Spaces:
Running

Running
Silvia Terragni
commited on
Commit
•
944631b
1
Parent(s):
d88764c
added table image for captions
Browse files- introduction.md +3 -2
- static/img/table_captions.png +0 -0
introduction.md
CHANGED
|
@@ -99,6 +99,7 @@ weighting - of 0.858 (great agreement!).
|
|
| 99 |
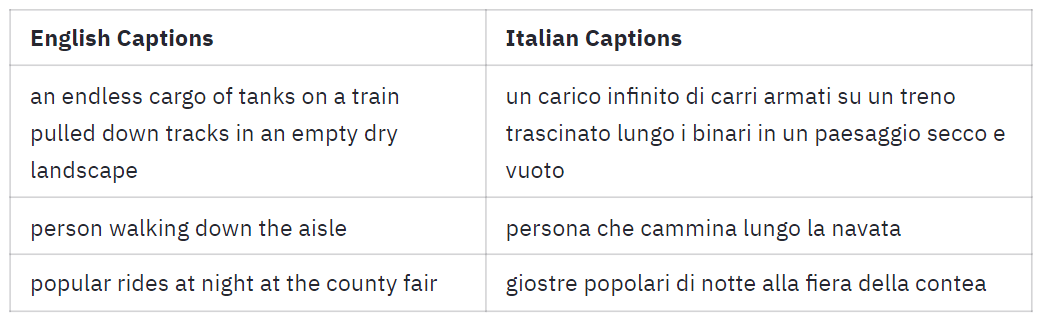
| person walking down the aisle | persona che cammina lungo la navata |
|
| 100 |
| popular rides at night at the county fair | giostre popolari di notte alla fiera della contea |
|
| 101 |
|
|
|
|
| 102 |
|
| 103 |
We know that we annotated our own data; in the spirit of fairness we also share the annotations and the captions so
|
| 104 |
that those interested can check the quality. The Google Sheet is [here](https://docs.google.com/spreadsheets/d/1m6TkcpJbmJlEygL7SXURIq2w8ZHuVvsmdEuCIH0VENk/edit?usp=sharing).
|
|
@@ -195,7 +196,7 @@ described by the original caption. As evaluation metrics we use the MRR@K.
|
|
| 195 |
| MRR@5 | **0.5039** | 0.3957|
|
| 196 |
| MRR@10 | **0.5204** | 0.4129|
|
| 197 |
|
| 198 |
-
_If the table above doesn
|
| 199 |
|
| 200 |
It is true that we used the training set of MSCOCO-IT in training, and this might give us an advantage. However, the original CLIP model was trained
|
| 201 |
on 400million images (and some of them might have been from MSCOCO).
|
|
@@ -213,7 +214,7 @@ We evaluate the models computing the accuracy at different levels.
|
|
| 213 |
| Accuracy@10 | **52.55** | 42.91 |
|
| 214 |
| Accuracy@100 | **81.08** | 67.11 |
|
| 215 |
|
| 216 |
-
_If the table above doesn
|
| 217 |
|
| 218 |
### Discussion
|
| 219 |
|
|
|
|
| 99 |
| person walking down the aisle | persona che cammina lungo la navata |
|
| 100 |
| popular rides at night at the county fair | giostre popolari di notte alla fiera della contea |
|
| 101 |
|
| 102 |
+
_If the table above doesn't show, you can have a look at it [here](https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/table_captions.png)._
|
| 103 |
|
| 104 |
We know that we annotated our own data; in the spirit of fairness we also share the annotations and the captions so
|
| 105 |
that those interested can check the quality. The Google Sheet is [here](https://docs.google.com/spreadsheets/d/1m6TkcpJbmJlEygL7SXURIq2w8ZHuVvsmdEuCIH0VENk/edit?usp=sharing).
|
|
|
|
| 196 |
| MRR@5 | **0.5039** | 0.3957|
|
| 197 |
| MRR@10 | **0.5204** | 0.4129|
|
| 198 |
|
| 199 |
+
_If the table above doesn't show, you can have a look at it [here](https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/table_imagenet.png)._
|
| 200 |
|
| 201 |
It is true that we used the training set of MSCOCO-IT in training, and this might give us an advantage. However, the original CLIP model was trained
|
| 202 |
on 400million images (and some of them might have been from MSCOCO).
|
|
|
|
| 214 |
| Accuracy@10 | **52.55** | 42.91 |
|
| 215 |
| Accuracy@100 | **81.08** | 67.11 |
|
| 216 |
|
| 217 |
+
_If the table above doesn't show, you can have a look at it [here](https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/table_IR.png)._
|
| 218 |
|
| 219 |
### Discussion
|
| 220 |
|
static/img/table_captions.png
ADDED
|