

A newer version of the Gradio SDK is available:
5.6.0
title: factool_dev
app_file: ./app.py
sdk: gradio
sdk_version: 3.39.0
FacTool: Factuality Detection in Generative AI
Factuality Leaderboard | Installation | Quick Start | ChatGPT Plugin with FacTool | Citation |
This repository contains the source code and plugin configuration for our paper:
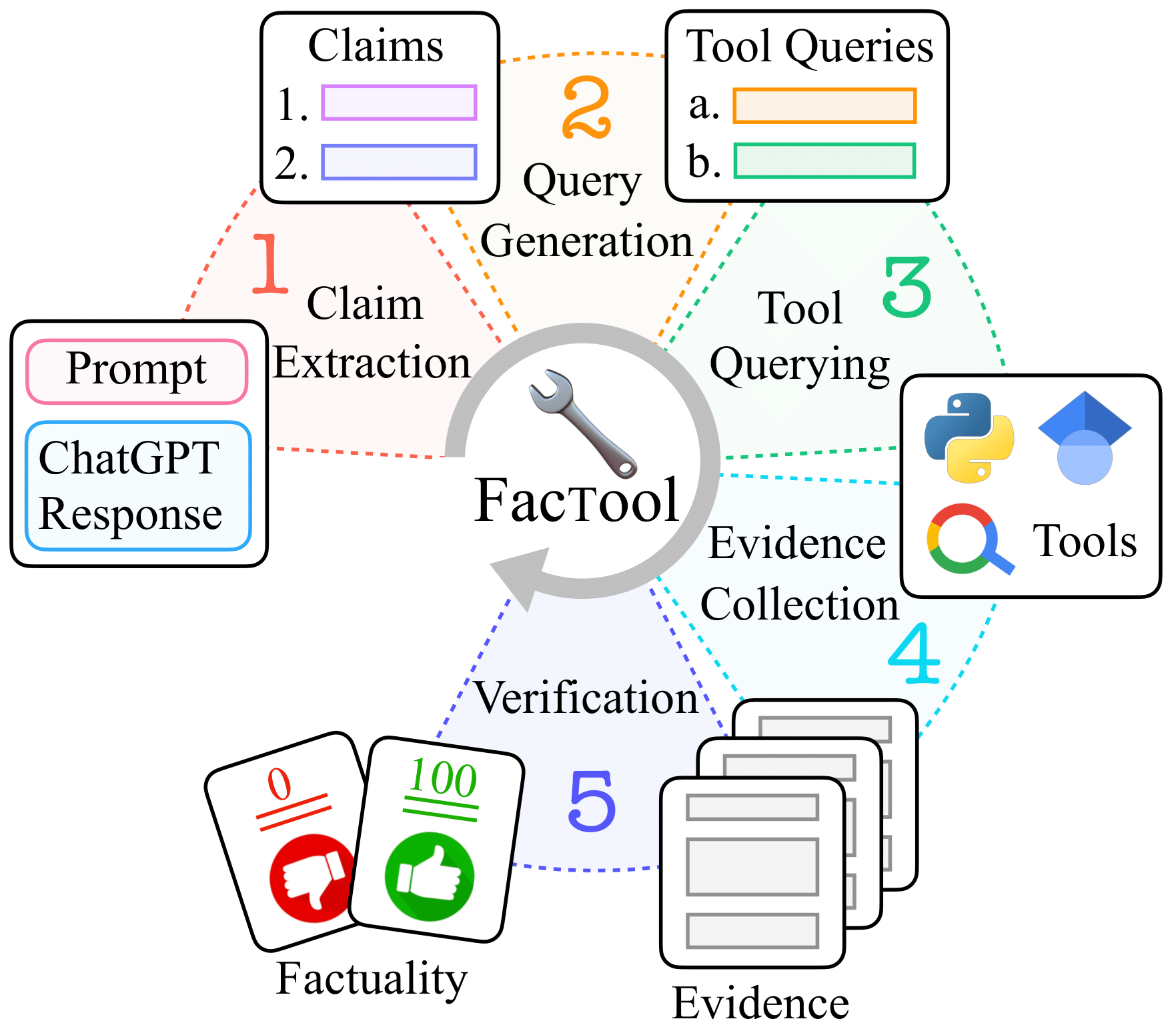
Factool is a tool augmented framework for detecting factual errors of texts generated by large language models (e.g., ChatGPT). Factool now supports 4 tasks:
- knowledge-based QA: Factool detects factual errors in knowledge-based QA.
