出現錯誤時該怎麼辦

在本節中, 我們將研究當你嘗試從新調整的 Transformer 模型生成預測時可能發生的一些常見錯誤。這將為 第四節 做準備, 我們將探索如何調試訓練階段本身。
我們為這一節準備了一個 模板模型庫, 如果你想運行本章中的代碼, 你首先需要將模型複製到你的 Hugging Face Hub 賬號。為此, 首先通過在 Jupyter 筆記本中運行以下任一命令來登錄:
from huggingface_hub import notebook_login
notebook_login()或在你最喜歡的終端中執行以下操作:
huggingface-cli login
這將提示你輸入用戶名和密碼, 並將在下面保存一個令牌 ~/.cache/huggingface/。登錄後, 你可以使用以下功能複製模板存儲庫:
from distutils.dir_util import copy_tree
from huggingface_hub import Repository, snapshot_download, create_repo, get_full_repo_name
def copy_repository_template():
# Clone the repo and extract the local path
template_repo_id = "lewtun/distilbert-base-uncased-finetuned-squad-d5716d28"
commit_hash = "be3eaffc28669d7932492681cd5f3e8905e358b4"
template_repo_dir = snapshot_download(template_repo_id, revision=commit_hash)
# Create an empty repo on the Hub
model_name = template_repo_id.split("/")[1]
create_repo(model_name, exist_ok=True)
# Clone the empty repo
new_repo_id = get_full_repo_name(model_name)
new_repo_dir = model_name
repo = Repository(local_dir=new_repo_dir, clone_from=new_repo_id)
# Copy files
copy_tree(template_repo_dir, new_repo_dir)
# Push to Hub
repo.push_to_hub()現在, 當你調用 copy_repository_template() 時, 它將在你的帳戶下創建模板存儲庫的副本。
從 🤗 Transformers 調試管道
要開始我們調試 Transformer 模型的奇妙世界之旅, 請考慮以下場景: 你正在與一位同事合作進行問答項目, 以幫助電子商務網站的客戶找到有關消費品的答案。你的同事給你發了一條消息, 比如:
嗨! 我剛剛使用了抱抱臉課程的 第七章 中的技術進行了一個實驗, 並在 SQuAD 上獲得了一些很棒的結果! 我認為我們可以用這個模型作為我們項目的起點。Hub上的模型ID是 “lewtun/distillbert-base-uncased-finetuned-squad-d5716d28”。請隨意測試一下 :)
你首先想到的是使用 🤗 Transformers 中的 管道:
from transformers import pipeline
model_checkpoint = get_full_repo_name("distillbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""哦不對, 好像出了什麼問題! 如果你是編程新手, 這些類型的錯誤一開始看起來有點神秘 (甚至是一個 OSError?!)。這裡顯示的錯誤只是一個更大的錯誤報告的最後一部分, 稱為 Python traceback (又名堆棧跟蹤)。例如, 如果你在 Google Colab 上運行此代碼, 你應該會看到類似於以下屏幕截圖的內容:
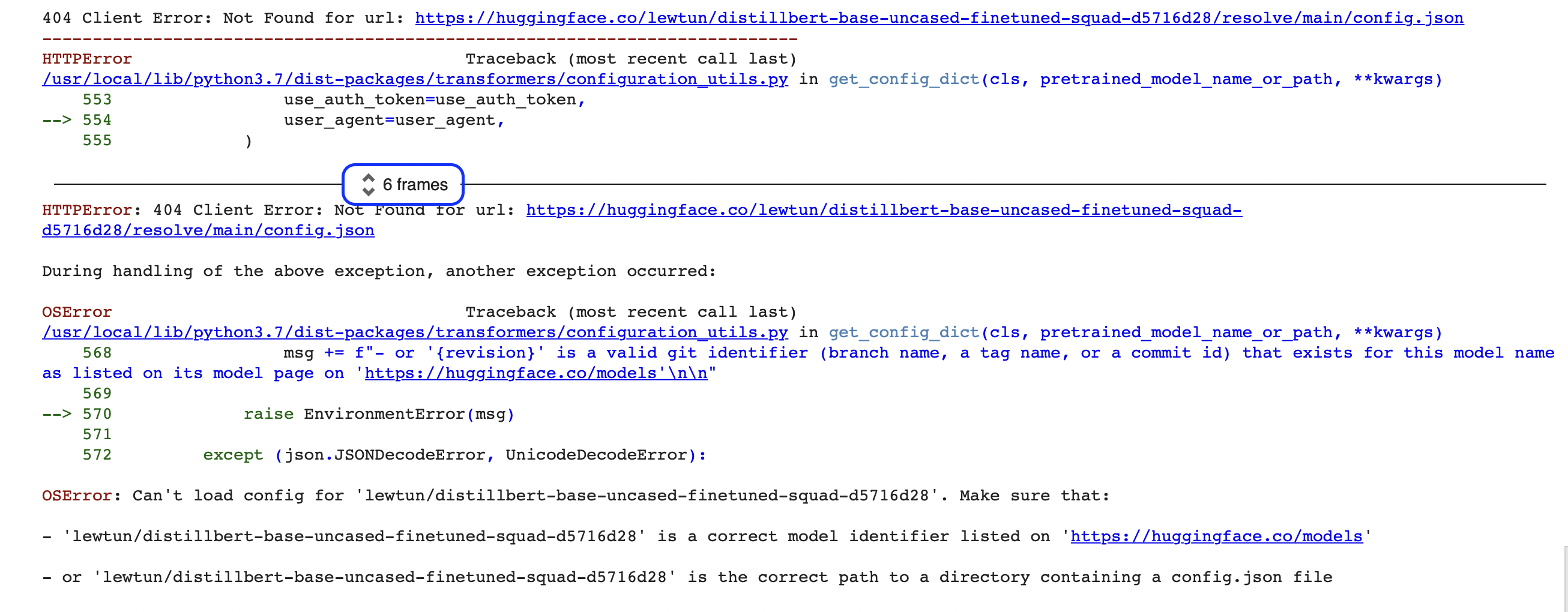
這些報告中包含很多信息, 所以讓我們一起來看看關鍵部分。首先要注意的是, 應該從 從底部到頂部 讀取回溯。如果你習慣於從上到下閱讀英文文本, 這可能聽起來很奇怪,但它反映了這樣一個事實,即回溯顯示了在下載模型和標記器時 管道 進行的函數調用序列。(查看 第二章 瞭解有關 pipeline 如何在後臺工作的更多詳細信息。)
🚨 看到Google Colab 回溯中 “6 幀” 周圍的藍色框了嗎? 這是 Colab 的一個特殊功能, 它將回溯壓縮為”幀”。如果你似乎無法找到錯誤的來源, 請確保通過單擊這兩個小箭頭來展開完整的回溯。
