
metadata
language:
- zh
- en
tags:
- chatglm
- pytorch
- zh
- en
- Text2Text-Generation
license: apache-2.0
widget:
- text: 一岁宝宝发烧能吃啥药?
Medical QA LoRA Model
基于LLaMA-13B的中英医疗问答模型(LoRA)
shibing624/ziya-llama-13b-medical-lora evaluate test data:
The overall performance of chatglm-6b-belle-zh-lora on QA test:
| input_text | predict |
|---|---|
| 一岁宝宝发烧能吃啥药? | 孩子的身体是很脆弱的,如果不注意保护好自己就会出现各种疾病。有些家长在看到孩子生病后都非常着急,想要立刻给他们用药治疗,但其实并没有那么简单,因为每个人对于药物的敏感度和耐受性都是不同的,所以我们需要根据具体情况来选择合适的方法进行治疗才可以达到最佳效果。1、首先大多数小儿退热药中含有解热镇痛成分阿司匹林或布洛芬等,这类药品虽然副作用较少,但也存在过量使用引起胃肠道损伤甚至消化道溃疡出血的风险;2、还有部分小儿退热药中含有扑尔敏等抗组胺药,它们本身属于处方药,应该严格按照医嘱服用,切勿擅自加减剂量或者延长用药时间;3、此外,某些小儿退热药中含有维生素C及葡萄糖酸钙等营养补充剂,只有当患儿伴随脱水症状(如口渴、尿色深)时才考虑添加,否则容易造成电解质紊乱。 |
在中文开放测试集中的表现优异,继承了两方面的优势:1)微调训练的底座是Ziya-LLaMA-13B模型,是较强的中英文底座模型,2)微调使用的是高质量240万条中英文医疗指令数据集,和多种通用指令数据集,微调后的模型在医疗行业答复能力达到领先水平,在通用问题上的答复能力不弱于LLaMA-13B。
Training details
training args:
{"per_device_train_batch_size": 8, "per_device_eval_batch_size": 8, "per_gpu_train_batch_size": null, "per_gpu_eval_batch_size": null, "gradient_accumulation_steps": 1, "eval_accumulation_steps": null, "eval_delay": 0, "learning_rate": 2e-05, "weight_decay": 0.0, "adam_beta1": 0.9, "adam_beta2": 0.999, "adam_epsilon": 1e-08, "max_grad_norm": 1.0, "num_train_epochs": 10.0, "max_steps": -1, "lr_scheduler_type": "linear", "warmup_ratio": 0.0, "warmup_steps": 