license: mit
tags:
- vision
- generation
datasets:
- Laion2B-en
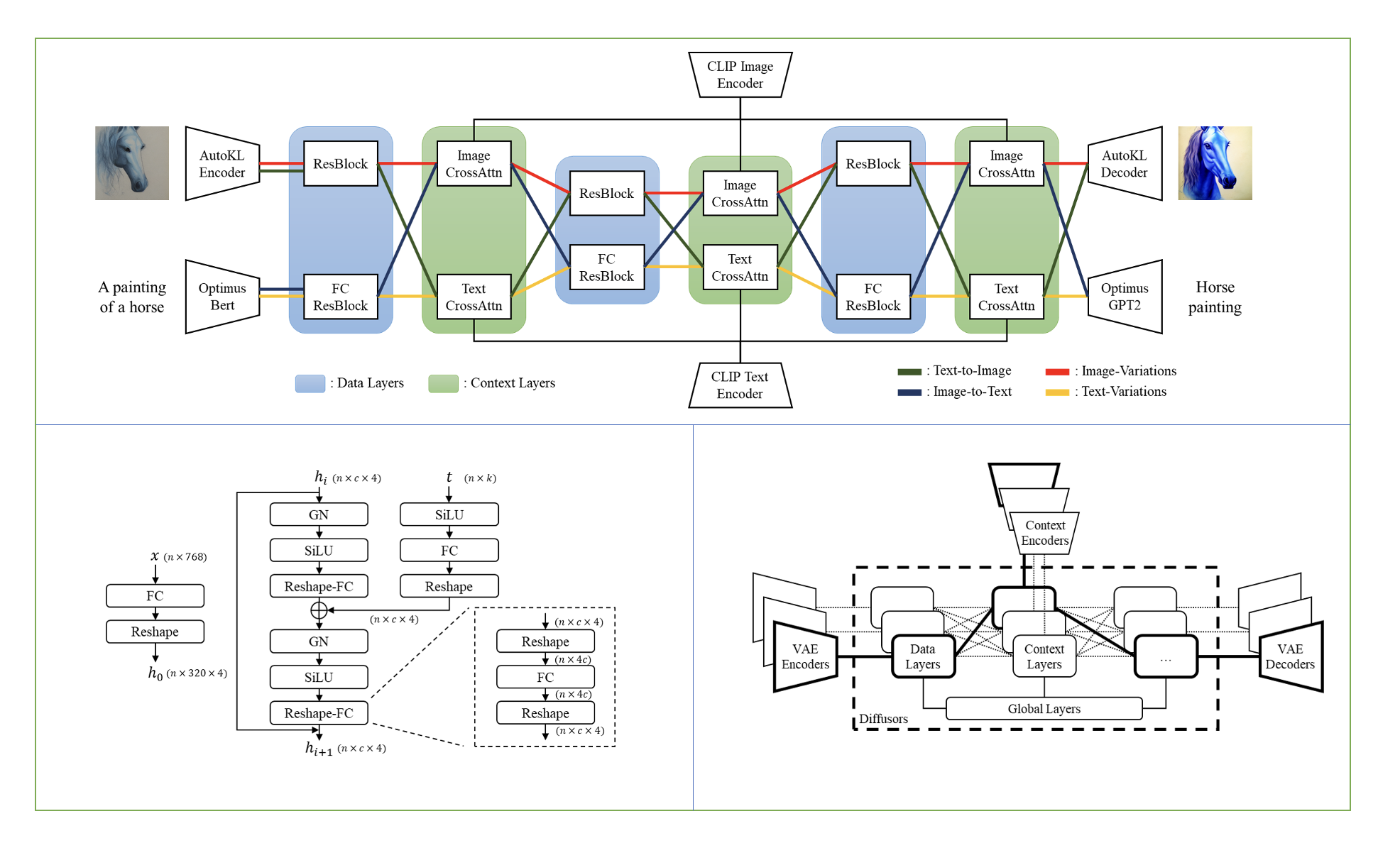
Versatile Diffusion (v1.0, four-flow)
We built Versatile Diffusion (VD), the first unified multi-flow multimodal diffusion framework, as a step towards Universal Generative AI. Versatile Diffusion can natively support image-to-text, image-variation, text-to-image, and text-variation, and can be further extended to other applications such as semantic-style disentanglement, image-text dual-guided generation, latent image-to-text-to-image editing, and more. Future versions will support more modalities such as speech, music, video and 3D.
Model Description
One single flow of Versatile Diffusion contains a VAE, a diffuser, and a context encoder, and thus handles one task (e.g., text-to-image) under one data type (e.g., image) and one context type (e.g., text). The multi-flow structure of Versatile Diffusion shows in the following diagram: