
haoyang
commited on
Commit
•
4b33d2c
1
Parent(s):
943f952
UPDATE LEADERBOARD
Browse files- .gitignore +1 -0
- README.md +1 -1
- app.py +5 -101
- figures/weighted_accuracy_failed.png +0 -0
- src/display/about.py +88 -33
- src/display/utils.py +1 -1
- src/envs.py +3 -4
- src/leaderboard/read_evals.py +5 -1
- src/submission/submit.py +2 -93
.gitignore
CHANGED
|
@@ -5,6 +5,7 @@ __pycache__/
|
|
| 5 |
.ipynb_checkpoints
|
| 6 |
*ipynb
|
| 7 |
.vscode/
|
|
|
|
| 8 |
|
| 9 |
gpt_4_evals/
|
| 10 |
human_evals/
|
|
|
|
| 5 |
.ipynb_checkpoints
|
| 6 |
*ipynb
|
| 7 |
.vscode/
|
| 8 |
+
.DS_Store
|
| 9 |
|
| 10 |
gpt_4_evals/
|
| 11 |
human_evals/
|
README.md
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
emoji: 🥇
|
| 4 |
colorFrom: green
|
| 5 |
colorTo: indigo
|
|
|
|
| 1 |
---
|
| 2 |
+
title: NPHardEval Leaderboard
|
| 3 |
emoji: 🥇
|
| 4 |
colorFrom: green
|
| 5 |
colorTo: indigo
|
app.py
CHANGED
|
@@ -25,21 +25,13 @@ from src.display.utils import (
|
|
| 25 |
WeightType,
|
| 26 |
Precision
|
| 27 |
)
|
| 28 |
-
from src.envs import API, EVAL_REQUESTS_PATH, EVAL_RESULTS_PATH, TOKEN,
|
| 29 |
from src.populate import get_evaluation_queue_df, get_leaderboard_df
|
| 30 |
-
from src.submission.submit import add_new_eval
|
| 31 |
|
| 32 |
|
| 33 |
def restart_space():
|
| 34 |
API.restart_space(repo_id=REPO_ID, token=TOKEN)
|
| 35 |
|
| 36 |
-
try:
|
| 37 |
-
print(EVAL_REQUESTS_PATH)
|
| 38 |
-
snapshot_download(
|
| 39 |
-
repo_id=QUEUE_REPO, local_dir=EVAL_REQUESTS_PATH, repo_type="dataset", tqdm_class=None, etag_timeout=30
|
| 40 |
-
)
|
| 41 |
-
except Exception:
|
| 42 |
-
restart_space()
|
| 43 |
try:
|
| 44 |
print(EVAL_RESULTS_PATH)
|
| 45 |
snapshot_download(
|
|
@@ -52,12 +44,6 @@ except Exception:
|
|
| 52 |
raw_data, original_df = get_leaderboard_df(EVAL_RESULTS_PATH, EVAL_REQUESTS_PATH, COLS, BENCHMARK_COLS)
|
| 53 |
leaderboard_df = original_df.copy()
|
| 54 |
|
| 55 |
-
(
|
| 56 |
-
finished_eval_queue_df,
|
| 57 |
-
running_eval_queue_df,
|
| 58 |
-
pending_eval_queue_df,
|
| 59 |
-
) = get_evaluation_queue_df(EVAL_REQUESTS_PATH, EVAL_COLS)
|
| 60 |
-
|
| 61 |
|
| 62 |
# Searching and filtering
|
| 63 |
def update_table(
|
|
@@ -240,95 +226,13 @@ with demo:
|
|
| 240 |
queue=True,
|
| 241 |
)
|
| 242 |
|
| 243 |
-
with gr.TabItem("
|
| 244 |
-
gr.Markdown(LLM_BENCHMARKS_TEXT, elem_classes="markdown-text")
|
| 245 |
-
|
| 246 |
-
