Phải làm gì khi bạn gặp lỗi

Trong phần này, chúng ta sẽ xem xét một số lỗi phổ biến có thể xảy ra khi bạn đang cố gắng tạo dự đoán từ mô hình Transformer mới được điều chỉnh của mình. Điều này sẽ giúp bạn chuẩn bị cho section 4, nơi chúng ta sẽ khám phá cách gỡ lỗi chính giai đoạn huấn luyện.
Chúng tôi đã chuẩn bị kho lưu trữ mô hình mẫu cho phần này và nếu bạn muốn chạy mã trong chương này, trước tiên, bạn cần sao chép mô hình vào tài khoản của bạn trên Hugging Face Hub. Để làm như vậy, trước tiên hãy đăng nhập bằng cách chạy một trong hai thao tác sau trong notebook Jupyter:
from huggingface_hub import notebook_login
notebook_login()hoặc sau trong terminal yêu thích của bạn:
huggingface-cli login
Thao tác này sẽ nhắc bạn nhập tên người dùng và mật khẩu của mình, đồng thời sẽ lưu token dưới ~/.cache/huggingface/. Khi bạn đã đăng nhập, bạn có thể sao chép kho mẫu với hàm sau:
from distutils.dir_util import copy_tree
from huggingface_hub import Repository, snapshot_download, create_repo, get_full_repo_name
def copy_repository_template():
# Sao chép kho và trích xuất đường dẫn cục bộ
template_repo_id = "lewtun/distilbert-base-uncased-finetuned-squad-d5716d28"
commit_hash = "be3eaffc28669d7932492681cd5f3e8905e358b4"
template_repo_dir = snapshot_download(template_repo_id, revision=commit_hash)
# Tạo ra một kho rỗng trên Hub
model_name = template_repo_id.split("/")[1]
create_repo(model_name, exist_ok=True)
# Sao chép kho rỗng
new_repo_id = get_full_repo_name(model_name)
new_repo_dir = model_name
repo = Repository(local_dir=new_repo_dir, clone_from=new_repo_id)
# Sao chép các tệp
copy_tree(template_repo_dir, new_repo_dir)
# Đẩy lên Hub
repo.push_to_hub()Giờ khi bạn gọi copy_repository_template(), nó sẽ tạo ra một bản sao kho lưu trữ mẫu dưới tài khoản của bạn.
Gỡ lỗi pipeline 🤗 Transformers
