|
import gradio as gr |
|
from haystack.document_stores import FAISSDocumentStore |
|
from haystack.nodes import EmbeddingRetriever |
|
import openai |
|
import os |
|
from utils import ( |
|
make_pairs, |
|
set_openai_api_key, |
|
create_user_id, |
|
to_completion, |
|
) |
|
import numpy as np |
|
from datetime import datetime |
|
from azure.storage.fileshare import ShareServiceClient |
|
|
|
|
|
|
|
|
|
|
|
|
|
theme = gr.themes.Soft( |
|
primary_hue="sky", |
|
font=[gr.themes.GoogleFont("Inter"), "ui-sans-serif", "system-ui", "sans-serif"], |
|
) |
|
|
|
system_template = {"role": "system", "content": os.environ["content"]} |
|
|
|
openai.api_type = "azure" |
|
openai.api_key = os.environ["api_key"] |
|
openai.api_base = os.environ["ressource_endpoint"] |
|
openai.api_version = "2022-12-01" |
|
|
|
retrieve_all = EmbeddingRetriever( |
|
document_store=FAISSDocumentStore.load( |
|
index_path="./documents/climate_gpt.faiss", |
|
config_path="./documents/climate_gpt.json", |
|
), |
|
embedding_model="sentence-transformers/multi-qa-mpnet-base-dot-v1", |
|
model_format="sentence_transformers", |
|
) |
|
|
|
retrieve_giec = EmbeddingRetriever( |
|
document_store=FAISSDocumentStore.load( |
|
index_path="./documents/climate_gpt_only_giec.faiss", |
|
config_path="./documents/climate_gpt_only_giec.json", |
|
), |
|
embedding_model="sentence-transformers/multi-qa-mpnet-base-dot-v1", |
|
model_format="sentence_transformers", |
|
) |
|
|
|
credential = { |
|
"account_key": os.environ["account_key"], |
|
"account_name": os.environ["account_name"], |
|
} |
|
|
|
account_url = os.environ["account_url"] |
|
file_share_name = "climategpt" |
|
service = ShareServiceClient(account_url=account_url, credential=credential) |
|
share_client = service.get_share_client(file_share_name) |
|
user_id = create_user_id(10) |
|
|
|
|
|
def chat( |
|
user_id: str, |
|
query: str, |
|
history: list = [system_template], |
|
report_type: str = "IPCC only", |
|
threshold: float = 0.555, |
|
) -> tuple: |
|
"""retrieve relevant documents in the document store then query gpt-turbo |
|
|
|
Args: |
|
query (str): user message. |
|
history (list, optional): history of the conversation. Defaults to [system_template]. |
|
report_type (str, optional): should be "All available" or "IPCC only". Defaults to "All available". |
|
threshold (float, optional): similarity threshold, don't increase more than 0.568. Defaults to 0.56. |
|
|
|
Yields: |
|
tuple: chat gradio format, chat openai format, sources used. |
|
""" |
|
|
|
if report_type == "All available": |
|
retriever = retrieve_all |
|
elif report_type == "IPCC only": |
|
retriever = retrieve_giec |
|
else: |
|
raise Exception("report_type arg should be in (All available, IPCC only)") |
|
|
|
reformulated_query = openai.Completion.create( |
|
engine="climateGPT", |
|
prompt=f"Reformulate the following user message to be a short standalone question in English, in the context of an educationnal discussion about climate change.\n---\nquery: La technologie nous sauvera-t-elle ?\nstandalone question: Can technology help humanity mitigate the effects of climate change?\n---\nquery: what are our reserves in fossil fuel?\nstandalone question: What are the current reserves of fossil fuels and how long will they last?\n---\nquery: {query}\nstandalone question: ", |