- code generation: Factool detects execution errors in code generation.
- mathematical reasoning: Factool detects calculation errors in mathematical reasoning.
- scientific literature review: Factool detects hallucinated scientific literatures.
Demo of Knowledge-based QA:



Factuality Leaderboard
Our factuality leaderboard shows the factual accuracy of different chatbots evaluated by FacTool.
| LLMs | Weighted Claim-Level Accuracy | Response-Level Accuracy |
|---|---|---|
| GPT-4 | 75.60 | 43.33 |
| ChatGPT | 68.63 | 36.67 |
| Claude-v1 | 63.95 | 26.67 |
| Bard | 61.15 | 33.33 |
| Vicuna-13B | 50.35 | 21.67 |
Installation
pip install factool
git clone git@github.com:GAIR-NLP/factool.git
cd factool
pip install -e .
Quick Start
API Key Preparation
- get your OpenAI API key from here. This is used in all scenarios (Knowledge-based QA, Code, Math, Scientific Literature Review).
- get your Serper API key from here. This is only used in Knowledge-based QA.
- get your Scraper API key from here. This is only used in Scientific Literature Review.
General Usage
You could also directly refer to ./example/example.py and example_inputs.jsonl for general usage.
General Usage (click to toggle the content)
export OPENAI_API_KEY=... # this is required in all tasks
export SERPER_API_KEY=... # this is required only in knowledge-based QA
export SCRAPER_API_KEY=... # this is requried only in scientific literature review
# Initialize a list of inputs. "entry_point" is only needed when the task is "code generation"
# please refer to example_inputs.jsonl for example inputs for each category
inputs = [
{"prompt": "<prompt1>", "response": "<response1>", "category": "<category1>", "entry_point": "<entry_point_1>"},
{"prompt": "<prompt2>", "response": "<response2>", "category": "<category2>", "entry_point": "<entry_point_2>"},
...
]
where
prompt: The prompt for the model to generate the response.response: The response generated by the model.category: The category of the task. it could be:kbqacodemathscientific
entry_point: The function name of the code snippet to be fact-checked in the response. Could be "null" if the category of the task is notcode.
from factool import Factool
# Initialize a Factool instance with the specified keys. foundation_model could be either "gpt-3.5-turbo" or "gpt-4"
factool_instance = Factool("gpt-4")
inputs = [
{
"prompt": "Introduce Graham Neubig",
"response": "Graham Neubig is a professor at MIT",
"category": "kbqa"
},
...
]
response_list = factool_instance.run(inputs)
print(response_list)
Knowledge-based QA
Detailed usage of factool on knowledge-based QA (click to toggle the content)
export OPENAI_API_KEY=...
export SERPER_API_KEY=...
from factool import Factool
# Initialize a Factool instance with the specified keys. foundation_model could be either "gpt-3.5-turbo" or "gpt-4"
factool_instance = Factool("gpt-4")
inputs = [
{
"prompt": "Introduce Graham Neubig",
"response": "Graham Neubig is a professor at MIT",
"category": "kbqa"
},
]
response_list = factool_instance.run(inputs)
print(response_list)
The response_list should follow the following format:
{
"average_claim_level_factuality": avg_claim_level_factuality
"average_response_level_factuality": avg_response_level_factuality
"detailed_information": [
{
'prompt': prompt_1,
'response': response_1,
'category': 'kbqa',
'claims': [claim_11, claim_12, ..., claims_1n],
'queries': [[query_111, query_112], [query_121, query_122], ..[query_1n1, query_1n2]],
'evidences': [[evidences_with_source_11], [evidences_with_source_12], ..., [evidences_with_source_1n]],
'claim_level_factuality': [{claim_11, reasoning_11, error_11, correction_11, factuality_11}, {claim_12, reasoning_12, error_12, correction_12, factuality_12}, ..., {claim_1n, reasoning_1n, error_1n, correction_1n, factuality_1n}],
'response_level_factuality': factuality_1
},
{
'prompt': prompt_2,
'response': response_2,
'category': 'kbqa',
'claims': [claim_21, claim_22, ..., claims_2n],
'queries': [[query_211, query_212], [query_221, query_222], ..., [query_2n1, query_2n2]],
'evidences': [[evidences_with_source_21], [evidences_with_source_22], ..., [evidences_with_source_2n]],
'claim_level_factuality': [{claim_21, reasoning_21, error_21, correction_21, factuality_21}, {claim_22, reasoning_22, error_22, correction_22, factuality_22}, ..., {claim_2n, reasoning_2n, error_2n, correction_2n, factuality_2n}],
'response_level_factuality': factuality_2,
},
...
