Tinh chỉnh một mô hình ngôn ngữ bị ẩn đi

Đối với nhiều ứng dụng NLP liên quan đến các mô hình Transformer, bạn có thể chỉ cần lấy một mô hình được huấn luyện trước từ Hugging Face Hub và tinh chỉnh trực tiếp trên dữ liệu của bạn cho tác vụ hiện tại. Với điều kiện là ngữ liệu được sử dụng để huấn luyện trước không quá khác biệt với ngữ liệu được sử dụng để tinh chỉnh, việc học chuyển tiếp thường sẽ mang lại kết quả tốt.
Tuy nhiên, có một vài trường hợp mà trước tiên bạn sẽ muốn tinh chỉnh các mô hình ngôn ngữ trên dữ liệu của mình, trước khi huấn luyện đầu tác vụ cụ thể. Ví dụ: nếu tập dữ liệu của bạn chứa các hợp đồng pháp lý hoặc các bài báo khoa học, thì mô hình thuần Transformer như BERT thường sẽ coi các từ chuyên môn trong kho dữ liệu của bạn là token hiếm và hiệu suất kết quả có thể kém hơn. Bằng cách tinh chỉnh mô hình ngôn ngữ trên dữ liệu chuyên môn, bạn có thể tăng hiệu suất của nhiều tác vụ xuôi dòng, có nghĩa là bạn thường chỉ phải thực hiện bước này một lần!
Quá trình tinh chỉnh mô hình ngôn ngữ được huấn luyện trước trên dữ liệu trong mảng này thường được gọi là domain adapt hay thích ứng chuyên môn. Nó được phổ biến vào năm 2018 bởi ULMFiT, là một trong những kiến trúc mạng thần kinh đầu tiên (dựa trên LSTM) để làm cho việc học chuyển tiếp thực sự hiệu quả cho NLP. Một ví dụ về thích ứng chuyên môn với ULMFiT được hiển thị trong hình dưới đây; trong phần này, chúng ta sẽ làm điều tương tự, nhưng với Transformer thay vì LSTM!


Đến cuối phần này, bạn sẽ có một mô hình ngôn ngữ bị ẩn đi trên Hub có thể tự động hoàn thiện câu như dưới đây:
Cùng đi sâu vào thôi!
🙋 Nếu các thuật ngữ “mô hình ngôn ngữ bị ẩn đi” và “mô hình huấn luyện trước” nghe có vẻ xa lạ với bạn, hãy xem Chương 1, nơi chúng tôi giải thích tất cả các khái niệm cốt lõi này, kèm theo video!
Chọn một mô hình huấn luyện trước cho mô hình ngôn ngữ bị ẩn đi
Để bắt đầu, hãy chọn một mô hình được huấn luyện trước phù hợp để tạo mô hình ngôn ngữ bị ẩn đi. Như được hiển thị trong ảnh chụp màn hình dưới đây, bạn có thể tìm thấy danh sách các ứng cử viên bằng cách áp dụng bộ lọc “Fill-Mask” trên Hugging Face Hub:
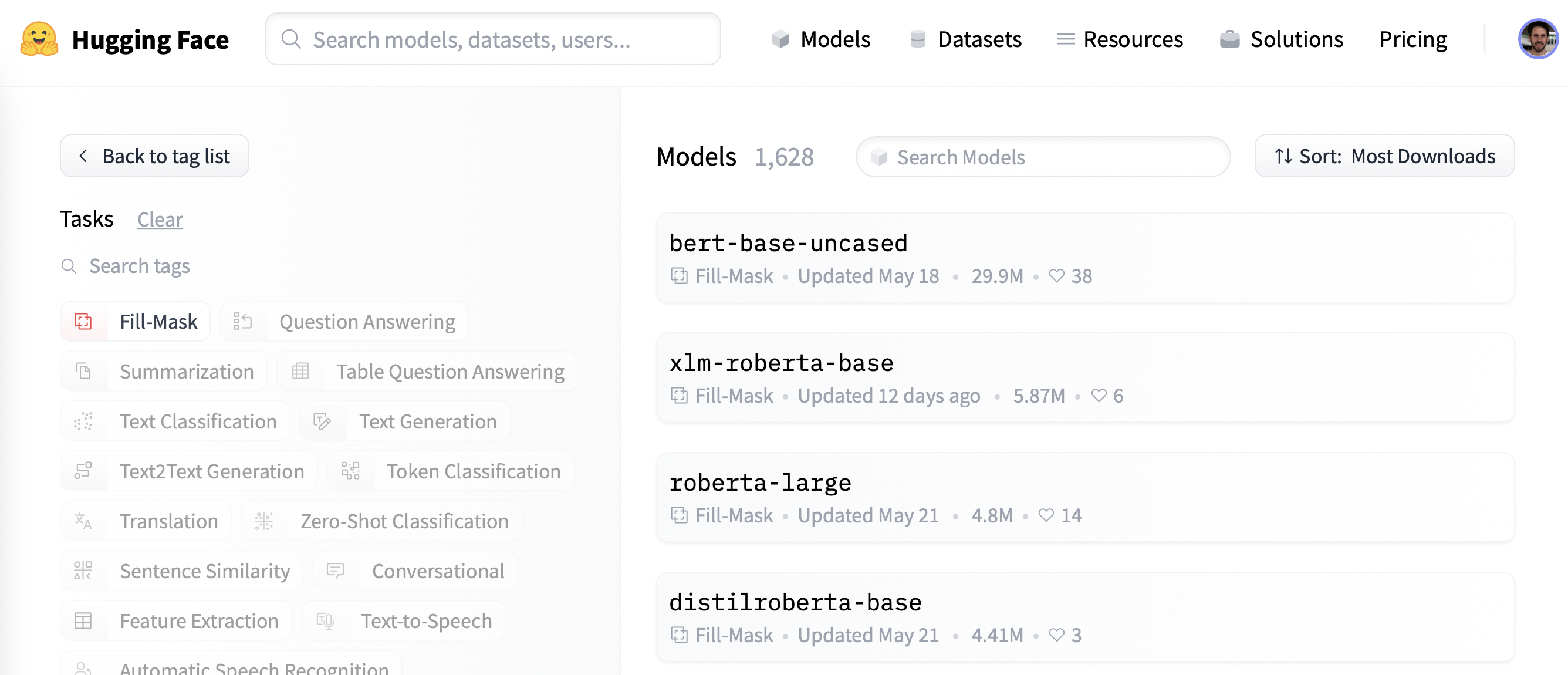
Mặc dù dòng mô hình BERT và RoBERTa được tải xuống nhiều nhất, chúng ta sẽ sử dụng mô hình có tên DistilBERT có thể huấn luyện nhanh hơn nhiều mà ít hoặc không bị mất hiệu suất. Mô hình này được huấn luyện bằng cách sử dụng một kỹ thuật đặc biệt có tên là knowledge distillation, trong đó một “mô hình giáo viên” lớn như BERT được sử dụng để hướng dẫn huấn luyện “mô hình sinh viên” có ít tham số hơn nhiều. Phần giải thích chi tiết về quá trình chắt lọc kiến thức sẽ đưa chúng ta đi quá xa trong phần này, nhưng nếu bạn quan tâm, bạn có thể đọc tất cả về nó trong Natural Language Processing with Transformers (thường được gọi là sách giáo khoa về Transformer).
