Criando seu próprio dataset

Às vezes, o conjunto de dados de que você precisa para criar um aplicativo de PLN não existe, portanto, você mesmo precisará criá-lo. Nesta seção, mostraremos como criar um corpus de issues do GitHub, que são comumente usados para rastrear bugs ou recursos nos repositórios do GitHub. Este corpus pode ser usado para vários fins, incluindo:
- Explorar quanto tempo leva para fechar as issues abertos ou pull requests
- Treinar um classificador multilabel que pode marcar issues com metadados com base na descrição da issue (por exemplo, “bug”, “melhoria” ou “pergunta”)
- Criando um mecanismo de pesquisa semântica para descobrir quais issues correspondem à consulta de um usuário
Aqui nos concentraremos na criação do corpus e, na próxima seção, abordaremos o aplicativo de pesquisa semântica. Para manter a meta, usaremos as issues do GitHub associados a um projeto de código aberto popular: 🤗 Datasets! Vamos dar uma olhada em como obter os dados e explorar as informações contidas nessas edições.
Obtendo os dados
Você pode encontrar todos as issues em 🤗 Datasets navegando até a guia de issues do repositório. Conforme mostrado na captura de tela a seguir, no momento da redação, havia 331 issues abertos e 668 fechados.

Se você clicar em uma dessas issues, verá que ele contém um título, uma descrição e um conjunto de rótulos que caracterizam a issue. Um exemplo é mostrado na captura de tela abaixo.

Para baixar todos as issues do repositório, usaremos a GitHub REST API para pesquisar o [Issues endpoint](https://docs.github. com/en/rest/reference/issues#list-repository-issues). Esse endpoint retorna uma lista de objetos JSON, com cada objeto contendo um grande número de campos que incluem o título e a descrição, bem como metadados sobre o status da issue e assim por diante.
Uma maneira conveniente de baixar as issues é por meio da biblioteca requests, que é a maneira padrão de fazer solicitações HTTP em Python. Você pode instalar a biblioteca executando:
!pip install requests
Uma vez que a biblioteca esteja instalada, você pode fazer solicitações GET para o endpoint Issues invocando a função requests.get(). Por exemplo, você pode executar o seguinte comando para recuperar a primeira issue na primeira página:
import requests
url = "https://api.github.com/repos/huggingface/datasets/issues?page=1&per_page=1"
response = requests.get(url)O objeto response contém muitas informações úteis sobre a solicitação, incluindo o código de status HTTP:
response.status_code
200onde um status 200 significa que a solicitação foi bem-sucedida (você pode encontrar uma lista de possíveis códigos de status HTTP aqui). O que realmente nos interessa, porém, é o payload, que pode ser acessado em vários formatos como bytes, strings ou JSON. Como sabemos que nossas issues estão no formato JSON, vamos inspecionar o payload da seguinte forma:
response.json()
[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
'repository_url': 'https://api.github.com/repos/huggingface/datasets',
'labels_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/labels{/name}',
'comments_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/comments',
'events_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/events',
'html_url': 'https://github.com/huggingface/datasets/pull/2792',
'id': 968650274,
'node_id': 'MDExOlB1bGxSZXF1ZXN0NzEwNzUyMjc0',
'number': 2792,
'title': 'Update GooAQ',
'user': {'login': 'bhavitvyamalik',
'id': 19718818,
'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
'gravatar_id': '',
'url': 'https://api.github.com/users/bhavitvyamalik',
'html_url': 'https://github.com/bhavitvyamalik',
'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
'type': 'User',
'site_admin': False},
'labels': [],
'state': 'open',
'locked': False,
'assignee': None,
'assignees': [],
'milestone': None,
'comments': 1,
'created_at': '2021-08-12T11:40:18Z',
'updated_at': '2021-08-12T12:31:17Z',
'closed_at': None,
'author_association': 'CONTRIBUTOR',
'active_lock_reason': None,
'pull_request': {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/2792',
'html_url': 'https://github.com/huggingface/datasets/pull/2792',
'diff_url': 'https://github.com/huggingface/datasets/pull/2792.diff',
'patch_url': 'https://github.com/huggingface/datasets/pull/2792.patch'},
'body': '[GooAQ](https://github.com/allenai/gooaq) dataset was recently updated after splits were added for the same. This PR contains new updated GooAQ with train/val/test splits and updated README as well.',
'performed_via_github_app': None}]Uau, é muita informação! Podemos ver campos úteis como title, body e number que descrevem a issue, bem como informações sobre o usuário do GitHub que abriu a issue.
✏️ Experimente! Clique em alguns dos URLs na carga JSON acima para ter uma ideia de que tipo de informação cada issue do GitHub está vinculado.
Conforme descrito na [documentação] do GitHub (https://docs.github.com/en/rest/overview/resources-in-the-rest-api#rate-limiting), as solicitações não autenticadas são limitadas a 60 solicitações por hora. Embora você possa aumentar o parâmetro de consulta per_page para reduzir o número de solicitações feitas, você ainda atingirá o limite de taxa em qualquer repositório que tenha mais do que alguns milhares de issues. Então, em vez disso, você deve seguir as [instruções] do GitHub (https://docs.github.com/en/github/authenticating-to-github/creating-a-personal-access-token) sobre como criar um token de acesso pessoal para que você pode aumentar o limite de taxa para 5.000 solicitações por hora. Depois de ter seu token, você pode incluí-lo como parte do cabeçalho da solicitação:
GITHUB_TOKEN = xxx # Copy your GitHub token here
headers = {"Authorization": f"token {GITHUB_TOKEN}"}⚠️ Não compartilhe um notebook com seu GITHUB_TOKEN colado nele. Recomendamos que você exclua a última célula depois de executá-la para evitar o vazamento dessas informações acidentalmente. Melhor ainda, armazene o token em um arquivo .env e use a python-dotenv library para carregá-lo automaticamente para você como uma variável de ambiente.
Agora que temos nosso token de acesso, vamos criar uma função que possa baixar todas as issues de um repositório do GitHub:
import time
import math
from pathlib import Path
import pandas as pd
from tqdm.notebook import tqdm
def fetch_issues(
owner="huggingface",
repo="datasets",
num_issues=10_000,
rate_limit=5_000,
issues_path=Path("."),
):
if not issues_path.is_dir():
issues_path.mkdir(exist_ok=True)
batch = []
all_issues = []
per_page = 100 # Number of issues to return per page
num_pages = math.ceil(num_issues / per_page)
base_url = "https://api.github.com/repos"
for page in tqdm(range(num_pages)):
# Query with state=all to get both open and closed issues
query = f"issues?page={page}&per_page={per_page}&state=all"
issues = requests.get(f"{base_url}/{owner}/{repo}/{query}", headers=headers)
batch.extend(issues.json())
if len(batch) > rate_limit and len(all_issues) < num_issues:
all_issues.extend(batch)
batch = [] # Flush batch for next time period
print(f"Reached GitHub rate limit. Sleeping for one hour ...")
time.sleep(60 * 60 + 1)
all_issues.extend(batch)
df = pd.DataFrame.from_records(all_issues)
df.to_json(f"{issues_path}/{repo}-issues.jsonl", orient="records", lines=True)
print(
f"Downloaded all the issues for {repo}! Dataset stored at {issues_path}/{repo}-issues.jsonl"
)Agora, quando chamamos fetch_issues(), ele fará o download de todas as issues em lotes para evitar exceder o limite do GitHub no número de solicitações por hora; o resultado será armazenado em um arquivo repository_name-issues.jsonl, onde cada linha é um objeto JSON que representa uma issue. Vamos usar esta função para pegar todas as issues de 🤗 Datasets:
# Depending on your internet connection, this can take several minutes to run...
fetch_issues()Depois que as issues forem baixadas, podemos carregá-las localmente usando nossas novas habilidades da seção 2:
issues_dataset = load_dataset("json", data_files="datasets-issues.jsonl", split="train")
issues_datasetDataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'timeline_url', 'performed_via_github_app'],
num_rows: 3019
})Ótimo, criamos nosso primeiro conjunto de dados do zero! Mas por que existem vários milhares de issues quando a guia Issue do repositório 🤗 Datasets mostra apenas cerca de 1.000 issues no total 🤔? Conforme descrito na [documentação] do GitHub (https://docs.github.com/en/rest/reference/issues#list-issues-assigned-to-the-authenticated-user), isso ocorre porque baixamos todos os pull request também:
A API REST v3 do GitHub considera cada pull request como uma issue, mas nem toda issue é um pull request. Por esse motivo, os endpoints de “issues” podem retornar issues e solicitações de pull na resposta. Você pode identificar solicitações de pull pela chave
pull_request. Esteja ciente de que oidde uma solicitação pull retornada de endpoints “issues” será um ID de issue.
Como o conteúdo das issues e dos pull request são bem diferentes, vamos fazer um pequeno pré-processamento para nos permitir distinguir entre eles.
