
Upload 66 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- Libtorch C++ Infer/VITS-LibTorch.cpp +121 -0
- Libtorch C++ Infer/toLibTorch.ipynb +142 -0
- attentions.py +303 -0
- commons.py +161 -0
- configs/chinese_base.json +55 -0
- configs/cjke_base.json +54 -0
- configs/cjks_base.json +55 -0
- configs/japanese_base.json +55 -0
- configs/japanese_base2.json +55 -0
- configs/japanese_ss_base2.json +54 -0
- configs/korean_base.json +55 -0
- configs/sanskrit_base.json +55 -0
- configs/shanghainese_base.json +55 -0
- configs/uma87.json +55 -0
- configs/yuzu.json +35 -0
- configs/zero_japanese_base2.json +55 -0
- configs/zh_ja_mixture_base.json +55 -0
- data_utils.py +393 -0
- flagged/log.csv +2 -0
- inference.py +40 -0
- losses.py +61 -0
- mel_processing.py +112 -0
- models.py +534 -0
- modules.py +390 -0
- monotonic_align/__init__.py +19 -0
- monotonic_align/__pycache__/__init__.cpython-37.pyc +0 -0
- monotonic_align/build/lib.win-amd64-cpython-37/monotonic_align/core.cp37-win_amd64.pyd +0 -0
- monotonic_align/build/temp.win-amd64-cpython-37/Release/core.cp37-win_amd64.exp +0 -0
- monotonic_align/build/temp.win-amd64-cpython-37/Release/core.cp37-win_amd64.lib +0 -0
- monotonic_align/build/temp.win-amd64-cpython-37/Release/core.obj +0 -0
- monotonic_align/core.c +0 -0
- monotonic_align/core.pyx +42 -0
- monotonic_align/monotonic_align/core.cp37-win_amd64.pyd +0 -0
- monotonic_align/setup.py +9 -0
- preprocess.py +25 -0
- pretrained_models/uma87_639000.pth +3 -0
- resources/fig_1a.png +0 -0
- resources/fig_1b.png +0 -0
- resources/training.png +0 -0
- text/LICENSE +19 -0
- text/__init__.py +56 -0
- text/__pycache__/__init__.cpython-37.pyc +0 -0
- text/__pycache__/cleaners.cpython-37.pyc +0 -0
- text/__pycache__/english.cpython-37.pyc +0 -0
- text/__pycache__/japanese.cpython-37.pyc +0 -0
- text/__pycache__/korean.cpython-37.pyc +0 -0
- text/__pycache__/mandarin.cpython-37.pyc +0 -0
- text/__pycache__/sanskrit.cpython-37.pyc +0 -0
- text/__pycache__/symbols.cpython-37.pyc +0 -0
- text/__pycache__/thai.cpython-37.pyc +0 -0
Libtorch C++ Infer/VITS-LibTorch.cpp
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#include <iostream>
|
| 2 |
+
#include <torch/torch.h>
|
| 3 |
+
#include <torch/script.h>
|
| 4 |
+
#include <string>
|
| 5 |
+
#include <vector>
|
| 6 |
+
#include <locale>
|
| 7 |
+
#include <codecvt>
|
| 8 |
+
#include <direct.h>
|
| 9 |
+
#include <fstream>
|
| 10 |
+
typedef int64_t int64;
|
| 11 |
+
namespace Shirakana {
|
| 12 |
+
|
| 13 |
+
struct WavHead {
|
| 14 |
+
char RIFF[4];
|
| 15 |
+
long int size0;
|
| 16 |
+
char WAVE[4];
|
| 17 |
+
char FMT[4];
|
| 18 |
+
long int size1;
|
| 19 |
+
short int fmttag;
|
| 20 |
+
short int channel;
|
| 21 |
+
long int samplespersec;
|
| 22 |
+
long int bytepersec;
|
| 23 |
+
short int blockalign;
|
| 24 |
+
short int bitpersamples;
|
| 25 |
+
char DATA[4];
|
| 26 |
+
long int size2;
|
| 27 |
+
};
|
| 28 |
+
|
| 29 |
+
int conArr2Wav(int64 size, int16_t* input, const char* filename) {
|
| 30 |
+
WavHead head = { {'R','I','F','F'},0,{'W','A','V','E'},{'f','m','t',' '},16,
|
| 31 |
+
1,1,22050,22050 * 2,2,16,{'d','a','t','a'},
|
| 32 |
+
0 };
|
| 33 |
+
head.size0 = size * 2 + 36;
|
| 34 |
+
head.size2 = size * 2;
|
| 35 |
+
std::ofstream ocout;
|
| 36 |
+
char* outputData = (char*)input;
|
| 37 |
+
ocout.open(filename, std::ios::out | std::ios::binary);
|
| 38 |
+
ocout.write((char*)&head, 44);
|
| 39 |
+
ocout.write(outputData, (int32_t)(size * 2));
|
| 40 |
+
ocout.close();
|
| 41 |
+
return 0;
|
| 42 |
+
}
|
| 43 |
+
|
| 44 |
+
inline std::wstring to_wide_string(const std::string& input)
|
| 45 |
+
{
|
| 46 |
+
std::wstring_convert<std::codecvt_utf8<wchar_t>> converter;
|
| 47 |
+
return converter.from_bytes(input);
|
| 48 |
+
}
|
| 49 |
+
|
| 50 |
+
inline std::string to_byte_string(const std::wstring& input)
|
| 51 |
+
{
|
| 52 |
+
std::wstring_convert<std::codecvt_utf8<wchar_t>> converter;
|
| 53 |
+
return converter.to_bytes(input);
|
| 54 |
+
}
|
| 55 |
+
}
|
| 56 |
+
|
| 57 |
+
#define val const auto
|
| 58 |
+
int main()
|
| 59 |
+
{
|
| 60 |
+
torch::jit::Module Vits;
|
| 61 |
+
std::string buffer;
|
| 62 |
+
std::vector<int64> text;
|
| 63 |
+
std::vector<int16_t> data;
|
| 64 |
+
while(true)
|
| 65 |
+
{
|
| 66 |
+
while (true)
|
| 67 |
+
{
|
| 68 |
+
std::cin >> buffer;
|
| 69 |
+
if (buffer == "end")
|
| 70 |
+
return 0;
|
| 71 |
+
if(buffer == "model")
|
| 72 |
+
{
|
| 73 |
+
std::cin >> buffer;
|
| 74 |
+
Vits = torch::jit::load(buffer);
|
| 75 |
+
continue;
|
| 76 |
+
}
|
| 77 |
+
if (buffer == "endinfer")
|
| 78 |
+
{
|
| 79 |
+
Shirakana::conArr2Wav(data.size(), data.data(), "temp\\tmp.wav");
|
| 80 |
+
data.clear();
|
| 81 |
+
std::cout << "endofinfe";
|
| 82 |
+
continue;
|
| 83 |
+
}
|
| 84 |
+
if (buffer == "line")
|
| 85 |
+
{
|
| 86 |
+
std::cin >> buffer;
|
| 87 |
+
while (buffer.find("endline")==std::string::npos)
|
| 88 |
+
{
|
| 89 |
+
text.push_back(std::atoi(buffer.c_str()));
|
| 90 |
+
std::cin >> buffer;
|
| 91 |
+
}
|
| 92 |
+
val InputTensor = torch::from_blob(text.data(), { 1,static_cast<int64>(text.size()) }, torch::kInt64);
|
| 93 |
+
std::array<int64, 1> TextLength{ static_cast<int64>(text.size()) };
|
| 94 |
+
val InputTensor_length = torch::from_blob(TextLength.data(), { 1 }, torch::kInt64);
|
| 95 |
+
std::vector<torch::IValue> inputs;
|
| 96 |
+
inputs.push_back(InputTensor);
|
| 97 |
+
inputs.push_back(InputTensor_length);
|
| 98 |
+
if (buffer.length() > 7)
|
| 99 |
+
{
|
| 100 |
+
std::array<int64, 1> speakerIndex{ (int64)atoi(buffer.substr(7).c_str()) };
|
| 101 |
+
inputs.push_back(torch::from_blob(speakerIndex.data(), { 1 }, torch::kLong));
|
| 102 |
+
}
|
| 103 |
+
val output = Vits.forward(inputs).toTuple()->elements()[0].toTensor().multiply(32276.0F);
|
| 104 |
+
val outputSize = output.sizes().at(2);
|
| 105 |
+
val floatOutput = output.data_ptr<float>();
|
| 106 |
+
int16_t* outputTmp = (int16_t*)malloc(sizeof(float) * outputSize);
|
| 107 |
+
if (outputTmp == nullptr) {
|
| 108 |
+
throw std::exception("内存不足");
|
| 109 |
+
}
|
| 110 |
+
for (int i = 0; i < outputSize; i++) {
|
| 111 |
+
*(outputTmp + i) = (int16_t) * (floatOutput + i);
|
| 112 |
+
}
|
| 113 |
+
data.insert(data.end(), outputTmp, outputTmp+outputSize);
|
| 114 |
+
free(outputTmp);
|
| 115 |
+
text.clear();
|
| 116 |
+
std::cout << "endofline";
|
| 117 |
+
}
|
| 118 |
+
}
|
| 119 |
+
}
|
| 120 |
+
//model S:\VSGIT\ShirakanaTTSUI\build\x64\Release\Mods\AtriVITS\AtriVITS_LJS.pt
|
| 121 |
+
}
|
Libtorch C++ Infer/toLibTorch.ipynb
ADDED
|
@@ -0,0 +1,142 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": null,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [],
|
| 8 |
+
"source": [
|
| 9 |
+
"%matplotlib inline\n",
|
| 10 |
+
"import matplotlib.pyplot as plt\n",
|
| 11 |
+
"import IPython.display as ipd\n",
|
| 12 |
+
"\n",
|
| 13 |
+
"import os\n",
|
| 14 |
+
"import json\n",
|
| 15 |
+
"import math\n",
|
| 16 |
+
"import torch\n",
|
| 17 |
+
"from torch import nn\n",
|
| 18 |
+
"from torch.nn import functional as F\n",
|
| 19 |
+
"from torch.utils.data import DataLoader\n",
|
| 20 |
+
"\n",
|
| 21 |
+
"import ../commons\n",
|
| 22 |
+
"import ../utils\n",
|
| 23 |
+
"from ../data_utils import TextAudioLoader, TextAudioCollate, TextAudioSpeakerLoader, TextAudioSpeakerCollate\n",
|
| 24 |
+
"from ../models import SynthesizerTrn\n",
|
| 25 |
+
"from ../text.symbols import symbols\n",
|
| 26 |
+
"from ../text import text_to_sequence\n",
|
| 27 |
+
"\n",
|
| 28 |
+
"from scipy.io.wavfile import write\n",
|
| 29 |
+
"\n",
|
| 30 |
+
"\n",
|
| 31 |
+
"def get_text(text, hps):\n",
|
| 32 |
+
" text_norm = text_to_sequence(text, hps.data.text_cleaners)\n",
|
| 33 |
+
" if hps.data.add_blank:\n",
|
| 34 |
+
" text_norm = commons.intersperse(text_norm, 0)\n",
|
| 35 |
+
" text_norm = torch.LongTensor(text_norm)\n",
|
| 36 |
+
" return text_norm"
|
| 37 |
+
]
|
| 38 |
+
},
|
| 39 |
+
{
|
| 40 |
+
"cell_type": "code",
|
| 41 |
+
"execution_count": null,
|
| 42 |
+
"metadata": {},
|
| 43 |
+
"outputs": [],
|
| 44 |
+
"source": [
|
| 45 |
+
"#############################################################\n",
|
| 46 |
+
"# #\n",
|
| 47 |
+
"# Single Speakers #\n",
|
| 48 |
+
"# #\n",
|
| 49 |
+
"#############################################################"
|
| 50 |
+
]
|
| 51 |
+
},
|
| 52 |
+
{
|
| 53 |
+
"cell_type": "code",
|
| 54 |
+
"execution_count": null,
|
| 55 |
+
"metadata": {},
|
| 56 |
+
"outputs": [],
|
| 57 |
+
"source": [
|
| 58 |
+
"hps = utils.get_hparams_from_file(\"configs/XXX.json\") #将\"\"内的内容修改为你的模型路径与config路径\n",
|
| 59 |
+
"net_g = SynthesizerTrn(\n",
|
| 60 |
+
" len(symbols),\n",
|
| 61 |
+
" hps.data.filter_length // 2 + 1,\n",
|
| 62 |
+
" hps.train.segment_size // hps.data.hop_length,\n",
|
| 63 |
+
" **hps.model).cuda()\n",
|
| 64 |
+
"_ = net_g.eval()\n",
|
| 65 |
+
"\n",
|
| 66 |
+
"_ = utils.load_checkpoint(\"/path/to/model.pth\", net_g, None)"
|
| 67 |
+
]
|
| 68 |
+
},
|
| 69 |
+
{
|
| 70 |
+
"cell_type": "code",
|
| 71 |
+
"execution_count": null,
|
| 72 |
+
"metadata": {},
|
| 73 |
+
"outputs": [],
|
| 74 |
+
"source": [
|
| 75 |
+
"stn_tst = get_text(\"こんにちは\", hps)\n",
|
| 76 |
+
"with torch.no_grad():\n",
|
| 77 |
+
" x_tst = stn_tst.cuda().unsqueeze(0)\n",
|
| 78 |
+
" x_tst_lengths = torch.LongTensor([stn_tst.size(0)]).cuda()\n",
|
| 79 |
+
" traced_mod = torch.jit.trace(net_g,(x_tst, x_tst_lengths,sid))\n",
|
| 80 |
+
" torch.jit.save(traced_mod,\"OUTPUTLIBTORCHMODEL.pt\")\n",
|
| 81 |
+
" audio = net_g.infer(x_tst, x_tst_lengths, noise_scale=.667, noise_scale_w=0.8, length_scale=1)[0][0,0].data.cpu().float().numpy()\n",
|
| 82 |
+
"ipd.display(ipd.Audio(audio, rate=hps.data.sampling_rate, normalize=False))"
|
| 83 |
+
]
|
| 84 |
+
},
|
| 85 |
+
{
|
| 86 |
+
"cell_type": "code",
|
| 87 |
+
"execution_count": null,
|
| 88 |
+
"metadata": {},
|
| 89 |
+
"outputs": [],
|
| 90 |
+
"source": [
|
| 91 |
+
"#############################################################\n",
|
| 92 |
+
"# #\n",
|
| 93 |
+
"# Multiple Speakers #\n",
|
| 94 |
+
"# #\n",
|
| 95 |
+
"#############################################################"
|
| 96 |
+
]
|
| 97 |
+
},
|
| 98 |
+
{
|
| 99 |
+
"cell_type": "code",
|
| 100 |
+
"execution_count": null,
|
| 101 |
+
"metadata": {},
|
| 102 |
+
"outputs": [],
|
| 103 |
+
"source": [
|
| 104 |
+
"hps = utils.get_hparams_from_file(\"./configs/XXX.json\") #将\"\"内的内容修改为你的模型路径与config路径\n",
|
| 105 |
+
"net_g = SynthesizerTrn(\n",
|
| 106 |
+
" len(symbols),\n",
|
| 107 |
+
" hps.data.filter_length // 2 + 1,\n",
|
| 108 |
+
" hps.train.segment_size // hps.data.hop_length,\n",
|
| 109 |
+
" n_speakers=hps.data.n_speakers,\n",
|
| 110 |
+
" **hps.model).cuda()\n",
|
| 111 |
+
"_ = net_g.eval()\n",
|
| 112 |
+
"\n",
|
| 113 |
+
"_ = utils.load_checkpoint(\"/path/to/model.pth\", net_g, None)"
|
| 114 |
+
]
|
| 115 |
+
},
|
| 116 |
+
{
|
| 117 |
+
"cell_type": "code",
|
| 118 |
+
"execution_count": null,
|
| 119 |
+
"metadata": {},
|
| 120 |
+
"outputs": [],
|
| 121 |
+
"source": [
|
| 122 |
+
"stn_tst = get_text(\"こんにちは\", hps)\n",
|
| 123 |
+
"with torch.no_grad():\n",
|
| 124 |
+
" x_tst = stn_tst.cuda().unsqueeze(0)\n",
|
| 125 |
+
" x_tst_lengths = torch.LongTensor([stn_tst.size(0)]).cuda()\n",
|
| 126 |
+
" sid = torch.LongTensor([4]).cuda()\n",
|
| 127 |
+
" traced_mod = torch.jit.trace(net_g,(x_tst, x_tst_lengths,sid))\n",
|
| 128 |
+
" torch.jit.save(traced_mod,\"OUTPUTLIBTORCHMODEL.pt\")\n",
|
| 129 |
+
" audio = net_g.infer(x_tst, x_tst_lengths, sid=sid, noise_scale=.667, noise_scale_w=0.8, length_scale=1)[0][0,0].data.cpu().float().numpy()\n",
|
| 130 |
+
"ipd.display(ipd.Audio(audio, rate=hps.data.sampling_rate, normalize=False))"
|
| 131 |
+
]
|
| 132 |
+
}
|
| 133 |
+
],
|
| 134 |
+
"metadata": {
|
| 135 |
+
"language_info": {
|
| 136 |
+
"name": "python"
|
| 137 |
+
},
|
| 138 |
+
"orig_nbformat": 4
|
| 139 |
+
},
|
| 140 |
+
"nbformat": 4,
|
| 141 |
+
"nbformat_minor": 2
|
| 142 |
+
}
|
attentions.py
ADDED
|
@@ -0,0 +1,303 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import math
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch
|
| 5 |
+
from torch import nn
|
| 6 |
+
from torch.nn import functional as F
|
| 7 |
+
|
| 8 |
+
import commons
|
| 9 |
+
import modules
|
| 10 |
+
from modules import LayerNorm
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class Encoder(nn.Module):
|
| 14 |
+
def __init__(self, hidden_channels, filter_channels, n_heads, n_layers, kernel_size=1, p_dropout=0., window_size=4, **kwargs):
|
| 15 |
+
super().__init__()
|
| 16 |
+
self.hidden_channels = hidden_channels
|
| 17 |
+
self.filter_channels = filter_channels
|
| 18 |
+
self.n_heads = n_heads
|
| 19 |
+
self.n_layers = n_layers
|
| 20 |
+
self.kernel_size = kernel_size
|
| 21 |
+
self.p_dropout = p_dropout
|
| 22 |
+
self.window_size = window_size
|
| 23 |
+
|
| 24 |
+
self.drop = nn.Dropout(p_dropout)
|
| 25 |
+
self.attn_layers = nn.ModuleList()
|
| 26 |
+
self.norm_layers_1 = nn.ModuleList()
|
| 27 |
+
self.ffn_layers = nn.ModuleList()
|
| 28 |
+
self.norm_layers_2 = nn.ModuleList()
|
| 29 |
+
for i in range(self.n_layers):
|
| 30 |
+
self.attn_layers.append(MultiHeadAttention(hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout, window_size=window_size))
|
| 31 |
+
self.norm_layers_1.append(LayerNorm(hidden_channels))
|
| 32 |
+
self.ffn_layers.append(FFN(hidden_channels, hidden_channels, filter_channels, kernel_size, p_dropout=p_dropout))
|
| 33 |
+
self.norm_layers_2.append(LayerNorm(hidden_channels))
|
| 34 |
+
|
| 35 |
+
def forward(self, x, x_mask):
|
| 36 |
+
attn_mask = x_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
|
| 37 |
+
x = x * x_mask
|
| 38 |
+
for i in range(self.n_layers):
|
| 39 |
+
y = self.attn_layers[i](x, x, attn_mask)
|
| 40 |
+
y = self.drop(y)
|
| 41 |
+
x = self.norm_layers_1[i](x + y)
|
| 42 |
+
|
| 43 |
+
y = self.ffn_layers[i](x, x_mask)
|
| 44 |
+
y = self.drop(y)
|
| 45 |
+
x = self.norm_layers_2[i](x + y)
|
| 46 |
+
x = x * x_mask
|
| 47 |
+
return x
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
class Decoder(nn.Module):
|
| 51 |
+
def __init__(self, hidden_channels, filter_channels, n_heads, n_layers, kernel_size=1, p_dropout=0., proximal_bias=False, proximal_init=True, **kwargs):
|
| 52 |
+
super().__init__()
|
| 53 |
+
self.hidden_channels = hidden_channels
|
| 54 |
+
self.filter_channels = filter_channels
|
| 55 |
+
self.n_heads = n_heads
|
| 56 |
+
self.n_layers = n_layers
|
| 57 |
+
self.kernel_size = kernel_size
|
| 58 |
+
self.p_dropout = p_dropout
|
| 59 |
+
self.proximal_bias = proximal_bias
|
| 60 |
+
self.proximal_init = proximal_init
|
| 61 |
+
|
| 62 |
+
self.drop = nn.Dropout(p_dropout)
|
| 63 |
+
self.self_attn_layers = nn.ModuleList()
|
| 64 |
+
self.norm_layers_0 = nn.ModuleList()
|
| 65 |
+
self.encdec_attn_layers = nn.ModuleList()
|
| 66 |
+
self.norm_layers_1 = nn.ModuleList()
|
| 67 |
+
self.ffn_layers = nn.ModuleList()
|
| 68 |
+
self.norm_layers_2 = nn.ModuleList()
|
| 69 |
+
for i in range(self.n_layers):
|
| 70 |
+
self.self_attn_layers.append(MultiHeadAttention(hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout, proximal_bias=proximal_bias, proximal_init=proximal_init))
|
| 71 |
+
self.norm_layers_0.append(LayerNorm(hidden_channels))
|
| 72 |
+
self.encdec_attn_layers.append(MultiHeadAttention(hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout))
|
| 73 |
+
self.norm_layers_1.append(LayerNorm(hidden_channels))
|
| 74 |
+
self.ffn_layers.append(FFN(hidden_channels, hidden_channels, filter_channels, kernel_size, p_dropout=p_dropout, causal=True))
|
| 75 |
+
self.norm_layers_2.append(LayerNorm(hidden_channels))
|
| 76 |
+
|
| 77 |
+
def forward(self, x, x_mask, h, h_mask):
|
| 78 |
+
"""
|
| 79 |
+
x: decoder input
|
| 80 |
+
h: encoder output
|
| 81 |
+
"""
|
| 82 |
+
self_attn_mask = commons.subsequent_mask(x_mask.size(2)).to(device=x.device, dtype=x.dtype)
|
| 83 |
+
encdec_attn_mask = h_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
|
| 84 |
+
x = x * x_mask
|
| 85 |
+
for i in range(self.n_layers):
|
| 86 |
+
y = self.self_attn_layers[i](x, x, self_attn_mask)
|
| 87 |
+
y = self.drop(y)
|
| 88 |
+
x = self.norm_layers_0[i](x + y)
|
| 89 |
+
|
| 90 |
+
y = self.encdec_attn_layers[i](x, h, encdec_attn_mask)
|
| 91 |
+
y = self.drop(y)
|
| 92 |
+
x = self.norm_layers_1[i](x + y)
|
| 93 |
+
|
| 94 |
+
y = self.ffn_layers[i](x, x_mask)
|
| 95 |
+
y = self.drop(y)
|
| 96 |
+
x = self.norm_layers_2[i](x + y)
|
| 97 |
+
x = x * x_mask
|
| 98 |
+
return x
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
class MultiHeadAttention(nn.Module):
|
| 102 |
+
def __init__(self, channels, out_channels, n_heads, p_dropout=0., window_size=None, heads_share=True, block_length=None, proximal_bias=False, proximal_init=False):
|
| 103 |
+
super().__init__()
|
| 104 |
+
assert channels % n_heads == 0
|
| 105 |
+
|
| 106 |
+
self.channels = channels
|
| 107 |
+
self.out_channels = out_channels
|
| 108 |
+
self.n_heads = n_heads
|
| 109 |
+
self.p_dropout = p_dropout
|
| 110 |
+
self.window_size = window_size
|
| 111 |
+
self.heads_share = heads_share
|
| 112 |
+
self.block_length = block_length
|
| 113 |
+
self.proximal_bias = proximal_bias
|
| 114 |
+
self.proximal_init = proximal_init
|
| 115 |
+
self.attn = None
|
| 116 |
+
|
| 117 |
+
self.k_channels = channels // n_heads
|
| 118 |
+
self.conv_q = nn.Conv1d(channels, channels, 1)
|
| 119 |
+
self.conv_k = nn.Conv1d(channels, channels, 1)
|
| 120 |
+
self.conv_v = nn.Conv1d(channels, channels, 1)
|
| 121 |
+
self.conv_o = nn.Conv1d(channels, out_channels, 1)
|
| 122 |
+
self.drop = nn.Dropout(p_dropout)
|
| 123 |
+
|
| 124 |
+
if window_size is not None:
|
| 125 |
+
n_heads_rel = 1 if heads_share else n_heads
|
| 126 |
+
rel_stddev = self.k_channels**-0.5
|
| 127 |
+
self.emb_rel_k = nn.Parameter(torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels) * rel_stddev)
|
| 128 |
+
self.emb_rel_v = nn.Parameter(torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels) * rel_stddev)
|
| 129 |
+
|
| 130 |
+
nn.init.xavier_uniform_(self.conv_q.weight)
|
| 131 |
+
nn.init.xavier_uniform_(self.conv_k.weight)
|
| 132 |
+
nn.init.xavier_uniform_(self.conv_v.weight)
|
| 133 |
+
if proximal_init:
|
| 134 |
+
with torch.no_grad():
|
| 135 |
+
self.conv_k.weight.copy_(self.conv_q.weight)
|
| 136 |
+
self.conv_k.bias.copy_(self.conv_q.bias)
|
| 137 |
+
|
| 138 |
+
def forward(self, x, c, attn_mask=None):
|
| 139 |
+
q = self.conv_q(x)
|
| 140 |
+
k = self.conv_k(c)
|
| 141 |
+
v = self.conv_v(c)
|
| 142 |
+
|
| 143 |
+
x, self.attn = self.attention(q, k, v, mask=attn_mask)
|
| 144 |
+
|
| 145 |
+
x = self.conv_o(x)
|
| 146 |
+
return x
|
| 147 |
+
|
| 148 |
+
def attention(self, query, key, value, mask=None):
|
| 149 |
+
# reshape [b, d, t] -> [b, n_h, t, d_k]
|
| 150 |
+
b, d, t_s, t_t = (*key.size(), query.size(2))
|
| 151 |
+
query = query.view(b, self.n_heads, self.k_channels, t_t).transpose(2, 3)
|
| 152 |
+
key = key.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
|
| 153 |
+
value = value.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
|
| 154 |
+
|
| 155 |
+
scores = torch.matmul(query / math.sqrt(self.k_channels), key.transpose(-2, -1))
|
| 156 |
+
if self.window_size is not None:
|
| 157 |
+
assert t_s == t_t, "Relative attention is only available for self-attention."
|
| 158 |
+
key_relative_embeddings = self._get_relative_embeddings(self.emb_rel_k, t_s)
|
| 159 |
+
rel_logits = self._matmul_with_relative_keys(query /math.sqrt(self.k_channels), key_relative_embeddings)
|
| 160 |
+
scores_local = self._relative_position_to_absolute_position(rel_logits)
|
| 161 |
+
scores = scores + scores_local
|
| 162 |
+
if self.proximal_bias:
|
| 163 |
+
assert t_s == t_t, "Proximal bias is only available for self-attention."
|
| 164 |
+
scores = scores + self._attention_bias_proximal(t_s).to(device=scores.device, dtype=scores.dtype)
|
| 165 |
+
if mask is not None:
|
| 166 |
+
scores = scores.masked_fill(mask == 0, -1e4)
|
| 167 |
+
if self.block_length is not None:
|
| 168 |
+
assert t_s == t_t, "Local attention is only available for self-attention."
|
| 169 |
+
block_mask = torch.ones_like(scores).triu(-self.block_length).tril(self.block_length)
|
| 170 |
+
scores = scores.masked_fill(block_mask == 0, -1e4)
|
| 171 |
+
p_attn = F.softmax(scores, dim=-1) # [b, n_h, t_t, t_s]
|
| 172 |
+
p_attn = self.drop(p_attn)
|
| 173 |
+
output = torch.matmul(p_attn, value)
|
| 174 |
+
if self.window_size is not None:
|
| 175 |
+
relative_weights = self._absolute_position_to_relative_position(p_attn)
|
| 176 |
+
value_relative_embeddings = self._get_relative_embeddings(self.emb_rel_v, t_s)
|
| 177 |
+
output = output + self._matmul_with_relative_values(relative_weights, value_relative_embeddings)
|
| 178 |
+
output = output.transpose(2, 3).contiguous().view(b, d, t_t) # [b, n_h, t_t, d_k] -> [b, d, t_t]
|
| 179 |
+
return output, p_attn
|
| 180 |
+
|
| 181 |
+
def _matmul_with_relative_values(self, x, y):
|
| 182 |
+
"""
|
| 183 |
+
x: [b, h, l, m]
|
| 184 |
+
y: [h or 1, m, d]
|
| 185 |
+
ret: [b, h, l, d]
|
| 186 |
+
"""
|
| 187 |
+
ret = torch.matmul(x, y.unsqueeze(0))
|
| 188 |
+
return ret
|
| 189 |
+
|
| 190 |
+
def _matmul_with_relative_keys(self, x, y):
|
| 191 |
+
"""
|
| 192 |
+
x: [b, h, l, d]
|
| 193 |
+
y: [h or 1, m, d]
|
| 194 |
+
ret: [b, h, l, m]
|
| 195 |
+
"""
|
| 196 |
+
ret = torch.matmul(x, y.unsqueeze(0).transpose(-2, -1))
|
| 197 |
+
return ret
|
| 198 |
+
|
| 199 |
+
def _get_relative_embeddings(self, relative_embeddings, length):
|
| 200 |
+
max_relative_position = 2 * self.window_size + 1
|
| 201 |
+
# Pad first before slice to avoid using cond ops.
|
| 202 |
+
pad_length = max(length - (self.window_size + 1), 0)
|
| 203 |
+
slice_start_position = max((self.window_size + 1) - length, 0)
|
| 204 |
+
slice_end_position = slice_start_position + 2 * length - 1
|
| 205 |
+
if pad_length > 0:
|
| 206 |
+
padded_relative_embeddings = F.pad(
|
| 207 |
+
relative_embeddings,
|
| 208 |
+
commons.convert_pad_shape([[0, 0], [pad_length, pad_length], [0, 0]]))
|
| 209 |
+
else:
|
| 210 |
+
padded_relative_embeddings = relative_embeddings
|
| 211 |
+
used_relative_embeddings = padded_relative_embeddings[:,slice_start_position:slice_end_position]
|
| 212 |
+
return used_relative_embeddings
|
| 213 |
+
|
| 214 |
+
def _relative_position_to_absolute_position(self, x):
|
| 215 |
+
"""
|
| 216 |
+
x: [b, h, l, 2*l-1]
|
| 217 |
+
ret: [b, h, l, l]
|
| 218 |
+
"""
|
| 219 |
+
batch, heads, length, _ = x.size()
|
| 220 |
+
# Concat columns of pad to shift from relative to absolute indexing.
|
| 221 |
+
x = F.pad(x, commons.convert_pad_shape([[0,0],[0,0],[0,0],[0,1]]))
|
| 222 |
+
|
| 223 |
+
# Concat extra elements so to add up to shape (len+1, 2*len-1).
|
| 224 |
+
x_flat = x.view([batch, heads, length * 2 * length])
|
| 225 |
+
x_flat = F.pad(x_flat, commons.convert_pad_shape([[0,0],[0,0],[0,length-1]]))
|
| 226 |
+
|
| 227 |
+
# Reshape and slice out the padded elements.
|
| 228 |
+
x_final = x_flat.view([batch, heads, length+1, 2*length-1])[:, :, :length, length-1:]
|
| 229 |
+
return x_final
|
| 230 |
+
|
| 231 |
+
def _absolute_position_to_relative_position(self, x):
|
| 232 |
+
"""
|
| 233 |
+
x: [b, h, l, l]
|
| 234 |
+
ret: [b, h, l, 2*l-1]
|
| 235 |
+
"""
|
| 236 |
+
batch, heads, length, _ = x.size()
|
| 237 |
+
# padd along column
|
| 238 |
+
x = F.pad(x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, length-1]]))
|
| 239 |
+
x_flat = x.view([batch, heads, length**2 + length*(length -1)])
|
| 240 |
+
# add 0's in the beginning that will skew the elements after reshape
|
| 241 |
+
x_flat = F.pad(x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [length, 0]]))
|
| 242 |
+
x_final = x_flat.view([batch, heads, length, 2*length])[:,:,:,1:]
|
| 243 |
+
return x_final
|
| 244 |
+
|
| 245 |
+
def _attention_bias_proximal(self, length):
|
| 246 |
+
"""Bias for self-attention to encourage attention to close positions.
|
| 247 |
+
Args:
|
| 248 |
+
length: an integer scalar.
|
| 249 |
+
Returns:
|
| 250 |
+
a Tensor with shape [1, 1, length, length]
|
| 251 |
+
"""
|
| 252 |
+
r = torch.arange(length, dtype=torch.float32)
|
| 253 |
+
diff = torch.unsqueeze(r, 0) - torch.unsqueeze(r, 1)
|
| 254 |
+
return torch.unsqueeze(torch.unsqueeze(-torch.log1p(torch.abs(diff)), 0), 0)
|
| 255 |
+
|
| 256 |
+
|
| 257 |
+
class FFN(nn.Module):
|
| 258 |
+
def __init__(self, in_channels, out_channels, filter_channels, kernel_size, p_dropout=0., activation=None, causal=False):
|
| 259 |
+
super().__init__()
|
| 260 |
+
self.in_channels = in_channels
|
| 261 |
+
self.out_channels = out_channels
|
| 262 |
+
self.filter_channels = filter_channels
|
| 263 |
+
self.kernel_size = kernel_size
|
| 264 |
+
self.p_dropout = p_dropout
|
| 265 |
+
self.activation = activation
|
| 266 |
+
self.causal = causal
|
| 267 |
+
|
| 268 |
+
if causal:
|
| 269 |
+
self.padding = self._causal_padding
|
| 270 |
+
else:
|
| 271 |
+
self.padding = self._same_padding
|
| 272 |
+
|
| 273 |
+
self.conv_1 = nn.Conv1d(in_channels, filter_channels, kernel_size)
|
| 274 |
+
self.conv_2 = nn.Conv1d(filter_channels, out_channels, kernel_size)
|
| 275 |
+
self.drop = nn.Dropout(p_dropout)
|
| 276 |
+
|
| 277 |
+
def forward(self, x, x_mask):
|
| 278 |
+
x = self.conv_1(self.padding(x * x_mask))
|
| 279 |
+
if self.activation == "gelu":
|
| 280 |
+
x = x * torch.sigmoid(1.702 * x)
|
| 281 |
+
else:
|
| 282 |
+
x = torch.relu(x)
|
| 283 |
+
x = self.drop(x)
|
| 284 |
+
x = self.conv_2(self.padding(x * x_mask))
|
| 285 |
+
return x * x_mask
|
| 286 |
+
|
| 287 |
+
def _causal_padding(self, x):
|
| 288 |
+
if self.kernel_size == 1:
|
| 289 |
+
return x
|
| 290 |
+
pad_l = self.kernel_size - 1
|
| 291 |
+
pad_r = 0
|
| 292 |
+
padding = [[0, 0], [0, 0], [pad_l, pad_r]]
|
| 293 |
+
x = F.pad(x, commons.convert_pad_shape(padding))
|
| 294 |
+
return x
|
| 295 |
+
|
| 296 |
+
def _same_padding(self, x):
|
| 297 |
+
if self.kernel_size == 1:
|
| 298 |
+
return x
|
| 299 |
+
pad_l = (self.kernel_size - 1) // 2
|
| 300 |
+
pad_r = self.kernel_size // 2
|
| 301 |
+
padding = [[0, 0], [0, 0], [pad_l, pad_r]]
|
| 302 |
+
x = F.pad(x, commons.convert_pad_shape(padding))
|
| 303 |
+
return x
|
commons.py
ADDED
|
@@ -0,0 +1,161 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
from torch.nn import functional as F
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def init_weights(m, mean=0.0, std=0.01):
|
| 9 |
+
classname = m.__class__.__name__
|
| 10 |
+
if classname.find("Conv") != -1:
|
| 11 |
+
m.weight.data.normal_(mean, std)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def get_padding(kernel_size, dilation=1):
|
| 15 |
+
return int((kernel_size*dilation - dilation)/2)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def convert_pad_shape(pad_shape):
|
| 19 |
+
l = pad_shape[::-1]
|
| 20 |
+
pad_shape = [item for sublist in l for item in sublist]
|
| 21 |
+
return pad_shape
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def intersperse(lst, item):
|
| 25 |
+
result = [item] * (len(lst) * 2 + 1)
|
| 26 |
+
result[1::2] = lst
|
| 27 |
+
return result
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def kl_divergence(m_p, logs_p, m_q, logs_q):
|
| 31 |
+
"""KL(P||Q)"""
|
| 32 |
+
kl = (logs_q - logs_p) - 0.5
|
| 33 |
+
kl += 0.5 * (torch.exp(2. * logs_p) + ((m_p - m_q)**2)) * torch.exp(-2. * logs_q)
|
| 34 |
+
return kl
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def rand_gumbel(shape):
|
| 38 |
+
"""Sample from the Gumbel distribution, protect from overflows."""
|
| 39 |
+
uniform_samples = torch.rand(shape) * 0.99998 + 0.00001
|
| 40 |
+
return -torch.log(-torch.log(uniform_samples))
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def rand_gumbel_like(x):
|
| 44 |
+
g = rand_gumbel(x.size()).to(dtype=x.dtype, device=x.device)
|
| 45 |
+
return g
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def slice_segments(x, ids_str, segment_size=4):
|
| 49 |
+
ret = torch.zeros_like(x[:, :, :segment_size])
|
| 50 |
+
for i in range(x.size(0)):
|
| 51 |
+
idx_str = ids_str[i]
|
| 52 |
+
idx_end = idx_str + segment_size
|
| 53 |
+
ret[i] = x[i, :, idx_str:idx_end]
|
| 54 |
+
return ret
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def rand_slice_segments(x, x_lengths=None, segment_size=4):
|
| 58 |
+
b, d, t = x.size()
|
| 59 |
+
if x_lengths is None:
|
| 60 |
+
x_lengths = t
|
| 61 |
+
ids_str_max = x_lengths - segment_size + 1
|
| 62 |
+
ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long)
|
| 63 |
+
ret = slice_segments(x, ids_str, segment_size)
|
| 64 |
+
return ret, ids_str
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def get_timing_signal_1d(
|
| 68 |
+
length, channels, min_timescale=1.0, max_timescale=1.0e4):
|
| 69 |
+
position = torch.arange(length, dtype=torch.float)
|
| 70 |
+
num_timescales = channels // 2
|
| 71 |
+
log_timescale_increment = (
|
| 72 |
+
math.log(float(max_timescale) / float(min_timescale)) /
|
| 73 |
+
(num_timescales - 1))
|
| 74 |
+
inv_timescales = min_timescale * torch.exp(
|
| 75 |
+
torch.arange(num_timescales, dtype=torch.float) * -log_timescale_increment)
|
| 76 |
+
scaled_time = position.unsqueeze(0) * inv_timescales.unsqueeze(1)
|
| 77 |
+
signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], 0)
|
| 78 |
+
signal = F.pad(signal, [0, 0, 0, channels % 2])
|
| 79 |
+
signal = signal.view(1, channels, length)
|
| 80 |
+
return signal
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def add_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4):
|
| 84 |
+
b, channels, length = x.size()
|
| 85 |
+
signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
|
| 86 |
+
return x + signal.to(dtype=x.dtype, device=x.device)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def cat_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4, axis=1):
|
| 90 |
+
b, channels, length = x.size()
|
| 91 |
+
signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
|
| 92 |
+
return torch.cat([x, signal.to(dtype=x.dtype, device=x.device)], axis)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def subsequent_mask(length):
|
| 96 |
+
mask = torch.tril(torch.ones(length, length)).unsqueeze(0).unsqueeze(0)
|
| 97 |
+
return mask
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
@torch.jit.script
|
| 101 |
+
def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels):
|
| 102 |
+
n_channels_int = n_channels[0]
|
| 103 |
+
in_act = input_a + input_b
|
| 104 |
+
t_act = torch.tanh(in_act[:, :n_channels_int, :])
|
| 105 |
+
s_act = torch.sigmoid(in_act[:, n_channels_int:, :])
|
| 106 |
+
acts = t_act * s_act
|
| 107 |
+
return acts
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def convert_pad_shape(pad_shape):
|
| 111 |
+
l = pad_shape[::-1]
|
| 112 |
+
pad_shape = [item for sublist in l for item in sublist]
|
| 113 |
+
return pad_shape
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def shift_1d(x):
|
| 117 |
+
x = F.pad(x, convert_pad_shape([[0, 0], [0, 0], [1, 0]]))[:, :, :-1]
|
| 118 |
+
return x
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def sequence_mask(length, max_length=None):
|
| 122 |
+
if max_length is None:
|
| 123 |
+
max_length = length.max()
|
| 124 |
+
x = torch.arange(max_length, dtype=length.dtype, device=length.device)
|
| 125 |
+
return x.unsqueeze(0) < length.unsqueeze(1)
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
def generate_path(duration, mask):
|
| 129 |
+
"""
|
| 130 |
+
duration: [b, 1, t_x]
|
| 131 |
+
mask: [b, 1, t_y, t_x]
|
| 132 |
+
"""
|
| 133 |
+
device = duration.device
|
| 134 |
+
|
| 135 |
+
b, _, t_y, t_x = mask.shape
|
| 136 |
+
cum_duration = torch.cumsum(duration, -1)
|
| 137 |
+
|
| 138 |
+
cum_duration_flat = cum_duration.view(b * t_x)
|
| 139 |
+
path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype)
|
| 140 |
+
path = path.view(b, t_x, t_y)
|
| 141 |
+
path = path - F.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1]
|
| 142 |
+
path = path.unsqueeze(1).transpose(2,3) * mask
|
| 143 |
+
return path
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def clip_grad_value_(parameters, clip_value, norm_type=2):
|
| 147 |
+
if isinstance(parameters, torch.Tensor):
|
| 148 |
+
parameters = [parameters]
|
| 149 |
+
parameters = list(filter(lambda p: p.grad is not None, parameters))
|
| 150 |
+
norm_type = float(norm_type)
|
| 151 |
+
if clip_value is not None:
|
| 152 |
+
clip_value = float(clip_value)
|
| 153 |
+
|
| 154 |
+
total_norm = 0
|
| 155 |
+
for p in parameters:
|
| 156 |
+
param_norm = p.grad.data.norm(norm_type)
|
| 157 |
+
total_norm += param_norm.item() ** norm_type
|
| 158 |
+
if clip_value is not None:
|
| 159 |
+
p.grad.data.clamp_(min=-clip_value, max=clip_value)
|
| 160 |
+
total_norm = total_norm ** (1. / norm_type)
|
| 161 |
+
return total_norm
|
configs/chinese_base.json
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"eval_interval": 1000,
|
| 5 |
+
"seed": 1234,
|
| 6 |
+
"epochs": 10000,
|
| 7 |
+
"learning_rate": 2e-4,
|
| 8 |
+
"betas": [0.8, 0.99],
|
| 9 |
+
"eps": 1e-9,
|
| 10 |
+
"batch_size": 32,
|
| 11 |
+
"fp16_run": true,
|
| 12 |
+
"lr_decay": 0.999875,
|
| 13 |
+
"segment_size": 8192,
|
| 14 |
+
"init_lr_ratio": 1,
|
| 15 |
+
"warmup_epochs": 0,
|
| 16 |
+
"c_mel": 45,
|
| 17 |
+
"c_kl": 1.0
|
| 18 |
+
},
|
| 19 |
+
"data": {
|
| 20 |
+
"training_files":"filelists/juzi_train_filelist.txt.cleaned",
|
| 21 |
+
"validation_files":"filelists/juzi_val_filelist.txt.cleaned",
|
| 22 |
+
"text_cleaners":["chinese_cleaners"],
|
| 23 |
+
"max_wav_value": 32768.0,
|
| 24 |
+
"sampling_rate": 22050,
|
| 25 |
+
"filter_length": 1024,
|
| 26 |
+
"hop_length": 256,
|
| 27 |
+
"win_length": 1024,
|
| 28 |
+
"n_mel_channels": 80,
|
| 29 |
+
"mel_fmin": 0.0,
|
| 30 |
+
"mel_fmax": null,
|
| 31 |
+
"add_blank": true,
|
| 32 |
+
"n_speakers": 8,
|
| 33 |
+
"cleaned_text": true
|
| 34 |
+
},
|
| 35 |
+
"model": {
|
| 36 |
+
"inter_channels": 192,
|
| 37 |
+
"hidden_channels": 192,
|
| 38 |
+
"filter_channels": 768,
|
| 39 |
+
"n_heads": 2,
|
| 40 |
+
"n_layers": 6,
|
| 41 |
+
"kernel_size": 3,
|
| 42 |
+
"p_dropout": 0.1,
|
| 43 |
+
"resblock": "1",
|
| 44 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 45 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 46 |
+
"upsample_rates": [8,8,2,2],
|
| 47 |
+
"upsample_initial_channel": 512,
|
| 48 |
+
"upsample_kernel_sizes": [16,16,4,4],
|
| 49 |
+
"n_layers_q": 3,
|
| 50 |
+
"use_spectral_norm": false,
|
| 51 |
+
"gin_channels": 256
|
| 52 |
+
},
|
| 53 |
+
"speakers": ["\u5c0f\u8338", "\u5510\u4e50\u541f", "\u5c0f\u6bb7", "\u82b1\u73b2", "\u8bb8\u8001\u5e08", "\u90b1\u7433", "\u4e03\u4e00", "\u516b\u56db"],
|
| 54 |
+
"symbols": ["_", "\uff0c", "\u3002", "\uff01", "\uff1f", "\u2014", "\u2026", "\u3105", "\u3106", "\u3107", "\u3108", "\u3109", "\u310a", "\u310b", "\u310c", "\u310d", "\u310e", "\u310f", "\u3110", "\u3111", "\u3112", "\u3113", "\u3114", "\u3115", "\u3116", "\u3117", "\u3118", "\u3119", "\u311a", "\u311b", "\u311c", "\u311d", "\u311e", "\u311f", "\u3120", "\u3121", "\u3122", "\u3123", "\u3124", "\u3125", "\u3126", "\u3127", "\u3128", "\u3129", "\u02c9", "\u02ca", "\u02c7", "\u02cb", "\u02d9", " "]
|
| 55 |
+
}
|
configs/cjke_base.json
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"eval_interval": 1000,
|
| 5 |
+
"seed": 1234,
|
| 6 |
+
"epochs": 10000,
|
| 7 |
+
"learning_rate": 2e-4,
|
| 8 |
+
"betas": [0.8, 0.99],
|
| 9 |
+
"eps": 1e-9,
|
| 10 |
+
"batch_size": 32,
|
| 11 |
+
"fp16_run": true,
|
| 12 |
+
"lr_decay": 0.999875,
|
| 13 |
+
"segment_size": 8192,
|
| 14 |
+
"init_lr_ratio": 1,
|
| 15 |
+
"warmup_epochs": 0,
|
| 16 |
+
"c_mel": 45,
|
| 17 |
+
"c_kl": 1.0
|
| 18 |
+
},
|
| 19 |
+
"data": {
|
| 20 |
+
"training_files":"filelists/cjke_train_filelist.txt.cleaned",
|
| 21 |
+
"validation_files":"filelists/cjke_val_filelist.txt.cleaned",
|
| 22 |
+
"text_cleaners":["cjke_cleaners2"],
|
| 23 |
+
"max_wav_value": 32768.0,
|
| 24 |
+
"sampling_rate": 22050,
|
| 25 |
+
"filter_length": 1024,
|
| 26 |
+
"hop_length": 256,
|
| 27 |
+
"win_length": 1024,
|
| 28 |
+
"n_mel_channels": 80,
|
| 29 |
+
"mel_fmin": 0.0,
|
| 30 |
+
"mel_fmax": null,
|
| 31 |
+
"add_blank": true,
|
| 32 |
+
"n_speakers": 2891,
|
| 33 |
+
"cleaned_text": true
|
| 34 |
+
},
|
| 35 |
+
"model": {
|
| 36 |
+
"inter_channels": 192,
|
| 37 |
+
"hidden_channels": 192,
|
| 38 |
+
"filter_channels": 768,
|
| 39 |
+
"n_heads": 2,
|
| 40 |
+
"n_layers": 6,
|
| 41 |
+
"kernel_size": 3,
|
| 42 |
+
"p_dropout": 0.1,
|
| 43 |
+
"resblock": "1",
|
| 44 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 45 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 46 |
+
"upsample_rates": [8,8,2,2],
|
| 47 |
+
"upsample_initial_channel": 512,
|
| 48 |
+
"upsample_kernel_sizes": [16,16,4,4],
|
| 49 |
+
"n_layers_q": 3,
|
| 50 |
+
"use_spectral_norm": false,
|
| 51 |
+
"gin_channels": 256
|
| 52 |
+
},
|
| 53 |
+
"symbols": ["_", ",", ".", "!", "?", "-", "~", "\u2026", "N", "Q", "a", "b", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "s", "t", "u", "v", "w", "x", "y", "z", "\u0251", "\u00e6", "\u0283", "\u0291", "\u00e7", "\u026f", "\u026a", "\u0254", "\u025b", "\u0279", "\u00f0", "\u0259", "\u026b", "\u0265", "\u0278", "\u028a", "\u027e", "\u0292", "\u03b8", "\u03b2", "\u014b", "\u0266", "\u207c", "\u02b0", "`", "^", "#", "*", "=", "\u02c8", "\u02cc", "\u2192", "\u2193", "\u2191", " "]
|
| 54 |
+
}
|
configs/cjks_base.json
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"eval_interval": 1000,
|
| 5 |
+
"seed": 1234,
|
| 6 |
+
"epochs": 10000,
|
| 7 |
+
"learning_rate": 2e-4,
|
| 8 |
+
"betas": [0.8, 0.99],
|
| 9 |
+
"eps": 1e-9,
|
| 10 |
+
"batch_size": 32,
|
| 11 |
+
"fp16_run": true,
|
| 12 |
+
"lr_decay": 0.999875,
|
| 13 |
+
"segment_size": 8192,
|
| 14 |
+
"init_lr_ratio": 1,
|
| 15 |
+
"warmup_epochs": 0,
|
| 16 |
+
"c_mel": 45,
|
| 17 |
+
"c_kl": 1.0
|
| 18 |
+
},
|
| 19 |
+
"data": {
|
| 20 |
+
"training_files":"filelists/cjks_train_filelist.txt.cleaned",
|
| 21 |
+
"validation_files":"filelists/cjks_val_filelist.txt.cleaned",
|
| 22 |
+
"text_cleaners":["cjks_cleaners"],
|
| 23 |
+
"max_wav_value": 32768.0,
|
| 24 |
+
"sampling_rate": 22050,
|
| 25 |
+
"filter_length": 1024,
|
| 26 |
+
"hop_length": 256,
|
| 27 |
+
"win_length": 1024,
|
| 28 |
+
"n_mel_channels": 80,
|
| 29 |
+
"mel_fmin": 0.0,
|
| 30 |
+
"mel_fmax": null,
|
| 31 |
+
"add_blank": true,
|
| 32 |
+
"n_speakers": 24,
|
| 33 |
+
"cleaned_text": true
|
| 34 |
+
},
|
| 35 |
+
"model": {
|
| 36 |
+
"inter_channels": 192,
|
| 37 |
+
"hidden_channels": 192,
|
| 38 |
+
"filter_channels": 768,
|
| 39 |
+
"n_heads": 2,
|
| 40 |
+
"n_layers": 6,
|
| 41 |
+
"kernel_size": 3,
|
| 42 |
+
"p_dropout": 0.1,
|
| 43 |
+
"resblock": "1",
|
| 44 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 45 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 46 |
+
"upsample_rates": [8,8,2,2],
|
| 47 |
+
"upsample_initial_channel": 512,
|
| 48 |
+
"upsample_kernel_sizes": [16,16,4,4],
|
| 49 |
+
"n_layers_q": 3,
|
| 50 |
+
"use_spectral_norm": false,
|
| 51 |
+
"gin_channels": 256
|
| 52 |
+
},
|
| 53 |
+
"speakers": ["\u7dbe\u5730\u5be7\u3005", "\u671d\u6b66\u82b3\u4e43", "\u5728\u539f\u4e03\u6d77", "\u30eb\u30a4\u30ba", "\u91d1\u8272\u306e\u95c7", "\u30e2\u30e2", "\u7d50\u57ce\u7f8e\u67d1", "\u5c0f\u8338", "\u5510\u4e50\u541f", "\u5c0f\u6bb7", "\u82b1\u73b2", "\u516b\u56db", "\uc218\uc544", "\ubbf8\ubbf8\ub974", "\uc544\ub9b0", "\uc720\ud654", "\uc5f0\ud654", "SA1", "SA2", "SA3", "SA4", "SA5", "SA6", ""],
|
| 54 |
+
"symbols": ["_", ",", ".", "!", "?", "-", "~", "\u2026", "N", "Q", "a", "b", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "s", "t", "u", "v", "w", "x", "y", "z", "\u0283", "\u02a7", "\u02a5", "\u02a6", "\u026f", "\u0279", "\u0259", "\u0265", "\u00e7", "\u0278", "\u027e", "\u03b2", "\u014b", "\u0266", "\u02d0", "\u207c", "\u02b0", "`", "^", "#", "*", "=", "\u2192", "\u2193", "\u2191", " "]
|
| 55 |
+
}
|
configs/japanese_base.json
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"eval_interval": 1000,
|
| 5 |
+
"seed": 1234,
|
| 6 |
+
"epochs": 10000,
|
| 7 |
+
"learning_rate": 2e-4,
|
| 8 |
+
"betas": [0.8, 0.99],
|
| 9 |
+
"eps": 1e-9,
|
| 10 |
+
"batch_size": 32,
|
| 11 |
+
"fp16_run": true,
|
| 12 |
+
"lr_decay": 0.999875,
|
| 13 |
+
"segment_size": 8192,
|
| 14 |
+
"init_lr_ratio": 1,
|
| 15 |
+
"warmup_epochs": 0,
|
| 16 |
+
"c_mel": 45,
|
| 17 |
+
"c_kl": 1.0
|
| 18 |
+
},
|
| 19 |
+
"data": {
|
| 20 |
+
"training_files":"filelists/train_filelist.txt.cleaned",
|
| 21 |
+
"validation_files":"filelists/val_filelist.txt.cleaned",
|
| 22 |
+
"text_cleaners":["japanese_cleaners"],
|
| 23 |
+
"max_wav_value": 32768.0,
|
| 24 |
+
"sampling_rate": 22050,
|
| 25 |
+
"filter_length": 1024,
|
| 26 |
+
"hop_length": 256,
|
| 27 |
+
"win_length": 1024,
|
| 28 |
+
"n_mel_channels": 80,
|
| 29 |
+
"mel_fmin": 0.0,
|
| 30 |
+
"mel_fmax": null,
|
| 31 |
+
"add_blank": true,
|
| 32 |
+
"n_speakers": 7,
|
| 33 |
+
"cleaned_text": true
|
| 34 |
+
},
|
| 35 |
+
"model": {
|
| 36 |
+
"inter_channels": 192,
|
| 37 |
+
"hidden_channels": 192,
|
| 38 |
+
"filter_channels": 768,
|
| 39 |
+
"n_heads": 2,
|
| 40 |
+
"n_layers": 6,
|
| 41 |
+
"kernel_size": 3,
|
| 42 |
+
"p_dropout": 0.1,
|
| 43 |
+
"resblock": "1",
|
| 44 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 45 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 46 |
+
"upsample_rates": [8,8,2,2],
|
| 47 |
+
"upsample_initial_channel": 512,
|
| 48 |
+
"upsample_kernel_sizes": [16,16,4,4],
|
| 49 |
+
"n_layers_q": 3,
|
| 50 |
+
"use_spectral_norm": false,
|
| 51 |
+
"gin_channels": 256
|
| 52 |
+
},
|
| 53 |
+
"speakers": ["\u7dbe\u5730\u5be7\u3005", "\u56e0\u5e61\u3081\u3050\u308b", "\u671d\u6b66\u82b3\u4e43", "\u5e38\u9678\u8309\u5b50", "\u30e0\u30e9\u30b5\u30e1", "\u978d\u99ac\u5c0f\u6625", "\u5728\u539f\u4e03\u6d77"],
|
| 54 |
+
"symbols": ["_", ",", ".", "!", "?", "-", "A", "E", "I", "N", "O", "Q", "U", "a", "b", "d", "e", "f", "g", "h", "i", "j", "k", "m", "n", "o", "p", "r", "s", "t", "u", "v", "w", "y", "z", "\u0283", "\u02a7", "\u2193", "\u2191", " "]
|
| 55 |
+
}
|
configs/japanese_base2.json
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"eval_interval": 1000,
|
| 5 |
+
"seed": 1234,
|
| 6 |
+
"epochs": 10000,
|
| 7 |
+
"learning_rate": 2e-4,
|
| 8 |
+
"betas": [0.8, 0.99],
|
| 9 |
+
"eps": 1e-9,
|
| 10 |
+
"batch_size": 32,
|
| 11 |
+
"fp16_run": true,
|
| 12 |
+
"lr_decay": 0.999875,
|
| 13 |
+
"segment_size": 8192,
|
| 14 |
+
"init_lr_ratio": 1,
|
| 15 |
+
"warmup_epochs": 0,
|
| 16 |
+
"c_mel": 45,
|
| 17 |
+
"c_kl": 1.0
|
| 18 |
+
},
|
| 19 |
+
"data": {
|
| 20 |
+
"training_files":"filelists/hamidashi_train_filelist.txt.cleaned",
|
| 21 |
+
"validation_files":"filelists/hamidashi_val_filelist.txt.cleaned",
|
| 22 |
+
"text_cleaners":["japanese_cleaners2"],
|
| 23 |
+
"max_wav_value": 32768.0,
|
| 24 |
+
"sampling_rate": 22050,
|
| 25 |
+
"filter_length": 1024,
|
| 26 |
+
"hop_length": 256,
|
| 27 |
+
"win_length": 1024,
|
| 28 |
+
"n_mel_channels": 80,
|
| 29 |
+
"mel_fmin": 0.0,
|
| 30 |
+
"mel_fmax": null,
|
| 31 |
+
"add_blank": true,
|
| 32 |
+
"n_speakers": 8,
|
| 33 |
+
"cleaned_text": true
|
| 34 |
+
},
|
| 35 |
+
"model": {
|
| 36 |
+
"inter_channels": 192,
|
| 37 |
+
"hidden_channels": 192,
|
| 38 |
+
"filter_channels": 768,
|
| 39 |
+
"n_heads": 2,
|
| 40 |
+
"n_layers": 6,
|
| 41 |
+
"kernel_size": 3,
|
| 42 |
+
"p_dropout": 0.1,
|
| 43 |
+
"resblock": "1",
|
| 44 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 45 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 46 |
+
"upsample_rates": [8,8,2,2],
|
| 47 |
+
"upsample_initial_channel": 512,
|
| 48 |
+
"upsample_kernel_sizes": [16,16,4,4],
|
| 49 |
+
"n_layers_q": 3,
|
| 50 |
+
"use_spectral_norm": false,
|
| 51 |
+
"gin_channels": 256
|
| 52 |
+
},
|
| 53 |
+
"speakers": ["\u548c\u6cc9\u5983\u611b", "\u5e38\u76e4\u83ef\u4e43", "\u9326\u3042\u3059\u307f", "\u938c\u5009\u8a69\u685c", "\u7adc\u9591\u5929\u68a8", "\u548c\u6cc9\u91cc", "\u65b0\u5ddd\u5e83\u5922", "\u8056\u8389\u3005\u5b50"],
|
| 54 |
+
"symbols": ["_", ",", ".", "!", "?", "-", "~", "\u2026", "A", "E", "I", "N", "O", "Q", "U", "a", "b", "d", "e", "f", "g", "h", "i", "j", "k", "m", "n", "o", "p", "r", "s", "t", "u", "v", "w", "y", "z", "\u0283", "\u02a7", "\u02a6", "\u2193", "\u2191", " "]
|
| 55 |
+
}
|
configs/japanese_ss_base2.json
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"eval_interval": 1000,
|
| 5 |
+
"seed": 1234,
|
| 6 |
+
"epochs": 20000,
|
| 7 |
+
"learning_rate": 2e-4,
|
| 8 |
+
"betas": [0.8, 0.99],
|
| 9 |
+
"eps": 1e-9,
|
| 10 |
+
"batch_size": 32,
|
| 11 |
+
"fp16_run": true,
|
| 12 |
+
"lr_decay": 0.999875,
|
| 13 |
+
"segment_size": 8192,
|
| 14 |
+
"init_lr_ratio": 1,
|
| 15 |
+
"warmup_epochs": 0,
|
| 16 |
+
"c_mel": 45,
|
| 17 |
+
"c_kl": 1.0
|
| 18 |
+
},
|
| 19 |
+
"data": {
|
| 20 |
+
"training_files":"filelists/train_filelist.txt.cleaned",
|
| 21 |
+
"validation_files":"filelists/val_filelist.txt.cleaned",
|
| 22 |
+
"text_cleaners":["japanese_cleaners2"],
|
| 23 |
+
"max_wav_value": 32768.0,
|
| 24 |
+
"sampling_rate": 22050,
|
| 25 |
+
"filter_length": 1024,
|
| 26 |
+
"hop_length": 256,
|
| 27 |
+
"win_length": 1024,
|
| 28 |
+
"n_mel_channels": 80,
|
| 29 |
+
"mel_fmin": 0.0,
|
| 30 |
+
"mel_fmax": null,
|
| 31 |
+
"add_blank": true,
|
| 32 |
+
"n_speakers": 0,
|
| 33 |
+
"cleaned_text": true
|
| 34 |
+
},
|
| 35 |
+
"model": {
|
| 36 |
+
"inter_channels": 192,
|
| 37 |
+
"hidden_channels": 192,
|
| 38 |
+
"filter_channels": 768,
|
| 39 |
+
"n_heads": 2,
|
| 40 |
+
"n_layers": 6,
|
| 41 |
+
"kernel_size": 3,
|
| 42 |
+
"p_dropout": 0.1,
|
| 43 |
+
"resblock": "1",
|
| 44 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 45 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 46 |
+
"upsample_rates": [8,8,2,2],
|
| 47 |
+
"upsample_initial_channel": 512,
|
| 48 |
+
"upsample_kernel_sizes": [16,16,4,4],
|
| 49 |
+
"n_layers_q": 3,
|
| 50 |
+
"use_spectral_norm": false
|
| 51 |
+
},
|
| 52 |
+
"speakers": ["\u30eb\u30a4\u30ba"],
|
| 53 |
+
"symbols": ["_", ",", ".", "!", "?", "-", "~", "\u2026", "A", "E", "I", "N", "O", "Q", "U", "a", "b", "d", "e", "f", "g", "h", "i", "j", "k", "m", "n", "o", "p", "r", "s", "t", "u", "v", "w", "y", "z", "\u0283", "\u02a7", "\u02a6", "\u2193", "\u2191", " "]
|
| 54 |
+
}
|
configs/korean_base.json
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"eval_interval": 1000,
|
| 5 |
+
"seed": 1234,
|
| 6 |
+
"epochs": 10000,
|
| 7 |
+
"learning_rate": 2e-4,
|
| 8 |
+
"betas": [0.8, 0.99],
|
| 9 |
+
"eps": 1e-9,
|
| 10 |
+
"batch_size": 32,
|
| 11 |
+
"fp16_run": true,
|
| 12 |
+
"lr_decay": 0.999875,
|
| 13 |
+
"segment_size": 8192,
|
| 14 |
+
"init_lr_ratio": 1,
|
| 15 |
+
"warmup_epochs": 0,
|
| 16 |
+
"c_mel": 45,
|
| 17 |
+
"c_kl": 1.0
|
| 18 |
+
},
|
| 19 |
+
"data": {
|
| 20 |
+
"training_files":"filelists/fox_train_filelist.txt.cleaned",
|
| 21 |
+
"validation_files":"filelists/fox_val_filelist.txt.cleaned",
|
| 22 |
+
"text_cleaners":["korean_cleaners"],
|
| 23 |
+
"max_wav_value": 32768.0,
|
| 24 |
+
"sampling_rate": 22050,
|
| 25 |
+
"filter_length": 1024,
|
| 26 |
+
"hop_length": 256,
|
| 27 |
+
"win_length": 1024,
|
| 28 |
+
"n_mel_channels": 80,
|
| 29 |
+
"mel_fmin": 0.0,
|
| 30 |
+
"mel_fmax": null,
|
| 31 |
+
"add_blank": true,
|
| 32 |
+
"n_speakers": 6,
|
| 33 |
+
"cleaned_text": true
|
| 34 |
+
},
|
| 35 |
+
"model": {
|
| 36 |
+
"inter_channels": 192,
|
| 37 |
+
"hidden_channels": 192,
|
| 38 |
+
"filter_channels": 768,
|
| 39 |
+
"n_heads": 2,
|
| 40 |
+
"n_layers": 6,
|
| 41 |
+
"kernel_size": 3,
|
| 42 |
+
"p_dropout": 0.1,
|
| 43 |
+
"resblock": "1",
|
| 44 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 45 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 46 |
+
"upsample_rates": [8,8,2,2],
|
| 47 |
+
"upsample_initial_channel": 512,
|
| 48 |
+
"upsample_kernel_sizes": [16,16,4,4],
|
| 49 |
+
"n_layers_q": 3,
|
| 50 |
+
"use_spectral_norm": false,
|
| 51 |
+
"gin_channels": 256
|
| 52 |
+
},
|
| 53 |
+
"speakers": ["\uc218\uc544", "\ubbf8\ubbf8\ub974", "\uc544\ub9b0", "\uc5f0\ud654", "\uc720\ud654", "\uc120\ubc30"],
|
| 54 |
+
"symbols": ["_", ",", ".", "!", "?", "\u2026", "~", "\u3131", "\u3134", "\u3137", "\u3139", "\u3141", "\u3142", "\u3145", "\u3147", "\u3148", "\u314a", "\u314b", "\u314c", "\u314d", "\u314e", "\u3132", "\u3138", "\u3143", "\u3146", "\u3149", "\u314f", "\u3153", "\u3157", "\u315c", "\u3161", "\u3163", "\u3150", "\u3154", " "]
|
| 55 |
+
}
|
configs/sanskrit_base.json
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"eval_interval": 1000,
|
| 5 |
+
"seed": 1234,
|
| 6 |
+
"epochs": 10000,
|
| 7 |
+
"learning_rate": 2e-4,
|
| 8 |
+
"betas": [0.8, 0.99],
|
| 9 |
+
"eps": 1e-9,
|
| 10 |
+
"batch_size": 32,
|
| 11 |
+
"fp16_run": true,
|
| 12 |
+
"lr_decay": 0.999875,
|
| 13 |
+
"segment_size": 8192,
|
| 14 |
+
"init_lr_ratio": 1,
|
| 15 |
+
"warmup_epochs": 0,
|
| 16 |
+
"c_mel": 45,
|
| 17 |
+
"c_kl": 1.0
|
| 18 |
+
},
|
| 19 |
+
"data": {
|
| 20 |
+
"training_files":"filelists/sanskrit_train_filelist.txt.cleaned",
|
| 21 |
+
"validation_files":"filelists/sanskrit_val_filelist.txt.cleaned",
|
| 22 |
+
"text_cleaners":["sanskrit_cleaners"],
|
| 23 |
+
"max_wav_value": 32768.0,
|
| 24 |
+
"sampling_rate": 22050,
|
| 25 |
+
"filter_length": 1024,
|
| 26 |
+
"hop_length": 256,
|
| 27 |
+
"win_length": 1024,
|
| 28 |
+
"n_mel_channels": 80,
|
| 29 |
+
"mel_fmin": 0.0,
|
| 30 |
+
"mel_fmax": null,
|
| 31 |
+
"add_blank": true,
|
| 32 |
+
"n_speakers": 27,
|
| 33 |
+
"cleaned_text": true
|
| 34 |
+
},
|
| 35 |
+
"model": {
|
| 36 |
+
"inter_channels": 192,
|
| 37 |
+
"hidden_channels": 192,
|
| 38 |
+
"filter_channels": 768,
|
| 39 |
+
"n_heads": 2,
|
| 40 |
+
"n_layers": 6,
|
| 41 |
+
"kernel_size": 3,
|
| 42 |
+
"p_dropout": 0.1,
|
| 43 |
+
"resblock": "1",
|
| 44 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 45 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 46 |
+
"upsample_rates": [8,8,2,2],
|
| 47 |
+
"upsample_initial_channel": 512,
|
| 48 |
+
"upsample_kernel_sizes": [16,16,4,4],
|
| 49 |
+
"n_layers_q": 3,
|
| 50 |
+
"use_spectral_norm": false,
|
| 51 |
+
"gin_channels": 256
|
| 52 |
+
},
|
| 53 |
+
"speakers": ["Male 1", "Male 2", "Male 3", "Male 4 (Malayalam)", "Male 5", "Male 6", "Male 7", "Male 8 (Kannada)", "Female 1 (Tamil)", "Male 9 (Kannada)", "Female 2 (Marathi)", "Female 3 (Marathi)", "Female 4 (Marathi)", "Female 5 (Telugu)", "Female 6 (Telugu)", "Male 10 (Kannada)", "Male 11 (Kannada)", "Male 12", "Male 13", "Male 14", "Male 15", "Female 7", "Male 16 (Malayalam)", "Male 17 (Tamil)", "Male 18 (Hindi)", "Male 19 (Telugu)", "Male 20 (Hindi)"],
|
| 54 |
+
"symbols": ["_", "\u0964", "\u0901", "\u0902", "\u0903", "\u0905", "\u0906", "\u0907", "\u0908", "\u0909", "\u090a", "\u090b", "\u090f", "\u0910", "\u0913", "\u0914", "\u0915", "\u0916", "\u0917", "\u0918", "\u0919", "\u091a", "\u091b", "\u091c", "\u091d", "\u091e", "\u091f", "\u0920", "\u0921", "\u0922", "\u0923", "\u0924", "\u0925", "\u0926", "\u0927", "\u0928", "\u092a", "\u092b", "\u092c", "\u092d", "\u092e", "\u092f", "\u0930", "\u0932", "\u0933", "\u0935", "\u0936", "\u0937", "\u0938", "\u0939", "\u093d", "\u093e", "\u093f", "\u0940", "\u0941", "\u0942", "\u0943", "\u0944", "\u0947", "\u0948", "\u094b", "\u094c", "\u094d", "\u0960", "\u0962", " "]
|
| 55 |
+
}
|
configs/shanghainese_base.json
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"eval_interval": 1000,
|
| 5 |
+
"seed": 1234,
|
| 6 |
+
"epochs": 10000,
|
| 7 |
+
"learning_rate": 2e-4,
|
| 8 |
+
"betas": [0.8, 0.99],
|
| 9 |
+
"eps": 1e-9,
|
| 10 |
+
"batch_size": 32,
|
| 11 |
+
"fp16_run": true,
|
| 12 |
+
"lr_decay": 0.999875,
|
| 13 |
+
"segment_size": 8192,
|
| 14 |
+
"init_lr_ratio": 1,
|
| 15 |
+
"warmup_epochs": 0,
|
| 16 |
+
"c_mel": 45,
|
| 17 |
+
"c_kl": 1.0
|
| 18 |
+
},
|
| 19 |
+
"data": {
|
| 20 |
+
"training_files":"filelists/zaonhe_train_filelist.txt.cleaned",
|
| 21 |
+
"validation_files":"filelists/zaonhe_val_filelist.txt.cleaned",
|
| 22 |
+
"text_cleaners":["shanghainese_cleaners"],
|
| 23 |
+
"max_wav_value": 32768.0,
|
| 24 |
+
"sampling_rate": 22050,
|
| 25 |
+
"filter_length": 1024,
|
| 26 |
+
"hop_length": 256,
|
| 27 |
+
"win_length": 1024,
|
| 28 |
+
"n_mel_channels": 80,
|
| 29 |
+
"mel_fmin": 0.0,
|
| 30 |
+
"mel_fmax": null,
|
| 31 |
+