50, "log_level": "passive", "log_level_replica": "warning", "log_on_each_node": true, "logging_dir": "outputs-ziya-llama-13b-sft-med-v2/logs", "logging_strategy": "steps", "logging_first_step": false, "logging_steps": 50, "logging_nan_inf_filter": true, "save_strategy": "steps", "save_steps": 50, "save_total_limit": 3, "save_safetensors": false, "save_on_each_node": false, "no_cuda": false, "use_mps_device": false, "seed": 42, "data_seed": null, "jit_mode_eval": false, "use_ipex": false, "bf16": false, "fp16": true, "fp16_opt_level": "O1", "half_precision_backend": "cuda_amp", "bf16_full_eval": false, "fp16_full_eval": false, "tf32": null, "local_rank": 0, "xpu_backend": null, "tpu_num_cores": null, "tpu_metrics_debug": false, "debug": [], "dataloader_drop_last": false, "eval_steps": 50, "dataloader_num_workers": 0, "past_index": -1, "run_name": "outputs-ziya-llama-13b-sft-med-v2", "disable_tqdm": false, "remove_unused_columns": false, "label_names": null, "load_best_model_at_end": true, "metric_for_best_model": "loss", "greater_is_better": false, "ignore_data_skip": false, "sharded_ddp": [], "fsdp": [], "fsdp_min_num_params": 0, "fsdp_config": { "fsdp_min_num_params": 0, "xla": false, "xla_fsdp_grad_ckpt": false }, "fsdp_transformer_layer_cls_to_wrap": null, "deepspeed": null, "label_smoothing_factor": 0.0, "optim": "adamw_torch", "optim_args": null, "adafactor": false, "group_by_length": false, "length_column_name": "length", "report_to": [ "tensorboard" ], "ddp_find_unused_parameters": false, "ddp_bucket_cap_mb": null, "dataloader_pin_memory": true, "skip_memory_metrics": true, "use_legacy_prediction_loop": false, "push_to_hub": false, "resume_from_checkpoint": null, "hub_model_id": null, "hub_strategy": "every_save", "hub_token": "<hub_token>", "hub_private_repo": false, "gradient_checkpointing": false, "include_inputs_for_metrics": false, "fp16_backend": "auto", "push_to_hub_model_id": null, "push_to_hub_organization": null, "push_to_hub_token": "<push_to_hub_token>", "mp_parameters": "", "auto_find_batch_size": false, "full_determinism": false, "torchdynamo": null, "ray_scope": "last", "ddp_timeout": 1800, "torch_compile": false, "torch_compile_backend": null, "torch_compile_mode": null }
train log:
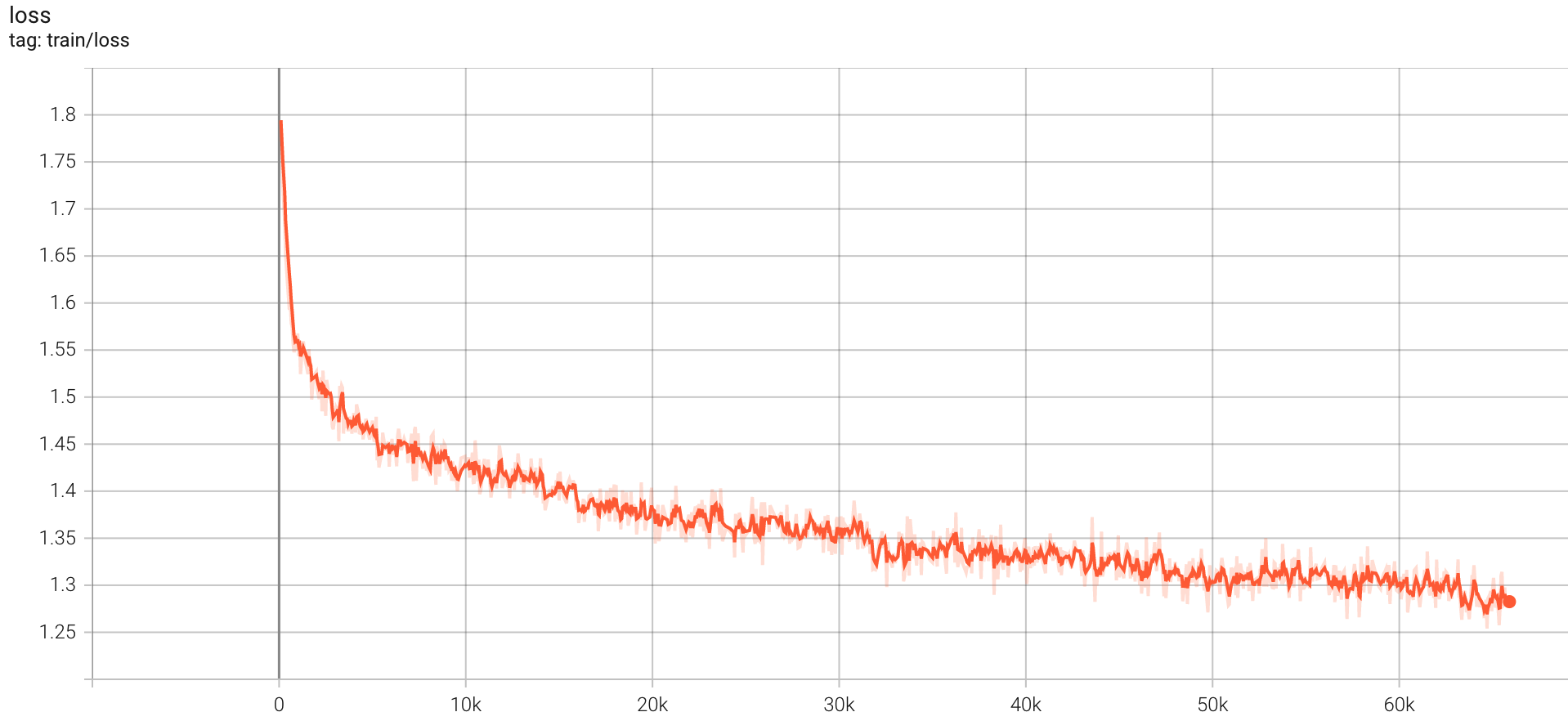
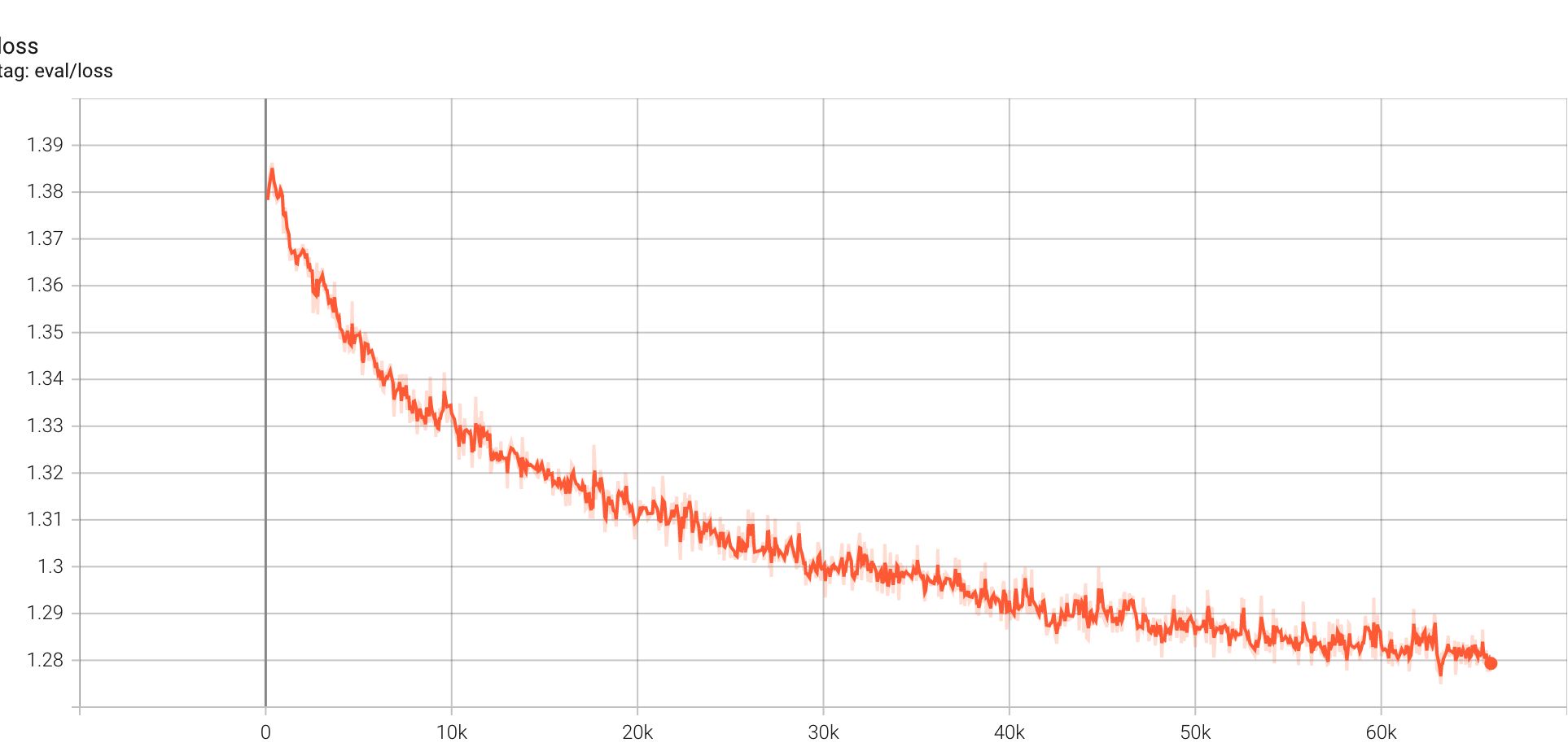
evaluate log:
Usage
本项目开源在 github repo:
使用textgen库:textgen,可调用LLaMA模型:
Install package:
pip install -U textgen
from textgen import LlamaModel
def generate_prompt(instruction):
return f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:{instruction}\n\n### Response: """
ziya_model_dir = "" # ziya模型合并后的路径
model = LlamaModel("llama", ziya_model_dir, peft_name="shibing624/ziya-llama-13b-medical-lora")
predict_sentence = generate_prompt("一岁宝宝发烧能吃啥药?")
