Spaces:
Running


Italian CLIP
With a few tricks, we have been able to fine-tune a competitive CLIP-italian model with only 1 million training samples.
In building this project we kept in mind the following things:
- Novel Contributions: we tried to bring something new to the table;
- Scientific Validity: models can look very cool, but external validation is important to assess the real impact;
- Broader Outlook: we always considered which are the possible usages for this model.
We put our hearts and souls in this project during this week! Not only we worked on a cool project, but we were able to meet new people and make new friends that worked together for a common goal! Thank you for this amazing opportunity, we hope you will like our project :heart:.
Novel Contributions
The original CLIP model was trained on 400millions text-image pairs; this amount of data is not available for Italian and the only datasets for captioning in the literature are MSCOCO-IT (translated version of MSCOCO) and WIT. To get competitive results we follewed three directions: 1) more data 2) better augmentation and 3) better training.
More Data
We eventually had to deal with the fact that we do not have the same data that OpenAI had during the training of CLIP. Thus, we opted for one choice, data of medium-high quality.
We considered three main sources of data:
WIT. Most of these captions describe ontological knowledge and encyclopedic facts (e.g., Roberto Baggio in 1994). However, this kind of text, without more information, is not useful to learn a good mapping between images and captions. On the other hand, this text is written in Italian and it is good quality. To prevent polluting the data with captions that are not meaningful, we used POS tagging on the data and removed all the captions that were composed for the 80% or more by PROPN.
MSCOCO-IT.
Conceptual Captions.
Better Augmentations
Better Training
After different trials, we realized that the usual way of training this model was not good enough to get good results. We thus modified two different parts of the training pipeline: the optimizer and the training with frozen components.
Optimizer
The standard AdamW didn't seem enough to train the model...
Backbone Freezing
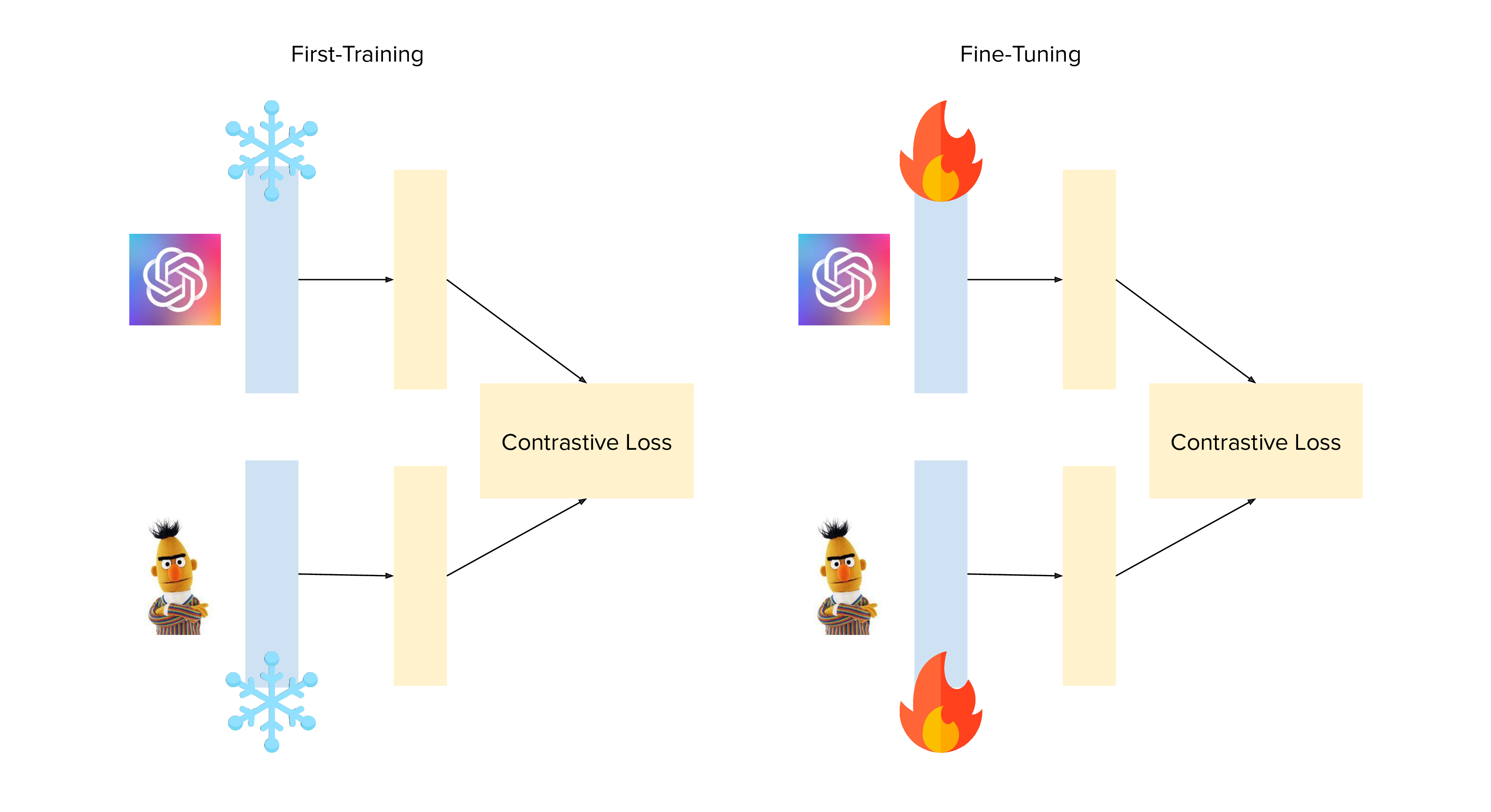
Scientific Validity
Quantitative Evaluation
Those images are definitely cool and interesting, but a model is nothing without validation. To better understand how well our clip-italian model works we run an experimental evaluation. Since this is the first clip-based model in Italian, we used the multilingual CLIP model as a comparison baseline.
mCLIP
Experiments Replication
We provide two colab notebooks to replicate both experiments.
Tasks
We selected two different tasks:
- image-retrieval
- zero-shot classification
Image Retrieval
| MRR | CLIP-Italian | mCLIP |
|---|---|---|
| MRR@1 | ||
| MRR@5 | ||
| MRR@10 |
Zero-shot classification
| Accuracy | CLIP-Italian | mCLIP |
|---|---|---|
| Accuracy@1 | ||
| Accuracy@5 | ||
| Accuracy@10 | ||
| Accuracy@100 | 81.08 | 67.11 |
Qualitative Evaluation
Broader Outlook
Other Notes
This readme has been designed using resources from Flaticon.com