<i> Finetuner </i> un modèle de langage masqué
Pour de nombreuses applications de NLP impliquant des transformers, vous pouvez simplement prendre un modèle pré-entraîné du Hub et le finetuner directement sur vos données pour la tâche à accomplir. Pour autant que le corpus utilisé pour le pré-entraînement ne soit pas trop différent du corpus utilisé pour le finetuning. L’apprentissage par transfert produira généralement de bons résultats.
Cependant, il existe quelques cas où vous voudrez d’abord finetuner les modèles de langue sur vos données, avant d’entraîner une tête spécifique à la tâche. Par exemple, si votre jeu de données contient des contrats légaux ou des articles scientifiques, un transformer classique comme BERT traitera généralement les mots spécifiques au domaine dans votre corpus comme des tokens rares et les performances résultantes peuvent être moins que satisfaisantes. En finetunant le modèle de langage sur les données du domaine, vous pouvez améliorer les performances de nombreuses tâches en aval, ce qui signifie que vous ne devez généralement effectuer cette étape qu’une seule fois !
Ce processus de finetuning d’un modèle de langage pré-entraîné sur des données dans le domaine est généralement appelé adaptation au domaine. Il a été popularisé en 2018 par ULMFiT qui a été l’une des premières architectures neuronales (basées sur des LSTMs) à faire en sorte que l’apprentissage par transfert fonctionne réellement pour le NLP. Un exemple d’adaptation de domaine avec ULMFiT est présenté dans l’image ci-dessous. Dans cette section, nous ferons quelque chose de similaire mais avec un transformer au lieu d’une LSTM !


À la fin de cette section, vous aurez un modèle de langage masqué sur le Hub qui peut autocompléter des phrases comme indiqué ci-dessous :
Allons-y !
🙋 Si les termes « modélisation du langage masqué » et « modèle pré-entraîné » ne vous sont pas familiers, consultez le chapitre 1, où nous expliquons tous ces concepts fondamentaux, vidéos à l’appui !
Choix d’un modèle pré-entraîné pour la modélisation du langage masqué
Pour commencer, nous allons choisir un modèle pré-entraîné approprié pour la modélisation du langage masqué. Comme le montre la capture d’écran suivante, vous pouvez trouver une liste de candidats en appliquant le filtre « Fill-Mask » sur le Hub :
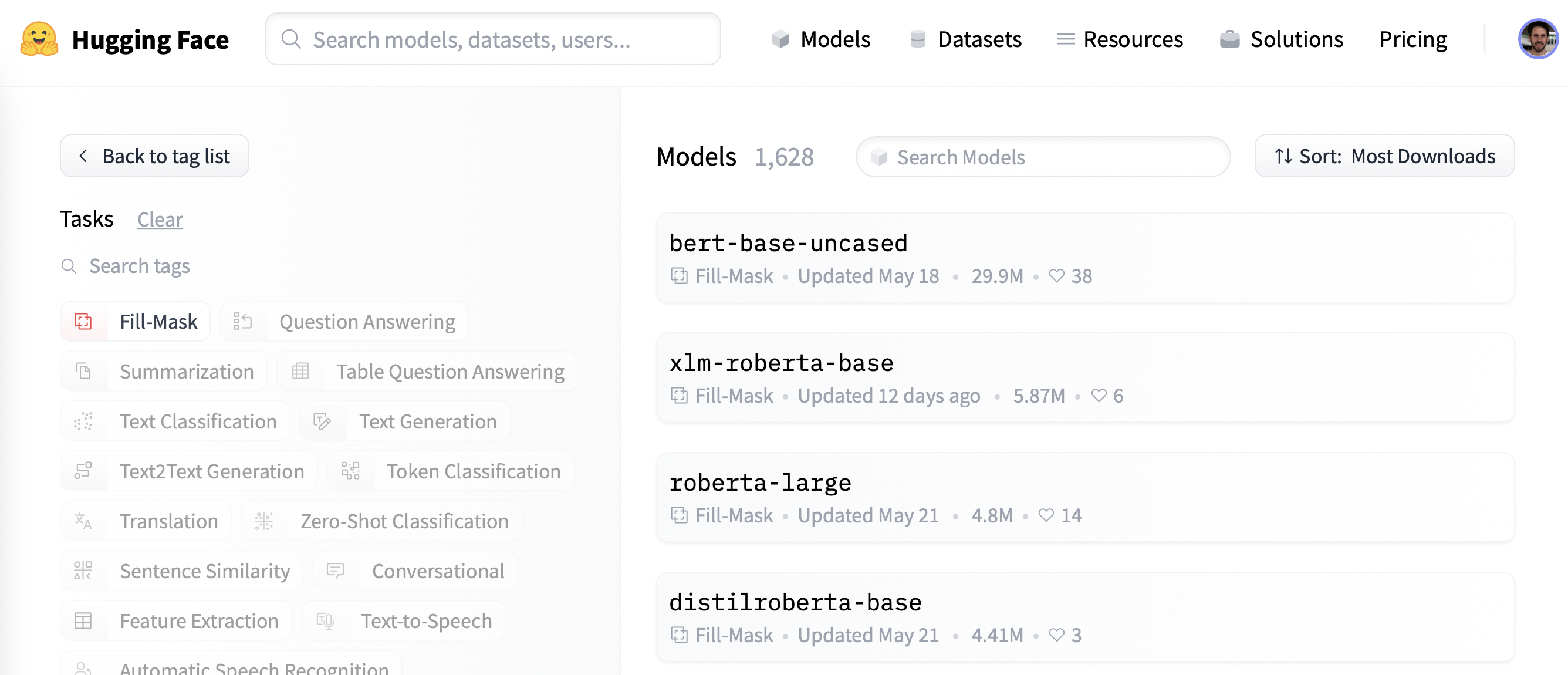
Bien que les modèles de la famille BERT et RoBERTa soient les plus téléchargés, nous utiliserons un modèle appelé DistilBERT qui peut être entraîné beaucoup plus rapidement avec peu ou pas de perte de performance en aval. Ce modèle a été entraîné à l’aide d’une technique spéciale appelée distillation de connaissances, où un grand modèle enseignant comme BERT est utilisé pour guider l’entraînement d’un modèle étudiant qui a beaucoup moins de paramètres. Une explication des détails de la distillation de connaissances nous mènerait trop loin dans cette section mais si vous êtes intéressé, vous pouvez lire tout cela dans le livre Natural Language Processing with Transformers.
