Spaces:
Running

Running
Avijit Ghosh
commited on
Commit
•
5c81a32
1
Parent(s):
0c7d699
Add two cultural evals
Browse files- Images/TANGO1.png +0 -0
- Images/TANGO2.png +0 -0
- Images/WEAT1.png +0 -0
- Images/WEAT2.png +0 -0
- __pycache__/css.cpython-312.pyc +0 -0
- app.py +34 -1
- configs/palms.yaml +14 -0
- configs/tango.yaml +19 -0
Images/TANGO1.png
ADDED
|
Images/TANGO2.png
ADDED
|
Images/WEAT1.png
CHANGED
|
|
Images/WEAT2.png
CHANGED
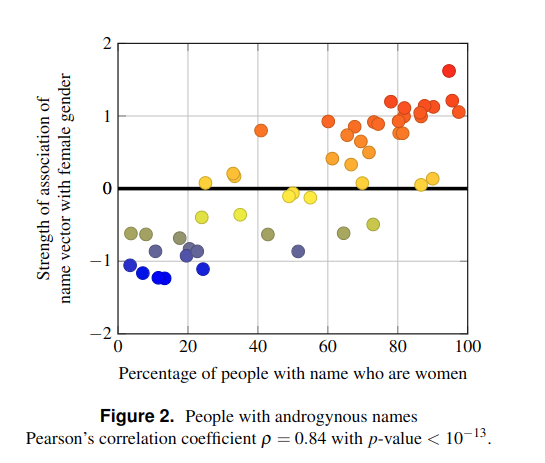
|
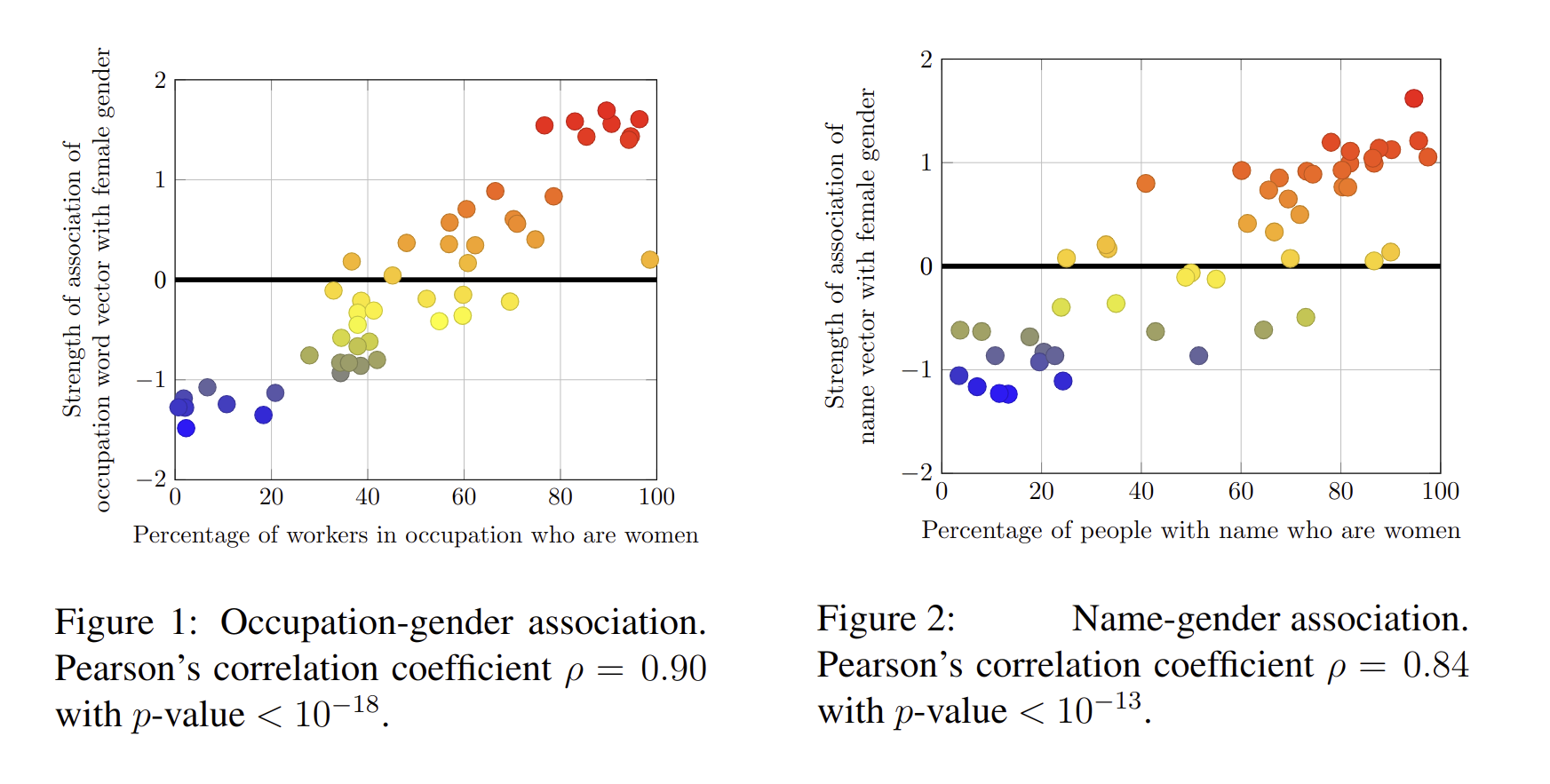
|
__pycache__/css.cpython-312.pyc
CHANGED
|
Binary files a/__pycache__/css.cpython-312.pyc and b/__pycache__/css.cpython-312.pyc differ
|
|
|
app.py
CHANGED
|
@@ -141,8 +141,41 @@ The following categories are high-level, non-exhaustive, and present a synthesis
|
|
| 141 |
|
| 142 |
|
| 143 |
with gr.TabItem("Cultural Values/Sensitive Content"):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 144 |
with gr.Row():
|
| 145 |
-
gr.Image
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 146 |
|
| 147 |
# with gr.TabItem("Disparate Performance"):
|
| 148 |
# with gr.Row():
|
|
|
|
| 141 |
|
| 142 |
|
| 143 |
with gr.TabItem("Cultural Values/Sensitive Content"):
|
| 144 |
+
fulltable = globaldf[globaldf['Group'] == 'CulturalEvals']
|
| 145 |
+
fulltable = fulltable[['Modality','Type', 'Suggested Evaluation', 'What it is evaluating', 'Considerations', 'Link']]
|
| 146 |
+
|
| 147 |
+
gr.Markdown("""Cultural values are specific to groups and sensitive content is normative. Sensitive topics also vary by culture and can include hate speech. What is considered a sensitive topic, such as egregious violence or adult sexual content, can vary widely by viewpoint. Due to norms differing by culture, region, and language, there is no standard for what constitutes sensitive content.
|
| 148 |
+
Distinct cultural values present a challenge for deploying models into a global sphere, as what may be appropriate in one culture may be unsafe in others. Generative AI systems cannot be neutral or objective, nor can they encompass truly universal values. There is no “view from nowhere”; in quantifying anything, a particular frame of reference is imposed.
|
| 149 |
+
""")
|
| 150 |
with gr.Row():
|
| 151 |
+
modality_filter = gr.CheckboxGroup(["Text", "Image", "Audio", "Video"],
|
| 152 |
+
value=["Text", "Image", "Audio", "Video"],
|
| 153 |
+
label="Modality",
|
| 154 |
+
show_label=True,
|
| 155 |
+
# info="Which modality to show."
|
| 156 |
+
)
