
Commit
•
6200b11
1
Parent(s):
cefc640
Update README.md
Browse files
README.md
CHANGED
|
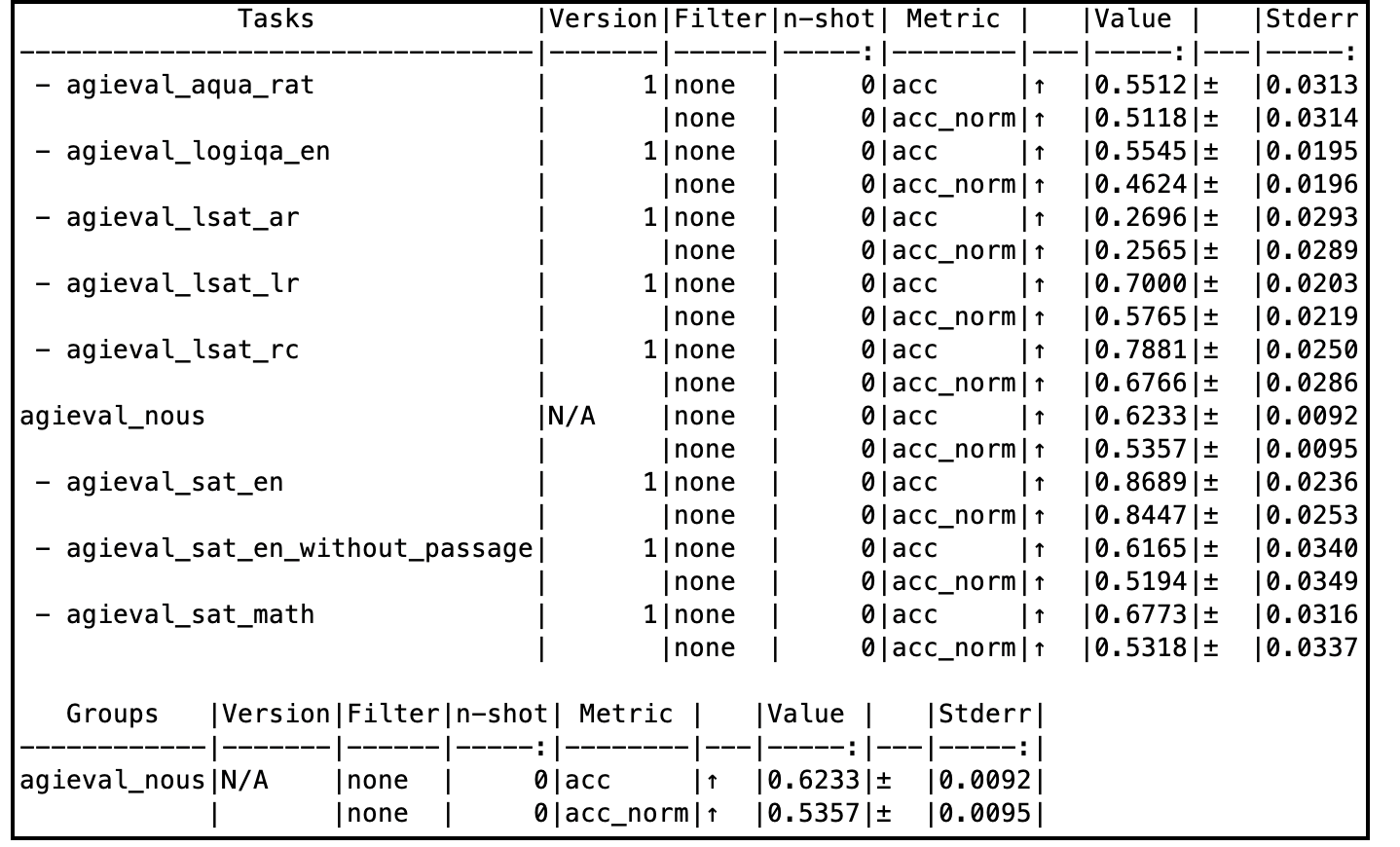
@@ -21,10 +21,13 @@ When evaluated on a subset of AGIEval (Nous), this model compares very well with
|
|
| 21 |
|
| 22 |
Tess-v2.5 model was initiated with the base weights of Qwen2-72B. It was then fine-tuned with the Tess-v2.5 dataset, using Axolotl as the training framework. Most of Tess models follow a common fine-tuning methodology: low learning rates, low number of epochs, and uses very high quality and diverse data. This model was fine-tuned on a 4xA100 VM on Microsoft Azure for 4 days. The model has not been aligned with RLHF or DPO.
|
| 23 |
|
| 24 |
-
The author believes that model's capabilities seem to come primariliy from the pre-training process. This is the foundation for every fine-tune of Tess models.
|
| 25 |
|
| 26 |
# Evaluation Results
|
| 27 |
|
|
|
|
|
|
|
|
|
|
| 28 |
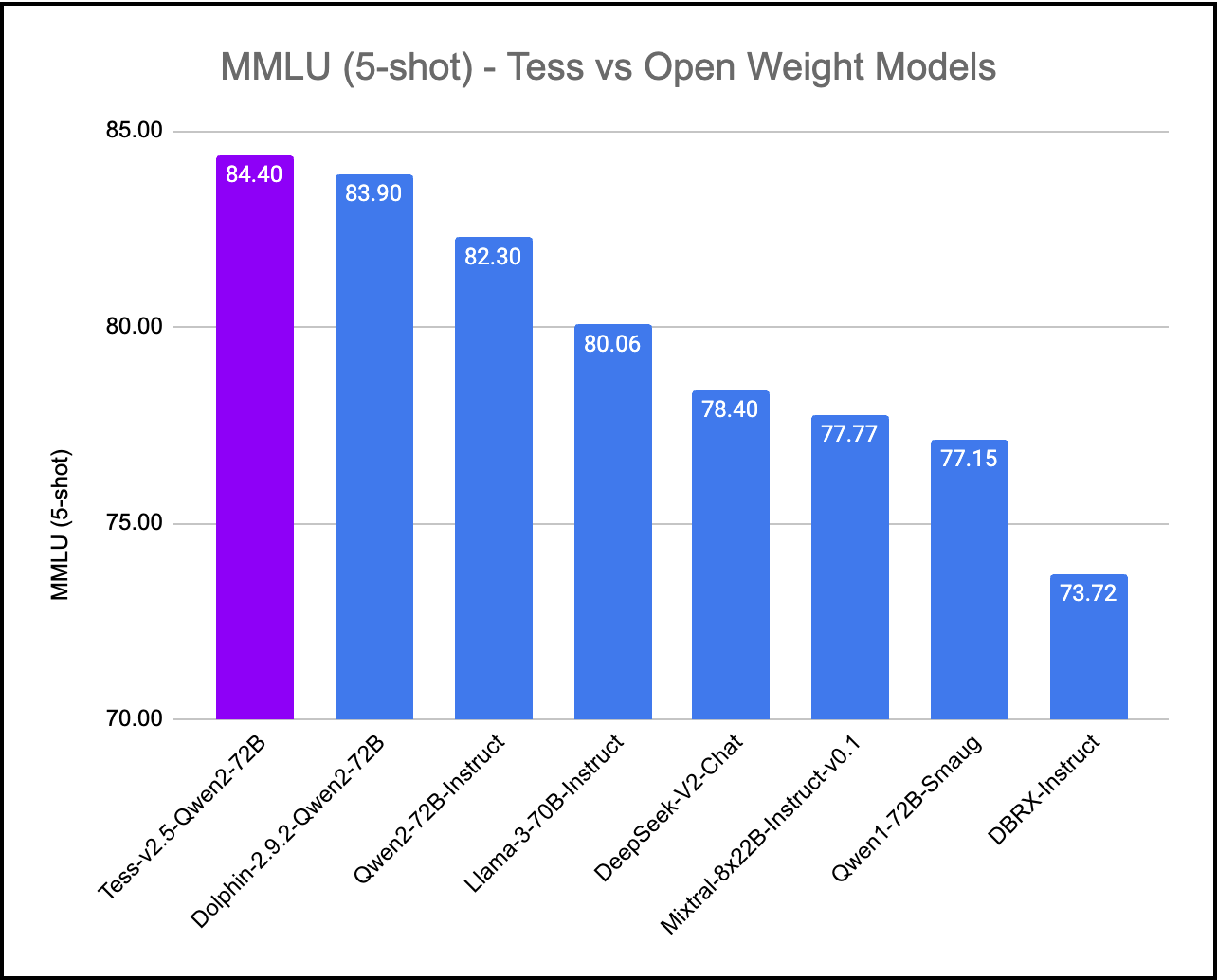
## MMLU (Massive Multitask Language Understanding)
|
| 29 |
|
| 30 |
|
|
@@ -34,5 +37,72 @@ The author believes that model's capabilities seem to come primariliy from the p
|
|
| 34 |
|
| 35 |
|
| 36 |
|
| 37 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 38 |
|
|
|
|
| 21 |
|
| 22 |
Tess-v2.5 model was initiated with the base weights of Qwen2-72B. It was then fine-tuned with the Tess-v2.5 dataset, using Axolotl as the training framework. Most of Tess models follow a common fine-tuning methodology: low learning rates, low number of epochs, and uses very high quality and diverse data. This model was fine-tuned on a 4xA100 VM on Microsoft Azure for 4 days. The model has not been aligned with RLHF or DPO.
