
Create README.md
Browse files
README.md
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: llama2
|
| 3 |
+
library_name: transformers
|
| 4 |
+
---
|
| 5 |
+
|
| 6 |
+
# Bitnet-LLama-70M
|
| 7 |
+
|
| 8 |
+
Inspired from
|
| 9 |
+
Bitnet-LLama-70M is a 70M parameter model trained using the method described in [The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits](https://arxiv.org/abs/2402.17764).
|
| 10 |
+
|
| 11 |
+
It was trained on the subset of the [HuggingFaceTB/cosmopedia](https://huggingface.co/datasets/HuggingFaceTB/cosmopedia) dataset. This is just a small experiment to try out BitNet. Bitnet-LLama-70M was trained for 2 epochs on Colab T4.
|
| 12 |
+
|
| 13 |
+
This model is just an experiment and you might not get good results while chatting with it due to smaller model size and less training.
|
| 14 |
+
|
| 15 |
+
Wandb training report is as follows:
|
| 16 |
+
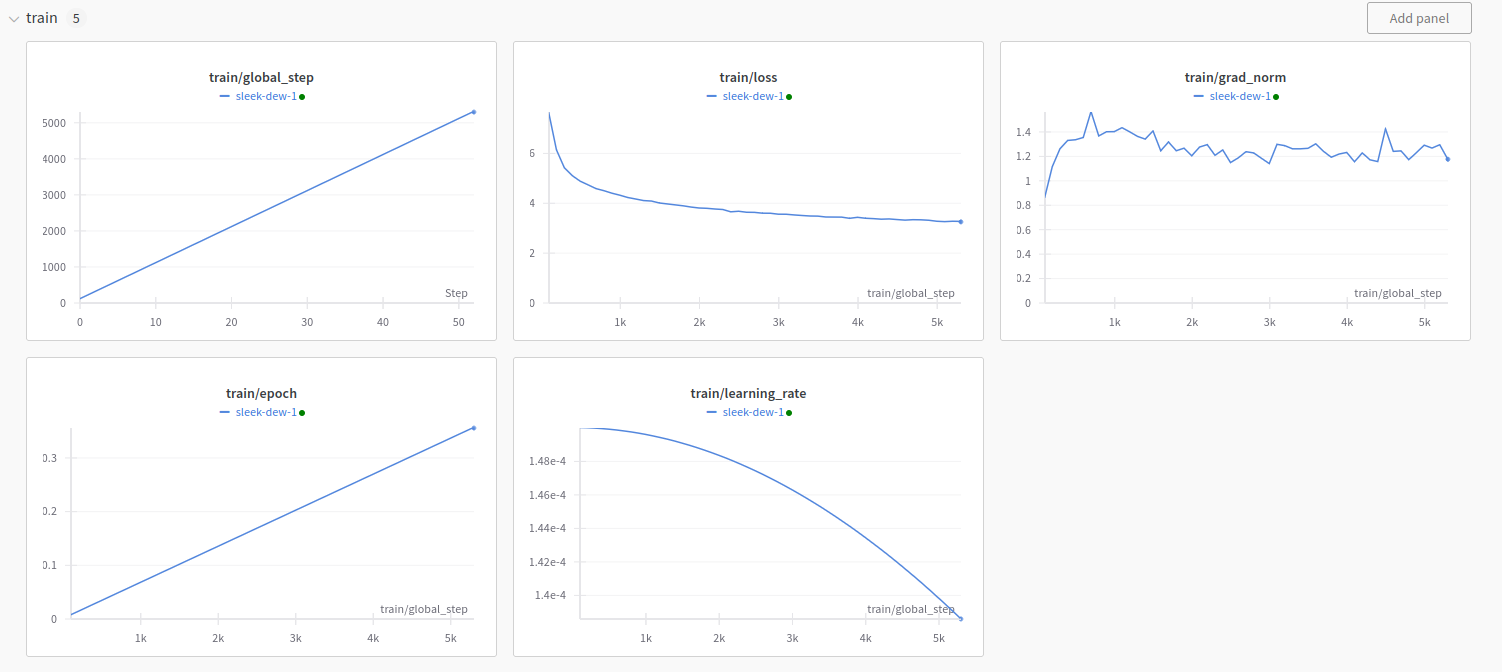
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
# Load a pretrained BitNet model
|
| 20 |
+
|
| 21 |
+
```python
|
| 22 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 23 |
+
from transformers.models.llama.modeling_llama import *
|
| 24 |
+
|
| 25 |
+
model = "nijil-k/Bitnet-1.58b-Nous-Llama2-70M"
|
| 26 |
+
tokenizer = AutoTokenizer.from_pretrained(model)
|
| 27 |
+
model = AutoModelForCausalLM.from_pretrained(model)
|
| 28 |
+
|
| 29 |
+
def convert_to_bitnet(model, copy_weights):
|
| 30 |
+
for name, module in model.named_modules():
|
| 31 |
+
# Replace linear layers with BitNet
|
| 32 |
+
if isinstance(module, LlamaSdpaAttention) or isinstance(module, LlamaMLP):
|
| 33 |
+
for child_name, child_module in module.named_children():
|
| 34 |
+
if isinstance(child_module, nn.Linear):
|
| 35 |
+
bitlinear = BitLinear(child_module.in_features, child_module.out_features, child_module.bias is not None).to(device="cuda:0")
|
| 36 |
+
if copy_weights:
|
| 37 |
+
bitlinear.weight = child_module.weight
|
| 38 |
+
if child_module.bias is not None:
|
| 39 |
+
bitlinear.bias = child_module.bias
|
| 40 |
+
setattr(module, child_name, bitlinear)
|
| 41 |
+
# Remove redundant input_layernorms
|
| 42 |
+
elif isinstance(module, LlamaDecoderLayer):
|
| 43 |
+
for child_name, child_module in module.named_children():
|
| 44 |
+
if isinstance(child_module, LlamaRMSNorm) and child_name == "input_layernorm":
|
| 45 |
+
setattr(module, child_name, nn.Identity().to(device="cuda:0"))
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
convert_to_bitnet(model, copy_weights=True)
|
| 49 |
+
model.to(device="cuda:0")
|
| 50 |
+
|
| 51 |
+
prompt = "What is Machine Learning?"
|
| 52 |
+
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
|
| 53 |
+
generate_ids = model.generate(inputs.input_ids, max_length=100)
|
| 54 |
+
tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
|
| 55 |
+
```
|