Spaces:
Runtime error

Runtime error

We also released Github code dataset, a 1TB of code data from Github repositories in 32 programming languages. It was created from the public GitHub dataset on Google BigQuery. The dataset can be loaded in streaming mode if you don't want to download it because of memory limitations, this will create an iterable dataset:
from datasets import load_dataset
ds = load_dataset("lvwerra/github-code", streaming=True, split="train")
print(next(iter(ds)))
#OUTPUT:
{
'code': "import mod189 from './mod189';\nvar value=mod189+1;\nexport default value;\n",
'repo_name': 'MirekSz/webpack-es6-ts',
'path': 'app/mods/mod190.js',
'language': 'JavaScript',
'license': 'isc',
'size': 73
}
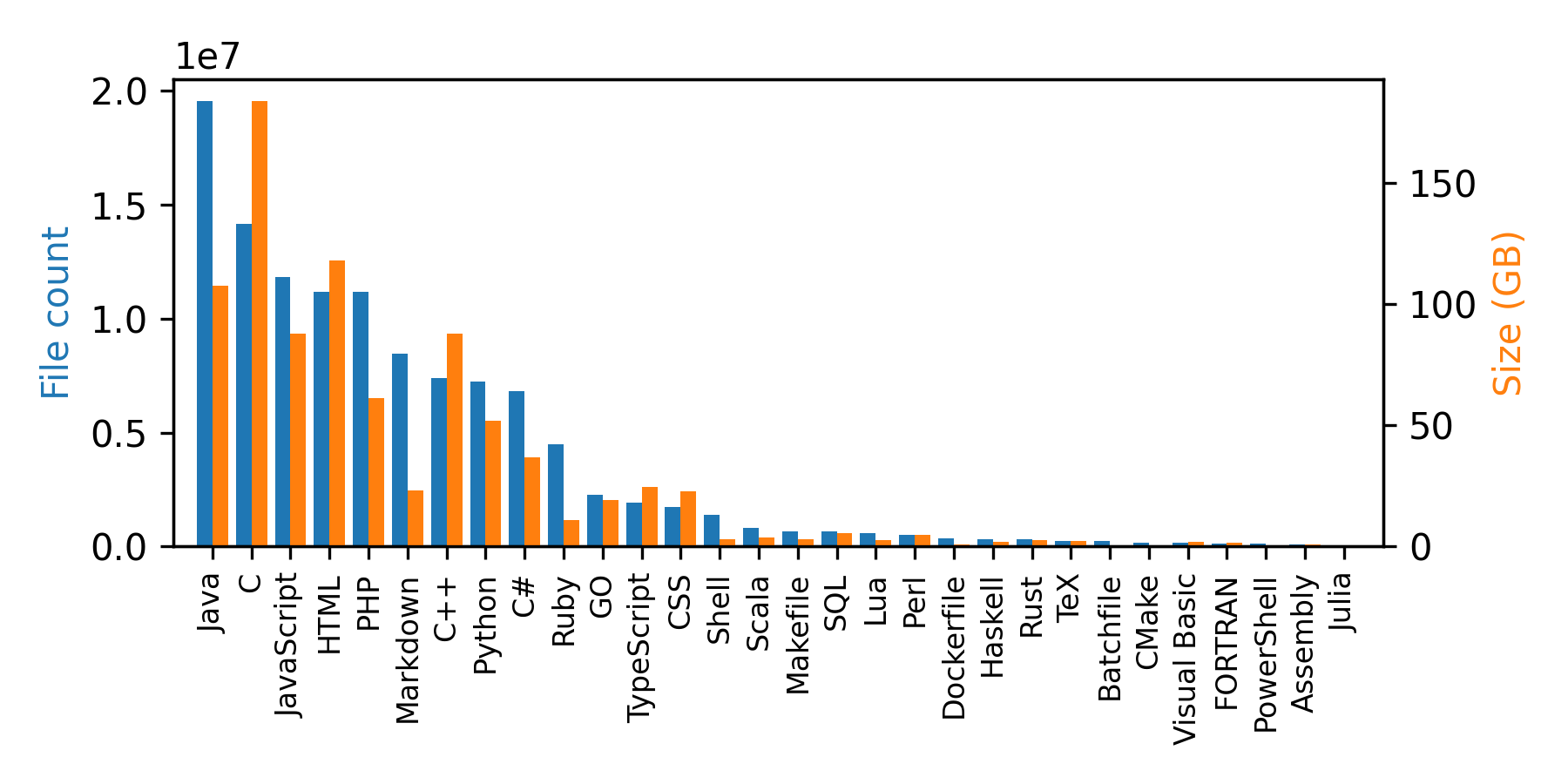
You can see that in addition to the code, the samples include some metadata: repo name, path, language, license, and the size of the file. Below is the distribution of programming languages in this dataset.
For model-specific information about the pretraining dataset, please select a model below: