O que fazer quando ocorrer um erro

Nesta seção, veremos alguns erros comuns que podem ocorrer ao tentar gerar previsões de seu modelo Transformer recém treinado. Isso irá prepará-lo para a seção 4, onde exploraremos como debugar a própria fase de treinamento.
Preparamos um repositório modelo para esta seção e, se você quiser executar o código neste capítulo, Primeiro, você precisará copiar o modelo para sua conta no Hugging Face Hub. Para fazer isso, primeiro faça login executando o seguinte em um notebook Jupyter:
from huggingface_hub import notebook_login
notebook_login()ou usando seu terminal favorito:
huggingface-cli login
Isso solicitará que você insira seu nome de usuário e senha e salvará um token em ~/.cache/huggingface/. Depois de fazer login, você pode copiar o repositório de modelos com a seguinte função:
from distutils.dir_util import copy_tree
from huggingface_hub import Repository, snapshot_download, create_repo, get_full_repo_name
def copy_repository_template():
# Clone the repo and extract the local path
template_repo_id = "lewtun/distilbert-base-uncased-finetuned-squad-d5716d28"
commit_hash = "be3eaffc28669d7932492681cd5f3e8905e358b4"
template_repo_dir = snapshot_download(template_repo_id, revision=commit_hash)
# Create an empty repo on the Hub
model_name = template_repo_id.split("/")[1]
create_repo(model_name, exist_ok=True)
# Clone the empty repo
new_repo_id = get_full_repo_name(model_name)
new_repo_dir = model_name
repo = Repository(local_dir=new_repo_dir, clone_from=new_repo_id)
# Copy files
copy_tree(template_repo_dir, new_repo_dir)
# Push to Hub
repo.push_to_hub()Agora, quando você chamar copy_repository_template(), ele criará uma cópia do repositório de modelos em sua conta.
Debugando o pipeline de 🤗 Transformers
Para iniciar nossa jornada no maravilhoso mundo de debug de modelos Transformer, considere o seguinte cenário: você está trabalhando com um colega em um projeto de resposta a perguntas para ajudar os clientes de um site de comércio eletrônico a encontrar respostas sobre produtos de consumo. Seu colega lhe envia uma mensagem como:
Bom dia! Acabei de fazer um experimento usando as técnicas do Capítulo 7 do curso Hugging Face e obtive ótimos resultados no SQuAD! Acho que podemos usar esse modelo como checkpoint para o nosso projeto. O ID do modelo no Hub é “lewtun/distillbert-base-uncased-finetuned-squad-d5716d28”. Fique a vontade para testar :)
