

Commit
•
736e538
1
Parent(s):
724d968
End of training
Browse files- README.md +5 -5
- all_results.json +8 -8
- eval_results.json +4 -4
- model-00001-of-00004.safetensors +1 -1
- model-00002-of-00004.safetensors +1 -1
- model-00003-of-00004.safetensors +1 -1
- model-00004-of-00004.safetensors +1 -1
- train_results.json +4 -4
- trainer_log.jsonl +3 -3
- trainer_state.json +13 -13
- training_args.bin +2 -2
- training_eval_loss.png +0 -0
README.md
CHANGED
|
@@ -18,7 +18,7 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 18 |
|
| 19 |
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B) on the PrincetonPLI/Instruct-SkillMix-SDD dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
-
- Loss:
|
| 22 |
|
| 23 |
## Model description
|
| 24 |
|
|
@@ -50,19 +50,19 @@ The following hyperparameters were used during training:
|
|
| 50 |
- lr_scheduler_type: constant
|
| 51 |
- lr_scheduler_warmup_ratio: 0.1
|
| 52 |
- lr_scheduler_warmup_steps: 1738
|
| 53 |
-
- num_epochs: 3
|
| 54 |
|
| 55 |
### Training results
|
| 56 |
|
| 57 |
| Training Loss | Epoch | Step | Validation Loss |
|
| 58 |
|:-------------:|:------:|:----:|:---------------:|
|
| 59 |
-
| No log | 0.5333 | 1 |
|
| 60 |
-
| No log | 1.6 | 3 |
|
| 61 |
|
| 62 |
|
| 63 |
### Framework versions
|
| 64 |
|
| 65 |
- Transformers 4.45.2
|
| 66 |
-
- Pytorch 2.
|
| 67 |
- Datasets 2.21.0
|
| 68 |
- Tokenizers 0.20.1
|
|
|
|
| 18 |
|
| 19 |
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B) on the PrincetonPLI/Instruct-SkillMix-SDD dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
+
- Loss: 1.7085
|
| 22 |
|
| 23 |
## Model description
|
| 24 |
|
|
|
|
| 50 |
- lr_scheduler_type: constant
|
| 51 |
- lr_scheduler_warmup_ratio: 0.1
|
| 52 |
- lr_scheduler_warmup_steps: 1738
|
| 53 |
+
- num_epochs: 3
|
| 54 |
|
| 55 |
### Training results
|
| 56 |
|
| 57 |
| Training Loss | Epoch | Step | Validation Loss |
|
| 58 |
|:-------------:|:------:|:----:|:---------------:|
|
| 59 |
+
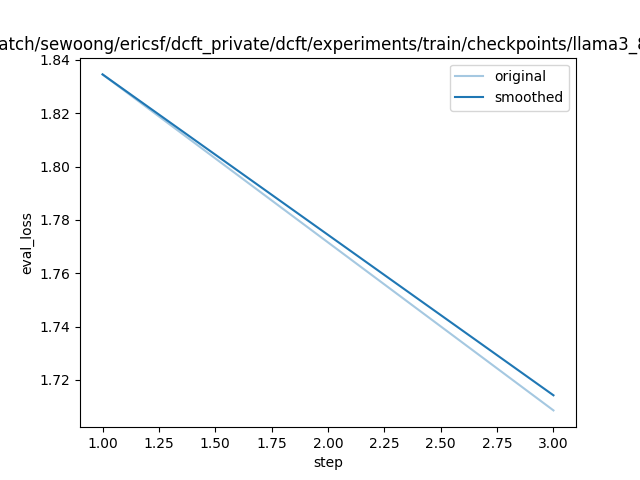
| No log | 0.5333 | 1 | 1.8346 |
|
| 60 |
+
| No log | 1.6 | 3 | 1.7085 |
|
| 61 |
|
| 62 |
|
| 63 |
### Framework versions
|
| 64 |
|
| 65 |
- Transformers 4.45.2
|
| 66 |
+
- Pytorch 2.4.0+cu121
|
| 67 |
- Datasets 2.21.0
|
| 68 |
- Tokenizers 0.20.1
|
all_results.json
CHANGED
|
@@ -1,12 +1,12 @@
|
|
| 1 |
{
|
| 2 |
"epoch": 1.6,
|
| 3 |
-
"eval_loss":
|
| 4 |
-
"eval_runtime":
|
| 5 |
-
"eval_samples_per_second":
|
| 6 |
-
"eval_steps_per_second": 0.
|
| 7 |
-
"total_flos":
|
| 8 |
-
"train_loss": 1.
|
| 9 |
-
"train_runtime":
|
| 10 |
-
"train_samples_per_second":
|
| 11 |
"train_steps_per_second": 0.002
|
| 12 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"epoch": 1.6,
|
| 3 |
+
"eval_loss": 1.7085474729537964,
|
| 4 |
+
"eval_runtime": 13.3752,
|
| 5 |
+
"eval_samples_per_second": 7.551,
|
| 6 |
+
"eval_steps_per_second": 0.299,
|
| 7 |
+
"total_flos": 1.9221024474136576e+16,
|
| 8 |
+
"train_loss": 1.8231021563212078,
|
| 9 |
+
"train_runtime": 1450.8496,
|
| 10 |
+
"train_samples_per_second": 3.968,
|
| 11 |
"train_steps_per_second": 0.002
|
| 12 |
}
|
eval_results.json
CHANGED
|
@@ -1,7 +1,7 @@
|
|
| 1 |
{
|
| 2 |
"epoch": 1.6,
|
| 3 |
-
"eval_loss":
|
| 4 |
-
"eval_runtime":
|
| 5 |
-
"eval_samples_per_second":
|
| 6 |
-
"eval_steps_per_second": 0.
|
| 7 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"epoch": 1.6,
|
| 3 |
+
"eval_loss": 1.7085474729537964,
|
| 4 |
+
"eval_runtime": 13.3752,
|
| 5 |
+
"eval_samples_per_second": 7.551,
|
| 6 |
+
"eval_steps_per_second": 0.299
|
| 7 |
}
|
model-00001-of-00004.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 4976698672
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:aa7ddf40a53c01580113b725a0016eec9561e858e589517f9d83205265478d6b
|
| 3 |
size 4976698672
|
model-00002-of-00004.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 4999802720
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d362d83c2e9ba973e98cca23893617dd1bf3577389c0af075b784abd7f877f9d
|
| 3 |
size 4999802720
|
model-00003-of-00004.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 4915916176
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:55b0d48a0edc756a4f62d053427ec9337fc67951899617d08adfc913344f0caa
|
| 3 |
size 4915916176
|
model-00004-of-00004.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 1168138808
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b229c76dc68a962cfcf861b4b833add51f486c85f418864f20b6ce72b2e7d061
|
| 3 |
size 1168138808
|
train_results.json
CHANGED
|
@@ -1,8 +1,8 @@
|
|
| 1 |
{
|
| 2 |
"epoch": 1.6,
|
| 3 |
-
"total_flos":
|
| 4 |
-
"train_loss": 1.
|
| 5 |
-
"train_runtime":
|
| 6 |
-
"train_samples_per_second":
|
| 7 |
"train_steps_per_second": 0.002
|
| 8 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"epoch": 1.6,
|
| 3 |
+
"total_flos": 1.9221024474136576e+16,
|
| 4 |
+
"train_loss": 1.8231021563212078,
|
| 5 |
+
"train_runtime": 1450.8496,
|
| 6 |
+
"train_samples_per_second": 3.968,
|
| 7 |
"train_steps_per_second": 0.002
|
| 8 |
}
|
trainer_log.jsonl
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
-
{"current_steps": 1, "total_steps": 3, "eval_loss":
|
| 2 |
-
{"current_steps": 3, "total_steps": 3, "eval_loss":
|
| 3 |
-
{"current_steps": 3, "total_steps": 3, "epoch": 1.6, "percentage": 100.0, "elapsed_time": "0:
|
|
|
|
| 1 |
+
{"current_steps": 1, "total_steps": 3, "eval_loss": 1.8345922231674194, "epoch": 0.5333333333333333, "percentage": 33.33, "elapsed_time": "0:14:04", "remaining_time": "0:28:08"}
|
| 2 |
+
{"current_steps": 3, "total_steps": 3, "eval_loss": 1.7085474729537964, "epoch": 1.6, "percentage": 100.0, "elapsed_time": "0:23:22", "remaining_time": "0:00:00"}
|
| 3 |
+
{"current_steps": 3, "total_steps": 3, "epoch": 1.6, "percentage": 100.0, "elapsed_time": "0:24:06", "remaining_time": "0:00:00"}
|
trainer_state.json
CHANGED
|
@@ -10,27 +10,27 @@
|
|
| 10 |
"log_history": [
|
| 11 |
{
|
| 12 |
"epoch": 0.5333333333333333,
|
| 13 |
-
"eval_loss":
|
| 14 |
-
"eval_runtime":
|
| 15 |
-
"eval_samples_per_second":
|
| 16 |
-
"eval_steps_per_second": 0.
|
| 17 |
"step": 1
|
| 18 |
},
|
| 19 |
{
|
| 20 |
"epoch": 1.6,
|
| 21 |
-
"eval_loss":
|
| 22 |
-
"eval_runtime":
|
| 23 |
-
"eval_samples_per_second":
|
| 24 |
-
"eval_steps_per_second": 0.
|
| 25 |
"step": 3
|
| 26 |
},
|
| 27 |
{
|
| 28 |
"epoch": 1.6,
|
| 29 |
"step": 3,
|
| 30 |
-
"total_flos":
|
| 31 |
-
"train_loss": 1.
|
| 32 |
-
"train_runtime":
|
| 33 |
-
"train_samples_per_second":
|
| 34 |
"train_steps_per_second": 0.002
|
| 35 |
}
|
| 36 |
],
|
|
@@ -51,7 +51,7 @@
|
|
| 51 |
"attributes": {}
|
| 52 |
}
|
| 53 |
},
|
| 54 |
-
"total_flos":
|
| 55 |
"train_batch_size": 4,
|
| 56 |
"trial_name": null,
|
| 57 |
"trial_params": null
|
|
|
|
| 10 |
"log_history": [
|
| 11 |
{
|
| 12 |
"epoch": 0.5333333333333333,
|
| 13 |
+
"eval_loss": 1.8345922231674194,
|
| 14 |
+
"eval_runtime": 13.5492,
|
| 15 |
+
"eval_samples_per_second": 7.454,
|
| 16 |
+
"eval_steps_per_second": 0.295,
|
| 17 |
"step": 1
|
| 18 |
},
|
| 19 |
{
|
| 20 |
"epoch": 1.6,
|
| 21 |
+
"eval_loss": 1.7085474729537964,
|
| 22 |
+
"eval_runtime": 13.4084,
|
| 23 |
+
"eval_samples_per_second": 7.533,
|
| 24 |
+
"eval_steps_per_second": 0.298,
|
| 25 |
"step": 3
|
| 26 |
},
|
| 27 |
{
|
| 28 |
"epoch": 1.6,
|
| 29 |
"step": 3,
|
| 30 |
+
"total_flos": 1.9221024474136576e+16,
|
| 31 |
+
"train_loss": 1.8231021563212078,
|
| 32 |
+
"train_runtime": 1450.8496,
|
| 33 |
+
"train_samples_per_second": 3.968,
|
| 34 |
"train_steps_per_second": 0.002
|
| 35 |
}
|
| 36 |
],
|
|
|
|
| 51 |
"attributes": {}
|
| 52 |
}
|
| 53 |
},
|
| 54 |
+
"total_flos": 1.9221024474136576e+16,
|
| 55 |
"train_batch_size": 4,
|
| 56 |
"trial_name": null,
|
| 57 |
"trial_params": null
|
training_args.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2b6bbd7933c9b40eb1823cb2c3687ea40b57253d5960d77ed2a4d8a1912f48c2
|
| 3 |
+
size 7288
|
training_eval_loss.png
CHANGED
|
|