Spaces:
Sleeping

A newer version of the Gradio SDK is available:
6.0.1
title: GenerativeChatBot
emoji: 👁
colorFrom: purple
colorTo: green
sdk: gradio
sdk_version: 4.19.2
app_file: app.py
pinned: false
Intro
In this repository, Natural Language Processing (NLP) techniques are used to explore the speech style of Rachel from the TV series Friends, perform a multi-lingual analysis for English, and train a neural network to communicate in Rachel's style. Style transfer is very popular in NLP, and is now being used in a wide range of applications, from education to personalising electronic assistants. And with the development of large transformer models that show outstanding abilities in natural language comprehension and imitation of a wide variety of styles, style transfer has reached a new level. Today, large language models such as GPT3, due to their volumes and billions of parameters, are able to perfectly learn all the features of the training sample (i.e., train distribution) and generate realistic text in a particular style. In this post, I explore the possibilities of language models to generate text in the style of Rachel from the famous TV series "Friends". For this purpose, a corpus of English transcripts of the TV series, which was collected for retrieval chatbot is used and trained bilingual models to communicate in the style of Rachel Green. In addition, I conducted a style analysis, studied the speech features of Rachel. Thus, the project can be roughly divided into 3 parts:
- data collection
- Stylistic analysis of the characters' speech
- Framework for training models that write text in the Rachel style You can find all the code in this HF repository.
Data
Selecting a character
I decided to continue to use TV series, which I settled in the previuos project, sitcom "Friends", which ran from 1994 to 2004. Despite its age, it is still popular today. This comedy series tells about the life of six friends (Ross, Phoebe, Monica, Rachel, Joey, and Chandler), who live in New York and constantly get into some trouble and funny situations. I did we choose this particular series? For three reasons:
I found transcripts of 236 episodes in the public domain. It's a lot of data, which i can use to train a language model.
The TV series contains dialogues of as many as six characters (rather than one), which opens me up to comparative analysis
This is a popular TV series that many of us have watched and know well. This means I can make assumptions about the data (e.g. Phoebe speaks in simpler words, etc.) and assess the realism of the style of the generated text based on my viewing experience.
Data collection
The original transcripts that I scraped from the Internet were in English. Then I performed the following preprocessing of the text:
Firstly, I cleaned the data from minor graphemic errors specific to the transcripts. For example, if a character said something long, his words might contain repetitions of vowels to imitate a long sound ("noooooooooooooooooooooo"). Other phrases contained repetitions of question and exclamation marks to imitate emotions in writing ("Noooooo!!!!", "WHATooooo????") Since such "errors" are quite non-standard, I wrote my our own system of data cleaning rules and applied it to transcripts.
Secondly, I noticed that some words contained repetitions of the same word for comicality. I also removed such repetitions, leaving only one copy of the repeated word.
Third, because I wanted to capture a style unique to each character, I threw out common phrases used by all 6 main characters ("You know what!", "Oh my god!", etc.).
Thus, I collected a corpus of dialogues for the 6 characters that included about 8k sentences for every character. You can see the detailed distribution by number of sentences for each character in the table below:

Data analysis
Number of replicas for all seasons are shown below:
 As could be seen that mean value of replicas over all seasons are 6000 with standard deviation about 400.
As could be seen that mean value of replicas over all seasons are 6000 with standard deviation about 400.
Number of replicas for all episodes are shown below:
 As could be seen mean value of replicas in episode are 265. Standard deviation is about 65 replicas.
As could be seen mean value of replicas in episode are 265. Standard deviation is about 65 replicas.
Most frequent words in dataset:

Analysing the styles of the characters
Before training the language patterns, I investigated the style features of Rachel. Specifically, to identify the speech features, I did the following:
Calculated descriptive statistics: number of words, average number of words per sentence, readability index, proportion of compound words, etc.
The most frequent words for the characters;
The proportion of positive and negative words.
From the plot above, we can draw tentative conclusions about the specifics of the characters' speech. For example, Ross and Rachel are the most talkative, they have the maximum number of sentences.
After this initial analysis of speech, I investigated the vocabulary in more detail and analysed it in terms of the complexity of the words used by the characters. We conventionally took long words consisting of more than 4 syllables as "difficult" words. The proportion of difficult words for each character can be seen in the graph below:
Most frequent Rachel words
I've done an analysis of Rachel's most frequent words, excluding stopwords from nltk.stopwords("english"). Result of this analysis is shown below.
 Or this data could be shown in image
Or this data could be shown in image