Hãy tiếp tục và tải xuống DistilBERT bằng cách sử dụng lớp AutoModelForMaskedLM:
from transformers import AutoModelForMaskedLM
model_checkpoint = "distilbert-base-uncased"
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)Chúng ta có thể xem mô hình này có bao nhiêu tham số bằng cách gọi phương thức num_parameters():
distilbert_num_parameters = model.num_parameters() / 1_000_000
print(f"'>>> DistilBERT number of parameters: {round(distilbert_num_parameters)}M'")
print(f"'>>> BERT number of parameters: 110M'")'>>> DistilBERT number of parameters: 67M'
'>>> BERT number of parameters: 110M'Với khoảng 67 triệu tham số, DistilBERT nhỏ hơn khoảng hai lần so với mô hình cơ sở BERT, gần như được hiểu là tăng tốc gấp hai lần khi huấn luyện - thật tuyệt! Bây giờ chúng ta hãy xem những loại token nào mô hình này dự đoán là có nhiều khả năng hoàn thành một mẫu văn bản nhỏ:
text = "This is a great [MASK]."Là con người, chúng ta có thể tưởng tượng ra nhiều khả năng đối với token [MASK], ví dụ “day”, “ride”, hoặc “painting”. Đối với các mô hình được huấn luyện trước, các dự đoán phụ thuộc vào kho ngữ liệu mô hình đó huấn luyện, vì nó học cách chọn các mẫu thống kê có trong dữ liệu. Giống BERT, DistilBERT được huấn luyện trước trên bộ dữ liệu English Wikipedia và BookCorpus, nên ta kì vọng các dự đoán cho [MASK] sẽ phản ánh các mảng này. Để dự đoán ta cần trình tokenizer của DistilBERT tạo ra các đầu vào cho mô hình, vì vậy hãy tải từ Hub:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)Với một tokenizer và một mô hình, ta có thể truyền các đoạn văn ví dụ tới mô hình, trích xuất logits, và xin ra 5 ứng cử viên:
import torch
inputs = tokenizer(text, return_tensors="pt")
token_logits = model(**inputs).logits
# Tìm vị trí [MASK] và trích xuất logit
mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
mask_token_logits = token_logits[0, mask_token_index, :]
# Chọn ứng viên cho [MASK] với logit cao nhất
top_5_tokens = torch.topk(mask_token_logits, 5, dim=1).indices[0].tolist()
for token in top_5_tokens:
print(f"'>>> {text.replace(tokenizer.mask_token, tokenizer.decode([token]))}'")'>>> This is a great deal.'
'>>> This is a great success.'
'>>> This is a great adventure.'
'>>> This is a great idea.'
'>>> This is a great feat.'Chúng ta có thể thấy từ kết quả đầu ra rằng các dự đoán của mô hình đề cập đến các thuật ngữ hàng ngày, điều này có lẽ không có gì đáng ngạc nhiên khi dựa trên nền tảng của Wikipedia tiếng Anh. Hãy xem cách chúng ta có thể thay đổi mảng này thành một thứ gì đó thích hợp hơn một chút - các bài đánh giá phim phân cực cao!
Bộ dữ liệu
Để giới thiệu việc thích ứng chuyên môn, chúng ta sẽ sử dụng bộ dữ liệu nổi tiếng Large Movie Review Dataset(hay viết tắt là IMDb), là tập hợp các bài đánh giá phim thường được dùng để đánh giá các mô hình phân tích cảm xúc. Bằng cách tinh chỉnh DistilBERT trên kho ngữ liệu này, chúng ta hy vọng mô hình ngôn ngữ sẽ điều chỉnh vốn từ vựng của nó từ dữ liệu thực tế của Wikipedia mà nó đã được huấn luyện trước để phù hợp với các yếu tố chủ quan hơn của các bài đánh giá phim. Chúng ta có thể lấy dữ liệu từ Hugging Face Hub bằng hàm load_dataset() từ 🤗 Datasets:
from datasets import load_dataset
imdb_dataset = load_dataset("imdb")
imdb_datasetDatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
test: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
unsupervised: Dataset({
features: ['text', 'label'],
num_rows: 50000
})
})Chúng ta có thể thấy rằng mỗi phần huấn luyện và kiểm thử bao gồm 25,000 đánh giá, trong khi phần không được gắn nhãn được gọi là phi giám sát chứa 50,000 đánh giá. Chúng ta hãy xem một vài mẫu để có ý tưởng về loại văn bản mà ta đang xử lý. Như chúng ta đã thực hiện trong các chương trước của khóa học, chúng ta sẽ xâu chuỗi các hàm Dataset.shuffle() và Dataset.select() để tạo một mẫu ngẫu nhiên:
sample = imdb_dataset["train"].shuffle(seed=42).select(range(3))
for row in sample:
print(f"\n'>>> Review: {row['text']}'")
print(f"'>>> Label: {row['label']}'")
'>>> Review: This is your typical Priyadarshan movie--a bunch of loony characters out on some silly mission. His signature climax has the entire cast of the film coming together and fighting each other in some crazy moshpit over hidden money. Whether it is a winning lottery ticket in Malamaal Weekly, black money in Hera Pheri, "kodokoo" in Phir Hera Pheri, etc., etc., the director is becoming ridiculously predictable. Don\'t get me wrong; as clichéd and preposterous his movies may be, I usually end up enjoying the comedy. However, in most his previous movies there has actually been some good humor, (Hungama and Hera Pheri being noteworthy ones). Now, the hilarity of his films is fading as he is using the same formula over and over again.<br /><br />Songs are good. Tanushree Datta looks awesome. Rajpal Yadav is irritating, and Tusshar is not a whole lot better. Kunal Khemu is OK, and Sharman Joshi is the best.'
