

title: README
emoji: 📉
colorFrom: red
colorTo: pink
sdk: static
pinned: false
Centro de I+D+i pionero en Big Data e Inteligencia Artificial en España
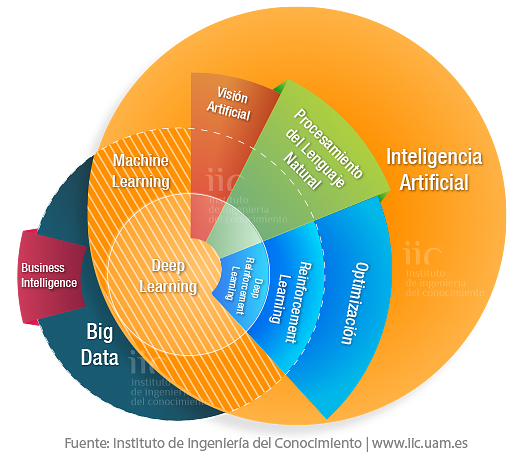
El Instituto de Ingeniería del Conocimiento (IIC) es un centro de I+D+i sin ánimo de lucro que se fundó en 1989 y, por tanto, lleva más de 30 años trabajando en análisis Big Data e Inteligencia Artificial. Su apuesta de valor es el desarrollo de algoritmos y soluciones de analítica a medida de diferentes negocios en diferentes sectores, basadas siempre en la investigación aplicada. De hecho, su misión es abarcar el ciclo completo de la innovación: desde la investigación básica hasta la transferencia de los avances tecnológicos a la sociedad. Todo ello bajo el amparo de sus actuales asociados: IBM España, Grupo Santander, MAPFRE y la Universidad Autónoma de Madrid.
Actualmente contamos con más de 150 profesionales y nos diferenciamos por ser un equipo multidisciplinar en el que tienen cabida sobre todo científicos de datos, ingenieros informáticos y matemáticos, pero también lingüistas computacionales, psicólogos y psicómetras, entre otros. La variedad de perfiles nos permite tener un conocimiento más amplio de los ámbitos a los que dirigimos y ofrecerles proyectos y soluciones más integrales. En concreto, estamos especializados en las áreas de Banca, RR. HH., Energía, Salud, Seguros e Inteligencia de Cliente.
Expertos en Procesamiento del Lenguaje Natural (PLN)
Una de las líneas de trabajo del IIC que más impacto está teniendo actualmente es la del Procesamiento del Lenguaje Natural (PLN) y las tecnologías del lenguaje. Ante la gran cantidad de información en texto que generamos, surge la posibilidad de analizarla, aprovecharla y descubrir datos y relaciones que pueden pasar desapercibidos.
Las técnicas de PLN permiten extraer insights automáticamente de la información disponible en cualquier sector. En el IIC, desarrollamos modelos de Machine learning y modelos de lenguaje que se aplican a la búsqueda avanzada de información, la clasificación de documentos, la extracción de términos y entidades, la detección de anomalías, el análisis del sentimiento o como base de los conocidos chatbots. Estas aplicaciones están siendo muy útiles, por ejemplo, en el sector legal, en la atención al cliente o en salud.
Entre nuestros avances de investigación dentro del campo del PLN ha sido la creación de RigoBERTa, un modelo de lenguaje español entrenado para la comprensión general de nuestro idioma. Este cuenta con la posibilidad de adaptarse a diferentes dominios del lenguaje (legal, salud, etc.) para mejorar las aplicaciones del Procesamiento del Lenguaje Natural (PLN) en ámbitos específicos.

El desarrollo de este modelo de lenguaje en español adaptado al sector legal surge como parte de un proyecto de investigación del IIC donde se ha estudiado la explotación y creación de modelos de lenguaje en español: RigoBERTa

Las aplicaciones de Procesamiento del Lenguaje Natural (PLN) pueden ser especialmente útiles para el sector legal, por el tiempo que sus profesionales pasan entre grandes cantidades de documentos.

En Lingüística Computacional (LC) y en Procesamiento del Lenguaje Natural (PLN), los datos se recogen en corpus, que no dejan de ser conjuntos de datos (textos) reales y representativos de un dominio concreto de la lengua a la que pertenecen.