

license: mit
license_link: https://huggingface.co/nvidia/BigVGAN/blob/main/LICENSE
tags:
- neural-vocoder
- audio-generation
library_name: PyTorch
pipeline_tag: audio-to-audio
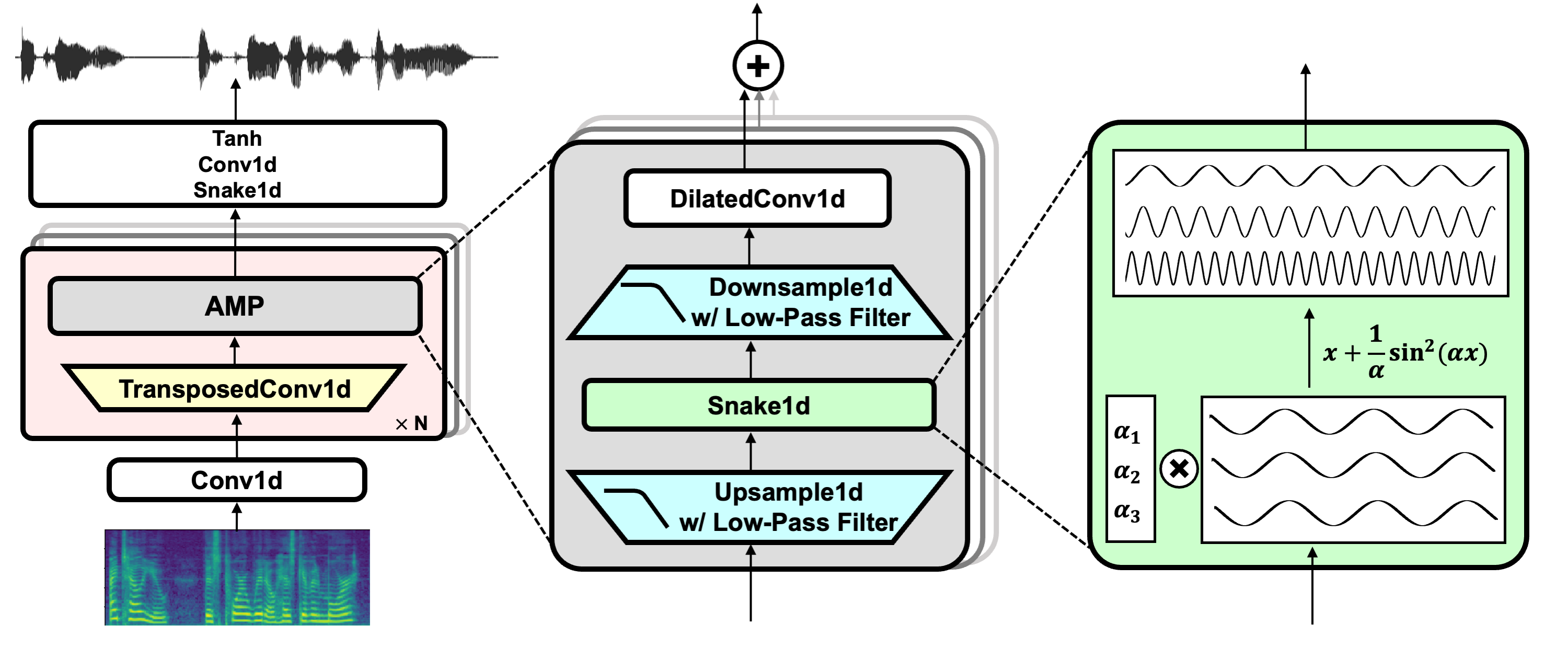
BigVGAN: A Universal Neural Vocoder with Large-Scale Training
Paper: https://arxiv.org/abs/2206.04658
Code: https://github.com/NVIDIA/BigVGAN
Project page: https://research.nvidia.com/labs/adlr/projects/bigvgan/
🤗 Spaces Demo: https://huggingface.co/spaces/nvidia/BigVGAN
News
[Jul 2024] We release BigVGAN-v2 along with pretrained checkpoints. Below are the highlights:
- Custom CUDA kernel for inference: we provide a fused upsampling + activation kernel written in CUDA for accelerated inference speed. Our test shows 1.5 - 3x faster speed on a single A100 GPU.
- Improved discriminator and loss: BigVGAN-v2 is trained using a multi-scale sub-band CQT discriminator and a multi-scale mel spectrogram loss.
- Larger training data: BigVGAN-v2 is trained using datasets containing diverse audio types, including speech in multiple languages, environmental sounds, and instruments.