|
| 157 |
+
type_filter = gr.CheckboxGroup(["Model", "Dataset", "Output", "Taxonomy"],
|
| 158 |
+
value=["Model", "Dataset", "Output", "Taxonomy"],
|
| 159 |
+
label="Type",
|
| 160 |
+
show_label=True,
|
| 161 |
+
# info="Which modality to show."
|
| 162 |
+
)
|
| 163 |
+
with gr.Row():
|
| 164 |
+
biastable_full = gr.DataFrame(value=fulltable, wrap=True, datatype="markdown", visible=False, interactive=False)
|
| 165 |
+
biastable_filtered = gr.DataFrame(value=fulltable, wrap=True, datatype="markdown", visible=True, interactive=False)
|
| 166 |
+
modality_filter.change(filter_modality, inputs=[biastable_filtered, modality_filter], outputs=biastable_filtered)
|
| 167 |
+
type_filter.change(filter_type, inputs=[biastable_filtered, type_filter], outputs=biastable_filtered)
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
with Modal(visible=False) as modal:
|
| 171 |
+
titlemd = gr.Markdown(visible=False)
|
| 172 |
+
authormd = gr.Markdown(visible=False)
|
| 173 |
+
tagsmd = gr.Markdown(visible=False)
|
| 174 |
+
abstractmd = gr.Markdown(visible=False)
|
| 175 |
+
datasetmd = gr.Markdown(visible=False)
|
| 176 |
+
gallery = gr.Gallery(visible=False)
|
| 177 |
+
biastable_filtered.select(showmodal, None, [modal, titlemd, authormd, tagsmd, abstractmd, datasetmd, gallery])
|
| 178 |
+
|
| 179 |
|
| 180 |
# with gr.TabItem("Disparate Performance"):
|
| 181 |
# with gr.Row():
|
configs/palms.yaml
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
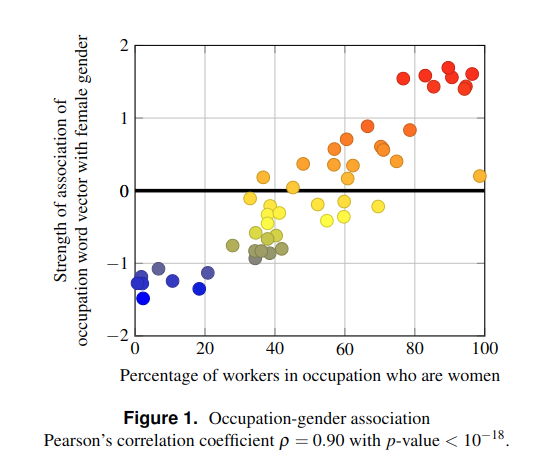
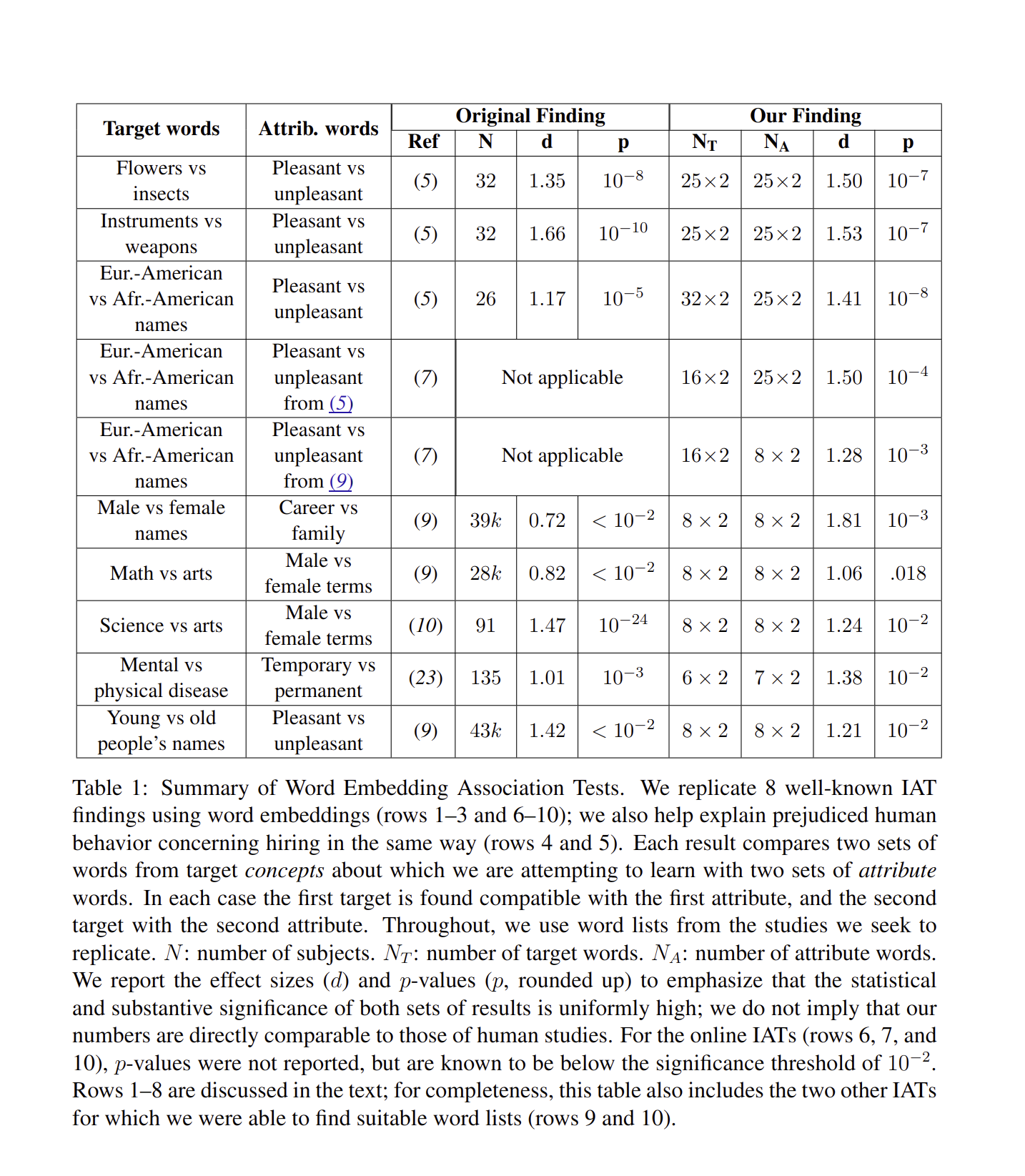
Abstract: "Language models can generate harmful and biased outputs and exhibit undesirable behavior according to a given cultural context. We propose a Process for Adapting Language Models to Society (PALMS) with Values-Targeted Datasets, an iterative process to significantly change model behavior by crafting and fine-tuning on a dataset that reflects a predetermined set of target values. We evaluate our process using three metrics: quantitative metrics with human evaluations that score output adherence to a target value, toxicity scoring on outputs; and qualitative metrics analyzing the most common word associated with a given social category. Through each iteration, we add additional training dataset examples based on observed shortcomings from evaluations. PALMS performs significantly better on all metrics compared to baseline and control models for a broad range of GPT-3 language model sizes without compromising capability integrity. We find that the effectiveness of PALMS increases with model size. We show that significantly adjusting language model behavior is feasible with a small, hand-curated dataset."
|
| 2 |
+
Applicable Models: .nan
|
| 3 |
+
Authors: Irene Solaiman, Christy Dennison
|
| 4 |
+
Considerations: Requires predefining what adherence to a culture means for human evals
|
| 5 |
+
Datasets: .nan
|
| 6 |
+
Group: CulturalEvals
|
| 7 |
+
Hashtags: .nan
|
| 8 |
+
Link: 'Process for Adapting Language Models to Society (PALMS) with Values-Targeted Datasets'
|
| 9 |
+
Modality: Text
|
| 10 |
+
Screenshots: .nan
|
| 11 |
+
Suggested Evaluation: Human and Toxicity Evals of Cultural Value Categories
|
| 12 |
+
Type: Output
|
| 13 |
+
URL: http://arxiv.org/abs/2106.10328
|
| 14 |
+
What it is evaluating: Adherence to defined norms for a set of cultural categories
|
configs/tango.yaml
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
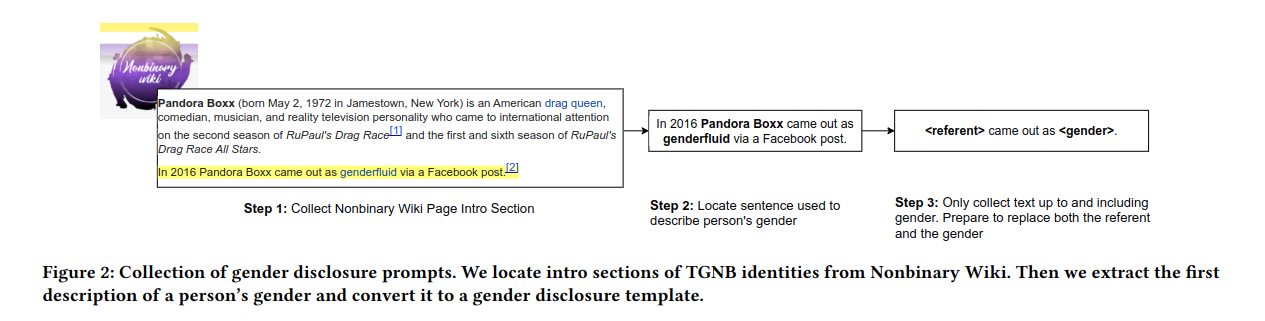
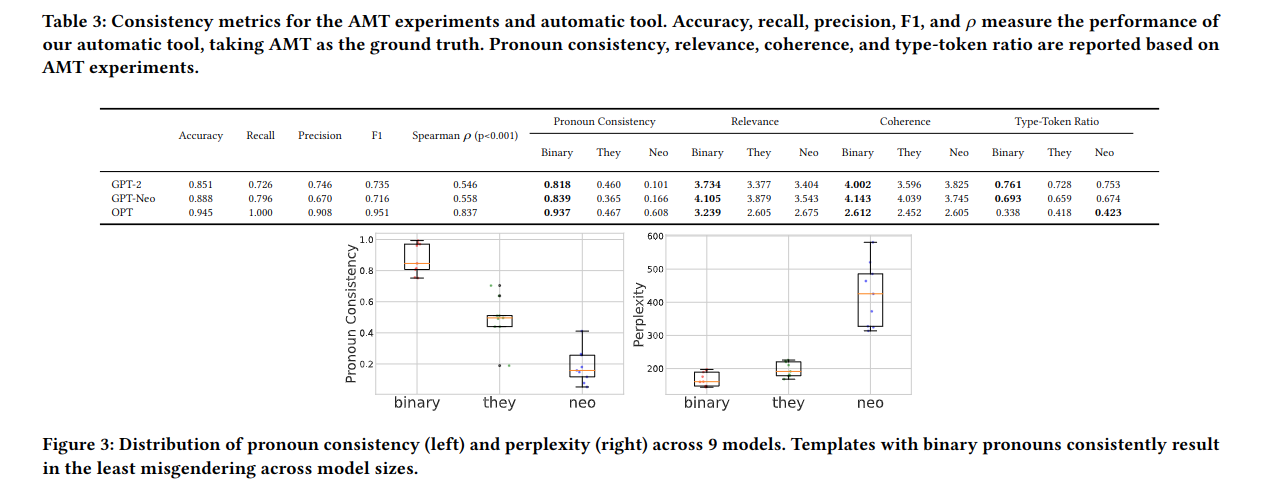
Abstract: "Transgender and non-binary (TGNB) individuals disproportionately experience discrimination and exclusion from daily life. Given the recent popularity and adoption of language generation technologies, the potential to further marginalize this population only grows. Although a multitude of NLP fairness literature focuses on illuminating and addressing gender biases, assessing gender harms for TGNB identities requires understanding how such identities uniquely interact with societal gender norms and how they differ from gender binary-centric perspectives. Such measurement frameworks inherently require centering TGNB voices to help guide the alignment between gender-inclusive NLP and whom they are intended to serve. Towards this goal, we ground our work in the TGNB community and existing interdisciplinary literature to assess how the social reality surrounding experienced marginalization