這意味著回溯的最後一行指示最後一條錯誤消息並給出引發的異常的名稱。在這種情況下, 異常類型是OSError, 表示與系統相關的錯誤。如果我們閱讀隨附的錯誤消息, 我們可以看到模型的 config.json 文件似乎有問題, 我們給出了兩個修復它的建議:
"""
Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""💡 如果你遇到難以理解的錯誤消息, 只需將該消息複製並粘貼到 Google 或 Stack Overflow 搜索欄中 (是的, 真的!)。你很可能不是第一個遇到錯誤的人, 這是找到社區中其他人發佈的解決方案的好方法。例如, 在 Stack Overflow 上搜索 OSError: Can't load config for 給出了幾個hits, 可能是用作解決問題的起點。
第一個建議是要求我們檢查模型ID是否真的正確, 所以首先要做的就是複製標識符並將其粘貼到Hub的搜索欄中:

嗯, 看起來我們同事的模型確實不在 Hub 上… 啊哈, 但是模型名稱中有一個錯字! DistilBERT 的名稱中只有一個 “l”, 所以讓我們解決這個問題並尋找 “lewtun/distilbert-base-uncased-finetuned-squad-d5716d28”:

好的, 這很受歡迎。現在讓我們嘗試使用正確的模型 ID 再次下載模型:
model_checkpoint = get_full_repo_name("distilbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""啊, 再次挫敗 — 歡迎來到機器學習工程師的日常生活! 因為我們已經修復了模型 ID, 所以問題一定出在存儲庫本身。訪問 🤗 Hub 上存儲庫內容的一種快速方法是通過 huggingface_hub 庫的 list_repo_files() 方法:
from huggingface_hub import list_repo_files
list_repo_files(repo_id=model_checkpoint)['.gitattributes', 'README.md', 'pytorch_model.bin', 'special_tokens_map.json', 'tokenizer_config.json', 'training_args.bin', 'vocab.txt']有趣 — 似乎沒有配置文件存儲庫中的 config.json 文件! 難怪我們的 pipeline 無法加載模型; 我們的同事一定是在微調後忘記將這個文件推送到 Hub。在這種情況下, 問題似乎很容易解決: 我們可以要求他們添加文件, 或者, 因為我們可以從模型 ID 中看到使用的預訓練模型是 distilbert-base-uncased, 我們可以下載此模型的配置並將其推送到我們的存儲庫以查看是否可以解決問題。讓我們試試看。使用我們在 第二章 中學習的技術, 我們使用 AutoConfig 類下載模型的配置:
from transformers import AutoConfig
pretrained_checkpoint = "distilbert-base-uncased"
config = AutoConfig.from_pretrained(pretrained_checkpoint)🚨 我們在這裡採用的方法並不是萬無一失的, 因為我們的同事可能在微調模型之前已經調整了 distilbert-base-uncased 配置。在現實生活中, 我們想首先檢查它們, 但出於本節的目的, 我們假設它們使用默認配置。
然後我們可以使用配置的 push_to_hub() 方法將其推送到我們的模型存儲庫:
config.push_to_hub(model_checkpoint, commit_message="Add config.json")現在我們可以通過從最新提交的 main 分支中加載模型來測試這是否有效:
reader = pipeline("question-answering", model=model_checkpoint, revision="main")
context = r"""
Extractive Question Answering is the task of extracting an answer from a text
given a question. An example of a question answering dataset is the SQuAD
dataset, which is entirely based on that task. If you would like to fine-tune a
model on a SQuAD task, you may leverage the
examples/pytorch/question-answering/run_squad.py script.
🤗 Transformers is interoperable with the PyTorch, TensorFlow, and JAX
frameworks, so you can use your favourite tools for a wide variety of tasks!
"""
question = "What is extractive question answering?"
reader(question=question, context=context){'score': 0.38669535517692566,
'start': 34,
'end': 95,
'answer': 'the task of extracting an answer from a text given a question'}哇哦, 成功了!讓我們回顧一下你剛剛學到的東西:
- Python 中的錯誤消息稱為 tracebacks , 並從下到上閱讀。錯誤消息的最後一行通常包含定位問題根源所需的信息。
- 如果最後一行沒有包含足夠的信息, 請按照您的方式進行回溯, 看看您是否可以確定源代碼中發生錯誤的位置。
- 如果沒有任何錯誤消息可以幫助您調試問題, 請嘗試在線搜索類似問題的解決方案。
huggingface_hub// 🤗 Hub? 庫提供了一套工具, 你可以使用這些工具與 Hub 上的存儲庫進行交互和調試。
現在你知道如何調試管道, 讓我們看一下模型本身前向傳遞中的一個更棘手的示例。
調試模型的前向傳遞
儘管 pipeline 對於大多數需要快速生成預測的應用程序來說非常有用, 有時您需要訪問模型的 logits (例如, 如果您有一些想要應用的自定義後處理)。為了看看在這種情況下會出現什麼問題, 讓我們首先從 pipeline 中獲取模型和標記器:
tokenizer = reader.tokenizer model = reader.model
接下來我們需要一個問題, 那麼讓我們看看是否支持我們最喜歡的框架:
question = "Which frameworks can I use?"正如我們在 第七章 中學習的, 我們需要採取的通常步驟是對輸入進行標記化, 提取開始和結束標記的對數, 然後解碼答案範圍:
import torch
inputs = tokenizer(question, context, add_special_tokens=True)
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# Get the most likely beginning of answer with the argmax of the score
answer_start = torch.argmax(answer_start_scores)
# Get the most likely end of answer with the argmax of the score
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/var/folders/28/k4cy5q7s2hs92xq7_h89_vgm0000gn/T/ipykernel_75743/2725838073.py in <module>
1 inputs = tokenizer(question, text, add_special_tokens=True)
2 input_ids = inputs["input_ids"]
----> 3 outputs = model(**inputs)
4 answer_start_scores = outputs.start_logits
5 answer_end_scores = outputs.end_logits
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, start_positions, end_positions, output_attentions, output_hidden_states, return_dict)
