'), ('查尔斯·阿兰基斯', '出生地', '智利圣地亚哥'), ('查尔斯·阿兰基斯', '出生日期', '1989年4月17日')], [('离开', '歌手', '张宇'), ('离开', '作曲', '张宇')]]\n"
|
| 376 |
+
]
|
| 377 |
+
}
|
| 378 |
+
],
|
| 379 |
+
"source": [
|
| 380 |
+
"print(traget_spo_list[0:2], '\\n\\n\\n',predict_spo_list[0:2])"
|
| 381 |
+
]
|
| 382 |
+
},
|
| 383 |
+
{
|
| 384 |
+
"cell_type": "code",
|
| 385 |
+
"execution_count": 8,
|
| 386 |
+
"metadata": {},
|
| 387 |
+
"outputs": [
|
| 388 |
+
{
|
| 389 |
+
"name": "stdout",
|
| 390 |
+
"output_type": "stream",
|
| 391 |
+
"text": [
|
| 392 |
+
"21636 21636\n"
|
| 393 |
+
]
|
| 394 |
+
}
|
| 395 |
+
],
|
| 396 |
+
"source": [
|
| 397 |
+
"print(len(predict_spo_list), len(traget_spo_list))"
|
| 398 |
+
]
|
| 399 |
+
},
|
| 400 |
+
{
|
| 401 |
+
"cell_type": "code",
|
| 402 |
+
"execution_count": 9,
|
| 403 |
+
"metadata": {},
|
| 404 |
+
"outputs": [
|
| 405 |
+
{
|
| 406 |
+
"name": "stdout",
|
| 407 |
+
"output_type": "stream",
|
| 408 |
+
"text": [
|
| 409 |
+
"f1: 0.74, precision: 0.75, recall: 0.73\n"
|
| 410 |
+
]
|
| 411 |
+
}
|
| 412 |
+
],
|
| 413 |
+
"source": [
|
| 414 |
+
"f1, p, r = f1_p_r_compute(predict_spo_list, traget_spo_list)\n",
|
| 415 |
+
"print(f\"f1: {f1:.2f}, precision: {p:.2f}, recall: {r:.2f}\")"
|
| 416 |
+
]
|
| 417 |
+
},
|
| 418 |
+
{
|
| 419 |
+
"cell_type": "code",
|
| 420 |
+
"execution_count": 2,
|
| 421 |
+
"metadata": {},
|
| 422 |
+
"outputs": [
|
| 423 |
+
{
|
| 424 |
+
"data": {
|
| 425 |
+
"text/plain": [
|
| 426 |
+
"['你好,有什么我可以帮你的吗?',\n",
|
| 427 |
+
" '[(江苏省赣榆海洋经济开发区,成立日期,2003年1月28日)]',\n",
|
| 428 |
+
" '南方地区气候干燥,气候寒冷,冬季寒冷,夏季炎热,冬季寒冷的原因很多,可能是由于全球气候变暖导致的。\\n南方气候的变化可以引起天气的变化,例如气温下降、降雨增多、冷空气南下等。南方气候的变化可以促进气候的稳定,有利于经济发展和经济繁荣。\\n此外,南方地区的气候也可能受到自然灾害的影响,例如台风、台风、暴雨等,这些自然灾害会对南方气候产生影响。\\n总之,南方气候的变化是一个复杂的过程,需要综合考虑多方面因素,才能应对。']"
|
| 429 |
+
]
|
| 430 |
+
},
|
| 431 |
+
"execution_count": 2,
|
| 432 |
+
"metadata": {},
|
| 433 |
+
"output_type": "execute_result"
|
| 434 |
+
}
|
| 435 |
+
],
|
| 436 |
+
"source": [
|
| 437 |
+
"# 测试一下对话能力\n",
|
| 438 |
+
"bot.chat(['你好', '请抽取出给定句子中的所有三元组。给定句子:江苏省赣榆海洋经济开发区位于赣榆区青口镇临海而建,2003年1月28日,经江苏省人民政府《关于同意设立赣榆海洋经济开发区的批复》(苏政复〔2003〕14号)文件批准为全省首家省级海洋经济开发区,','如何看待最近南方天气突然变冷?'])"
|
| 439 |
+
]
|
| 440 |
+
}
|
| 441 |
+
],
|
| 442 |
+
"metadata": {
|
| 443 |
+
"kernelspec": {
|
| 444 |
+
"display_name": "py310",
|
| 445 |
+
"language": "python",
|
| 446 |
+
"name": "python3"
|
| 447 |
+
},
|
| 448 |
+
"language_info": {
|
| 449 |
+
"codemirror_mode": {
|
| 450 |
+
"name": "ipython",
|
| 451 |
+
"version": 3
|
| 452 |
+
},
|
| 453 |
+
"file_extension": ".py",
|
| 454 |
+
"mimetype": "text/x-python",
|
| 455 |
+
"name": "python",
|
| 456 |
+
"nbconvert_exporter": "python",
|
| 457 |
+
"pygments_lexer": "ipython3",
|
| 458 |
+
"version": "3.10.12"
|
| 459 |
+
}
|
| 460 |
+
},
|
| 461 |
+
"nbformat": 4,
|
| 462 |
+
"nbformat_minor": 2
|
| 463 |
+
}
|
img/api_example.png
ADDED

|
img/dpo_loss.png
ADDED

|
img/ie_task_chat.png
ADDED

|
img/sentence_length.png
ADDED
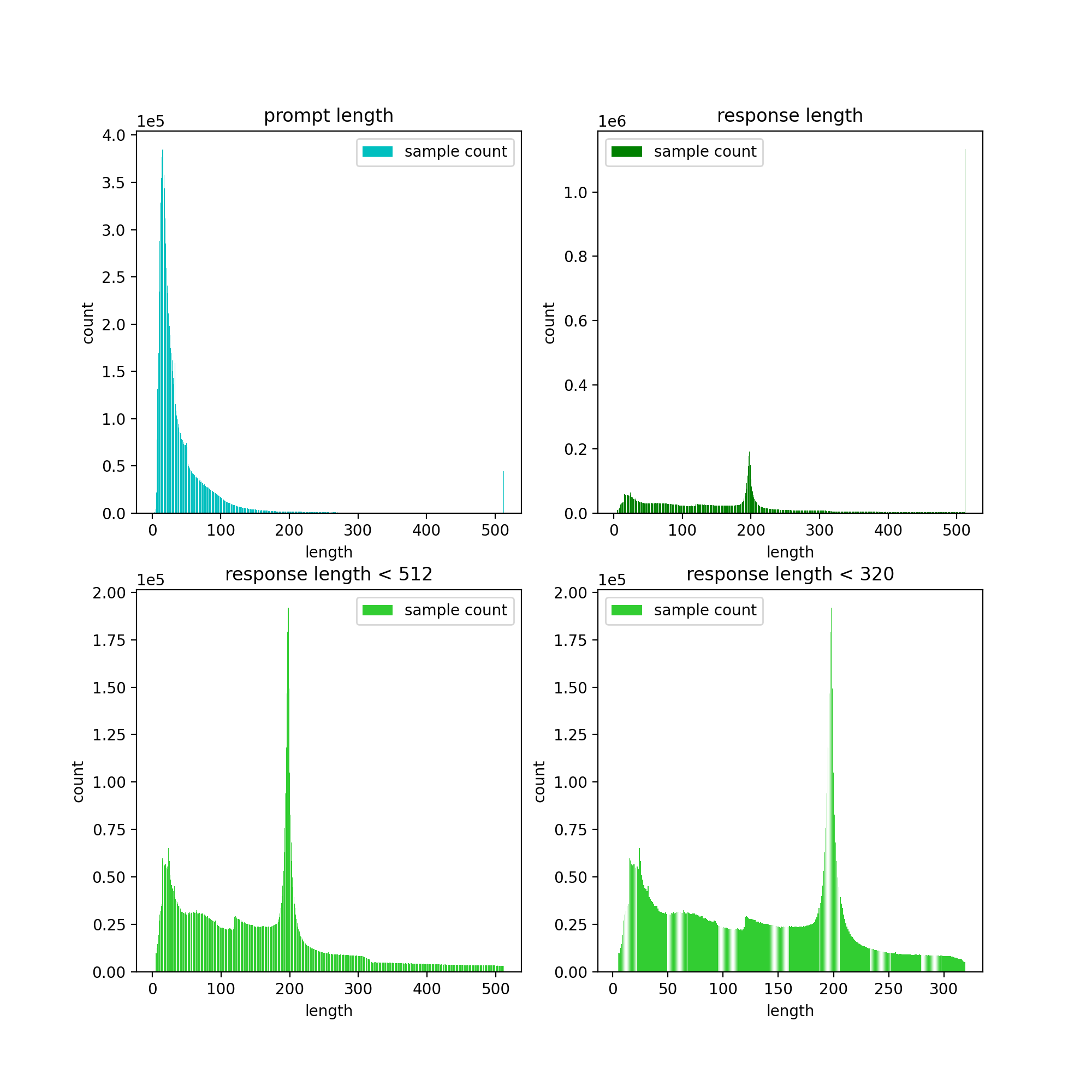
|
img/sft_loss.png
ADDED

|
img/show1.png
ADDED
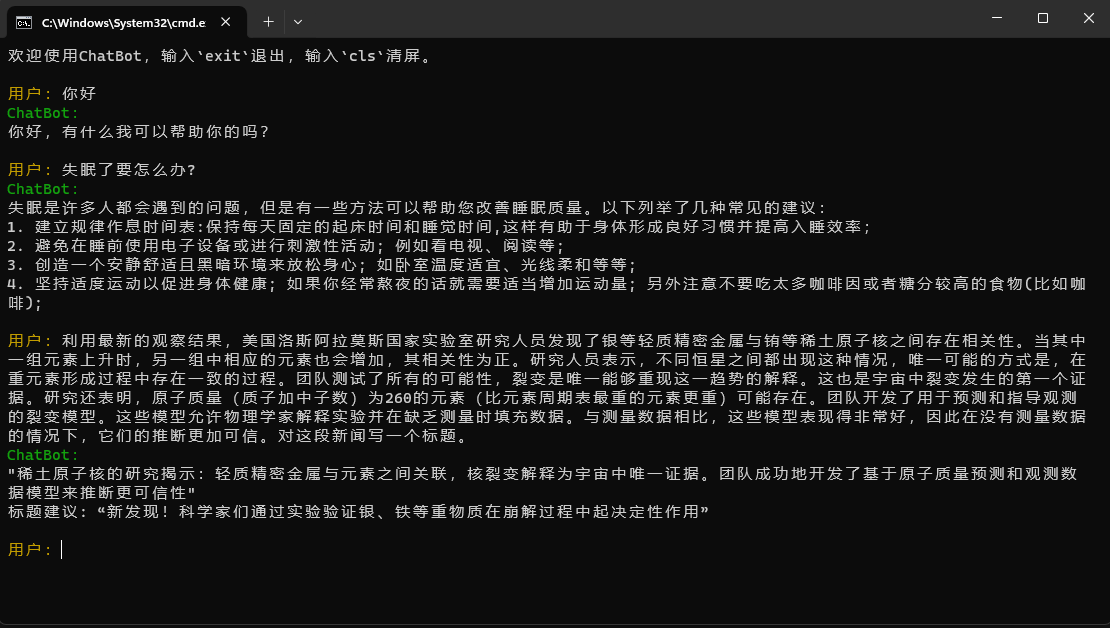
|
img/stream_chat.gif
ADDED

|
Git LFS Details
|
img/train_loss.png
ADDED
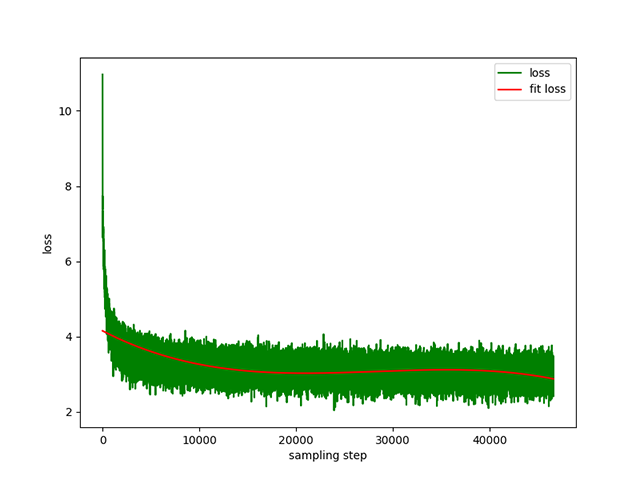
|
model/__pycache__/chat_model.cpython-310.pyc
ADDED
|
Binary file (2.7 kB). View file
|
|
|
model/__pycache__/infer.cpython-310.pyc
ADDED
|
Binary file (3.73 kB). View file
|
|
|
model/chat_model.py
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch import Tensor, LongTensor
|
| 3 |
+
from transformers import T5ForConditionalGeneration, T5Config
|
| 4 |
+
from transformers import TextIteratorStreamer
|
| 5 |
+
from transformers.generation.configuration_utils import GenerationConfig
|
| 6 |
+
|
| 7 |
+
class TextToTextModel(T5ForConditionalGeneration):
|
| 8 |
+
def __init__(self, config: T5Config) -> None:
|
| 9 |
+
'''
|
| 10 |
+
TextToTextModel继承T5ForConditionalGeneration
|
| 11 |
+
'''
|
| 12 |
+
super().__init__(config)
|
| 13 |
+
|
| 14 |
+
@torch.no_grad()
|
| 15 |
+
def my_generate(self,
|
| 16 |
+
input_ids: LongTensor,
|
| 17 |
+
attention_mask: LongTensor,
|
| 18 |
+
max_seq_len: int=256,
|
| 19 |
+
search_type: str='beam',
|
| 20 |
+
streamer: TextIteratorStreamer=None,
|
| 21 |
+
) -> Tensor:
|
| 22 |
+
'''
|
| 23 |
+
自定义gennerate方法方便调用、测试
|
| 24 |
+
search_type: ['greedy', 'beam', 'sampling', 'contrastive', ]
|
| 25 |
+
|
| 26 |
+
- *greedy decoding* by calling [`~generation.GenerationMixin.greedy_search`] if `num_beams=1` and
|
| 27 |
+
`do_sample=False`
|
| 28 |
+
- *contrastive search* by calling [`~generation.GenerationMixin.contrastive_search`] if `penalty_alpha>0.`
|
| 29 |
+
and `top_k>1`
|
| 30 |
+
- *multinomial sampling* by calling [`~generation.GenerationMixin.sample`] if `num_beams=1` and
|
| 31 |
+
`do_sample=True`
|
| 32 |
+
- *beam-search decoding* by calling [`~generation.GenerationMixin.beam_search`] if `num_beams>1` and
|
| 33 |
+
`do_sample=False`
|
| 34 |
+
- *beam-search multinomial sampling* by calling [`~generation.GenerationMixin.beam_sample`] if
|
| 35 |
+
`num_beams>1` and `do_sample=True`
|
| 36 |
+