|
temperature=0, |
|
max_tokens=128, |
|
stop=["\n---\n", "<|im_end|>"], |
|
) |
|
reformulated_query = reformulated_query["choices"][0]["text"] |
|
|
|
docs = retriever.retrieve(query=reformulated_query, top_k=10) |
|
|
|
messages = history + [{"role": "user", "content": query}] |
|
sources = "\n\n".join( |
|
[f"query used for retrieval:\n{reformulated_query}"] |
|
+ [ |
|
f"📃 doc {i}: {d.meta['file_name']} page {d.meta['page_number']}\n{d.content}" |
|
for i, d in enumerate(docs, 1) |
|
if d.score > threshold |
|
] |
|
) |
|
|
|
if docs: |
|
messages.append({"role": "system", "content": f"{os.environ['sources']}\n\n{sources}"}) |
|
|
|
response = openai.Completion.create( |
|
engine="climateGPT", |
|
prompt=to_completion(messages), |
|
temperature=0, |
|
stream=True, |
|
max_tokens=1024, |
|
) |
|
|
|
complete_response = "" |
|
messages.pop() |
|
|
|
messages.append({"role": "assistant", "content": complete_response}) |
|
timestamp = str(datetime.now().timestamp()) |
|
file = user_id[0] + timestamp + ".json" |
|
logs = { |
|
"user_id": user_id[0], |
|
"prompt": query, |
|
"retrived": sources, |
|
"report_type": report_type, |
|
"prompt_eng": messages[0], |
|
"answer": messages[-1]["content"], |
|
"time": timestamp, |
|
} |
|
log_on_azure(file, logs, share_client) |
|
|
|
for chunk in response: |
|
if (chunk_message := chunk["choices"][0].get("text")) and chunk_message != "<|im_end|>": |
|
complete_response += chunk_message |
|
messages[-1]["content"] = complete_response |
|
gradio_format = make_pairs([a["content"] for a in messages[1:]]) |
|
yield gradio_format, messages, sources |
|
|
|
else: |
|
sources = "⚠️ No relevant passages found in the climate science reports" |
|
complete_response = "**⚠️ No relevant passages found in the climate science reports, you may want to ask a more specific question (specifying your question on climate issues).**" |
|
messages.append({"role": "assistant", "content": complete_response}) |
|
gradio_format = make_pairs([a["content"] for a in messages[1:]]) |
|
yield gradio_format, messages, sources |
|
|
|
|
|
def save_feedback(feed: str, user_id): |
|
if len(feed) > 1: |
|
timestamp = str(datetime.now().timestamp()) |
|
file = user_id[0] + timestamp + ".json" |
|
logs = { |
|
"user_id": user_id[0], |
|
"feedback": feed, |
|
"time": timestamp, |
|
} |
|
log_on_azure(file, logs, share_client) |
|
return "Feedback submitted, thank you!" |
|
|
|
|
|
def reset_textbox(): |
|
return gr.update(value="") |
|
|
|
|
|
def log_on_azure(file, logs, share_client): |
|
file_client = share_client.get_file_client(file) |
|
file_client.upload_file(str(logs)) |
|
|
|
|
|
with gr.Blocks(title="🌍 Climate Q&A", css="style.css", theme=theme) as demo: |
|
user_id_state = gr.State([user_id]) |
|
|
|
|
|
gr.Markdown("<h1><center>Climate Q&A 🌍</center></h1>") |
|
gr.Markdown("<h4><center>Ask climate-related questions to the IPCC reports</center></h4>") |
|
with gr.Row(): |
|
with gr.Column(scale=1): |
|
gr.Markdown( |
|
""" |
|