Allons-y et téléchargeons DistilBERT en utilisant la classe AutoModelForMaskedLM :
from transformers import AutoModelForMaskedLM
model_checkpoint = "distilbert-base-uncased"
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)Nous pouvons voir combien de paramètres ce modèle possède en appelant la méthode num_parameters() :
distilbert_num_parameters = model.num_parameters() / 1_000_000
print(f"'>>> DistilBERT nombre de paramètres : {round(distilbert_num_parameters)}M'")
print(f"'>>> BERT nombre de paramètres : 110M'")'>>> DistilBERT nombre de paramètres : 67M'
'>>> BERT nombre de paramètres : 110M'Avec environ 67 millions de paramètres, DistilBERT est environ deux fois plus petit que le modèle de base de BERT, ce qui se traduit approximativement par une accélération de l’entraînement d’un facteur deux. Voyons maintenant quels types de tokens ce modèle prédit comme étant les compléments les plus probables d’un petit échantillon de texte :
text = "This is a great [MASK]."En tant qu’êtres humains, nous pouvons imaginer de nombreuses possibilités pour le token [MASK], telles que « jour », « promenade » ou « peinture ». Pour les modèles pré-entraînés, les prédictions dépendent du corpus sur lequel le modèle a été entraîné puisqu’il apprend à détecter les modèles statistiques présents dans les données. Comme BERT, DistilBERT a été pré-entraîné sur les jeux de données English Wikipedia et BookCorpus, nous nous attendons donc à ce que les prédictions pour [MASK] reflètent ces domaines. Pour prédire le masque, nous avons besoin du tokenizer de DistilBERT pour produire les entrées du modèle, alors téléchargeons-le également depuis le Hub :
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)Avec un tokenizer et un modèle, nous pouvons maintenant passer notre exemple de texte au modèle, extraire les logits, et afficher les 5 meilleurs candidats :
import torch
inputs = tokenizer(text, return_tensors="pt")
token_logits = model(**inputs).logits
# Trouve l'emplacement de [MASK] et extrait ses logits
mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
mask_token_logits = token_logits[0, mask_token_index, :]
# Choisissez les candidats [MASK] avec les logits les plus élevés
top_5_tokens = torch.topk(mask_token_logits, 5, dim=1).indices[0].tolist()
for token in top_5_tokens:
print(f"'>>> {text.replace(tokenizer.mask_token, tokenizer.decode([token]))}'")'>>> This is a great deal.' # C'est une bonne affaire
'>>> This is a great success.' # C'est un grand succès
'>>> This is a great adventure.' # C'est une grande aventure
'>>> This is a great idea.' # C'est une bonne idée
'>>> This is a great feat.' # C'est un grand exploitNous pouvons voir dans les sorties que les prédictions du modèle se réfèrent à des termes de tous les jours, ce qui n’est peut-être pas surprenant étant donné le fondement de Wikipédia. Voyons comment nous pouvons changer ce domaine pour quelque chose d’un peu plus spécialisé : des critiques de films !
