

新闻
[2024-05-14]
我们目前已经发布了模型权重、训练代码和技术报告,欢迎大家关注。
我们的训练代码放在了github上: https://github.com/hjq133/piccolo-embedding
对于训练细节,可以参考我们的技术报告: https://arxiv.org/abs/2405.06932
[2024-04-22]
piccolo-large-zh-v2 目前在C-MTEB榜单取得第一名,领先上一名BERT模型约1.9个点。
Piccolo-large-zh-v2
piccolo-large-zh-v2是商汤研究院通用模型组开发的中文嵌入模型。 Piccolo此次的升级版本旨在关注通用的下游微调方法。 Piccolo2主要通过利用高效的多任务混合损失训练方法,有效地利用来自不同下游的文本数据和标签。 此外,Piccolo2扩大了嵌入维度,同时使用MRL训练来支持更灵活的向量维度。
💡 模型亮点
piccolo2的主要特点是在训练过程中使用了多任务混合损失。
对于检retrieval/reranking任务,我们使用带有批内负样本的InfoNCE:
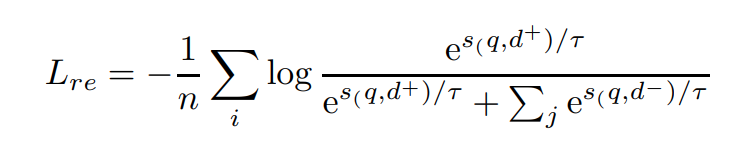
对于 sts/pair classification任务,我们使用排序损失:cosent loss。在具有细粒度标签的数据集上(比如有相似度的score),排序损失通常被证明表现更好:
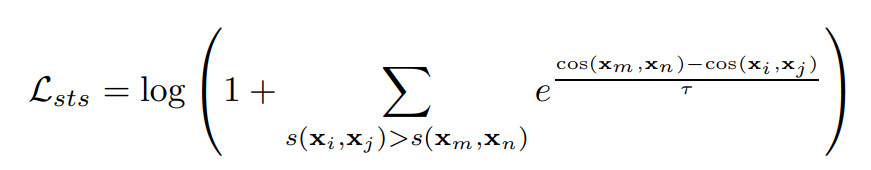
对于分类/聚类任务,我们通过将文本和其语义标签视为正负对,将数据集转换为三元组的格式来进行训练。我们同样采用InfoNCE对其进行优化。但这类任务不能再使用批内负样本,因为很容易导致训练目标的冲突:
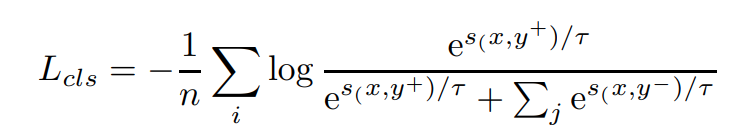
📃 实验和结果
Piccolo2主要关注在一种通用的下游微调范式。我们的开源模型使用了stella-v3.5作为初始化,在32张A100上训练了2500 step,对于更多的实现细节,可以参考我们的 技术报告, 以及训练代码
| Model Name | Model Size (GB) | Dimension | Sequence Length | Classification (9) | Clustering (4) | Pair Classification (2) | Reranking (4) | Retrieval (8) | STS (8) | Average (35) |
|---|---|---|---|---|---|---|---|---|---|---|
| piccolo-large-zh-v2 | 1.21 | 1792 | 512 | 74.59 | 62.17 | 90.24 | 70 | 74.36 | 63.5 | 70.95 |
| gte-Qwen1.5-7B-instruct | 26.45 | 32768 | 4096 | 73.35 | 67.08 | 88.52 | 66.38 | 70.62 | 62.32 | 69.56 |
| acge-text-embedding | 1.21 | 1792 | 512 | 72.75 | 58.7 | 87.84 | 67.98 | 72.93 | 62.09 | 69.07 |
🔨 使用方法
在sentence-transformer中使用piccolo:
# for s2s/s2p dataset, you can use piccolo as below
from sklearn.preprocessing import normalize
from sentence_transformers import SentenceTransformer
sentences = ["数据1", "数据2"]
matryoshka_dim=1792 # support 256, 512, 768, 1024, 1280, 1536, 1792
model = SentenceTransformer('sensenova/piccolo-large-zh-v2')
embeddings_1 = model.encode(sentences, normalize_embeddings=False)
embeddings_2 = model.encode(sentences, normalize_embeddings=False)
embeddings_1 = normalize(embeddings_1[..., :matryoshka_dim], norm="l2", axis=1)
embeddings_2 = normalize(embeddings_2[..., :matryoshka_dim], norm="l2", axis=1)
similarity = embeddings_1 @ embeddings_2.T
🤗 Model List
| Model | Language | Description | prompt |
|---|---|---|---|
| sensenova/piccolo-large-zh-v2 | Chinese | version2: finetuning with multi-task hybrid loss training | None |
| sensenova/piccolo-large-zh | Chinese | version1: pretrain under 400 million chinese text pair | '查询'/'结果' |
| sensenova/piccolo-base-zh | Chinese | version1: pretrain under 400 million chinese text pair | '查询'/'结果' |
Citation
如果我们的技术报告、模型或训练代码对您有帮助,请像下面这样引用我们的论文,或者在 github、 Huggingface 上给一个 Star!
@misc{2405.06932,
Author = {Junqin Huang and Zhongjie Hu and Zihao Jing and Mengya Gao and Yichao Wu},
Title = {Piccolo2: General Text Embedding with Multi-task Hybrid Loss Training},
Year = {2024},
Eprint = {arXiv:2405.06932},
}