"add_blank": true,
|
| 32 |
+
"n_speakers": 2,
|
| 33 |
+
"cleaned_text": true
|
| 34 |
+
},
|
| 35 |
+
"model": {
|
| 36 |
+
"inter_channels": 192,
|
| 37 |
+
"hidden_channels": 192,
|
| 38 |
+
"filter_channels": 768,
|
| 39 |
+
"n_heads": 2,
|
| 40 |
+
"n_layers": 6,
|
| 41 |
+
"kernel_size": 3,
|
| 42 |
+
"p_dropout": 0.1,
|
| 43 |
+
"resblock": "1",
|
| 44 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 45 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 46 |
+
"upsample_rates": [8,8,2,2],
|
| 47 |
+
"upsample_initial_channel": 512,
|
| 48 |
+
"upsample_kernel_sizes": [16,16,4,4],
|
| 49 |
+
"n_layers_q": 3,
|
| 50 |
+
"use_spectral_norm": false,
|
| 51 |
+
"gin_channels": 256
|
| 52 |
+
},
|
| 53 |
+
"speakers": ["1", "2"],
|
| 54 |
+
"symbols": ["_", ",", ".", "!", "?", "\u2026", "a", "b", "d", "f", "g", "h", "i", "k", "l", "m", "n", "o", "p", "s", "t", "u", "v", "y", "z", "\u00f8", "\u014b", "\u0235", "\u0251", "\u0254", "\u0255", "\u0259", "\u0264", "\u0266", "\u026a", "\u027f", "\u0291", "\u0294", "\u02b0", "\u0303", "\u0329", "\u1d00", "\u1d07", "1", "5", "6", "7", "8", " "]
|
| 55 |
+
}
|
configs/uma87.json
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"eval_interval": 1000,
|
| 5 |
+
"seed": 1234,
|
| 6 |
+
"epochs": 10000,
|
| 7 |
+
"learning_rate": 2e-4,
|
| 8 |
+
"betas": [0.8, 0.99],
|
| 9 |
+
"eps": 1e-9,
|
| 10 |
+
"batch_size": 1,
|
| 11 |
+
"fp16_run": true,
|
| 12 |
+
"lr_decay": 0.999875,
|
| 13 |
+
"segment_size": 8192,
|
| 14 |
+
"init_lr_ratio": 1,
|
| 15 |
+
"warmup_epochs": 0,
|
| 16 |
+
"c_mel": 45,
|
| 17 |
+
"c_kl": 1.0
|
| 18 |
+
},
|
| 19 |
+
"data": {
|
| 20 |
+
"training_files":"E:/uma_voice/output_train.txt.cleaned",
|
| 21 |
+
"validation_files":"E:/uma_voice/output_val.txt.cleaned",
|
| 22 |
+
"text_cleaners":["japanese_cleaners"],
|
| 23 |
+
"max_wav_value": 32768.0,
|
| 24 |
+
"sampling_rate": 22050,
|
| 25 |
+
"filter_length": 1024,
|
| 26 |
+
"hop_length": 256,
|
| 27 |
+
"win_length": 1024,
|
| 28 |
+
"n_mel_channels": 80,
|
| 29 |
+
"mel_fmin": 0.0,
|
| 30 |
+
"mel_fmax": null,
|
| 31 |
+
"add_blank": true,
|
| 32 |
+
"n_speakers": 87,
|
| 33 |
+
"cleaned_text": true
|
| 34 |
+
},
|
| 35 |
+
"model": {
|
| 36 |
+
"inter_channels": 192,
|
| 37 |
+
"hidden_channels": 192,
|
| 38 |
+
"filter_channels": 768,
|
| 39 |
+
"n_heads": 2,
|
| 40 |
+
"n_layers": 6,
|
| 41 |
+
"kernel_size": 3,
|
| 42 |
+
"p_dropout": 0.1,
|
| 43 |
+
"resblock": "1",
|
| 44 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 45 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 46 |
+
"upsample_rates": [8,8,2,2],
|
| 47 |
+
"upsample_initial_channel": 512,
|
| 48 |
+
"upsample_kernel_sizes": [16,16,4,4],
|
| 49 |
+
"n_layers_q": 3,
|
| 50 |
+
"use_spectral_norm": false,
|
| 51 |
+
"gin_channels": 256
|
| 52 |
+
},
|
| 53 |
+
"speakers": ["\u7dbe\u5730\u5be7\u3005", "\u56e0\u5e61\u3081\u3050\u308b", "\u671d\u6b66\u82b3\u4e43", "\u5e38\u9678\u8309\u5b50", "\u30e0\u30e9\u30b5\u30e1", "\u978d\u99ac\u5c0f\u6625", "\u5728\u539f\u4e03\u6d77"],
|
| 54 |
+
"symbols": ["_", ",", ".", "!", "?", "-", "A", "E", "I", "N", "O", "Q", "U", "a", "b", "d", "e", "f", "g", "h", "i", "j", "k", "m", "n", "o", "p", "r", "s", "t", "u", "v", "w", "y", "z", "\u0283", "\u02a7", "\u2193", "\u2191", " "]
|
| 55 |
+
}
|
configs/yuzu.json
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"segment_size": 8192
|
| 4 |
+
},
|
| 5 |
+
"data": {
|
| 6 |
+
"text_cleaners":["japanese_cleaners"],
|
| 7 |
+
"max_wav_value": 32768.0,
|
| 8 |
+
"sampling_rate": 22050,
|
| 9 |
+
"filter_length": 1024,
|
| 10 |
+
"hop_length": 256,
|
| 11 |
+
"win_length": 1024,
|
| 12 |
+
"add_blank": true,
|
| 13 |
+
"n_speakers": 7
|
| 14 |
+
},
|
| 15 |
+
"model": {
|
| 16 |
+
"inter_channels": 192,
|
| 17 |
+
"hidden_channels": 192,
|
| 18 |
+
"filter_channels": 768,
|
| 19 |
+
"n_heads": 2,
|
| 20 |
+
"n_layers": 6,
|
| 21 |
+
"kernel_size": 3,
|
| 22 |
+
"p_dropout": 0.1,
|
| 23 |
+
"resblock": "1",
|
| 24 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 25 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 26 |
+
"upsample_rates": [8,8,2,2],
|
| 27 |
+
"upsample_initial_channel": 512,
|
| 28 |
+
"upsample_kernel_sizes": [16,16,4,4],
|
| 29 |
+
"n_layers_q": 3,
|
| 30 |
+
"use_spectral_norm": false,
|
| 31 |
+
"gin_channels": 256
|
| 32 |
+
},
|
| 33 |
+
"speakers": ["\u7dbe\u5730\u5be7\u3005", "\u56e0\u5e61\u3081\u3050\u308b", "\u671d\u6b66\u82b3\u4e43", "\u5e38\u9678\u8309\u5b50", "\u30e0\u30e9\u30b5\u30e1", "\u978d\u99ac\u5c0f\u6625", "\u5728\u539f\u4e03\u6d77"],
|
| 34 |
+
"symbols": ["_", ",", ".", "!", "?", "-", "A", "E", "I", "N", "O", "Q", "U", "a", "b", "d", "e", "f", "g", "h", "i", "j", "k", "m", "n", "o", "p", "r", "s", "t", "u", "v", "w", "y", "z", "\u0283", "\u02a7", "\u2193", "\u2191", " "]
|
| 35 |
+
}
|
configs/zero_japanese_base2.json
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"eval_interval": 1000,
|
| 5 |
+
"seed": 1234,
|
| 6 |
+
"epochs": 10000,
|
| 7 |
+
"learning_rate": 2e-4,
|
| 8 |
+
"betas": [0.8, 0.99],
|
| 9 |
+
"eps": 1e-9,
|
| 10 |
+
"batch_size": 32,
|
| 11 |
+
"fp16_run": true,
|
| 12 |
+
"lr_decay": 0.999875,
|
| 13 |
+
"segment_size": 8192,
|
| 14 |
+
"init_lr_ratio": 1,
|
| 15 |
+
"warmup_epochs": 0,
|
| 16 |
+
"c_mel": 45,
|
| 17 |
+
"c_kl": 1.0
|
| 18 |
+
},
|
| 19 |
+
"data": {
|
| 20 |
+
"training_files":"filelists/zero_train_filelist.txt.cleaned",
|
| 21 |
+
"validation_files":"filelists/zero_val_filelist.txt.cleaned",
|
| 22 |
+
"text_cleaners":["japanese_cleaners2"],
|
| 23 |
+
"max_wav_value": 32768.0,
|
| 24 |
+
"sampling_rate": 22050,
|
| 25 |
+
"filter_length": 1024,
|
| 26 |
+
"hop_length": 256,
|
| 27 |
+
"win_length": 1024,
|
| 28 |
+
"n_mel_channels": 80,
|
| 29 |
+
"mel_fmin": 0.0,
|
| 30 |
+
"mel_fmax": null,
|
| 31 |
+
"add_blank": true,
|
| 32 |
+
"n_speakers": 26,
|
| 33 |
+
"cleaned_text": true
|
| 34 |
+
},
|
| 35 |
+
"model": {
|
| 36 |
+
"inter_channels": 192,
|
| 37 |
+
"hidden_channels": 192,
|
| 38 |
+
"filter_channels": 768,
|
| 39 |
+
"n_heads": 2,
|
| 40 |
+
"n_layers": 6,
|
| 41 |
+
"kernel_size": 3,
|
| 42 |
+
"p_dropout": 0.1,
|
| 43 |
+
"resblock": "1",
|
| 44 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 45 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 46 |
+
"upsample_rates": [8,8,2,2],
|
| 47 |
+
"upsample_initial_channel": 512,
|
| 48 |
+
"upsample_kernel_sizes": [16,16,4,4],
|
| 49 |
+
"n_layers_q": 3,
|
| 50 |
+
"use_spectral_norm": false,
|
| 51 |
+
"gin_channels": 256
|
| 52 |
+
},
|
| 53 |
+
"speakers": ["\u30eb\u30a4\u30ba", "\u30c6\u30a3\u30d5\u30a1\u30cb\u30a2", "\u30a4\u30eb\u30af\u30af\u30a5", "\u30a2\u30f3\u30ea\u30a8\u30c3\u30bf", "\u30bf\u30d0\u30b5", "\u30b7\u30a8\u30b9\u30bf", "\u30cf\u30eb\u30ca", "\u5c11\u5973\u30ea\u30b7\u30e5", "\u30ea\u30b7\u30e5", "\u30a2\u30ad\u30ca", "\u30af\u30ea\u30b9", "\u30ab\u30c8\u30ec\u30a2", "\u30a8\u30ec\u30aa\u30ce\u30fc\u30eb", "\u30e2\u30f3\u30e2\u30e9\u30f3\u30b7\u30fc", "\u30ea\u30fc\u30f4\u30eb", "\u30ad\u30e5\u30eb\u30b1", "\u30a6\u30a7\u30b6\u30ea\u30fc", "\u30b5\u30a4\u30c8", "\u30ae\u30fc\u30b7\u30e5", "\u30b3\u30eb\u30d9\u30fc\u30eb", "\u30aa\u30b9\u30de\u30f3", "\u30c7\u30eb\u30d5\u30ea\u30f3\u30ac\u30fc", "\u30c6\u30af\u30b9\u30c8", "\u30c0\u30f3\u30d7\u30ea\u30e1", "\u30ac\u30ec\u30c3\u30c8", "\u30b9\u30ab\u30ed\u30f3"],
|
| 54 |
+
"symbols": ["_", ",", ".", "!", "?", "-", "~", "\u2026", "A", "E", "I", "N", "O", "Q", "U", "a", "b", "d", "e", "f", "g", "h", "i", "j", "k", "m", "n", "o", "p", "r", "s", "t", "u", "v", "w", "y", "z", "\u0283", "\u02a7", "\u02a6", "\u2193", "\u2191", " "]
|
| 55 |
+
}
|
configs/zh_ja_mixture_base.json
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"eval_interval": 1000,
|
| 5 |
+
"seed": 1234,
|
| 6 |
+
"epochs": 10000,
|
| 7 |
+
"learning_rate": 2e-4,
|
| 8 |
+
"betas": [0.8, 0.99],
|
| 9 |
+
"eps": 1e-9,
|
| 10 |
+
"batch_size": 32,
|
| 11 |
+
"fp16_run": true,
|
| 12 |
+
"lr_decay": 0.999875,
|
| 13 |
+
"segment_size": 8192,
|
| 14 |
+
"init_lr_ratio": 1,
|
| 15 |
+
"warmup_epochs": 0,
|
| 16 |
+
"c_mel": 45,
|
| 17 |
+
"c_kl": 1.0
|
| 18 |
+
},
|
| 19 |
+
"data": {
|
| 20 |
+
"training_files":"filelists/mix_train_filelist.txt.cleaned",
|
| 21 |
+
"validation_files":"filelists/mix_val_filelist.txt.cleaned",
|
| 22 |
+
"text_cleaners":["zh_ja_mixture_cleaners"],
|
| 23 |
+
"max_wav_value": 32768.0,
|
| 24 |
+
"sampling_rate": 22050,
|
| 25 |
+
"filter_length": 1024,
|
| 26 |
+
"hop_length": 256,
|
| 27 |
+
"win_length": 1024,
|
| 28 |
+
"n_mel_channels": 80,
|
| 29 |
+
"mel_fmin": 0.0,
|
| 30 |
+
"mel_fmax": null,
|
| 31 |
+
"add_blank": true,
|
| 32 |
+
"n_speakers": 5,
|
| 33 |
+
"cleaned_text": true
|
| 34 |
+
},
|
| 35 |
+
"model": {
|
| 36 |
+
"inter_channels": 192,
|
| 37 |
+
"hidden_channels": 192,
|
| 38 |
+
"filter_channels": 768,
|
| 39 |
+
"n_heads": 2,
|
| 40 |
+
"n_layers": 6,
|
| 41 |
+
"kernel_size": 3,
|
| 42 |
+
"p_dropout": 0.1,
|
| 43 |
+
"resblock": "1",
|
| 44 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 45 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 46 |
+
"upsample_rates": [8,8,2,2],
|
| 47 |
+
"upsample_initial_channel": 512,
|
| 48 |
+
"upsample_kernel_sizes": [16,16,4,4],
|
| 49 |
+
"n_layers_q": 3,
|
| 50 |
+
"use_spectral_norm": false,
|
| 51 |
+
"gin_channels": 256
|
| 52 |
+
},
|
| 53 |
+
"speakers": ["\u7dbe\u5730\u5be7\u3005", "\u5728\u539f\u4e03\u6d77", "\u5c0f\u8338", "\u5510\u4e50\u541f"],
|
| 54 |
+
"symbols": ["_", ",", ".", "!", "?", "-", "~", "\u2026", "A", "E", "I", "N", "O", "Q", "U", "a", "b", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "r", "s", "t", "u", "v", "w", "y", "z", "\u0283", "\u02a7", "\u02a6", "\u026f", "\u0279", "\u0259", "\u0265", "\u207c", "\u02b0", "`", "\u2192", "\u2193", "\u2191", " "]
|
| 55 |
+
}
|
data_utils.py
ADDED
|
@@ -0,0 +1,393 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import time
|
| 2 |
+
import os
|
| 3 |
+
import random
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import torch.utils.data
|
| 7 |
+
|
| 8 |
+
import commons
|
| 9 |
+
from mel_processing import spectrogram_torch
|
| 10 |
+
from utils import load_wav_to_torch, load_filepaths_and_text
|
| 11 |
+
from text import text_to_sequence, cleaned_text_to_sequence
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class TextAudioLoader(torch.utils.data.Dataset):
|
| 15 |
+
"""
|
| 16 |
+
1) loads audio, text pairs
|
| 17 |
+
2) normalizes text and converts them to sequences of integers
|
| 18 |
+
3) computes spectrograms from audio files.
|
| 19 |
+
"""
|
| 20 |
+
def __init__(self, audiopaths_and_text, hparams):
|
| 21 |
+
self.audiopaths_and_text = load_filepaths_and_text(audiopaths_and_text)
|
| 22 |
+
self.text_cleaners = hparams.text_cleaners
|
| 23 |
+
self.max_wav_value = hparams.max_wav_value
|
| 24 |
+
self.sampling_rate = hparams.sampling_rate
|
| 25 |
+
self.filter_length = hparams.filter_length
|
| 26 |
+
self.hop_length = hparams.hop_length
|
| 27 |
+
self.win_length = hparams.win_length
|
| 28 |
+
self.sampling_rate = hparams.sampling_rate
|
| 29 |
+
|
| 30 |
+
self.cleaned_text = getattr(hparams, "cleaned_text", False)
|
| 31 |
+
|
| 32 |
+
self.add_blank = hparams.add_blank
|
| 33 |
+
self.min_text_len = getattr(hparams, "min_text_len", 1)
|
| 34 |
+
self.max_text_len = getattr(hparams, "max_text_len", 190)
|
| 35 |
+
|
| 36 |
+
random.seed(1234)
|
| 37 |
+
random.shuffle(self.audiopaths_and_text)
|
| 38 |
+
self._filter()
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def _filter(self):
|
| 42 |
+
"""
|
| 43 |
+
Filter text & store spec lengths
|
| 44 |
+
"""
|
| 45 |
+
# Store spectrogram lengths for Bucketing
|
| 46 |
+
# wav_length ~= file_size / (wav_channels * Bytes per dim) = file_size / (1 * 2)
|
| 47 |
+
# spec_length = wav_length // hop_length
|
| 48 |
+
|
| 49 |
+
audiopaths_and_text_new = []
|
| 50 |
+
lengths = []
|
| 51 |
+
for audiopath, text in self.audiopaths_and_text:
|
| 52 |
+
if self.min_text_len <= len(text) and len(text) <= self.max_text_len:
|
| 53 |
+
audiopaths_and_text_new.append([audiopath, text])
|
| 54 |
+
lengths.append(os.path.getsize(audiopath) // (2 * self.hop_length))
|
| 55 |
+
self.audiopaths_and_text = audiopaths_and_text_new
|
| 56 |
+
self.lengths = lengths
|
| 57 |
+
|
| 58 |
+
def get_audio_text_pair(self, audiopath_and_text):
|
| 59 |
+
# separate filename and text
|
| 60 |
+
audiopath, text = audiopath_and_text[0], audiopath_and_text[1]
|
| 61 |
+
text = self.get_text(text)
|
| 62 |
+
spec, wav = self.get_audio(audiopath)
|
| 63 |
+
return (text, spec, wav)
|
| 64 |
+
|
| 65 |
+
def get_audio(self, filename):
|
| 66 |
+
audio, sampling_rate = load_wav_to_torch(filename)
|
| 67 |
+
if sampling_rate != self.sampling_rate:
|
| 68 |
+
raise ValueError("{} {} SR doesn't match target {} SR".format(
|
| 69 |
+
sampling_rate, self.sampling_rate))
|
| 70 |
+
audio_norm = audio / self.max_wav_value
|
| 71 |
+
audio_norm = audio_norm.unsqueeze(0)
|
| 72 |
+
spec_filename = filename.replace(".wav", ".spec.pt")
|
| 73 |
+
if os.path.exists(spec_filename):
|
| 74 |
+
spec = torch.load(spec_filename)
|
| 75 |
+
else:
|
| 76 |
+
spec = spectrogram_torch(audio_norm, self.filter_length,
|
| 77 |
+
self.sampling_rate, self.hop_length, self.win_length,
|
| 78 |
+
center=False)
|
| 79 |
+
spec = torch.squeeze(spec, 0)
|
| 80 |
+
torch.save(spec, spec_filename)
|
| 81 |
+
return spec, audio_norm
|
| 82 |
+
|
| 83 |
+
def get_text(self, text):
|
| 84 |
+
if self.cleaned_text:
|
| 85 |
+
text_norm = cleaned_text_to_sequence(text)
|
| 86 |
+
else:
|
| 87 |
+
text_norm = text_to_sequence(text, self.text_cleaners)
|
| 88 |
+
if self.add_blank:
|
| 89 |
+
text_norm = commons.intersperse(text_norm, 0)
|
| 90 |
+
text_norm = torch.LongTensor(text_norm)
|
| 91 |
+
return text_norm
|
| 92 |
+
|
| 93 |
+
def __getitem__(self, index):
|
| 94 |
+
return self.get_audio_text_pair(self.audiopaths_and_text[index])
|
| 95 |
+
|
| 96 |
+
def __len__(self):
|
| 97 |
+
return len(self.audiopaths_and_text)
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
class TextAudioCollate():
|
| 101 |
+
""" Zero-pads model inputs and targets
|
| 102 |
+
"""
|
| 103 |
+
def __init__(self, return_ids=False):
|
| 104 |
+
self.return_ids = return_ids
|
| 105 |
+
|
| 106 |
+
def __call__(self, batch):
|
| 107 |
+
"""Collate's training batch from normalized text and aduio
|
| 108 |
+
PARAMS
|
| 109 |
+
------
|
| 110 |
+
batch: [text_normalized, spec_normalized, wav_normalized]
|
| 111 |
+
"""
|
| 112 |
+
# Right zero-pad all one-hot text sequences to max input length
|
| 113 |
+
_, ids_sorted_decreasing = torch.sort(
|
| 114 |
+
torch.LongTensor([x[1].size(1) for x in batch]),
|
| 115 |
+
dim=0, descending=True)
|
| 116 |
+
|
| 117 |
+
max_text_len = max([len(x[0]) for x in batch])
|
| 118 |
+
max_spec_len = max([x[1].size(1) for x in batch])
|
| 119 |
+
max_wav_len = max([x[2].size(1) for x in batch])
|
| 120 |
+
|
| 121 |
+
text_lengths = torch.LongTensor(len(batch))
|
| 122 |
+
spec_lengths = torch.LongTensor(len(batch))
|
| 123 |
+
wav_lengths = torch.LongTensor(len(batch))
|
| 124 |
+
|
| 125 |
+
text_padded = torch.LongTensor(len(batch), max_text_len)
|
| 126 |
+
spec_padded = torch.FloatTensor(len(batch), batch[0][1].size(0), max_spec_len)
|
| 127 |
+
wav_padded = torch.FloatTensor(len(batch), 1, max_wav_len)
|
| 128 |
+
text_padded.zero_()
|
| 129 |
+
spec_padded.zero_()
|
| 130 |
+
wav_padded.zero_()
|
| 131 |
+
for i in range(len(ids_sorted_decreasing)):
|
| 132 |
+
row = batch[ids_sorted_decreasing[i]]
|
| 133 |
+
|
| 134 |
+
text = row[0]
|
| 135 |
+
text_padded[i, :text.size(0)] = text
|
| 136 |
+
text_lengths[i] = text.size(0)
|
| 137 |
+
|
| 138 |
+
spec = row[1]
|
| 139 |
+
spec_padded[i, :, :spec.size(1)] = spec
|
| 140 |
+
spec_lengths[i] = spec.size(1)
|
| 141 |
+
|
| 142 |
+
wav = row[2]
|
| 143 |
+
wav_padded[i, :, :wav.size(1)] = wav
|
| 144 |
+
wav_lengths[i] = wav.size(1)
|
| 145 |
+
|
| 146 |
+
if self.return_ids:
|
| 147 |
+
return text_padded, text_lengths, spec_padded, spec_lengths, wav_padded, wav_lengths, ids_sorted_decreasing
|
| 148 |
+
return text_padded, text_lengths, spec_padded, spec_lengths, wav_padded, wav_lengths
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
"""Multi speaker version"""
|
| 152 |
+
class TextAudioSpeakerLoader(torch.utils.data.Dataset):
|
| 153 |
+
"""
|
| 154 |
+
1) loads audio, speaker_id, text pairs
|
| 155 |
+
2) normalizes text and converts them to sequences of integers
|
| 156 |
+
3) computes spectrograms from audio files.