]
}
In this case, you will get:
{
'average_claim_level_factuality': 0.0,
'average_response_level_factuality': 0.0,
'detailed_information': [
{'prompt': 'Introduce Graham Neubig',
'response': 'Graham Neubig is a professor at MIT',
'category': 'kbqa', 'search_type': 'online',
'claims': [{'claim': 'Graham Neubig is a professor at MIT'}],
'queries': [['Graham Neubig current position', 'Is Graham Neubig a professor at MIT?']],
'evidences': [{'evidence': 'I am an Associate Professor of Computer Science at Carnegie Mellon University and CEO of Inspired Cognition. My research and development focuses on AI and ...', 'source': 'https://www.linkedin.com/in/graham-neubig-10b41616b'}, {'evidence': 'Missing: position | Show results with:position', 'source': 'https://www.linkedin.com/in/graham-neubig-10b41616b'}, {'evidence': 'My research is concerned with language and its role in human communication. In particular, my long-term research goal is to break down barriers in ...', 'source': 'https://miis.cs.cmu.edu/people/222215657/graham-neubig'}, {'evidence': 'My research focuses on handling human languages (like English or Japanese) with computers -- natural language processing. In particular, I am interested in ...', 'source': 'http://www.phontron.com/'}, {'evidence': 'Missing: current | Show results with:current', 'source': 'http://www.phontron.com/'}, {'evidence': 'Graham Neubig. I am an Associate Professor at the Carnegie Mellon University Language Technology Institute in the School of Computer Science, and work with ...', 'source': 'http://www.phontron.com/'}, {'evidence': 'Missing: MIT? | Show results with:MIT?', 'source': 'http://www.phontron.com/'}, {'evidence': 'Associate Professor, Language Technology Institute, Carnegie Mellon University Affiliated Faculty, Machine Learning Department, Carnegie Mellon University', 'source': 'https://www.phontron.com/research.php'}, {'evidence': 'Missing: MIT? | Show results with:MIT?', 'source': 'https://www.phontron.com/research.php'}, {'evidence': 'MIT Embodied Intelligence ... About the speaker: Graham ...', 'source': 'https://youtube.com/watch?v=CtcP5bvODzY'}],
'claim_level_factuality': [
{'reasoning': 'The given text is non-factual. The evidence provided clearly states that Graham Neubig is an Associate Professor of Computer Science at Carnegie Mellon University, not at MIT.',
'error': 'The error in the text is the incorrect affiliation of Graham Neubig. He is not a professor at MIT.',
'correction': 'Graham Neubig is a professor at Carnegie Mellon University.',
'factuality': False,
'claim': 'Graham Neubig is a professor at MIT'}
],
'response_level_factuality': False}
]
}
Code
Detailed usage of factool on code (click to toggle the content)
export OPENAI_API_KEY=...
