Spaces:
Runtime error

sdk: streamlit
sdk_version: 1.10.0
app_file: app.py
pinned: false
fullWidth: true
Planogram Scoring
- Train a Yolo Model on the available products in our data base to detect them on a shelf - https://wandb.ai/abhilash001vj/YOLOv5/runs/1v6yh7nk?workspace=user-abhilash001vj - Have the master planogram data captured as a matrix of products encoded as numbers (label encoding by looking the products names saved in a list of all - the available product names ) - Detect the products on real images from stores. - Arrange the detected products in the captured photograph to rows and columns - Compare the product arrangement of captured photograph to the existing master planogram and produce the compliance score for correctly placed products
YOLOv5
YOLOv5 🚀 is a family of object detection architectures and models pretrained on the COCO dataset, and represents Ultralytics open-source research into future vision AI methods, incorporating lessons learned and best practices evolved over thousands of hours of research and development.
Documentation
See the YOLOv5 Docs for full documentation on training, testing and deployment.
Quick Start Examples
Install
Python>=3.6.0 is required with all requirements.txt installed including PyTorch>=1.7:
$ git clone https://github.com/ultralytics/yolov5
$ cd yolov5
$ pip install -r requirements.txt
Inference
Inference with YOLOv5 and PyTorch Hub. Models automatically download from the latest YOLOv5 release.
import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5m, yolov5l, yolov5x, custom
# Images
img = 'https://ultralytics.com/images/zidane.jpg' # or file, Path, PIL, OpenCV, numpy, list
# Inference
results = model(img)
# Results
results.print() # or .show(), .save(), .crop(), .pandas(), etc.
Why YOLOv5

YOLOv5-P5 640 Figure (click to expand)
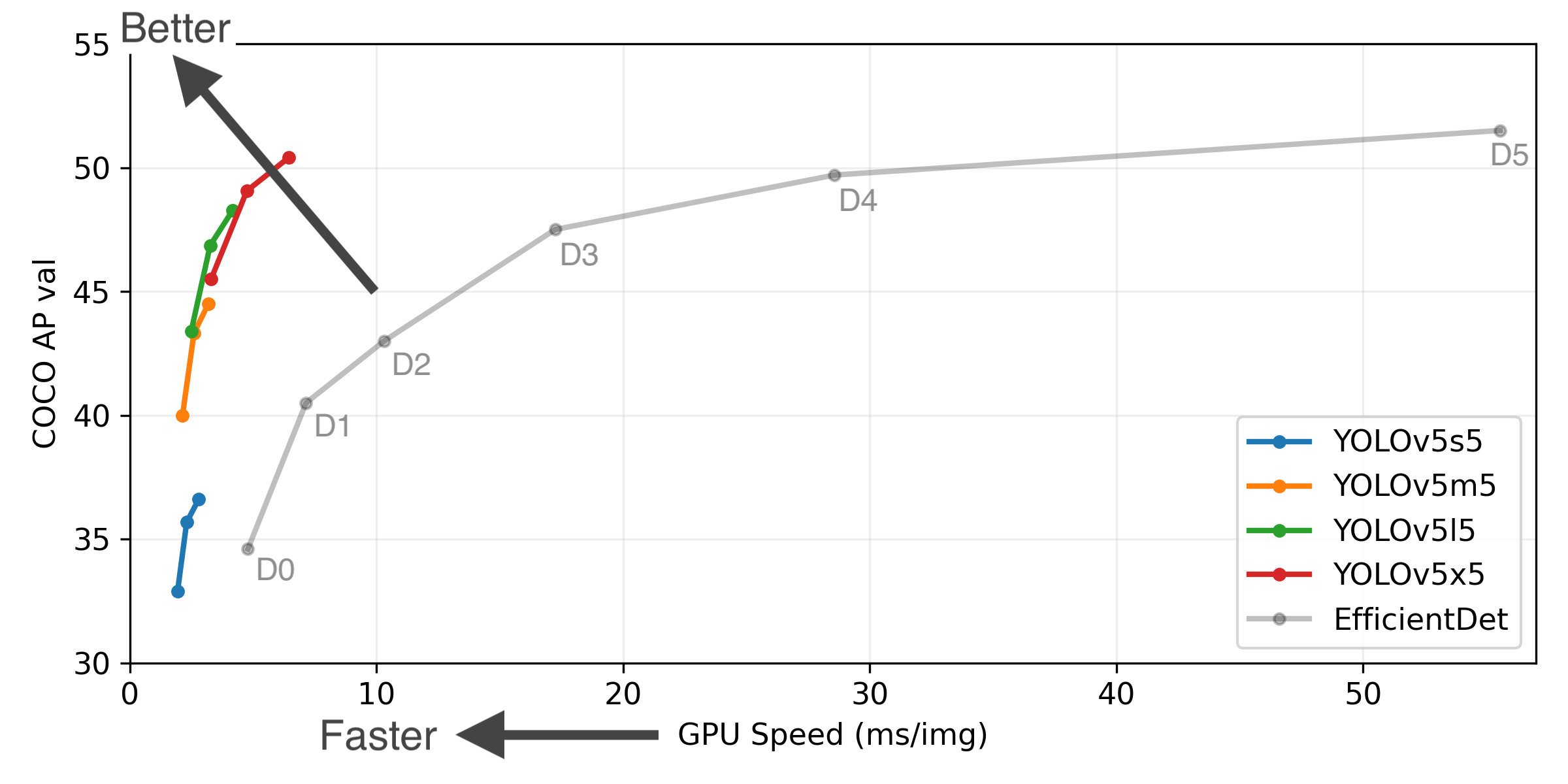
Figure Notes (click to expand)
- GPU Speed measures end-to-end time per image averaged over 5000 COCO val2017 images using a V100 GPU with batch size 32, and includes image preprocessing, PyTorch FP16 inference, postprocessing and NMS.