'>>> Label: 0'
'>>> Review: Okay, the story makes no sense, the characters lack any dimensionally, the best dialogue is ad-libs about the low quality of movie, the cinematography is dismal, and only editing saves a bit of the muddle, but Sam" Peckinpah directed the film. Somehow, his direction is not enough. For those who appreciate Peckinpah and his great work, this movie is a disappointment. Even a great cast cannot redeem the time the viewer wastes with this minimal effort.<br /><br />The proper response to the movie is the contempt that the director San Peckinpah, James Caan, Robert Duvall, Burt Young, Bo Hopkins, Arthur Hill, and even Gig Young bring to their work. Watch the great Peckinpah films. Skip this mess.'
'>>> Label: 0'
'>>> Review: I saw this movie at the theaters when I was about 6 or 7 years old. I loved it then, and have recently come to own a VHS version. <br /><br />My 4 and 6 year old children love this movie and have been asking again and again to watch it. <br /><br />I have enjoyed watching it again too. Though I have to admit it is not as good on a little TV.<br /><br />I do not have older children so I do not know what they would think of it. <br /><br />The songs are very cute. My daughter keeps singing them over and over.<br /><br />Hope this helps.'
'>>> Label: 1'Đúng, đây chắc chắn là những bài đánh giá phim, và nếu bạn đủ lớn, bạn thậm chí có thể hiểu nhận xét trong bài đánh giá cuối cùng về việc sở hữu phiên bản VHS 😜! Mặc dù chúng ta sẽ không cần nhãn để cho mô hình ngôn ngữ, nhưng chúng ta có thể thấy rằng 0 biểu thị một đánh giá tiêu cực, trong khi 1 tương ứng với một đánh giá tích cực.
✏️ Thử nghiệm thôi! Tạo ra các mẫu ngẫu nhiền từ phần phi giám sát và kiểm định xem nhãn của chúng là 0 hay 1. Khi đang ở đó, bạn cũng có thể kiểm tra xem các nhãn trong phần huấn luyện và kiểm thử có thực sử là 0 hoặc 1 không — đây là một phần kiểm tra hữu ích mànhững nhà NLP nên thực hiện đầu dự án!.
Bây giờ chúng ta đã có một cái nhìn nhanh về dữ liệu, hãy đi sâu vào việc chuẩn bị nó cho việc lập mô hình ngôn ngữ bị ẩn đi. Như chúng ta sẽ thấy, có một số bước bổ sung mà người ta cần thực hiện so với các tác vụ phân loại chuỗi mà chúng ta đã thấy trong Chương 3. Đi thôi!
Tiền xử lý dữ liệu
Đối với cả mô hình ngôn ngữ tự động hồi quy và bị ẩn đi, một bước tiền xử lý phổ biến là nối tất cả các mẫu và sau đó chia toàn bộ ngữ liệu thành các phần có kích thước bằng nhau. Điều này hoàn toàn khác với cách tiếp cận thông thường, khi chúng ta chỉ cần tokenize các mẫu riêng lẻ. Tại sao lại nối mọi thứ lại với nhau? Lý do là các mẫu riêng lẻ có thể bị cắt ngắn nếu chúng quá dài và điều đó sẽ dẫn đến việc mất thông tin có thể hữu ích cho tác vụ mô hình hóa ngôn ngữ!
Vì vậy, để bắt đầu, trước tiên chúng ta sẽ tokenize kho tài liệu của mình như bình thường, nhưng không đặt tùy chọn truncation=True trong trình tokenize của chúng ta. Chúng ta cũng sẽ lấy các ID từ nếu chúng có sẵn ((chúng sẽ có sẵn nếu ta đang sử dụng công cụ tokenize nhanh, như được mô tả trong Chương 6), vì ta sẽ cần chúng sau này để thực hiện che toàn bộ từ. Chúng ta sẽ gói nó trong một hàm đơn giản và trong khi thực hiện, ta sẽ xóa các cột text và label vì không cần chúng nữa:
def tokenize_function(examples):
result = tokenizer(examples["text"])
if tokenizer.is_fast:
result["word_ids"] = [result.word_ids(i) for i in range(len(result["input_ids"]))]
return result
# Dùng batched=True để kích hoạt đa luồng nhanh!
tokenized_datasets = imdb_dataset.map(
tokenize_function, batched=True, remove_columns=["text", "label"]
)
tokenized_datasetsDatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'word_ids'],
num_rows: 25000
})
test: Dataset({
features: ['attention_mask', 'input_ids', 'word_ids'],
num_rows: 25000
})
unsupervised: Dataset({
features: ['attention_mask', 'input_ids', 'word_ids'],
num_rows: 50000
})
})Vì DistilBERT là một mô hình giống như BERT, chúng ta có thể thấy rằng các văn bản được tokenize bao gồm input_ids và attention_mask ta đã thấy trong các chương khác, cũng như word_ids mà ta đã thêm vào.
Gờ chúng ta đã tokenize các bài đánh giá phim của mình, bước tiếp theo là nhóm tất cả chúng lại với nhau và chia kết quả thành nhiều phần. Nhưng những khối này phải lớn đến mức nào? Điều này cuối cùng sẽ được xác định bởi dung lượng bộ nhớ GPU mà bạn có sẵn, nhưng điểm khởi đầu tốt là xem kích thước ngữ cảnh tối đa của mô hình là bao nhiêu. Điều này có thể được suy ra bằng cách kiểm tra thuộc tính model_max_length của tokenizer:
tokenizer.model_max_length
512Giá trị này có nguồn gốc từ tệp tokenizer_config.json được liên kết với một checkpoint; trong trường hợp này, chúng ta có thể thấy rằng kích thước ngữ cảnh là 512 token, giống như với BERT.
✏️ Thử nghiệm thôi! Một số mô hình Transformer, nhưBigBird và Longformer,có độ dài ngữ cảnh dài hơn nhiều so với BERT và các mô hình Transformer đời đầu khác. Khởi tạo tokenizer cho một trong những checkpoint và xác minh rằng model_max_length tương ứng với những gì được trích dẫn trên thẻ mô hình của nó.
Vì vậy, để chạy các thử nghiệm trên GPU như những GPU được tìm thấy trên Google Colab, chúng ta sẽ chọn thứ gì đó nhỏ hơn một chút có thể vừa với bộ nhớ:
chunk_size = 128Lưu ý rằng việc sử dụng kích thước phân đoạn nhỏ có thể gây bất lợi trong các tình huống thực tế, vì vậy bạn nên sử dụng kích thước tương ứng với trường hợp sử dụng mà bạn sẽ áp dụng mô hình của mình.
Bây giờ đến phần thú vị. Để cho biết cách nối hoạt động, hãy lấy một vài bài đánh giá từ bộ huấn luyện được tokenize và in ra số lượng token cho mỗi bài đánh giá:
# Tạo ra một danh sách các danh sách cho từng đặc trưng
tokenized_samples = tokenized_datasets["train"][:3]
for idx, sample in enumerate(tokenized_samples["input_ids"]):
print(f"'>>> Review {idx} length: {len(sample)}'")'>>> Review 0 length: 200'
'>>> Review 1 length: 559'
'>>> Review 2 length: 192'We can then concatenate all these examples with a simple dictionary comprehension, as follows:
concatenated_examples = {
k: sum(tokenized_samples[k], []) for k in tokenized_samples.keys()
}
total_length = len(concatenated_examples["input_ids"])
print(f"'>>> Concatenated reviews length: {total_length}'")'>>> Concatenated reviews length: 951'Tuyệt vời, tổng độ dài đã được kiểm tra - vì vậy bây giờ hãy chia các bài đánh giá được nối thành các phần có kích thước được cung cấp bởi block_size. Để làm như vậy, chúng ta lặp qua các đặc trưng trong concatenated_examples và sử dụng khả năng hiểu danh sách để tạo các phần của từng đặc trưng. Kết quả là một từ điển các khối cho từng đặc trưng:
chunks = {
k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
for k, t in concatenated_examples.items()
}
for chunk in chunks["input_ids"]:
print(f"'>>> Chunk length: {len(chunk)}'")'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 55'Như bạn có thể thấy trong ví dụ này, đoạn cuối thường sẽ nhỏ hơn kích thước đoạn tối đa. Có hai chiến lược chính để giải quyết vấn đề này:
- Bỏ đoạn cuối cùng nếu nó nhỏ hơn
chunk_size. - Đệm đoạn cuối cùng cho đến khi độ dài của nó bằng
chunk_size.
Chúng tôi sẽ thực hiện cách tiếp cận đầu tiên ở đây, vì vậy hãy gói tất cả logic ở trên trong một hàm duy nhất mà chúng tôi có thể áp dụng cho tập dữ liệu được tokenize của mình:
def group_texts(examples):
# Nối tất cả các văn bản
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
# Tính độ dài của các văn bản được nối
total_length = len(concatenated_examples[list(examples.keys())[0]])
# Chúng tôi bỏ đoạn cuối cùng nếu nó nhỏ hơn chunk_size
total_length = (total_length // chunk_size) * chunk_size
# Chia phần theo max_len
result = {
k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
for k, t in concatenated_examples.items()
}
# Tạo cột nhãn mới
result["labels"] = result["input_ids"].copy()
return resultLưu ý rằng trong bước cuối cùng của group_texts(), chúng ta tạo một cột mới labels là bản sao của cột input_ids. Như chúng ta sẽ thấy ngay sau đây, đó là bởi vì trong mô hình ngôn ngữ bị ẩn đi, mục tiêu là dự đoán các token được che ngẫu nhiên trong lô đầu vào và bằng cách tạo cột labels, chúng ta cung cấp sự thật cơ bản cho mô hình ngôn ngữ để học hỏi.