Để bắt đầu cuộc hành trình của chúng ta vào thế giới tuyệt vời của việc gỡ lỗi các mô hình Transformer, hãy xem xét tình huống sau: bạn đang làm việc với một đồng nghiệp trong một dự án hỏi đáp để giúp khách hàng của một trang web thương mại điện tử tìm thấy câu trả lời về các sản phẩm tiêu dùng. Đồng nghiệp của bạn gửi cho bạn một tin nhắn như:
Chúc bạn một ngày tốt lành! Tôi vừa chạy một thử nghiệm bằng cách sử dụng các kỹ thuật trong Chương 7 của khóa học Hugging Face và nhận được một số kết quả tuyệt vời trên SQuAD! Tôi nghĩ chúng ta có thể sử dụng mô hình này như một điểm khởi đầu cho dự án của mình. ID mô hình trên Hub là “lewtun/distillbert-base-uncased-finetuned-squad-d5716d28”. Hãy thử nghiệm nó xem :)
và điều đầu tiên bạn nghĩ đến là tải mô hình bằng cách sử dụng pipeline từ 🤗 Transformers:
from transformers import pipeline
model_checkpoint = get_full_repo_name("distillbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""Ôi không, có vẻ như có gì đó không ổn! Nếu bạn là người mới lập trình, những lỗi kiểu này thoạt đầu có vẻ hơi khó hiểu (thậm chí OSError là gì ?!). Lỗi được hiển thị ở đây chỉ là phần cuối cùng của một báo cáo lỗi lớn hơn nhiều được gọi là Python traceback (hay còn gọi là đáu vết ngăn xếp). Ví dụ: nếu bạn đang chạy đoạn mã này trên Google Colab, bạn sẽ thấy một cái gì đó giống như ảnh chụp màn hình sau:
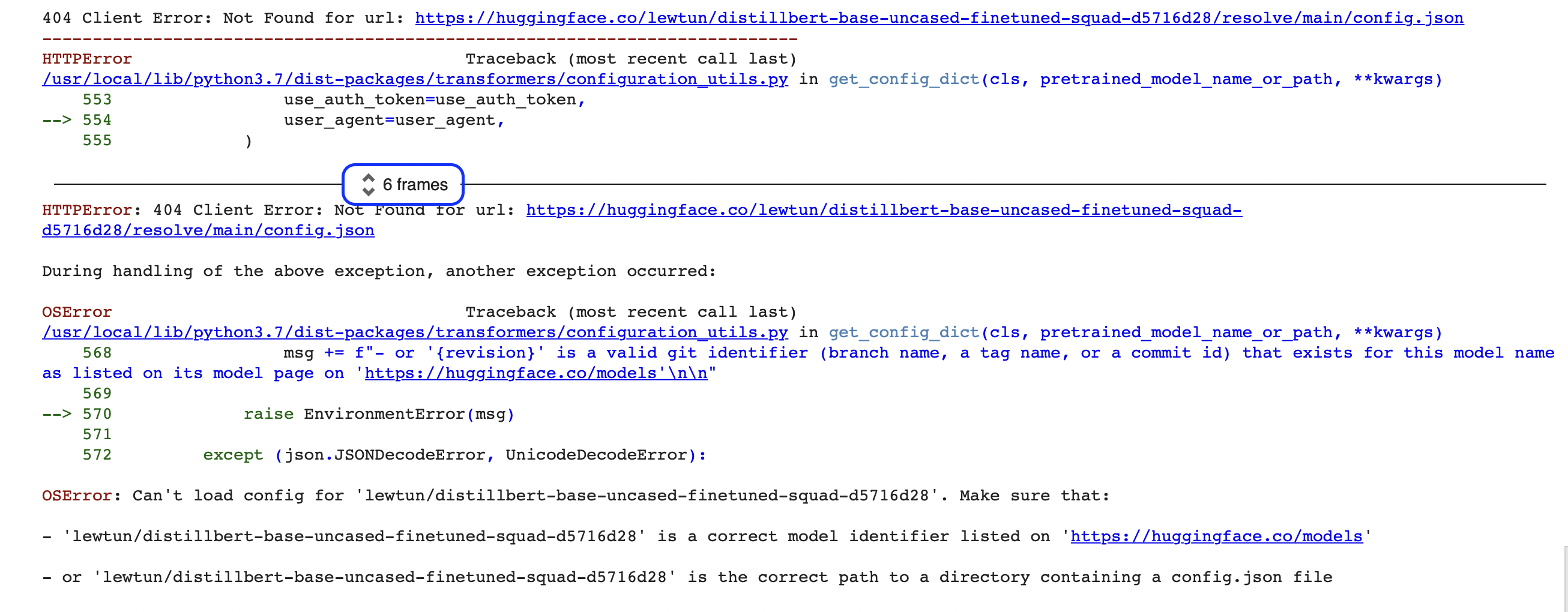
Có rất nhiều thông tin có trong các báo cáo này, vì vậy chúng ta hãy cùng nhau xem qua các phần chính. Điều đầu tiên cần lưu ý là theo dõi phải được đọc từ dưới lên trên. Điều này nghe có vẻ kỳ lạ nếu bạn đã quen đọc văn bản tiếng Anh từ trên xuống dưới, nhưng nó phản ánh thực tế là bản truy xuất hiển thị chuỗi các lệnh gọi hàm mà pipeline thực hiện khi tải xuống mô hình và trình tokenizer. (Xem Chương 2 để biết thêm chi tiết về cách hoạt động của pipeline.)
