
| ## Efficient Grounded-SAM | |
| We're going to combine [Grounding-DINO](https://github.com/IDEA-Research/GroundingDINO) with efficient SAM variants for faster annotating. | |
| <!-- Combining [Grounding-DINO](https://github.com/IDEA-Research/GroundingDINO) and [Fast-SAM](https://github.com/CASIA-IVA-Lab/FastSAM) for faster zero-shot detect and segment anything. --> | |
| ### Table of Contents | |
| - [Installation](#installation) | |
| - [Efficient SAM Series](#efficient-sams) | |
| - [Run Grounded-FastSAM Demo](#run-grounded-fastsam-demo) | |
| - [Run Grounded-MobileSAM Demo](#run-grounded-mobilesam-demo) | |
| - [Run Grounded-LightHQSAM Demo](#run-grounded-light-hqsam-demo) | |
| - [Run Grounded-Efficient-SAM Demo](#run-grounded-efficient-sam-demo) | |
| - [Run Grounded-Edge-SAM Demo](#run-grounded-edge-sam-demo) | |
| - [Run Grounded-RepViT-SAM Demo](#run-grounded-repvit-sam-demo) | |
| ### Installation | |
| - Install [Grounded-SAM](https://github.com/IDEA-Research/Grounded-Segment-Anything#installation) | |
| - Install [Fast-SAM](https://github.com/CASIA-IVA-Lab/FastSAM#installation) | |
| - Note that we may use the sam image as the demo image in order to compare the inference results of different efficient-sam variants. | |
| ### Efficient SAMs | |
| Here's the list of Efficient SAM variants: | |
| <div align="center"> | |
| | Title | Intro | Description | Links | | |
| |:----:|:----:|:----:|:----:| | |
| | [FastSAM](https://arxiv.org/pdf/2306.12156.pdf) |  | The Fast Segment Anything Model(FastSAM) is a CNN Segment Anything Model trained by only 2% of the SA-1B dataset published by SAM authors. The FastSAM achieve a comparable performance with the SAM method at 50× higher run-time speed. | [[Github](https://github.com/CASIA-IVA-Lab/FastSAM)] [[Demo](https://huggingface.co/spaces/An-619/FastSAM)] | | |
