Spaces:
Running

Running

Merge branch 'main' of https://huggingface.co/spaces/clip-italian/clip-italian-demo
Browse files# Conflicts:
# examples.py
# home.py
# image2text.py
# introduction.md
# text2image.py
- examples.py +13 -14
- introduction.md +12 -9
- static/img/table_captions.png +0 -0
examples.py
CHANGED
|
@@ -20,37 +20,36 @@ def app():
|
|
| 20 |
st.markdown("### 1. Actors in Scenes")
|
| 21 |
st.markdown("These examples were taken from the CC dataset")
|
| 22 |
|
| 23 |
-
st.subheader("
|
| 24 |
-
st.markdown("*
|
| 25 |
st.image("static/img/examples/couple_0.jpeg")
|
| 26 |
|
| 27 |
col1, col2 = st.beta_columns(2)
|
| 28 |
-
col1.subheader("
|
| 29 |
-
col1.markdown("*
|
| 30 |
col1.image("static/img/examples/couple_1.jpeg")
|
| 31 |
|
| 32 |
-
col2.subheader("
|
| 33 |
-
col2.markdown("*
|
| 34 |
col2.image("static/img/examples/couple_2.jpeg")
|
| 35 |
|
| 36 |
-
st.subheader("
|
| 37 |
-
st.markdown("*
|
| 38 |
st.image("static/img/examples/couple_3.jpeg")
|
| 39 |
|
| 40 |
st.markdown("### 2. Dresses")
|
| 41 |
st.markdown("These examples were taken from the Unsplash dataset")
|
| 42 |
|
| 43 |
col1, col2 = st.beta_columns(2)
|
| 44 |
-
col1.subheader("
|
| 45 |
-
col1.markdown("*
|
| 46 |
col1.image("static/img/examples/vestito1.png")
|
| 47 |
|
| 48 |
-
col2.subheader("
|
| 49 |
-
col2.markdown("*
|
| 50 |
col2.image("static/img/examples/vestito_autunnale.png")
|
| 51 |
|
| 52 |
-
|
| 53 |
-
st.markdown("<h2 style='text-align: center; color: #008C45; font-weight:bold;'> Zero Shot Image Classification </h2>", unsafe_allow_html=True)
|
| 54 |
st.markdown("We report this cool example provided by the "
|
| 55 |
"[DALLE-mini team](https://github.com/borisdayma/dalle-mini). "
|
| 56 |
"Is the DALLE-mini logo an *avocado* or an armchair (*poltrona*)?")
|
|
|
|
| 20 |
st.markdown("### 1. Actors in Scenes")
|
| 21 |
st.markdown("These examples were taken from the CC dataset")
|
| 22 |
|
| 23 |
+
st.subheader("Una coppia")
|
| 24 |
+
st.markdown("*A couple*")
|
| 25 |
st.image("static/img/examples/couple_0.jpeg")
|
| 26 |
|
| 27 |
col1, col2 = st.beta_columns(2)
|
| 28 |
+
col1.subheader("Una coppia con il tramonto sullo sfondo")
|
| 29 |
+
col1.markdown("*A couple with the sunset in the background*")
|
| 30 |
col1.image("static/img/examples/couple_1.jpeg")
|
| 31 |
|
| 32 |
+
col2.subheader("Una coppia che passeggia sulla spiaggia")
|
| 33 |
+
col2.markdown("*A couple walking on the beach*")
|
| 34 |
col2.image("static/img/examples/couple_2.jpeg")
|
| 35 |
|
| 36 |
+
st.subheader("Una coppia che passeggia sulla spiaggia al tramonto")
|
| 37 |
+
st.markdown("*A couple walking on the beach at sunset*")
|
| 38 |
st.image("static/img/examples/couple_3.jpeg")
|
| 39 |
|
| 40 |
st.markdown("### 2. Dresses")
|
| 41 |
st.markdown("These examples were taken from the Unsplash dataset")
|
| 42 |
|
| 43 |
col1, col2 = st.beta_columns(2)
|
| 44 |
+
col1.subheader("Un vestito primaverile")
|
| 45 |
+
col1.markdown("*A dress for the spring*")
|
| 46 |
col1.image("static/img/examples/vestito1.png")
|
| 47 |
|
| 48 |
+
col2.subheader("Un vestito autunnale")
|
| 49 |
+
col2.markdown("*A dress for the autumn*")
|
| 50 |
col2.image("static/img/examples/vestito_autunnale.png")
|
| 51 |
|
| 52 |
+
st.markdown("## Image Classification")
|
|
|
|
| 53 |
st.markdown("We report this cool example provided by the "
|
| 54 |
"[DALLE-mini team](https://github.com/borisdayma/dalle-mini). "
|
| 55 |
"Is the DALLE-mini logo an *avocado* or an armchair (*poltrona*)?")