Data preparation
So we collected Rachel's phrases and split them into two datasets: replicas and phrases. For modelling purposes, we provided all replicas with an additional set of tokens and tags:
Special tokens and that denote the beginning and end of the example.
The character's name is written in capital letters.
A special pseudonym NOTFRIEND, which was a marker of the other speaker's replica in dialogue pairs "the replica of the NOTFRIED - the response of the HERO". We used such a pseudonym to separate other people's replicas from the hero whose style we want to mimic.
Using the data with additional tokens, I generated two datasets for Rachel in English. Below is a brief description of each of them:
- Raw monologues - a dataset containing individual lines of one of the characters. This dataset allows the model to get the most information about the style of a particular character.

- Raw dialogues - a dataset that contains the pairs "NON-Friend's cue - HERO's response", separated by a line break character \n. The dialogue dataset is needed because we want our model to be able to maintain a Friends-style conversation with the user, not just generate text.

Training
For training the model to transfer style of Rachel to chatbot I used several models. Models are trained in two stages. First stage, when the model tries to catch the personal of Rachel and learns her monologues. Second step the model tries to learn how the Rachel behaves in dialoges, so at this stage model is trained on dialogues.
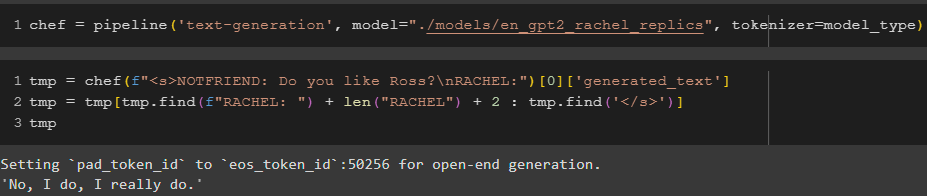
First one is GPT2. For datasets I used TextDataset by PyTorch and library transformers by huggingface. The results are shown on the image below