| | [MobileSAM](https://arxiv.org/pdf/2306.14289.pdf) |  | MobileSAM performs on par with the original SAM (at least visually) and keeps exactly the same pipeline as the original SAM except for a change on the image encoder. Specifically, we replace the original heavyweight ViT-H encoder (632M) with a much smaller Tiny-ViT (5M). On a single GPU, MobileSAM runs around 12ms per image: 8ms on the image encoder and 4ms on the mask decoder. | [[Github](https://github.com/ChaoningZhang/MobileSAM)] | | |
| | [Light-HQSAM](https://arxiv.org/pdf/2306.01567.pdf) | 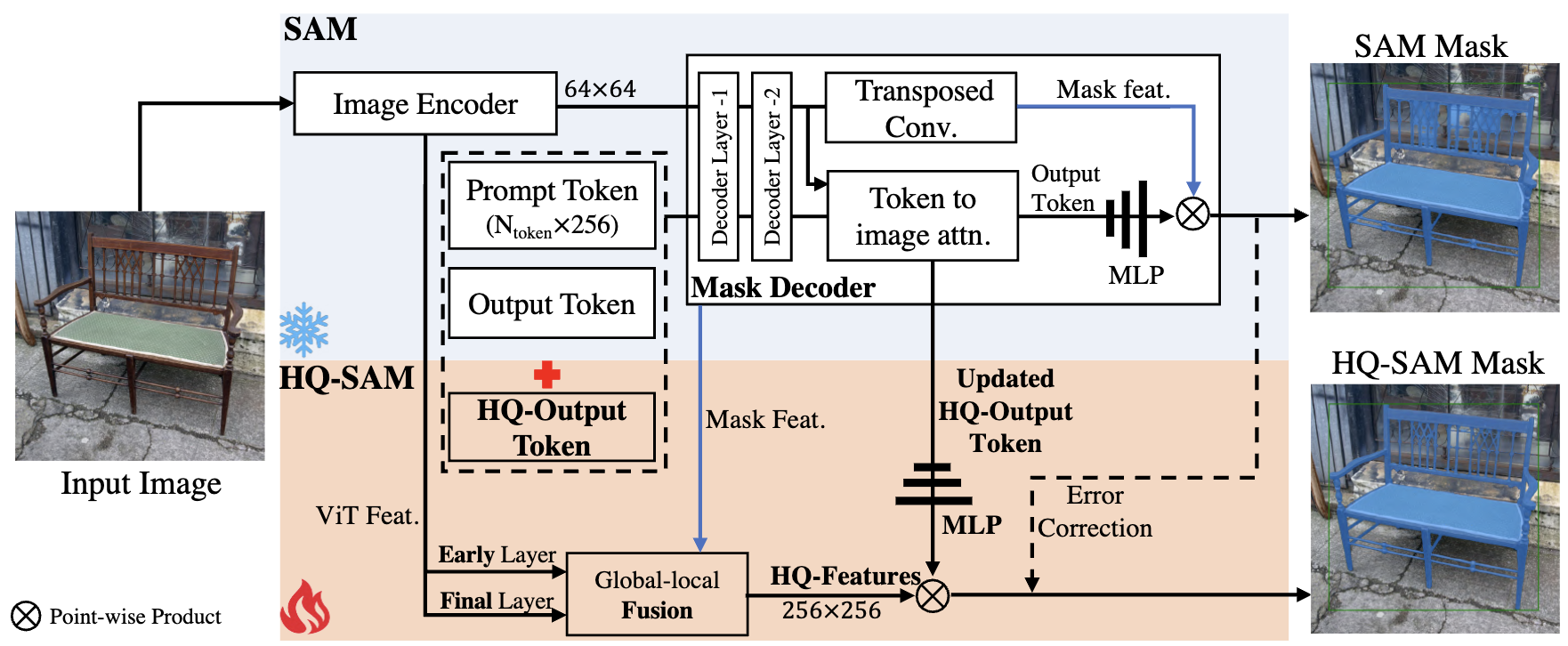 | Light HQ-SAM is based on the tiny vit image encoder provided by MobileSAM. We design a learnable High-Quality Output Token, which is injected into SAM's mask decoder and is responsible for predicting the high-quality mask. Instead of only applying it on mask-decoder features, we first fuse them with ViT features for improved mask details. Refer to [Light HQ-SAM vs. MobileSAM](https://github.com/SysCV/sam-hq#light-hq-sam-vs-mobilesam-on-coco) for more details. | [[Github](https://github.com/SysCV/sam-hq)] | | |
| | [Efficient-SAM](https://github.com/yformer/EfficientSAM) | 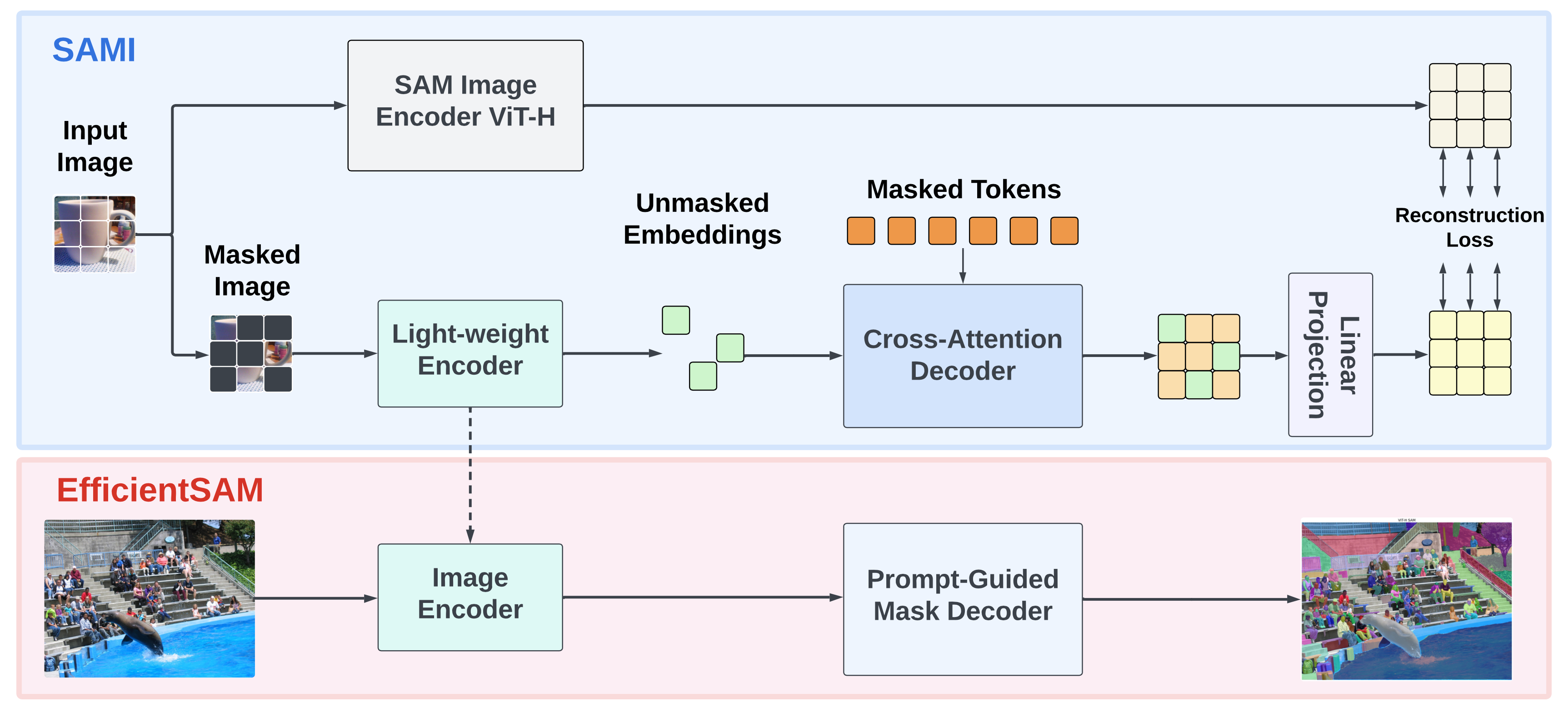 |Segment Anything Model (SAM) has emerged as a powerful tool for numerous vision applications. However, the huge computation cost of SAM model has limited its applications to wider real-world applications. To address this limitation, we propose EfficientSAMs, light-weight SAM models that exhibit decent performance with largely reduced complexity. Our idea is based on leveraging masked image pretraining, SAMI, which learns to reconstruct features from SAM image encoder for effective visual representation learning. Further, we take SAMI-pretrained light-weight image encoders and mask decoder to build EfficientSAMs, and finetune the models on SA-1B for segment anything task. Refer to [EfficientSAM arXiv](https://arxiv.org/pdf/2312.00863.pdf) for more details.| [[Github](https://github.com/yformer/EfficientSAM)] | | |