with gr.TabItem("🚀 Submit here! ", elem_id="llm-benchmark-tab-table", id=3):
|
| 247 |
-
with gr.Column():
|
| 248 |
-
with gr.Row():
|
| 249 |
-
gr.Markdown(EVALUATION_QUEUE_TEXT, elem_classes="markdown-text")
|
| 250 |
-
|
| 251 |
-
with gr.Column():
|
| 252 |
-
with gr.Accordion(
|
| 253 |
-
f"✅ Finished Evaluations ({len(finished_eval_queue_df)})",
|
| 254 |
-
open=False,
|
| 255 |
-
):
|
| 256 |
-
with gr.Row():
|
| 257 |
-
finished_eval_table = gr.components.Dataframe(
|
| 258 |
-
value=finished_eval_queue_df,
|
| 259 |
-
headers=EVAL_COLS,
|
| 260 |
-
datatype=EVAL_TYPES,
|
| 261 |
-
row_count=5,
|
| 262 |
-
)
|
| 263 |
-
with gr.Accordion(
|
| 264 |
-
f"🔄 Running Evaluation Queue ({len(running_eval_queue_df)})",
|
| 265 |
-
open=False,
|
| 266 |
-
):
|
| 267 |
-
with gr.Row():
|
| 268 |
-
running_eval_table = gr.components.Dataframe(
|
| 269 |
-
value=running_eval_queue_df,
|
| 270 |
-
headers=EVAL_COLS,
|
| 271 |
-
datatype=EVAL_TYPES,
|
| 272 |
-
row_count=5,
|
| 273 |
-
)
|
| 274 |
-
|
| 275 |
-
with gr.Accordion(
|
| 276 |
-
f"⏳ Pending Evaluation Queue ({len(pending_eval_queue_df)})",
|
| 277 |
-
open=False,
|
| 278 |
-
):
|
| 279 |
-
with gr.Row():
|
| 280 |
-
pending_eval_table = gr.components.Dataframe(
|
| 281 |
-
value=pending_eval_queue_df,
|
| 282 |
-
headers=EVAL_COLS,
|
| 283 |
-
datatype=EVAL_TYPES,
|
| 284 |
-
row_count=5,
|
| 285 |
-
)
|
| 286 |
-
with gr.Row():
|
| 287 |
-
gr.Markdown("# ✉️✨ Submit your model here!", elem_classes="markdown-text")
|
| 288 |
-
|
| 289 |
with gr.Row():
|
| 290 |
with gr.Column():
|
| 291 |
-
|
| 292 |
-
revision_name_textbox = gr.Textbox(label="Revision commit", placeholder="main")
|
| 293 |
-
model_type = gr.Dropdown(
|
| 294 |
-
choices=[t.to_str(" : ") for t in ModelType if t != ModelType.Unknown],
|
| 295 |
-
label="Model type",
|
| 296 |
-
multiselect=False,
|
| 297 |
-
value=None,
|
| 298 |
-
interactive=True,
|
| 299 |
-
)
|
| 300 |
|
| 301 |
-
|
| 302 |
-
|
| 303 |
-
choices=[i.value.name for i in Precision if i != Precision.Unknown],
|
| 304 |
-
label="Precision",
|
| 305 |
-
multiselect=False,
|
| 306 |
-
value="float16",
|
| 307 |
-
interactive=True,
|
| 308 |
-
)
|
| 309 |
-
weight_type = gr.Dropdown(
|
| 310 |
-
choices=[i.value.name for i in WeightType],
|
| 311 |
-
label="Weights type",
|
| 312 |
-
multiselect=False,
|
| 313 |
-
value="Original",
|
| 314 |
-
interactive=True,
|
| 315 |
-
)
|
| 316 |
-