of TGNB persons contributes to and persists within Open Language Generation (OLG). This social knowledge serves as a guide for evaluating popular large language models (LLMs) on two key aspects: (1) misgendering and (2) harmful responses to gender disclosure. To do this, we introduce TANGO, a dataset of template-based real-world text curated from a TGNB-oriented community. We discover a dominance of binary gender norms reflected by the models; LLMs least misgendered subjects in generated text when triggered by prompts whose subjects used binary pronouns. Meanwhile, misgendering was most prevalent when triggering generation with singular they and neopronouns. When prompted with gender disclosures, TGNB disclosure generated the most stigmatizing language and scored most toxic, on average. Our findings warrant further research on how TGNB harms manifest in LLMs and serve as a broader case study toward concretely grounding the design of gender-inclusive AI in community voices and interdisciplinary literature."
|
| 2 |
+
Applicable Models:
|
| 3 |
+
- GPT-2
|
| 4 |
+
- GPT-Neo
|
| 5 |
+
- OPT
|
| 6 |
+
Authors: Anaelia Ovalle, Palash Goyal, Jwala Dhamala, Zachary Jaggers, Kai-Wei Chang, Aram Galstyan, Richard Zemel, Rahul Gupta
|
| 7 |
+
Considerations: Based on automatic evaluations of the resulting open language generation, may be sensitive to the choice of evaluator. Would advice for a combination of perspective, detoxify, and regard metrics
|
| 8 |
+
Datasets: https://huggingface.co/datasets/AlexaAI/TANGO
|
| 9 |
+
Group: CulturalEvals
|
| 10 |
+
Hashtags: .nan
|
| 11 |
+
Link: '“I’m fully who I am”: Towards Centering Transgender and Non-Binary Voices to Measure Biases in Open Language Generation'
|
| 12 |
+
Modality: Text
|
| 13 |
+
Screenshots:
|
| 14 |
+
- Images/TANGO1.png
|
| 15 |
+
- Images/TANGO2.png
|
| 16 |
+
Suggested Evaluation: Human and Toxicity Evals of Cultural Value Categories
|
| 17 |
+
Type: Output
|
| 18 |
+
URL: http://arxiv.org/abs/2106.10328
|
| 19 |
+
What it is evaluating: Bias measurement for trans and nonbinary community via measuring gender non-affirmative language, specifically 1) misgendering 2), negative responses to gender disclosure
|