|
| 157 |
+
"""
|
| 158 |
+
def __init__(self, audiopaths_sid_text, hparams):
|
| 159 |
+
self.audiopaths_sid_text = load_filepaths_and_text(audiopaths_sid_text)
|
| 160 |
+
self.text_cleaners = hparams.text_cleaners
|
| 161 |
+
self.max_wav_value = hparams.max_wav_value
|
| 162 |
+
self.sampling_rate = hparams.sampling_rate
|
| 163 |
+
self.filter_length = hparams.filter_length
|
| 164 |
+
self.hop_length = hparams.hop_length
|
| 165 |
+
self.win_length = hparams.win_length
|
| 166 |
+
self.sampling_rate = hparams.sampling_rate
|
| 167 |
+
|
| 168 |
+
self.cleaned_text = getattr(hparams, "cleaned_text", False)
|
| 169 |
+
|
| 170 |
+
self.add_blank = hparams.add_blank
|
| 171 |
+
self.min_text_len = getattr(hparams, "min_text_len", 1)
|
| 172 |
+
self.max_text_len = getattr(hparams, "max_text_len", 190)
|
| 173 |
+
|
| 174 |
+
random.seed(1234)
|
| 175 |
+
random.shuffle(self.audiopaths_sid_text)
|
| 176 |
+
self._filter()
|
| 177 |
+
|
| 178 |
+
def _filter(self):
|
| 179 |
+
"""
|
| 180 |
+
Filter text & store spec lengths
|
| 181 |
+
"""
|
| 182 |
+
# Store spectrogram lengths for Bucketing
|
| 183 |
+
# wav_length ~= file_size / (wav_channels * Bytes per dim) = file_size / (1 * 2)
|
| 184 |
+
# spec_length = wav_length // hop_length
|
| 185 |
+
|
| 186 |
+
audiopaths_sid_text_new = []
|
| 187 |
+
lengths = []
|
| 188 |
+
for audiopath, sid, text in self.audiopaths_sid_text:
|
| 189 |
+
audiopath = "E:/uma_voice/" + audiopath
|
| 190 |
+
if self.min_text_len <= len(text) and len(text) <= self.max_text_len:
|
| 191 |
+
audiopaths_sid_text_new.append([audiopath, sid, text])
|
| 192 |
+
lengths.append(os.path.getsize(audiopath) // (2 * self.hop_length))
|
| 193 |
+
self.audiopaths_sid_text = audiopaths_sid_text_new
|
| 194 |
+
self.lengths = lengths
|
| 195 |
+
|
| 196 |
+
def get_audio_text_speaker_pair(self, audiopath_sid_text):
|
| 197 |
+
# separate filename, speaker_id and text
|
| 198 |
+
audiopath, sid, text = audiopath_sid_text[0], audiopath_sid_text[1], audiopath_sid_text[2]
|
| 199 |
+
text = self.get_text(text)
|
| 200 |
+
spec, wav = self.get_audio(audiopath)
|
| 201 |
+
sid = self.get_sid(sid)
|
| 202 |
+
return (text, spec, wav, sid)
|
| 203 |
+
|
| 204 |
+
def get_audio(self, filename):
|
| 205 |
+
audio, sampling_rate = load_wav_to_torch(filename)
|
| 206 |
+
if sampling_rate != self.sampling_rate:
|
| 207 |
+
raise ValueError("{} {} SR doesn't match target {} SR".format(
|
| 208 |
+
sampling_rate, self.sampling_rate))
|
| 209 |
+
audio_norm = audio / self.max_wav_value
|
| 210 |
+
audio_norm = audio_norm.unsqueeze(0)
|
| 211 |
+
spec_filename = filename.replace(".wav", ".spec.pt")
|
| 212 |
+
if os.path.exists(spec_filename):
|
| 213 |
+
spec = torch.load(spec_filename)
|
| 214 |
+
else:
|
| 215 |
+
spec = spectrogram_torch(audio_norm, self.filter_length,
|
| 216 |
+
self.sampling_rate, self.hop_length, self.win_length,
|
| 217 |
+
center=False)
|
| 218 |
+
spec = torch.squeeze(spec, 0)
|
| 219 |
+
torch.save(spec, spec_filename)
|
| 220 |
+
return spec, audio_norm
|
| 221 |
+
|
| 222 |
+
def get_text(self, text):
|
| 223 |
+
if self.cleaned_text:
|
| 224 |
+
text_norm = cleaned_text_to_sequence(text)
|
| 225 |
+
else:
|
| 226 |
+
text_norm = text_to_sequence(text, self.text_cleaners)
|
| 227 |
+
if self.add_blank:
|
| 228 |
+
text_norm = commons.intersperse(text_norm, 0)
|
| 229 |
+
text_norm = torch.LongTensor(text_norm)
|
| 230 |
+
return text_norm
|
| 231 |
+
|
| 232 |
+
def get_sid(self, sid):
|
| 233 |
+
sid = torch.LongTensor([int(sid)])
|
| 234 |
+
return sid
|
| 235 |
+
|
| 236 |
+
def __getitem__(self, index):
|
| 237 |
+
return self.get_audio_text_speaker_pair(self.audiopaths_sid_text[index])
|
| 238 |
+
|
| 239 |
+
def __len__(self):
|
| 240 |
+
return len(self.audiopaths_sid_text)
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
class TextAudioSpeakerCollate():
|
| 244 |
+
""" Zero-pads model inputs and targets
|
| 245 |
+
"""
|
| 246 |
+
def __init__(self, return_ids=False):
|
| 247 |
+
self.return_ids = return_ids
|
| 248 |
+
|
| 249 |
+
def __call__(self, batch):
|
| 250 |
+
"""Collate's training batch from normalized text, audio and speaker identities
|
| 251 |
+
PARAMS
|
| 252 |
+
------
|
| 253 |
+
batch: [text_normalized, spec_normalized, wav_normalized, sid]
|
| 254 |
+
"""
|
| 255 |
+
# Right zero-pad all one-hot text sequences to max input length
|
| 256 |
+
_, ids_sorted_decreasing = torch.sort(
|
| 257 |
+
torch.LongTensor([x[1].size(1) for x in batch]),
|
| 258 |
+
dim=0, descending=True)
|
| 259 |
+
|
| 260 |
+
max_text_len = max([len(x[0]) for x in batch])
|
| 261 |
+
max_spec_len = max([x[1].size(1) for x in batch])
|
| 262 |
+
max_wav_len = max([x[2].size(1) for x in batch])
|
| 263 |
+
|
| 264 |
+
text_lengths = torch.LongTensor(len(batch))
|
| 265 |
+
spec_lengths = torch.LongTensor(len(batch))
|
| 266 |
+
wav_lengths = torch.LongTensor(len(batch))
|
| 267 |
+
sid = torch.LongTensor(len(batch))
|
| 268 |
+
|
| 269 |
+
text_padded = torch.LongTensor(len(batch), max_text_len)
|
| 270 |
+
spec_padded = torch.FloatTensor(len(batch), batch[0][1].size(0), max_spec_len)
|
| 271 |
+
wav_padded = torch.FloatTensor(len(batch), 1, max_wav_len)
|
| 272 |
+
text_padded.zero_()
|
| 273 |
+
spec_padded.zero_()
|
| 274 |
+
wav_padded.zero_()
|
| 275 |
+
for i in range(len(ids_sorted_decreasing)):
|
| 276 |
+
row = batch[ids_sorted_decreasing[i]]
|
| 277 |
+
|
| 278 |
+
text = row[0]
|
| 279 |
+
text_padded[i, :text.size(0)] = text
|
| 280 |
+
text_lengths[i] = text.size(0)
|
| 281 |
+
|
| 282 |
+
spec = row[1]
|
| 283 |
+
spec_padded[i, :, :spec.size(1)] = spec
|
| 284 |
+
spec_lengths[i] = spec.size(1)
|
| 285 |
+
|
| 286 |
+
wav = row[2]
|
| 287 |
+
wav_padded[i, :, :wav.size(1)] = wav
|
| 288 |
+
wav_lengths[i] = wav.size(1)
|
| 289 |
+
|
| 290 |
+
sid[i] = row[3]
|
| 291 |
+
|
| 292 |
+
if self.return_ids:
|
| 293 |
+
return text_padded, text_lengths, spec_padded, spec_lengths, wav_padded, wav_lengths, sid, ids_sorted_decreasing
|
| 294 |
+
return text_padded, text_lengths, spec_padded, spec_lengths, wav_padded, wav_lengths, sid
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
class DistributedBucketSampler(torch.utils.data.distributed.DistributedSampler):
|
| 298 |
+
"""
|
| 299 |
+
Maintain similar input lengths in a batch.
|
| 300 |
+
Length groups are specified by boundaries.
|
| 301 |
+
Ex) boundaries = [b1, b2, b3] -> any batch is included either {x | b1 < length(x) <=b2} or {x | b2 < length(x) <= b3}.
|
| 302 |
+
|
| 303 |
+
It removes samples which are not included in the boundaries.
|
| 304 |
+
Ex) boundaries = [b1, b2, b3] -> any x s.t. length(x) <= b1 or length(x) > b3 are discarded.
|
| 305 |
+
"""
|
| 306 |
+
def __init__(self, dataset, batch_size, boundaries, num_replicas=None, rank=None, shuffle=True):
|
| 307 |
+
super().__init__(dataset, num_replicas=num_replicas, rank=rank, shuffle=shuffle)
|
| 308 |
+
self.lengths = dataset.lengths
|
| 309 |
+
self.batch_size = batch_size
|
| 310 |
+
self.boundaries = boundaries
|
| 311 |
+
|
| 312 |
+
self.buckets, self.num_samples_per_bucket = self._create_buckets()
|
| 313 |
+
self.total_size = sum(self.num_samples_per_bucket)
|
| 314 |
+
self.num_samples = self.total_size // self.num_replicas
|
| 315 |
+
|
| 316 |
+
def _create_buckets(self):
|
| 317 |
+
buckets = [[] for _ in range(len(self.boundaries) - 1)]
|
| 318 |
+
for i in range(len(self.lengths)):
|
| 319 |
+
length = self.lengths[i]
|
| 320 |
+
idx_bucket = self._bisect(length)
|
| 321 |
+
if idx_bucket != -1:
|
| 322 |
+
buckets[idx_bucket].append(i)
|
| 323 |
+
|
| 324 |
+
for i in range(len(buckets) - 1, 0, -1):
|
| 325 |
+
if len(buckets[i]) == 0:
|
| 326 |
+
buckets.pop(i)
|
| 327 |
+
self.boundaries.pop(i+1)
|
| 328 |
+
|
| 329 |
+
num_samples_per_bucket = []
|
| 330 |
+
for i in range(len(buckets)):
|
| 331 |
+
len_bucket = len(buckets[i])
|
| 332 |
+
total_batch_size = self.num_replicas * self.batch_size
|
| 333 |
+
rem = (total_batch_size - (len_bucket % total_batch_size)) % total_batch_size
|
| 334 |
+
num_samples_per_bucket.append(len_bucket + rem)
|
| 335 |
+
return buckets, num_samples_per_bucket
|
| 336 |
+
|
| 337 |
+
def __iter__(self):
|
| 338 |
+
# deterministically shuffle based on epoch
|
| 339 |
+
g = torch.Generator()
|
| 340 |
+
g.manual_seed(self.epoch)
|
| 341 |
+
|
| 342 |
+
indices = []
|
| 343 |
+
if self.shuffle:
|
| 344 |
+
for bucket in self.buckets:
|
| 345 |
+
indices.append(torch.randperm(len(bucket), generator=g).tolist())
|
| 346 |
+
else:
|
| 347 |
+
for bucket in self.buckets:
|
| 348 |
+
indices.append(list(range(len(bucket))))
|
| 349 |
+
|
| 350 |
+
batches = []
|
| 351 |
+
for i in range(len(self.buckets)):
|
| 352 |
+
bucket = self.buckets[i]
|
| 353 |
+
len_bucket = len(bucket)
|
| 354 |
+
ids_bucket = indices[i]
|
| 355 |
+
num_samples_bucket = self.num_samples_per_bucket[i]
|
| 356 |
+
|
| 357 |
+
# add extra samples to make it evenly divisible
|
| 358 |
+
rem = num_samples_bucket - len_bucket
|
| 359 |
+
ids_bucket = ids_bucket + ids_bucket * (rem // len_bucket) + ids_bucket[:(rem % len_bucket)]
|
| 360 |
+
|
| 361 |
+
# subsample
|
| 362 |
+
ids_bucket = ids_bucket[self.rank::self.num_replicas]
|
| 363 |
+
|
| 364 |
+
# batching
|
| 365 |
+
for j in range(len(ids_bucket) // self.batch_size):
|
| 366 |
+
batch = [bucket[idx] for idx in ids_bucket[j*self.batch_size:(j+1)*self.batch_size]]
|
| 367 |
+
batches.append(batch)
|
| 368 |
+
|
| 369 |
+
if self.shuffle:
|
| 370 |
+
batch_ids = torch.randperm(len(batches), generator=g).tolist()
|
| 371 |
+
batches = [batches[i] for i in batch_ids]
|
| 372 |
+
self.batches = batches
|
| 373 |
+
|
| 374 |
+
assert len(self.batches) * self.batch_size == self.num_samples
|
| 375 |
+
return iter(self.batches)
|
| 376 |
+
|
| 377 |
+
def _bisect(self, x, lo=0, hi=None):
|
| 378 |
+
if hi is None:
|
| 379 |
+
hi = len(self.boundaries) - 1
|
| 380 |
+
|
| 381 |
+
if hi > lo:
|
| 382 |
+
mid = (hi + lo) // 2
|
| 383 |
+
if self.boundaries[mid] < x and x <= self.boundaries[mid+1]:
|
| 384 |
+
return mid
|
| 385 |
+
elif x <= self.boundaries[mid]:
|
| 386 |
+
return self._bisect(x, lo, mid)
|
| 387 |
+
else:
|
| 388 |
+
return self._bisect(x, mid + 1, hi)
|
| 389 |
+
else:
|
| 390 |
+
return -1
|
| 391 |
+
|
| 392 |
+
def __len__(self):
|
| 393 |
+
return self.num_samples // self.batch_size
|
flagged/log.csv
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Type your sentence here:,output,flag,username,timestamp
|
| 2 |
+
,,,,2022-12-17 19:11:31.767915
|
inference.py
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import matplotlib.pyplot as plt
|
| 2 |
+
import IPython.display as ipd
|
| 3 |
+
|
| 4 |
+
import os
|
| 5 |
+
import json
|
| 6 |
+
import math
|
| 7 |
+
import torch
|
| 8 |
+
from torch import nn
|
| 9 |
+
from torch.nn import functional as F
|
| 10 |
+
from torch.utils.data import DataLoader
|
| 11 |
+
|
| 12 |
+
import commons
|
| 13 |
+
import utils
|
| 14 |
+
from data_utils import TextAudioLoader, TextAudioCollate, TextAudioSpeakerLoader, TextAudioSpeakerCollate
|
| 15 |
+
from models import SynthesizerTrn
|
| 16 |
+
from text.symbols import symbols
|
| 17 |
+
from text import text_to_sequence
|
| 18 |
+
|
| 19 |
+
from scipy.io.wavfile import write
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def get_text(text, hps):
|
| 23 |
+
text_norm = text_to_sequence(text, hps.data.text_cleaners)
|
| 24 |
+
if hps.data.add_blank:
|
| 25 |
+
text_norm = commons.intersperse(text_norm, 0)
|
| 26 |
+
text_norm = torch.LongTensor(text_norm)
|
| 27 |
+
return text_norm
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
hps = utils.get_hparams_from_file("./configs/yuzu.json")
|
| 31 |
+
|
| 32 |
+
net_g = SynthesizerTrn(
|
| 33 |
+
len(symbols),
|
| 34 |
+
hps.data.filter_length // 2 + 1,
|
| 35 |
+
hps.train.segment_size // hps.data.hop_length,
|
| 36 |
+
n_speakers=hps.data.n_speakers,
|
| 37 |
+
**hps.model).cuda()
|
| 38 |
+
_ = net_g.eval()
|
| 39 |
+
|
| 40 |
+
_ = utils.load_checkpoint("pretrained_models/yuzu.pth", net_g, None)
|
losses.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch.nn import functional as F
|
| 3 |
+
|
| 4 |
+
import commons
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def feature_loss(fmap_r, fmap_g):
|
| 8 |
+
loss = 0
|
| 9 |
+
for dr, dg in zip(fmap_r, fmap_g):
|
| 10 |
+
for rl, gl in zip(dr, dg):
|
| 11 |
+
rl = rl.float().detach()
|
| 12 |
+
gl = gl.float()
|
| 13 |
+
loss += torch.mean(torch.abs(rl - gl))
|
| 14 |
+
|
| 15 |
+
return loss * 2
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def discriminator_loss(disc_real_outputs, disc_generated_outputs):
|
| 19 |
+
loss = 0
|
| 20 |
+
r_losses = []
|
| 21 |
+
g_losses = []
|
| 22 |
+
for dr, dg in zip(disc_real_outputs, disc_generated_outputs):
|
| 23 |
+
dr = dr.float()
|
| 24 |
+
dg = dg.float()
|
| 25 |
+
r_loss = torch.mean((1-dr)**2)
|
| 26 |
+
g_loss = torch.mean(dg**2)
|
| 27 |
+
loss += (r_loss + g_loss)
|
| 28 |
+
r_losses.append(r_loss.item())
|
| 29 |
+
g_losses.append(g_loss.item())
|
| 30 |
+
|
| 31 |
+
return loss, r_losses, g_losses
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def generator_loss(disc_outputs):
|
| 35 |
+
loss = 0
|
| 36 |
+
gen_losses = []
|
| 37 |
+
for dg in disc_outputs:
|
| 38 |
+
dg = dg.float()
|
| 39 |
+
l = torch.mean((1-dg)**2)
|
| 40 |
+
gen_losses.append(l)
|
| 41 |
+
loss += l
|
| 42 |
+
|
| 43 |
+
return loss, gen_losses
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def kl_loss(z_p, logs_q, m_p, logs_p, z_mask):
|
| 47 |
+
"""
|
| 48 |
+
z_p, logs_q: [b, h, t_t]
|
| 49 |
+
m_p, logs_p: [b, h, t_t]
|
| 50 |
+
"""
|
| 51 |
+
z_p = z_p.float()
|
| 52 |
+
logs_q = logs_q.float()
|
| 53 |
+
m_p = m_p.float()
|
| 54 |
+
logs_p = logs_p.float()
|
| 55 |
+
z_mask = z_mask.float()
|
| 56 |
+
|
| 57 |
+
kl = logs_p - logs_q - 0.5
|
| 58 |
+
kl += 0.5 * ((z_p - m_p)**2) * torch.exp(-2. * logs_p)
|
| 59 |
+
kl = torch.sum(kl * z_mask)
|
| 60 |
+
l = kl / torch.sum(z_mask)
|
| 61 |
+
return l
|
mel_processing.py
ADDED
|
@@ -0,0 +1,112 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import os
|
| 3 |
+
import random
|
| 4 |
+
import torch
|
| 5 |
+
from torch import nn
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
import torch.utils.data
|
| 8 |
+
import numpy as np
|
| 9 |
+
import librosa
|
| 10 |
+
import librosa.util as librosa_util
|
| 11 |
+
from librosa.util import normalize, pad_center, tiny
|
| 12 |
+
from scipy.signal import get_window
|
| 13 |
+
from scipy.io.wavfile import read
|
| 14 |
+
from librosa.filters import mel as librosa_mel_fn
|
| 15 |
+
|
| 16 |
+
MAX_WAV_VALUE = 32768.0
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
|
| 20 |
+
"""
|
| 21 |
+
PARAMS
|
| 22 |
+
------
|
| 23 |
+
C: compression factor
|
| 24 |
+
"""
|
| 25 |
+
return torch.log(torch.clamp(x, min=clip_val) * C)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def dynamic_range_decompression_torch(x, C=1):
|
| 29 |
+
"""
|
| 30 |
+
PARAMS
|
| 31 |
+
------
|
| 32 |
+
C: compression factor used to compress
|
| 33 |
+
"""
|
| 34 |
+
return torch.exp(x) / C
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def spectral_normalize_torch(magnitudes):
|
| 38 |
+
output = dynamic_range_compression_torch(magnitudes)
|
| 39 |
+
return output
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def spectral_de_normalize_torch(magnitudes):
|
| 43 |
+
output = dynamic_range_decompression_torch(magnitudes)
|
| 44 |
+
return output
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
mel_basis = {}
|
| 48 |
+
hann_window = {}
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def spectrogram_torch(y, n_fft, sampling_rate, hop_size, win_size, center=False):
|
| 52 |
+
if torch.min(y) < -1.:
|
| 53 |
+
print('min value is ', torch.min(y))
|
| 54 |
+
if torch.max(y) > 1.:
|
| 55 |
+
print('max value is ', torch.max(y))
|
| 56 |
+
|
| 57 |
+
global hann_window
|
| 58 |
+
dtype_device = str(y.dtype) + '_' + str(y.device)
|
| 59 |
+
wnsize_dtype_device = str(win_size) + '_' + dtype_device
|
| 60 |
+
if wnsize_dtype_device not in hann_window:
|
| 61 |
+
hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(dtype=y.dtype, device=y.device)
|
| 62 |
+
|
| 63 |
+
y = torch.nn.functional.pad(y.unsqueeze(1), (int((n_fft-hop_size)/2), int((n_fft-hop_size)/2)), mode='reflect')
|
| 64 |
+
y = y.squeeze(1)
|
| 65 |
+
|
| 66 |
+
spec = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[wnsize_dtype_device],
|
| 67 |
+
center=center, pad_mode='reflect', normalized=False, onesided=True)
|
| 68 |
+
|
| 69 |
+
spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6)
|
| 70 |
+
return spec
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def spec_to_mel_torch(spec, n_fft, num_mels, sampling_rate, fmin, fmax):
|
| 74 |
+
global mel_basis
|
| 75 |
+
dtype_device = str(spec.dtype) + '_' + str(spec.device)
|
| 76 |
+
fmax_dtype_device = str(fmax) + '_' + dtype_device
|
| 77 |
+
if fmax_dtype_device not in mel_basis:
|
| 78 |
+
mel = librosa_mel_fn(sampling_rate, n_fft, num_mels, fmin, fmax)
|
| 79 |
+
mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(dtype=spec.dtype, device=spec.device)
|
| 80 |
+
spec = torch.matmul(mel_basis[fmax_dtype_device], spec)
|
| 81 |
+
spec = spectral_normalize_torch(spec)
|
| 82 |
+
return spec
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def mel_spectrogram_torch(y, n_fft, num_mels, sampling_rate, hop_size, win_size, fmin, fmax, center=False):
|
| 86 |
+
if torch.min(y) < -1.:
|
| 87 |
+
print('min value is ', torch.min(y))
|
| 88 |
+
if torch.max(y) > 1.:
|
| 89 |
+
print('max value is ', torch.max(y))
|
| 90 |
+
|
| 91 |
+
global mel_basis, hann_window
|
| 92 |
+
dtype_device = str(y.dtype) + '_' + str(y.device)
|
| 93 |
+
fmax_dtype_device = str(fmax) + '_' + dtype_device
|
| 94 |
+
wnsize_dtype_device = str(win_size) + '_' + dtype_device
|
| 95 |
+
if fmax_dtype_device not in mel_basis:
|
| 96 |
+
mel = librosa_mel_fn(sampling_rate, n_fft, num_mels, fmin, fmax)
|
| 97 |
+
mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(dtype=y.dtype, device=y.device)
|
| 98 |
+
if wnsize_dtype_device not in hann_window:
|
| 99 |
+
hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(dtype=y.dtype, device=y.device)
|
| 100 |
+
|
| 101 |
+
y = torch.nn.functional.pad(y.unsqueeze(1), (int((n_fft-hop_size)/2), int((n_fft-hop_size)/2)), mode='reflect')
|
| 102 |
+
y = y.squeeze(1)
|
| 103 |
+
|
| 104 |
+
spec = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[wnsize_dtype_device],
|
| 105 |
+
center=center, pad_mode='reflect', normalized=False, onesided=True)
|
| 106 |
+
|
| 107 |
+
spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6)
|
| 108 |
+
|
| 109 |
+
spec = torch.matmul(mel_basis[fmax_dtype_device], spec)
|
| 110 |
+
spec = spectral_normalize_torch(spec)
|
| 111 |
+
|
| 112 |
+
return spec
|
models.py
ADDED
|
@@ -0,0 +1,534 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import math
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
from torch.nn import functional as F
|
| 6 |
+
|
| 7 |
+
import commons
|
| 8 |
+
import modules
|
| 9 |
+
import attentions
|
| 10 |
+
import monotonic_align
|
| 11 |
+
|
| 12 |
+
from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
|
| 13 |
+
from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm
|
| 14 |
+
from commons import init_weights, get_padding
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class StochasticDurationPredictor(nn.Module):
|
| 18 |
+
def __init__(self, in_channels, filter_channels, kernel_size, p_dropout, n_flows=4, gin_channels=0):
|
| 19 |
+
super().__init__()
|
| 20 |
+
filter_channels = in_channels # it needs to be removed from future version.
|
| 21 |
+
self.in_channels = in_channels
|
| 22 |
+
self.filter_channels = filter_channels
|
| 23 |
+
self.kernel_size = kernel_size
|
| 24 |
+
self.p_dropout = p_dropout
|
| 25 |
+
self.n_flows = n_flows
|
| 26 |
+
self.gin_channels = gin_channels
|
| 27 |
+
|
| 28 |
+
self.log_flow = modules.Log()
|
| 29 |
+
self.flows = nn.ModuleList()
|
| 30 |
+
self.flows.append(modules.ElementwiseAffine(2))
|
| 31 |
+
for i in range(n_flows):
|
| 32 |
+
self.flows.append(modules.ConvFlow(2, filter_channels, kernel_size, n_layers=3))
|
| 33 |
+
self.flows.append(modules.Flip())
|
| 34 |
+
|
| 35 |
+
self.post_pre = nn.Conv1d(1, filter_channels, 1)
|
| 36 |
+
self.post_proj = nn.Conv1d(filter_channels, filter_channels, 1)
|
| 37 |
+
self.post_convs = modules.DDSConv(filter_channels, kernel_size, n_layers=3, p_dropout=p_dropout)
|
| 38 |
+
self.post_flows = nn.ModuleList()
|
| 39 |
+
self.post_flows.append(modules.ElementwiseAffine(2))
|
| 40 |
+
for i in range(4):
|
| 41 |
+
self.post_flows.append(modules.ConvFlow(2, filter_channels, kernel_size, n_layers=3))
|
| 42 |
+
self.post_flows.append(modules.Flip())
|
| 43 |
+
|
| 44 |
+
self.pre = nn.Conv1d(in_channels, filter_channels, 1)
|
| 45 |
+
self.proj = nn.Conv1d(filter_channels, filter_channels, 1)
|
| 46 |
+
self.convs = modules.DDSConv(filter_channels, kernel_size, n_layers=3, p_dropout=p_dropout)
|
| 47 |
+
if gin_channels != 0:
|
| 48 |
+
self.cond = nn.Conv1d(gin_channels, filter_channels, 1)
|
| 49 |
+
|
| 50 |
+
def forward(self, x, x_mask, w=None, g=None, reverse=False, noise_scale=1.0):
|
| 51 |
+
x = torch.detach(x)
|
| 52 |
+
x = self.pre(x)
|
| 53 |
+
if g is not None:
|
| 54 |
+
g = torch.detach(g)
|
| 55 |
+
x = x + self.cond(g)
|
| 56 |
+
x = self.convs(x, x_mask)
|
| 57 |
+
x = self.proj(x) * x_mask
|
| 58 |
+
|
| 59 |
+
if not reverse:
|
| 60 |
+
flows = self.flows
|
| 61 |
+
assert w is not None
|
| 62 |
+
|
| 63 |
+
logdet_tot_q = 0
|
| 64 |
+
h_w = self.post_pre(w)
|
| 65 |
+
h_w = self.post_convs(h_w, x_mask)
|
| 66 |
+
h_w = self.post_proj(h_w) * x_mask
|
| 67 |
+
e_q = torch.randn(w.size(0), 2, w.size(2)).to(device=x.device, dtype=x.dtype) * x_mask
|
| 68 |
+
z_q = e_q
|
| 69 |
+
for flow in self.post_flows:
|
| 70 |
+
z_q, logdet_q = flow(z_q, x_mask, g=(x + h_w))
|
| 71 |
+
logdet_tot_q += logdet_q
|
| 72 |
+
z_u, z1 = torch.split(z_q, [1, 1], 1)
|
| 73 |
+
u = torch.sigmoid(z_u) * x_mask
|
| 74 |
+
z0 = (w - u) * x_mask
|
| 75 |
+
logdet_tot_q += torch.sum((F.logsigmoid(z_u) + F.logsigmoid(-z_u)) * x_mask, [1,2])
|
| 76 |
+
logq = torch.sum(-0.5 * (math.log(2*math.pi) + (e_q**2)) * x_mask, [1,2]) - logdet_tot_q
|
| 77 |
+
|
| 78 |
+
logdet_tot = 0
|
| 79 |
+
z0, logdet = self.log_flow(z0, x_mask)
|
| 80 |
+
logdet_tot += logdet
|
| 81 |
+
z = torch.cat([z0, z1], 1)
|
| 82 |
+
for flow in flows:
|
| 83 |
+
z, logdet = flow(z, x_mask, g=x, reverse=reverse)
|
| 84 |
+
logdet_tot = logdet_tot + logdet
|
| 85 |
+
nll = torch.sum(0.5 * (math.log(2*math.pi) + (z**2)) * x_mask, [1,2]) - logdet_tot
|
| 86 |
+
return nll + logq # [b]
|
| 87 |
+
else:
|
| 88 |
+
flows = list(reversed(self.flows))
|
| 89 |
+
flows = flows[:-2] + [flows[-1]] # remove a useless vflow
|
| 90 |
+
z = torch.randn(x.size(0), 2, x.size(2)).to(device=x.device, dtype=x.dtype) * noise_scale
|
| 91 |
+
for flow in flows:
|
| 92 |
+
z = flow(z, x_mask, g=x, reverse=reverse)
|
| 93 |
+
z0, z1 = torch.split(z, [1, 1], 1)
|
| 94 |
+
logw = z0
|
| 95 |
+
return logw
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
class DurationPredictor(nn.Module):
|
| 99 |
+
def __init__(self, in_channels, filter_channels, kernel_size, p_dropout, gin_channels=0):
|
| 100 |
+
super().__init__()
|
| 101 |
+
|
| 102 |
+
self.in_channels = in_channels
|
| 103 |
+
self.filter_channels = filter_channels
|
| 104 |
+
self.kernel_size = kernel_size
|
| 105 |
+
self.p_dropout = p_dropout
|
| 106 |
+
self.gin_channels = gin_channels
|
| 107 |
+
|
| 108 |
+
self.drop = nn.Dropout(p_dropout)
|
| 109 |
+
self.conv_1 = nn.Conv1d(in_channels, filter_channels, kernel_size, padding=kernel_size//2)
|
| 110 |
+
self.norm_1 = modules.LayerNorm(filter_channels)
|
| 111 |
+
self.conv_2 = nn.Conv1d(filter_channels, filter_channels, kernel_size, padding=kernel_size//2)
|
| 112 |
+
self.norm_2 = modules.LayerNorm(filter_channels)
|
| 113 |
+
self.proj = nn.Conv1d(filter_channels, 1, 1)
|
| 114 |
+
|
| 115 |
+
if gin_channels != 0:
|
| 116 |
+
self.cond = nn.Conv1d(gin_channels, in_channels, 1)
|
| 117 |
+
|
| 118 |
+
def forward(self, x, x_mask, g=None):
|
| 119 |
+
x = torch.detach(x)
|
| 120 |
+
if g is not None:
|
| 121 |
+
g = torch.detach(g)
|
| 122 |
+
x = x + self.cond(g)
|
| 123 |
+
x = self.conv_1(x * x_mask)
|
| 124 |
+
x = torch.relu(x)
|
| 125 |
+
x = self.norm_1(x)
|
| 126 |
+
x = self.drop(x)
|
| 127 |
+
x = self.conv_2(x * x_mask)
|
| 128 |
+
x = torch.relu(x)
|
| 129 |
+
x = self.norm_2(x)
|
| 130 |
+
x = self.drop(x)
|
| 131 |
+
x = self.proj(x * x_mask)
|
| 132 |
+
return x * x_mask
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
class TextEncoder(nn.Module):
|
| 136 |
+
def __init__(self,
|
| 137 |
+
n_vocab,
|
| 138 |
+
out_channels,
|
| 139 |
+
hidden_channels,
|
| 140 |
+
filter_channels,
|
| 141 |
+
n_heads,
|
| 142 |
+
n_layers,
|
| 143 |
+
kernel_size,
|
| 144 |
+
p_dropout):
|
| 145 |
+
super().__init__()
|
| 146 |
+
self.n_vocab = n_vocab
|
| 147 |
+
self.out_channels = out_channels
|
| 148 |
+
self.hidden_channels = hidden_channels
|
| 149 |
+
self.filter_channels = filter_channels
|
| 150 |
+
self.n_heads = n_heads
|
| 151 |
+
self.n_layers = n_layers
|
| 152 |
+
self.kernel_size = kernel_size
|
| 153 |
+
self.p_dropout = p_dropout
|
| 154 |
+
|
| 155 |
+
self.emb = nn.Embedding(n_vocab, hidden_channels)
|
| 156 |
+
nn.init.normal_(self.emb.weight, 0.0, hidden_channels**-0.5)
|
| 157 |
+
|
| 158 |
+
self.encoder = attentions.Encoder(
|
| 159 |
+
hidden_channels,
|
| 160 |
+
filter_channels,
|
| 161 |
+
n_heads,
|
| 162 |
+
n_layers,
|
| 163 |
+
kernel_size,
|
| 164 |
+
p_dropout)
|
| 165 |
+
self.proj= nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
| 166 |
+
|
| 167 |
+
def forward(self, x, x_lengths):
|
| 168 |
+
x = self.emb(x) * math.sqrt(self.hidden_channels) # [b, t, h]
|
| 169 |
+
x = torch.transpose(x, 1, -1) # [b, h, t]
|
| 170 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype)
|
| 171 |
+
|
| 172 |
+
x = self.encoder(x * x_mask, x_mask)
|
| 173 |
+
stats = self.proj(x) * x_mask
|
| 174 |
+
|
| 175 |
+
m, logs = torch.split(stats, self.out_channels, dim=1)
|
| 176 |
+
return x, m, logs, x_mask
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
class ResidualCouplingBlock(nn.Module):
|
| 180 |
+
def __init__(self,
|
| 181 |
+
channels,
|
| 182 |
+
hidden_channels,
|
| 183 |
+
kernel_size,
|
| 184 |
+
dilation_rate,
|
| 185 |
+
n_layers,
|
| 186 |
+
n_flows=4,
|
| 187 |
+
gin_channels=0):
|
| 188 |
+
super().__init__()
|
| 189 |
+
self.channels = channels
|
| 190 |
+
self.hidden_channels = hidden_channels
|
| 191 |
+
self.kernel_size = kernel_size
|
| 192 |
+
self.dilation_rate = dilation_rate
|
| 193 |
+
self.n_layers = n_layers
|
| 194 |
+
self.n_flows = n_flows
|
| 195 |
+
self.gin_channels = gin_channels
|
| 196 |
+
|
| 197 |
+
self.flows = nn.ModuleList()
|
| 198 |
+
for i in range(n_flows):
|
| 199 |
+
self.flows.append(modules.ResidualCouplingLayer(channels, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=gin_channels, mean_only=True))
|
| 200 |
+
self.flows.append(modules.Flip())
|
| 201 |
+
|
| 202 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 203 |
+
if not reverse:
|
| 204 |
+
for flow in self.flows:
|
| 205 |
+
x, _ = flow(x, x_mask, g=g, reverse=reverse)
|
| 206 |
+
else:
|
| 207 |
+
for flow in reversed(self.flows):
|
| 208 |
+
x = flow(x, x_mask, g=g, reverse=reverse)
|
| 209 |
+
return x
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
class PosteriorEncoder(nn.Module):
|
| 213 |
+
def __init__(self,
|
| 214 |
+
in_channels,
|
| 215 |
+
out_channels,
|
| 216 |
+
hidden_channels,
|
| 217 |
+
kernel_size,
|
| 218 |
+
dilation_rate,
|
| 219 |
+
n_layers,
|
| 220 |
+
gin_channels=0):
|
| 221 |
+
super().__init__()
|
| 222 |
+
self.in_channels = in_channels
|
| 223 |
+
self.out_channels = out_channels
|
| 224 |
+
self.hidden_channels = hidden_channels
|
| 225 |
+
self.kernel_size = kernel_size
|
| 226 |
+
self.dilation_rate = dilation_rate
|
| 227 |
+
self.n_layers = n_layers
|
| 228 |
+
self.gin_channels = gin_channels
|
| 229 |
+
|
| 230 |
+
self.pre = nn.Conv1d(in_channels, hidden_channels, 1)
|
| 231 |
+
self.enc = modules.WN(hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=gin_channels)
|
| 232 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
| 233 |
+
|
| 234 |
+
def forward(self, x, x_lengths, g=None):
|
| 235 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype)
|
| 236 |
+
x = self.pre(x) * x_mask
|
| 237 |
+
x = self.enc(x, x_mask, g=g)
|
| 238 |
+
stats = self.proj(x) * x_mask
|
| 239 |
+
m, logs = torch.split(stats, self.out_channels, dim=1)
|
| 240 |
+
z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask
|
| 241 |
+
return z, m, logs, x_mask
|
| 242 |
+
|
| 243 |
+
|
| 244 |
+
class Generator(torch.nn.Module):
|
| 245 |
+
def __init__(self, initial_channel, resblock, resblock_kernel_sizes, resblock_dilation_sizes, upsample_rates, upsample_initial_channel, upsample_kernel_sizes, gin_channels=0):
|
| 246 |
+
super(Generator, self).__init__()
|
| 247 |
+
self.num_kernels = len(resblock_kernel_sizes)
|
| 248 |
+
self.num_upsamples = len(upsample_rates)
|
| 249 |
+
self.conv_pre = Conv1d(initial_channel, upsample_initial_channel, 7, 1, padding=3)
|
| 250 |
+
resblock = modules.ResBlock1 if resblock == '1' else modules.ResBlock2
|
| 251 |
+
|
| 252 |
+
self.ups = nn.ModuleList()
|
| 253 |
+
for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
|
| 254 |
+
self.ups.append(weight_norm(
|
| 255 |
+
ConvTranspose1d(upsample_initial_channel//(2**i), upsample_initial_channel//(2**(i+1)),
|
| 256 |
+
k, u, padding=(k-u)//2)))
|
| 257 |
+
|
| 258 |
+
self.resblocks = nn.ModuleList()
|
| 259 |
+
for i in range(len(self.ups)):
|
| 260 |
+
ch = upsample_initial_channel//(2**(i+1))
|
| 261 |
+
for j, (k, d) in enumerate(zip(resblock_kernel_sizes, resblock_dilation_sizes)):
|
| 262 |
+
self.resblocks.append(resblock(ch, k, d))
|
| 263 |
+
|
| 264 |
+
self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
|
| 265 |
+
self.ups.apply(init_weights)
|
| 266 |
+
|
| 267 |
+
if gin_channels != 0:
|
| 268 |
+
self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
|
| 269 |
+
|
| 270 |
+
def forward(self, x, g=None):
|
| 271 |
+
x = self.conv_pre(x)
|
| 272 |
+
if g is not None:
|
| 273 |
+
x = x + self.cond(g)
|
| 274 |
+
|
| 275 |
+
for i in range(self.num_upsamples):
|
| 276 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 277 |
+
x = self.ups[i](x)
|
| 278 |
+
xs = None
|
| 279 |
+
for j in range(self.num_kernels):
|
| 280 |
+
if xs is None:
|
| 281 |
+
xs = self.resblocks[i*self.num_kernels+j](x)
|
| 282 |
+
else:
|
| 283 |
+
xs += self.resblocks[i*self.num_kernels+j](x)
|
| 284 |
+
x = xs / self.num_kernels
|
| 285 |
+
x = F.leaky_relu(x)
|
| 286 |
+
x = self.conv_post(x)
|
| 287 |
+
x = torch.tanh(x)
|
| 288 |
+
|
| 289 |
+
return x
|
| 290 |
+
|
| 291 |
+
def remove_weight_norm(self):
|
| 292 |
+
print('Removing weight norm...')