| | [Edge-SAM](https://github.com/chongzhou96/EdgeSAM) | 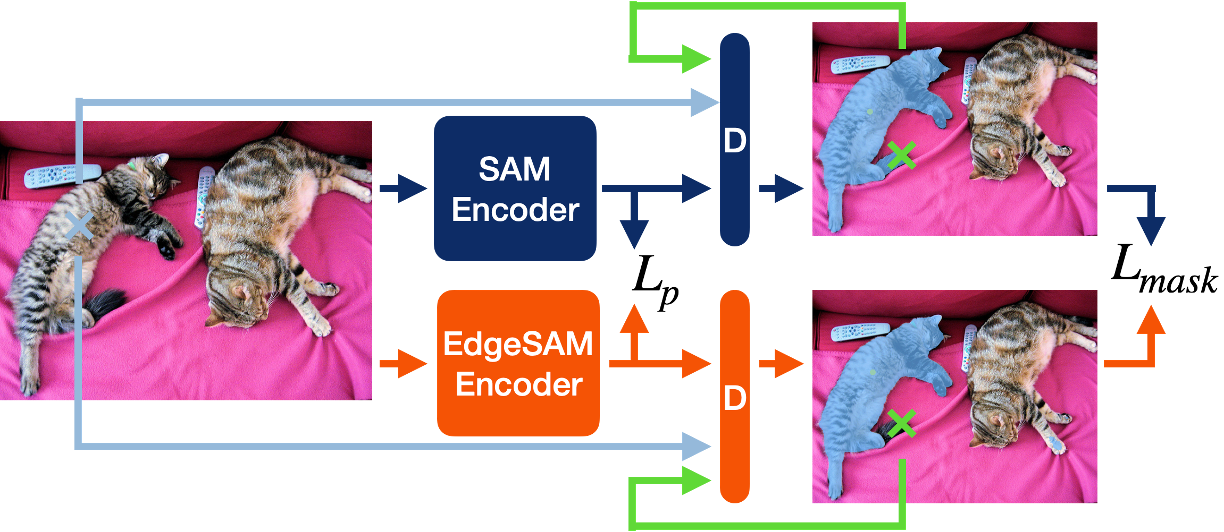 | EdgeSAM involves distilling the original ViT-based SAM image encoder into a purely CNN-based architecture, better suited for edge devices. We carefully benchmark various distillation strategies and demonstrate that task-agnostic encoder distillation fails to capture the full knowledge embodied in SAM. Refer to [Edge-SAM arXiv](https://arxiv.org/abs/2312.06660) for more details. | [[Github](https://github.com/chongzhou96/EdgeSAM)] | | |
| | [RepViT-SAM](https://github.com/THU-MIG/RepViT/tree/main/sam) |  | Recently, RepViT achieves the state-of-the-art performance and latency trade-off on mobile devices by incorporating efficient architectural designs of ViTs into CNNs. Here, to achieve real-time segmenting anything on mobile devices, following MobileSAM, we replace the heavyweight image encoder in SAM with RepViT model, ending up with the RepViT-SAM model. Extensive experiments show that RepViT-SAM can enjoy significantly better zero-shot transfer capability than MobileSAM, along with nearly 10× faster inference speed. Refer to [RepViT-SAM arXiv](https://arxiv.org/pdf/2312.05760.pdf) for more details. | [[Github](https://github.com/THU-MIG/RepViT)] | | |
| </div> | |
| ### Run Grounded-FastSAM Demo | |
| - Firstly, download the pretrained Fast-SAM weight [here](https://github.com/CASIA-IVA-Lab/FastSAM#model-checkpoints) | |
| - Run the demo with the following script: | |
| ```bash | |
| cd Grounded-Segment-Anything | |
| python EfficientSAM/grounded_fast_sam.py --model_path "./FastSAM-x.pt" --img_path "assets/demo4.jpg" --text "the black dog." --output "./output/" | |
| ``` | |
| - And the results will be saved in `./output/` as: | |
| <div style="text-align: center"> | |