🚨 Bạn có thấy hộp màu xanh lam xung quanh “6 frames” trong phần truy xuất từ Google Colab không? Đó là một tính năng đặc biệt của Colab, nén phần truy xuất vào các “frames”. Nếu bạn dường như không thể tìm ra nguồn gốc của lỗi, hãy đảm bảo rằng bạn mở rộng toàn bộ theo dõi bằng cách nhấp vào hai mũi tên nhỏ đó.
Điều này có nghĩa là dòng cuối cùng của truy xuất cho biết thông báo lỗi cuối cùng và cung cấp tên của ngoại lệ đã được nêu ra. Trong trường hợp này, loại ngoại lệ là OSError, cho biết lỗi liên quan đến hệ thống. Nếu chúng ta đọc thông báo lỗi kèm theo, chúng ta có thể thấy rằng dường như có sự cố với tệp config.json của mô hình và ta sẽ đưa ra hai đề xuất để khắc phục:
"""
Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""💡 Nếu bạn gặp phải thông báo lỗi khó hiểu, chỉ cần sao chép và dán thông báo đó vào thanh tìm kiếm Google hoặc Stack Overflow (vâng, thực sự!). Có nhiều khả năng bạn không phải là người đầu tiên gặp phải lỗi và đây là một cách tốt để tìm giải pháp mà những người khác trong cộng đồng đã đăng. Ví dụ: tìm kiếm OSError: Can't load config for trên Stack Overflow mang lại nhiều lần truy cập có thể được sử dụng như một điểm khởi đầu để giải quyết vấn đề.
Đề xuất đầu tiên là yêu cầu ta kiểm tra xem ID mô hình có thực sự chính xác hay không, vì vậy, việc đầu tiên ta làm là sao chép chỉ số nhận dạng và dán nó vào thanh tìm kiếm của Hub:

Rất tiếc, có vẻ như mô hình của anh đồng nghiệp không có trên Hub … aha, nhưng có một lỗi đánh máy trong tên của mô hình! DistilBERT chỉ có một chữ “l” trong tên của nó, vì vậy hãy sửa lỗi đó và tìm “lewtun/distilbert-base-unsased-finetuned-Squad-d5716d28” thay thế:

Được rồi, điều này đã thành công. Bây giờ, hãy thử tải xuống mô hình một lần nữa với đúng ID mô hình:
model_checkpoint = get_full_repo_name("distilbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""Argh, lại thất bại - chào mừng bạn đến với cuộc sống hàng ngày của một kỹ sư học máy! Vì chúng ta đã sửa ID mô hình, vấn đề phải nằm ở chính kho lưu trữ. Một cách nhanh chóng để truy cập nội dung của một kho lưu trữ trên 🤗 Hub là thông qua hàm list_repo_files() của thư viện huggingface_hub:
from huggingface_hub import list_repo_files
list_repo_files(repo_id=model_checkpoint)['.gitattributes', 'README.md', 'pytorch_model.bin', 'special_tokens_map.json', 'tokenizer_config.json', 'training_args.bin', 'vocab.txt']Thật thú vị - dường như không có tệp config.json trong kho lưu trữ! Không có gì ngạc nhiên khi pipeline không thể tải mô hình; đồng nghiệp của chúng ta chắc hẳn đã quên đẩy tệp này vào Hub sau khi đã tinh chỉnh nó. Trong trường hợp này, vấn đề có vẻ khá đơn giản để khắc phục: chúng ta có thể yêu cầu họ thêm tệp hoặc, vì chúng ta có thể thấy từ ID mô hình mà mô hình huấn luyện trước đã sử dụng là distilbert-base-uncased, chúng ta có thể tải xuống cấu hình cho mô hình này và đẩy nó vào kho lưu trữ của mình để xem liệu điều đó có giải quyết được sự cố hay không. Hãy thử điều đó. Sử dụng các kỹ thuật chúng ta đã học trong Chương 2, chúng ta có thể tải xuống cấu hình của mô hình với lớp AutoConfig:
from transformers import AutoConfig
pretrained_checkpoint = "distilbert-base-uncased"
config = AutoConfig.from_pretrained(pretrained_checkpoint)🚨 Cách tiếp cận mà chúng tôi đang thực hiện ở đây không phải là hoàn hảo, vì đồng nghiệp của chúng ta có thể đã chỉnh sửa cấu hình của distilbert-base-uncased trước khi tinh chỉnh mô hình. Trong thực tế, chúng ta muốn kiểm tra với họ trước, nhưng với mục đích của phần này, chúng ta sẽ giả định rằng họ đã sử dụng cấu hình mặc định.