r = model.predict([predict_sentence])
print(r) # ["1、首先大多数小儿退热药中含有解热镇痛成分阿司匹林或布洛芬等,这类药品虽然副作用较少..."]
Usage (HuggingFace Transformers)
Without textgen, you can use the model like this:
First, you pass your input through the transformer model, then you get the generated sentence.
Install package:
pip install transformers
import sys
from peft import PeftModel
from transformers import LlamaForCausalLM, LlamaTokenizer
ziya_model_dir = "" # ziya模型合并后的路径
model = LlamaForCausalLM.from_pretrained(ziya_model_dir, device_map='auto')
tokenizer = LlamaTokenizer.from_pretrained(ziya_model_dir)
model = PeftModel.from_pretrained(model, "shibing624/ziya-llama-13b-medical-lora")
device = "cuda" if torch.cuda.is_available() else "cpu"
def generate_prompt(instruction):
return f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:{instruction}\n\n### Response: """
sents = ['一岁宝宝发烧能吃啥药', "who are you?"]
for s in sents:
q = generate_prompt(s)
inputs = tokenizer(q, return_tensors="pt")
inputs = inputs.to(device=device)
generate_ids = ref_model.generate(
**inputs,
max_new_tokens=120,
do_sample=True,
top_p=0.85,
temperature=1.0,
repetition_penalty=1.0,
eos_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
pad_token_id=tokenizer.pad_token_id,
)
output = tokenizer.batch_decode(generate_ids, skip_special_tokens=True)[0]
print(output)
print()
output:
一岁宝宝发烧能吃啥药
孩子的身体是很脆弱的,如果不注意保护好自己就会出现各种疾病。有些家长在看到孩子生病后都非常着急,想要立刻给他们用药治疗,但其实并没有那么简单,因为每个人对于药物的敏感度和耐受性都是不同的,所以我们需要根据具体情况来选择合适的方法进行治疗才可以达到最佳效果。1、首先大多数小儿退热药中含有解热镇痛成分阿司匹林或布洛芬等,这类药品虽然副作用较少,但也存在过量使用引起胃肠道损伤甚至消化道溃疡出血的风险;2、还有部分小儿退热药中含有扑尔敏等抗组胺药,它们本身属于处方药,应该严格按照医嘱服用,切勿擅自加减剂量或者延长用药时间;3、此外,某些小儿退热药中含有维生素C及葡萄糖酸钙等营养补充剂,只有当患儿伴随脱水症状(如口渴、尿色深)时才考虑添加,否则容易造成电解质紊乱。
模型文件组成:
ziya-llama-13b-medical-lora
├── adapter_config.json
└── adapter_model.bin
训练数据集
- 50万条中文ChatGPT指令Belle数据集:BelleGroup/train_0.5M_CN
- 100万条中文ChatGPT指令Belle数据集:BelleGroup/train_1M_CN
- 5万条英文ChatGPT指令Alpaca数据集:50k English Stanford Alpaca dataset
- 2万条中文ChatGPT指令Alpaca数据集:shibing624/alpaca-zh
- 69万条中文指令Guanaco数据集(Belle50万条+Guanaco19万条):Chinese-Vicuna/guanaco_belle_merge_v1.0
- 240万条中文医疗数据集(包括预训练数据和指令微调数据集):shibing624/medical
如果需要训练ChatGLM/LLAMA/BLOOM模型,请参考https://github.com/shibing624/textgen
Citation
@software{textgen,
author = {Ming Xu},
title = {textgen: Implementation of language model finetune},
year = {2023},
url = {https://github.com/shibing624/textgen},
}