

metadata
license: mit
datasets:
- numind/NuNER
library_name: gliner
language:
- en
pipeline_tag: token-classification
tags:
- entity recognition
- NER
- named entity recognition
- zero shot
- zero-shot
NuNerZero - is the family of Zero-Shot Entity Recognition models inspired by GLiNER and built with insights we gathered throughout our work on NuNER.
The key differences between NuNerZero Long in comparison to GLiNER are:
- The possibility to detect entities that are longer than 12 tokens, as NuZero Token operates on the token level rather than on the span level.
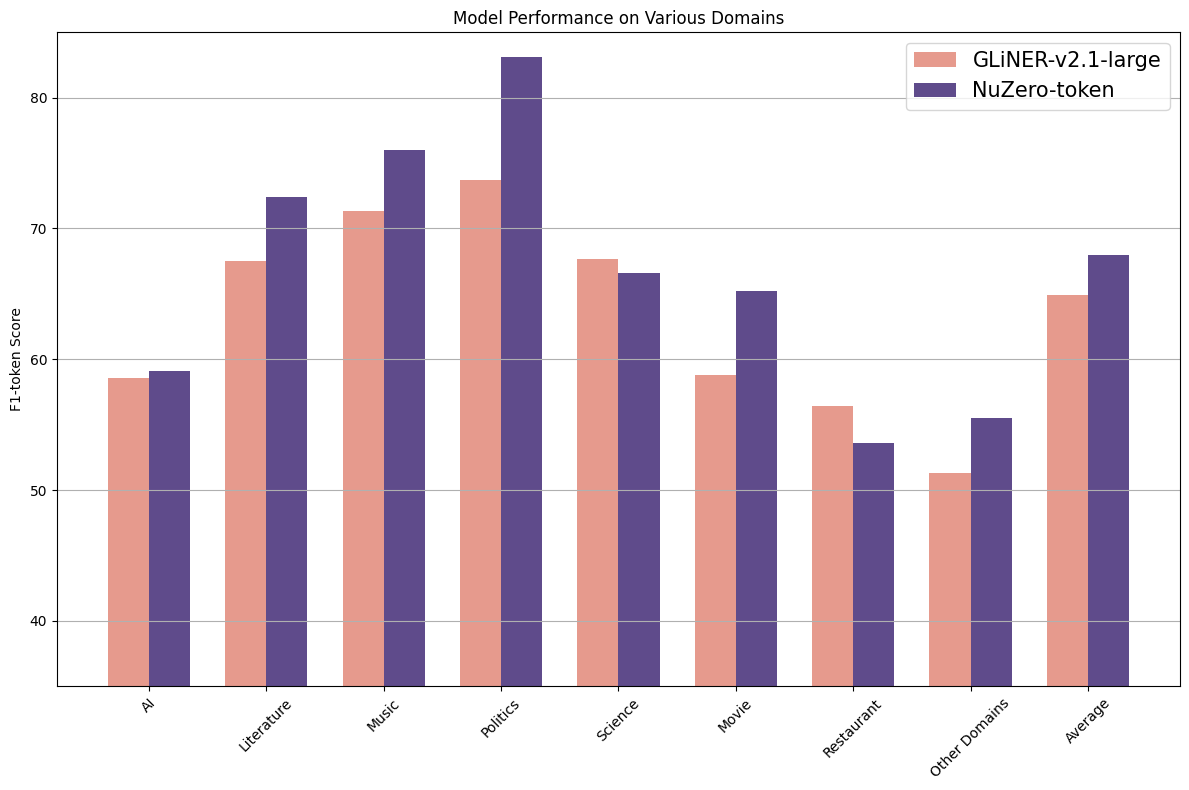
- a more powerful version of GLiNER-large-v2.1, surpassing it by +3.1% on average
- NuNerZero family is trained on the diverse dataset tailored for real-life use cases - NuNER v2.0 dataset
Installation & Usage
!pip install gliner
NuZero requires labels to be lower-cased
from gliner import GLiNER
model = GLiNER.from_pretrained("numind/NuNerZero")
# NuZero requires labels to be lower-cased!
labels = ["person", "award", "date", "competitions", "teams"]
labels [l.lower() for l in labels]
text = """
"""
entities = model.predict_entities(text, labels)
for entity in entities:
print(entity["text"], "=>", entity["label"])
Fine-tuning
A fine-tuning script can be found here.
Citation
This work
@misc{bogdanov2024nuner,
title={NuNER: Entity Recognition Encoder Pre-training via LLM-Annotated Data},
author={Sergei Bogdanov and Alexandre Constantin and Timothée Bernard and Benoit Crabbé and Etienne Bernard},
year={2024},
eprint={2402.15343},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Previous work
@misc{zaratiana2023gliner,
title={GLiNER: Generalist Model for Named Entity Recognition using Bidirectional Transformer},
author={Urchade Zaratiana and Nadi Tomeh and Pierre Holat and Thierry Charnois},
year={2023},
eprint={2311.08526},
archivePrefix={arXiv},
primaryClass={cs.CL}
}