<p><b>Climate change and environmental disruptions have become some of the most pressing challenges facing our planet today</b>. As global temperatures rise and ecosystems suffer, it is essential for individuals to understand the gravity of the situation in order to make informed decisions and advocate for appropriate policy changes.</p> |
|
<p>However, comprehending the vast and complex scientific information can be daunting, as the scientific consensus references, such as <b>the Intergovernmental Panel on Climate Change (IPCC) reports, span thousands of pages</b>. To bridge this gap and make climate science more accessible, we introduce <b>ClimateQ&A as a tool to distill expert-level knowledge into easily digestible insights about climate science.</b></p> |
|
<div class="tip-box"> |
|
<div class="tip-box-title"> |
|
<span class="light-bulb" role="img" aria-label="Light Bulb">💡</span> |
|
How does ClimateQ&A work? |
|
</div> |
|
ClimateQ&A harnesses modern OCR techniques to parse and preprocess IPCC reports. By leveraging state-of-the-art question-answering algorithms, <i>ClimateQ&A is able to sift through the extensive collection of climate scientific reports and identify relevant passages in response to user inquiries</i>. Furthermore, the integration of the ChatGPT API allows ClimateQ&A to present complex data in a user-friendly manner, summarizing key points and facilitating communication of climate science to a wider audience. |
|
</div> |
|
|
|
<div class="warning-box"> |
|
Version 0.2-beta - This tool is under active development |
|
</div> |
|
|
|
|
|
""" |
|
) |
|
|
|
with gr.Column(scale=1): |
|
gr.Markdown("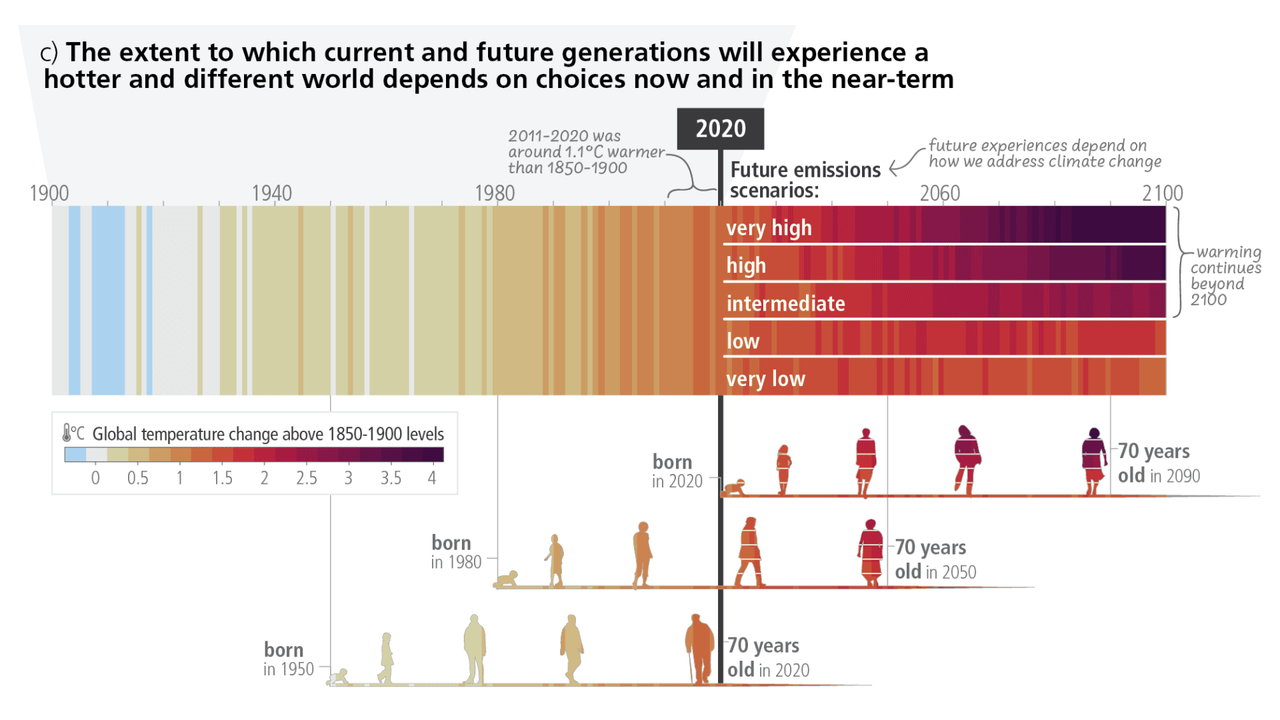") |
|
gr.Markdown("*Source : IPCC AR6 - Synthesis Report of the IPCC 6th assessment report (AR6)*") |
|
|
|
with gr.Row(): |
|
with gr.Column(scale=2): |
|
chatbot = gr.Chatbot(elem_id="chatbot", label="ClimateQ&A chatbot") |
|
state = gr.State([system_template]) |
|
|
|
with gr.Row(): |
|
ask = gr.Textbox( |
|
show_label=False, |
|
placeholder="Ask here your climate-related question and press enter", |
|
).style(container=False) |
|
ask_examples_hidden = gr.Textbox(elem_id="hidden-message") |
|
|
|
examples_questions = gr.Examples( |
|
[ |
|
"What are the main causes of climate change?", |
|
"What are the impacts of climate change?", |
|
"Can climate change be reversed?", |
|
"What is the difference between climate change and global warming?", |
|
"What can individuals do to address climate change? Answer with bullet points", |
|
"What evidence do we have of climate change?", |
|
"What is the Paris Agreement and why is it important?", |
|
"Which industries have the highest GHG emissions?", |
|
"Is climate change caused by humans?", |
|
"Is climate change a hoax created by the government or environmental organizations?", |
|
"What is the relationship between climate change and biodiversity loss?", |
|
"What is the link between gender equality and climate change?", |
|
"Is the impact of climate change really as severe as it is claimed to be?", |
|
"What is the impact of rising sea levels?", |
|
"What are the different greenhouse gases (GHG)?", |
|
"What is the warming power of methane?", |
|
"What is the jet stream?", |
|
"What is the breakdown of carbon sinks?", |