Le jeu de données
Pour illustrer l’adaptation au domaine, nous utiliserons le célèbre Large Movie Review Dataset (ou IMDb en abrégé), qui est un corpus de critiques de films souvent utilisé pour évaluer les modèles d’analyse de sentiments. En finetunant DistilBERT sur ce corpus, nous espérons que le modèle de langage adaptera son vocabulaire des données factuelles de Wikipédia sur lesquelles il a été pré-entraîné aux éléments plus subjectifs des critiques de films. Nous pouvons obtenir les données du Hub avec la fonction load_dataset() de 🤗 Datasets :
from datasets import load_dataset
imdb_dataset = load_dataset("imdb")
imdb_datasetDatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
test: Dataset({
features: ['text', 'label'],
num_rows: 25000
})
unsupervised: Dataset({
features: ['text', 'label'],
num_rows: 50000
})
})Nous pouvons voir que les parties train et test sont chacune composées de 25 000 critiques, alors qu’il y a une partie non étiquetée appelée unsupervised qui contient 50 000 critiques. Jetons un coup d’œil à quelques échantillons pour avoir une idée du type de texte auquel nous avons affaire. Comme nous l’avons fait dans les chapitres précédents du cours, nous allons enchaîner les fonctions Dataset.shuffle() et Dataset.select() pour créer un échantillon aléatoire :
sample = imdb_dataset["train"].shuffle(seed=42).select(range(3))
for row in sample:
print(f"\n'>>> Review: {row['text']}'")
print(f"'>>> Label: {row['label']}'")
'>>> Review: This is your typical Priyadarshan movie--a bunch of loony characters out on some silly mission. His signature climax has the entire cast of the film coming together and fighting each other in some crazy moshpit over hidden money. Whether it is a winning lottery ticket in Malamaal Weekly, black money in Hera Pheri, "kodokoo" in Phir Hera Pheri, etc., etc., the director is becoming ridiculously predictable. Don\'t get me wrong; as clichéd and preposterous his movies may be, I usually end up enjoying the comedy. However, in most his previous movies there has actually been some good humor, (Hungama and Hera Pheri being noteworthy ones). Now, the hilarity of his films is fading as he is using the same formula over and over again.<br /><br />Songs are good. Tanushree Datta looks awesome. Rajpal Yadav is irritating, and Tusshar is not a whole lot better. Kunal Khemu is OK, and Sharman Joshi is the best.'
'>>> Label: 0'
'>>> Review: Okay, the story makes no sense, the characters lack any dimensionally, the best dialogue is ad-libs about the low quality of movie, the cinematography is dismal, and only editing saves a bit of the muddle, but Sam" Peckinpah directed the film. Somehow, his direction is not enough. For those who appreciate Peckinpah and his great work, this movie is a disappointment. Even a great cast cannot redeem the time the viewer wastes with this minimal effort.<br /><br />The proper response to the movie is the contempt that the director San Peckinpah, James Caan, Robert Duvall, Burt Young, Bo Hopkins, Arthur Hill, and even Gig Young bring to their work. Watch the great Peckinpah films. Skip this mess.'
'>>> Label: 0'
'>>> Review: I saw this movie at the theaters when I was about 6 or 7 years old. I loved it then, and have recently come to own a VHS version. <br /><br />My 4 and 6 year old children love this movie and have been asking again and again to watch it. <br /><br />I have enjoyed watching it again too. Though I have to admit it is not as good on a little TV.<br /><br />I do not have older children so I do not know what they would think of it. <br /><br />The songs are very cute. My daughter keeps singing them over and over.<br /><br />Hope this helps.'
'>>> Label: 1'Oui, ce sont bien des critiques de films, et si vous êtes assez âgés, vous pouvez même comprendre le commentaire dans la dernière critique sur le fait de posséder une version VHS 😜 ! Bien que nous n’ayons pas besoin des étiquettes pour la modélisation du langage, nous pouvons déjà voir qu’un 0 dénote une critique négative, tandis qu’un 1 correspond à une critique positive.
✏️ Essayez ! Créez un échantillon aléatoire de la répartition unsupervised et vérifiez que les étiquettes ne sont ni 0 ni 1. Pendant que vous y êtes, vous pouvez aussi vérifier que les étiquettes dans les échantillons train et test sont bien 0 ou 1. C’est un contrôle utile que tout praticien en NLP devrait effectuer au début d’un nouveau projet !
Maintenant que nous avons jeté un coup d’œil rapide aux données, plongeons dans leur préparation pour la modélisation du langage masqué. Comme nous allons le voir, il y a quelques étapes supplémentaires à suivre par rapport aux tâches de classification de séquences que nous avons vues au chapitre 3. Allons-y !
Prétraitement des données
Pour la modélisation autorégressive et la modélisation du langage masqué, une étape commune de prétraitement consiste à concaténer tous les exemples, puis à diviser le corpus entier en morceaux de taille égale. C’est très différent de notre approche habituelle, où nous nous contentons de tokenizer les exemples individuels. Pourquoi tout concaténer ? La raison est que les exemples individuels peuvent être tronqués s’ils sont trop longs, ce qui entraînerait la perte d’informations qui pourraient être utiles pour la tâche de modélisation du langage !