'''
|
| 37 |
+
generation_config = GenerationConfig()
|
| 38 |
+
generation_config.remove_invalid_values = True
|
| 39 |
+
generation_config.eos_token_id = 1
|
| 40 |
+
generation_config.pad_token_id = 0
|
| 41 |
+
generation_config.decoder_start_token_id = self.config.decoder_start_token_id
|
| 42 |
+
generation_config.max_new_tokens = max_seq_len
|
| 43 |
+
# generation_config.repetition_penalty = 1.1 # 重复词惩罚
|
| 44 |
+
|
| 45 |
+
if search_type == 'greedy':
|
| 46 |
+
generation_config.num_beams = 1
|
| 47 |
+
generation_config.do_sample = False
|
| 48 |
+
elif search_type == 'beam':
|
| 49 |
+
generation_config.top_k = 50
|
| 50 |
+
generation_config.num_beams = 5
|
| 51 |
+
generation_config.do_sample = True
|
| 52 |
+
generation_config.top_p = 0.95
|
| 53 |
+
generation_config.no_repeat_ngram_size = 4
|
| 54 |
+
generation_config.length_penalty = -2.0
|
| 55 |
+
generation_config.early_stopping = True
|
| 56 |
+
elif search_type == 'sampling':
|
| 57 |
+
generation_config.num_beams = 1
|
| 58 |
+
generation_config.do_sample = True
|
| 59 |
+
generation_config.top_k = 50
|
| 60 |
+
generation_config.temperature = 0.98 # 越低,贫富差距越大,越高(>1),越趋向于均匀分布
|
| 61 |
+
generation_config.top_p = 0.80
|
| 62 |
+
generation_config.no_repeat_ngram_size = 4
|
| 63 |
+
elif search_type == 'contrastive':
|
| 64 |
+
generation_config.penalty_alpha = 0.5
|
| 65 |
+
generation_config.top_k = 50
|
| 66 |
+
|
| 67 |
+
result = self.generate(
|
| 68 |
+
inputs=input_ids,
|
| 69 |
+
attention_mask=attention_mask,
|
| 70 |
+
generation_config=generation_config,
|
| 71 |
+
streamer=streamer,
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
return result
|
model/chat_model_config.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import T5Config
|
| 2 |
+
|
| 3 |
+
class TextToTextModelConfig(T5Config):
|
| 4 |
+
model_type = 't5'
|
model/dataset.py
ADDED
|
@@ -0,0 +1,290 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Union
|
| 2 |
+
|
| 3 |
+
from torch.utils.data import Dataset
|
| 4 |
+
from torch import LongTensor, cuda
|
| 5 |
+
from transformers import PreTrainedTokenizerFast
|
| 6 |
+
from fastparquet import ParquetFile
|
| 7 |
+
from torch.utils.data import DataLoader
|
| 8 |
+
from datasets import load_dataset
|
| 9 |
+
import datasets
|
| 10 |
+
import pyarrow.parquet as pq
|
| 11 |
+
from numpy import array, int64
|
| 12 |
+
from numpy.random import shuffle
|
| 13 |
+
|
| 14 |
+
# import sys
|
| 15 |
+
# sys.path.extend(['.', '..'])
|
| 16 |
+
|
| 17 |
+
from config import PROJECT_ROOT
|
| 18 |
+
|
| 19 |
+
class MyDataset(Dataset):
|
| 20 |
+
|
| 21 |
+
def __init__(self,
|
| 22 |
+
parquet_file: str,
|
| 23 |
+
tokenizer_dir: str,
|
| 24 |
+
keep_in_memory: bool=False,
|
| 25 |
+
max_seq_len: int=512,
|
| 26 |
+
buffer_size: int=40960,
|
| 27 |
+
) -> None:
|
| 28 |
+
'''
|
| 29 |
+
keep_in_memory: 是否将parquet文件转换为pandas.DataFrame格式存放到内存,
|
| 30 |
+
False将使用迭代生成器(迭代生成器不支持打乱数据),减少大数据集内存占用
|
| 31 |
+
'''
|
| 32 |
+
super().__init__()
|
| 33 |
+
|
| 34 |
+
if cuda.device_count() >= 2 and not keep_in_memory:
|
| 35 |
+
raise ValueError(f'多GPU时使用MyDataset,参数keep_in_memory必须=True,否则无法进行分布式训练. 当前keep_in_memory={keep_in_memory}')
|
| 36 |
+
|
| 37 |
+
self.keep_in_memory = keep_in_memory
|
| 38 |
+
self.max_seq_len = max_seq_len
|
| 39 |
+
|
| 40 |
+
# 使用pyarrow.parquet读取,to_pandas、for遍历速度更快
|
| 41 |
+
parquet_table = pq.read_table(parquet_file)
|
| 42 |
+
|
| 43 |
+
# 获取数据集长度
|
| 44 |
+
self.length = parquet_table.num_rows
|
| 45 |
+
|
| 46 |
+
# 缓冲区大小不能超过数据长度
|
| 47 |
+
self.buffer_size = self.length if buffer_size > self.length else buffer_size
|
| 48 |
+
|
| 49 |
+
if keep_in_memory:
|
| 50 |
+
# 转化为pandas放到内存中
|
| 51 |
+
self.data = parquet_table.to_pandas()
|
| 52 |
+
else:
|
| 53 |
+
self.data = parquet_table
|
| 54 |
+
|
| 55 |
+
# 初始化tokenizer
|
| 56 |
+
self.tokenizer = PreTrainedTokenizerFast.from_pretrained(tokenizer_dir)
|
| 57 |
+
|
| 58 |
+
# 在这里初始化generator
|
| 59 |
+
self.sample_generator = self.item_generator()
|
| 60 |
+
|
| 61 |
+
def item_generator(self,) -> tuple:
|
| 62 |
+
'''
|
| 63 |
+
一条数据的生成器,防止大数据集OOM
|
| 64 |
+
'''
|
| 65 |
+
|
| 66 |
+
parquet_table = self.data
|
| 67 |
+
|
| 68 |
+
# 生成器是死循环,不用退出,训练结束(epoch结束)会停止调用next()
|
| 69 |
+
buffer_list = []
|
| 70 |
+
while True:
|
| 71 |
+
|
| 72 |
+
for prompt, response in zip(parquet_table['prompt'], parquet_table['response']):
|
| 73 |
+
|
| 74 |
+
# 缓存数据不够,添加数据
|
| 75 |
+
if len(buffer_list) < self.buffer_size:
|
| 76 |
+
buffer_list.append( (prompt.as_py(), response.as_py()) )
|
| 77 |
+
continue
|
| 78 |
+
|
| 79 |
+
# 执行到这里,缓存区够了,打乱数据
|
| 80 |
+
shuffle(buffer_list)
|
| 81 |
+
for p, r in buffer_list:
|
| 82 |
+
# 在这里迭代
|
| 83 |
+
yield p, r
|
| 84 |
+
|
| 85 |
+
# 迭代完成,清空缓存区
|
| 86 |
+
buffer_list = []
|
| 87 |
+
|
| 88 |
+
def __getitem__(self, index):
|
| 89 |
+
'''
|
| 90 |
+
返回一条样本
|
| 91 |
+
'''
|
| 92 |
+
if self.keep_in_memory:
|
| 93 |
+
data = self.data
|
| 94 |
+
prompt, response = data.iloc[index].prompt, data.iloc[index].response
|
| 95 |
+
else:
|
| 96 |
+
prompt, response = next(self.sample_generator)
