

library_name: transformers
library: transformers
license: cc-by-nc-4.0
tags:
- depth
- relative depth
pipeline_tag: depth-estimation
widget:
- inference: false
Depth Anything V2 Base – Transformers Version
Depth Anything V2 is trained from 595K synthetic labeled images and 62M+ real unlabeled images, providing the most capable monocular depth estimation (MDE) model with the following features:
- more fine-grained details than Depth Anything V1
- more robust than Depth Anything V1 and SD-based models (e.g., Marigold, Geowizard)
- more efficient (10x faster) and more lightweight than SD-based models
- impressive fine-tuned performance with our pre-trained models
This model checkpoint is compatible with the transformers library.
Depth Anything V2 was introduced in the paper of the same name by Lihe Yang et al. It uses the same architecture as the original Depth Anything release, but uses synthetic data and a larger capacity teacher model to achieve much finer and robust depth predictions. The original Depth Anything model was introduced in the paper Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data by Lihe Yang et al., and was first released in this repository.
Model description
Depth Anything V2 leverages the DPT architecture with a DINOv2 backbone.
The model is trained on ~600K synthetic labeled images and ~62 million real unlabeled images, obtaining state-of-the-art results for both relative and absolute depth estimation.
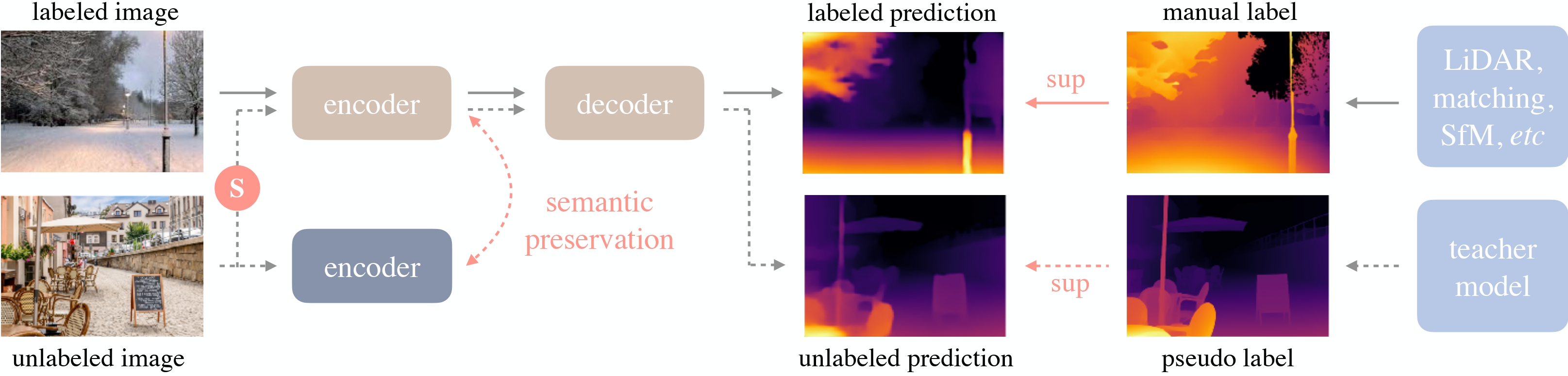
Depth Anything overview. Taken from the original paper.
Intended uses & limitations
You can use the raw model for tasks like zero-shot depth estimation. See the model hub to look for other versions on a task that interests you.
How to use
Here is how to use this model to perform zero-shot depth estimation:
from transformers import pipeline
from PIL import Image
import requests
# load pipe
pipe = pipeline(task="depth-estimation", model="depth-anything/Depth-Anything-V2-Large-hf")
# load image
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
# inference
depth = pipe(image)["depth"]
Alternatively, you can use the model and processor classes:
from transformers import AutoImageProcessor, AutoModelForDepthEstimation
import torch
import numpy as np
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image_processor = AutoImageProcessor.from_pretrained("depth-anything/Depth-Anything-V2-Large-hf")
model = AutoModelForDepthEstimation.from_pretrained("depth-anything/Depth-Anything-V2-Large-hf")
# prepare image for the model
inputs = image_processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
predicted_depth = outputs.predicted_depth
# interpolate to original size
prediction = torch.nn.functional.interpolate(
predicted_depth.unsqueeze(1),
size=image.size[::-1],
mode="bicubic",
align_corners=False,
)
For more code examples, please refer to the documentation.
Citation
@misc{yang2024depth,
title={Depth Anything V2},
author={Lihe Yang and Bingyi Kang and Zilong Huang and Zhen Zhao and Xiaogang Xu and Jiashi Feng and Hengshuang Zhao},
year={2024},
eprint={2406.09414},
archivePrefix={arXiv},
primaryClass={id='cs.CV' full_name='Computer Vision and Pattern Recognition' is_active=True alt_name=None in_archive='cs' is_general=False description='Covers image processing, computer vision, pattern recognition, and scene understanding. Roughly includes material in ACM Subject Classes I.2.10, I.4, and I.5.'}
}