
Update README.md
Browse files
README.md
CHANGED
|
@@ -6,7 +6,7 @@ license: apache-2.0
|
|
| 6 |
|
| 7 |
This is an experimental version of LimaRP for Llama2, using a somewhat updated dataset (1800 training samples)
|
| 8 |
and a 2-pass training procedure. The first pass includes unsupervised tuning on 2800 stories within
|
| 9 |
-
4k tokens length and the second is LimaRP.
|
| 10 |
|
| 11 |
For more details about LimaRP, see the model page for the [previously released version](https://huggingface.co/lemonilia/limarp-llama2-v2).
|
| 12 |
Most details written there apply for this version as well.
|
|
@@ -42,18 +42,41 @@ Character: {utterance}
|
|
| 42 |
(etc.)
|
| 43 |
```
|
| 44 |
|
| 45 |
-
|
| 46 |
- Replace all the text in curly braces (curly braces included) with your own text.
|
| 47 |
- `User` and `Character` should be replaced with appropriate names.
|
| 48 |
|
| 49 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 50 |
## Training procedure
|
| 51 |
[Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) was used for training.
|
| 52 |
The model has been trained as a 4-bit LoRA adapter. It's so large because a LoRA rank
|
| 53 |
of 256 was used. It's suggested to merge it to the base Llama2-7B model.
|
| 54 |
|
| 55 |
### Training hyperparameters
|
| 56 |
-
For
|
| 57 |
|
| 58 |
- learning_rate: 0.0002
|
| 59 |
- lr_scheduler_type: constant
|
|
@@ -71,4 +94,8 @@ For both passes these settings were used:
|
|
| 71 |
- optimizer: adamw_torch
|
| 72 |
|
| 73 |
In the second pass, the `lora_model_dir` option was used to load and train the adapter
|
| 74 |
-
previously trained on a stories dataset.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
|
| 7 |
This is an experimental version of LimaRP for Llama2, using a somewhat updated dataset (1800 training samples)
|
| 8 |
and a 2-pass training procedure. The first pass includes unsupervised tuning on 2800 stories within
|
| 9 |
+
4k tokens length and the second pass is LimaRP with slight changes.
|
| 10 |
|
| 11 |
For more details about LimaRP, see the model page for the [previously released version](https://huggingface.co/lemonilia/limarp-llama2-v2).
|
| 12 |
Most details written there apply for this version as well.
|
|
|
|
| 42 |
(etc.)
|
| 43 |
```
|
| 44 |
|
| 45 |
+
You should:
|
| 46 |
- Replace all the text in curly braces (curly braces included) with your own text.
|
| 47 |
- `User` and `Character` should be replaced with appropriate names.
|
| 48 |
|
| 49 |
|
| 50 |
+
### Message length control
|
| 51 |
+
Starting from this version it is possible to append a length modifier to the response
|
| 52 |
+
instruction sequence, like this:
|
| 53 |
+
|
| 54 |
+
```
|
| 55 |
+
### Input
|
| 56 |
+
User: {utterance}
|
| 57 |
+
|
| 58 |
+
### Response: (length = medium)
|
| 59 |
+
Character: {utterance}
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
This has an immediately noticeable effect on the bot responses. The possible lenghts are:
|
| 63 |
+
`tiny`, `short`, `medium`, `long`, `huge`, `humongous`, `extreme`, `unlimited`. The
|
| 64 |
+
recommended starting length is `medium` or `long`. The AI may ramble and impersonation
|
| 65 |
+
can occur with much longer messages.
|
| 66 |
+
|
| 67 |
+
You can follow these instruction format settings in SillyTavern:
|
| 68 |
+
|
| 69 |
+
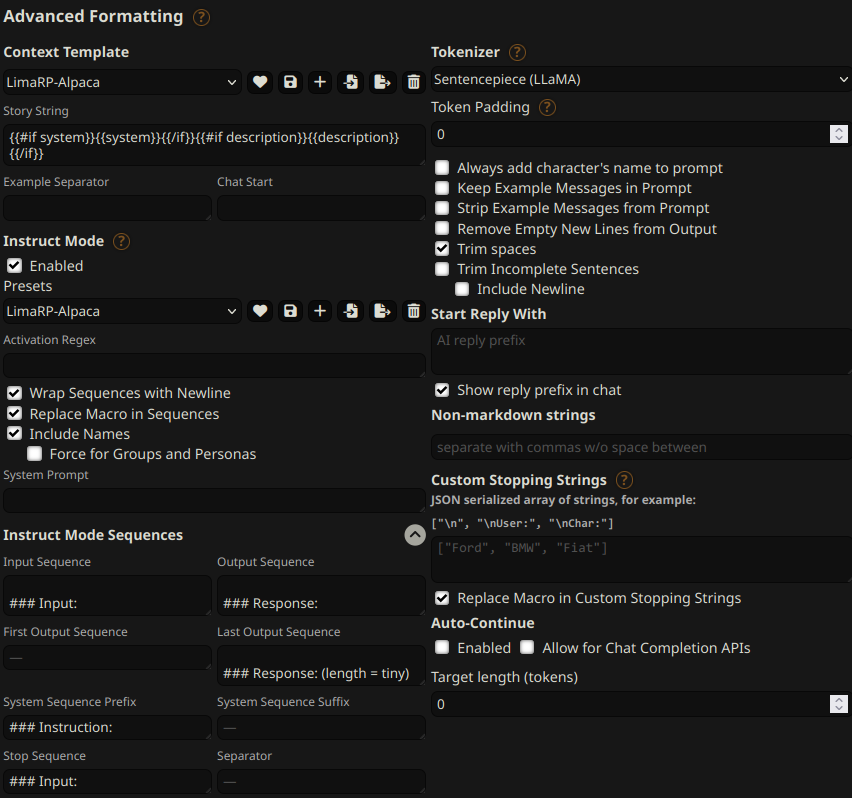
|
| 70 |
+
|
| 71 |
+
Replacing `tiny` with your desired response length.
|
| 72 |
+
|
| 73 |
## Training procedure
|
| 74 |
[Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) was used for training.
|
| 75 |
The model has been trained as a 4-bit LoRA adapter. It's so large because a LoRA rank
|
| 76 |
of 256 was used. It's suggested to merge it to the base Llama2-7B model.
|
| 77 |
|
| 78 |
### Training hyperparameters
|
| 79 |
+
For the first pass these settings were used:
|
| 80 |
|
| 81 |
- learning_rate: 0.0002
|
| 82 |
- lr_scheduler_type: constant
|
|
|
|
| 94 |
- optimizer: adamw_torch
|
| 95 |
|
| 96 |
In the second pass, the `lora_model_dir` option was used to load and train the adapter
|
| 97 |
+
previously trained on a stories dataset. These settings were also changed:
|
| 98 |
+
|
| 99 |
+
- lora_dropout: 0.0
|
| 100 |
+
- gradient_accumulation_steps: 8
|
| 101 |
+
- learning_rate: 0.0006
|