from factool import Factool
# Initialize a Factool instance with the specified keys. foundation_model could be either "gpt-3.5-turbo" or "gpt-4"
factool_instance = Factool("gpt-4")
inputs = [
{
"prompt": "def get_max_triples(n): \"\"\" You are given a positive integer n. You have to create an integer array a of length n. For each i (1 \u2264 i \u2264 n), the value of a[i] = i * i - i + 1. Return the number of triples (a[i], a[j], a[k]) of a where i < j < k, and a[i] + a[j] + a[k] is a multiple of 3. Example : Input: n = 5 Output: 1 Explanation: a = [1, 3, 7, 13, 21] The only valid triple is (1, 7, 13). \"\"\" Now implement the function get_max_triples using Python",
"response": "def get_max_triples(n):\n a = [i * i - i + 1 for i in range(1, n+1)]\n count = 0\n for i in range(n-2):\n for j in range(i+1, n-1):\n for k in range(j+1, n):\n if (a[i] + a[j] + a[k]) % 3 == 0:\n count += 1\n return count\n\nprint(get_max_triples(5)) # Output: 1",
"category": "code",
"entry_point": "get_max_triples"
}
]
response_list = factool_instance.run(inputs)
print(response_list)
The response_list should follow the following format:
response_list =
{
"average_claim_level_factuality": avg_claim_level_factuality,
"average_response_level_factuality": avg_response_level_factuality,
"detailed_information": [
{
'prompt': prompt_1,
'response': response_1,
'category': 'code',
'entry_point': entry_point_1,
'claim': claim_1,
'testcases_queries': [testcase_query_11, testcase_query_12, testcase_query_13],
'potential_solutions_queries': [potential_solution_query_11, potential_solution_query_12, potential_solution_query_13],
'exec_results': [[evidences_111, evidences_112, evidences_113, evidences_114], [evidences_121, evidences_122, evidences_123, evidences_124], [evidences_131, evidences_132, evidences_133, evidences_134]], # note that evidences_114, evidences_124, evidences_134 are the execution results of response_1 against testcase_query_11, testcase_query_12, and testcase_query_13, respectively.
'claim_level_factuality': factuality_1,
'response_level_factuality': factuality_1,
},
{
'prompt': prompt_2,
'response': response_2,
'category': 'code',
'entry_point': entry_point_2,
'claim': claim_2,
'testcases_queries': [testcase_query_21, testcase_query_22, testcase_query_23],
'potential_solutions_queries': [potential_solution_query_21, potential_solution_query_22, potential_solution_query_23],
'exec_results': [[evidences_211, evidences_212, evidences_213, evidences_214], [evidences_221, evidences_222, evidences_223, evidences_224], [evidences_231, evidences_232, evidences_233, evidences_234]], # note that evidences_214, evidences_224, evidences_234 are the execution results of response_1 against testcase_query_21, testcase_query_22, and testcase_query_23, respectively.
'claim_level_factuality': factuality_2,
'response_level_factuality': factuality_2,
},
]
...
}
In this case, you will get:
{
"average_claim_level_factuality": 1.0,
"average_response_level_factuality": 1.0,
"detailed_information": [
{
'prompt': 'def get_max_triples(n): """ You are given a positive integer n. You have to create an integer array a of length n. For each i (1 ≤ i ≤ n), the value of a[i] = i * i - i + 1. Return the number of triples (a[i], a[j], a[k]) of a where i < j < k, and a[i] + a[j] + a[k] is a multiple of 3. Example : Input: n = 5 Output: 1 Explanation: a = [1, 3, 7, 13, 21] The only valid triple is (1, 7, 13). """ Now implement the function get_max_triples using Python',
'response': 'def get_max_triples(n):\n a = [i * i - i + 1 for i in range(1, n+1)]\n count = 0\n for i in range(n-2):\n for j in range(i+1, n-1):\n for k in range(j+1, n):\n if (a[i] + a[j] + a[k]) % 3 == 0:\n count += 1\n return count\n\nprint(get_max_triples(5)) # Output: 1',