base_model_name_textbox = gr.Textbox(label="Base model (for delta or adapter weights)")
|
| 317 |
-
|
| 318 |
-
submit_button = gr.Button("Submit Eval")
|
| 319 |
-
submission_result = gr.Markdown()
|
| 320 |
-
submit_button.click(
|
| 321 |
-
add_new_eval,
|
| 322 |
-
[
|
| 323 |
-
model_name_textbox,
|
| 324 |
-
base_model_name_textbox,
|
| 325 |
-
revision_name_textbox,
|
| 326 |
-
precision,
|
| 327 |
-
weight_type,
|
| 328 |
-
model_type,
|
| 329 |
-
],
|
| 330 |
-
submission_result,
|
| 331 |
-
)
|
| 332 |
|
| 333 |
with gr.Row():
|
| 334 |
with gr.Accordion("📙 Citation", open=False):
|
|
|
|
| 25 |
WeightType,
|
| 26 |
Precision
|
| 27 |
)
|
| 28 |
+
from src.envs import API, EVAL_REQUESTS_PATH, EVAL_RESULTS_PATH, TOKEN, REPO_ID, RESULTS_REPO
|
| 29 |
from src.populate import get_evaluation_queue_df, get_leaderboard_df
|
|
|
|
| 30 |
|
| 31 |
|
| 32 |
def restart_space():
|
| 33 |
API.restart_space(repo_id=REPO_ID, token=TOKEN)
|
| 34 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 35 |
try:
|
| 36 |
print(EVAL_RESULTS_PATH)
|
| 37 |
snapshot_download(
|
|
|
|
| 44 |
raw_data, original_df = get_leaderboard_df(EVAL_RESULTS_PATH, EVAL_REQUESTS_PATH, COLS, BENCHMARK_COLS)
|
| 45 |
leaderboard_df = original_df.copy()
|
| 46 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 47 |
|
| 48 |
# Searching and filtering
|
| 49 |
def update_table(
|
|
|
|
| 226 |
queue=True,
|
| 227 |
)
|
| 228 |
|
| 229 |
+
with gr.TabItem("📈 Metrics", elem_id="llm-benchmark-tab-table", id=2):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 230 |
with gr.Row():
|
| 231 |
with gr.Column():
|
| 232 |
+
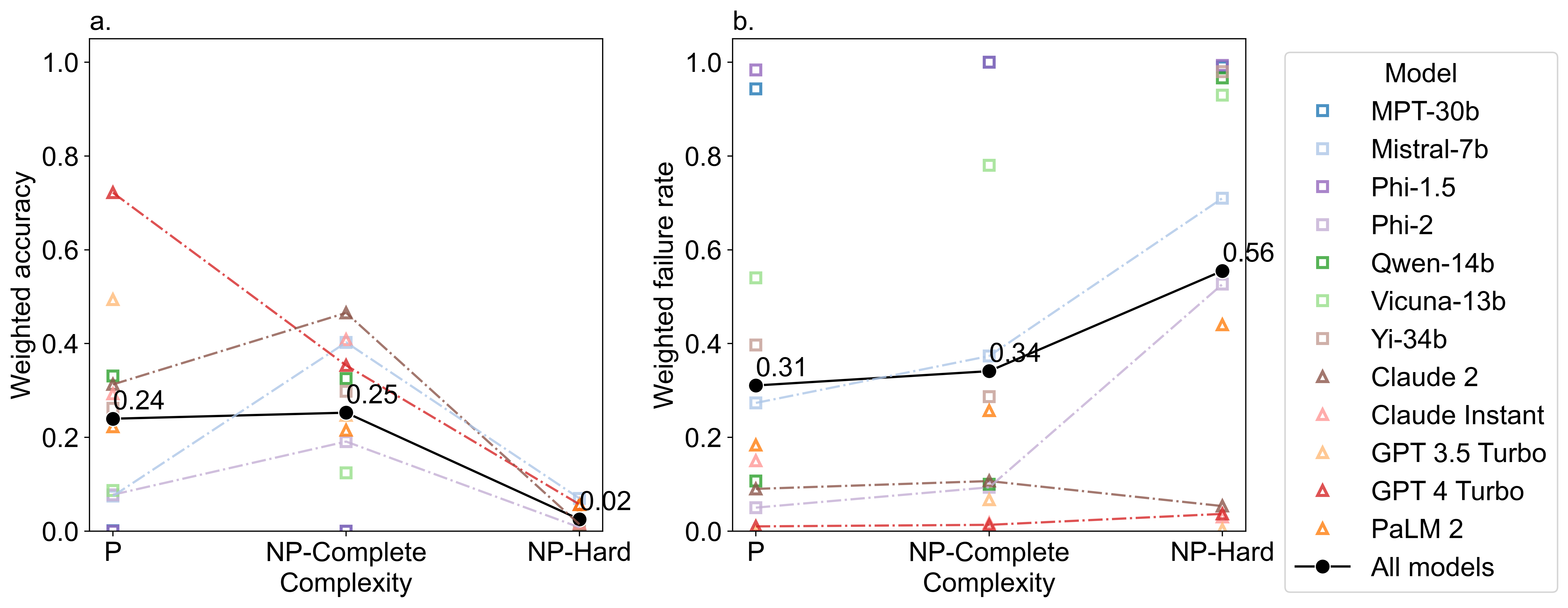
gr.Image("figures/weighted_accuracy_failed.png", min_width=500)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 233 |
|
| 234 |
+
with gr.TabItem("📝 About", elem_id="llm-benchmark-tab-table", id=3):
|
| 235 |
+
gr.Markdown(LLM_BENCHMARKS_TEXT, elem_classes="markdown-text")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 236 |
|
| 237 |
with gr.Row():
|
| 238 |
with gr.Accordion("📙 Citation", open=False):
|
figures/weighted_accuracy_failed.png
ADDED
|
src/display/about.py
CHANGED
|
@@ -11,57 +11,112 @@ class Task:
|
|
| 11 |
# Init: to update with your specific keys
|
| 12 |
class Tasks(Enum):
|
| 13 |
# task_key in the json file, metric_key in the json file, name to display in the leaderboard
|
| 14 |
-
task0 = Task("
|
| 15 |
-
task1 = Task("