Donc pour commencer, nous allons d’abord tokeniser notre corpus comme d’habitude, mais sans mettre l’option truncation=True dans notre tokenizer. Nous allons aussi récupérer les identifiants des mots s’ils sont disponibles (ce qui sera le cas si nous utilisons un tokenizer rapide, comme décrit dans le chapitre 6), car nous en aurons besoin plus tard pour faire le masquage de mots entiers. Nous allons envelopper cela dans une simple fonction, et pendant que nous y sommes, nous allons supprimer les colonnes text et label puisque nous n’en avons plus besoin :
def tokenize_function(examples):
result = tokenizer(examples["text"])
if tokenizer.is_fast:
result["word_ids"] = [result.word_ids(i) for i in range(len(result["input_ids"]))]
return result
# Utilisation de batched=True pour activer le multithreading rapide !
tokenized_datasets = imdb_dataset.map(
tokenize_function, batched=True, remove_columns=["text", "label"]
)
tokenized_datasetsDatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'word_ids'],
num_rows: 25000
})
test: Dataset({
features: ['attention_mask', 'input_ids', 'word_ids'],
num_rows: 25000
})
unsupervised: Dataset({
features: ['attention_mask', 'input_ids', 'word_ids'],
num_rows: 50000
})
})Comme DistilBERT est un modèle de type BERT, nous pouvons voir que les textes encodés sont constitués des input_ids et des attention_mask que nous avons vus dans d’autres chapitres, ainsi que des word_ids que nous avons ajoutés.
Maintenant que nos critiques de films ont été tokenisées, l’étape suivante consiste à les regrouper et à diviser le résultat en chunks. Mais quelle taille doivent avoir ces chunks ? Cela sera finalement déterminé par la quantité de mémoire GPU dont vous disposez, mais un bon point de départ est de voir quelle est la taille maximale du contexte du modèle. Cela peut être déduit en inspectant l’attribut model_max_length du tokenizer :
tokenizer.model_max_length
512Cette valeur est dérivée du fichier tokenizer_config.json associé à un checkpoint. Dans ce cas, nous pouvons voir que la taille du contexte est de 512 tokens, tout comme avec BERT.
✏️ Essayez ! Certains transformers, comme BigBird et Longformer, ont une longueur de contexte beaucoup plus longue que BERT et les autres premiers transformers. Instanciez le tokenizer pour l’un de ces checkpoints et vérifiez que le model_max_length correspond à ce qui est indiqué sur sa carte.
Ainsi, pour réaliser nos expériences sur des GPUs comme ceux disponibles sur Google Colab, nous choisirons quelque chose d’un peu plus petit qui peut tenir en mémoire :
chunk_size = 128Notez que l’utilisation d’une petite taille peut être préjudiciable dans les scénarios du monde réel. Vous devez donc utiliser une taille qui correspond au cas d’utilisation auquel vous appliquerez votre modèle.
Maintenant vient la partie amusante. Pour montrer comment la concaténation fonctionne, prenons quelques commentaires de notre ensemble d’entraînement et affichons le nombre de tokens par commentaire :
# Le découpage produit une liste de listes pour chaque caractéristique
tokenized_samples = tokenized_datasets["train"][:3]
for idx, sample in enumerate(tokenized_samples["input_ids"]):
print(f"'>>> Review {idx} length: {len(sample)}'")'>>> Review 0 length: 200'
'>>> Review 1 length: 559'
'>>> Review 2 length: 192'Nous pouvons ensuite concaténer tous ces exemples avec une simple compréhension du dictionnaire, comme suit :
concatenated_examples = {
k: sum(tokenized_samples[k], []) for k in tokenized_samples.keys()
}
total_length = len(concatenated_examples["input_ids"])
print(f"'>>> Longueur des critiques concaténées : {total_length}'")'>>> Longueur des critiques concaténées : 951'Super, la longueur totale est correcte. Donc maintenant, nous allons diviser les exemples concaténés en morceaux de la taille donnée par block_size. Pour ce faire, nous itérons sur les caractéristiques de concatenated_examples et utilisons une compréhension de liste pour créer des chunks de chaque caractéristique. Le résultat est un dictionnaire de chunks pour chaque caractéristique :
chunks = {
k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
for k, t in concatenated_examples.items()
}
for chunk in chunks["input_ids"]:
print(f"'>>> Chunk length: {len(chunk)}'")'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 128'
'>>> Chunk length: 55'Comme vous pouvez le voir dans cet exemple, le dernier chunk sera généralement plus petit que la taille maximale des morceaux. Il y a deux stratégies principales pour gérer cela :
- Abandonner le dernier morceau s’il est plus petit que
chunk_size. - Rembourrer le dernier morceau jusqu’à ce que sa longueur soit égale à
chunk_size.
Nous adopterons la première approche ici, donc nous allons envelopper toute la logique ci-dessus dans une seule fonction que nous pouvons appliquer à nos jeux de données tokenisés :
def group_texts(examples):
# Concaténation de tous les textes
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
# Calcule la longueur des textes concaténés
total_length = len(concatenated_examples[list(examples.keys())[0]])
# Nous laissons tomber le dernier morceau s'il est plus petit que chunk_size
total_length = (total_length // chunk_size) * chunk_size
# Fractionnement par chunk de max_len
result = {
k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
for k, t in concatenated_examples.items()
}
# Créer une nouvelle colonne d'étiquettes
result["labels"] = result["input_ids"].copy()
return resultNotez que dans la dernière étape de group_texts() nous créons une nouvelle colonne labels qui est une copie de la colonne input_ids. Comme nous le verrons bientôt, c’est parce que dans la modélisation du langage masqué, l’objectif est de prédire des tokens masqués aléatoirement dans le batch d’entrée, et en créant une colonne labels, nous fournissons la vérité de base pour notre modèle de langage à apprendre.