|
introduction.md
CHANGED
|
@@ -36,6 +36,7 @@ different applications that can start from here.
|
|
| 36 |
The original CLIP model was trained on 400 million image-text pairs; this amount of data is currently not available for Italian.
|
| 37 |
We indeed worked in a **low-resource setting**. The only datasets for Italian captioning in the literature are MSCOCO-IT (a translated version of MSCOCO) and WIT.
|
| 38 |
To get competitive results, we followed three strategies:
|
|
|
|
| 39 |
1. more and better data;
|
| 40 |
2. better augmentations;
|
| 41 |
3. better training strategies.
|
|
@@ -82,7 +83,7 @@ Each photo comes along with an Italian caption.
|
|
| 82 |
|
| 83 |
Instead of relying on open-source translators, we decided to use DeepL. **Translation quality** of the data was the main
|
| 84 |
reason of this choice. With the few images (wrt OpenAI) that we have, we cannot risk polluting our own data. CC is a great resource,
|
| 85 |
-
but the captions have to be handled accordingly. We translated 700K captions and we evaluated their quality
|
| 86 |
|
| 87 |
Three of us looked at a sample of 100 of the translations and rated them with scores from 1 to 4.
|
| 88 |
The meaning of the value is as follows: 1, the sentence has lost is meaning, or it's not possible to understand it; 2, it is possible to get the idea
|
|
@@ -97,6 +98,8 @@ weighting - of 0.858 (great agreement!).
|
|
| 97 |
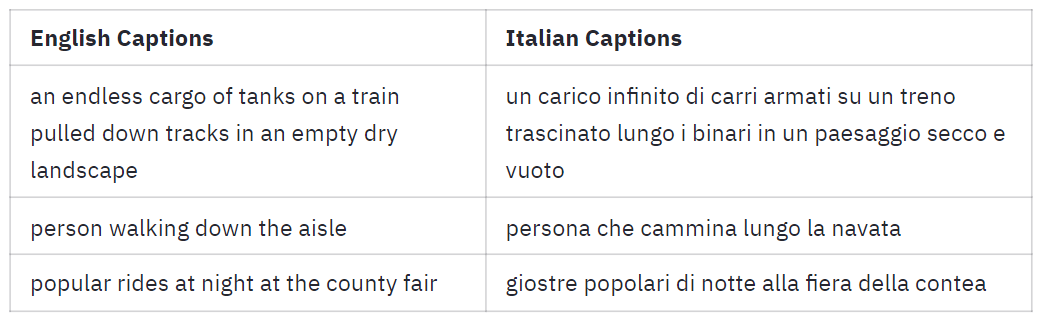
| person walking down the aisle | persona che cammina lungo la navata |
|
| 98 |
| popular rides at night at the county fair | giostre popolari di notte alla fiera della contea |
|
| 99 |
|
|
|
|
|
|
|
| 100 |
We know that we annotated our own data; in the spirit of fairness we also share the annotations and the captions so
|
| 101 |
that those interested can check the quality. The Google Sheet is [here](https://docs.google.com/spreadsheets/d/1m6TkcpJbmJlEygL7SXURIq2w8ZHuVvsmdEuCIH0VENk/edit?usp=sharing).
|
| 102 |
|
|
@@ -192,7 +195,7 @@ described by the original caption. As evaluation metrics we use the MRR@K.
|
|
| 192 |
| MRR@5 | **0.5039** | 0.3957|
|
| 193 |
| MRR@10 | **0.5204** | 0.4129|
|
| 194 |
|
| 195 |
-
_If the table above
|
| 196 |
|
| 197 |
It is true that we used the training set of MSCOCO-IT in training, and this might give us an advantage. However, the original CLIP model was trained
|
| 198 |
on 400million images (and some of them might have been from MSCOCO).
|
|
@@ -210,7 +213,7 @@ We evaluate the models computing the accuracy at different levels.
|
|
| 210 |
| Accuracy@10 | **52.55** | 42.91 |
|
| 211 |
| Accuracy@100 | **81.08** | 67.11 |
|
| 212 |
|
| 213 |
-
_If the table above doesn
|
| 214 |
|
| 215 |
### Discussion
|
| 216 |
|
|
@@ -233,24 +236,24 @@ Look at the following - slightly cherry picked - examples:
|
|
| 233 |
|
| 234 |
### Colors
|
| 235 |
Here's "a yellow flower"
|
| 236 |
-
<img src="https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/fiore_giallo.png" alt="drawing" width="
|
| 237 |
|
| 238 |
And here's "a blue flower"
|
| 239 |
-
<img src="https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/fiore_blu.png" alt="drawing" width="
|
| 240 |
|
| 241 |
### Counting
|
| 242 |
What about "one cat"?