|
| 97 |
+
|
| 98 |
+
max_seq_len = self.max_seq_len - 5 # len('[EOS]') = 5
|
| 99 |
+
# add an eos token note that end of resopnse, using in generate.
|
| 100 |
+
return f"{prompt[0: max_seq_len]}[EOS]", f"{response[0: max_seq_len]}[EOS]"
|
| 101 |
+
|
| 102 |
+
def collate_fn(self, data: list[list]) -> dict:
|
| 103 |
+
'''
|
| 104 |
+
合并一个批次数据返回
|
| 105 |
+
'''
|
| 106 |
+
tokenizer = self.tokenizer
|
| 107 |
+
|
| 108 |
+
prompt = tokenizer([item[0] for item in data], padding=True, return_token_type_ids=False)
|
| 109 |
+
response = tokenizer([item[1] for item in data], padding=True, return_token_type_ids=False)
|
| 110 |
+
|
| 111 |
+
input_ids = array(prompt.input_ids, dtype=int64)
|
| 112 |
+
input_mask = array(prompt.attention_mask, dtype=int64)
|
| 113 |
+
target_ids = array(response.input_ids, dtype=int64)
|
| 114 |
+
|
| 115 |
+
ret = {
|
| 116 |
+
'input_ids': LongTensor(input_ids),
|
| 117 |
+
'input_mask': LongTensor(input_mask),
|
| 118 |
+
'target_ids': LongTensor(target_ids),
|
| 119 |
+
}
|
| 120 |
+
return ret
|
| 121 |
+
|
| 122 |
+
def __len__(self) -> int:
|
| 123 |
+
return self.length
|
| 124 |
+
|
| 125 |
+
class ParquetDataset:
|
| 126 |
+
|
| 127 |
+
def __init__(self,
|
| 128 |
+
parquet_file: Union[str, dict],
|
| 129 |
+
tokenizer_dir: str,
|
| 130 |
+
keep_in_memory: bool=False,
|
| 131 |
+
cache_dir: str='./.cache',
|
| 132 |
+
buffer_size: int=10240,
|
| 133 |
+
max_len: int=512,
|
| 134 |
+
seed: int=23333
|
| 135 |
+
) -> None:
|
| 136 |
+
'''
|
| 137 |
+
使用huggingface的loaddataset方法加载,
|
| 138 |
+
parquet_file: 单个文件,此时只能使用dataset['train'],
|
| 139 |
+
多个文件请用:parquet_file={'train': 'train.parquet', 'test': 'test.parquet', 'validation': 'validation.parquet'})
|
| 140 |
+
其他用法见:https://huggingface.co/docs/datasets/loading
|
| 141 |
+
keep_in_memory: 是否将parquet文件转换为pandas.DataFrame格式存放到内存
|
| 142 |
+
'''
|
| 143 |
+
self.keep_in_memory = keep_in_memory
|
| 144 |
+
self.len_dict = self.__get_all_parquet_file_size(parquet_file=parquet_file)
|
| 145 |
+
|
| 146 |
+
self.max_len = max_len
|
| 147 |
+
self.tokenizer = PreTrainedTokenizerFast.from_pretrained(tokenizer_dir)
|
| 148 |
+
|
| 149 |
+
self.tokenizer = self.tokenizer
|
| 150 |
+
|
| 151 |
+
streaming = False if keep_in_memory else True
|
| 152 |
+
# streaming=True,否则大数据集OOM
|
| 153 |
+
dataset = load_dataset('parquet', data_files=parquet_file, cache_dir=cache_dir, streaming=streaming)
|
| 154 |
+
|
| 155 |
+
# 这里的batch_size不是训练的batch_size,是传递给precess_batch_func批处理的batch_size
|
| 156 |
+
dataset = dataset.map(self.precess_batch_func, batched=True, batch_size=buffer_size, \
|
| 157 |
+
remove_columns=['prompt', 'response'], fn_kwargs={'max_len': max_len})
|
| 158 |
+
|
| 159 |
+
dataset = dataset.with_format(type="torch")
|
| 160 |
+
|
| 161 |
+
if keep_in_memory:
|
| 162 |
+
dataset = dataset.shuffle(seed=seed, keep_in_memory=keep_in_memory)
|
| 163 |
+
else:
|
| 164 |
+
# 只能打乱缓冲区内的数据,不能打乱整个数据集,因此可以将缓存区设置稍微大一些
|
| 165 |
+
dataset = dataset.shuffle(seed=seed, buffer_size=buffer_size)
|
| 166 |
+
|
| 167 |
+
self.dataset = dataset
|
| 168 |
+
|
| 169 |
+
@staticmethod
|
| 170 |
+
def precess_batch_func(item: dict, max_len: int=512) -> dict:
|
| 171 |
+
'''
|
| 172 |
+
添加EOS
|
| 173 |
+
'''
|
| 174 |
+
max_len -= 5 # len('[EOS]') = 5
|
| 175 |
+
for i in range(len(item['prompt'])):
|
| 176 |
+
item['prompt'][i] = f"{item['prompt'][i][0: max_len]}[EOS]"
|
| 177 |
+
for i in range(len(item['response'])):
|
| 178 |
+
item['response'][i] = f"{item['response'][i][0: max_len]}[EOS]"
|
| 179 |
+
|
| 180 |
+
return {
|
| 181 |
+
'prompt': item['prompt'],
|
| 182 |
+
'response': item['response'],
|
| 183 |
+
}
|
| 184 |
+
|
| 185 |
+
def collate_fn(self, data: list[list]) -> dict:
|
| 186 |
+
'''
|
| 187 |
+
合并一个批次数据返回
|
| 188 |
+
'''
|
| 189 |
+
|
| 190 |
+
tokenizer = self.tokenizer
|
| 191 |
+
prompt = [item['prompt'] for item in data ]
|
| 192 |
+
response = [item['response'] for item in data ]
|
| 193 |
+
|
| 194 |
+
# 按批次pad
|
| 195 |
+
prompt_encoded = tokenizer(prompt, padding=True, return_token_type_ids=False)
|
| 196 |
+
response_encoded = tokenizer(response, padding=True, return_token_type_ids=False)
|
| 197 |
+
|
| 198 |
+
input_ids = array(prompt_encoded.input_ids, dtype=int64)
|
| 199 |
+
input_mask = array(prompt_encoded.attention_mask, dtype=int64)
|
| 200 |
+
target_ids = array(response_encoded.input_ids, dtype=int64)
|
| 201 |
+
|
| 202 |
+
ret = {
|
| 203 |
+
'input_ids': LongTensor(input_ids),
|
| 204 |
+
'input_mask': LongTensor(input_mask),
|
| 205 |
+
'target_ids': LongTensor(target_ids),
|
| 206 |
+
}
|
| 207 |
+
return ret
|
| 208 |
+
def __getitem__(self, index: str) -> datasets.Dataset:
|
| 209 |
+
'''
|
| 210 |
+
魔术方法,实现下标访问,如:dataset['train']、dataset['validation']、dataset['test']
|
| 211 |
+
'''
|
| 212 |
+
return self.dataset[index]
|
| 213 |
+
|
| 214 |
+
def __get_all_parquet_file_size(self, parquet_file: Union[str, dict]) -> dict:
|
| 215 |
+
'''
|
| 216 |
+
获取所有parquet file的长度
|
| 217 |
+
'''
|
| 218 |
+
len_dict = dict()
|
| 219 |
+
if type(parquet_file) is str:
|
| 220 |
+
train_len = self.__get_size_of_praquet(parquet_file)
|
| 221 |
+
len_dict['train'] = train_len
|
| 222 |
+
|
| 223 |
+
if type(parquet_file) is dict:
|
| 224 |
+
for split_type, file in parquet_file.items():
|
| 225 |
+
len_dict[split_type] = self.__get_size_of_praquet(file)
|
| 226 |
+
|
| 227 |
+
return len_dict
|
| 228 |
+
|
| 229 |
+
def __get_size_of_praquet(self, file_name: str) -> int:
|
| 230 |
+
'''
|
| 231 |
+
获取一个parquet文件的行数
|
| 232 |
+
'''
|
| 233 |
+
parquet_data = pq.read_table(file_name)
|
| 234 |
+
|
| 235 |
+
return parquet_data.num_rows
|
| 236 |
+
|
| 237 |
+
def __len__(self) -> int:
|
| 238 |
+
'''
|
| 239 |
+
魔术方法,如果只有一个数据集,返回默认数据集大小
|
| 240 |
+
'''
|
| 241 |
+
if len(self.len_dict) == 1:
|
| 242 |
+
return self.len_dict['train']
|
| 243 |
+
else:
|
| 244 |
+
raise Exception("this dataset contains many splited datasets, use `get_dataset_size(split_name)` function to get length, e.g: get_dataset_size('train')")
|
| 245 |
+
|
| 246 |
+
def get_dataset_size(self, split_name: str) -> int:
|
| 247 |
+
'''
|
| 248 |
+
获取每个切分数据集的长度
|
| 249 |
+
split_name可取:train、validation、test
|
| 250 |
+
'''
|
| 251 |
+
return self.len_dict[split_name]
|
| 252 |
+
|
| 253 |
+
def get_tokenizer(self, ) -> PreTrainedTokenizerFast:
|
| 254 |
+
return self.tokenizer
|
| 255 |
+
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
if __name__ == '__main__':
|
| 259 |
+
parquet_file = PROJECT_ROOT + '/data/my_valid_dataset.parquet'
|
| 260 |
+
tokenizer_dir = PROJECT_ROOT + '/model_save/tokenizer'
|
| 261 |
+
|
| 262 |
+
# example 1:
|
| 263 |
+
dataset = MyDataset(parquet_file, tokenizer_dir, keep_in_memory=False, max_seq_len=128)
|
| 264 |
+
print('\nexample 1, dataset size: ', len(dataset))
|
| 265 |
+
dataloader = DataLoader(dataset, batch_size=32, collate_fn=dataset.collate_fn)
|
| 266 |
+
|
| 267 |
+
for epoch in range(2):
|
| 268 |
+
print('epoch: {}'.format(epoch))
|
| 269 |
+
for step, batch in enumerate(dataloader):
|
| 270 |
+
x, x_mask, y = batch['input_ids'], batch['input_mask'], batch['target_ids']
|
| 271 |
+
print('step:{}'.format(step), x.shape, x_mask.shape, y.shape)
|
| 272 |
+
if step == 5:
|
| 273 |
+
break
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
# exit(0)
|
| 277 |
+
# example 2:
|
| 278 |
+
dataset = ParquetDataset(parquet_file, tokenizer_dir, keep_in_memory=True, max_len=32)
|
| 279 |
+
dataloader = DataLoader(dataset['train'], batch_size=32, collate_fn=dataset.collate_fn)
|
| 280 |
+
print('\nexample 2, dataset size: ', dataset.get_dataset_size('train'))
|
| 281 |
+
|
| 282 |
+
for epoch in range(2):
|
| 283 |
+
print('epoch: {}'.format(epoch))
|
| 284 |
+
for step, batch in enumerate(dataloader):
|
| 285 |
+
x, x_mask, y = batch['input_ids'], batch['input_mask'], batch['target_ids']
|
| 286 |
+
print('step:{}'.format(step), x.shape, x_mask.shape, y.shape)
|
| 287 |
+
if step == 5:
|
| 288 |
+
break
|
| 289 |
+
|
| 290 |
+
|
model/infer.py
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from threading import Thread
|
| 3 |
+
import platform
|
| 4 |
+
from typing import Union
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
from transformers import TextIteratorStreamer,PreTrainedTokenizerFast
|
| 8 |
+
from safetensors.torch import load_model
|
| 9 |
+
|
| 10 |
+
from accelerate import init_empty_weights, load_checkpoint_and_dispatch
|
| 11 |
+
|
| 12 |
+
# import 自定义类和函数
|
| 13 |
+
from model.chat_model import TextToTextModel
|
| 14 |
+
from utils.functions import get_T5_config
|
| 15 |
+
|
| 16 |
+
from config import InferConfig, T5ModelConfig
|
| 17 |
+
|
| 18 |
+
class ChatBot:
|
| 19 |
+
def __init__(self, infer_config: InferConfig) -> None:
|
| 20 |
+
'''
|
| 21 |
+
'''
|
| 22 |
+
self.infer_config = infer_config
|
| 23 |
+
# 初始化tokenizer
|
| 24 |
+
tokenizer = PreTrainedTokenizerFast.from_pretrained(infer_config.model_dir)
|
| 25 |
+
self.tokenizer = tokenizer
|
| 26 |
+
self.encode = tokenizer.encode_plus
|
| 27 |
+
self.batch_decode = tokenizer.batch_decode
|
| 28 |
+
self.batch_encode_plus = tokenizer.batch_encode_plus
|
| 29 |
+
|
| 30 |
+
t5_config = get_T5_config(T5ModelConfig(), vocab_size=len(tokenizer), decoder_start_token_id=tokenizer.pad_token_id, eos_token_id=tokenizer.eos_token_id)
|
| 31 |
+
|
| 32 |
+
try:
|
| 33 |
+
model = TextToTextModel(t5_config)
|
| 34 |
+
|
| 35 |
+
if os.path.isdir(infer_config.model_dir):
|
| 36 |
+
|
| 37 |
+
# from_pretrained
|
| 38 |
+
model = model.from_pretrained(infer_config.model_dir)
|
| 39 |
+
|
| 40 |
+
elif infer_config.model_dir.endswith('.safetensors'):
|
| 41 |
+
|
| 42 |
+
# load safetensors
|
| 43 |
+
load_model(model, infer_config.model_dir)
|
| 44 |
+
|
| 45 |
+
else:
|
| 46 |
+
|
| 47 |
+
# load torch checkpoint
|
| 48 |
+
model.load_state_dict(torch.load(infer_config.model_dir))
|
| 49 |
+
|
| 50 |
+
self.model = model
|
| 51 |
+
|
| 52 |
+
except Exception as e:
|
| 53 |
+
print(str(e), 'transformers and pytorch load fail, try accelerate load function.')
|
| 54 |
+
|
| 55 |
+
empty_model = None
|
| 56 |
+
with init_empty_weights():
|
| 57 |
+
empty_model = TextToTextModel(t5_config)
|
| 58 |
+
|
| 59 |
+
self.model = load_checkpoint_and_dispatch(
|
| 60 |
+
model=empty_model,
|
| 61 |
+
checkpoint=infer_config.model_dir,
|
| 62 |
+
device_map='auto',
|
| 63 |
+
dtype=torch.float16,
|
| 64 |
+
)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 68 |
+
self.model.to(self.device)
|
| 69 |
+
|
| 70 |
+
self.streamer = TextIteratorStreamer(tokenizer=tokenizer, clean_up_tokenization_spaces=True, skip_special_tokens=True)
|
| 71 |
+
|
| 72 |
+
def stream_chat(self, input_txt: str) -> TextIteratorStreamer:
|
| 73 |
+
'''
|
| 74 |
+
流式对话,线程启动后可返回,通过迭代streamer获取生成的文字,仅支持greedy search
|
| 75 |
+
'''
|
| 76 |
+
encoded = self.encode(input_txt + '[EOS]')
|
| 77 |
+
|
| 78 |
+
input_ids = torch.LongTensor([encoded.input_ids]).to(self.device)
|
| 79 |
+
attention_mask = torch.LongTensor([encoded.attention_mask]).to(self.device)
|
| 80 |
+
|
| 81 |
+
generation_kwargs = {
|
| 82 |
+
'input_ids': input_ids,
|
| 83 |
+
'attention_mask': attention_mask,
|
| 84 |
+
'max_seq_len': self.infer_config.max_seq_len,
|
| 85 |
+
'streamer': self.streamer,
|
| 86 |
+
'search_type': 'greedy',
|
| 87 |
+
}
|
| 88 |
+
|
| 89 |
+
thread = Thread(target=self.model.my_generate, kwargs=generation_kwargs)
|
| 90 |
+
thread.start()
|
| 91 |
+
|
| 92 |
+
return self.streamer
|
| 93 |
+
|
| 94 |
+
def chat(self, input_txt: Union[str, list[str]] ) -> Union[str, list[str]]:
|
| 95 |
+
'''
|
| 96 |
+
非流式生成,可以使用beam search、beam sample等方法生成文本。
|
| 97 |
+
'''
|
| 98 |
+
if isinstance(input_txt, str):
|
| 99 |
+
input_txt = [input_txt]
|
| 100 |
+
elif not isinstance(input_txt, list):
|
| 101 |
+
raise Exception('input_txt mast be a str or list[str]')
|
| 102 |
+
|
| 103 |
+
# add EOS token
|
| 104 |
+
input_txts = [f"{txt}[EOS]" for txt in input_txt]
|
| 105 |
+
encoded = self.batch_encode_plus(input_txts, padding=True)
|
| 106 |
+
input_ids = torch.LongTensor(encoded.input_ids).to(self.device)
|
| 107 |
+
attention_mask = torch.LongTensor(encoded.attention_mask).to(self.device)
|
| 108 |
+
|
| 109 |
+
outputs = self.model.my_generate(
|
| 110 |
+
input_ids=input_ids,
|
| 111 |
+
attention_mask=attention_mask,
|
| 112 |
+
max_seq_len=self.infer_config.max_seq_len,
|
| 113 |
+
search_type='greedy',
|
| 114 |
+
)
|
| 115 |
+
|
| 116 |
+
outputs = self.batch_decode(outputs.cpu().numpy(), clean_up_tokenization_spaces=True, skip_special_tokens=True)
|
| 117 |
+
|
| 118 |
+
note = "我是一个参数很少的AI模型🥺,知识库较少,无法直接回答您的问题,换个问题试试吧👋"
|
| 119 |
+
outputs = [item if len(item) != 0 else note for item in outputs]
|
| 120 |
+
|
| 121 |
+
return outputs[0] if len(outputs) == 1 else outputs
|
model/trainer.py
ADDED
|
@@ -0,0 +1,606 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import signal
|
| 2 |
+
import sys
|
| 3 |
+
import os
|
| 4 |
+
import time
|
| 5 |
+
from typing import Union
|
| 6 |
+
import platform
|
| 7 |
+
|
| 8 |
+
from psutil import virtual_memory, cpu_count
|
| 9 |
+
import numpy as np
|
| 10 |
+
from torch.utils.data import DataLoader
|
| 11 |
+
import torch
|
| 12 |
+
from rich.progress import Progress, TextColumn, BarColumn, TimeElapsedColumn, TimeRemainingColumn
|
| 13 |
+
from transformers import PreTrainedTokenizerFast
|
| 14 |
+
from torch_optimizer import Adafactor
|
| 15 |
+
|
| 16 |
+
# import accelerate
|
| 17 |
+
from accelerate import Accelerator
|
| 18 |
+
from accelerate.utils import set_seed
|
| 19 |
+
|
| 20 |
+
# import 自定义类和函数
|
| 21 |
+
from model.chat_model import TextToTextModel
|
| 22 |
+
from utils.logger import Logger
|
| 23 |
+
from model.dataset import MyDataset
|
| 24 |
+
from config import TrainConfig, T5ModelConfig
|
| 25 |
+
from utils.functions import (
|
| 26 |
+
get_bleu4_score,
|
| 27 |
+
save_model_config,
|
| 28 |
+
get_free_space_of_disk,
|
| 29 |
+
my_average,
|
| 30 |
+
get_path_of_suffix_files,
|
| 31 |
+
get_T5_config,
|
| 32 |
+
)
|
| 33 |
+
|
| 34 |
+
class ChatTrainer:
|
| 35 |
+
def __init__(self, train_config: TrainConfig, model_config: T5ModelConfig, ) -> None:
|
| 36 |
+
|
| 37 |
+
self.train_config = train_config
|
| 38 |
+
self.model_config = model_config
|
| 39 |
+
|
| 40 |
+
# file_name=None会自动生成以当前日期命名的log文件名
|
| 41 |
+
self.logger = Logger('chat_trainer', std_out=True, save2file=True, file_name=None)
|
| 42 |
+
|
| 43 |
+
self.model = None
|
| 44 |
+
self.accelerator = None
|
| 45 |
+
|
| 46 |
+
signal.signal(signal.SIGINT, self.process_exit_handler)
|
| 47 |
+
|
| 48 |
+
self.is_win_platform = True if platform.system().lower() == 'windows' else False
|
| 49 |
+
|
| 50 |
+
torch.manual_seed(train_config.seed)
|
| 51 |
+
torch.cuda.manual_seed_all(train_config.seed)
|
| 52 |
+
|
| 53 |
+
def process_exit_handler(self, signal_received, frame) -> None:
|
| 54 |
+
'''
|
| 55 |
+
进程退出时的操作,保存模型
|
| 56 |
+
'''
|
| 57 |
+
if self.accelerator and self.model:
|
| 58 |
+
ask = "you are pressed `ctrl+c`, do you want to save checkpoint? Yes (y) or No (n)"
|
| 59 |
+
self.accelerator.print(ask)
|
| 60 |
+
ins = input()
|
| 61 |
+
|
| 62 |
+
if ins.lower() in ('yes', 'y'):
|
| 63 |
+
|
| 64 |
+
suffix = 'exit_save_{}'.format(str(time.strftime('%Y%m%d%H%M%S', time.localtime())))
|
| 65 |
+
|
| 66 |
+
self.accelerator.wait_for_everyone()
|
| 67 |
+
self.accelerator.save_state(output_dir=self.train_config.train_state_dir)
|
| 68 |
+
|
| 69 |
+
self.accelerator.print('model ckeck point has been saved in {}'.format(self.train_config.train_state_dir))
|
| 70 |
+
|
| 71 |
+
sys.exit(0)
|
| 72 |
+
else:
|
| 73 |
+
print('process not in trainingg, exit.')
|
| 74 |
+
sys.exit(0)
|
| 75 |
+
|
| 76 |
+
def save_model(self, suffix: Union[str, int]) -> None:
|
| 77 |
+
'''保存模型到文件
|
| 78 |
+
注意:save_model不能放到is_main_process里面
|
| 79 |
+
e.g:
|
| 80 |
+
>>> self.save_model(epoch) # 在这里使用
|
| 81 |
+
>>> if accelerator.is_main_process:
|
| 82 |
+
>>> do_somthing()
|
| 83 |
+
'''
|
| 84 |
+
if self.model and self.accelerator:
|
| 85 |
+
|
| 86 |
+
# 先wait_for_everyone,再保存
|
| 87 |
+
self.accelerator.wait_for_everyone()
|
| 88 |
+
|
| 89 |
+
if self.accelerator.is_main_process:
|
| 90 |
+
unwrap_model = self.accelerator.unwrap_model(self.model)
|
| 91 |
+
model_dict = self.accelerator.get_state_dict(unwrap_model)
|
| 92 |
+
torch.save(model_dict, self.train_config.model_file.format(suffix))
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def delete_early_checkpoint(self, epoch: int, keep_latest_n: int=3,) -> None:
|
| 96 |
+
'''
|
| 97 |
+
删除最早的模型,最保留最近keep_latest_n个模型文件
|
| 98 |
+
'''
|
| 99 |
+
model_save_path = self.train_config.model_file
|
| 100 |
+
model_save_path = model_save_path.replace('\\', '/') # 针对win的路径,将\替换为/
|
| 101 |
+
model_save_path = '/'.join(model_save_path.split('/')[0: -1]) # 删除末尾文件名后缀
|
| 102 |
+
|
| 103 |
+
model_files = get_path_of_suffix_files(model_save_path, suffix='.bin', with_create_time=True)
|
| 104 |
+
|
| 105 |
+
# 进程异常退出保存模型文件不在删除范围
|
| 106 |
+
train_save_model_fils = []
|
| 107 |
+
for item in model_files:
|
| 108 |
+
if 'exit_save' not in item[0]:
|
| 109 |
+
|
| 110 |
+
# 大于当前epoch的文件不不删除
|
| 111 |
+
f_epoch = int(item[0].split('.')[-2])
|
| 112 |
+
if epoch >= f_epoch:
|
| 113 |
+
print(epoch, f_epoch, item)
|
| 114 |
+
train_save_model_fils.append(item)
|
| 115 |
+
|
| 116 |
+
train_save_model_fils.sort(key=lambda x: x[1]) # 按照时间从小到大排序
|
| 117 |
+
|
| 118 |
+
if len(train_save_model_fils) <= keep_latest_n:
|
| 119 |
+
return
|
| 120 |
+
|
| 121 |
+
to_delete_files = train_save_model_fils[0: -keep_latest_n]
|
| 122 |
+
for item in to_delete_files:
|
| 123 |
+
os.remove(item[0])
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
def train(self, is_keep_training: bool=False, is_finetune: bool=False) -> None:
|
| 127 |
+
'''
|
| 128 |
+
is_keep_training: 是否从断点处加载状态继续训练
|
| 129 |
+
is_finetune: 是否微调,微调的话可能需要冻结部分参数
|
| 130 |
+
'''
|
| 131 |
+
log = self.logger
|
| 132 |
+
train_config = self.train_config
|
| 133 |
+
save_steps = self.train_config.save_steps
|
| 134 |
+
logging_steps = self.train_config.logging_steps
|
| 135 |
+
|
| 136 |
+
# 梯度累计的步数
|
| 137 |
+
accumulation_steps = train_config.gradient_accumulation_steps
|
| 138 |
+
|
| 139 |
+
set_seed(train_config.seed)
|
| 140 |
+
|
| 141 |
+
accelerator = Accelerator(
|
| 142 |
+
mixed_precision=train_config.mixed_precision, # 混合精度
|
| 143 |
+
gradient_accumulation_steps=accumulation_steps, # 梯度累积
|
| 144 |
+
project_dir=train_config.train_state_dir,
|
| 145 |
+
)
|
| 146 |
+
|
| 147 |
+
# 根据剩余内存大小决定是否完全加载数据集到内存中
|
| 148 |
+
unuse_mem = virtual_memory().available / (1024 ** 3) # 单位:GB
|
| 149 |
+
unuse_disk = get_free_space_of_disk('./')
|
| 150 |
+
|
| 151 |
+
# 剩余内存≥48GB将把数据集留在内存中,因为2个显卡+全全部装载900多万的训练数据到内存需要大概43GB的CPU内存
|
| 152 |
+
# 如果不放在内存中,将会使用迭代器生成数据,CPU 内存小于16GB也可以运行,但是不支持顺序打乱。
|
| 153 |
+
# 多GPU keep_in_memory必须=True,否则无法进行分布式训练
|
| 154 |
+
keep_in_memory = True if unuse_mem >= 48.0 or torch.cuda.device_count() >= 2 else False
|
| 155 |
+
|
| 156 |
+
if accelerator.is_main_process:
|
| 157 |
+
log.info('cpu memory available: {:.2f} GB, disk space available: {:.2f} GB, keep dataset in memory: {}.'\
|
| 158 |
+
.format(unuse_mem, unuse_disk, keep_in_memory), save_to_file=True)
|
| 159 |
+
log.info('operation: {}, keep training: {}, loading datasets ...'.format('finetune' if is_finetune else 'train', is_keep_training))
|
| 160 |
+
|
| 161 |
+
# args for dataloader
|
| 162 |
+
num_workers = 0
|
| 163 |
+
# if not self.is_win_platform:
|
| 164 |
+
# cpu_cnt = cpu_count(logical=False)
|
| 165 |
+
# gpu_cnt = torch.cuda.device_count()
|
| 166 |
+
# if cpu_cnt >= 8 * gpu_cnt:
|
| 167 |
+
# # num_workers = 4 x number of available GPUs
|
| 168 |
+
# num_workers = int(4 * gpu_cnt)
|
| 169 |
+
# else:
|
| 170 |
+
# num_workers = int(cpu_cnt // 2)
|
| 171 |
+
|
| 172 |
+
train_dataset = MyDataset(
|
| 173 |
+
parquet_file=train_config.train_file,
|
| 174 |
+
tokenizer_dir=train_config.tokenizer_dir,
|
| 175 |
+
keep_in_memory=keep_in_memory,
|
| 176 |
+
max_seq_len=train_config.max_seq_len,
|
| 177 |
+
)
|
| 178 |
+
valid_dataset = MyDataset(
|
| 179 |
+