Bây giờ, hãy áp dụng group_texts() cho các tập dữ liệu được tokenize của mình bằng cách sử dụng hàm Dataset.map() đáng tin cậy:
lm_datasets = tokenized_datasets.map(group_texts, batched=True)
lm_datasetsDatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 61289
})
test: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 59905
})
unsupervised: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 122963
})
})Bạn có thể thấy rằng việc nhóm và sau đó phân chia các đoạn văn bản đã tạo ra nhiều mẫu hơn so với 25,000 mẫu ban đầu của chúng ta cho phần tách huấn luyện và kiểm thử. Đó là bởi vì chúng ta hiện có các mẫu liên quan đến token liên tục trải dài trên nhiều mẫu từ kho tài liệu gốc. Bạn có thể thấy điều này một cách rõ ràng bằng cách tìm kiếm các token đặc biệt [SEP] và [CLS] trong một trong các phần:
tokenizer.decode(lm_datasets["train"][1]["input_ids"])".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"Trong ví dụ này, bạn có thể thấy hai bài đánh giá phim trùng nhau, một bài về phim cấp ba và bài còn lại về tình trạng vô gia cư. Hãy cũng xem các nhãn trông như thế nào cho mô hình ngôn ngữ bị ẩn đi:
tokenizer.decode(lm_datasets["train"][1]["labels"])".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"Như mong đợi từ hàm group_texts() của chúng ta ở trên, hàm này trông giống hệt với input_ids đã được giải mã - nhưng sau đó làm thế nào để mô hình của chúng ta có thể học được bất cứ điều gì? Chúng ta đang thiếu một bước quan trọng: chèn token [MASK] ở các vị trí ngẫu nhiên trong đầu vào! Hãy xem cách chúng ta có thể thực hiện điều này một cách nhanh chóng trong quá trình tinh chỉnh bằng công cụ đối chiếu dữ liệu đặc biệt.
Tinh chỉnh DistilBERT với API Trainer
Tinh chỉnh mô hình ngôn ngữ bị ẩn đi gần giống như tinh chỉnh mô hình phân loại chuỗi, giống như chúng ta đã làm trong Chương 3. Sự khác biệt duy nhất là chúng ta cần một trình đối chiếu dữ liệu đặc biệt có thể che giấu ngẫu nhiên một số token trong mỗi lô văn bản. May mắn thay, 🤗 Transformers được chuẩn bị với một DataCollatorForLanguageModeling dành riêng cho tác vụ này. Chúng ta chỉ cần chuyển nó vào tokenizer và tham số mlm_probability để chỉ định phần nào trong số các token cần che. Chúng tôi sẽ chọn 15%, là số được sử dụng cho BERT và một lựa chọn phổ biến trong các tài liệu:
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)Để xem cách hoạt động của việc che ngẫu nhiên, hãy cung cấp một vài mẫu cho trình đối chiếu dữ liệu. Vì nó mong đợi một danh sách các dict, trong đó mỗi dict đại diện cho một đoạn văn bản liền kề, đầu tiên chúng ta lặp tập dữ liệu trước khi cung cấp lô cho bộ đối chiếu. Chúng ta xóa khóa "word_ids" cho trình đối chiếu dữ liệu này vì nó không cần chúng:
samples = [lm_datasets["train"][i] for i in range(2)]
for sample in samples:
_ = sample.pop("word_ids")
for chunk in data_collator(samples)["input_ids"]:
print(f"\n'>>> {tokenizer.decode(chunk)}'")'>>> [CLS] bromwell [MASK] is a cartoon comedy. it ran at the same [MASK] as some other [MASK] about school life, [MASK] as " teachers ". [MASK] [MASK] [MASK] in the teaching [MASK] lead [MASK] to believe that bromwell high\'[MASK] satire is much closer to reality than is " teachers ". the scramble [MASK] [MASK] financially, the [MASK]ful students whogn [MASK] right through [MASK] pathetic teachers\'pomp, the pettiness of the whole situation, distinction remind me of the schools i knew and their students. when i saw [MASK] episode in [MASK] a student repeatedly tried to burn down the school, [MASK] immediately recalled. [MASK]...'
'>>> .... at.. [MASK]... [MASK]... high. a classic line plucked inspector : i\'[MASK] here to [MASK] one of your [MASK]. student : welcome to bromwell [MASK]. i expect that many adults of my age think that [MASK]mwell [MASK] is [MASK] fetched. what a pity that it isn\'t! [SEP] [CLS] [MASK]ness ( or [MASK]lessness as george 宇in stated )公 been an issue for years but never [MASK] plan to help those on the street that were once considered human [MASK] did everything from going to school, [MASK], [MASK] vote for the matter. most people think [MASK] the homeless'Tốt, nó đã hoạt động! Chúng ta có thể thấy rằng [MASK] đã được chèn ngẫu nhiên tại các vị trí khác nhau trong văn bản. Đây sẽ là những token mà mô hình sẽ phải dự đoán trong quá trình huấn luyện - và cái hay của công cụ đối chiếu dữ liệu là nó sẽ ngẫu nhiên chèn [MASK] với mọi lô!
✏️ Thử nghiệm thôi! Chạy đoạn mã trên vài lần để xem việc che ngẫu nhiên diễn ra ngay trước mắt bạn! Đồng thời thử thay thế phương thức tokenizer.decode() bằng tokenizer.convert_ids_to_tokens() để thấy rằng đôi khi một token từ một từ nhất định bị che, chứ không phải những cái khác.
Một tác dụng phụ của việc che ngẫu nhiên là các chỉ số đánh giá của chúng ta sẽ không xác định khi sử dụng Trainer, vì chúng ta sử dụng cùng một công cụ đối chiếu dữ liệu cho các tập huấn luyện và kiểm thủ. Chúng ta sẽ thấy ở phần sau, khi chúng ta xem xét việc tinh chỉnh với 🤗 Accelerate, chúng ta có thể sử dụng tính linh hoạt của vòng đánh giá tùy chỉnh như thế nào để đóng băng tính ngẫu nhiên.