|
| 243 |
-
<img src="https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/gatto.png" alt="drawing" width="
|
| 244 |
|
| 245 |
And what about "two cats"?
|
| 246 |
-
<img src="https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/due_gatti.png" alt="drawing" width="
|
| 247 |
|
| 248 |
### Complex Queries
|
| 249 |
Have you ever seen "two brown horses"?
|
| 250 |
-
<img src="https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/due_cavalli_marroni.png" alt="drawing" width="
|
| 251 |
|
| 252 |
And finally, here's a very nice "cat on a chair"
|
| 253 |
-
<img src="https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/gatto_su_sedia.png" alt="drawing" width="
|
| 254 |
|
| 255 |
|
| 256 |
# Broader Outlook
|
|
|
|
| 36 |
The original CLIP model was trained on 400 million image-text pairs; this amount of data is currently not available for Italian.
|
| 37 |
We indeed worked in a **low-resource setting**. The only datasets for Italian captioning in the literature are MSCOCO-IT (a translated version of MSCOCO) and WIT.
|
| 38 |
To get competitive results, we followed three strategies:
|
| 39 |
+
|
| 40 |
1. more and better data;
|
| 41 |
2. better augmentations;
|
| 42 |
3. better training strategies.
|
|
|
|
| 83 |
|
| 84 |
Instead of relying on open-source translators, we decided to use DeepL. **Translation quality** of the data was the main
|
| 85 |
reason of this choice. With the few images (wrt OpenAI) that we have, we cannot risk polluting our own data. CC is a great resource,
|
| 86 |
+
but the captions have to be handled accordingly. We translated 700K captions and we evaluated their quality.
|
| 87 |
|
| 88 |
Three of us looked at a sample of 100 of the translations and rated them with scores from 1 to 4.
|
| 89 |
The meaning of the value is as follows: 1, the sentence has lost is meaning, or it's not possible to understand it; 2, it is possible to get the idea
|
|
|
|
| 98 |
| person walking down the aisle | persona che cammina lungo la navata |
|
| 99 |
| popular rides at night at the county fair | giostre popolari di notte alla fiera della contea |
|
| 100 |
|
| 101 |
+
_If the table above doesn't show, you can have a look at it [here](https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/table_captions.png)._
|
| 102 |
+
|
| 103 |
We know that we annotated our own data; in the spirit of fairness we also share the annotations and the captions so
|
| 104 |
that those interested can check the quality. The Google Sheet is [here](https://docs.google.com/spreadsheets/d/1m6TkcpJbmJlEygL7SXURIq2w8ZHuVvsmdEuCIH0VENk/edit?usp=sharing).
|
| 105 |
|
|
|
|
| 195 |
| MRR@5 | **0.5039** | 0.3957|
|
| 196 |
| MRR@10 | **0.5204** | 0.4129|
|
| 197 |
|
| 198 |
+
_If the table above doesn't show, you can have a look at it [here](https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/table_imagenet.png)._
|
| 199 |
|
| 200 |
It is true that we used the training set of MSCOCO-IT in training, and this might give us an advantage. However, the original CLIP model was trained
|
| 201 |
on 400million images (and some of them might have been from MSCOCO).
|
|
|
|
| 213 |
| Accuracy@10 | **52.55** | 42.91 |
|
| 214 |
| Accuracy@100 | **81.08** | 67.11 |
|
| 215 |
|
| 216 |
+
_If the table above doesn't show, you can have a look at it [here](https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/table_IR.png)._
|
| 217 |
|
| 218 |
### Discussion
|
| 219 |
|
|
|
|
| 236 |
|
| 237 |
### Colors
|
| 238 |
Here's "a yellow flower"
|
| 239 |
+
<img src="https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/fiore_giallo.png" alt="drawing" width="500"/>
|
| 240 |
|
| 241 |
And here's "a blue flower"
|
| 242 |
+
<img src="https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/fiore_blu.png" alt="drawing" width="500"/>
|
| 243 |
|
| 244 |
### Counting
|
| 245 |
What about "one cat"?
|
| 246 |
+
<img src="https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/gatto.png" alt="drawing" width="500"/>
|
| 247 |
|
| 248 |
And what about "two cats"?
|
| 249 |
+
<img src="https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/due_gatti.png" alt="drawing" width="500"/>
|
| 250 |
|
| 251 |
### Complex Queries
|
| 252 |
Have you ever seen "two brown horses"?
|
| 253 |
+
<img src="https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/due_cavalli_marroni.png" alt="drawing" width="500"/>
|
| 254 |
|
| 255 |
And finally, here's a very nice "cat on a chair"
|
| 256 |
+
<img src="https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/gatto_su_sedia.png" alt="drawing" width="500"/>
|
| 257 |
|
| 258 |
|
| 259 |
# Broader Outlook
|
static/img/table_captions.png
ADDED
|