parquet_file=train_config.validation_file,
|
| 180 |
+
tokenizer_dir=train_config.tokenizer_dir,
|
| 181 |
+
keep_in_memory=keep_in_memory,
|
| 182 |
+
max_seq_len=train_config.max_seq_len,
|
| 183 |
+
)
|
| 184 |
+
|
| 185 |
+
batch_size = train_config.batch_size_per_gpu
|
| 186 |
+
|
| 187 |
+
train_dataloader = DataLoader(
|
| 188 |
+
train_dataset,
|
| 189 |
+
batch_size=batch_size,
|
| 190 |
+
shuffle=True,
|
| 191 |
+
collate_fn=train_dataset.collate_fn,
|
| 192 |
+
pin_memory=False,
|
| 193 |
+
num_workers=num_workers, #设置>1会导致cpu内存缓慢增涨,最后OOM,后面再研究为什么,num_workers=4,一个epoch只减少30分钟
|
| 194 |
+
)
|
| 195 |
+
valid_dataloader = DataLoader(
|
| 196 |
+
valid_dataset,
|
| 197 |
+
batch_size=batch_size,
|
| 198 |
+
shuffle=False,
|
| 199 |
+
collate_fn=valid_dataset.collate_fn,
|
| 200 |
+
pin_memory=False,
|
| 201 |
+
num_workers=num_workers,
|
| 202 |
+
)
|
| 203 |
+
|
| 204 |
+
device = accelerator.device
|
| 205 |
+
log.info('using device: {} '.format(str(device)), save_to_file=True)
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
# T5: All labels set to `-100` are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
|
| 209 |
+
tokenizer = train_dataset.tokenizer
|
| 210 |
+
decoder_start_token_id = tokenizer.pad_token_id
|
| 211 |
+
|
| 212 |
+
# for t5, set decoder_start_token_id = pad_token_id
|
| 213 |
+
t5_config = get_T5_config(T5ModelConfig(), vocab_size=len(tokenizer), decoder_start_token_id=decoder_start_token_id, eos_token_id=tokenizer.eos_token_id)
|
| 214 |
+
|
| 215 |
+
model = TextToTextModel(t5_config)
|
| 216 |
+
|
| 217 |
+
# 微调加载的模型并冻结embedding和encoder
|
| 218 |
+
if is_finetune:
|
| 219 |
+
model.load_state_dict(torch.load(train_config.finetune_from_ckp_file))
|
| 220 |
+
# print(model)
|
| 221 |
+
|
| 222 |
+
layers_to_freeze = [model.shared, model.encoder]
|
| 223 |
+
|
| 224 |
+
for layer in layers_to_freeze:
|
| 225 |
+
for param in layer.parameters():
|
| 226 |
+
param.requires_grad = False
|
| 227 |
+
|
| 228 |
+
# 保存模型配置,方便修改配置后恢复
|
| 229 |
+
save_model_config(t5_config.to_diff_dict(), train_config.model_config_file)
|
| 230 |
+
|
| 231 |
+
# T5训练,论文推荐使用Adafactor
|
| 232 |
+
optimizer = Adafactor(params=model.parameters(), lr=train_config.learn_rate)
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
# 获取当前机器有多少个GPU,默认全部使用
|
| 236 |
+
num_gpus_used = accelerator.state.num_processes
|
| 237 |
+
|
| 238 |
+
# 单机多卡,每个step总共的batch_size = batch_size_per_gpu * num_gpus_used
|
| 239 |
+
# total_batch_size 初始化为batch_size_per_gpu真的只有CPU的情况
|
| 240 |
+
total_batch_size = train_config.batch_size_per_gpu
|
| 241 |
+
if num_gpus_used >= 1:
|
| 242 |
+
total_batch_size = num_gpus_used * train_config.batch_size_per_gpu
|
| 243 |
+
|
| 244 |
+
steps_per_epoch = int(np.ceil(len(train_dataset) // total_batch_size))
|
| 245 |
+
eval_steps = int(np.ceil(len(valid_dataset) // total_batch_size))
|
| 246 |
+
|
| 247 |
+
if accelerator.is_main_process:
|
| 248 |
+
log.info('train dataset size: {}, steps per epoch:{}; validation dataset size: {}, steps per validation: {}; datalodater num_workers: {}.'\
|
| 249 |
+
.format(len(train_dataset), steps_per_epoch, len(valid_dataset), eval_steps, num_workers), save_to_file=True)
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
lr_scheduler = torch.optim.lr_scheduler.OneCycleLR(
|
| 253 |
+
optimizer=optimizer,
|
| 254 |
+
max_lr=train_config.div_factor * train_config.learn_rate,
|
| 255 |
+
epochs=train_config.epochs,
|
| 256 |
+
steps_per_epoch=int(np.ceil( len(train_dataset) / (batch_size * accumulation_steps) )), # 梯度累积相当于增大了batch_size
|
| 257 |
+
div_factor=train_config.div_factor,
|
| 258 |
+
cycle_momentum=False,
|
| 259 |
+
)
|
| 260 |
+
|
| 261 |
+
model, optimizer, lr_scheduler, train_dataloader, valid_dataloader = accelerator.prepare(
|
| 262 |
+
model,
|
| 263 |
+
optimizer,
|
| 264 |
+
lr_scheduler,
|
| 265 |
+
train_dataloader,
|
| 266 |
+
valid_dataloader,
|
| 267 |
+
)
|
| 268 |
+
|
| 269 |
+
if is_keep_training:
|
| 270 |
+
accelerator.load_state(input_dir=train_config.train_state_dir)
|
| 271 |
+
accelerator.register_for_checkpointing(lr_scheduler)
|
| 272 |
+
|
| 273 |
+
self.model = model
|
| 274 |
+
self.accelerator = accelerator
|
| 275 |
+
|
| 276 |
+
best_bleu4 = 0.0
|
| 277 |
+
best_epoch = 0
|
| 278 |
+
epoch_loss_list = []
|
| 279 |
+
|
| 280 |
+
# 添加进度条,只在主进程更新
|
| 281 |
+
if accelerator.is_main_process:
|
| 282 |
+
progress = Progress(TextColumn("[progress.description]{task.description}"),
|
| 283 |
+
BarColumn(),
|
| 284 |
+
TextColumn("[progress.percentage]{task.percentage:>3.0f}%"),
|
| 285 |
+
TimeRemainingColumn(),
|
| 286 |
+
TimeElapsedColumn(),
|
| 287 |
+
TextColumn("[bold blue]{task.fields[show_info]}"),
|
| 288 |
+
refresh_per_second=1, # 每1秒钟更新一次,不要频繁更新
|
| 289 |
+
)
|
| 290 |
+
|
| 291 |
+
epoch_progress = progress.add_task(description='epoch: ', show_info='', total=train_config.epochs)
|
| 292 |
+
steps_progress = progress.add_task(description='steps: ', show_info='', \
|
| 293 |
+
total=np.ceil(steps_per_epoch / logging_steps))
|
| 294 |
+
eval_progress = progress.add_task(description='evaluate: ', show_info='', total=eval_steps, visible=False)
|
| 295 |
+
|
| 296 |
+
self.progress = progress
|
| 297 |
+
self.eval_progress = eval_progress
|
| 298 |
+
|
| 299 |
+
progress.start()
|
| 300 |
+
|
| 301 |
+
# end if
|
| 302 |
+
|
| 303 |
+
for epoch in range(train_config.epochs):
|
| 304 |
+
|
| 305 |
+
if accelerator.is_main_process:
|
| 306 |
+
epoch_show_txt = 'epoch: {}/{}, avg_loss: {:.6f}, best_epoch: {}, best_bleu: {}'.format(
|
| 307 |
+
epoch, train_config.epochs, my_average(epoch_loss_list), best_epoch, best_bleu4
|
| 308 |
+
)
|
| 309 |
+
progress.update(epoch_progress, show_info=epoch_show_txt)
|
| 310 |
+
progress.reset(steps_progress)
|
| 311 |
+
|
| 312 |
+
epoch_loss_list = []
|
| 313 |
+
model.train()
|
| 314 |
+
|
| 315 |
+
# torch.cuda.empty_cache()
|
| 316 |
+
|
| 317 |
+
for step, batch_data in enumerate(train_dataloader):
|
| 318 |
+
|
| 319 |
+
input_ids, input_mask = batch_data['input_ids'], batch_data['input_mask']
|
| 320 |
+
target_ids = batch_data['target_ids']
|
| 321 |
+
# for t5 model, all labels set to `-100` are ignored (masked)
|
| 322 |
+
target_ids[target_ids == decoder_start_token_id] = -100
|
| 323 |
+
|
| 324 |
+
outputs = model(
|
| 325 |
+
input_ids=input_ids,
|
| 326 |
+
attention_mask=input_mask,
|
| 327 |
+
labels=target_ids,
|
| 328 |
+
)
|
| 329 |
+
|
| 330 |
+
loss = outputs.loss.mean() / accumulation_steps
|
| 331 |
+
|
| 332 |
+
# attention here! loss.backward()
|
| 333 |
+
accelerator.backward(loss)
|
| 334 |
+
|
| 335 |
+
# 梯度累计
|
| 336 |
+
if (step + 1) % accumulation_steps == 0:
|
| 337 |
+
accelerator.clip_grad_norm_(model.parameters(), 1.0)
|
| 338 |
+
|
| 339 |
+
optimizer.step()
|
| 340 |
+
lr_scheduler.step()
|
| 341 |
+
optimizer.zero_grad()
|
| 342 |
+
|
| 343 |
+
# 每隔save_steps步保存一次模型
|
| 344 |
+
if (step + 1) % save_steps == 0 or step == steps_per_epoch:
|
| 345 |
+
self.save_model('epoch_{}_latest'.format(epoch))
|
| 346 |
+
accelerator.save_state(output_dir=train_config.train_state_dir)
|
| 347 |
+
|
| 348 |
+
# ==================================以下记录loss到日志============================================
|
| 349 |
+
# 每n步更新一次,避免频繁的cpu-gpu数据复制
|
| 350 |
+
# 参考:https://pytorch.org/tutorials/recipes/recipes/tuning_guide.html#avoid-unnecessary-cpu-gpu-synchronization
|
| 351 |
+
|
| 352 |
+
if step % logging_steps == 0 or step == steps_per_epoch:
|
| 353 |
+
|
| 354 |
+
loss_cpu = loss.detach().item() * accumulation_steps
|
| 355 |
+
epoch_loss_list.append(loss_cpu)
|
| 356 |
+
|
| 357 |
+
info_txt = 'training loss: epoch:{}, step:{}, loss:{}, device:{}'.\
|
| 358 |
+
format(epoch, step, loss_cpu, str(accelerator.device))
|
| 359 |
+
|
| 360 |
+
log.info(info_txt, std_out=False, save_to_file=True) # 保存 loss 到文件
|
| 361 |
+
|
| 362 |
+
# 更新进度条
|
| 363 |
+
if accelerator.is_main_process:
|
| 364 |
+
step_show_txt = 'step: {}/{}, loss: {:.6f}'.format(step, steps_per_epoch, loss_cpu)
|
| 365 |
+
progress.advance(steps_progress, advance=1)
|
| 366 |
+
progress.update(steps_progress, show_info=step_show_txt)
|
| 367 |
+
|
| 368 |
+
# ==================================以上记录loss到日志============================================
|
| 369 |
+
|
| 370 |
+
# if step >= 20:break
|
| 371 |
+
|
| 372 |
+
# end for batch setps
|
| 373 |
+
|
| 374 |
+
model.eval()
|
| 375 |
+
|
| 376 |
+
cur_bleu4_score = self.evaluate(
|
| 377 |
+
model=model,
|
| 378 |
+
tokenizer=tokenizer,
|
| 379 |
+
valid_dataloader=valid_dataloader,
|
| 380 |
+
accelerator=accelerator,
|
| 381 |
+
eval_steps=eval_steps,
|
| 382 |
+
)
|
| 383 |
+
|
| 384 |
+
# save model
|
| 385 |
+
if cur_bleu4_score >= best_bleu4:
|
| 386 |
+
|
| 387 |
+
best_bleu4 = cur_bleu4_score
|
| 388 |
+
best_epoch = epoch
|
| 389 |
+
# 最多保存最近keep_latest_n_ckp个模型文件
|
| 390 |
+
# self.delete_early_checkpoint(epoch=epoch, keep_latest_n=train_config.keep_latest_n_ckp)
|
| 391 |
+
self.save_model('best')
|
| 392 |
+
accelerator.save_state(output_dir=train_config.train_state_dir)
|
| 393 |
+
|
| 394 |
+
# 每个epoch打印一下日志
|
| 395 |
+
if accelerator.is_main_process:
|
| 396 |
+
|
| 397 |
+
progress.advance(epoch_progress, advance=1)
|
| 398 |
+
info_txt = 'epoch log: epoch:{}, avg_loss:{}, cur_bleu4:{}, best_bleu4:{}, best_epoch:{}'.\
|
| 399 |
+
format(epoch, my_average(epoch_loss_list), cur_bleu4_score, best_bleu4, best_epoch)
|
| 400 |
+
# log.info(info_txt, std_out=True, save_to_file=True)
|
| 401 |
+
self.print_and_log(info_txt, accelerator)
|
| 402 |
+
|
| 403 |
+
|
| 404 |
+
def evaluate(self,
|
| 405 |
+
model: TextToTextModel,
|
| 406 |
+
tokenizer: PreTrainedTokenizerFast,
|
| 407 |
+
valid_dataloader: DataLoader,
|
| 408 |
+
accelerator: Accelerator,
|
| 409 |
+
eval_steps: int,
|
| 410 |
+
) -> float:
|
| 411 |
+
|
| 412 |
+
'''
|
| 413 |
+
评估,返回平均的bleu分数
|
| 414 |
+
'''
|
| 415 |
+
max_seq_len = self.train_config.max_seq_len
|
| 416 |
+
batch_decode = tokenizer.batch_decode
|
| 417 |
+
bleu4_scores = []
|
| 418 |
+
|
| 419 |
+
if accelerator.is_main_process:
|
| 420 |
+
self.progress.reset(self.eval_progress)
|