Khi huấn luyện các mô hình để tạo mô hình ngôn ngữ bị ẩn đi, một kỹ thuật có thể được sử dụng là ghép các từ lại với nhau, không chỉ các token riêng lẻ. Cách tiếp cận này được gọi là whole word masking hay che toàn bộ từ. Nếu chúng ta muốn che toàn bộ từ, chúng ta sẽ cần phải tự xây dựng một bộ đối chiếu dữ liệu. Bộ đối chiếu dữ liệu chỉ là một chức năng lấy danh sách các mẫu và chuyển đổi chúng thành một lô, vì vậy hãy làm điều này ngay bây giờ! Chúng ta sẽ sử dụng các ID từ đã tính toán trước đó để tạo bản đồ giữa các chỉ số từ và các mã thông báo tương ứng, sau đó quyết định ngẫu nhiên những từ nào cần che và che các đầu vào. Lưu ý rằng tất cả các nhãn đều là -100 ngoại trừ các nhãn tương ứng với các từ bị che.
import collections
import numpy as np
from transformers import default_data_collator
wwm_probability = 0.2
def whole_word_masking_data_collator(features):
for feature in features:
word_ids = feature.pop("word_ids")
# Tạo ra ánh xạ giữa các từ và chỉ mục token tương ứng
mapping = collections.defaultdict(list)
current_word_index = -1
current_word = None
for idx, word_id in enumerate(word_ids):
if word_id is not None:
if word_id != current_word:
current_word = word_id
current_word_index += 1
mapping[current_word_index].append(idx)
# Che ngẫu nhiền từ
mask = np.random.binomial(1, wwm_probability, (len(mapping),))
input_ids = feature["input_ids"]
labels = feature["labels"]
new_labels = [-100] * len(labels)
for word_id in np.where(mask)[0]:
word_id = word_id.item()
for idx in mapping[word_id]:
new_labels[idx] = labels[idx]
input_ids[idx] = tokenizer.mask_token_id
feature["labels"] = new_labels
return default_data_collator(features)Tiếp theo, ta cso thể thử trên một vài mẫu như trên:
samples = [lm_datasets["train"][i] for i in range(2)]
batch = whole_word_masking_data_collator(samples)
for chunk in batch["input_ids"]:
print(f"\n'>>> {tokenizer.decode(chunk)}'")'>>> [CLS] bromwell high is a cartoon comedy [MASK] it ran at the same time as some other programs about school life, such as " teachers ". my 35 years in the teaching profession lead me to believe that bromwell high\'s satire is much closer to reality than is " teachers ". the scramble to survive financially, the insightful students who can see right through their pathetic teachers\'pomp, the pettiness of the whole situation, all remind me of the schools i knew and their students. when i saw the episode in which a student repeatedly tried to burn down the school, i immediately recalled.....'
'>>> .... [MASK] [MASK] [MASK] [MASK]....... high. a classic line : inspector : i\'m here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn\'t! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless'✏️ Thử nghiệm thôi! Chạy đoạn mã trên vài lần để xem việc che ngẫu nhiên diễn ra ngay trước mắt bạn! Đồng thời thử thay thế phương thức tokenizer.decode() bằng tokenizer.convert_ids_to_tokens() để thấy rằng đôi khi một token từ một từ nhất định bị che, chứ không phải những cái khác.
Giờ chúng ta có hai trình đối chiếu dữ liệu, phần còn lại của các bước tinh chỉnh là tiêu chuẩn. Quá trình huấn luyện có thể mất một khoảng thời gian trên Google Colab nếu bạn không đủ may mắn để đạt được GPU P100 thần thoại 😭, vì vậy, trước tiên chúng ta sẽ giảm kích thước của tập huấn luyện xuống còn vài nghìn mẫu. Đừng lo lắng, chúng ta sẽ vẫn nhận được một mô hình ngôn ngữ khá tốt! Một cách nhanh chóng để giảm mẫu một tập dữ liệu trong 🤗 Datasets là thông qua hàm Dataset.train_test_split() mà chúng ta đã thấy trong Chapter 5:
train_size = 10_000
test_size = int(0.1 * train_size)
downsampled_dataset = lm_datasets["train"].train_test_split(
train_size=train_size, test_size=test_size, seed=42
)
downsampled_datasetDatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 10000
})
test: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 1000
})
})Điều này đã tự động tạo các phần tách huấn luyện và kiểm thử mới, với kích thước tập huấn luyện được đặt thành 10,000 mẫu và xác thực được đặt thành 10% - vui lòng tăng điều này nếu bạn có GPU mạnh! Điều tiếp theo chúng ta cần làm là đăng nhập vào Hugging Face Hub. Nếu bạn đang chạy mã này trong notebook, bạn có thể làm như vậy với chức năng tiện ích sau:
from huggingface_hub import notebook_login
notebook_login()sẽ hiển thị một tiện ích mà bạn có thể nhập thông tin đăng nhập của mình. Ngoài ra, bạn có thể chạy:
huggingface-cli logintrong thiết bị đầu cuối yêu thích của bạn và đăng nhập ở đó.
Khi đã đăng nhập, chúng ta có thể chỉ định các tham số cho Trainer:
from transformers import TrainingArguments
batch_size = 64
# In ra sự mất mát khi huấn luyện ở mỗi epoch
logging_steps = len(downsampled_dataset["train"]) // batch_size
model_name = model_checkpoint.split("/")[-1]
training_args = TrainingArguments(
output_dir=f"{model_name}-finetuned-imdb",
overwrite_output_dir=True,
evaluation_strategy="epoch",
learning_rate=2e-5,
weight_decay=0.01,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
push_to_hub=True,
fp16=True,
logging_steps=logging_steps,
)Ở đây, chúng ta đã điều chỉnh một số tùy chọn mặc định, bao gồm log_steps để đảm bảo theo dõi sự mất mát trong quá trình huấn luyện theo từng epoch. Chúng ta cũng đã sử dụng fp16=True để cho phép huấn luyện chính xác hỗn hợp, giúp tăng tốc độ. Theo mặc định, Trainer sẽ loại bỏ bất kỳ cột nào không phải là một phần của phương thức forward() của mô hình. Điều này có nghĩa là nếu bạn đang sử dụng công cụ che toàn bộ từ, bạn cũng cần đặt remove_unused_columns=False để đảm bảo chúng ta không mất cột word_ids trong quá trình huấn luyện.
Lưu ý rằng bạn có thể chỉ định tên của kho lưu trữ mà bạn muốn đẩy đến bằng tham số hub_model_id (cụ thể là bạn sẽ phải sử dụng tham số này để đẩy đến một tổ chức). Ví dụ: khi chúng ta đẩy mô hình vào tổ chức huggingface-course, chúng ta đã thêm hub_model_id="huggingface-course/distilbert-finetuned-imdb" vào TrainingArguments. Theo mặc định, kho lưu trữ được sử dụng sẽ nằm trong không gian tên của bạn và được đặt tên theo thư mục đầu ra mà bạn đã đặt, vì vậy trong trường hợp của chúng ta, nó sẽ là"lewtun/distilbert-finetuned-imdb".