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 16 |
|
| 17 |
|
| 18 |
# Your leaderboard name
|
| 19 |
-
TITLE = """<h1 align="center" id="space-title">
|
| 20 |
|
| 21 |
# What does your leaderboard evaluate?
|
| 22 |
INTRODUCTION_TEXT = """
|
| 23 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 24 |
"""
|
| 25 |
|
| 26 |
# Which evaluations are you running? how can people reproduce what you have?
|
| 27 |
LLM_BENCHMARKS_TEXT = f"""
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
|
| 36 |
-
|
| 37 |
-
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
|
| 41 |
-
|
| 42 |
-
|
| 43 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 44 |
```
|
| 45 |
-
If this step fails, follow the error messages to debug your model before submitting it. It's likely your model has been improperly uploaded.
|
| 46 |
|
| 47 |
-
|
| 48 |
-
|
| 49 |
|
| 50 |
-
###
|
| 51 |
-
|
| 52 |
|
| 53 |
-
|
| 54 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 55 |
|
| 56 |
-
|
| 57 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 58 |
|
| 59 |
-
|
| 60 |
-
|
| 61 |
-
Make sure you have followed the above steps first.
|
| 62 |
-
If everything is done, check you can launch the EleutherAIHarness on your model locally, using the above command without modifications (you can add `--limit` to limit the number of examples per task).
|
| 63 |
"""
|
| 64 |
|
| 65 |
CITATION_BUTTON_LABEL = "Copy the following snippet to cite these results"
|
| 66 |
CITATION_BUTTON_TEXT = r"""
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 67 |
"""
|
|
|
|
| 11 |
# Init: to update with your specific keys
|
| 12 |
class Tasks(Enum):
|
| 13 |
# task_key in the json file, metric_key in the json file, name to display in the leaderboard
|
| 14 |
+
task0 = Task("SAS", "weighted_accuracy", "SAS")
|
| 15 |
+
task1 = Task("SPP", "weighted_accuracy", "SPP")
|
| 16 |
+
task2 = Task("EDP", "weighted_accuracy", "EDP")
|
| 17 |
+
task3 = Task("TSP_D", "weighted_accuracy", "TSP_D")
|
| 18 |
+
task4 = Task("GCP_D", "weighted_accuracy", "GCP_D")
|
| 19 |
+
task5 = Task("KSP", "weighted_accuracy", "KSP")
|
| 20 |
+
task6 = Task("TSP", "weighted_accuracy", "TSP")
|
| 21 |
+
task7 = Task("GCP", "weighted_accuracy", "GCP")
|
| 22 |
+
task8 = Task("MSP", "weighted_accuracy", "MSP")
|
| 23 |
|
| 24 |
|
| 25 |
# Your leaderboard name
|
| 26 |
+
TITLE = """<h1 align="center" id="space-title">NPHardEval leaderboard</h1>"""
|
| 27 |
|
| 28 |
# What does your leaderboard evaluate?
|
| 29 |
INTRODUCTION_TEXT = """
|
| 30 |
+
NPHardEval serves as a comprehensive benchmark for assessing the reasoning abilities of large language models (LLMs) through the lens of computational complexity classes.
|
| 31 |
+
[Our repository](https://github.com/casmlab/NPHardEval) contains datasets, data generation scripts, and experimental procedures designed to evaluate LLMs in various reasoning tasks.