| 421 |
+
self.progress.update(self.eval_progress, visible=True)
|
| 422 |
+
|
| 423 |
+
with torch.no_grad():
|
| 424 |
+
for step, batch_data in enumerate(valid_dataloader):
|
| 425 |
+
|
| 426 |
+
if accelerator.is_main_process:
|
| 427 |
+
self.progress.advance(self.eval_progress, advance=1)
|
| 428 |
+
self.progress.update(self.eval_progress, show_info='step: {}/{}'.format(step, eval_steps))
|
| 429 |
+
|
| 430 |
+
input_ids, input_mask = batch_data['input_ids'], batch_data['input_mask']
|
| 431 |
+
target_ids = batch_data['target_ids']
|
| 432 |
+
|
| 433 |
+
outputs = accelerator.unwrap_model(model).my_generate(
|
| 434 |
+
input_ids=input_ids,
|
| 435 |
+
attention_mask=input_mask,
|
| 436 |
+
max_seq_len=max_seq_len,
|
| 437 |
+
)
|
| 438 |
+
|
| 439 |
+
# gather data from multi-gpus (used when in ddp mode)
|
| 440 |
+
outputs = accelerator.gather_for_metrics(outputs).detach().cpu().numpy()
|
| 441 |
+
target_ids = accelerator.gather_for_metrics(target_ids).detach().cpu().numpy()
|
| 442 |
+
|
| 443 |
+
outputs = batch_decode(outputs, skip_special_tokens=True, clean_up_tokenization_spaces=False)
|
| 444 |
+
target_ids = batch_decode(target_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
|
| 445 |
+
|
| 446 |
+
# print(outputs, target_ids)
|
| 447 |
+
|
| 448 |
+
bleu4_scores = [get_bleu4_score(reference=target_ids[i], outputs=outputs[i]) for i in range(len(target_ids))]
|
| 449 |
+
bleu4_scores.extend(bleu4_scores)
|
| 450 |
+
|
| 451 |
+
# if step >= 5: break
|
| 452 |
+
|
| 453 |
+
avg_bleu4_score = my_average(bleu4_scores)
|
| 454 |
+
if accelerator.is_main_process:
|
| 455 |
+
self.progress.update(self.eval_progress, show_info='bleu4 score: {}'.format(avg_bleu4_score))
|
| 456 |
+
self.progress.update(self.eval_progress, visible=False)
|
| 457 |
+
|
| 458 |
+
return avg_bleu4_score
|
| 459 |
+
|
| 460 |
+
def test(self, best_epoch: int=0) -> None:
|
| 461 |
+
'''
|
| 462 |
+
'''
|
| 463 |
+
import os
|
| 464 |
+
|
| 465 |
+
train_config = self.train_config
|
| 466 |
+
log = self.logger
|
| 467 |
+
|
| 468 |
+
# args for dataloader
|
| 469 |
+
num_workers = 0 if self.is_win_platform else 4
|
| 470 |
+
|
| 471 |
+
test_dataset = MyDataset(
|
| 472 |
+
parquet_file=train_config.train_file,
|
| 473 |
+
tokenizer_dir=train_config.tokenizer_dir,
|
| 474 |
+
keep_in_memory=False if self.is_win_platform else True,
|
| 475 |
+
max_seq_len=train_config.max_seq_len,
|
| 476 |
+
)
|
| 477 |
+
|
| 478 |
+
test_dataloader = DataLoader(
|
| 479 |
+
test_dataset,
|
| 480 |
+
batch_size=train_config.batch_size_per_gpu,
|
| 481 |
+
shuffle=False,
|
| 482 |
+
collate_fn=test_dataset.collate_fn,
|
| 483 |
+
pin_memory=False,
|
| 484 |
+
num_workers=num_workers,
|
| 485 |
+
)
|
| 486 |
+
|
| 487 |
+
log.info('test dataset size: {}.'.format(len(test_dataset)), save_to_file=True)
|
| 488 |
+
|
| 489 |
+
set_seed(train_config.seed)
|
| 490 |
+
accelerator = Accelerator(mixed_precision=train_config.mixed_precision)
|
| 491 |
+
device = accelerator.device
|
| 492 |
+
log.info('using device: {} '.format(str(device)), save_to_file=True)
|
| 493 |
+
|
| 494 |
+
# 获取当前运行使用了多少个GPU
|
| 495 |
+
num_gpus_used = accelerator.state.num_processes
|
| 496 |
+
|
| 497 |
+
# 单机多卡,每个step总共的batch_size = batch_size_per_gpu * num_gpus_used
|
| 498 |
+
# total_batch_size 初始化为batch_size_per_gpu真的只有CPU的情况
|
| 499 |
+
total_batch_size = train_config.batch_size_per_gpu
|
| 500 |
+
if num_gpus_used >= 1:
|
| 501 |
+
total_batch_size = num_gpus_used * train_config.batch_size_per_gpu
|
| 502 |
+
|
| 503 |
+
# T5: All labels set to `-100` are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
|
| 504 |
+
tokenizer = test_dataset.tokenizer
|
| 505 |
+
|
| 506 |
+
model_file = train_config.model_file.format(best_epoch)
|
| 507 |
+
if os.path.isdir(model_file):
|
| 508 |
+
# 传入文件夹则 from_pretrained
|
| 509 |
+
model = TextToTextModel.from_pretrained(model_file)
|
| 510 |
+
else:
|
| 511 |
+
# load_state_dict
|
| 512 |
+
t5_config = get_T5_config(T5ModelConfig(), vocab_size=len(tokenizer), decoder_start_token_id=tokenizer.pad_token_id, eos_token_id=tokenizer.eos_token_id)
|
| 513 |
+
model = TextToTextModel(t5_config)
|
| 514 |
+
model.load_state_dict(torch.load(model_file, map_location='cpu')) # set cpu for no exception
|
| 515 |
+
|
| 516 |
+
model, test_dataloader = accelerator.prepare(
|
| 517 |
+
model,
|
| 518 |
+
test_dataloader,
|
| 519 |
+
)
|
| 520 |
+
|
| 521 |
+
steps = int(np.ceil(len(test_dataset) // total_batch_size))
|
| 522 |
+
|
| 523 |
+
bleu4 = 0.0
|
| 524 |
+
bleu4_scores = []
|
| 525 |
+
batch_decode = tokenizer.batch_decode
|
| 526 |
+
max_seq_len = self.train_config.max_seq_len
|
| 527 |
+
model.eval()
|
| 528 |
+
|
| 529 |
+
if accelerator.is_main_process:
|
| 530 |
+
progress = Progress(TextColumn("[progress.description]{task.description}"),
|
| 531 |
+
BarColumn(),
|
| 532 |
+
TextColumn("[progress.percentage]{task.percentage:>3.0f}%"),
|
| 533 |
+
TimeRemainingColumn(),
|
| 534 |
+
TimeElapsedColumn(),
|
| 535 |
+
TextColumn("[bold blue]{task.fields[show_info]}"),
|
| 536 |
+
refresh_per_second=1.0,
|
| 537 |
+
)
|
| 538 |
+
|
| 539 |
+
steps_progress = progress.add_task(description='steps: ', show_info='', total=steps)
|
| 540 |
+
progress.start()
|
| 541 |
+
|
| 542 |
+
with torch.no_grad():
|
| 543 |
+
for step, batch_data in enumerate(test_dataloader):
|
| 544 |
+
|
| 545 |
+
if accelerator.is_main_process:
|
| 546 |
+
progress.advance(steps_progress, advance=1)
|
| 547 |
+
progress.update(steps_progress, show_info='step: {}/{}'.format(step, steps))
|
| 548 |
+
|
| 549 |
+
input_ids, input_mask = batch_data['input_ids'], batch_data['input_mask']
|
| 550 |
+
target_ids = batch_data['target_ids']
|
| 551 |
+
|
| 552 |
+
# s = time.time()
|
| 553 |
+
outputs = accelerator.unwrap_model(model).my_generate(
|
| 554 |
+
input_ids=input_ids,
|
| 555 |
+
attention_mask=input_mask,
|
| 556 |
+
max_seq_len=max_seq_len,
|
| 557 |
+
)
|
| 558 |
+
# accelerator.print('generate used: {}'.format(time.time() - s))
|
| 559 |
+
|
| 560 |
+
# gather data from multi-gpus (used when in ddp mode)
|
| 561 |
+
outputs = accelerator.gather_for_metrics(outputs).cpu().numpy()
|
| 562 |
+
target_ids = accelerator.gather_for_metrics(target_ids).cpu().numpy()
|
| 563 |
+
|
| 564 |
+
outputs = batch_decode(outputs, skip_special_tokens=True, clean_up_tokenization_spaces=False)
|
| 565 |
+
target_ids = batch_decode(target_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
|
| 566 |
+
|
| 567 |
+
# print('outputs: {}'.format(outputs[0:5]))
|
| 568 |
+
# print('target_ids: {}'.format(target_ids[0:5]))
|
| 569 |
+
# print()
|
| 570 |
+
|
| 571 |
+
|
| 572 |
+
bleu4_scores = [get_bleu4_score(reference=target_ids[i], outputs=outputs[i]) for i in range(len(target_ids))]
|
| 573 |
+
bleu4_scores.extend(bleu4_scores)
|
| 574 |
+
|
| 575 |
+
# if step >= 10: break
|
| 576 |
+
|
| 577 |
+
avg_bleu4_score = my_average(bleu4_scores)
|
| 578 |
+
if accelerator.is_main_process:
|
| 579 |
+
progress.update(steps_progress, show_info='bleu4 score: {}'.format(avg_bleu4_score))
|
| 580 |
+
|
| 581 |
+
info_txt = 'test_dataset_size: {}, avg_bleu4_score:{}.'.format(len(test_dataset), avg_bleu4_score)
|
| 582 |
+
log.info(info_txt, save_to_file=True)
|
| 583 |
+
|
| 584 |
+
return avg_bleu4_score
|
| 585 |
+
|
| 586 |
+
|
| 587 |
+
def print_and_log(self, info: str, accelerator: Accelerator=None) -> None:
|
| 588 |
+
'''
|
| 589 |
+
使用accelerator.print, 否则多进程打印会异常
|
| 590 |
+
'''
|
| 591 |
+
if not accelerator:
|
| 592 |
+
print(info)
|
| 593 |
+
else:
|
| 594 |
+
accelerator.print(info)
|
| 595 |
+
self.logger.info(info, std_out=False, save_to_file=True)
|
| 596 |
+
|
| 597 |
+
if __name__ == '__main__':
|
| 598 |
+
|
| 599 |
+
# trainer = ChatTrainer()
|
| 600 |
+
train_config = TrainConfig()
|
| 601 |
+
model_config = T5ModelConfig()
|
| 602 |
+
|
| 603 |
+
chat_trainer = ChatTrainer(train_config=train_config, model_config=model_config)
|
| 604 |
+
|
| 605 |
+
chat_trainer.train()
|
| 606 |
+
# chat_trainer.test(best_epoch=0)
|
model_save/.gitattributes
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
model_save/README.md
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model_save/config.json
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "./model_save/dpo/",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"TextToTextModel"
|
| 5 |
+
],
|
| 6 |
+
"auto_map": {
|
| 7 |
+
"AutoModelForSeq2SeqLM": "modeling_chat_model.TextToTextModel"
|
| 8 |
+
},
|
| 9 |
+
"classifier_dropout": 0.0,
|
| 10 |
+
"d_ff": 3072,
|
| 11 |
+
"d_kv": 64,
|
| 12 |
+
"d_model": 768,
|
| 13 |
+
"decoder_start_token_id": 0,
|
| 14 |
+
"dense_act_fn": "relu",
|
| 15 |
+
"dropout_rate": 0.1,
|
| 16 |
+
"eos_token_id": 1,
|
| 17 |
+
"feed_forward_proj": "relu",
|
| 18 |
+
"initializer_factor": 1.0,
|
| 19 |
+
"is_encoder_decoder": true,
|
| 20 |
+
"is_gated_act": false,
|
| 21 |
+
"layer_norm_epsilon": 1e-06,
|
| 22 |
+
"model_type": "t5",
|
| 23 |
+
"num_decoder_layers": 10,
|
| 24 |
+
"num_heads": 12,
|
| 25 |
+
"num_layers": 10,
|
| 26 |
+
"pad_token_id": 0,
|
| 27 |
+
"relative_attention_max_distance": 128,
|
| 28 |
+
"relative_attention_num_buckets": 32,
|
| 29 |
+
"torch_dtype": "float32",
|
| 30 |
+
"transformers_version": "4.36.2",
|
| 31 |
+
"use_cache": true,
|
| 32 |
+
"vocab_size": 29298
|
| 33 |
+
}
|
model_save/configuration_chat_model.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import T5Config
|
| 2 |
+
|
| 3 |
+
class TextToTextModelConfig(T5Config):
|
| 4 |
+
model_type = 't5'
|
model_save/generation_config.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"decoder_start_token_id": 0,
|
| 4 |
+
"eos_token_id": 1,
|
| 5 |
+
"pad_token_id": 0,
|
| 6 |
+
"transformers_version": "4.36.2"
|
| 7 |
+
}
|
model_save/model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:054caeae92bcc13f0b6e7a12f86e75c8e18117279ecd89c4aa1f8ac74c95c02a
|
| 3 |
+
size 750794624
|
model_save/modeling_chat_model.py
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch import Tensor, LongTensor
|
| 3 |
+
from transformers import T5ForConditionalGeneration, T5Config