'category': 'code',
'entry_point': 'get_max_triples',
'claim': 'def get_max_triples(n):\n a = [i * i - i + 1 for i in range(1, n+1)]\n count = 0\n for i in range(n-2):\n for j in range(i+1, n-1):\n for k in range(j+1, n):\n if (a[i] + a[j] + a[k]) % 3 == 0:\n count += 1\n return count\n\nprint(get_max_triples(5)) # Output: 1',
'testcases_queries': ['get_max_triples(5)', 'get_max_triples(10)', 'get_max_triples(3)'], 'potential_solutions_queries': ['def get_max_triples(n):\n a = [i * i - i + 1 for i in range(1, n+1)]\n count = 0\n for i in range(n-2):\n for j in range(i+1, n-1):\n for k in range(j+1, n):\n if (a[i] + a[j] + a[k]) % 3 == 0:\n count += 1\n return count', 'def get_max_triples(n):\n a = [i * i - i + 1 for i in range(1, n + 1)]\n count = 0\n for i in range(n):\n for j in range(i + 1, n):\n for k in range(j + 1, n):\n if (a[i] + a[j] + a[k]) % 3 == 0:\n count += 1\n return count', 'def get_max_triples(n):\n a = [i * i - i + 1 for i in range(1, n+1)]\n count = 0\n for i in range(n):\n for j in range(i+1, n):\n for k in range(j+1, n):\n if (a[i] + a[j] + a[k]) % 3 == 0:\n count += 1\n return count', 'def get_max_triples(n):\n a = [i * i - i + 1 for i in range(1, n+1)]\n count = 0\n for i in range(n-2):\n for j in range(i+1, n-1):\n for k in range(j+1, n):\n if (a[i] + a[j] + a[k]) % 3 == 0:\n count += 1\n return count\n\nprint(get_max_triples(5)) # Output: 1'],
'exec_results': [[1, 1, 1, 1], [36, 36, 36, 36], [0, 0, 0, 0]],
'claim_level_factuality': True,
'response_level_factuality': True
}
]
}
Math
Detailed usage of factool on math (click to toggle the content)
export OPENAI_API_KEY=...
from factool import Factool
# Initialize a Factool instance with the specified keys. foundation_model could be either "gpt-3.5-turbo" or "gpt-4"
factool_instance = Factool("gpt-4")
inputs = [
{
"prompt": "Stephen placed an online order for groceries. His final bill came to $7023116. Because this was through a delivery vendor, they tacked on a 25% fee to his final total and charged him $3.00 in delivery fees. Stephen also added a $4.00 tip. After the extra fees, what was the final price of Stephen's groceries?",
"category": "math",
"response": "Okay, here are the steps to solve this:\n* Stephen's initial grocery bill was $7023116\n* The delivery vendor charged a 25% fee on top of that. 25% of $7023116 is 0.25 * $7023116 = $1755779\n* They also charged a flat $3 delivery fee\n* Stephen added a $4 tip\n* So the total charges were:\n * Initial groceries: $7023116\n * 25% fee: $1755779\n * Delivery fee: $3 \n * Tip: $4\n* Adding all that up, the total final price was $7023116 + $1755779 + $3 + $4 = $8779902\n\nSo the final price of Stephen's groceries was $8779902"
},
]
response_list = factool_instance.run(inputs)
print(response_list)
The response_list should follow the following format:
{
"average_claim_level_factuality": avg_claim_level_factuality,
"average_response_level_factuality": avg_response_level_factuality,
"detailed_information": [
{
'prompt': prompt_1,
'response': response_1,
'category': 'math',
'claims': [claim_11, claim_12, ..., claims_1n],
'queries': [query_11, query_12, ..., query_1n],
'execution_results': [exec_result_11, exec_result_12, ..., exec_result_1n],
'claim_level_factuality': [factuality_11, factuality_12, ..., factuality_1n],
'response_level_factuality': factuality_1
},
{
'prompt': prompt_2,
'response': response_2,
'category': 'math',
'claims': [claim_21, claim_22, ..., claims_2n],
'queries': [query_21, query_22, ..., query_2n],
'execution_results': [exec_result_21, exec_result_22, ..., exec_result_2n],
'claim_level_factuality': [factuality_21, factuality_22, ..., factuality_2n],
'response_level_factuality': factuality_2
},
...