|
| 32 |
+
In particular, we use three complexity classes to define the task complexity in the benchmark, including P (polynomial time), NP-complete (nondeterministic polynomial-time complete),
|
| 33 |
+
and NP-hard, which are increasingly complex in both the intrinsic difficulty and the resources needed to solve them. The selected nine problems are:
|
| 34 |
+
1) P problems: Sorted Array Search (SAS), Edit Distance Problem (EDP), Shortest Path Problem (SPP);
|
| 35 |
+
2) NP-complete problems: Traveling Salesman Problem Decision Version (TSP-D), Graph Coloring Problem Decision Version (GCP-D), and Knapsack Problem (KSP);
|
| 36 |
+
3) NP-hard problems: Traveling Salesman Problem Optimization Version (TSP), Graph Coloring Problem Optimization Version (GCP), and Meeting Scheduling Problem (MSP).
|
| 37 |
+
|
| 38 |
+
The following figure shows their relation regarding computational complexity in an Euler diagram.
|
| 39 |
+
|
| 40 |
+
<div align="center">
|
| 41 |
+
<img
|
| 42 |
+
src="https://raw.githubusercontent.com/casmlab/NPHardEval/main/NP-hard.jpg"
|
| 43 |
+
style="width: 50%;"
|
| 44 |
+
alt="Selected problems and the Euler diagram of computational complexity classes"
|
| 45 |
+
>
|
| 46 |
+
</div>
|
| 47 |
+
|
| 48 |
+
Our benchmark offers several advantages compared with current benchmarks:
|
| 49 |
+
- Data construction grounded in the established computational complexity hierarchy
|
| 50 |
+
- Automatic checking mechanisms
|
| 51 |
+
- Automatic generation of datapoints
|
| 52 |
+
- Complete focus on reasoning while exclude numerical computation
|
| 53 |
"""
|
| 54 |
|
| 55 |
# Which evaluations are you running? how can people reproduce what you have?
|
| 56 |
LLM_BENCHMARKS_TEXT = f"""
|
| 57 |
+
The paramount importance of complex reasoning in Large Language Models (LLMs) is well-recognized,
|
| 58 |
+
especially in their application to intricate decision-making tasks. This underscores the necessity
|
| 59 |
+
of thoroughly investigating LLMs' reasoning capabilities. To this end, various benchmarks have been
|
| 60 |
+
developed to evaluate these capabilities. However, existing benchmarks fall short in providing a
|
| 61 |
+
comprehensive assessment of LLMs' potential in reasoning. Additionally, there is a risk of overfitting,
|
| 62 |
+
as these benchmarks are static and publicly accessible, allowing models to tailor responses to specific
|
| 63 |
+
metrics, thus artificially boosting their performance.
|
| 64 |
+
|
| 65 |
+
In response, our research introduces 'NPHardEval,' a novel benchmark meticulously designed to
|
| 66 |
+
comprehensively evaluate LLMs' reasoning abilities. It comprises a diverse array of 900 algorithmic
|
| 67 |
+
questions, spanning the spectrum up to NP-Hard complexity. These questions are strategically selected
|
| 68 |
+
to cover a vast range of complexities, ensuring a thorough evaluation of LLMs' reasoning power. This
|
| 69 |
+
benchmark not only offers insights into the current state of reasoning in LLMs but also establishes
|
| 70 |
+
a benchmark for comparing LLMs' performance across various complexity classes.
|
| 71 |
+
|
| 72 |
+
Our study marks a significant contribution to understanding LLMs' current reasoning capabilities
|
| 73 |
+
and paves the way for future enhancements. Furthermore, NPHardEval features a dynamic update mechanism,
|
| 74 |
+
refreshing data points monthly. This approach is crucial in reducing the risk of model overfitting,
|
| 75 |
+
leading to a more accurate and dependable evaluation of LLMs' reasoning skills. The benchmark dataset
|
| 76 |
+
and the associated code are accessible at [NPHardEval GitHub Repository]("https://github.com/casmlab/NPHardEval").
|
| 77 |
+
|
| 78 |
+
## Quick Start
|
| 79 |
+
### Environment setup
|
| 80 |
+
```bash
|
| 81 |
+
conda create --name llm_reason python=3.10
|
| 82 |
+
conda activate llm_reason
|
| 83 |
+
git clone https://github.com/casmlab/NPHardEval.git
|
| 84 |
+
pip install -r requirements.txt
|
| 85 |
```
|
|
|
|
| 86 |
|
| 87 |
+
### Set-up API keys
|
| 88 |
+
Please set up your API keys in `secrets.txt`. **Please don't directly upload your keys to any public repository.**
|
| 89 |
|
| 90 |
+
### Example Commands
|
| 91 |
+
Let's use the GPT 4 Turbo model (GPT-4-1106-preview) and the EDP for example.