|
| 4 |
+
from transformers import TextIteratorStreamer
|
| 5 |
+
from transformers.generation.configuration_utils import GenerationConfig
|
| 6 |
+
|
| 7 |
+
class TextToTextModel(T5ForConditionalGeneration):
|
| 8 |
+
def __init__(self, config: T5Config) -> None:
|
| 9 |
+
'''
|
| 10 |
+
TextToTextModel继承T5ForConditionalGeneration
|
| 11 |
+
'''
|
| 12 |
+
super().__init__(config)
|
| 13 |
+
|
| 14 |
+
@torch.no_grad()
|
| 15 |
+
def my_generate(self,
|
| 16 |
+
input_ids: LongTensor,
|
| 17 |
+
attention_mask: LongTensor,
|
| 18 |
+
max_seq_len: int=256,
|
| 19 |
+
search_type: str='beam',
|
| 20 |
+
streamer: TextIteratorStreamer=None,
|
| 21 |
+
) -> Tensor:
|
| 22 |
+
'''
|
| 23 |
+
自定义gennerate方法方便调用、测试
|
| 24 |
+
search_type: ['greedy', 'beam', 'sampling', 'contrastive', ]
|
| 25 |
+
|
| 26 |
+
- *greedy decoding* by calling [`~generation.GenerationMixin.greedy_search`] if `num_beams=1` and
|
| 27 |
+
`do_sample=False`
|
| 28 |
+
- *contrastive search* by calling [`~generation.GenerationMixin.contrastive_search`] if `penalty_alpha>0.`
|
| 29 |
+
and `top_k>1`
|
| 30 |
+
- *multinomial sampling* by calling [`~generation.GenerationMixin.sample`] if `num_beams=1` and
|
| 31 |
+
`do_sample=True`
|
| 32 |
+
- *beam-search decoding* by calling [`~generation.GenerationMixin.beam_search`] if `num_beams>1` and
|
| 33 |
+
`do_sample=False`
|
| 34 |
+
- *beam-search multinomial sampling* by calling [`~generation.GenerationMixin.beam_sample`] if
|
| 35 |
+
`num_beams>1` and `do_sample=True`
|
| 36 |
+
'''
|
| 37 |
+
generation_config = GenerationConfig()
|
| 38 |
+
generation_config.remove_invalid_values = True
|
| 39 |
+
generation_config.eos_token_id = 1
|
| 40 |
+
generation_config.pad_token_id = 0
|
| 41 |
+
generation_config.decoder_start_token_id = self.config.decoder_start_token_id
|
| 42 |
+
generation_config.max_new_tokens = max_seq_len
|
| 43 |
+
# generation_config.repetition_penalty = 1.1 # 重复词惩罚
|
| 44 |
+
|
| 45 |
+
if search_type == 'greedy':
|
| 46 |
+
generation_config.num_beams = 1
|
| 47 |
+
generation_config.do_sample = False
|
| 48 |
+
elif search_type == 'beam':
|
| 49 |
+
generation_config.top_k = 50
|
| 50 |
+
generation_config.num_beams = 5
|
| 51 |
+
generation_config.do_sample = True
|
| 52 |
+
generation_config.top_p = 0.95
|
| 53 |
+
generation_config.no_repeat_ngram_size = 4
|
| 54 |
+
generation_config.length_penalty = -2.0
|
| 55 |
+
generation_config.early_stopping = True
|
| 56 |
+
elif search_type == 'sampling':
|
| 57 |
+
generation_config.num_beams = 1
|
| 58 |
+
generation_config.do_sample = True
|
| 59 |
+
generation_config.top_k = 50
|
| 60 |
+
generation_config.temperature = 0.98 # 越低概率越趋向于均匀分布
|
| 61 |
+
generation_config.top_p = 0.80
|
| 62 |
+
generation_config.no_repeat_ngram_size = 4
|
| 63 |
+
elif search_type == 'contrastive':
|
| 64 |
+
generation_config.penalty_alpha = 0.5
|
| 65 |
+
generation_config.top_k = 50
|
| 66 |
+
|
| 67 |
+
result = self.generate(
|
| 68 |
+
inputs=input_ids,
|
| 69 |
+
attention_mask=attention_mask,
|
| 70 |
+
generation_config=generation_config,
|
| 71 |
+
streamer=streamer,
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
return result
|
model_save/put_model_files_here
ADDED
|
File without changes
|
model_save/special_tokens_map.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"eos_token": "[EOS]",
|
| 3 |
+
"pad_token": "[PAD]",
|
| 4 |
+
"unk_token": "[UNK]"
|
| 5 |
+
}
|
model_save/tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model_save/tokenizer_config.json
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"0": {
|
| 4 |
+
"content": "[PAD]",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"1": {
|
| 12 |
+
"content": "[EOS]",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"2": {
|
| 20 |
+
"content": "[SEP]",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
},
|
| 27 |
+
"3": {
|
| 28 |
+
"content": "[BOS]",
|
| 29 |
+
"lstrip": false,
|
| 30 |
+
"normalized": false,
|
| 31 |
+
"rstrip": false,
|
| 32 |
+
"single_word": false,
|
| 33 |
+
"special": true
|
| 34 |
+
},
|
| 35 |
+
"4": {
|
| 36 |
+
"content": "[CLS]",
|
| 37 |
+
"lstrip": false,
|
| 38 |
+
"normalized": false,
|
| 39 |
+
"rstrip": false,
|
| 40 |
+
"single_word": false,
|
| 41 |
+
"special": true
|
| 42 |
+
},
|
| 43 |
+
"5": {
|
| 44 |
+
"content": "[MASK]",
|
| 45 |
+
"lstrip": false,
|
| 46 |
+
"normalized": false,
|
| 47 |
+
"rstrip": false,
|
| 48 |
+
"single_word": false,
|
| 49 |
+
"special": true
|
| 50 |
+
},
|
| 51 |
+
"6": {
|
| 52 |
+
"content": "[UNK]",
|
| 53 |
+
"lstrip": false,
|
| 54 |
+
"normalized": false,
|
| 55 |
+
"rstrip": false,
|
| 56 |
+
"single_word": false,
|
| 57 |
+
"special": true
|
| 58 |
+
}
|
| 59 |
+
},
|
| 60 |
+
"clean_up_tokenization_spaces": true,
|
| 61 |
+
"eos_token": "[EOS]",
|
| 62 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 63 |
+
"pad_token": "[PAD]",
|
| 64 |
+
"tokenizer_class": "PreTrainedTokenizerFast",
|
| 65 |
+
"unk_token": "[UNK]"
|
| 66 |
+
}
|
pre_train.py
ADDED
|
@@ -0,0 +1,136 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
import time
|
| 3 |
+
import os
|
| 4 |
+
import pandas as pd
|
| 5 |
+
from dataclasses import dataclass
|
| 6 |
+
import torch
|
| 7 |
+
from typing import Dict
|
| 8 |
+
|
| 9 |
+
from tqdm import tqdm
|
| 10 |
+
import numpy as np
|
| 11 |
+
from transformers import PreTrainedTokenizerFast, Seq2SeqTrainer, DataCollatorForSeq2Seq, Seq2SeqTrainingArguments
|
| 12 |
+
|
| 13 |
+
from transformers.generation.configuration_utils import GenerationConfig
|
| 14 |
+
from datasets import Dataset, load_dataset
|
| 15 |
+
|
| 16 |
+
from model.chat_model import TextToTextModel
|
| 17 |
+
from model.dataset import MyDataset
|
| 18 |
+
from config import TrainConfig, T5ModelConfig
|
| 19 |
+
|
| 20 |
+
from utils.functions import json_to_dataclass, get_T5_config, MyTrainerCallback
|
| 21 |
+
|
| 22 |
+
tqdm.pandas()
|
| 23 |
+
|
| 24 |
+
os.environ['TF_ENABLE_ONEDNN_OPTS'] = '0'
|
| 25 |
+
|
| 26 |
+
def get_dataset(file: str, split: str, tokenizer: PreTrainedTokenizerFast, cache_dir: str='.cache') -> Dataset:
|
| 27 |
+
"""
|
| 28 |
+
加载数据集
|
| 29 |
+
"""
|
| 30 |
+
dataset = load_dataset('parquet', data_files=file, split=split, cache_dir=cache_dir)
|
| 31 |
+
|
| 32 |
+
def tokens_to_ids(samples: dict) -> Dict[str, str]:
|
| 33 |
+
|
| 34 |
+
eos_token_id = tokenizer.eos_token_id
|
| 35 |
+
|
| 36 |
+
batch_prompt = samples['prompt']
|
| 37 |
+
batch_response = samples['response']
|
| 38 |
+
|
| 39 |
+
encoded_prompt = tokenizer(batch_prompt, truncation=False, padding=False, return_attention_mask=False,)
|
| 40 |
+
encoded_response = tokenizer(batch_response, truncation=False, padding=False, return_attention_mask=False,)
|
| 41 |
+
|
| 42 |
+
# vocab size 小于65535 可以用 uint16, 每个样本都要添加eos_token_id
|
| 43 |
+
input_ids = [np.array(item + [eos_token_id], dtype=np.uint16) for item in encoded_prompt["input_ids"]]
|
| 44 |
+
labels = [np.array(item + [eos_token_id], dtype=np.uint16) for item in encoded_response["input_ids"]]
|
| 45 |
+
|
| 46 |
+
return {
|
| 47 |
+
'input_ids': input_ids,
|
| 48 |
+
'labels': labels,
|
| 49 |
+
}
|
| 50 |
+
|
| 51 |
+
dataset = dataset.map(tokens_to_ids, batched=True, batch_size=8192, remove_columns=dataset.column_names)
|
| 52 |
+
|
| 53 |
+
return dataset
|
| 54 |
+
|
| 55 |
+
def pre_train(config: TrainConfig) -> None:
|
| 56 |
+
|
| 57 |
+
# step 1. 加载tokenizer
|
| 58 |
+
tokenizer = PreTrainedTokenizerFast.from_pretrained(config.tokenizer_dir)
|
| 59 |
+
|
| 60 |
+
# step 2. 加载模型配置文件
|
| 61 |
+
t5_config = get_T5_config(T5ModelConfig(), vocab_size=len(tokenizer), decoder_start_token_id=tokenizer.pad_token_id, eos_token_id=tokenizer.eos_token_id)
|
| 62 |
+
|
| 63 |
+
# step 3. 初始化模型
|
| 64 |
+
model = TextToTextModel(t5_config)
|
| 65 |
+
|
| 66 |
+
# Step 4: Load my dataset
|
| 67 |
+
dataset = get_dataset(file=config.train_file, split='train', tokenizer=tokenizer)
|
| 68 |
+
|
| 69 |
+
# Step 5: Define the training arguments
|
| 70 |
+
|
| 71 |
+
# T5属于sequence to sequence模型,故要使用Seq2SeqTrainingArguments、DataCollatorForSeq2Seq、Seq2SeqTrainer
|
| 72 |
+
# huggingface官网的sft工具适用于language model/LM模型
|
| 73 |
+
|
| 74 |
+
generation_config = GenerationConfig()
|
| 75 |
+
generation_config.remove_invalid_values = True
|
| 76 |
+
generation_config.eos_token_id = tokenizer.eos_token_id
|
| 77 |
+
generation_config.pad_token_id = tokenizer.pad_token_id
|
| 78 |
+
generation_config.decoder_start_token_id = tokenizer.pad_token_id
|
| 79 |
+
generation_config.max_new_tokens = 320
|
| 80 |
+
generation_config.num_beams = 1 # greedy search
|
| 81 |
+
generation_config.do_sample = False # greedy search
|
| 82 |
+
|
| 83 |
+
training_args = Seq2SeqTrainingArguments(
|
| 84 |
+
output_dir=config.output_dir,
|
| 85 |
+
per_device_train_batch_size=config.batch_size_per_gpu,
|
| 86 |
+
auto_find_batch_size=True, # 防止OOM
|
| 87 |
+
gradient_accumulation_steps=config.gradient_accumulation_steps,
|
| 88 |
+
learning_rate=config.learn_rate,
|
| 89 |
+
logging_steps=config.logging_steps,
|
| 90 |
+
num_train_epochs=config.epochs,
|
| 91 |
+
optim="adafactor",
|
| 92 |
+
report_to='tensorboard',
|
| 93 |
+
log_level='info',
|
| 94 |
+
save_steps=config.save_steps,
|
| 95 |
+
save_total_limit=3,
|
| 96 |
+
fp16=True if config.mixed_precision == 'fp16' else False,
|
| 97 |
+
bf16=True if config.mixed_precision == 'bf16' else False,
|
| 98 |
+
logging_first_step=True,
|
| 99 |
+
warmup_steps=config.warmup_steps,
|
| 100 |
+
seed=config.seed,
|
| 101 |
+
generation_config=generation_config,
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
# step 6: init my collator,
|
| 105 |
+
collator = DataCollatorForSeq2Seq(tokenizer, max_length=config.max_seq_len)
|
| 106 |
+
empty_cuda_cahce = MyTrainerCallback()
|
| 107 |
+
|
| 108 |
+
# Step 7: Define the Trainer
|
| 109 |
+
trainer = Seq2SeqTrainer(
|
| 110 |
+
model=model,
|
| 111 |
+
args=training_args,
|
| 112 |
+
train_dataset=dataset,
|
| 113 |
+
tokenizer=tokenizer,
|
| 114 |
+
data_collator=collator,
|
| 115 |
+
callbacks=[empty_cuda_cahce],
|
| 116 |
+
)
|