|
"How do the GHGs work ? Why does temperature increase ?", |
|
"What is the impact of global warming on ocean currents?", |
|
"How much warming is possible in 2050?", |
|
"What is the impact of climate change in Africa?", |
|
"Will climate change accelerate diseases and epidemics like COVID?", |
|
"What are the economic impacts of climate change?", |
|
"How much is the cost of inaction ?", |
|
"What is the relationship between climate change and poverty?", |
|
"What are the most effective strategies and technologies for reducing greenhouse gas (GHG) emissions?", |
|
"Is economic growth possible? What do you think about degrowth?", |
|
"Will technology save us?", |
|
"Is climate change a natural phenomenon ?", |
|
"Is climate change really happening or is it just a natural fluctuation in Earth's temperature?", |
|
"Is the scientific consensus on climate change really as strong as it is claimed to be?", |
|
], |
|
[ask_examples_hidden], |
|
examples_per_page=15, |
|
) |
|
|
|
with gr.Column(scale=1, variant="panel"): |
|
gr.Markdown("### Sources") |
|
sources_textbox = gr.Textbox(interactive=False, show_label=False, max_lines=50) |
|
|
|
|
|
|
|
|
|
|
|
ask.submit( |
|
fn=chat, |
|
inputs=[ |
|
user_id_state, |
|
ask, |
|
state, |
|
gr.inputs.Dropdown( |
|
["IPCC only", "All available"], |
|
default="IPCC only", |
|
label="Select reports", |
|
), |
|
], |
|
outputs=[chatbot, state, sources_textbox], |
|
) |
|
ask.submit(reset_textbox, [], [ask]) |
|
|
|
ask_examples_hidden.change( |
|
fn=chat, |
|
inputs=[ |
|
user_id_state, |
|
ask_examples_hidden, |
|
state, |
|
], |
|
outputs=[chatbot, state, sources_textbox], |
|
) |
|
|
|
gr.Markdown("## How to use ClimateQ&A") |
|
with gr.Row(): |
|
with gr.Column(scale=1): |
|
gr.Markdown( |
|
""" |
|
### 💪 Getting started |
|
- In the chatbot section, simply type your climate-related question, and ClimateQ&A will provide an answer with references to relevant IPCC reports. |
|
- ClimateQ&A retrieves specific passages from the IPCC reports to help answer your question accurately. |
|
- Source information, including page numbers and passages, is displayed on the right side of the screen for easy verification. |
|
- Feel free to ask follow-up questions within the chatbot for a more in-depth understanding. |
|
- ClimateQ&A integrates multiple sources (IPCC, IPBES, IEA, Limits to Growth, … ) to cover various aspects of environmental science, such as climate change, biodiversity, energy, economy, and pollution. See all sources used below. |
|
""" |
|
) |
|
with gr.Column(scale=1): |
|
gr.Markdown( |
|
""" |
|
### ⚠️ Limitations |
|
<div class="warning-box"> |
|
<ul> |
|
<li>Currently available in English only.</li> |
|
<li>Please note that, like any AI, the model may occasionally generate an inaccurate or imprecise answer. Always refer to the provided sources to verify the validity of the information given. If you find any issues with the response, kindly provide feedback to help improve the system.</li> |
|
<li>ClimateQ&A is specifically designed for climate-related inquiries. If you ask a non-environmental question, the chatbot will politely remind you that its focus is on climate and environmental issues.</li> |