]
}
In this case, you will get:
{
"average_claim_level_factuality": 0.5,
"average_response_level_factuality": 0.0,
"detailed_information": [
{
'prompt': "Stephen placed an online order for groceries. His final bill came to $7023116. Because this was through a delivery vendor, they tacked on a 25% fee to his final total and charged him $3.00 in delivery fees. Stephen also added a $4.00 tip. After the extra fees, what was the final price of Stephen's groceries?",
'category': 'math',
'response': "Okay, here are the steps to solve this:\n* Stephen's initial grocery bill was $7023116\n* The delivery vendor charged a 25% fee on top of that. 25% of $7023116 is 0.25 * $7023116 = $1755779\n* They also charged a flat $3 delivery fee\n* Stephen added a $4 tip\n* So the total charges were:\n * Initial groceries: $7023116\n * 25% fee: $1755779\n * Delivery fee: $3 \n * Tip: $4\n* Adding all that up, the total final price was $7023116 + $1755779 + $3 + $4 = $8779902\n\nSo the final price of Stephen's groceries was $8779902", 'claims': [{'math_calculation': '0.25 * 7023116', 'calculated_answer': '1755779'}, {'math_calculation': '7023116 + 1755779 + 3 + 4', 'calculated_answer': '8779902'}], 'queries': [{'python_snippet': 'print(0.25 * 7023116 == 1755779)'}, {'python_snippet': 'print(7023116 + 1755779 + 3 + 4 == 8779902)'}], 'execution_results': ['True', 'False'],
'claim_level_factuality': [True, False],
'response_level_factuality': False
}
]
}
Scientific Literature Review
Detailed usage of factool on scientific literature review (click to toggle the content)
export OPENAI_API_KEY=...
export SCRAPER_API_KEY=...
from factool import Factool
# Initialize a Factool instance with the specified keys. foundation_model could be either "gpt-3.5-turbo" or "gpt-4"
factool_instance = Factool("gpt-4")
inputs = [
{
"prompt": "Detail how machine learning algorithms are applied in data"
" analytics and the processes involved in training"
" these algorithms. Please cite relevant research papers"
" or textbooks to support your points, including the author's"
" name, the title of the work, and the year of publication.",
"category": "scientific",
"response": "Machine learning algorithms play a crucial role in data"
" analytics. They are used to extract insights and knowledge"
" from large datasets, which can be used to make informed"
" decisions and predictions. The following are the processes"
" involved in training machine learning algorithms:\n\n1. "
"Data Preprocessing: The first step in training a machine"
" learning algorithm is to preprocess the data. This involves"
" cleaning the data, handling missing values, "
"encoding categorical variables, and scaling the data. "
"The aim of preprocessing is to ensure that the data is in"
" a format that can be used by the machine learning algorithm.\n2. Feature Selection: Once the data has been preprocessed, the next step is to select the relevant features that will be used to train the machine learning algorithm. This involves identifying the features that are most important for predicting the target variable. Feature selection can be done using various techniques, such as filter methods, wrapper methods, and embedded methods.\n3. Model Selection: After feature selection, the next step is to select the appropriate machine learning algorithm to use. There are various types of machine learning algorithms, such as supervised learning, unsupervised learning, and reinforcement learning. The choice of algorithm depends on the nature of the problem and the type of data available.\n4. Training the Model: Once the model has been selected, the next step is to train the machine learning algorithm using the preprocessed data. This involves using a training set of data to optimize the parameters of the model so that it can accurately predict the target variable.\n5. Model Evaluation: After the model has been trained, the next step is to evaluate its performance. This involves testing the model on a separate test set of data and measuring its accuracy, precision, recall, and other performance metrics.\n6. Model Deployment: Once the model has been evaluated and fine-tuned, it can be deployed in a production environment. This involves integrating the model into a larger system or workflow, and monitoring its performance over time.\n\nResearch papers and textbooks that support the above points include:\n\n* \"An Introduction to Machine Learning\" by Alpaydin, B., (2010) which provides a comprehensive overview of machine learning algorithms and their applications.\n* \"Data Mining: Concepts and Techniques\" by Han, J., Kamber, B., & Pei, J., (2011) which provides a detailed introduction to data mining and its applications.\n* \"Machine Learning: Trends, Perspectives, and Prospects\" by Kamber, B., & Pei, J., (2012) which provides an overview of the current trends and future prospects of machine learning.\n* \"Machine Learning for Data Mining\" by He, C., & Wang, Y., (2015) which provides an in-depth introduction to machine learning algorithms and their applications in data mining."