- EfficientDet data from google/automl at batch size 8.
- Reproduce by
python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.pt
Pretrained Checkpoints
| Model | size (pixels) |
mAPval 0.5:0.95 |
mAPtest 0.5:0.95 |
mAPval 0.5 |
Speed V100 (ms) |
params (M) |
FLOPs 640 (B) |
|
|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 640 | 36.7 | 36.7 | 55.4 | 2.0 | 7.3 | 17.0 | |
| YOLOv5m | 640 | 44.5 | 44.5 | 63.1 | 2.7 | 21.4 | 51.3 | |
| YOLOv5l | 640 | 48.2 | 48.2 | 66.9 | 3.8 | 47.0 | 115.4 | |
| YOLOv5x | 640 | 50.4 | 50.4 | 68.8 | 6.1 | 87.7 | 218.8 | |
| YOLOv5s6 | 1280 | 43.3 | 43.3 | 61.9 | 4.3 | 12.7 | 17.4 | |
| YOLOv5m6 | 1280 | 50.5 | 50.5 | 68.7 | 8.4 | 35.9 | 52.4 | |
| YOLOv5l6 | 1280 | 53.4 | 53.4 | 71.1 | 12.3 | 77.2 | 117.7 | |
| YOLOv5x6 | 1280 | 54.4 | 54.4 | 72.0 | 22.4 | 141.8 | 222.9 | |
| YOLOv5x6 TTA | 1280 | 55.0 | 55.0 | 72.0 | 70.8 | - | - |
Table Notes (click to expand)
- APtest denotes COCO test-dev2017 server results, all other AP results denote val2017 accuracy.
- AP values are for single-model single-scale unless otherwise noted. Reproduce mAP
by
python val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65 - SpeedGPU averaged over 5000 COCO val2017 images using a
GCP n1-standard-16 V100 instance, and
includes FP16 inference, postprocessing and NMS. Reproduce speed
by
python val.py --data coco.yaml --img 640 --conf 0.25 --iou 0.45 --half - All checkpoints are trained to 300 epochs with default settings and hyperparameters (no autoaugmentation).
- Test Time Augmentation (TTA) includes reflection and scale
augmentation. Reproduce TTA by
python val.py --data coco.yaml --img 1536 --iou 0.7 --augment
Contribute
We love your input! We want to make contributing to YOLOv5 as easy and transparent as possible. Please see our Contributing Guide to get started.
Contact
For issues running YOLOv5 please visit GitHub Issues. For business or professional support requests please visit https://ultralytics.com/contact.