Limpando os dados
O trecho acima da documentação do GitHub nos diz que a coluna pull_request pode ser usada para diferenciar entre issues e solicitações de pull request. Vamos olhar para uma amostra aleatória para ver qual é a diferença. Como fizemos na seção 3, vamos encadear Dataset.shuffle() e Dataset.select() para criar uma amostra aleatória e então compactar o html_url e pull_request para que possamos comparar os vários URLs:
sample = issues_dataset.shuffle(seed=666).select(range(3))
# Print out the URL and pull request entries
for url, pr in zip(sample["html_url"], sample["pull_request"]):
print(f">> URL: {url}")
print(f">> Pull request: {pr}\n")>> URL: https://github.com/huggingface/datasets/pull/850
>> Pull request: {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/850', 'html_url': 'https://github.com/huggingface/datasets/pull/850', 'diff_url': 'https://github.com/huggingface/datasets/pull/850.diff', 'patch_url': 'https://github.com/huggingface/datasets/pull/850.patch'}
>> URL: https://github.com/huggingface/datasets/issues/2773
>> Pull request: None
>> URL: https://github.com/huggingface/datasets/pull/783
>> Pull request: {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/783', 'html_url': 'https://github.com/huggingface/datasets/pull/783', 'diff_url': 'https://github.com/huggingface/datasets/pull/783.diff', 'patch_url': 'https://github.com/huggingface/datasets/pull/783.patch'}Aqui podemos ver que cada pull request está associado a vários URLs, enquanto as issues comuns têm uma entrada None. Podemos usar essa distinção para criar uma nova coluna is_pull_request que verifica se o campo pull_request é None ou não:
issues_dataset = issues_dataset.map(
lambda x: {"is_pull_request": False if x["pull_request"] is None else True}
)✏️ Experimente! Calcule o tempo médio que leva para fechar as issues em 🤗 Datasets. Você pode achar a função Dataset.filter() útil para filtrar os pull requests e as issues abertas, e você pode usar a função Dataset.set_format() para converter o conjunto de dados em um DataFrame para que você possa manipular facilmente os timestamps created_at e closed_at. Para pontos de bônus, calcule o tempo médio que leva para fechar os pull requests.
Embora possamos continuar a limpar o conjunto de dados descartando ou renomeando algumas colunas, geralmente é uma boa prática manter o conjunto de dados o mais “bruto” possível neste estágio para que possa ser facilmente usado em vários aplicativos.
Antes de enviarmos nosso conjunto de dados para o Hugging Face Hub, vamos lidar com uma coisa que está faltando: os comentários associados a cada issue e pull request. Vamos adicioná-los a seguir - você adivinhou - a API REST do GitHub!
Aumentando o conjunto de dados
Conforme mostrado na captura de tela a seguir, os comentários associados a uma issue ou a pull request fornecem uma rica fonte de informações, especialmente se estivermos interessados em criar um mecanismo de pesquisa para responder às consultas dos usuários sobre a biblioteca.

A API REST do GitHub fornece um endpoint Comments que retorna todos os comentários associados a uma issue. Vamos testar o endpoint para ver o que ele retorna:
issue_number = 2792
url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
response = requests.get(url, headers=headers)
response.json()[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/comments/897594128',
'html_url': 'https://github.com/huggingface/datasets/pull/2792#issuecomment-897594128',
'issue_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
'id': 897594128,
'node_id': 'IC_kwDODunzps41gDMQ',
'user': {'login': 'bhavitvyamalik',
'id': 19718818,
'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
'gravatar_id': '',
'url': 'https://api.github.com/users/bhavitvyamalik',
'html_url': 'https://github.com/bhavitvyamalik',
'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
'type': 'User',
'site_admin': False},
'created_at': '2021-08-12T12:21:52Z',
'updated_at': '2021-08-12T12:31:17Z',
'author_association': 'CONTRIBUTOR',
'body': "@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?",
'performed_via_github_app': None}]Podemos ver que o comentário está armazenado no campo body, então vamos escrever uma função simples que retorna todos os comentários associados a uma issue selecionando o conteúdo do body para cada elemento em response.json():
def get_comments(issue_number):
url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
response = requests.get(url, headers=headers)
return [r["body"] for r in response.json()]
# Test our function works as expected
get_comments(2792)["@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?"]Isso parece certo, então vamos usar Dataset.map() para adicionar uma nova coluna comments para cada issue em nosso conjunto de dados:
# Depending on your internet connection, this can take a few minutes...
issues_with_comments_dataset = issues_dataset.map(
lambda x: {"comments": get_comments(x["number"])}
)A etapa final é salvar o conjunto de dados aumentado junto com nossos dados brutos para que possamos enviá-los para o Hub:
issues_with_comments_dataset.to_json("issues-datasets-with-comments.jsonl")Carregando o conjunto de dados para o Hugging Face Hub
Agora que temos nosso conjunto de dados aumentado, é hora de enviá-lo para o Hub para que possamos compartilhá-lo com a comunidade! Para fazer o upload do conjunto de dados, usaremos a 🤗 Hub library, que nos permite interagir com o Hugging Face Hub por meio de uma API Python. 🤗 Hub vem pré-instalado com 🤗 Transformers, para que possamos usá-lo diretamente. Por exemplo, podemos usar a função list_datasets() para obter informações sobre todos os conjuntos de dados públicos atualmente hospedados no Hub:
from huggingface_hub import list_datasets
all_datasets = list_datasets()
print(f"Number of datasets on Hub: {len(all_datasets)}")
print(all_datasets[0])Number of datasets on Hub: 1487
Dataset Name: acronym_identification, Tags: ['annotations_creators:expert-generated', 'language_creators:found', 'languages:en', 'licenses:mit', 'multilinguality:monolingual', 'size_categories:10K<n<100K', 'source_datasets:original', 'task_categories:structure-prediction', 'task_ids:structure-prediction-other-acronym-identification']Podemos ver que atualmente existem cerca de 1.500 conjuntos de dados no Hub, e a função list_datasets() também fornece alguns metadados básicos sobre cada repositório de conjuntos de dados.
Para nossos propósitos, a primeira coisa que precisamos fazer é criar um novo repositório de conjunto de dados no Hub. Para fazer isso, precisamos de um token de autenticação, que pode ser obtido primeiro entrando no Hugging Face Hub com a função notebook_login():
from huggingface_hub import notebook_login
notebook_login()Isso criará um widget onde você poderá inserir seu nome de usuário e senha, e um token de API será salvo em ~/.huggingface/token. Se você estiver executando o código em um terminal, poderá fazer login via CLI:
huggingface-cli login
Feito isso, podemos criar um novo repositório de conjunto de dados com a função create_repo():
from huggingface_hub import create_repo
repo_url = create_repo(name="github-issues", repo_type="dataset")
repo_url'https://huggingface.co/datasets/lewtun/github-issues'Neste exemplo, criamos um repositório de conjunto de dados vazio chamado github-issues sob o nome de usuário lewtun (o nome de usuário deve ser seu nome de usuário do Hub quando você estiver executando este código!).
✏️ Experimente! Use seu nome de usuário e senha do Hugging Face Hub para obter um token e criar um repositório vazio chamado github-issues. Lembre-se de nunca salvar suas credenciais no Colab ou em qualquer outro repositório, pois essas informações podem ser exploradas por agentes mal-intencionados.
Em seguida, vamos clonar o repositório do Hub para nossa máquina local e copiar nosso arquivo de conjunto de dados para ele. O 🤗 Hub fornece uma classe Repository útil que envolve muitos dos comandos comuns do Git, portanto, para clonar o repositório remoto, basta fornecer o URL e o caminho local para o qual desejamos clonar:
from huggingface_hub import Repository
repo = Repository(local_dir="github-issues", clone_from=repo_url)
!cp datasets-issues-with-comments.jsonl github-issues/Por padrão, várias extensões de arquivo (como .bin, .gz e .zip) são rastreadas com o Git LFS para que arquivos grandes possam ser versionados no mesmo fluxo de trabalho do Git. Você pode encontrar uma lista de extensões de arquivos rastreados dentro do arquivo .gitattributes do repositório. Para incluir o formato JSON Lines na lista, podemos executar o seguinte comando:
repo.lfs_track("*.jsonl")Então podemos usar Repository.push_to_hub() para enviar o conjunto de dados para o Hub:
repo.push_to_hub()
Se navegarmos para a URL contida em repo_url, veremos agora que nosso arquivo de conjunto de dados foi carregado.