Appliquons maintenant group_texts() à nos jeux de données tokenisés en utilisant notre fidèle fonction Dataset.map() :
lm_datasets = tokenized_datasets.map(group_texts, batched=True)
lm_datasetsDatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 61289
})
test: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 59905
})
unsupervised: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 122963
})
})Vous pouvez voir que le regroupement puis le découpage des textes a produit beaucoup plus d’exemples que nos 25 000 exemples initiaux pour les divisions train et test. C’est parce que nous avons maintenant des exemples impliquant des tokens contigus qui s’étendent sur plusieurs exemples du corpus original. Vous pouvez le voir explicitement en cherchant les tokens spéciaux [SEP] et [CLS] dans l’un des chunks :
tokenizer.decode(lm_datasets["train"][1]["input_ids"])".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"Dans cet exemple, vous pouvez voir deux critiques de films qui se chevauchent, l’une sur un film de lycée et l’autre sur les sans-abri. Voyons également à quoi ressemblent les étiquettes pour la modélisation du langage masqué :
tokenizer.decode(lm_datasets["train"][1]["labels"])".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"Comme prévu par notre fonction group_texts() ci-dessus, cela semble identique aux input_ids décodés. Mais alors comment notre modèle peut-il apprendre quoi que ce soit ? Il nous manque une étape clé : insérer des tokens à des positions aléatoires dans les entrées ! Voyons comment nous pouvons le faire à la volée pendant le finetuning en utilisant un assembleur de données spécial.
<i> Finetuning </i> de DistilBERT avec l’API Trainer
Le finetuning d’un modèle de langage masqué est presque identique au finetuning d’un modèle de classification de séquences, comme nous l’avons fait dans le chapitre 3. La seule différence est que nous avons besoin d’un collecteur de données spécial qui peut masquer de manière aléatoire certains des tokens dans chaque batch de textes. Heureusement, 🤗 Transformers est livré préparé avec un DataCollatorForLanguageModeling dédié à cette tâche. Nous devons juste lui passer le tokenizer et un argument mlm_probability qui spécifie quelle fraction des tokens à masquer. Nous choisirons 15%, qui est la quantité utilisée pour BERT et un choix commun dans la littérature :
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)Pour voir comment le masquage aléatoire fonctionne, nous allons donner quelques exemples à l’assembleur de données. Puisqu’il s’attend à une liste de dict où chaque dict représente un seul morceau de texte contigu, nous itérons d’abord sur le jeu de données avant de donner le batch à l’assembleur. Nous supprimons la clé "word_ids" pour cet assembleur de données car il ne l’attend pas :
samples = [lm_datasets["train"][i] for i in range(2)]
for sample in samples:
_ = sample.pop("word_ids")
for chunk in data_collator(samples)["input_ids"]:
print(f"\n'>>> {tokenizer.decode(chunk)}'")'>>> [CLS] bromwell [MASK] is a cartoon comedy. it ran at the same [MASK] as some other [MASK] about school life, [MASK] as " teachers ". [MASK] [MASK] [MASK] in the teaching [MASK] lead [MASK] to believe that bromwell high\'[MASK] satire is much closer to reality than is " teachers ". the scramble [MASK] [MASK] financially, the [MASK]ful students whogn [MASK] right through [MASK] pathetic teachers\'pomp, the pettiness of the whole situation, distinction remind me of the schools i knew and their students. when i saw [MASK] episode in [MASK] a student repeatedly tried to burn down the school, [MASK] immediately recalled. [MASK]...'
'>>> .... at.. [MASK]... [MASK]... high. a classic line plucked inspector : i\'[MASK] here to [MASK] one of your [MASK]. student : welcome to bromwell [MASK]. i expect that many adults of my age think that [MASK]mwell [MASK] is [MASK] fetched. what a pity that it isn\'t! [SEP] [CLS] [MASK]ness ( or [MASK]lessness as george 宇in stated )公 been an issue for years but never [MASK] plan to help those on the street that were once considered human [MASK] did everything from going to school, [MASK], [MASK] vote for the matter. most people think [MASK] the homeless'Super, ça a marché ! Nous pouvons voir que le token [MASK] a été inséré de façon aléatoire à différents endroits dans notre texte. Ce seront les tokens que notre modèle devra prédire pendant l’entraînement. Et la beauté du collecteur de données est qu’il va rendre aléatoire l’insertion du [MASK] à chaque batch !
✏️ Essayez Exécutez le code ci-dessus plusieurs fois pour voir le masquage aléatoire se produire sous vos yeux ! Remplacez aussi la méthode tokenizer.decode() par tokenizer.convert_ids_to_tokens() pour voir que parfois un seul token d’un mot donné est masqué et pas les autres.