|
| 92 |
|
| 93 |
+
For its zeroshot experiment, you can use:
|
| 94 |
+
```
|
| 95 |
+
cd run
|
| 96 |
+
cd run_close_zeroshot
|
| 97 |
+
python run_hard_GCP.py gpt-4-1106-preview
|
| 98 |
+
```
|
| 99 |
|
| 100 |
+
For its fewshot experiment,
|
| 101 |
+
```
|
| 102 |
+
cd run
|
| 103 |
+
cd run_close_fewshot
|
| 104 |
+
python run_close_fewshot/run_hard_GCP.py gpt-4-1106-preview self
|
| 105 |
+
```
|
| 106 |
+
"""
|
| 107 |
|
| 108 |
+
EVALUATION_QUEUE_TEXT = """
|
| 109 |
+
Currently, we don't support the submission of new evaluations.
|
|
|
|
|
|
|
| 110 |
"""
|
| 111 |
|
| 112 |
CITATION_BUTTON_LABEL = "Copy the following snippet to cite these results"
|
| 113 |
CITATION_BUTTON_TEXT = r"""
|
| 114 |
+
@misc{fan2023nphardeval,
|
| 115 |
+
title={NPHardEval: Dynamic Benchmark on Reasoning Ability of Large Language Models via Complexity Classes},
|
| 116 |
+
author={Lizhou Fan and Wenyue Hua and Lingyao Li and Haoyang Ling and Yongfeng Zhang and Libby Hemphill},
|
| 117 |
+
year={2023},
|
| 118 |
+
eprint={2312.14890},
|
| 119 |
+
archivePrefix={arXiv},
|
| 120 |
+
primaryClass={cs.AI}
|
| 121 |
+
}
|
| 122 |
"""
|
src/display/utils.py
CHANGED
|
@@ -27,7 +27,7 @@ auto_eval_column_dict = []
|
|
| 27 |
auto_eval_column_dict.append(["model_type_symbol", ColumnContent, ColumnContent("T", "str", True, never_hidden=True)])
|
| 28 |
auto_eval_column_dict.append(["model", ColumnContent, ColumnContent("Model", "markdown", True, never_hidden=True)])
|
| 29 |
#Scores
|
| 30 |
-
auto_eval_column_dict.append(["average", ColumnContent, ColumnContent("
|
| 31 |
for task in Tasks:
|
| 32 |
auto_eval_column_dict.append([task.name, ColumnContent, ColumnContent(task.value.col_name, "number", True)])
|
| 33 |
# Model information
|
|
|
|
| 27 |
auto_eval_column_dict.append(["model_type_symbol", ColumnContent, ColumnContent("T", "str", True, never_hidden=True)])
|
| 28 |
auto_eval_column_dict.append(["model", ColumnContent, ColumnContent("Model", "markdown", True, never_hidden=True)])
|
| 29 |
#Scores
|
| 30 |
+
auto_eval_column_dict.append(["average", ColumnContent, ColumnContent("Avg ⬆️", "number", True)])
|
| 31 |
for task in Tasks:
|
| 32 |
auto_eval_column_dict.append([task.name, ColumnContent, ColumnContent(task.value.col_name, "number", True)])
|
| 33 |
# Model information
|
src/envs.py
CHANGED
|
@@ -5,10 +5,9 @@ from huggingface_hub import HfApi
|
|
| 5 |
# clone / pull the lmeh eval data
|
| 6 |
TOKEN = os.environ.get("TOKEN", None)
|
| 7 |
|
| 8 |
-
OWNER = "
|
| 9 |
-
REPO_ID = f"{OWNER}/leaderboard"
|
| 10 |
-
|
| 11 |
-
RESULTS_REPO = f"{OWNER}/results"
|
| 12 |
|
| 13 |
CACHE_PATH=os.getenv("HF_HOME", ".")
|
| 14 |
|
|
|
|
| 5 |
# clone / pull the lmeh eval data
|
| 6 |
TOKEN = os.environ.get("TOKEN", None)
|
| 7 |
|
| 8 |
+
OWNER = "hyfrankl"
|
| 9 |
+
REPO_ID = f"{OWNER}/NPHardEval-leaderboard"
|
| 10 |
+
RESULTS_REPO = f"{OWNER}/NPHardEval-results"
|
|
|
|
| 11 |
|
| 12 |
CACHE_PATH=os.getenv("HF_HOME", ".")
