

Commit
•
725aa53
1
Parent(s):
159ae46
Update README.md
Browse files
README.md
CHANGED
|
@@ -12,6 +12,11 @@ library_name: transformers
|
|
| 12 |
|
| 13 |
[Project Page](https://rlhf-v.github.io/) | [GitHub ](https://github.com/RLHF-V/RLHF-V) | [Demo](http://120.92.209.146:8081/) | [Paper](https://arxiv.org/abs/2312.00849)
|
| 14 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 15 |
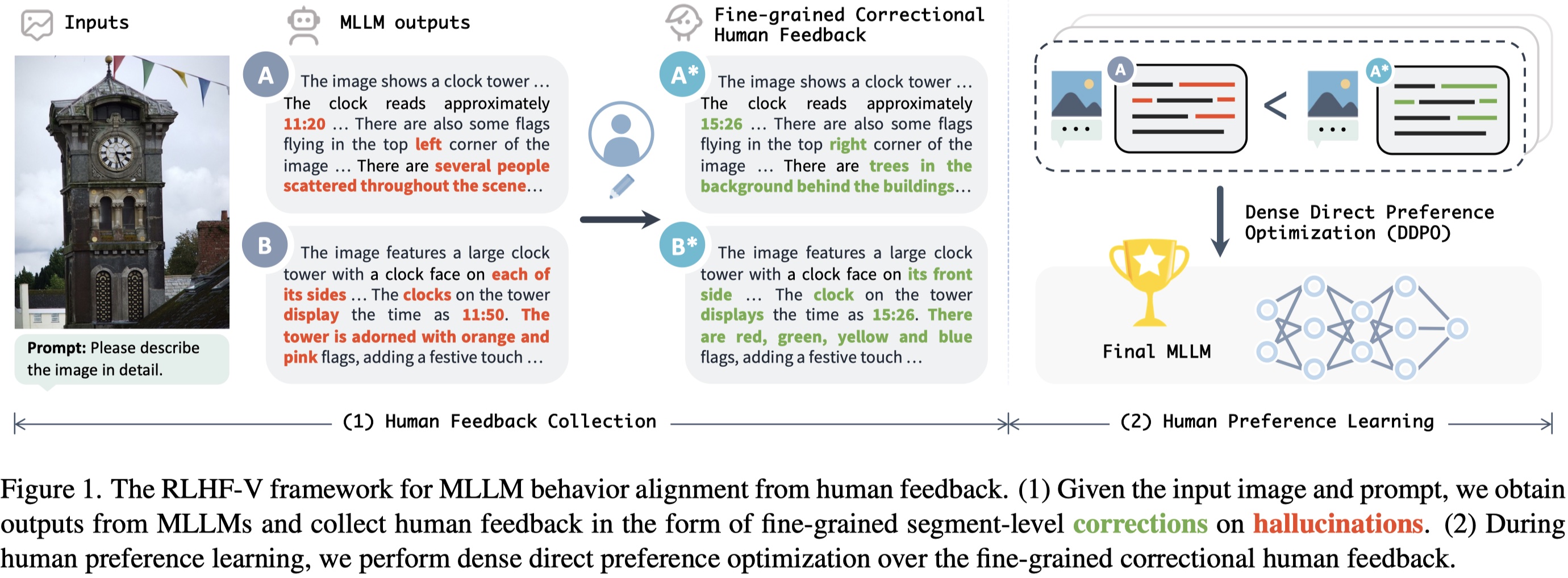
RLHF-V is an open-source multimodal large language model with the **lowest hallucination rate** on both long-form instructions and short-form questions.
|
| 16 |
|
| 17 |
RLHF-V is trained on [RLHF-V-Dataset](https://huggingface.co/datasets/HaoyeZhang/RLHF-V-Dataset), which contains **fine-grained segment-level human corrections** on diverse instructions. The base model is trained on [UniMM-Chat](https://huggingface.co/datasets/Yirany/UniMM-Chat), which is a high-quality knowledge-intensive SFT dataset. We introduce a new method **Dense Direct Preference Optimization (DDPO)** that can make better use of the fine-grained annotations.
|
|
@@ -20,10 +25,6 @@ For more details, please refer to our [paper](https://arxiv.org/abs/2312.00849).
|
|
| 20 |
|
| 21 |
|
| 22 |
|
| 23 |
-
## News
|
| 24 |
-
* [2024.05.20] 🎉 We introduce [RLAIF-V](https://github.com/RLHF-V/RLAIF-V), our new alignment framework that utilize open-source models for feedback generation and reach **super GPT-4V trustworthiness**. You can download the corresponding [🤗 dataset](https://huggingface.co/datasets/openbmb/RLAIF-V-Dataset) now!
|
| 25 |
-
* [2024.04.11] 🔥 Our data is used in [MiniCPM-V 2.0](https://huggingface.co/openbmb/MiniCPM-V-2), an **end-side** multimodal large language model that exhibits **comparable trustworthiness with GPT-4V**!
|
| 26 |
-
|
| 27 |
## Model Details
|
| 28 |
|
| 29 |
### Model Description
|
|
|
|
| 12 |
|
| 13 |
[Project Page](https://rlhf-v.github.io/) | [GitHub ](https://github.com/RLHF-V/RLHF-V) | [Demo](http://120.92.209.146:8081/) | [Paper](https://arxiv.org/abs/2312.00849)
|
| 14 |
|
| 15 |
+
## News
|
| 16 |
+
* [2024.05.20] 🎉 We introduce [RLAIF-V](https://github.com/RLHF-V/RLAIF-V), our new alignment framework that utilize open-source models for feedback generation and reach **super GPT-4V trustworthiness**. You can download the corresponding [🤗 dataset](https://huggingface.co/datasets/openbmb/RLAIF-V-Dataset) now!
|
| 17 |
+
* [2024.04.11] 🔥 Our data is used in [MiniCPM-V 2.0](https://huggingface.co/openbmb/MiniCPM-V-2), an **end-side** multimodal large language model that exhibits **comparable trustworthiness with GPT-4V**!
|
| 18 |
+
|
| 19 |
+
## Brief Introduction
|
| 20 |
RLHF-V is an open-source multimodal large language model with the **lowest hallucination rate** on both long-form instructions and short-form questions.
|
| 21 |
|
| 22 |
RLHF-V is trained on [RLHF-V-Dataset](https://huggingface.co/datasets/HaoyeZhang/RLHF-V-Dataset), which contains **fine-grained segment-level human corrections** on diverse instructions. The base model is trained on [UniMM-Chat](https://huggingface.co/datasets/Yirany/UniMM-Chat), which is a high-quality knowledge-intensive SFT dataset. We introduce a new method **Dense Direct Preference Optimization (DDPO)** that can make better use of the fine-grained annotations.
|
|
|
|
| 25 |
|
| 26 |

|
| 27 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 28 |
## Model Details
|
| 29 |
|
| 30 |
### Model Description
|