Un effet secondaire du masquage aléatoire est que nos métriques d’évaluation ne seront pas déterministes lorsque nous utilisons la fonction Trainer puisque nous utilisons le même assembleur de données pour les échantillons d’entraînement et de test. Nous verrons plus tard, lorsque nous examinerons le finetuning avec 🤗 Accelerate, comment nous pouvons utiliser la flexibilité d’une boucle d’évaluation personnalisée pour geler le caractère aléatoire.
Lors de l’entraînement des modèles pour la modélisation du langage masqué, une technique qui peut être utilisée est de masquer des mots entiers ensemble et pas seulement des tokens individuels. Cette approche est appelée masquage de mots entiers. Si nous voulons utiliser le masquage de mots entiers, nous devons construire nous-mêmes un assembleur de données. Un assembleur de données est simplement une fonction qui prend une liste d’échantillons et les convertit en un batch. Faisons-le ! Nous utiliserons les identifiants des mots calculés plus tôt pour faire une correspondance entre les indices des mots et les tokens, puis nous déciderons aléatoirement quels mots masquer et appliquerons ce masque sur les entrées. Notez que les étiquettes sont toutes -100 sauf celles qui correspondent aux mots masqués.
import collections
import numpy as np
from transformers import default_data_collator
wwm_probability = 0.2
def whole_word_masking_data_collator(features):
for feature in features:
word_ids = feature.pop("word_ids")
# Création d'une correspondance entre les mots et les indices des tokens correspondants
mapping = collections.defaultdict(list)
current_word_index = -1
current_word = None
for idx, word_id in enumerate(word_ids):
if word_id is not None:
if word_id != current_word:
current_word = word_id
current_word_index += 1
mapping[current_word_index].append(idx)
# Masquer des mots de façon aléatoire
mask = np.random.binomial(1, wwm_probability, (len(mapping),))
input_ids = feature["input_ids"]
labels = feature["labels"]
new_labels = [-100] * len(labels)
for word_id in np.where(mask)[0]:
word_id = word_id.item()
for idx in mapping[word_id]:
new_labels[idx] = labels[idx]
input_ids[idx] = tokenizer.mask_token_id
feature["labels"] = new_labels
return default_data_collator(features)Ensuite, nous pouvons l’essayer sur les mêmes échantillons que précédemment :
samples = [lm_datasets["train"][i] for i in range(2)]
batch = whole_word_masking_data_collator(samples)
for chunk in batch["input_ids"]:
print(f"\n'>>> {tokenizer.decode(chunk)}'")'>>> [CLS] bromwell high is a cartoon comedy [MASK] it ran at the same time as some other programs about school life, such as " teachers ". my 35 years in the teaching profession lead me to believe that bromwell high\'s satire is much closer to reality than is " teachers ". the scramble to survive financially, the insightful students who can see right through their pathetic teachers\'pomp, the pettiness of the whole situation, all remind me of the schools i knew and their students. when i saw the episode in which a student repeatedly tried to burn down the school, i immediately recalled.....'
'>>> .... [MASK] [MASK] [MASK] [MASK]....... high. a classic line : inspector : i\'m here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn\'t! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless'✏️ Essayez Exécutez le code ci-dessus plusieurs fois pour voir le masquage aléatoire se produire sous vos yeux ! Remplacez aussi la méthode tokenizer.decode() par tokenizer.convert_ids_to_tokens() pour voir que les tokens d’un mot donné sont toujours masqués ensemble.
Maintenant que nous avons deux assembleurs de données, les étapes restantes du finetuning sont standards. L’entraînement peut prendre un certain temps sur Google Colab si vous n’avez pas la chance de tomber sur un mythique GPU P100 😭. Ainsi nous allons d’abord réduire la taille du jeu d’entraînement à quelques milliers d’exemples. Ne vous inquiétez pas, nous obtiendrons quand même un modèle de langage assez décent ! Un moyen rapide de réduire la taille d’un jeu de données dans 🤗 Datasets est la fonction Dataset.train_test_split() que nous avons vue au chapitre 5 :
train_size = 10_000
test_size = int(0.1 * train_size)
downsampled_dataset = lm_datasets["train"].train_test_split(
train_size=train_size, test_size=test_size, seed=42
)
downsampled_datasetDatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 10000
})
test: Dataset({
features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
num_rows: 1000
})
})Cela a automatiquement créé de nouvelles divisions train et test avec la taille du jeu d’entraînement fixée à 10.000 exemples et la validation fixée à 10% de cela. N’hésitez pas à augmenter la taille si vous avez un GPU puissant ! La prochaine chose que nous devons faire est de nous connecter au Hub. Si vous exécutez ce code dans un notebook, vous pouvez le faire avec la fonction suivante :
from huggingface_hub import notebook_login
notebook_login()qui affichera un widget où vous pourrez saisir vos informations d’identification. Alternativement, vous pouvez exécuter :
huggingface-cli logindans votre terminal préféré et connectez-vous là.
