
Commit
•
0066775
1
Parent(s):
626af10
Upload folder using huggingface_hub
Browse files- .gitattributes +2 -0
- Llama-3-8B-Instruct-80K-QLoRA-Merged-Q4_K_M.gguf +3 -0
- Llama-3-8B-Instruct-80K-QLoRA-Merged-Q8_0.gguf +3 -0
- README.md +105 -3
- data/needle.png +0 -0
- data/needle.txt +0 -0
- data/topic.png +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
Llama-3-8B-Instruct-80K-QLoRA-Merged-Q4_K_M.gguf filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
Llama-3-8B-Instruct-80K-QLoRA-Merged-Q8_0.gguf filter=lfs diff=lfs merge=lfs -text
|
Llama-3-8B-Instruct-80K-QLoRA-Merged-Q4_K_M.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c88be4f922031df3d02d99566d612934e4b44a2a2adfcaf6633fc0f2a3c1e31e
|
| 3 |
+
size 4921247040
|
Llama-3-8B-Instruct-80K-QLoRA-Merged-Q8_0.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bb20ef2f6ab01b2ccfd33a56d45ade06d66e247266b99330636b08b4e181a52a
|
| 3 |
+
size 8541283648
|
README.md
CHANGED
|
@@ -1,3 +1,105 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: mit
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
pipeline_tag: text-generation
|
| 4 |
+
---
|
| 5 |
+
|
| 6 |
+
<div align="center">
|
| 7 |
+
<h1>Llama-3-8B-Instruct-80K-QLoRA-Merged</h1>
|
| 8 |
+
|
| 9 |
+
<a href="https://github.com/FlagOpen/FlagEmbedding/tree/master/Long_LLM/longllm_qlora">[Data&Code]</a>
|
| 10 |
+
</div>
|
| 11 |
+
|
| 12 |
+
We extend the context length of Llama-3-8B-Instruct to 80K using QLoRA and 3.5K long-context training data synthesized from GPT-4. The entire training cycle is super efficient, which takes 8 hours on a 8xA800 (80G) machine. Yet, the resulted model achieves remarkable performance on a series of downstream long-context evaluation benchmarks.
|
| 13 |
+
|
| 14 |
+
**NOTE**: This repo contains the quantized model of [namespace-Pt/Llama-3-8B-Instruct-80K-QLoRA-Merged](https://huggingface.co/namespace-Pt/Llama-3-8B-Instruct-80K-QLoRA-Merged). The quantization is conducted with [llama.cpp](https://github.com/ggerganov/llama.cpp) (Q4_K_M and Q8_0).
|