e a primeira coisa que você pensa é carregar o modelo usando o pipeline de 🤗 Transformers:
from transformers import pipeline
model_checkpoint = get_full_repo_name("distillbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""Oh não, algo parece ter dado errado! Se você é novo em programação, esse tipo de erro pode parecer um pouco enigmático no começo (o que é mesmo um OSError?!). O erro exibido aqui é apenas a última parte de um relatório de erros muito maior chamado Python traceback (também conhecido como stack trace). Por exemplo, se você estiver executando este código no Google Colab, deverá ver algo como a captura de tela a seguir:
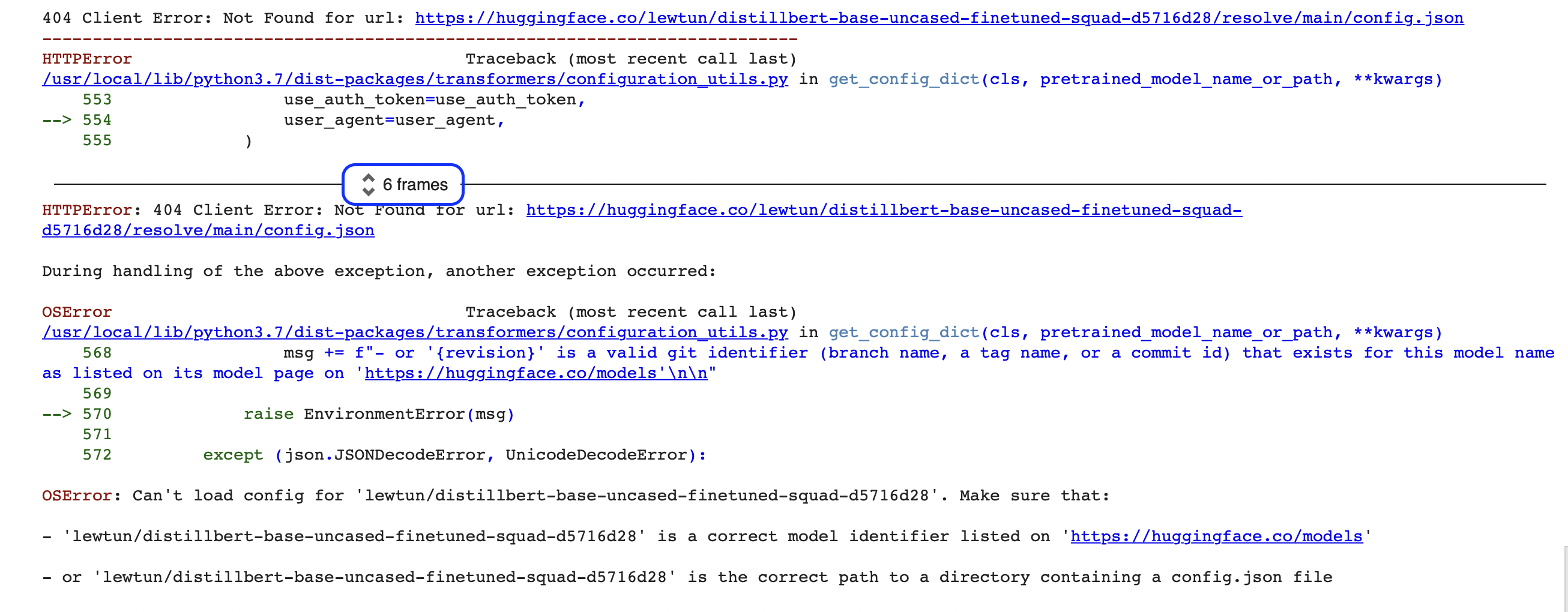
Há muitas informações contidas nesses relatórios, então vamos percorrer as partes principais juntos. A primeira coisa a notar é que os tracebacks devem ser lidos de baixo para cima. Isso pode soar estranho se você está acostumado a ler texto em inglês de cima para baixo, mas reflete o fato de que o traceback mostra a sequência de chamadas de função que o pipeline faz ao baixar o modelo e o tokenizer. (Confira o Capítulo 2 para mais detalhes sobre como o pipeline funciona nos bastidores.)
🚨 Está vendo aquela caixa azul em torno de “6 frames” no traceback do Google Colab? Esse é um recurso especial do Colab, que compacta o traceback em “quadros”. Se você não conseguir encontrar a fonte de um erro, certifique-se de expandir o rastreamento completo clicando nessas duas pequenas setas.
Isso significa que a última linha do traceback indica a última mensagem de erro e fornece o nome da exceção que foi gerada. Nesse caso, o tipo de exceção é OSError, que indica um erro relacionado ao sistema. Se lermos a mensagem de erro que a acompanha, veremos que parece haver um problema com o arquivo config.json do modelo e recebemos duas sugestões para corrigi-lo:
"""
Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""💡 Se você encontrar uma mensagem de erro difícil de entender, basta copiar e colar a mensagem na barra de pesquisa do Google ou Stack Overflow (sim, sério!). Há uma boa chance de você não ser a primeira pessoa a encontrar o erro, e essa é uma boa maneira de encontrar soluções que outras pessoas da comunidade postaram. Por exemplo, pesquisar por OSError: Can't load config for no Stack Overflow fornece vários hits que poderia ser usado como ponto de partida para resolver o problema.