Une fois que nous sommes connectés, nous pouvons spécifier les arguments pour le Trainer :
from transformers import TrainingArguments
batch_size = 64
# Montrer la perte d'entraînement à chaque époque
logging_steps = len(downsampled_dataset["train"]) // batch_size
model_name = model_checkpoint.split("/")[-1]
training_args = TrainingArguments(
output_dir=f"{model_name}-finetuned-imdb",
overwrite_output_dir=True,
evaluation_strategy="epoch",
learning_rate=2e-5,
weight_decay=0.01,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
push_to_hub=True,
fp16=True,
logging_steps=logging_steps,
)Ici, nous avons modifié quelques options par défaut, y compris logging_steps pour s’assurer que nous suivons la perte d’entraînement à chaque époque. Nous avons également utilisé fp16=True pour activer l’entraînement en précision mixte, ce qui nous donne un autre gain de vitesse. Par défaut, Trainer va supprimer toutes les colonnes qui ne font pas partie de la méthode forward() du modèle. Cela signifie que si vous utilisez l’assembleur de masquage de mots entiers, vous devrez également définir remove_unused_columns=False pour vous assurer que nous ne perdons pas la colonne word_ids pendant l’entraînement.
Notez que vous pouvez spécifier le nom du dépôt vers lequel vous voulez pousser avec l’argument hub_model_id (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, lorsque nous avons poussé le modèle vers l’organisation huggingface-course, nous avons ajouté hub_model_id="huggingface-course/distilbert-finetuned-imdb" TrainingArguments. Par défaut, le dépôt utilisé sera dans votre espace de noms et nommé après le répertoire de sortie que vous avez défini, donc dans notre cas ce sera "lewtun/distilbert-finetuned-imdb".
Nous avons maintenant tous les ingrédients pour instancier le Trainer. Ici, nous utilisons juste l’assembleur standard data_collator, mais vous pouvez essayer l’assembleur de masquage de mots entiers et comparer les résultats comme exercice :
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=downsampled_dataset["train"],
eval_dataset=downsampled_dataset["test"],
data_collator=data_collator,
tokenizer=tokenizer,
)Nous sommes maintenant prêts à exécuter trainer.train(). Mais avant, regardons brièvement la perplexité qui est une métrique commune pour évaluer la performance des modèles de langage.
Perplexité pour les modèles de langage
Contrairement à d’autres tâches, comme la classification de textes ou la réponse à des questions, sur lesquelles nous disposons d’un corpus étiqueté pour entraîner, la modélisation du langage ne s’appuie sur aucune étiquette explicite. Alors comment déterminer ce qui fait un bon modèle de langage ? Comme pour la fonction de correction automatique de votre téléphone, un bon modèle de langage est celui qui attribue des probabilités élevées aux phrases grammaticalement correctes et des probabilités faibles aux phrases absurdes. Pour vous donner une meilleure idée de ce à quoi cela ressemble, vous pouvez trouver en ligne des séries entières de « ratés d’autocorrection » où le modèle d’un téléphone produit des compléments plutôt amusants (et souvent inappropriés) !
En supposant que notre ensemble de test se compose principalement de phrases grammaticalement correctes, une façon de mesurer la qualité de notre modèle de langage est de calculer les probabilités qu’il attribue au mot suivant dans toutes les phrases de l’ensemble de test. Des probabilités élevées indiquent que le modèle n’est pas « surpris » ou « perplexe » vis-à-vis des exemples non vus, et suggèrent qu’il a appris les modèles de base de la grammaire de la langue. Il existe plusieurs définitions mathématiques de la perplexité. Celle que nous utiliserons la définit comme l’exponentielle de la perte d’entropie croisée. Ainsi, nous pouvons calculer la perplexité de notre modèle pré-entraîné en utilisant la fonction Trainer.evaluate() pour calculer la perte d’entropie croisée sur l’ensemble de test, puis en prenant l’exponentielle du résultat :
import math
eval_results = trainer.evaluate()
print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")>>> Perplexité : 21.75Un score de perplexité faible signifie un meilleur modèle de langue. Nous pouvons voir ici que notre modèle de départ a une valeur assez élevée. Voyons si nous pouvons la réduire en l’affinant ! Pour ce faire, nous commençons par exécuter la boucle d’entraînement :
trainer.train()
et ensuite calculer la perplexité résultante sur l’ensemble de test comme précédemment :
eval_results = trainer.evaluate()
print(f">>> Perplexité : {math.exp(eval_results['eval_loss']):.2f}")>>> Perplexité : 11.32Joli. C’est une réduction considérable de la perplexité, ce qui nous indique que le modèle a appris quelque chose sur le domaine des critiques de films !
Une fois l’entraînement terminé, nous pouvons pousser la carte de modèle avec les informations d’entraînement vers le Hub (les checkpoints sont sauvegardés pendant l’entraînement lui-même) :
trainer.push_to_hub()
✏️ A votre tour ! Exécutez l’entraînement ci-dessus après avoir remplacé le collecteur de données par le collecteur de mots entiers masqués. Obtenez-vous de meilleurs résultats ?