| 117 |
+
|
| 118 |
+
# step 8: train
|
| 119 |
+
trainer.train(
|
| 120 |
+
# resume_from_checkpoint=True
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
#step 9: save log
|
| 124 |
+
loss_log = pd.DataFrame(trainer.state.log_history)
|
| 125 |
+
log_dir = './logs'
|
| 126 |
+
if not os.path.exists(log_dir):
|
| 127 |
+
os.mkdir(log_dir)
|
| 128 |
+
loss_log.to_csv(f"{log_dir}/pre_train_log_{time.strftime('%Y%m%d-%H%M')}.csv")
|
| 129 |
+
|
| 130 |
+
# Step 10: Save the model
|
| 131 |
+
trainer.save_model(config.output_dir)
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
if __name__ == '__main__':
|
| 135 |
+
config = TrainConfig()
|
| 136 |
+
pre_train(config)
|
requirements.txt
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
accelerate==0.25.0
|
| 2 |
+
colorlog==6.8.0
|
| 3 |
+
datasets==2.15.0
|
| 4 |
+
datasketch==1.6.4
|
| 5 |
+
fastapi==0.109.1
|
| 6 |
+
fastparquet==2023.10.1
|
| 7 |
+
fire==0.5.0
|
| 8 |
+
jieba==0.42.1
|
| 9 |
+
matplotlib==3.8.2
|
| 10 |
+
modelscope==1.11.1
|
| 11 |
+
nltk==3.8.1
|
| 12 |
+
numpy==1.26.2
|
| 13 |
+
opencc_python_reimplemented==0.1.7
|
| 14 |
+
pandas==2.1.4
|
| 15 |
+
peft==0.6.2
|
| 16 |
+
psutil==5.9.6
|
| 17 |
+
pyarrow==14.0.1
|
| 18 |
+
pydantic==2.5.2
|
| 19 |
+
rich==13.7.0
|
| 20 |
+
safetensors==0.4.1
|
| 21 |
+
sentencepiece==0.1.99
|
| 22 |
+
tokenizers==0.15.0
|
| 23 |
+
torch==2.1.1
|
| 24 |
+
torch_optimizer==0.3.0
|
| 25 |
+
tqdm==4.66.1
|
| 26 |
+
transformers==4.36.0
|
| 27 |
+
trl==0.7.4
|
| 28 |
+
ujson==5.8.0
|
| 29 |
+
uvicorn==0.24.0.post1
|
sft_train.py
ADDED
|
@@ -0,0 +1,134 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
from typing import Dict
|
| 3 |
+
import time
|
| 4 |
+
import os
|
| 5 |
+
import pandas as pd
|
| 6 |
+
import numpy as np
|
| 7 |
+
import torch
|
| 8 |
+
from datasets import Dataset, load_dataset
|
| 9 |
+
from peft import LoraConfig
|
| 10 |
+
from tqdm import tqdm
|
| 11 |
+
from transformers import PreTrainedTokenizerFast, Seq2SeqTrainer, DataCollatorForSeq2Seq,Seq2SeqTrainingArguments
|
| 12 |
+
from transformers.generation.configuration_utils import GenerationConfig
|
| 13 |
+
|
| 14 |
+
from model.chat_model import TextToTextModel
|
| 15 |
+
from config import SFTconfig, T5ModelConfig
|
| 16 |
+
from utils.functions import get_T5_config, MyTrainerCallback
|
| 17 |
+
|
| 18 |
+
tqdm.pandas()
|
| 19 |
+
os.environ['TF_ENABLE_ONEDNN_OPTS'] = '0'
|
| 20 |
+
|
| 21 |
+
def get_dataset(file: str, split: str, tokenizer: PreTrainedTokenizerFast, cache_dir: str='.cache') -> Dataset:
|
| 22 |
+
"""
|
| 23 |
+
加载数据集
|
| 24 |
+
"""
|
| 25 |
+
|
| 26 |
+
# 加载json数据集,如果要加载parquet,更改为'parquet'即可
|
| 27 |
+
dataset = load_dataset('json', data_files=file, split=split, cache_dir=cache_dir)
|
| 28 |
+
|
| 29 |
+
def tokens_to_ids(samples: dict) -> Dict[str, str]:
|
| 30 |
+
|
| 31 |
+
eos_token_id = tokenizer.eos_token_id
|
| 32 |
+
|
| 33 |
+
batch_prompt = samples['prompt']
|
| 34 |
+
batch_response = samples['response']
|
| 35 |
+
|
| 36 |
+
encoded_prompt = tokenizer(batch_prompt, truncation=False, padding=False, return_attention_mask=False)
|
| 37 |
+
encoded_response = tokenizer(batch_response, truncation=False, padding=False, return_attention_mask=False)
|
| 38 |
+
|
| 39 |
+
# vocab size 小于65535 可以用 uint16, 每个样本都要添加eos_token_id
|
| 40 |
+
input_ids = [np.array(item + [eos_token_id], dtype=np.uint16) for item in encoded_prompt["input_ids"]]
|
| 41 |
+
labels = [np.array(item + [eos_token_id], dtype=np.uint16) for item in encoded_response["input_ids"]]
|
| 42 |
+
|
| 43 |
+
return {
|
| 44 |
+
'input_ids': input_ids,
|
| 45 |
+
'labels': labels,
|
| 46 |
+
}
|
| 47 |
+
|
| 48 |
+
dataset = dataset.map(tokens_to_ids, batched=True, batch_size=8192, remove_columns=dataset.column_names)
|
| 49 |
+
|
| 50 |
+
return dataset
|
| 51 |
+
|
| 52 |
+
def sft_train(config: SFTconfig) -> None:
|
| 53 |
+
|
| 54 |
+
# step 1. 加载tokenizer
|
| 55 |
+
tokenizer = PreTrainedTokenizerFast.from_pretrained(config.tokenizer_dir)
|
| 56 |
+
|
| 57 |
+
# step 2. 加载预训练模型
|
| 58 |
+
model = None
|
| 59 |
+
if os.path.isdir(config.finetune_from_ckp_file):
|
| 60 |
+
# 传入文件夹则 from_pretrained
|
| 61 |
+
model = TextToTextModel.from_pretrained(config.finetune_from_ckp_file)
|
| 62 |
+
else:
|
| 63 |
+
# load_state_dict
|
| 64 |
+
t5_config = get_T5_config(T5ModelConfig(), vocab_size=len(tokenizer), decoder_start_token_id=tokenizer.pad_token_id, eos_token_id=tokenizer.eos_token_id)
|
| 65 |
+
model = TextToTextModel(t5_config)
|
| 66 |
+
model.load_state_dict(torch.load(config.finetune_from_ckp_file, map_location='cpu')) # set cpu for no exception
|
| 67 |
+
|
| 68 |
+
# Step 4: Load the dataset
|
| 69 |
+
dataset = get_dataset(file=config.sft_train_file, split="train", tokenizer=tokenizer)
|
| 70 |
+
|
| 71 |
+
# Step 5: Define the training arguments
|
| 72 |
+
# T5属于sequence to sequence模型,故要使用Seq2SeqTrainingArguments、DataCollatorForSeq2Seq、Seq2SeqTrainer
|
| 73 |
+
# huggingface官网的sft工具适用于language model/LM模型
|
| 74 |
+
generation_config = GenerationConfig()
|
| 75 |
+
generation_config.remove_invalid_values = True
|
| 76 |
+
generation_config.eos_token_id = tokenizer.eos_token_id
|
| 77 |
+
generation_config.pad_token_id = tokenizer.pad_token_id
|
| 78 |
+
generation_config.decoder_start_token_id = tokenizer.pad_token_id
|
| 79 |
+
generation_config.max_new_tokens = 320
|
| 80 |
+
generation_config.repetition_penalty = 1.5
|
| 81 |
+
generation_config.num_beams = 1 # greedy search
|
| 82 |
+
generation_config.do_sample = False # greedy search
|
| 83 |
+
|
| 84 |
+
training_args = Seq2SeqTrainingArguments(
|
| 85 |
+
output_dir=config.output_dir,
|
| 86 |
+
per_device_train_batch_size=config.batch_size,
|
| 87 |
+
auto_find_batch_size=True, # 防止OOM
|
| 88 |
+
gradient_accumulation_steps=config.gradient_accumulation_steps,
|
| 89 |
+
learning_rate=config.learning_rate,
|
| 90 |
+
logging_steps=config.logging_steps,
|
| 91 |
+
num_train_epochs=config.num_train_epochs,
|
| 92 |
+
optim="adafactor",
|
| 93 |
+
report_to='tensorboard',
|
| 94 |
+
log_level='info',
|
| 95 |
+
save_steps=config.save_steps,
|
| 96 |
+
save_total_limit=3,
|
| 97 |
+
fp16=config.fp16,
|
| 98 |
+
logging_first_step=config.logging_first_step,
|
| 99 |
+
warmup_steps=config.warmup_steps,
|
| 100 |
+
seed=config.seed,
|
| 101 |
+
generation_config=generation_config,
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
# step 6: init a collator
|
| 105 |
+
collator = DataCollatorForSeq2Seq(tokenizer, max_length=config.max_seq_len)
|
| 106 |
+
empty_cuda_cahce = MyTrainerCallback()
|
| 107 |
+
|
| 108 |
+
# Step 7: Define the Trainer
|
| 109 |
+
trainer = Seq2SeqTrainer(
|
| 110 |
+
model=model,
|
| 111 |
+
args=training_args,
|
| 112 |
+
train_dataset=dataset,
|
| 113 |
+
tokenizer=tokenizer,
|
| 114 |
+
data_collator=collator,
|
| 115 |
+
callbacks=[empty_cuda_cahce]
|
| 116 |
+
)
|
| 117 |
+
|
| 118 |
+
# step 8: train
|
| 119 |
+
trainer.train(
|
| 120 |
+
# resume_from_checkpoint=True
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
loss_log = pd.DataFrame(trainer.state.log_history)
|
| 124 |
+
log_dir = './logs'
|
| 125 |
+
if not os.path.exists(log_dir):
|
| 126 |
+
os.mkdir(log_dir)
|
| 127 |
+
loss_log.to_csv(f"{log_dir}/sft_train_log_{time.strftime('%Y%m%d-%H%M')}.csv")
|
| 128 |
+
|
| 129 |
+
# Step 9: Save the model
|
| 130 |
+
trainer.save_model(config.output_dir)
|
| 131 |
+
|
| 132 |
+
if __name__ == '__main__':
|
| 133 |
+
config = SFTconfig()
|
| 134 |
+
sft_train(config)
|
train.ipynb
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": null,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [],
|
| 8 |
+
"source": [
|
| 9 |
+
"from accelerate import notebook_launcher\n",
|
| 10 |
+
"import torch\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"from model.trainer import ChatTrainer\n",
|
| 13 |
+
"from config import TrainConfig, T5ModelConfig"
|
| 14 |
+
]
|
| 15 |
+
},
|
| 16 |
+
{
|
| 17 |
+
"cell_type": "code",
|
| 18 |
+
"execution_count": null,
|
| 19 |
+
"metadata": {},
|
| 20 |
+
"outputs": [],
|
| 21 |
+
"source": [
|
| 22 |
+
"train_config = TrainConfig()\n",
|
| 23 |
+
"model_config = T5ModelConfig()\n",
|
| 24 |
+
"\n",
|
| 25 |
+
"print(train_config)\n",
|
| 26 |
+
"print(model_config)\n",
|
| 27 |
+
"\n",
|
| 28 |
+
"gpu_count = torch.cuda.device_count()\n",
|
| 29 |
+
"print('gpu device count: {}'.format(gpu_count))\n",
|
| 30 |
+
"\n",
|
| 31 |
+
"chat_trainer = ChatTrainer(train_config=train_config, model_config=model_config)"
|
| 32 |
+
]
|
| 33 |
+
},
|
| 34 |
+
{
|
| 35 |
+
"cell_type": "code",
|
| 36 |
+
"execution_count": null,
|
| 37 |
+
"metadata": {},
|
| 38 |
+
"outputs": [],
|
| 39 |
+
"source": [
|
| 40 |
+
"train = chat_trainer.train\n",
|
| 41 |
+
"\n",
|
| 42 |
+
"# chat_trainer.train() args: is_keep_training: bool, is_finetune: bool\n",
|
| 43 |
+
"train_args = (False, False)\n",
|
| 44 |
+
"\n",
|
| 45 |
+
"# 使用notebook_launcher函数启动多卡训练\n",
|
| 46 |
+
"notebook_launcher(train, num_processes=gpu_count, args=train_args, mixed_precision=train_config.mixed_precision)"
|
| 47 |
+
]
|
| 48 |
+
},
|
| 49 |
+
{
|
| 50 |
+
"cell_type": "code",
|
| 51 |
+
"execution_count": null,
|
| 52 |
+
"metadata": {},
|
| 53 |
+
"outputs": [],
|
| 54 |
+
"source": [
|
| 55 |
+
"test = chat_trainer.test\n",
|
| 56 |
+
"notebook_launcher(test, num_processes=gpu_count, mixed_precision=train_config.mixed_precision)"
|
| 57 |
+
]
|
| 58 |
+
}
|
| 59 |
+
],
|
| 60 |
+
"metadata": {
|
| 61 |
+
"kernelspec": {
|
| 62 |
+
"display_name": "Python 3 (ipykernel)",
|
| 63 |
+
"language": "python",
|
| 64 |
+
"name": "python3"
|
| 65 |
+
},
|
| 66 |
+
"language_info": {
|
| 67 |
+
"codemirror_mode": {
|
| 68 |
+
"name": "ipython",
|
| 69 |
+
"version": 3
|
| 70 |
+
},
|
| 71 |
+
"file_extension": ".py",
|
| 72 |
+
"mimetype": "text/x-python",
|
| 73 |
+
"name": "python",
|
| 74 |
+
"nbconvert_exporter": "python",
|
| 75 |
+
"pygments_lexer": "ipython3",
|
| 76 |
+
"version": "3.10.12"
|
| 77 |
+
},
|
| 78 |
+
"orig_nbformat": 4
|
| 79 |
+
},
|
| 80 |
+
"nbformat": 4,
|
| 81 |
+
"nbformat_minor": 2
|
| 82 |
+
}
|