|
| 293 |
+
for l in self.ups:
|
| 294 |
+
remove_weight_norm(l)
|
| 295 |
+
for l in self.resblocks:
|
| 296 |
+
l.remove_weight_norm()
|
| 297 |
+
|
| 298 |
+
|
| 299 |
+
class DiscriminatorP(torch.nn.Module):
|
| 300 |
+
def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):
|
| 301 |
+
super(DiscriminatorP, self).__init__()
|
| 302 |
+
self.period = period
|
| 303 |
+
self.use_spectral_norm = use_spectral_norm
|
| 304 |
+
norm_f = weight_norm if use_spectral_norm == False else spectral_norm
|
| 305 |
+
self.convs = nn.ModuleList([
|
| 306 |
+
norm_f(Conv2d(1, 32, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
|
| 307 |
+
norm_f(Conv2d(32, 128, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
|
| 308 |
+
norm_f(Conv2d(128, 512, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
|
| 309 |
+
norm_f(Conv2d(512, 1024, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
|
| 310 |
+
norm_f(Conv2d(1024, 1024, (kernel_size, 1), 1, padding=(get_padding(kernel_size, 1), 0))),
|
| 311 |
+
])
|
| 312 |
+
self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))
|
| 313 |
+
|
| 314 |
+
def forward(self, x):
|
| 315 |
+
fmap = []
|
| 316 |
+
|
| 317 |
+
# 1d to 2d
|
| 318 |
+
b, c, t = x.shape
|
| 319 |
+
if t % self.period != 0: # pad first
|
| 320 |
+
n_pad = self.period - (t % self.period)
|
| 321 |
+
x = F.pad(x, (0, n_pad), "reflect")
|
| 322 |
+
t = t + n_pad
|
| 323 |
+
x = x.view(b, c, t // self.period, self.period)
|
| 324 |
+
|
| 325 |
+
for l in self.convs:
|
| 326 |
+
x = l(x)
|
| 327 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 328 |
+
fmap.append(x)
|
| 329 |
+
x = self.conv_post(x)
|
| 330 |
+
fmap.append(x)
|
| 331 |
+
x = torch.flatten(x, 1, -1)
|
| 332 |
+
|
| 333 |
+
return x, fmap
|
| 334 |
+
|
| 335 |
+
|
| 336 |
+
class DiscriminatorS(torch.nn.Module):
|
| 337 |
+
def __init__(self, use_spectral_norm=False):
|
| 338 |
+
super(DiscriminatorS, self).__init__()
|
| 339 |
+
norm_f = weight_norm if use_spectral_norm == False else spectral_norm
|
| 340 |
+
self.convs = nn.ModuleList([
|
| 341 |
+
norm_f(Conv1d(1, 16, 15, 1, padding=7)),
|
| 342 |
+
norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)),
|
| 343 |
+
norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)),
|
| 344 |
+
norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)),
|
| 345 |
+
norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)),
|
| 346 |
+
norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),
|
| 347 |
+
])
|
| 348 |
+
self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))
|
| 349 |
+
|
| 350 |
+
def forward(self, x):
|
| 351 |
+
fmap = []
|
| 352 |
+
|
| 353 |
+
for l in self.convs:
|
| 354 |
+
x = l(x)
|
| 355 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 356 |
+
fmap.append(x)
|
| 357 |
+
x = self.conv_post(x)
|
| 358 |
+
fmap.append(x)
|
| 359 |
+
x = torch.flatten(x, 1, -1)
|
| 360 |
+
|
| 361 |
+
return x, fmap
|
| 362 |
+
|
| 363 |
+
|
| 364 |
+
class MultiPeriodDiscriminator(torch.nn.Module):
|
| 365 |
+
def __init__(self, use_spectral_norm=False):
|
| 366 |
+
super(MultiPeriodDiscriminator, self).__init__()
|
| 367 |
+
periods = [2,3,5,7,11]
|
| 368 |
+
|
| 369 |
+
discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
|
| 370 |
+
discs = discs + [DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods]
|
| 371 |
+
self.discriminators = nn.ModuleList(discs)
|
| 372 |
+
|
| 373 |
+
def forward(self, y, y_hat):
|
| 374 |
+
y_d_rs = []
|
| 375 |
+
y_d_gs = []
|
| 376 |
+
fmap_rs = []
|
| 377 |
+
fmap_gs = []
|
| 378 |
+
for i, d in enumerate(self.discriminators):
|
| 379 |
+
y_d_r, fmap_r = d(y)
|
| 380 |
+
y_d_g, fmap_g = d(y_hat)
|
| 381 |
+
y_d_rs.append(y_d_r)
|
| 382 |
+
y_d_gs.append(y_d_g)
|
| 383 |
+
fmap_rs.append(fmap_r)
|
| 384 |
+
fmap_gs.append(fmap_g)
|
| 385 |
+
|
| 386 |
+
return y_d_rs, y_d_gs, fmap_rs, fmap_gs
|
| 387 |
+
|
| 388 |
+
|
| 389 |
+
|
| 390 |
+
class SynthesizerTrn(nn.Module):
|
| 391 |
+
"""
|
| 392 |
+
Synthesizer for Training
|
| 393 |
+
"""
|
| 394 |
+
|
| 395 |
+
def __init__(self,
|
| 396 |
+
n_vocab,
|
| 397 |
+
spec_channels,
|
| 398 |
+
segment_size,
|
| 399 |
+
inter_channels,
|
| 400 |
+
hidden_channels,
|
| 401 |
+
filter_channels,
|
| 402 |
+
n_heads,
|
| 403 |
+
n_layers,
|
| 404 |
+
kernel_size,
|
| 405 |
+
p_dropout,
|
| 406 |
+
resblock,
|
| 407 |
+
resblock_kernel_sizes,
|
| 408 |
+
resblock_dilation_sizes,
|
| 409 |
+
upsample_rates,
|
| 410 |
+
upsample_initial_channel,
|
| 411 |
+
upsample_kernel_sizes,
|
| 412 |
+
n_speakers=0,
|
| 413 |
+
gin_channels=0,
|
| 414 |
+
use_sdp=True,
|
| 415 |
+
**kwargs):
|
| 416 |
+
|
| 417 |
+
super().__init__()
|
| 418 |
+
self.n_vocab = n_vocab
|
| 419 |
+
self.spec_channels = spec_channels
|
| 420 |
+
self.inter_channels = inter_channels
|
| 421 |
+
self.hidden_channels = hidden_channels
|
| 422 |
+
self.filter_channels = filter_channels
|
| 423 |
+
self.n_heads = n_heads
|
| 424 |
+
self.n_layers = n_layers
|
| 425 |
+
self.kernel_size = kernel_size
|
| 426 |
+
self.p_dropout = p_dropout
|
| 427 |
+
self.resblock = resblock
|
| 428 |
+
self.resblock_kernel_sizes = resblock_kernel_sizes
|
| 429 |
+
self.resblock_dilation_sizes = resblock_dilation_sizes
|
| 430 |
+
self.upsample_rates = upsample_rates
|
| 431 |
+
self.upsample_initial_channel = upsample_initial_channel
|
| 432 |
+
self.upsample_kernel_sizes = upsample_kernel_sizes
|
| 433 |
+
self.segment_size = segment_size
|
| 434 |
+
self.n_speakers = n_speakers
|
| 435 |
+
self.gin_channels = gin_channels
|
| 436 |
+
|
| 437 |
+
self.use_sdp = use_sdp
|
| 438 |
+
|
| 439 |
+
self.enc_p = TextEncoder(n_vocab,
|
| 440 |
+
inter_channels,
|
| 441 |
+
hidden_channels,
|
| 442 |
+
filter_channels,
|
| 443 |
+
n_heads,
|
| 444 |
+
n_layers,
|
| 445 |
+
kernel_size,
|
| 446 |
+
p_dropout)
|
| 447 |
+
self.dec = Generator(inter_channels, resblock, resblock_kernel_sizes, resblock_dilation_sizes, upsample_rates, upsample_initial_channel, upsample_kernel_sizes, gin_channels=gin_channels)
|
| 448 |
+
self.enc_q = PosteriorEncoder(spec_channels, inter_channels, hidden_channels, 5, 1, 16, gin_channels=gin_channels)
|
| 449 |
+
self.flow = ResidualCouplingBlock(inter_channels, hidden_channels, 5, 1, 4, gin_channels=gin_channels)
|
| 450 |
+
|
| 451 |
+
if use_sdp:
|
| 452 |
+
self.dp = StochasticDurationPredictor(hidden_channels, 192, 3, 0.5, 4, gin_channels=gin_channels)
|
| 453 |
+
else:
|
| 454 |
+
self.dp = DurationPredictor(hidden_channels, 256, 3, 0.5, gin_channels=gin_channels)
|
| 455 |
+
|
| 456 |
+
if n_speakers > 1:
|
| 457 |
+
self.emb_g = nn.Embedding(n_speakers, gin_channels)
|
| 458 |
+
|
| 459 |
+
def forward(self, x, x_lengths, y, y_lengths, sid=None):
|
| 460 |
+
|
| 461 |
+
x, m_p, logs_p, x_mask = self.enc_p(x, x_lengths)
|
| 462 |
+
if self.n_speakers > 0:
|
| 463 |
+
g = self.emb_g(sid).unsqueeze(-1) # [b, h, 1]
|
| 464 |
+
else:
|
| 465 |
+
g = None
|
| 466 |
+
|
| 467 |
+
z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
|
| 468 |
+
z_p = self.flow(z, y_mask, g=g)
|
| 469 |
+
|
| 470 |
+
with torch.no_grad():
|
| 471 |
+
# negative cross-entropy
|
| 472 |
+
s_p_sq_r = torch.exp(-2 * logs_p) # [b, d, t]
|
| 473 |
+
neg_cent1 = torch.sum(-0.5 * math.log(2 * math.pi) - logs_p, [1], keepdim=True) # [b, 1, t_s]
|
| 474 |
+
neg_cent2 = torch.matmul(-0.5 * (z_p ** 2).transpose(1, 2), s_p_sq_r) # [b, t_t, d] x [b, d, t_s] = [b, t_t, t_s]
|
| 475 |
+
neg_cent3 = torch.matmul(z_p.transpose(1, 2), (m_p * s_p_sq_r)) # [b, t_t, d] x [b, d, t_s] = [b, t_t, t_s]
|
| 476 |
+
neg_cent4 = torch.sum(-0.5 * (m_p ** 2) * s_p_sq_r, [1], keepdim=True) # [b, 1, t_s]
|
| 477 |
+
neg_cent = neg_cent1 + neg_cent2 + neg_cent3 + neg_cent4
|
| 478 |
+
|
| 479 |
+
attn_mask = torch.unsqueeze(x_mask, 2) * torch.unsqueeze(y_mask, -1)
|
| 480 |
+
attn = monotonic_align.maximum_path(neg_cent, attn_mask.squeeze(1)).unsqueeze(1).detach()
|
| 481 |
+
|
| 482 |
+
w = attn.sum(2)
|
| 483 |
+
if self.use_sdp:
|
| 484 |
+
l_length = self.dp(x, x_mask, w, g=g)
|
| 485 |
+
l_length = l_length / torch.sum(x_mask)
|
| 486 |
+
else:
|
| 487 |
+
logw_ = torch.log(w + 1e-6) * x_mask
|
| 488 |
+
logw = self.dp(x, x_mask, g=g)
|
| 489 |
+
l_length = torch.sum((logw - logw_)**2, [1,2]) / torch.sum(x_mask) # for averaging
|
| 490 |
+
|
| 491 |
+
# expand prior
|
| 492 |
+
m_p = torch.matmul(attn.squeeze(1), m_p.transpose(1, 2)).transpose(1, 2)
|
| 493 |
+
logs_p = torch.matmul(attn.squeeze(1), logs_p.transpose(1, 2)).transpose(1, 2)
|
| 494 |
+
|
| 495 |
+
z_slice, ids_slice = commons.rand_slice_segments(z, y_lengths, self.segment_size)
|
| 496 |
+
o = self.dec(z_slice, g=g)
|
| 497 |
+
return o, l_length, attn, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
|
| 498 |
+
|
| 499 |
+
def infer(self, x, x_lengths, sid=None, noise_scale=1, length_scale=1, noise_scale_w=1., max_len=None):
|
| 500 |
+
x, m_p, logs_p, x_mask = self.enc_p(x, x_lengths)
|
| 501 |
+
if self.n_speakers > 0:
|
| 502 |
+
g = self.emb_g(sid).unsqueeze(-1) # [b, h, 1]
|
| 503 |
+
else:
|
| 504 |
+
g = None
|
| 505 |
+
|
| 506 |
+
if self.use_sdp:
|
| 507 |
+
logw = self.dp(x, x_mask, g=g, reverse=True, noise_scale=noise_scale_w)
|
| 508 |
+
else:
|
| 509 |
+
logw = self.dp(x, x_mask, g=g)
|
| 510 |
+
w = torch.exp(logw) * x_mask * length_scale
|
| 511 |
+
w_ceil = torch.ceil(w)
|
| 512 |
+
y_lengths = torch.clamp_min(torch.sum(w_ceil, [1, 2]), 1).long()
|
| 513 |
+
y_mask = torch.unsqueeze(commons.sequence_mask(y_lengths, None), 1).to(x_mask.dtype)
|
| 514 |
+
attn_mask = torch.unsqueeze(x_mask, 2) * torch.unsqueeze(y_mask, -1)
|
| 515 |
+
attn = commons.generate_path(w_ceil, attn_mask)
|
| 516 |
+
|
| 517 |
+
m_p = torch.matmul(attn.squeeze(1), m_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t']
|
| 518 |
+
logs_p = torch.matmul(attn.squeeze(1), logs_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t']
|
| 519 |
+
|
| 520 |
+
z_p = m_p + torch.randn_like(m_p) * torch.exp(logs_p) * noise_scale
|
| 521 |
+
z = self.flow(z_p, y_mask, g=g, reverse=True)
|
| 522 |
+
o = self.dec((z * y_mask)[:,:,:max_len], g=g)
|
| 523 |
+
return o, attn, y_mask, (z, z_p, m_p, logs_p)
|
| 524 |
+
|
| 525 |
+
def voice_conversion(self, y, y_lengths, sid_src, sid_tgt):
|
| 526 |
+
assert self.n_speakers > 0, "n_speakers have to be larger than 0."
|
| 527 |
+
g_src = self.emb_g(sid_src).unsqueeze(-1)
|
| 528 |
+
g_tgt = self.emb_g(sid_tgt).unsqueeze(-1)
|
| 529 |
+
z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g_src)
|
| 530 |
+
z_p = self.flow(z, y_mask, g=g_src)
|
| 531 |
+
z_hat = self.flow(z_p, y_mask, g=g_tgt, reverse=True)
|
| 532 |
+
o_hat = self.dec(z_hat * y_mask, g=g_tgt)
|
| 533 |
+
return o_hat, y_mask, (z, z_p, z_hat)
|
| 534 |
+
|
modules.py
ADDED
|
@@ -0,0 +1,390 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import math
|
| 3 |
+
import numpy as np
|
| 4 |
+
import scipy
|
| 5 |
+
import torch
|
| 6 |
+
from torch import nn
|
| 7 |
+
from torch.nn import functional as F
|
| 8 |
+
|
| 9 |
+
from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
|
| 10 |
+
from torch.nn.utils import weight_norm, remove_weight_norm
|
| 11 |
+
|
| 12 |
+
import commons
|
| 13 |
+
from commons import init_weights, get_padding
|
| 14 |
+
from transforms import piecewise_rational_quadratic_transform
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
LRELU_SLOPE = 0.1
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class LayerNorm(nn.Module):
|
| 21 |
+
def __init__(self, channels, eps=1e-5):
|
| 22 |
+
super().__init__()
|
| 23 |
+
self.channels = channels
|
| 24 |
+
self.eps = eps
|
| 25 |
+
|
| 26 |
+
self.gamma = nn.Parameter(torch.ones(channels))
|
| 27 |
+
self.beta = nn.Parameter(torch.zeros(channels))
|
| 28 |
+
|
| 29 |
+
def forward(self, x):
|
| 30 |
+
x = x.transpose(1, -1)
|
| 31 |
+
x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
|
| 32 |
+
return x.transpose(1, -1)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class ConvReluNorm(nn.Module):
|
| 36 |
+
def __init__(self, in_channels, hidden_channels, out_channels, kernel_size, n_layers, p_dropout):
|
| 37 |
+
super().__init__()
|
| 38 |
+
self.in_channels = in_channels
|
| 39 |
+
self.hidden_channels = hidden_channels
|
| 40 |
+
self.out_channels = out_channels
|
| 41 |
+
self.kernel_size = kernel_size
|
| 42 |
+
self.n_layers = n_layers
|
| 43 |
+
self.p_dropout = p_dropout
|
| 44 |
+
assert n_layers > 1, "Number of layers should be larger than 0."
|
| 45 |
+
|
| 46 |
+
self.conv_layers = nn.ModuleList()
|
| 47 |
+
self.norm_layers = nn.ModuleList()
|
| 48 |
+
self.conv_layers.append(nn.Conv1d(in_channels, hidden_channels, kernel_size, padding=kernel_size//2))
|
| 49 |
+
self.norm_layers.append(LayerNorm(hidden_channels))
|
| 50 |
+
self.relu_drop = nn.Sequential(
|
| 51 |
+
nn.ReLU(),
|
| 52 |
+
nn.Dropout(p_dropout))
|
| 53 |
+
for _ in range(n_layers-1):
|
| 54 |
+
self.conv_layers.append(nn.Conv1d(hidden_channels, hidden_channels, kernel_size, padding=kernel_size//2))
|
| 55 |
+
self.norm_layers.append(LayerNorm(hidden_channels))
|
| 56 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
|
| 57 |
+
self.proj.weight.data.zero_()
|
| 58 |
+
self.proj.bias.data.zero_()
|
| 59 |
+
|
| 60 |
+
def forward(self, x, x_mask):
|
| 61 |
+
x_org = x
|
| 62 |
+
for i in range(self.n_layers):
|
| 63 |
+
x = self.conv_layers[i](x * x_mask)
|
| 64 |
+
x = self.norm_layers[i](x)
|
| 65 |
+
x = self.relu_drop(x)
|
| 66 |
+
x = x_org + self.proj(x)
|
| 67 |
+
return x * x_mask
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
class DDSConv(nn.Module):
|
| 71 |
+
"""
|
| 72 |
+
Dialted and Depth-Separable Convolution
|
| 73 |
+
"""
|
| 74 |
+
def __init__(self, channels, kernel_size, n_layers, p_dropout=0.):
|
| 75 |
+
super().__init__()
|
| 76 |
+
self.channels = channels
|
| 77 |
+
self.kernel_size = kernel_size
|
| 78 |
+
self.n_layers = n_layers
|
| 79 |
+
self.p_dropout = p_dropout
|
| 80 |
+
|
| 81 |
+
self.drop = nn.Dropout(p_dropout)
|
| 82 |
+
self.convs_sep = nn.ModuleList()
|
| 83 |
+
self.convs_1x1 = nn.ModuleList()
|
| 84 |
+
self.norms_1 = nn.ModuleList()
|
| 85 |
+
self.norms_2 = nn.ModuleList()
|
| 86 |
+
for i in range(n_layers):
|
| 87 |
+
dilation = kernel_size ** i
|
| 88 |
+
padding = (kernel_size * dilation - dilation) // 2
|
| 89 |
+
self.convs_sep.append(nn.Conv1d(channels, channels, kernel_size,
|
| 90 |
+
groups=channels, dilation=dilation, padding=padding
|
| 91 |
+
))
|
| 92 |
+
self.convs_1x1.append(nn.Conv1d(channels, channels, 1))
|
| 93 |
+
self.norms_1.append(LayerNorm(channels))
|
| 94 |
+
self.norms_2.append(LayerNorm(channels))
|
| 95 |
+
|
| 96 |
+
def forward(self, x, x_mask, g=None):
|
| 97 |
+
if g is not None:
|
| 98 |
+
x = x + g
|
| 99 |
+
for i in range(self.n_layers):
|
| 100 |
+
y = self.convs_sep[i](x * x_mask)
|
| 101 |
+
y = self.norms_1[i](y)
|
| 102 |
+
y = F.gelu(y)
|
| 103 |
+
y = self.convs_1x1[i](y)
|
| 104 |
+
y = self.norms_2[i](y)
|
| 105 |
+
y = F.gelu(y)
|
| 106 |
+
y = self.drop(y)
|
| 107 |
+
x = x + y
|
| 108 |
+
return x * x_mask
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
class WN(torch.nn.Module):
|
| 112 |
+
def __init__(self, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=0, p_dropout=0):
|
| 113 |
+
super(WN, self).__init__()
|
| 114 |
+
assert(kernel_size % 2 == 1)
|
| 115 |
+
self.hidden_channels =hidden_channels
|
| 116 |
+
self.kernel_size = kernel_size,
|
| 117 |
+
self.dilation_rate = dilation_rate
|
| 118 |
+
self.n_layers = n_layers
|
| 119 |
+
self.gin_channels = gin_channels
|
| 120 |
+
self.p_dropout = p_dropout
|
| 121 |
+
|
| 122 |
+
self.in_layers = torch.nn.ModuleList()
|
| 123 |
+
self.res_skip_layers = torch.nn.ModuleList()
|
| 124 |
+
self.drop = nn.Dropout(p_dropout)
|
| 125 |
+
|
| 126 |
+
if gin_channels != 0:
|
| 127 |
+
cond_layer = torch.nn.Conv1d(gin_channels, 2*hidden_channels*n_layers, 1)
|
| 128 |
+
self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight')
|
| 129 |
+
|
| 130 |
+
for i in range(n_layers):
|
| 131 |
+
dilation = dilation_rate ** i
|
| 132 |
+
padding = int((kernel_size * dilation - dilation) / 2)
|
| 133 |
+
in_layer = torch.nn.Conv1d(hidden_channels, 2*hidden_channels, kernel_size,
|
| 134 |
+
dilation=dilation, padding=padding)
|
| 135 |
+
in_layer = torch.nn.utils.weight_norm(in_layer, name='weight')
|
| 136 |
+
self.in_layers.append(in_layer)
|
| 137 |
+
|
| 138 |
+
# last one is not necessary
|
| 139 |
+
if i < n_layers - 1:
|
| 140 |
+
res_skip_channels = 2 * hidden_channels
|
| 141 |
+
else:
|
| 142 |
+
res_skip_channels = hidden_channels
|
| 143 |
+
|
| 144 |
+
res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)
|
| 145 |
+
res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight')
|
| 146 |
+
self.res_skip_layers.append(res_skip_layer)
|
| 147 |
+
|
| 148 |
+
def forward(self, x, x_mask, g=None, **kwargs):
|
| 149 |
+
output = torch.zeros_like(x)
|
| 150 |
+
n_channels_tensor = torch.IntTensor([self.hidden_channels])
|
| 151 |
+
|
| 152 |
+
if g is not None:
|
| 153 |
+
g = self.cond_layer(g)
|
| 154 |
+
|
| 155 |
+
for i in range(self.n_layers):
|
| 156 |
+
x_in = self.in_layers[i](x)
|
| 157 |
+
if g is not None:
|
| 158 |
+
cond_offset = i * 2 * self.hidden_channels
|
| 159 |
+
g_l = g[:,cond_offset:cond_offset+2*self.hidden_channels,:]
|
| 160 |
+
else:
|
| 161 |
+
g_l = torch.zeros_like(x_in)
|
| 162 |
+
|
| 163 |
+
acts = commons.fused_add_tanh_sigmoid_multiply(
|
| 164 |
+
x_in,
|
| 165 |
+
g_l,
|
| 166 |
+
n_channels_tensor)
|
| 167 |
+
acts = self.drop(acts)
|
| 168 |
+
|
| 169 |
+
res_skip_acts = self.res_skip_layers[i](acts)
|
| 170 |
+
if i < self.n_layers - 1:
|
| 171 |
+
res_acts = res_skip_acts[:,:self.hidden_channels,:]
|
| 172 |
+
x = (x + res_acts) * x_mask
|
| 173 |
+
output = output + res_skip_acts[:,self.hidden_channels:,:]
|
| 174 |
+
else:
|
| 175 |
+