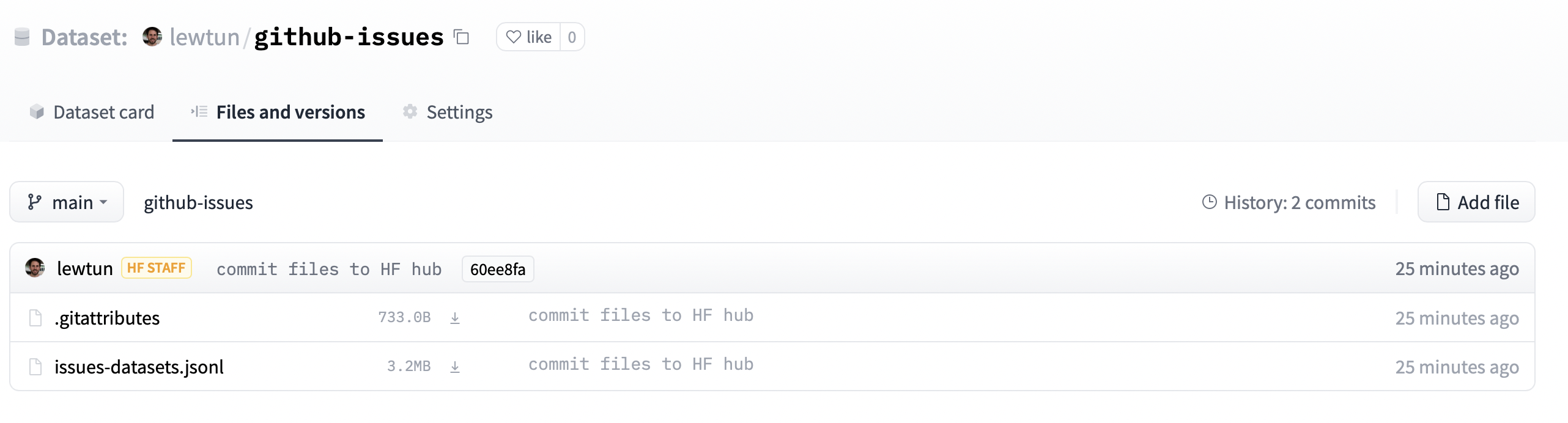
A partir daqui, qualquer um pode baixar o conjunto de dados simplesmente fornecendo load_dataset() com o ID do repositório como o argumento path:
remote_dataset = load_dataset("lewtun/github-issues", split="train")
remote_datasetDataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
num_rows: 2855
})Legal, nós enviamos nosso conjunto de dados para o Hub e está disponível para outros usarem! Há apenas uma coisa importante a fazer: adicionar um cartão de conjunto de dados que explica como o corpus foi criado e fornece outras informações úteis para a comunidade.
💡 Você também pode enviar um conjunto de dados para o Hugging Face Hub diretamente do terminal usando huggingface-cli e um pouco de magia Git. Consulte o guia do 🤗 Datasets para obter detalhes sobre como fazer isso.
Criando um cartão do datasets
Conjuntos de dados bem documentados são mais propensos a serem úteis para outras pessoas (incluindo você mesmo no futuro!), pois fornecem o contexto para permitir que os usuários decidam se o conjunto de dados é relevante para sua tarefa e avaliem possíveis vieses ou riscos associados ao uso o conjunto de dados.
No Hugging Face Hub, essas informações são armazenadas no arquivo README.md de cada repositório de conjunto de dados. Há duas etapas principais que você deve seguir antes de criar este arquivo:
- Use a aplicação
datasets-taggingpara criar tags de metadados no formato YAML. Essas tags são usadas para uma variedade de recursos de pesquisa no Hugging Face Hub e garantem que seu conjunto de dados possa ser facilmente encontrado pelos membros da comunidade. Como criamos um conjunto de dados personalizado aqui, você precisará clonar o repositóriodatasets-tagginge executar o aplicativo localmente. Veja como é a interface:

- Leia o guia do 🤗 datasets sobre como criar cartões informativos de conjuntos de dados e use-os como modelo.
Você pode criar o arquivo README.md diretamente no Hub e encontrar um cartão de conjunto de dados de modelo no repositório de conjunto de dados lewtun/github-issues. Uma captura de tela do cartão de conjunto de dados preenchido é mostrada abaixo.

✏️ Experimente! Use o aplicativo dataset-tagging e guia do 🤗 datasets para concluir o Arquivo README.md para o conjunto de dados de issues do GitHub.
É isso! Vimos nesta seção que criar um bom conjunto de dados pode ser bastante complicado, mas felizmente carregá-lo e compartilhá-lo com a comunidade não é. Na próxima seção, usaremos nosso novo conjunto de dados para criar um mecanismo de pesquisa semântica com o 🤗 datasets que podem corresponder perguntas as issues e comentários mais relevantes.
✏️ Experimente! Siga as etapas que seguimos nesta seção para criar um conjunto de dados de issues do GitHub para sua biblioteca de código aberto favorita (escolha algo diferente do 🤗 datasets, é claro!). Para pontos de bônus, ajuste um classificador multilabel para prever as tags presentes no campo labels.