723 return_dict = return_dict if return_dict is not None else self.config.use_return_dict
724
--> 725 distilbert_output = self.distilbert(
726 input_ids=input_ids,
727 attention_mask=attention_mask,
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'
"""噢, 看起來我們的代碼中有一個錯誤!但我們不怕一點調試。您可以在筆記本中使用 Python 調試器:
或在終端中:
在這裡, 閱讀錯誤消息告訴我們 'list' object has no attribute 'size', 我們可以看到一個 --> 箭頭指向 model(**inputs) 中出現問題的行。你可以使用 Python 調試器以交互方式調試它, 但現在我們只需打印出一部分 inputs, 看看我們有什麼:
inputs["input_ids"][:5][101, 2029, 7705, 2015, 2064]這當然看起來像一個普通的 Python list, 但讓我們仔細檢查一下類型:
type(inputs["input_ids"])list是的, 這肯定是一個 Python list。那麼出了什麼問題呢? 回憶 第二章 🤗 Transformers 中的 AutoModelForXxx 類在 tensors 上運行(PyTorch或者or TensorFlow), 一個常見的操作是使用 Tensor.size() 方法提取張量的維度, 例如, 在 PyTorch 中。讓我們再看看回溯, 看看哪一行觸發了異常:
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'看起來我們的代碼試圖調用 input_ids.size(), 但這顯然不適用於 Python list, 這只是一個容器。我們如何解決這個問題? 在 Stack Overflow 上搜索錯誤消息給出了很多相關的 hits。單擊第一個會顯示與我們類似的問題, 答案如下面的屏幕截圖所示:
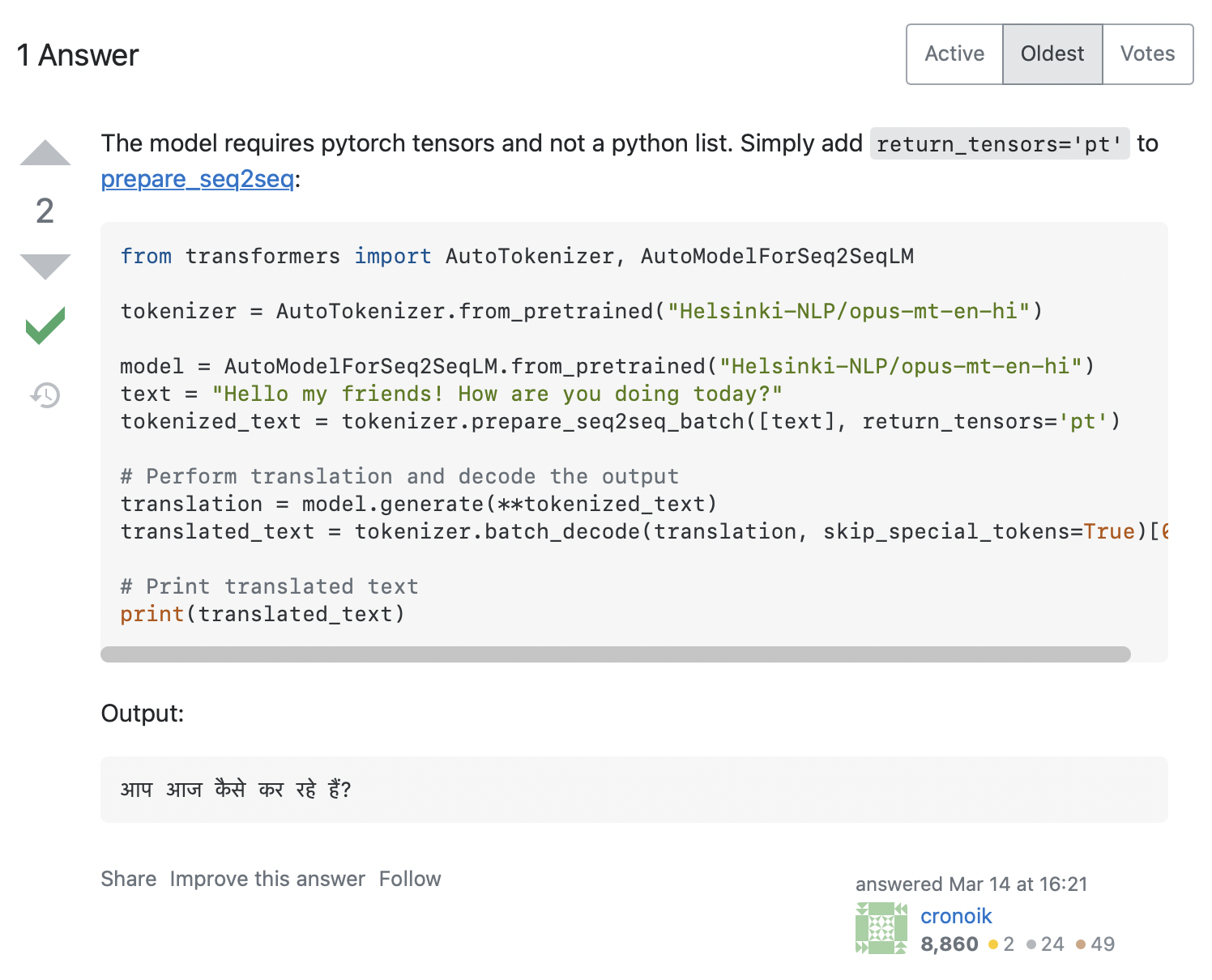
答案建議我們添加 return_tensors='pt' 到標記器, 所以讓我們看看這是否適合我們:
inputs = tokenizer(question, context, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# Get the most likely beginning of answer with the argmax of the score
answer_start = torch.argmax(answer_start_scores)
# Get the most likely end of answer with the argmax of the score
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
Question: Which frameworks can I use?
Answer: pytorch, tensorflow, and jax
"""不錯, 成功了! 這是 Stack Overflow 非常有用的一個很好的例子: 通過識別類似的問題, 我們能夠從社區中其他人的經驗中受益。然而, 像這樣的搜索並不總是會產生相關的答案, 那麼在這種情況下你能做什麼呢? 幸運的是, 有一個受歡迎的開發者社區 Hugging Face forums 可以幫助你! 在下一節中, 我們將看看如何設計可能得到回答的優秀論壇問題。