},
]
response_list = factool_instance.run(inputs)
print(response_list)
The response_list should follow the following format:
{
"average_claim_level_factuality": avg_claim_level_factuality,
"average_response_level_factuality": avg_response_level_factuality,
"detailed_information": [
{
'prompt': prompt_1,
'response': response_1,
'category': 'scientific',
'claims': [claim_11, claim_12, ..., claims_1n],
'queries': [query_11, query_12, ..., query_1n],
'evidences': [evidences_11, evidences_12, ..., evidences_1n],
'claim_level_factuality': [{claim_11, evidence_11, error_11, factuality_11}, {claim_12, evidence_12, error_12, factuality_12}, ..., {claim_1n, evidence_1n, error_1n, factuality_1n}],
'response_level_factuality': factuality_1
},
{
'prompt': prompt_2,
'response': response_2,
'category': 'scientific',
'claims': [claim_21, claim_22, ..., claims_2n],
'queries': [query_21, query_22, ..., query_2n],
'evidences': [evidences_21, evidences_22, ..., evidences_2n],
'claim_level_factuality': [{claim_21, evidence_21, error_21, factuality_21}, {claim_22, evidence_22, error_22, factuality_22}, ..., {claim_2n, evidence_2n, error_2n, factuality_2n}],
'response_level_factuality': factuality_2
},
...
]
}
In this case, you will get:
{
"average_claim_level_factuality": 0.0,
"average_response_level_factuality": 0.0,
"detailed_information": [
{
'prompt': "Detail how machine learning algorithms are applied in data analytics and the processes involved in training these algorithms. Please cite relevant research papers or textbooks to support your points, including the author's name, the title of the work, and the year of publication.", 'response': 'Machine learning algorithms play a crucial role in data analytics. They are used to extract insights and knowledge from large datasets, which can be used to make informed decisions and predictions. The following are the processes involved in training machine learning algorithms:\n\n1. Data Preprocessing: The first step in training a machine learning algorithm is to preprocess the data. This involves cleaning the data, handling missing values, encoding categorical variables, and scaling the data. The aim of preprocessing is to ensure that the data is in a format that can be used by the machine learning algorithm.\n2. Feature Selection: Once the data has been preprocessed, the next step is to select the relevant features that will be used to train the machine learning algorithm. This involves identifying the features that are most important for predicting the target variable. Feature selection can be done using various techniques, such as filter methods, wrapper methods, and embedded methods.\n3. Model Selection: After feature selection, the next step is to select the appropriate machine learning algorithm to use. There are various types of machine learning algorithms, such as supervised learning, unsupervised learning, and reinforcement learning. The choice of algorithm depends on the nature of the problem and the type of data available.\n4. Training the Model: Once the model has been selected, the next step is to train the machine learning algorithm using the preprocessed data. This involves using a training set of data to optimize the parameters of the model so that it can accurately predict the target variable.\n5. Model Evaluation: After the model has been trained, the next step is to evaluate its performance. This involves testing the model on a separate test set of data and measuring its accuracy, precision, recall, and other performance metrics.\n6. Model Deployment: Once the model has been evaluated and fine-tuned, it can be deployed in a production environment. This involves integrating the model into a larger system or workflow, and monitoring its performance over time.\n\nResearch papers and textbooks that support the above points include:\n\n* "An Introduction to Machine Learning" by Alpaydin, B., (2010) which provides a comprehensive overview of machine learning algorithms and their applications.\n* "Data Mining: Concepts and Techniques" by Han, J., Kamber, B., & Pei, J., (2011) which provides a detailed introduction to data mining and its applications.\n* "Machine Learning: Trends, Perspectives, and Prospects" by Kamber, B., & Pei, J., (2012) which provides an overview of the current trends and future prospects of machine learning.\n* "Machine Learning for Data Mining" by He, C., & Wang, Y., (2015) which provides an in-depth introduction to machine learning algorithms and their applications in data mining.',
