

metadata
language:
- es
license: apache-2.0
datasets:
- hackathon-somos-nlp-2023/Habilidades_Agente_v1

SalpiBloomZ-1b7: Spanish + BloomZ + Alpaca + softskills + virtual agents (WIP)
Adapter Description
This adapter was created with the PEFT library and allowed the base model bigscience/bloomz-1b7 to be fine-tuned on the hackathon-somos-nlp-2023/Habilidades_Agente_v1 by using the method LoRA.
How to use
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "hackathon-somos-nlp-2023/salsapaca-native"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path, return_dict=True, load_in_8bit=True, device_map='auto')
tokenizer = AutoTokenizer.from_pretrained(peft_model_id)
# Load the Lora model
model = PeftModel.from_pretrained(model, peft_model_id)
def gen_conversation(text):
text = "<SC>instruction: " + text + "\n "
batch = tokenizer(text, return_tensors='pt')
with torch.cuda.amp.autocast():
output_tokens = model.generate(**batch, max_new_tokens=256, eos_token_id=50258, early_stopping = True, temperature=.9)
print('\n\n', tokenizer.decode(output_tokens[0], skip_special_tokens=False))
text = "hola"
gen_conversation(text)
Resources used
Google Colab machine with the following specifications
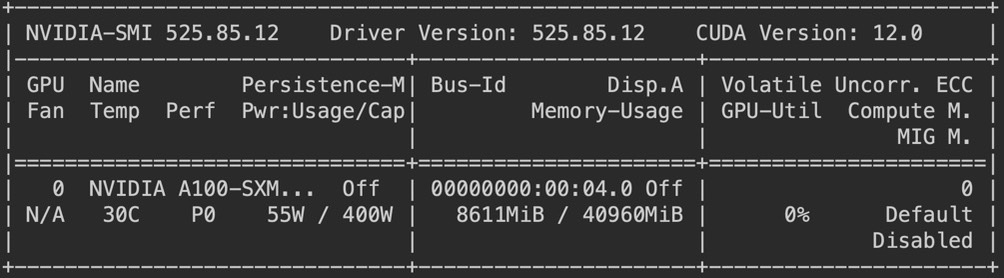
Citation
@misc {hackathon-somos-nlp-2023,
author = { {Edison Bejarano, Leonardo Bolaños, Alberto Ceballos, Santiago Pineda, Nicolay Potes} },
title = { SAlsapaca },
year = 2023,
url = { https://huggingface.co/hackathon-somos-nlp-2023/salsapaca-native }
publisher = { Hugging Face }
}