Bây giờ chúng ta có tất cả các thành phần để tạo ra Trainer. Ở đây chúng ta chỉ sử dụng data_collator tiêu chuẩn, nhưng bạn có thể thử toàn bộ công cụ che toàn bộ từ và so sánh kết quả như một bài tập:
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=downsampled_dataset["train"],
eval_dataset=downsampled_dataset["test"],
data_collator=data_collator,
tokenizer=tokenizer,
)Giờ chúng ta đã sẵn sàng chạy trainer.train() - nhưng trước khi làm như vậy, chúng ta hãy xem xét ngắn gọn perplexity, là một chỉ số phổ biến để đánh giá hiệu suất của các mô hình ngôn ngữ.
Perplexity cho mô hình ngôn ngữ
Không giống như các tác vụ khác như phân loại văn bản hoặc hỏi đáp mà chúng ta được cung cấp một kho ngữ liệu được gắn nhãn để huấn luyện, với mô hình ngôn ngữ, ta không có bất kỳ nhãn rõ ràng nào. Vậy làm cách nào để xác định điều gì tạo nên một mô hình ngôn ngữ tốt? Giống như tính năng tự động sửa lỗi trong điện thoại của bạn, một mô hình ngôn ngữ tốt là một mô hình ngôn ngữ chỉ định xác suất cao cho các câu đúng ngữ pháp và xác suất thấp cho các câu vô nghĩa. Để giúp bạn biết rõ hơn về hình thức này, bạn có thể tìm thấy toàn bộ tập hợp “tự động sửa lỗi” trực tuyến, trong đó mô hình trong điện thoại đã tạo ra một số hoàn thành khá hài hước (và thường không phù hợp)!
Giả sử bộ kiểm thử của chúng ta bao gồm hầu hết các câu đúng ngữ pháp, thì một cách để đo lường chất lượng của mô hình ngôn ngữ là tính toán xác suất nó gán cho từ tiếp theo trong tất cả các câu của bộ kiểm thử. Khả năng xảy ra cao chỉ ra rằng mô hình không bị “ngạc nhiên” hoặc “bối rối” bởi các mẫu không nhìn thấy và cho thấy nó đã học được các mẫu ngữ pháp cơ bản trong ngôn ngữ. Có nhiều định nghĩa toán học khác nhau về perplexity, nhưng chúng ta sẽ sử dụng định nghĩa là hàm mũ của mất mát entropy chéo. Do đó, chúng ta có thể tính toán perplexity của mô hình được huấn luyện trước của mình bằng cách sử dụng hàm Trainer.evaluate() để tính toán mất mát entropy chéo trên tập kiểm thử và sau đó lấy theo cấp số nhân của kết quả:
import math
eval_results = trainer.evaluate()
print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")>>> Perplexity: 21.75Perplexity thấp hơn có nghĩa là một mô hình ngôn ngữ tốt hơn và chúng ta có thể thấy ở đây rằng mô hình bắt đầu của chúng ta có một giá trị hơi lớn. Hãy xem liệu chúng ta có thể hạ thấp nó bằng cách tinh chỉnh không! Để làm điều đó, trước tiên chúng ta chạy vòng lặp huấn luyện:
trainer.train()
và sau đó tính kết quả perplexity trên tập kiểm thử:
eval_results = trainer.evaluate()
print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")>>> Perplexity: 11.32Tốt — nó giảm perplexity, cho thấy mô hình đã học được điều gì đó về mảng đánh giá phim!
Sau khi quá trình huấn luyện kết thúc, chúng ta có thể đẩy thẻ mô hình có thông tin huấn luyện vào Hub (các checkpoint được lưu trong quá trình tự huấn luyện):
Once training is finished, we can push the model card with the training information to the Hub (the checkpoints are saved during training itself):
trainer.push_to_hub()
✏️ Đến lượt bạn! Chạy bướchuấn luyện trên sau khi thay đổi trình thu thập dữ liệu thành che toàn bộ từ. Bạn có nhận được kết quả tốt hơn không?
Trong trường hợp của mình, chúng ta không cần làm gì đặc biệt với vòng huấn luyện, nhưng một số trường hợp bạn sẽ cần phải triển khai một số logic tuỳ chỉnh. Với những ứng dụng này, bạn có thể sử dụng 🤗 Accelerate — hãy cũng xem xem!
Tinh chỉnh DistilBERT với 🤗 Accelerate
Như chúng ta đã thấy với Trainer, việc tinh chỉnh mô hình ngôn ngữ bị ản đi rất giống với ví dụ phân loại văn bản từ Chapter 3. Trên thực tế, sự tinh tế duy nhất là việc sử dụng một công cụ đối chiếu dữ liệu đặc biệt và chúng ta đã đề cập đến điều đó trước đó trong phần này!