| 15 |
+
|
| 16 |
+
# Evaluation
|
| 17 |
+
|
| 18 |
+
All the following evaluation results are based on the [UNQUANTIZED MODEL](https://huggingface.co/namespace-Pt/Llama-3-8B-Instruct-80K-QLoRA-Merged). They can be reproduced following instructions [here](https://github.com/FlagOpen/FlagEmbedding/tree/master/Long_LLM/longllm_qlora).
|
| 19 |
+
|
| 20 |
+
**NOTE**: After quantization, you may observe quality degradation.
|
| 21 |
+
|
| 22 |
+
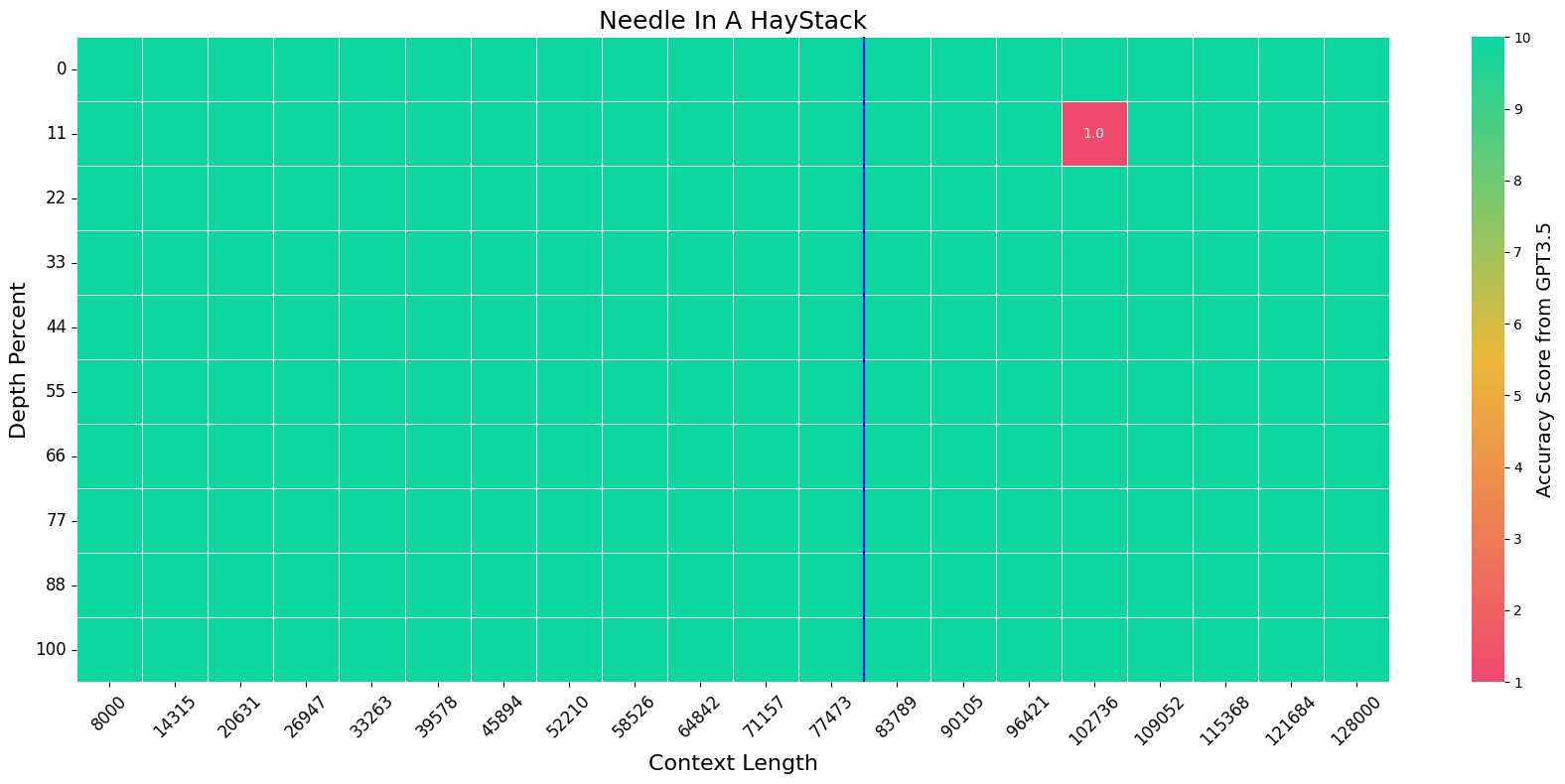
## Needle in a Haystack
|
| 23 |
+
We evaluate the model on the Needle-In-A-HayStack task using the official setting. The blue vertical line indicates the training context length, i.e. 80K.
|
| 24 |
+
|
| 25 |
+
<img src="data/needle.png"></img>
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
## LongBench
|
| 29 |
+
We evaluate the model on [LongBench](https://arxiv.org/abs/2308.14508) using 32K context length and the official prompt template. For [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct), we use 8K context length.
|
| 30 |
+
|
| 31 |
+
|Model|Single-Doc QA|Multi-Doc QA|Summarization|Few-Shot Learning|Synthetic|Code|Avg|
|
| 32 |
+
|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|
|
| 33 |
+
|[meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct)|37.33|36.04|26.83|**69.56**|37.75|53.24|43.20|
|
| 34 |
+
|[gradientai/Llama-3-8B-Instruct-262k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k)|37.29|31.20|26.18|67.25|44.25|**62.71**|43.73|
|
| 35 |
+
|Llama-3-8B-Instruct-80K-QLoRA-Merged|**43.57**|**43.07**|**28.93**|69.15|**48.50**|51.95|**47.19**|
|
| 36 |
+
|
| 37 |
+
## InfiniteBench
|
| 38 |
+
We evaluate the model on [InfiniteBench](https://arxiv.org/pdf/2402.13718.pdf) using 80K context length and the official prompt template. The results of GPT-4 is copied from the [paper](https://arxiv.org/pdf/2402.13718.pdf). For [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct), we use 8K context length.