A primeira sugestão é nos pedir para verificar se o ID do modelo está realmente correto, então a primeira ordem do dia é copiar o identificador e colá-lo na barra de pesquisa do Hub:

Hmm, realmente parece que o modelo do nosso colega não está no Hub… aha, mas há um erro de digitação no nome do modelo! DistilBERT tem apenas um “l” em seu nome, então vamos corrigir isso e procurar por “lewtun/distilbert-base-uncased-finetuned-squad-d5716d28”:

Ok, isso teve sucesso. Agora vamos tentar baixar o modelo novamente com o ID do modelo correto:
model_checkpoint = get_full_repo_name("distilbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""Argh, frustrado novamente - bem-vindo ao cotidiano de um engenheiro de aprendizado de máquina! Como corrigimos o ID do modelo, o problema deve estar no próprio repositório. Uma maneira rápida de acessar o conteúdo de um repositório no 🤗 Hub é através da função list_repo_files() da biblioteca huggingface_hub:
from huggingface_hub import list_repo_files
list_repo_files(repo_id=model_checkpoint)['.gitattributes', 'README.md', 'pytorch_model.bin', 'special_tokens_map.json', 'tokenizer_config.json', 'training_args.bin', 'vocab.txt']Interessante — não parece haver um arquivo config.json no repositório! Não é à toa que nosso pipeline não conseguiu carregar o modelo; nosso colega deve ter esquecido de enviar este arquivo para o Hub depois de ajustá-lo. Nesse caso, o problema parece bem simples de corrigir: poderíamos pedir para adicionar o arquivo ou, como podemos ver no ID do modelo, que o modelo pré-treinado usado foi [distilbert-base-uncased](https:/ /huggingface.co/distilbert-base-uncased), podemos baixar a configuração para este modelo e enviá-la para nosso repositório para ver se isso resolve o problema. Vamos tentar isso. Usando as técnicas que aprendemos no Capítulo 2, podemos baixar a configuração do modelo com a classe AutoConfig:
from transformers import AutoConfig
pretrained_checkpoint = "distilbert-base-uncased"
config = AutoConfig.from_pretrained(pretrained_checkpoint)🚨 A abordagem que estamos tomando aqui não é infalível, já que nosso colega pode ter ajustado a configuração de distilbert-base-uncased antes de ajustar o modelo. Na vida real, gostaríamos de verificar com eles primeiro, mas para os propósitos desta seção, vamos supor que eles usaram a configuração padrão.
Podemos então enviar isso para o nosso repositório de modelos com a função push_to_hub() da configuração:
config.push_to_hub(model_checkpoint, commit_message="Add config.json")Agora podemos testar se funcionou carregando o modelo do último commit no branch main:
reader = pipeline("question-answering", model=model_checkpoint, revision="main")
context = r"""
Extractive Question Answering is the task of extracting an answer from a text
given a question. An example of a question answering dataset is the SQuAD
dataset, which is entirely based on that task. If you would like to fine-tune a
model on a SQuAD task, you may leverage the
examples/pytorch/question-answering/run_squad.py script.
🤗 Transformers is interoperable with the PyTorch, TensorFlow, and JAX
frameworks, so you can use your favourite tools for a wide variety of tasks!
"""
question = "What is extractive question answering?"
reader(question=question, context=context){'score': 0.38669535517692566,
'start': 34,
'end': 95,
'answer': 'the task of extracting an answer from a text given a question'}Uhuuul, funcionou! Vamos recapitular o que você acabou de aprender:
- As mensagens de erro em Python são conhecidas como tracebacks e são lidas de baixo para cima. A última linha da mensagem de erro geralmente contém as informações necessárias para localizar a origem do problema.
- Se a última linha não contiver informações suficientes, suba o traceback e veja se você consegue identificar onde no código-fonte o erro ocorre.
- Se nenhuma das mensagens de erro puder ajudá-lo a debugar o problema, tente pesquisar online uma solução para um problema semelhante.
- O
huggingface_hub// 🤗 Hub? esta biblioteca fornece um conjunto de ferramentas que você pode usar para interagir e debugar repositórios no Hub.
Agora que você sabe como debugar um pipeline, vamos dar uma olhada em um exemplo mais complicado no forward pass do próprio modelo.