Tuy nhiên, chúng ta thấy rằng DataCollatorForLanguageModeling cũng áp dụng tính năng che ngẫu nhiên với mỗi lần đánh giá, vì vậy chúng ta sẽ thấy một số biến động về perplexity với mỗi lần chạy huấn luyện. Một cách để loại bỏ tính ngẫu nhiên này là áp dụng che chỉ một lần trên toàn bộ tập kiểm thử, sau đó sử dụng trình đối chiếu dữ liệu mặc định trong 🤗 Transformers để thu thập các lô trong quá trình đánh giá. Để xem cách này hoạt động như thế nào, hãy triển khai một chức năng đơn giản áp dụng che trên một lô, tương tự như lần đầu của chúng ta với DataCollatorForLanguageModeling:
def insert_random_mask(batch):
features = [dict(zip(batch, t)) for t in zip(*batch.values())]
masked_inputs = data_collator(features)
# Tạo ra một cột "masked" mới cho mỗi cột trong bộ dữ liệu
return {"masked_" + k: v.numpy() for k, v in masked_inputs.items()}Tiếp theo, chúng ta sẽ áp dụng chức năng này cho tập kiểm thử của mình và bỏ các cột không che để có thể thay thế chúng bằng những cột bị che. Bạn có thể sử dụng che toàn bộ từ bằng cách thay thế data_collator ở trên bằng cái thích hợp, trong trường hợp đó, bạn nên xóa dòng đầu tiên tại đây:
downsampled_dataset = downsampled_dataset.remove_columns(["word_ids"])
eval_dataset = downsampled_dataset["test"].map(
insert_random_mask,
batched=True,
remove_columns=downsampled_dataset["test"].column_names,
)
eval_dataset = eval_dataset.rename_columns(
{
"masked_input_ids": "input_ids",
"masked_attention_mask": "attention_mask",
"masked_labels": "labels",
}
)Sau đó, chúng ta có thể thiết lập bộ lưu dữ liệu như bình thường, nhưng ta sẽ sử dụng default_data_collator từ 🤗 Transformers cho tập kiểm định:
from torch.utils.data import DataLoader
from transformers import default_data_collator
batch_size = 64
train_dataloader = DataLoader(
downsampled_dataset["train"],
shuffle=True,
batch_size=batch_size,
collate_fn=data_collator,
)
eval_dataloader = DataLoader(
eval_dataset, batch_size=batch_size, collate_fn=default_data_collator
)Từ đây, chúng ta làm theo các bước tiêu chuẩn với 🤗 Accelerate. Yêu cầu đầu tiên của công việc là tải một phiên bản mới của mô hình được huấn luyện trước:
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)Sau đó, chúng ta cần chỉ định trình tối ưu hóa; chúng ta sẽ sử dụng tiêu chuẩn AdamW:
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=5e-5)Với những đối tượng này, bây giờ chúng ta có thể chuẩn bị mọi thứ cho quá trình huấn luyện với đối tượng Accelerator:
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)Bây giờ mô hình, trình tối ưu hóa và bộ ghi dữ liệu của chúng ta đã được định cấu hình, chúng ta có thể chỉ định bộ lập lịch tốc độ học như sau:
from transformers import get_scheduler
num_train_epochs = 3
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)Chỉ có một điều cuối cùng cần làm trước khi huấn luyện: tạo một kho lưu trữ mô hình trên Hugging Face Hub! Trước tiên, chúng ta có thể sử dụng thư viện 🤗 Hub để tạo tên đầy đủ cho repo của mình:
from huggingface_hub import get_full_repo_name
model_name = "distilbert-base-uncased-finetuned-imdb-accelerate"
repo_name = get_full_repo_name(model_name)
repo_name'lewtun/distilbert-base-uncased-finetuned-imdb-accelerate'sau đó tạo và sao chép kho lưu trữ bằng cách sử dụng lớp Repository từ 🤗 Hub:
from huggingface_hub import Repository
output_dir = model_name
repo = Repository(output_dir, clone_from=repo_name)Sau khi thực hiện xong, việc viết ra toàn bộ vòng lặp huấn luyện và đánh giá chỉ là một vấn đề đơn giản:
from tqdm.auto import tqdm
import torch
import math
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
# Huấn luyện
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# Đánh giá
model.eval()
losses = []
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
losses.append(accelerator.gather(loss.repeat(batch_size)))
losses = torch.cat(losses)
losses = losses[: len(eval_dataset)]
try:
perplexity = math.exp(torch.mean(losses))
except OverflowError:
perplexity = float("inf")
print(f">>> Epoch {epoch}: Perplexity: {perplexity}")
# Lưu và tải
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False
)>>> Epoch 0: Perplexity: 11.397545307900472
>>> Epoch 1: Perplexity: 10.904909330983092
>>> Epoch 2: Perplexity: 10.729503505340409Tuyệt vời, chúng tôi đã có thể đánh giá mức độ phức tạp theo từng epoch và đảm bảo rằng nhiều lần chạy huấn luyện có thể tái tạo!
Sử dụng mô hình tinh chỉnh của mình
ạn có thể tương tác với mô hình đã được tinh chỉnh của mình bằng cách sử dụng tiện ích của nó trên Hub hoặc cục bộ với pipeline từ 🤗 Transformers. Hãy sử dụng cái sau để tải xuống mô hình của chúng tôi bằng cách sử dụng pipeline fill-mask:
from transformers import pipeline
mask_filler = pipeline(
"fill-mask", model="huggingface-course/distilbert-base-uncased-finetuned-imdb"
)Sau đó, chúng ta có thể cung cấp văn bản mẫu “This is a great [MASK]” và xem 5 dự đoán đầu là gì:
preds = mask_filler(text)
for pred in preds:
print(f">>> {pred['sequence']}")'>>> this is a great movie.'
'>>> this is a great film.'
'>>> this is a great story.'
'>>> this is a great movies.'
'>>> this is a great character.'Gọn gàng - mô hình của chúng ta rõ ràng đã điều chỉnh trọng số của nó để dự đoán các từ liên quan nhiều hơn đến phim!
Điều này kết thúc thử nghiệm đầu tiên của chúng ta với việc huấn luyện một mô hình ngôn ngữ. Trong phần 6, bạn sẽ học cách huấn luyện một mô hình tự động hồi quy như GPT-2 từ đầu; hãy đến đó nếu bạn muốn xem cách bạn có thể huấn luyện trước mô hình Transformer của riêng mình!
✏️ Thử nghiệm thôi! Để định lượng lợi ích của việc thích ứng chuyên môn, hãy tinh chỉnh bộ phân loại trên các nhãn IMDb cho cả các checkpoint DistilBERT được huấn luyện trước và tinh chỉnh. Nếu bạn cần bồi dưỡng về phân loại văn bản, hãy xem Chương 3.