|
| 23 |
|
| 24 |
+
The author believes that model's capabilities seem to come primariliy from the pre-training process. This is the foundation for every fine-tune of Tess models, and preserving the entropy of the base models is of paramount to the author.
|
| 25 |
|
| 26 |
# Evaluation Results
|
| 27 |
|
| 28 |
+
Tess-v2.5 model is an overall well balanced model. Complete evaluation tables can be accessed here: [Google Spreadsheet](https://docs.google.com/spreadsheets/d/1k0BIKux_DpuoTPwFCTMBzczw17kbpxofigHF_0w2LGw/edit?usp=sharing)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
## MMLU (Massive Multitask Language Understanding)
|
| 32 |

|
| 33 |
|
|
|
|
| 37 |

|
| 38 |
|
| 39 |
|
| 40 |
+
# Sample code to run inference
|
| 41 |
+
|
| 42 |
+
```python
|
| 43 |
+
import torch, json
|
| 44 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 45 |
+
from stop_word import StopWordCriteria
|
| 46 |
+
|
| 47 |
+
model_path = "migtissera/Tess-v2.5-Qwen2-72B"
|
| 48 |
+
output_file_path = "/home/migel/conversations.jsonl"
|
| 49 |
+
|
| 50 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 51 |
+
model_path,
|
| 52 |
+
torch_dtype=torch.float16,
|
| 53 |
+
device_map="auto",
|
| 54 |
+
load_in_4bit=False,
|
| 55 |
+
trust_remote_code=True,
|
| 56 |
+
)
|
| 57 |
+
|
| 58 |
+
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
|
| 59 |
+
|
| 60 |
+
terminators = [
|
| 61 |
+
tokenizer.convert_tokens_to_ids("<|im_end|>")
|
| 62 |
+
]
|
| 63 |
+
|
| 64 |
+
def generate_text(instruction):
|
| 65 |
+
tokens = tokenizer.encode(instruction)
|
| 66 |
+
tokens = torch.LongTensor(tokens).unsqueeze(0)
|
| 67 |
+
tokens = tokens.to("cuda")
|
| 68 |
+
|
| 69 |
+
instance = {
|
| 70 |
+
"input_ids": tokens,
|
| 71 |
+
"top_p": 1.0,
|
| 72 |
+
"temperature": 0.75,
|
| 73 |
+
"generate_len": 1024,
|
| 74 |
+
"top_k": 50,
|
| 75 |
+
}
|
| 76 |
+
|
| 77 |
+
length = len(tokens[0])
|
| 78 |
+
with torch.no_grad():
|
| 79 |
+
rest = model.generate(
|
| 80 |
+
input_ids=tokens,
|
| 81 |
+
max_length=length + instance["generate_len"],
|
| 82 |
+
use_cache=True,
|
| 83 |
+
do_sample=True,
|
| 84 |
+
top_p=instance["top_p"],
|
| 85 |
+
temperature=instance["temperature"],
|
| 86 |
+
top_k=instance["top_k"],
|
| 87 |
+
num_return_sequences=1,
|
| 88 |
+
pad_token_id=tokenizer.eos_token_id,
|
| 89 |
+
eos_token_id=terminators,
|
| 90 |
+
)
|
| 91 |
+
output = rest[0][length:]
|
| 92 |
+
string = tokenizer.decode(output, skip_special_tokens=True)
|
| 93 |
+
return f"{string}"
|
| 94 |
+
|
| 95 |
+
conversation = f"""<|im_start|>system\nYou are Tesoro, a helful AI assitant. You always provide detailed answers without hesitation.<|im_end|>\n<|im_start|>user\n"""
|
| 96 |
+
|
| 97 |
+
while True:
|
| 98 |
+
user_input = input("You: ")
|
| 99 |
+
llm_prompt = f"{conversation}{user_input}<|im_end|>\n<|im_start|>assistant\n"
|
| 100 |
+
answer = generate_text(llm_prompt)
|
| 101 |
+
print(answer)
|
| 102 |
+
conversation = f"{llm_prompt}{answer}\n"
|
| 103 |
+
json_data = {"prompt": user_input, "answer": answer}
|
| 104 |
+
|
| 105 |
+
with open(output_file_path, "a") as output_file:
|
| 106 |
+
output_file.write(json.dumps(json_data) + "\n")
|
| 107 |
+
```
|
| 108 |
|