|
</div> |
|
""" |
|
) |
|
|
|
gr.Markdown("## 🙏 Feedback and feature requests") |
|
gr.Markdown( |
|
""" |
|
### Beta test |
|
- ClimateQ&A welcomes community contributions. To participate, head over to the Community Tab and create a "New Discussion" to ask questions and share your insights. |
|
- Provide feedback through our feedback form, letting us know which insights you found accurate, useful, or not. Your input will help us improve the platform. |
|
- Only a few sources (see below) are integrated (all IPCC, IPBES, IEA recent reports), if you are a climate science researcher and net to sift through another report, please let us know. |
|
""" |
|
) |
|
with gr.Row(): |
|
with gr.Column(scale=1): |
|
gr.Markdown("### Feedbacks") |
|
feedback = gr.Textbox(label="Write your feedback here") |
|
feedback_output = gr.Textbox(label="Submit status") |
|
feedback_save = gr.Button(value="submit feedback") |
|
feedback_save.click( |
|
save_feedback, |
|
inputs=[feedback, user_id_state], |
|
outputs=feedback_output, |
|
) |
|
gr.Markdown( |
|
"If you need us to ask another climate science report or ask any question, contact us at <b>theo.alvesdacosta@ekimetrics.com</b>" |
|
) |
|
|
|
with gr.Column(scale=1): |
|
gr.Markdown("### OpenAI API") |
|
gr.Markdown( |
|
"To make climate science accessible to a wider audience, we have opened our own OpenAI API key with a monthly cap of $1000. If you already have an API key, please use it to help conserve bandwidth for others." |
|
) |
|
openai_api_key_textbox = gr.Textbox( |
|
placeholder="Paste your OpenAI API key (sk-...) and hit Enter", |
|
show_label=False, |
|
lines=1, |
|
type="password", |
|
) |
|
openai_api_key_textbox.change(set_openai_api_key, inputs=[openai_api_key_textbox]) |
|
openai_api_key_textbox.submit(set_openai_api_key, inputs=[openai_api_key_textbox]) |
|
|
|
gr.Markdown( |
|
""" |
|
|
|
|
|
## 📚 Sources |
|
| Source | Report | URL | Number of pages | Release date | |
|
| --- | --- | --- | --- | --- | |
|
| IPCC | IPCC AR6 - First Assessment Report on the Physical Science of Climate Change | https://report.ipcc.ch/ar6/wg1/IPCC_AR6_WGI_FullReport.pdf | 2049 pages | August 2021 | |
|
| IPCC | IPCC AR6 - Second Assessment Report on Climate Change Adaptation | https://report.ipcc.ch/ar6/wg2/IPCC_AR6_WGII_FullReport.pdf | 3068 pages | February 2022 | |
|
| IPCC | IPCC AR6 - Third Assessment Report on Climate Change Mitigation | https://www.ipcc.ch/report/ar6/wg3/downloads/report/IPCC_AR6_WGIII_FullReport.pdf | 2258 pages | April 2022 | |
|
| IPCC | IPCC AR6 - Synthesis Report of the IPCC 6th assessment report (AR6) | https://report.ipcc.ch/ar6syr/pdf/IPCC_AR6_SYR_SPM.pdf | 36 pages | March 2023 | |
|
| IPBES | IPBES Global report on Biodiversity - March 2022 | https://www.ipbes.net/global-assessment | 1148 pages | June 2022 | |
|
| FAO | Food Outlook Biannual Report on Global Food Markets | https://www.fao.org/documents/card/en/c/cb9427en | 174 pages | June 2022 | |
|
| IEA | IEA’s report on the Role of Critical Minerals in Clean Energy Transitions | https://www.iea.org/reports/the-role-of-critical-minerals-in-clean-energy-transitions | 287 pages | May 2021 | |
|