|
| 13 |
|
src/leaderboard/read_evals.py
CHANGED
|
@@ -59,10 +59,13 @@ class EvalResult:
|
|
| 59 |
full_model, config.get("model_sha", "main"), trust_remote_code=True, test_tokenizer=False
|
| 60 |
)
|
| 61 |
architecture = "?"
|
|
|
|
| 62 |
if model_config is not None:
|
| 63 |
architectures = getattr(model_config, "architectures", None)
|
| 64 |
if architectures:
|
| 65 |
architecture = ";".join(architectures)
|
|
|
|
|
|
|
| 66 |
|
| 67 |
# Extract results available in this file (some results are split in several files)
|
| 68 |
results = {}
|
|
@@ -86,7 +89,8 @@ class EvalResult:
|
|
| 86 |
precision=precision,
|
| 87 |
revision= config.get("model_sha", ""),
|
| 88 |
still_on_hub=still_on_hub,
|
| 89 |
-
architecture=architecture
|
|
|
|
| 90 |
)
|
| 91 |
|
| 92 |
def update_with_request_file(self, requests_path):
|
|
|
|
| 59 |
full_model, config.get("model_sha", "main"), trust_remote_code=True, test_tokenizer=False
|
| 60 |
)
|
| 61 |
architecture = "?"
|
| 62 |
+
model_type = ModelType.from_str(config.get("model_type", "Unknown"))
|
| 63 |
if model_config is not None:
|
| 64 |
architectures = getattr(model_config, "architectures", None)
|
| 65 |
if architectures:
|
| 66 |
architecture = ";".join(architectures)
|
| 67 |
+
if model_type == ModelType.Unknown:
|
| 68 |
+
model_type = ModelType.from_str(getattr(model_config, "model_type", "Unknown"))
|
| 69 |
|
| 70 |
# Extract results available in this file (some results are split in several files)
|
| 71 |
results = {}
|
|
|
|
| 89 |
precision=precision,
|
| 90 |
revision= config.get("model_sha", ""),
|
| 91 |
still_on_hub=still_on_hub,
|
| 92 |
+
architecture=architecture,
|
| 93 |
+
model_type=model_type,
|
| 94 |
)
|
| 95 |
|
| 96 |
def update_with_request_file(self, requests_path):
|
src/submission/submit.py
CHANGED
|
@@ -3,7 +3,7 @@ import os
|
|
| 3 |
from datetime import datetime, timezone
|
| 4 |
|
| 5 |
from src.display.formatting import styled_error, styled_message, styled_warning
|
| 6 |
-
from src.envs import API, EVAL_REQUESTS_PATH, TOKEN
|
| 7 |
from src.submission.check_validity import (
|
| 8 |
already_submitted_models,
|
| 9 |
check_model_card,
|
|
@@ -22,97 +22,6 @@ def add_new_eval(
|
|
| 22 |
weight_type: str,
|
| 23 |
model_type: str,
|
| 24 |
):
|
| 25 |
-
global REQUESTED_MODELS
|
| 26 |
-
global USERS_TO_SUBMISSION_DATES
|
| 27 |
-
if not REQUESTED_MODELS:
|
| 28 |
-
REQUESTED_MODELS, USERS_TO_SUBMISSION_DATES = already_submitted_models(EVAL_REQUESTS_PATH)
|
| 29 |
-
|
| 30 |
-
user_name = ""
|
| 31 |
-
model_path = model
|
| 32 |
-
if "/" in model:
|
| 33 |
-
user_name = model.split("/")[0]
|
| 34 |
-
model_path = model.split("/")[1]
|
| 35 |
-
|
| 36 |
-
precision = precision.split(" ")[0]
|
| 37 |
-
current_time = datetime.now(timezone.utc).strftime("%Y-%m-%dT%H:%M:%SZ")
|
| 38 |
-
|
| 39 |
-
if model_type is None or model_type == "":
|
| 40 |
-
return styled_error("Please select a model type.")