- We provide pretrained checkpoints of BigVGAN-v2 using diverse audio configurations, supporting up to 44 kHz sampling rate and 512x upsampling ratio.
Installation
This repository contains pretrained BigVGAN checkpoints with easy access to inference and additional huggingface_hub support.
If you are interested in training the model and additional functionalities, please visit the official GitHub repository for more information: https://github.com/NVIDIA/BigVGAN
git lfs install
git clone https://huggingface.co/nvidia/bigvgan_v2_22khz_80band_256x
Usage
Below example describes how you can use load the pretrained BigVGAN generator, compute mel spectrogram from input waveform, and generate synthesized waveform using the mel spectrogram as the model's input.
device = 'cuda'
import torch
import bigvgan
# instantiate the model
model = bigvgan.BigVGAN.from_pretrained('nvidia/bigvgan_v2_22khz_80band_256x')
# remove weight norm in the model and set to eval mode
model.remove_weight_norm()
model = model.eval().to(device)
import librosa
from meldataset import get_mel_spectrogram
# load wav file and compute mel spectrogram
wav, sr = librosa.load('/path/to/your/audio.wav', sr=model.h.sampling_rate, mono=True) # wav is np.ndarray with shape [T_time] and values in [-1, 1]
wav = torch.FloatTensor(wav).to(device).unsqueeze(0) # wav is FloatTensor with shape [B(1), T_time]
# compute mel spectrogram from the ground truth audio
mel = get_mel_spectrogram(wav, model.h) # mel is FloatTensor with shape [B(1), C_mel, T_frame]
# generate waveform from mel
with torch.inference_mode():
wav_gen = model(mel) # wav_gen is FloatTensor with shape [B(1), 1, T_time] and values in [-1, 1]
wav_gen_float = wav_gen.squeeze(0).cpu() # wav_gen is FloatTensor with shape [1, T_time]
# you can convert the generated waveform to 16 bit linear PCM
wav_gen_int16 = (wav_gen_float * 32767.0).numpy().astype('int16') # wav_gen is now np.ndarray with int16 dtype
Using Custom CUDA Kernel for Synthesis
You can apply the fast CUDA inference kernel by using a parameter use_cuda_kernel when instantiating BigVGAN:
import bigvgan
model = bigvgan.BigVGAN.from_pretrained('nvidia/bigvgan_v2_22khz_80band_256x', use_cuda_kernel=True)
When applied for the first time, it builds the kernel using nvcc and ninja. If the build succeeds, the kernel is saved to alias_free_cuda/build and the model automatically loads the kernel. The codebase has been tested using CUDA 12.1.
Please make sure that both are installed in your system and nvcc installed in your system matches the version your PyTorch build is using.
For detail, see the official GitHub repository: https://github.com/NVIDIA/BigVGAN?tab=readme-ov-file#using-custom-cuda-kernel-for-synthesis
Pretrained Models
We provide the pretrained models.
One can download the checkpoints of the pretrained generator weight, named as bigvgan_generator.pt within the listed HuggingFace repositories.
| Model Name | Sampling Rate | Mel band | fmax | Upsampling Ratio | Params | Dataset | Fine-Tuned |
|---|---|---|---|---|---|---|---|
| bigvgan_v2_44khz_128band_512x | 44 kHz | 128 | 22050 | 512 | 122M | Large-scale Compilation | No |
| bigvgan_v2_44khz_128band_256x | 44 kHz | 128 | 22050 | 256 | 112M | Large-scale Compilation | No |
| bigvgan_v2_24khz_100band_256x | 24 kHz | 100 | 12000 | 256 | 112M | Large-scale Compilation | No |
| bigvgan_v2_22khz_80band_256x | 22 kHz | 80 | 11025 | 256 | 112M | Large-scale Compilation | No |
| bigvgan_v2_22khz_80band_fmax8k_256x | 22 kHz | 80 | 8000 | 256 | 112M | Large-scale Compilation | No |
| bigvgan_24khz_100band | 24 kHz | 100 | 12000 | 256 | 112M | LibriTTS | No |
| bigvgan_base_24khz_100band | 24 kHz | 100 | 12000 | 256 | 14M | LibriTTS | No |
| bigvgan_22khz_80band | 22 kHz | 80 | 8000 | 256 | 112M | LibriTTS + VCTK + LJSpeech | No |
| bigvgan_base_22khz_80band | 22 kHz | 80 | 8000 | 256 | 14M | LibriTTS + VCTK + LJSpeech | No |