| | Input | Text | Output | | |
| |:---:|:---:|:---:| | |
| | | "The black dog." |  | | |
| </div> | |
| **Note**: Due to the post process of FastSAM, only one box can be annotated at a time, if there're multiple box prompts, we simply save multiple annotate images to `./output` now, which will be modified in the future release. | |
| ### Run Grounded-MobileSAM Demo | |
| - Firstly, download the pretrained MobileSAM weight [here](https://github.com/ChaoningZhang/MobileSAM/tree/master/weights) | |
| - Run the demo with the following script: | |
| ```bash | |
| cd Grounded-Segment-Anything | |
| python EfficientSAM/grounded_mobile_sam.py --MOBILE_SAM_CHECKPOINT_PATH "./EfficientSAM/mobile_sam.pt" --SOURCE_IMAGE_PATH "./assets/demo2.jpg" --CAPTION "the running dog" | |
| ``` | |
| - And the result will be saved as `./gronded_mobile_sam_anontated_image.jpg` as: | |
| <div style="text-align: center"> | |
| | Input | Text | Output | | |
| |:---:|:---:|:---:| | |
| | | "the running dog" |  | | |
| </div> | |
| ### Run Grounded-Light-HQSAM Demo | |
| - Firstly, download the pretrained Light-HQSAM weight [here](https://github.com/SysCV/sam-hq#model-checkpoints) | |
| - Run the demo with the following script: | |
| ```bash | |
| cd Grounded-Segment-Anything | |
| python EfficientSAM/grounded_light_hqsam.py | |
| ``` | |
| - And the result will be saved as `./gronded_light_hqsam_anontated_image.jpg` as: | |
| <div style="text-align: center"> | |
| | Input | Text | Output | | |
| |:---:|:---:|:---:| | |
| | | "bench" |  | | |
| </div> | |
| ### Run Grounded-Efficient-SAM Demo | |
| - Download the pretrained EfficientSAM checkpoint from [here](https://github.com/yformer/EfficientSAM#model) and put it under `Grounded-Segment-Anything/EfficientSAM` | |
| - Run the demo with the following script: | |
| ```bash | |
| cd Grounded-Segment-Anything | |
| python EfficientSAM/grounded_efficient_sam.py | |