'category': 'scientific',
'claims': [{'paper_title': 'An Introduction to Machine Learning', 'paper_author(s)': 'Alpaydin, B.', 'paper_pub_year': '2010'}, {'paper_title': 'Data Mining: Concepts and Techniques', 'paper_author(s)': 'Han, J., Kamber, B., & Pei, J.', 'paper_pub_year': '2011'}, {'paper_title': 'Machine Learning: Trends, Perspectives, and Prospects', 'paper_author(s)': 'Kamber, B., & Pei, J.', 'paper_pub_year': '2012'}, {'paper_title': 'Machine Learning for Data Mining', 'paper_author(s)': 'He, C., & Wang, Y.', 'paper_pub_year': '2015'}],
'queries': ['An Introduction to Machine Learning', 'Data Mining: Concepts and Techniques', 'Machine Learning: Trends, Perspectives, and Prospects', 'Machine Learning for Data Mining'],
'evidences': [{'title': 'Introduction to machine learning', 'author': ['Y Baştanlar', 'M Özuysal'], 'pub_year': '2014'}, {'title': 'Data mining: Data mining concepts and techniques', 'author': ['S Agarwal'], 'pub_year': '2013'}, {'title': 'Machine learning: Trends, perspectives, and prospects', 'author': ['MI Jordan', 'TM Mitchell'], 'pub_year': '2015'}, {'title': 'Machine learning and data mining', 'author': ['TM Mitchell'], 'pub_year': '1999'}],
'claim_level_factuality': [{'generated_paper_title': 'An Introduction to Machine Learning', 'generated_paper_author(s)': 'Alpaydin, B.', 'generated_paper_pub_year': '2010', 'actual_paper_title': 'Introduction to machine learning', 'actual_paper_author(s)': ['Y Baştanlar', 'M Özuysal'], 'actual_paper_pub_year': '2014', 'error': ['wrong_paper_author(s)', 'wrong_paper_pub_year'], 'factuality': False}, {'generated_paper_title': 'Data Mining: Concepts and Techniques', 'generated_paper_author(s)': 'Han, J., Kamber, B., & Pei, J.', 'generated_paper_pub_year': '2011', 'actual_paper_title': 'Data mining: Data mining concepts and techniques', 'actual_paper_author(s)': ['S Agarwal'], 'actual_paper_pub_year': '2013', 'error': ['wrong_paper_title', 'wrong_paper_author(s)', 'wrong_paper_pub_year'], 'factuality': False}, {'generated_paper_title': 'Machine Learning: Trends, Perspectives, and Prospects', 'generated_paper_author(s)': 'Kamber, B., & Pei, J.', 'generated_paper_pub_year': '2012', 'actual_paper_title': 'Machine learning: Trends, perspectives, and prospects', 'actual_paper_author(s)': ['MI Jordan', 'TM Mitchell'], 'actual_paper_pub_year': '2015', 'error': ['wrong_paper_author(s)', 'wrong_paper_pub_year'], 'factuality': False}, {'generated_paper_title': 'Machine Learning for Data Mining', 'generated_paper_author(s)': 'He, C., & Wang, Y.', 'generated_paper_pub_year': '2015', 'actual_paper_title': 'Machine learning and data mining', 'actual_paper_author(s)': ['TM Mitchell'], 'actual_paper_pub_year': '1999', 'error': ['wrong_paper_title', 'wrong_paper_author(s)', 'wrong_paper_pub_year'], 'factuality': False}],
'response_level_factuality': False
}
]
}
ChatGPT Plugin with Factool
- export the API keys
- Install the package: Installation
- git clone the repo:
git clone https://github.com/GAIR-NLP/factool.git cd ./plugin_config- Run the API locally:
uvicorn main:app --host 0.0.0.0 --port ${PORT:-5003} - Enter plugin store of ChatGPT Website
- Click 'develop your own plugin' then enter the website domain
localhost:5003under 'domain'.
Demo
Videos (click to toggle the content)
Knowledge-based QA:


Code:

Math:

Scientific Literature Review:

Citation
Please cite our paper if you find the repository helpful.
@article{chern2023factool,
title={FacTool: Factuality Detection in Generative AI--A Tool Augmented Framework for Multi-Task and Multi-Domain Scenarios},
author={Chern, I-Chun and Chern, Steffi and Chen, Shiqi and Yuan, Weizhe and Feng, Kehua and Zhou, Chunting and He, Junxian and Neubig, Graham and Liu, Pengfei},
journal={arXiv preprint arXiv:2307.13528},
year={2023}
}