| Club de Rome | Limits to Growth | https://www.donellameadows.org/wp-content/userfiles/Limits-to-Growth-digital-scan-version.pdf | 211 pages | 1972 | |
|
| | Outside The Safe operating system of the Planetary Boundary for Novel Entities | https://pubs.acs.org/doi/10.1021/acs.est.1c04158 | 12 pages | January 2022 | |
|
| | Planetary boundaries: Guiding human development on a changing planet | https://www.science.org/doi/10.1126/science.1259855 | 11 pages | February 2015 | |
|
| UNFCCC | State of the Oceans report | https://unfccc.int/documents/568128 | 75 pages | August 2022 | |
|
| IEA | Word Energy Outlook 2021 | https://www.iea.org/reports/world-energy-outlook-2021 | 386 pages | October 2021 | |
|
| IEA | Word Energy Outlook 2022 | https://www.iea.org/reports/world-energy-outlook-2022 | 524 pages | October 2022 | |
|
| EU parliament | The environmental impacts of plastics and micro plastics use, waste and polution EU and national measures | https://www.europarl.europa.eu/thinktank/en/document/IPOL_STU(2020)658279 | 76 pages | October 2020 | |
|
|
|
## 🛢️ Carbon Footprint |
|
|
|
Carbon emissions were measured during the development and inference process using CodeCarbon [https://github.com/mlco2/codecarbon](https://github.com/mlco2/codecarbon) |
|
|
|
| Phase | Description | Emissions | Source | |
|
| --- | --- | --- | --- | |
|
| Development | OCR and parsing all pdf documents with AI | 28gCO2e | CodeCarbon | |
|
| Development | Question Answering development | 114gCO2e | CodeCarbon | |
|
| Inference | Question Answering | ~0.102gCO2e / call | CodeCarbon | |
|
| Inference | API call to turbo-GPT | ~0.38gCO2e / call | https://medium.com/@chrispointon/the-carbon-footprint-of-chatgpt-e1bc14e4cc2a | |
|
|
|
Carbon Emissions are **relatively low but not negligible** compared to other usages: one question asked to ClimateQ&A is around 0.482gCO2e - equivalent to 2.2m by car (https://datagir.ademe.fr/apps/impact-co2/) |
|
Or around 2 to 4 times more than a typical Google search. |
|
|
|
## 📧 Contact |
|
This tool has been developed by the R&D lab at **Ekimetrics** (Jean Lelong, Nina Achache, Gabriel Olympie, Nicolas Chesneau, Natalia De la Calzada, Théo Alves Da Costa) |
|
|
|
If you have any questions or feature requests, please feel free to reach us out at <b>theo.alvesdacosta@ekimetrics.com</b>. |
|
|
|
## 💻 Developers |
|
For developers, the methodology used is detailed below : |
|
|
|
- Extract individual paragraphs from scientific reports (e.g., IPCC, IPBES) using OCR techniques and open sources algorithms |
|
- Use Haystack to compute semantically representative embeddings for each paragraph using a sentence transformers model (https://huggingface.co/sentence-transformers/multi-qa-mpnet-base-dot-v1). |
|
- Store all the embeddings in a FAISS Flat index. |
|
- Reformulate each user query to be as specific as possible and compute its embedding. |
|
- Retrieve up to 10 semantically closest paragraphs (using dot product similarity) from all available scientific reports. |
|
- Provide these paragraphs as context for GPT-Turbo's answer in a system message. |
|
""" |
|
) |
|
|
|
demo.queue(concurrency_count=16) |
|
|
|
demo.launch() |
|
|