|
| 39 |
+
|
| 40 |
+
|Model|LongBookQA Eng|LongBookSum Eng|
|
| 41 |
+
|:-:|:-:|:-:|
|
| 42 |
+
|GPT-4|22.22|14.73|
|
| 43 |
+
|[meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct)|7.00|**16.40**|
|
| 44 |
+
|[gradientai/Llama-3-8B-Instruct-262k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k)|20.30|10.34|
|
| 45 |
+
|Llama-3-8B-Instruct-80K-QLoRA-Merged|**30.92**|14.73|
|
| 46 |
+
|
| 47 |
+
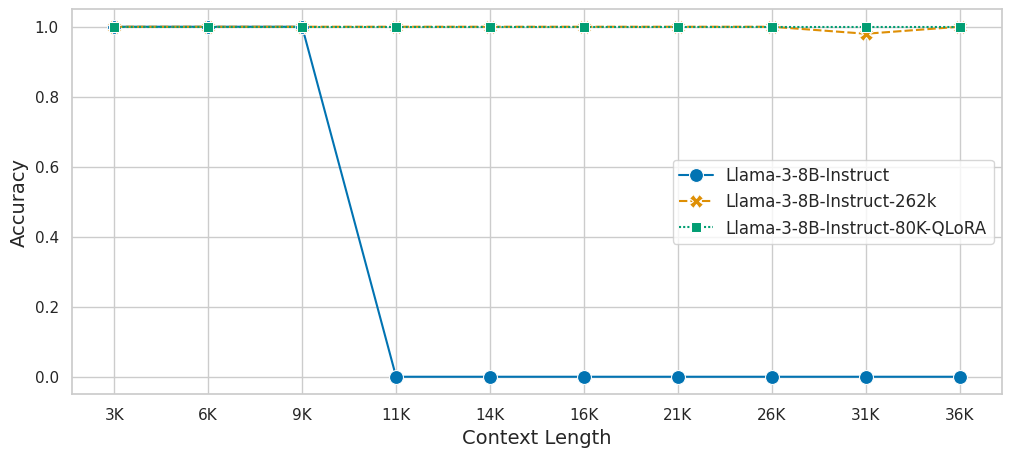
## Topic Retrieval
|
| 48 |
+
We evaluate the model on [Topic Retrieval](https://lmsys.org/blog/2023-06-29-longchat/) task with `[5,10,15,20,25,30,40,50,60,70]` topics.
|
| 49 |
+
|
| 50 |
+
<img src="data/topic.png"></img>
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
## MMLU
|
| 54 |
+
We evaluate the model's zero-shot performance on MMLU benchmark as a reflection of its short-context capability.
|
| 55 |
+
|
| 56 |
+
|Model|STEM|Social Sciences|Humanities|Others|Avg|
|
| 57 |
+
|:-:|:-:|:-:|:-:|:-:|:-:|
|
| 58 |
+
|[Llama-2-7B-Chat](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf)|35.92|54.37|51.74|51.42|47.22|
|
| 59 |
+
|[Mistral-7B-v0.2-Instruct](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)|48.79|69.95|64.99|61.64|60.10|
|
| 60 |
+
|[meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct)|**53.87**|**75.66**|**69.44**|69.75|**65.91**|
|
| 61 |
+
|[gradientai/Llama-3-8B-Instruct-262k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k)|52.10|73.26|67.15|**69.80**|64.34|
|
| 62 |
+
|Llama-3-8B-Instruct-80K-QLoRA-Merged|53.10|73.24|67.32|68.79|64.44|
|
| 63 |
+
|
| 64 |
+
# Environment
|
| 65 |
+
```bash
|
| 66 |
+
llama_cpp
|
| 67 |
+
torch==2.1.2
|
| 68 |
+
transformers==4.39.3
|
| 69 |
+
```
|
| 70 |
+
|
| 71 |
+
# Usage
|
| 72 |
+
```bash
|
| 73 |
+
huggingface-cli download namespace-Pt/Llama-3-8B-Instruct-80K-QLoRA-Merged-GGUF --local-dir . --local-dir-use-symlinks False
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
In python,
|
| 77 |
+
```python
|
| 78 |
+
from llama_cpp import Llama
|
| 79 |
+
|
| 80 |
+
llm = Llama(
|
| 81 |
+
model_path="./Llama-3-8B-Instruct-80K-QLoRA-Merged-Q4_K_M.gguf", # path to GGUF file
|
| 82 |
+
n_ctx=81920,
|
| 83 |
+
n_threads=96,
|
| 84 |
+
n_gpu_layers=32,
|
| 85 |
+
)
|
| 86 |
+
|
| 87 |
+
with open("./data/needle.txt") as f:
|
| 88 |
+
text = f.read()
|
| 89 |
+
inputs = f"{text}\n\nWhat is the best thing to do in San Francisco?"
|
| 90 |
+
|
| 91 |
+
print(
|
| 92 |
+
llm.create_chat_completion(
|
| 93 |
+
messages = [
|
| 94 |
+
{
|
| 95 |
+
"role": "user",
|
| 96 |
+
"content": inputs
|
| 97 |
+
}
|
| 98 |
+
],
|
| 99 |
+
temperature=0,
|
| 100 |
+
max_tokens=50
|
| 101 |
+
)
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
# The best thing to do in San Francisco is sitting in Helmer Dolores Park on a sunny day, eating a double cheeseburger with ketchup, and watching kids playing around.
|
| 105 |
+
```
|
data/needle.png
ADDED
|
data/needle.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/topic.png
ADDED
|