output = output + res_skip_acts
|
| 176 |
+
return output * x_mask
|
| 177 |
+
|
| 178 |
+
def remove_weight_norm(self):
|
| 179 |
+
if self.gin_channels != 0:
|
| 180 |
+
torch.nn.utils.remove_weight_norm(self.cond_layer)
|
| 181 |
+
for l in self.in_layers:
|
| 182 |
+
torch.nn.utils.remove_weight_norm(l)
|
| 183 |
+
for l in self.res_skip_layers:
|
| 184 |
+
torch.nn.utils.remove_weight_norm(l)
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
class ResBlock1(torch.nn.Module):
|
| 188 |
+
def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
|
| 189 |
+
super(ResBlock1, self).__init__()
|
| 190 |
+
self.convs1 = nn.ModuleList([
|
| 191 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
|
| 192 |
+
padding=get_padding(kernel_size, dilation[0]))),
|
| 193 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
|
| 194 |
+
padding=get_padding(kernel_size, dilation[1]))),
|
| 195 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
|
| 196 |
+
padding=get_padding(kernel_size, dilation[2])))
|
| 197 |
+
])
|
| 198 |
+
self.convs1.apply(init_weights)
|
| 199 |
+
|
| 200 |
+
self.convs2 = nn.ModuleList([
|
| 201 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
|
| 202 |
+
padding=get_padding(kernel_size, 1))),
|
| 203 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
|
| 204 |
+
padding=get_padding(kernel_size, 1))),
|
| 205 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
|
| 206 |
+
padding=get_padding(kernel_size, 1)))
|
| 207 |
+
])
|
| 208 |
+
self.convs2.apply(init_weights)
|
| 209 |
+
|
| 210 |
+
def forward(self, x, x_mask=None):
|
| 211 |
+
for c1, c2 in zip(self.convs1, self.convs2):
|
| 212 |
+
xt = F.leaky_relu(x, LRELU_SLOPE)
|
| 213 |
+
if x_mask is not None:
|
| 214 |
+
xt = xt * x_mask
|
| 215 |
+
xt = c1(xt)
|
| 216 |
+
xt = F.leaky_relu(xt, LRELU_SLOPE)
|
| 217 |
+
if x_mask is not None:
|
| 218 |
+
xt = xt * x_mask
|
| 219 |
+
xt = c2(xt)
|
| 220 |
+
x = xt + x
|
| 221 |
+
if x_mask is not None:
|
| 222 |
+
x = x * x_mask
|
| 223 |
+
return x
|
| 224 |
+
|
| 225 |
+
def remove_weight_norm(self):
|
| 226 |
+
for l in self.convs1:
|
| 227 |
+
remove_weight_norm(l)
|
| 228 |
+
for l in self.convs2:
|
| 229 |
+
remove_weight_norm(l)
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
class ResBlock2(torch.nn.Module):
|
| 233 |
+
def __init__(self, channels, kernel_size=3, dilation=(1, 3)):
|
| 234 |
+
super(ResBlock2, self).__init__()
|
| 235 |
+
self.convs = nn.ModuleList([
|
| 236 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
|
| 237 |
+
padding=get_padding(kernel_size, dilation[0]))),
|
| 238 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
|
| 239 |
+
padding=get_padding(kernel_size, dilation[1])))
|
| 240 |
+
])
|
| 241 |
+
self.convs.apply(init_weights)
|
| 242 |
+
|
| 243 |
+
def forward(self, x, x_mask=None):
|
| 244 |
+
for c in self.convs:
|
| 245 |
+
xt = F.leaky_relu(x, LRELU_SLOPE)
|
| 246 |
+
if x_mask is not None:
|
| 247 |
+
xt = xt * x_mask
|
| 248 |
+
xt = c(xt)
|
| 249 |
+
x = xt + x
|
| 250 |
+
if x_mask is not None:
|
| 251 |
+
x = x * x_mask
|
| 252 |
+
return x
|
| 253 |
+
|
| 254 |
+
def remove_weight_norm(self):
|
| 255 |
+
for l in self.convs:
|
| 256 |
+
remove_weight_norm(l)
|
| 257 |
+
|
| 258 |
+
|
| 259 |
+
class Log(nn.Module):
|
| 260 |
+
def forward(self, x, x_mask, reverse=False, **kwargs):
|
| 261 |
+
if not reverse:
|
| 262 |
+
y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask
|
| 263 |
+
logdet = torch.sum(-y, [1, 2])
|
| 264 |
+
return y, logdet
|
| 265 |
+
else:
|
| 266 |
+
x = torch.exp(x) * x_mask
|
| 267 |
+
return x
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
class Flip(nn.Module):
|
| 271 |
+
def forward(self, x, *args, reverse=False, **kwargs):
|
| 272 |
+
x = torch.flip(x, [1])
|
| 273 |
+
if not reverse:
|
| 274 |
+
logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)
|
| 275 |
+
return x, logdet
|
| 276 |
+
else:
|
| 277 |
+
return x
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
class ElementwiseAffine(nn.Module):
|
| 281 |
+
def __init__(self, channels):
|
| 282 |
+
super().__init__()
|
| 283 |
+
self.channels = channels
|
| 284 |
+
self.m = nn.Parameter(torch.zeros(channels,1))
|
| 285 |
+
self.logs = nn.Parameter(torch.zeros(channels,1))
|
| 286 |
+
|
| 287 |
+
def forward(self, x, x_mask, reverse=False, **kwargs):
|
| 288 |
+
if not reverse:
|
| 289 |
+
y = self.m + torch.exp(self.logs) * x
|
| 290 |
+
y = y * x_mask
|
| 291 |
+
logdet = torch.sum(self.logs * x_mask, [1,2])
|
| 292 |
+
return y, logdet
|
| 293 |
+
else:
|
| 294 |
+
x = (x - self.m) * torch.exp(-self.logs) * x_mask
|
| 295 |
+
return x
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
class ResidualCouplingLayer(nn.Module):
|
| 299 |
+
def __init__(self,
|
| 300 |
+
channels,
|
| 301 |
+
hidden_channels,
|
| 302 |
+
kernel_size,
|
| 303 |
+
dilation_rate,
|
| 304 |
+
n_layers,
|
| 305 |
+
p_dropout=0,
|
| 306 |
+
gin_channels=0,
|
| 307 |
+
mean_only=False):
|
| 308 |
+
assert channels % 2 == 0, "channels should be divisible by 2"
|
| 309 |
+
super().__init__()
|
| 310 |
+
self.channels = channels
|
| 311 |
+
self.hidden_channels = hidden_channels
|
| 312 |
+
self.kernel_size = kernel_size
|
| 313 |
+
self.dilation_rate = dilation_rate
|
| 314 |
+
self.n_layers = n_layers
|
| 315 |
+
self.half_channels = channels // 2
|
| 316 |
+
self.mean_only = mean_only
|
| 317 |
+
|
| 318 |
+
self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
|
| 319 |
+
self.enc = WN(hidden_channels, kernel_size, dilation_rate, n_layers, p_dropout=p_dropout, gin_channels=gin_channels)
|
| 320 |
+
self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
|
| 321 |
+
self.post.weight.data.zero_()
|
| 322 |
+
self.post.bias.data.zero_()
|
| 323 |
+
|
| 324 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 325 |
+
x0, x1 = torch.split(x, [self.half_channels]*2, 1)
|
| 326 |
+
h = self.pre(x0) * x_mask
|
| 327 |
+
h = self.enc(h, x_mask, g=g)
|
| 328 |
+
stats = self.post(h) * x_mask
|
| 329 |
+
if not self.mean_only:
|
| 330 |
+
m, logs = torch.split(stats, [self.half_channels]*2, 1)
|
| 331 |
+
else:
|
| 332 |
+
m = stats
|
| 333 |
+
logs = torch.zeros_like(m)
|
| 334 |
+
|
| 335 |
+
if not reverse:
|
| 336 |
+
x1 = m + x1 * torch.exp(logs) * x_mask
|
| 337 |
+
x = torch.cat([x0, x1], 1)
|
| 338 |
+
logdet = torch.sum(logs, [1,2])
|
| 339 |
+
return x, logdet
|
| 340 |
+
else:
|
| 341 |
+
x1 = (x1 - m) * torch.exp(-logs) * x_mask
|
| 342 |
+
x = torch.cat([x0, x1], 1)
|
| 343 |
+
return x
|
| 344 |
+
|
| 345 |
+
|
| 346 |
+
class ConvFlow(nn.Module):
|
| 347 |
+
def __init__(self, in_channels, filter_channels, kernel_size, n_layers, num_bins=10, tail_bound=5.0):
|
| 348 |
+
super().__init__()
|
| 349 |
+
self.in_channels = in_channels
|
| 350 |
+
self.filter_channels = filter_channels
|
| 351 |
+
self.kernel_size = kernel_size
|
| 352 |
+
self.n_layers = n_layers
|
| 353 |
+
self.num_bins = num_bins
|
| 354 |
+
self.tail_bound = tail_bound
|
| 355 |
+
self.half_channels = in_channels // 2
|
| 356 |
+
|
| 357 |
+
self.pre = nn.Conv1d(self.half_channels, filter_channels, 1)
|
| 358 |
+
self.convs = DDSConv(filter_channels, kernel_size, n_layers, p_dropout=0.)
|
| 359 |
+
self.proj = nn.Conv1d(filter_channels, self.half_channels * (num_bins * 3 - 1), 1)
|
| 360 |
+
self.proj.weight.data.zero_()
|
| 361 |
+
self.proj.bias.data.zero_()
|
| 362 |
+
|
| 363 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 364 |
+
x0, x1 = torch.split(x, [self.half_channels]*2, 1)
|
| 365 |
+
h = self.pre(x0)
|
| 366 |
+
h = self.convs(h, x_mask, g=g)
|
| 367 |
+
h = self.proj(h) * x_mask
|
| 368 |
+
|
| 369 |
+
b, c, t = x0.shape
|
| 370 |
+
h = h.reshape(b, c, -1, t).permute(0, 1, 3, 2) # [b, cx?, t] -> [b, c, t, ?]
|
| 371 |
+
|
| 372 |
+
unnormalized_widths = h[..., :self.num_bins] / math.sqrt(self.filter_channels)
|
| 373 |
+
unnormalized_heights = h[..., self.num_bins:2*self.num_bins] / math.sqrt(self.filter_channels)
|
| 374 |
+
unnormalized_derivatives = h[..., 2 * self.num_bins:]
|
| 375 |
+
|
| 376 |
+
x1, logabsdet = piecewise_rational_quadratic_transform(x1,
|
| 377 |
+
unnormalized_widths,
|
| 378 |
+
unnormalized_heights,
|
| 379 |
+
unnormalized_derivatives,
|
| 380 |
+
inverse=reverse,
|
| 381 |
+
tails='linear',
|
| 382 |
+
tail_bound=self.tail_bound
|
| 383 |
+
)
|
| 384 |
+
|
| 385 |
+
x = torch.cat([x0, x1], 1) * x_mask
|
| 386 |
+
logdet = torch.sum(logabsdet * x_mask, [1,2])
|
| 387 |
+
if not reverse:
|
| 388 |
+
return x, logdet
|
| 389 |
+
else:
|
| 390 |
+
return x
|
monotonic_align/__init__.py
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
from .monotonic_align.core import maximum_path_c
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def maximum_path(neg_cent, mask):
|
| 7 |
+
""" Cython optimized version.
|
| 8 |
+
neg_cent: [b, t_t, t_s]
|
| 9 |
+
mask: [b, t_t, t_s]
|
| 10 |
+
"""
|
| 11 |
+
device = neg_cent.device
|
| 12 |
+
dtype = neg_cent.dtype
|
| 13 |
+
neg_cent = neg_cent.data.cpu().numpy().astype(np.float32)
|
| 14 |
+
path = np.zeros(neg_cent.shape, dtype=np.int32)
|
| 15 |
+
|
| 16 |
+
t_t_max = mask.sum(1)[:, 0].data.cpu().numpy().astype(np.int32)
|
| 17 |
+
t_s_max = mask.sum(2)[:, 0].data.cpu().numpy().astype(np.int32)
|
| 18 |
+
maximum_path_c(path, neg_cent, t_t_max, t_s_max)
|
| 19 |
+
return torch.from_numpy(path).to(device=device, dtype=dtype)
|
monotonic_align/__pycache__/__init__.cpython-37.pyc
ADDED
|
Binary file (765 Bytes). View file
|
|
|
monotonic_align/build/lib.win-amd64-cpython-37/monotonic_align/core.cp37-win_amd64.pyd
ADDED
|
Binary file (120 kB). View file
|
|
|
monotonic_align/build/temp.win-amd64-cpython-37/Release/core.cp37-win_amd64.exp
ADDED
|
Binary file (697 Bytes). View file
|
|
|
monotonic_align/build/temp.win-amd64-cpython-37/Release/core.cp37-win_amd64.lib
ADDED
|
Binary file (1.94 kB). View file
|
|
|
monotonic_align/build/temp.win-amd64-cpython-37/Release/core.obj
ADDED
|
Binary file (848 kB). View file
|
|
|
monotonic_align/core.c
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
monotonic_align/core.pyx
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
cimport cython
|
| 2 |
+
from cython.parallel import prange
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
@cython.boundscheck(False)
|
| 6 |
+
@cython.wraparound(False)
|
| 7 |
+
cdef void maximum_path_each(int[:,::1] path, float[:,::1] value, int t_y, int t_x, float max_neg_val=-1e9) nogil:
|
| 8 |
+
cdef int x
|
| 9 |
+
cdef int y
|
| 10 |
+
cdef float v_prev
|
| 11 |
+
cdef float v_cur
|
| 12 |
+
cdef float tmp
|
| 13 |
+
cdef int index = t_x - 1
|
| 14 |
+
|
| 15 |
+
for y in range(t_y):
|
| 16 |
+
for x in range(max(0, t_x + y - t_y), min(t_x, y + 1)):
|
| 17 |
+
if x == y:
|
| 18 |
+
v_cur = max_neg_val
|
| 19 |
+
else:
|
| 20 |
+
v_cur = value[y-1, x]
|
| 21 |
+
if x == 0:
|
| 22 |
+
if y == 0:
|
| 23 |
+
v_prev = 0.
|
| 24 |
+
else:
|
| 25 |
+
v_prev = max_neg_val
|
| 26 |
+
else:
|
| 27 |
+
v_prev = value[y-1, x-1]
|
| 28 |
+
value[y, x] += max(v_prev, v_cur)
|
| 29 |
+
|
| 30 |
+
for y in range(t_y - 1, -1, -1):
|
| 31 |
+
path[y, index] = 1
|
| 32 |
+
if index != 0 and (index == y or value[y-1, index] < value[y-1, index-1]):
|
| 33 |
+
index = index - 1
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
@cython.boundscheck(False)
|
| 37 |
+
@cython.wraparound(False)
|
| 38 |
+
cpdef void maximum_path_c(int[:,:,::1] paths, float[:,:,::1] values, int[::1] t_ys, int[::1] t_xs) nogil:
|
| 39 |
+
cdef int b = paths.shape[0]
|
| 40 |
+
cdef int i
|
| 41 |
+
for i in prange(b, nogil=True):
|
| 42 |
+
maximum_path_each(paths[i], values[i], t_ys[i], t_xs[i])
|
monotonic_align/monotonic_align/core.cp37-win_amd64.pyd
ADDED
|
Binary file (120 kB). View file
|
|
|
monotonic_align/setup.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from distutils.core import setup
|
| 2 |
+
from Cython.Build import cythonize
|
| 3 |
+
import numpy
|
| 4 |
+
|
| 5 |
+
setup(
|
| 6 |
+
name = 'monotonic_align',
|
| 7 |
+
ext_modules = cythonize("core.pyx"),
|
| 8 |
+
include_dirs=[numpy.get_include()]
|
| 9 |
+
)
|
preprocess.py
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import text
|
| 3 |
+
from utils import load_filepaths_and_text
|
| 4 |
+
|
| 5 |
+
if __name__ == '__main__':
|
| 6 |
+
parser = argparse.ArgumentParser()
|
| 7 |
+
parser.add_argument("--out_extension", default="cleaned")
|
| 8 |
+
parser.add_argument("--text_index", default=2, type=int)
|
| 9 |
+
parser.add_argument("--filelists", nargs="+", default=["E:/uma_voice/output_train.txt", "E:/uma_voice/output_val.txt"])
|
| 10 |
+
parser.add_argument("--text_cleaners", nargs="+", default=["japanese_cleaners"])
|
| 11 |
+
|
| 12 |
+
args = parser.parse_args()
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
for filelist in args.filelists:
|
| 16 |
+
print("START:", filelist)
|
| 17 |
+
filepaths_and_text = load_filepaths_and_text(filelist)
|
| 18 |
+
for i in range(len(filepaths_and_text)):
|
| 19 |
+
original_text = filepaths_and_text[i][args.text_index]
|
| 20 |
+
cleaned_text = text._clean_text(original_text, args.text_cleaners)
|
| 21 |
+
filepaths_and_text[i][args.text_index] = cleaned_text
|
| 22 |
+
|
| 23 |
+
new_filelist = filelist + "." + args.out_extension
|
| 24 |
+
with open(new_filelist, "w", encoding="utf-8") as f:
|
| 25 |
+
f.writelines(["|".join(x) + "\n" for x in filepaths_and_text])
|
pretrained_models/uma87_639000.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:97558cc29d0226930696546654b880c3263a6d5d411bbeab576e857895e9fb98
|
| 3 |
+
size 477050267
|
resources/fig_1a.png
ADDED
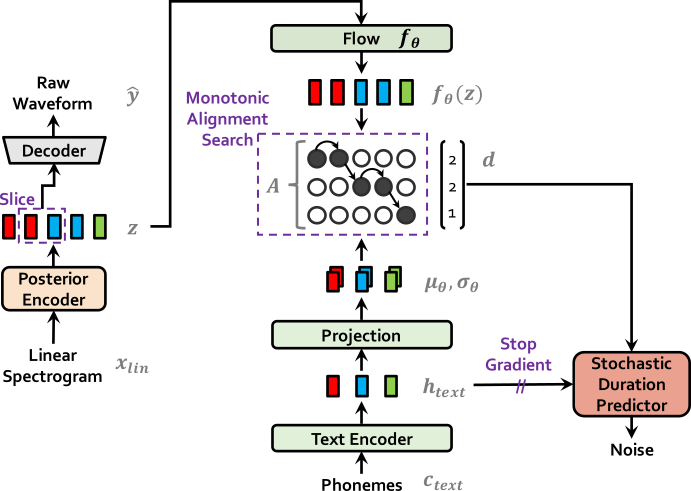
|
resources/fig_1b.png
ADDED
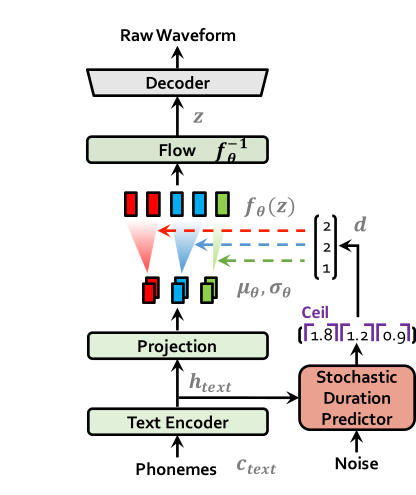
|
resources/training.png
ADDED
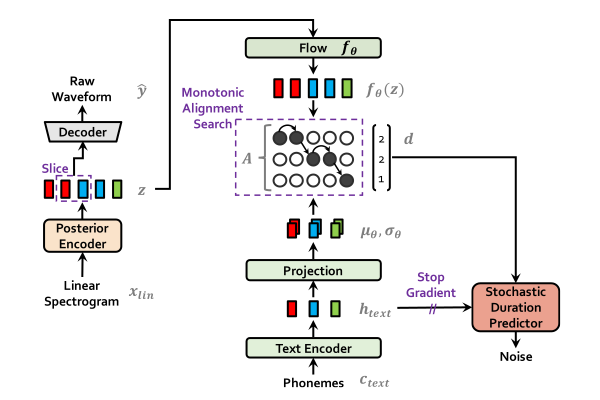
|
text/LICENSE
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright (c) 2017 Keith Ito
|
| 2 |
+
|
| 3 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 4 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 5 |
+
in the Software without restriction, including without limitation the rights
|
| 6 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 7 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 8 |
+
furnished to do so, subject to the following conditions:
|
| 9 |
+
|
| 10 |
+
The above copyright notice and this permission notice shall be included in
|
| 11 |
+
all copies or substantial portions of the Software.
|
| 12 |
+
|
| 13 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 15 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 16 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 17 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 18 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
| 19 |
+
THE SOFTWARE.
|
text/__init__.py
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""" from https://github.com/keithito/tacotron """
|
| 2 |
+
from text import cleaners
|
| 3 |
+
from text.symbols import symbols
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
# Mappings from symbol to numeric ID and vice versa:
|
| 7 |
+
_symbol_to_id = {s: i for i, s in enumerate(symbols)}
|
| 8 |
+
_id_to_symbol = {i: s for i, s in enumerate(symbols)}
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def text_to_sequence(text, cleaner_names):
|
| 12 |
+
'''Converts a string of text to a sequence of IDs corresponding to the symbols in the text.
|
| 13 |
+
Args:
|
| 14 |
+
text: string to convert to a sequence
|
| 15 |
+
cleaner_names: names of the cleaner functions to run the text through
|
| 16 |
+
Returns:
|
| 17 |
+
List of integers corresponding to the symbols in the text
|
| 18 |
+
'''
|
| 19 |
+
sequence = []
|
| 20 |
+
|
| 21 |
+
clean_text = _clean_text(text, cleaner_names)
|
| 22 |
+
for symbol in clean_text:
|
| 23 |
+
if symbol not in _symbol_to_id.keys():
|
| 24 |
+
continue
|
| 25 |
+
symbol_id = _symbol_to_id[symbol]
|
| 26 |
+
sequence += [symbol_id]
|
| 27 |
+
return sequence
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def cleaned_text_to_sequence(cleaned_text):
|
| 31 |
+
'''Converts a string of text to a sequence of IDs corresponding to the symbols in the text.
|
| 32 |
+
Args:
|
| 33 |
+
text: string to convert to a sequence
|
| 34 |
+
Returns:
|
| 35 |
+
List of integers corresponding to the symbols in the text
|
| 36 |
+
'''
|
| 37 |
+
sequence = [_symbol_to_id[symbol] for symbol in cleaned_text if symbol in _symbol_to_id.keys()]
|
| 38 |
+
return sequence
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def sequence_to_text(sequence):
|
| 42 |
+
'''Converts a sequence of IDs back to a string'''
|
| 43 |
+
result = ''
|
| 44 |
+
for symbol_id in sequence:
|
| 45 |
+
s = _id_to_symbol[symbol_id]
|
| 46 |
+
result += s
|
| 47 |
+
return result
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def _clean_text(text, cleaner_names):
|
| 51 |
+
for name in cleaner_names:
|
| 52 |
+
cleaner = getattr(cleaners, name)
|
| 53 |
+
if not cleaner:
|
| 54 |
+
raise Exception('Unknown cleaner: %s' % name)
|
| 55 |
+
text = cleaner(text)
|
| 56 |
+
return text
|
text/__pycache__/__init__.cpython-37.pyc
ADDED
|
Binary file (2.09 kB). View file
|
|
|
text/__pycache__/cleaners.cpython-37.pyc
ADDED
|
Binary file (5.45 kB). View file
|
|
|
text/__pycache__/english.cpython-37.pyc
ADDED
|
Binary file (4.93 kB). View file
|
|
|
text/__pycache__/japanese.cpython-37.pyc
ADDED
|
Binary file (4.6 kB). View file
|
|
|
text/__pycache__/korean.cpython-37.pyc
ADDED
|
Binary file (5.75 kB). View file
|
|
|
text/__pycache__/mandarin.cpython-37.pyc
ADDED
|
Binary file (7.51 kB). View file
|
|
|
text/__pycache__/sanskrit.cpython-37.pyc
ADDED
|
Binary file (1.63 kB). View file
|
|
|
text/__pycache__/symbols.cpython-37.pyc
ADDED
|
Binary file (357 Bytes). View file
|
|
|
text/__pycache__/thai.cpython-37.pyc
ADDED
|
Binary file (1.41 kB). View file
|
|
|