
Commit
•
5f94720
1
Parent(s):
b86bf2c
Update README.md
Browse files
README.md
CHANGED
|
@@ -13,9 +13,17 @@ We've created Tess-v2.5, the latest state-of-the-art model in the Tess series of
|
|
| 13 |
|
| 14 |
Tess-v2.5 (Qwen2-72B) was fine-tuned over the newly released Qwen2-72B base, using the Tess-v2.5 dataset that contain 300K samples spanning multiple topics, including business and management, marketing, history, social sciences, arts, STEM subjects and computer programming. This dataset was synthetically generated using the [Sensei](https://github.com/migtissera/Sensei) framework, using multiple frontier models such as GPT-4-Turbo, Claude-Opus and Mistral-Large.
|
| 15 |
|
| 16 |
-
The compute for this model was generously sponsored by [KindoAI](kindo.ai).
|
| 17 |
|
| 18 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 19 |
|
| 20 |
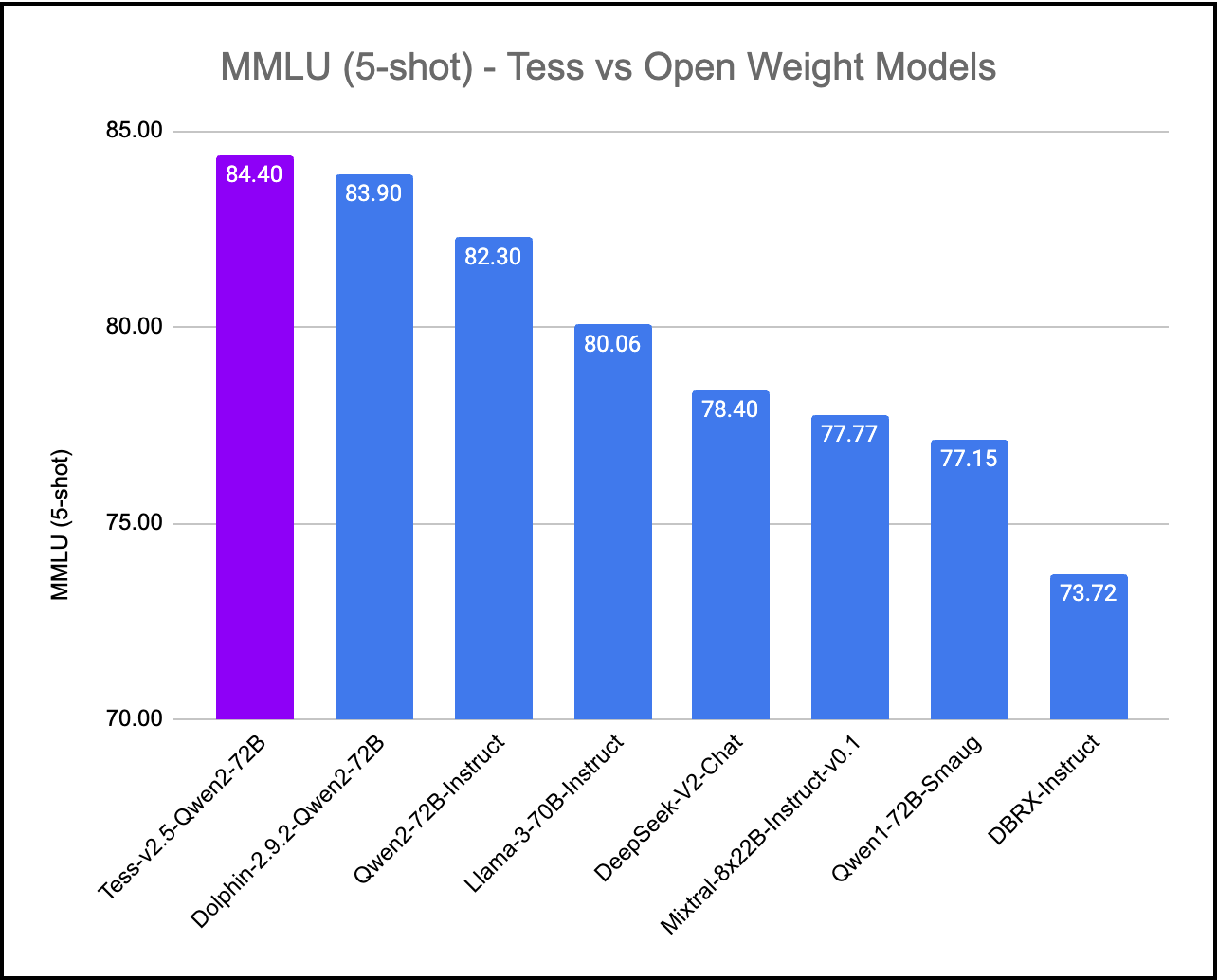
## MMLU (Massive Multitask Language Understanding)
|
| 21 |
|
|
|
|
| 13 |
|
| 14 |
Tess-v2.5 (Qwen2-72B) was fine-tuned over the newly released Qwen2-72B base, using the Tess-v2.5 dataset that contain 300K samples spanning multiple topics, including business and management, marketing, history, social sciences, arts, STEM subjects and computer programming. This dataset was synthetically generated using the [Sensei](https://github.com/migtissera/Sensei) framework, using multiple frontier models such as GPT-4-Turbo, Claude-Opus and Mistral-Large.
|
| 15 |
|
| 16 |
+
The compute for this model was generously sponsored by [KindoAI](https://kindo.ai).
|
| 17 |
|
| 18 |
+
When evaluated on a subset of AGIEval (Nous), this model compares very well with the godfather GPT-4-0314 model as well.
|
| 19 |
+
|
| 20 |
+
# Training Process
|
| 21 |
+
|
| 22 |
+
Tess-v2.5 model was initiated with the base weights of Qwen2-72B. Then it was fine-tuned with the Tess-v2.5 dataset, using Axolotl as the training framework. Most of Tess models follow a common fine-tuning methodology: low learning rates, low number of epochs, and uses very high quality and diverse data. This model was fine-tuned on a 4xA100 VM on Microsoft Azure for 4 days. The model has not been aligned with RLHF or DPO.
|
| 23 |
+
|
| 24 |
+
The author believes that model's capabilities seem to come primariliy from the pre-training process. This is the foundation for every fine-tune of Tess models.
|
| 25 |
+
|
| 26 |
+
# Evaluation Results
|
| 27 |
|
| 28 |
## MMLU (Massive Multitask Language Understanding)
|
| 29 |

|