| ``` | |
| - And the result will be saved as `./gronded_efficient_sam_anontated_image.jpg` as: | |
| <div style="text-align: center"> | |
| | Input | Text | Output | | |
| |:---:|:---:|:---:| | |
| | | "bench" |  | | |
| </div> | |
| ### Run Grounded-Edge-SAM Demo | |
| - Download the pretrained [Edge-SAM](https://github.com/chongzhou96/EdgeSAM) checkpoint follow the [official instruction](https://github.com/chongzhou96/EdgeSAM?tab=readme-ov-file#usage-) as: | |
| ```bash | |
| cd Grounded-Segment-Anything | |
| wget -P EfficientSAM/ https://huggingface.co/spaces/chongzhou/EdgeSAM/resolve/main/weights/edge_sam.pth | |
| wget -P EfficientSAM/ https://huggingface.co/spaces/chongzhou/EdgeSAM/resolve/main/weights/edge_sam_3x.pth | |
| ``` | |
| - Run the demo with the following script: | |
| ```bash | |
| cd Grounded-Segment-Anything | |
| python EfficientSAM/grounded_edge_sam.py | |
| ``` | |
| - And the result will be saved as `./gronded_edge_sam_anontated_image.jpg` as: | |
| <div style="text-align: center"> | |
| | Input | Text | Output | | |
| |:---:|:---:|:---:| | |
| | | "bench" |  | | |
| </div> | |
| ### Run Grounded-RepViT-SAM Demo | |
| - Download the pretrained [RepViT-SAM](https://github.com/THU-MIG/RepViT) checkpoint follow the [official instruction](https://github.com/THU-MIG/RepViT/tree/main/sam#installation) as: | |
| ```bash | |
| cd Grounded-Segment-Anything | |
| wget -P EfficientSAM/ https://github.com/THU-MIG/RepViT/releases/download/v1.0/repvit_sam.pt | |
| ``` | |
| - Run the demo with the following script: | |
| ```bash | |
| cd Grounded-Segment-Anything | |
| python EfficientSAM/grounded_repvit_sam.py | |
| ``` | |
| - And the result will be saved as `./gronded_repvit_sam_anontated_image.jpg` as: | |
| <div style="text-align: center"> | |
| | Input | Text | Output | | |
| |:---:|:---:|:---:| | |
| | | "bench" |  | | |
| </div> | |