Debugando o forward pass do seu modelo
Embora o pipeline seja ótimo para a maioria dos aplicativos em que você precisa gerar previsões rapidamente, às vezes você precisará acessar os logits do modelo (digamos, se você tiver algum pós-processamento personalizado que gostaria de aplicar). Para ver o que pode dar errado neste caso, vamos primeiro pegar o modelo e o tokenizer do nosso pipeline:
tokenizer = reader.tokenizer model = reader.model
Em seguida, precisamos de uma pergunta, então vamos ver se nossos frameworks favoritos são suportados:
question = "Which frameworks can I use?"Como vimos no Capítulo 7, as etapas usuais que precisamos seguir são tokenizar as entradas, extrair os logits dos tokens de início e fim e, em seguida, decodificar o intervalo de resposta:
import torch
inputs = tokenizer(question, context, add_special_tokens=True)
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# Get the most likely beginning of answer with the argmax of the score
answer_start = torch.argmax(answer_start_scores)
# Get the most likely end of answer with the argmax of the score
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/var/folders/28/k4cy5q7s2hs92xq7_h89_vgm0000gn/T/ipykernel_75743/2725838073.py in <module>
1 inputs = tokenizer(question, text, add_special_tokens=True)
2 input_ids = inputs["input_ids"]
----> 3 outputs = model(**inputs)
4 answer_start_scores = outputs.start_logits
5 answer_end_scores = outputs.end_logits
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, start_positions, end_positions, output_attentions, output_hidden_states, return_dict)
723 return_dict = return_dict if return_dict is not None else self.config.use_return_dict
724
--> 725 distilbert_output = self.distilbert(
726 input_ids=input_ids,
727 attention_mask=attention_mask,
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'
"""Oxii, parece que temos um bug em nosso código! Mas não temos medo de debugar um pouco. Você pode usar o debugger do Python em um notebook:
ou em um terminal:
Aqui, a leitura da mensagem de erro nos diz que o objeto 'list' não tem atributo 'size', e podemos ver uma seta --> apontando para a linha onde o problema foi levantado em model(**inputs) . Você pode debugar isso interativamente usando o debugger Python, mas por enquanto vamos simplesmente imprimir uma fatia de entradas para ver o que temos:
inputs["input_ids"][:5][101, 2029, 7705, 2015, 2064]Isso certamente se parece com uma lista comum do Python, mas vamos verificar novamente o tipo:
type(inputs["input_ids"])listSim, isso é uma lista do Python com certeza. Então o que deu errado? Lembre-se do Capítulo 2 que as classes AutoModelForXxx em 🤗 Transformers operam em tensors (em PyTorch ou TensorFlow), e uma operação comum é extrair as dimensões de um tensor usando Tensor.size( ) em, digamos, PyTorch. Vamos dar outra olhada no traceback, para ver qual linha acionou a exceção:
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'Parece que nosso código tentou chamar input_ids.size(), mas isso claramente não funcionará para uma list Python, que é apenas um contêiner. Como podemos resolver este problema? Pesquisar a mensagem de erro no Stack Overflow fornece alguns [hits] relevantes (https://stackoverflow.com/search?q=AttributeError%3A+%27list%27+object+has+no+attribute+%27size%27&s=c15ec54c-63cb-481d-a749-408920073e8f). Clicar no primeiro exibe uma pergunta semelhante à nossa, com a resposta mostrada na captura de tela abaixo:
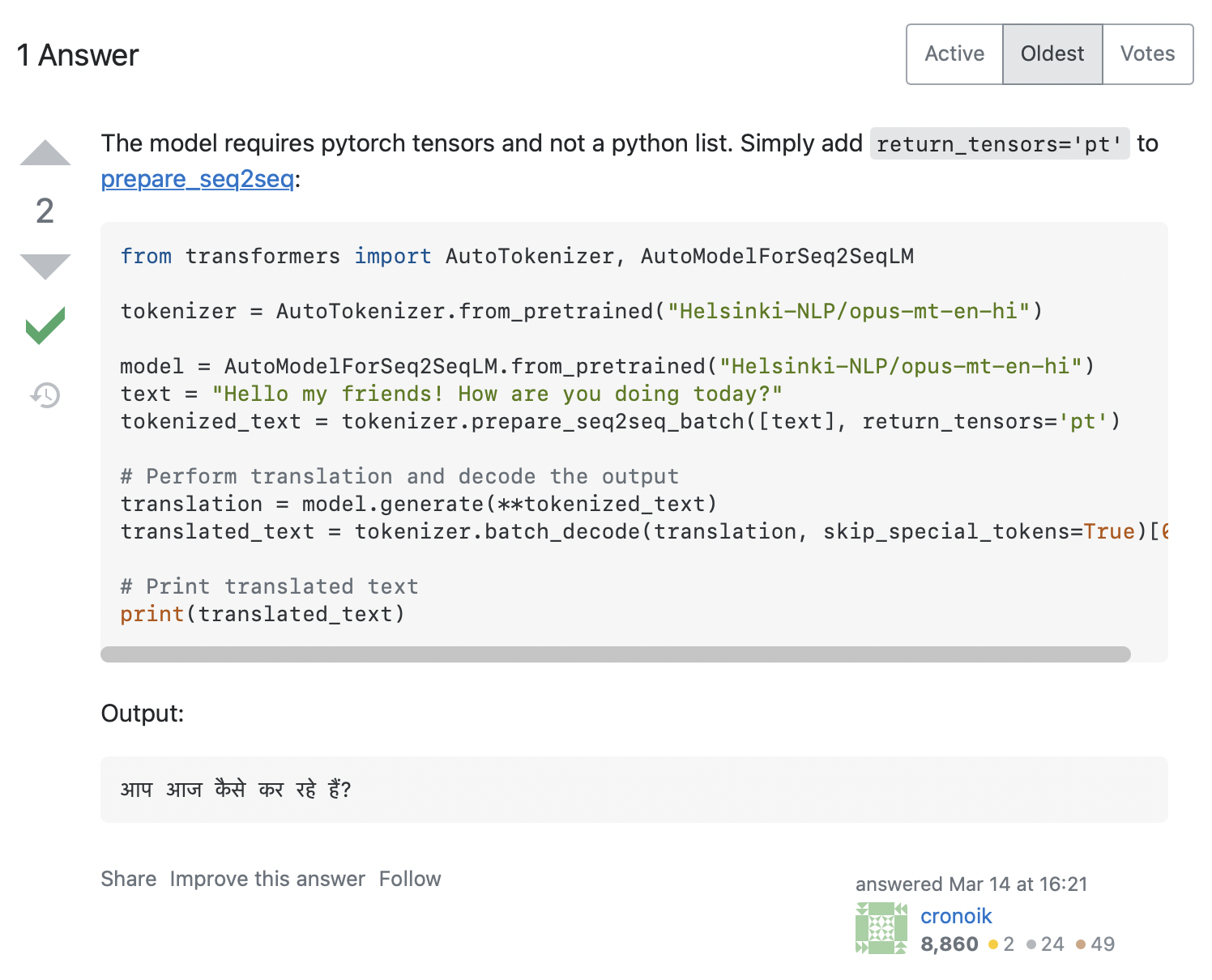
A resposta recomenda que adicionemos return_tensors='pt' ao tokenizer, então vamos ver se isso funciona para nós:
inputs = tokenizer(question, context, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# Get the most likely beginning of answer with the argmax of the score
answer_start = torch.argmax(answer_start_scores)
# Get the most likely end of answer with the argmax of the score
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
Question: Which frameworks can I use?
Answer: pytorch, tensorflow, and jax
"""Legal, funcionou! Este é um ótimo exemplo de como o Stack Overflow pode ser útil: ao identificar um problema semelhante, pudemos nos beneficiar da experiência de outras pessoas da comunidade. No entanto, uma pesquisa como essa nem sempre produz uma resposta relevante, então o que você pode fazer nesses casos? Felizmente, há uma comunidade acolhedora de desenvolvedores nos fóruns do Hugging Face que pode ajudá-lo! Na próxima seção, veremos como você pode criar boas perguntas no fórum que provavelmente serão respondidas.