Sau đó, chúng ta có thể đẩy nó vào kho lưu trữ mô hình của mình bằng hàm push_to_hub() của cấu hình:
config.push_to_hub(model_checkpoint, commit_message="Add config.json")Bây giờ chúng ta có thể kiểm tra xem điều này có hoạt động hay không bằng cách tải mô hình từ cam kết mới nhất trên nhánh main:
reader = pipeline("question-answering", model=model_checkpoint, revision="main")
context = r"""
Extractive Question Answering is the task of extracting an answer from a text
given a question. An example of a question answering dataset is the SQuAD
dataset, which is entirely based on that task. If you would like to fine-tune a
model on a SQuAD task, you may leverage the
examples/pytorch/question-answering/run_squad.py script.
🤗 Transformers is interoperable with the PyTorch, TensorFlow, and JAX
frameworks, so you can use your favourite tools for a wide variety of tasks!
"""
question = "What is extractive question answering?"
reader(question=question, context=context){'score': 0.38669535517692566,
'start': 34,
'end': 95,
'answer': 'the task of extracting an answer from a text given a question'}Tuyệt vời, nó đã hoạt động! Hãy tóm tắt lại những gì bạn vừa học được:
- Các thông báo lỗi trong Python được gọi là tracebacks và được đọc từ dưới lên trên. Dòng cuối cùng của thông báo lỗi thường chứa thông tin bạn cần để xác định nguồn gốc của vấn đề.
- Nếu dòng cuối cùng không chứa đủ thông tin, hãy làm theo cách của bạn để truy xuất lại và xem liệu bạn có thể xác định được lỗi xảy ra ở đâu trong mã nguồn hay không.
- Nếu không có thông báo lỗi nào có thể giúp bạn gỡ lỗi, hãy thử tìm kiếm trực tuyến giải pháp cho vấn đề tương tự.
- Các thư viện
huggingface_hub// 🤗 Hub? cung cấp một bộ công cụ mà bạn có thể sử dụng để tương tác và gỡ lỗi các kho lưu trữ trên Hub.
Bây giờ bạn đã biết cách gỡ lỗi một đường dẫn, chúng ta hãy xem một ví dụ phức tạp hơn trong bước truyền thẳng của chính mô hình.
Gỡ lỗi truyền thẳng mô hình của bạn
Mặc dù pipeline tuyệt vời cho hầu hết các ứng dụng mà bạn cần nhanh chóng tạo dự đoán, đôi khi bạn sẽ cần truy cập nhật ký của mô hình (giả sử, nếu bạn có một số hậu xử lý tùy chỉnh mà bạn muốn áp dụng). Để xem điều gì có thể sai trong trường hợp này, trước tiên hãy lấy mô hình và trình tokenize từ pipeline của mình:
tokenizer = reader.tokenizer model = reader.model
Tiếp theo, chúng ta cần một câu hỏi, vì vậy hãy xem liệu các khung yêu thích của chúng ta có được hỗ trợ không:
question = "Which frameworks can I use?"Như đã thấy trong Chương 7, các bước thông thường ta cần làm đó là tokenize đầu vào, trích xuất các logit của token bắt đầu và kết thúc, rồi sau đó giải mã các khoảng trả lời:
import torch
inputs = tokenizer(question, context, add_special_tokens=True)
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# Lấy phần có khả năng là bắt đầu của câu trả lời nhất với argmax của điểm trả về
answer_start = torch.argmax(answer_start_scores)
# Lấy phần có khả năng là kết thúc của câu trả lời nhất với argmax của điểm trả về
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/var/folders/28/k4cy5q7s2hs92xq7_h89_vgm0000gn/T/ipykernel_75743/2725838073.py in <module>
1 inputs = tokenizer(question, text, add_special_tokens=True)
2 input_ids = inputs["input_ids"]
----> 3 outputs = model(**inputs)
4 answer_start_scores = outputs.start_logits
5 answer_end_scores = outputs.end_logits
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, start_positions, end_positions, output_attentions, output_hidden_states, return_dict)
723 return_dict = return_dict if return_dict is not None else self.config.use_return_dict
724
--> 725 distilbert_output = self.distilbert(
726 input_ids=input_ids,
727 attention_mask=attention_mask,
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'
"""Ôi trời, có vẻ như chúng ta có một lỗi trong đoạn mã của mình! Nhưng chúng ta không sợ gỡ lỗi chút nào. Bạn có thể sử dụng trình gỡ lỗi Python trong notebook:
hoặc trong terminal:
Ở đây, khi đọc thông báo lỗi cho chúng ta biết rằng đối tượng 'list' object has no attribute 'size' và chúng ta có thể thấy một mũi tên --> trỏ đến dòng nơi vấn đề đã được nêu ra trong model(** input). Bạn có thể gỡ lỗi điều này một cách tương tự bằng cách sử dụng trình gỡ lỗi Python, nhưng bây giờ chúng ta chỉ cần in ra một phần của inputs để xem những gì chúng ta có:
Here, reading the error message tells us that 'list' object has no attribute 'size', and we can see a --> arrow pointing to the line where the problem was raised in model(**inputs).You can debug this interactively using the Python debugger, but for now we’ll simply print out a slice of inputs to see what we have:
inputs["input_ids"][:5][101, 2029, 7705, 2015, 2064]Điều này chắc chắn trông giống như một list Python bình thường, nhưng hãy kiểm tra kỹ loại:
type(inputs["input_ids"])listVâng, đó chắc chắn là một list Python. Vậy điều gì đã xảy ra? Nhớ lại từ Chương 2 rằng các lớp AutoModelForXxx trong 🤗 Transformers hoạt động trên tensors (trong PyTorch hoặc TensorFlow) và hoạt động phổ biến là trích xuất các kích thước của tensor bằng cách sử dụng Tensor.size() trong PyTorch. Chúng ta hãy xem xét lại quá trình truy vết, để xem dòng nào đã kích hoạt ngoại lệ:
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'Có vẻ như mã của chúng ta đã cố gắng gọi input_ids.size(), nhưng điều này rõ ràng sẽ không hoạt động đối với một list Python, vốn chỉ là một vùng chứa. Làm thế nào chúng ta có thể giải quyết vấn đề này? Tìm kiếm thông báo lỗi trên Stack Overflow đưa ra một số lượt truy cập liên quan. Nhấp vào câu hỏi đầu tiên sẽ hiển thị một câu hỏi tương tự như câu hỏi của chúng ta, với câu trả lời được hiển thị trong ảnh chụp màn hình bên dưới:
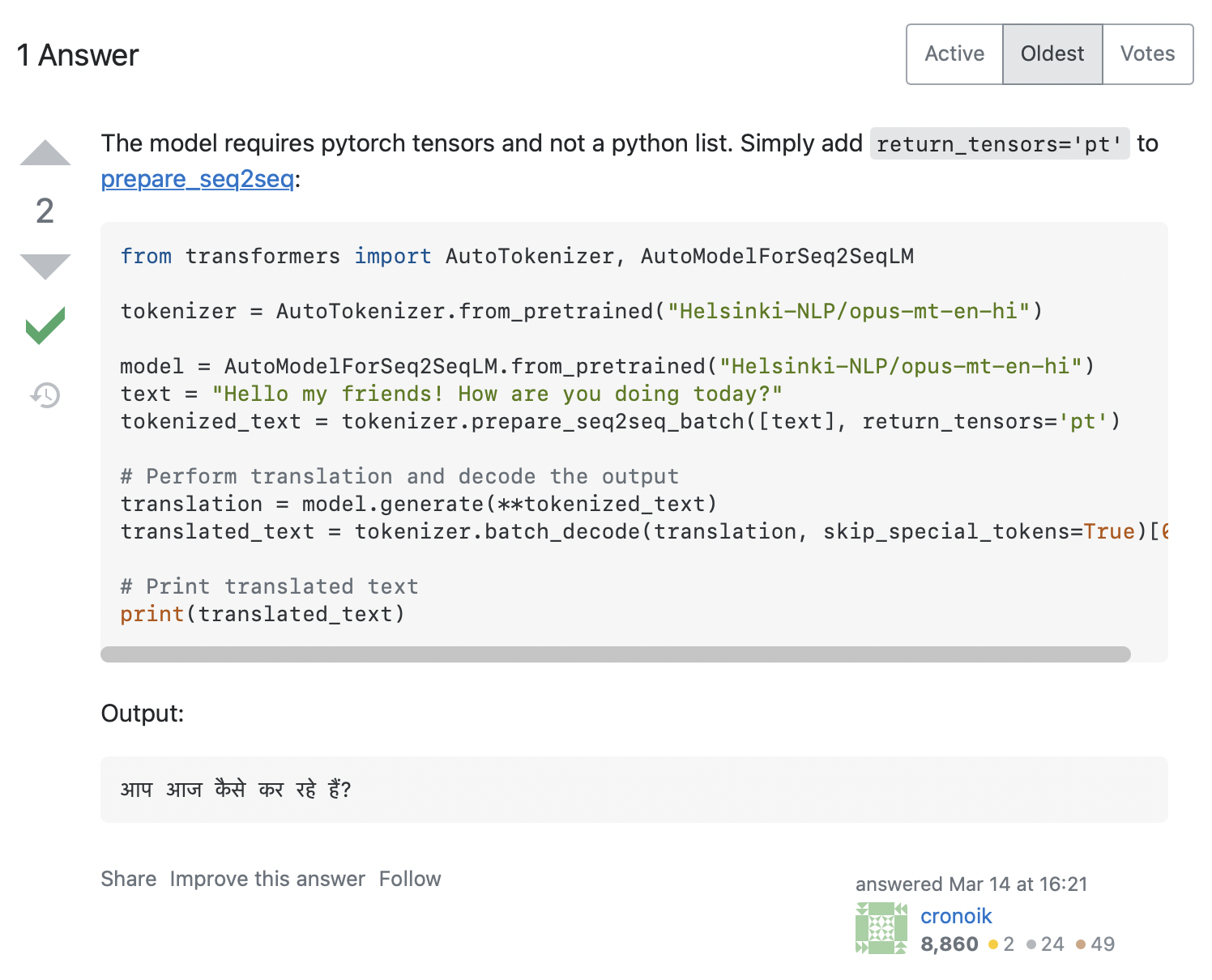
Câu trả lời khuyên chúng ta nên thêm return_tensors='pt' vào tokenizer, vì vậy hãy xem điều đó có phù hợp với chúng ta không:
inputs = tokenizer(question, context, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# Lấy phần có khả năng là bắt đầu của câu trả lời nhất với argmax của điểm trả về
answer_start = torch.argmax(answer_start_scores)
# Lấy phần có khả năng là kết thúc của câu trả lời nhất với argmax của điểm trả về
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
Question: Which frameworks can I use?
Answer: pytorch, tensorflow, and jax
"""Tốt, nó đã hoạt động! Đây là một ví dụ tuyệt vời về mức độ hữu ích của Stack Overflow: bằng cách xác định một vấn đề tương tự, chúng ta có thể hưởng lợi từ kinh nghiệm của những người khác trong cộng đồng. Tuy nhiên, một tìm kiếm như thế này không phải lúc nào cũng mang lại câu trả lời phù hợp, vậy bạn có thể làm gì trong những trường hợp như vậy? May mắn thay, có một cộng đồng các nhà phát triển chào đón trên diễn đàn Hugging Face có thể giúp bạn! Trong phần tiếp theo, chúng ta sẽ xem xét cách bạn có thể tạo ra các câu hỏi tốt trên diễn đàn có khả năng được trả lời.