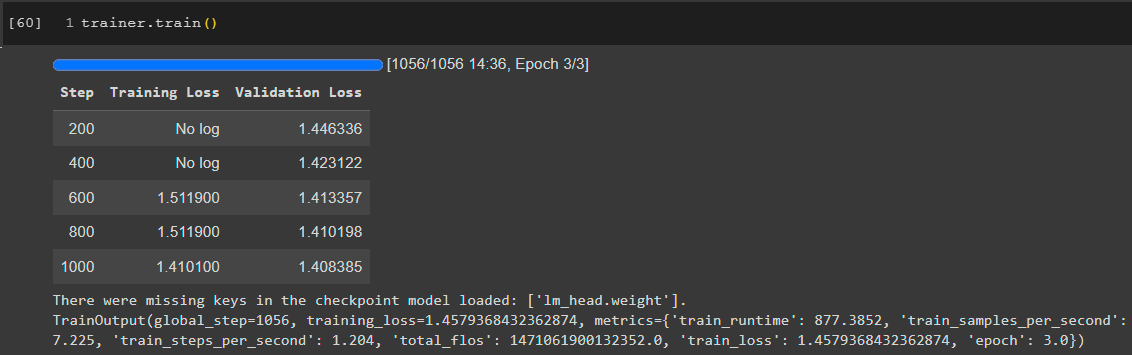
Second model is GPT2-medium. Training on monologues is shown below
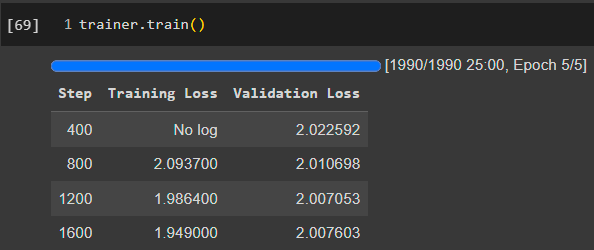
 Training on dialogues is shown on the next image
Training on dialogues is shown on the next image
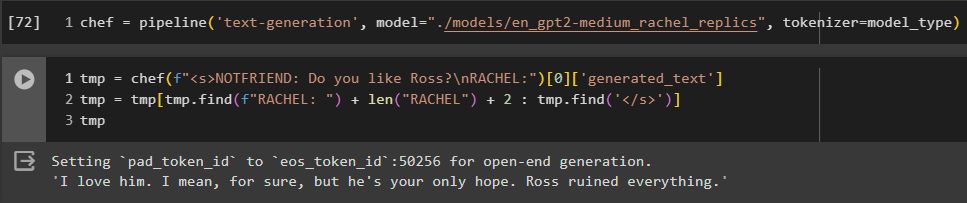
 Result of the training is shown below
Result of the training is shown below
Last model is GPT2-large. Training on monologues is shown below
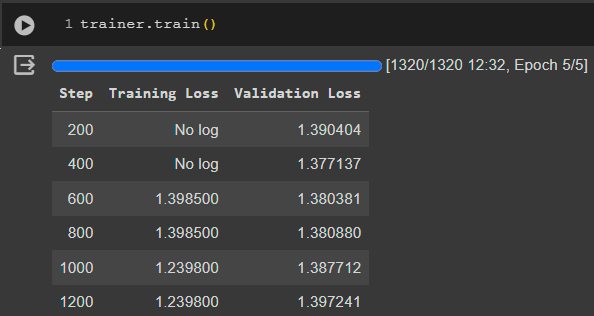 Training on dialogues is shown on the next image
Training on dialogues is shown on the next image
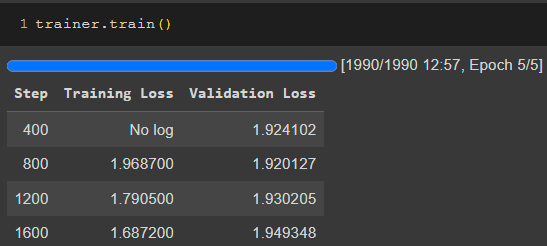 Result of the training is shown below
Result of the training is shown below
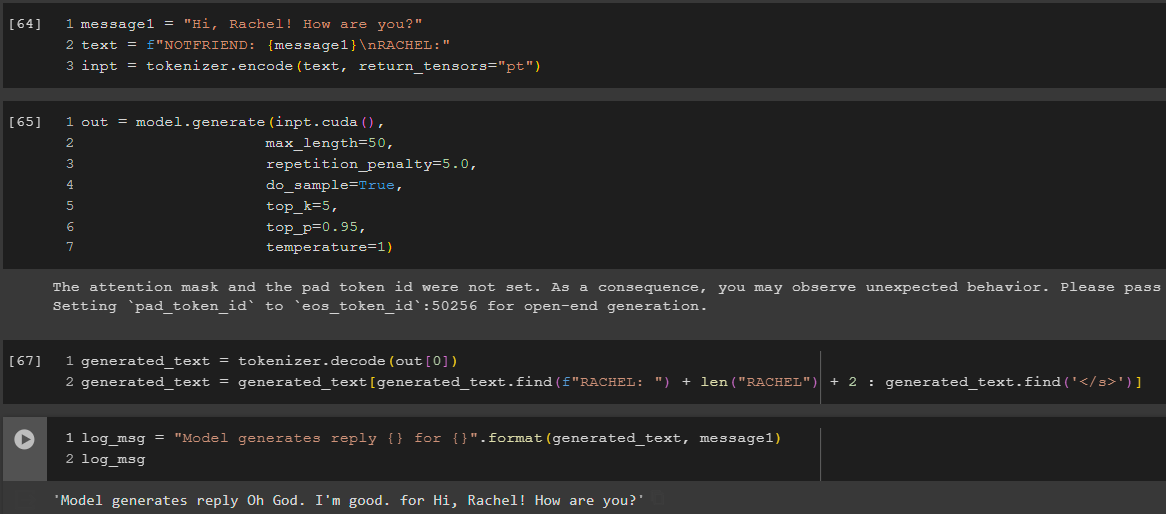







Architecture
- PrepareData.ipynb <- Parser data from the web, clean, tokenize and prepare for datasets
- train_data <- datasets folder with monologues and dialogs
- Training_gpt2_medium.ipynb <- training gpt2-medium
- en_gpt2-medium_rachel_replics <- gpt2-medium model
- Training_gpt2_large.ipynb <- training gpt2-large
- en_gpt2-large_rachel_replics <- gpt2-large model
- images <- images for README.md
- app.py <- main file
- requirements.txt <- needed libraries
Conclusion and future plans
So, I have used Natural Language Processing methods to study the speech style of Rachel from the famous TV series "Friends", performed multi-lingual analyses for English, and trained GPT-based language models to speak in the style of Rachel.
In the future, I want to experiment with even larger models. For example, with LLama, as well as methods of controlled text generation for them.