|
| 41 |
-
|
| 42 |
-
# Does the model actually exist?
|
| 43 |
-
if revision == "":
|
| 44 |
-
revision = "main"
|
| 45 |
-
|
| 46 |
-
# Is the model on the hub?
|
| 47 |
-
if weight_type in ["Delta", "Adapter"]:
|
| 48 |
-
base_model_on_hub, error, _ = is_model_on_hub(model_name=base_model, revision=revision, token=TOKEN, test_tokenizer=True)
|
| 49 |
-
if not base_model_on_hub:
|
| 50 |
-
return styled_error(f'Base model "{base_model}" {error}')
|
| 51 |
-
|
| 52 |
-
if not weight_type == "Adapter":
|
| 53 |
-
model_on_hub, error, _ = is_model_on_hub(model_name=model, revision=revision, test_tokenizer=True)
|
| 54 |
-
if not model_on_hub:
|
| 55 |
-
return styled_error(f'Model "{model}" {error}')
|
| 56 |
-
|
| 57 |
-
# Is the model info correctly filled?
|
| 58 |
-
try:
|
| 59 |
-
model_info = API.model_info(repo_id=model, revision=revision)
|
| 60 |
-
except Exception:
|
| 61 |
-
return styled_error("Could not get your model information. Please fill it up properly.")
|
| 62 |
-
|
| 63 |
-
model_size = get_model_size(model_info=model_info, precision=precision)
|
| 64 |
-
|
| 65 |
-
# Were the model card and license filled?
|
| 66 |
-
try:
|
| 67 |
-
license = model_info.cardData["license"]
|
| 68 |
-
except Exception:
|
| 69 |
-
return styled_error("Please select a license for your model")
|
| 70 |
-
|
| 71 |
-
modelcard_OK, error_msg = check_model_card(model)
|
| 72 |
-
if not modelcard_OK:
|
| 73 |
-
return styled_error(error_msg)
|
| 74 |
-
|
| 75 |
-
# Seems good, creating the eval
|
| 76 |
-
print("Adding new eval")
|
| 77 |
-
|
| 78 |
-
eval_entry = {
|
| 79 |
-
"model": model,
|
| 80 |
-
"base_model": base_model,
|
| 81 |
-
"revision": revision,
|
| 82 |
-
"precision": precision,
|
| 83 |
-
"weight_type": weight_type,
|
| 84 |
-
"status": "PENDING",
|
| 85 |
-
"submitted_time": current_time,
|
| 86 |
-
"model_type": model_type,
|
| 87 |
-
"likes": model_info.likes,
|
| 88 |
-
"params": model_size,
|
| 89 |
-
"license": license,
|
| 90 |
-
}
|
| 91 |
-
|
| 92 |
-
# Check for duplicate submission
|
| 93 |
-
if f"{model}_{revision}_{precision}" in REQUESTED_MODELS:
|
| 94 |
-
return styled_warning("This model has been already submitted.")
|
| 95 |
-
|
| 96 |
-
print("Creating eval file")
|
| 97 |
-
OUT_DIR = f"{EVAL_REQUESTS_PATH}/{user_name}"
|
| 98 |
-
os.makedirs(OUT_DIR, exist_ok=True)
|
| 99 |
-
out_path = f"{OUT_DIR}/{model_path}_eval_request_False_{precision}_{weight_type}.json"
|
| 100 |
-
|
| 101 |
-
with open(out_path, "w") as f:
|
| 102 |
-
f.write(json.dumps(eval_entry))
|
| 103 |
-
|
| 104 |
-
print("Uploading eval file")
|
| 105 |
-
API.upload_file(
|
| 106 |
-
path_or_fileobj=out_path,
|
| 107 |
-
path_in_repo=out_path.split("eval-queue/")[1],
|
| 108 |
-
repo_id=QUEUE_REPO,
|
| 109 |
-
repo_type="dataset",
|
| 110 |
-
commit_message=f"Add {model} to eval queue",
|
| 111 |
-
)
|
| 112 |
-
|
| 113 |
-
# Remove the local file
|
| 114 |
-
os.remove(out_path)
|
| 115 |
-
|
| 116 |
return styled_message(
|
| 117 |
-
"
|
| 118 |
)
|
|
|
|
| 3 |
from datetime import datetime, timezone
|
| 4 |
|
| 5 |
from src.display.formatting import styled_error, styled_message, styled_warning
|
| 6 |
+
from src.envs import API, EVAL_REQUESTS_PATH, TOKEN
|
| 7 |
from src.submission.check_validity import (
|
| 8 |
already_submitted_models,
|
| 9 |
check_model_card,
|
|
|
|
| 22 |
weight_type: str,
|
| 23 |
model_type: str,
|
| 24 |
):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 25 |
return styled_message(
|
| 26 |
+
"Currently, we don't support adding new evaluations. Please contact the admins for more information."
|
| 27 |
)
|