Dans notre cas d’utilisation, nous n’avons pas eu besoin de faire quelque chose de spécial avec la boucle d’entraînement, mais dans certains cas, vous pourriez avoir besoin de mettre en œuvre une logique personnalisée. Pour ces applications, vous pouvez utiliser 🤗 Accelerate. Jetons un coup d’œil !
<i> Finetuning </i> de DistilBERT avec 🤗 <i> Accelerate </i>
Comme nous l’avons vu, avec Trainer le finetuning d’un modèle de langage masqué est très similaire à l’exemple de classification de texte du chapitre 3. En fait, la seule subtilité est l’utilisation d’un assembleur de données spécial, et nous l’avons déjà couvert plus tôt dans cette section !
Cependant, nous avons vu que DataCollatorForLanguageModeling applique aussi un masquage aléatoire à chaque évaluation. Nous verrons donc quelques fluctuations dans nos scores de perplexité à chaque entrainement. Une façon d’éliminer cette source d’aléat est d’appliquer le masquage une fois sur l’ensemble de test, puis d’utiliser l’assembleur de données par défaut dans 🤗 Transformers pour collecter les batchs pendant l’évaluation. Pour voir comment cela fonctionne, implémentons une fonction simple qui applique le masquage sur un batch, similaire à notre première rencontre avec DataCollatorForLanguageModeling :
def insert_random_mask(batch):
features = [dict(zip(batch, t)) for t in zip(*batch.values())]
masked_inputs = data_collator(features)
# Créer une nouvelle colonne "masquée" pour chaque colonne du jeu de données
return {"masked_" + k: v.numpy() for k, v in masked_inputs.items()}Ensuite, nous allons appliquer cette fonction à notre jeu de test et laisser tomber les colonnes non masquées afin de les remplacer par les colonnes masquées. Vous pouvez utiliser le masquage de mots entiers en remplaçant le data_collator ci-dessus par celui qui est approprié. Dans ce cas vous devez supprimer la première ligne ici :
downsampled_dataset = downsampled_dataset.remove_columns(["word_ids"])
eval_dataset = downsampled_dataset["test"].map(
insert_random_mask,
batched=True,
remove_columns=downsampled_dataset["test"].column_names,
)
eval_dataset = eval_dataset.rename_columns(
{
"masked_input_ids": "input_ids",
"masked_attention_mask": "attention_mask",
"masked_labels": "labels",
}
)Nous pouvons ensuite configurer les dataloaders comme d’habitude, mais nous utiliserons le default_data_collator de 🤗 Transformers pour le jeu d’évaluation :
from torch.utils.data import DataLoader
from transformers import default_data_collator
batch_size = 64
train_dataloader = DataLoader(
downsampled_dataset["train"],
shuffle=True,
batch_size=batch_size,
collate_fn=data_collator,
)
eval_dataloader = DataLoader(
eval_dataset, batch_size=batch_size, collate_fn=default_data_collator
)Nous suivons les étapes standard avec 🤗 Accelerate. La première est de charger une version fraîche du modèle pré-entraîné :
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)Ensuite, nous devons spécifier l’optimiseur. Nous utiliserons le standard AdamW :
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=5e-5)Avec ces objets, nous pouvons maintenant tout préparer pour l’entraînement avec l’objet Accelerator :
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)Maintenant que notre modèle, notre optimiseur et nos chargeurs de données sont configurés, nous pouvons spécifier le planificateur du taux d’apprentissage comme suit :
from transformers import get_scheduler
num_train_epochs = 3
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)Il ne reste qu’une dernière chose à faire avant de s’entraîner : créer un dépôt de modèles sur le Hub d’Hugging Face ! Nous pouvons utiliser la bibliothèque 🤗 Hub pour générer d’abord le nom complet de notre dépôt :
from huggingface_hub import get_full_repo_name
model_name = "distilbert-base-uncased-finetuned-imdb-accelerate"
repo_name = get_full_repo_name(model_name)
repo_name'lewtun/distilbert-base-uncased-finetuned-imdb-accelerate'puis créer et cloner le dépôt en utilisant la classe Repository du 🤗 Hub :
from huggingface_hub import Repository
output_dir = model_name
repo = Repository(output_dir, clone_from=repo_name)Une fois cela fait, il ne reste plus qu’à rédiger la boucle complète d’entraînement et d’évaluation :
from tqdm.auto import tqdm
import torch
import math
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
# Entraînement
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# Evaluation
model.eval()
losses = []
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
losses.append(accelerator.gather(loss.repeat(batch_size)))
losses = torch.cat(losses)
losses = losses[: len(eval_dataset)]
try:
perplexity = math.exp(torch.mean(losses))
except OverflowError:
perplexity = float("inf")
print(f">>> Epoch {epoch}: Perplexity: {perplexity}")
# Sauvegarder et télécharger
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False
)>>> Epoch 0: Perplexity: 11.397545307900472
>>> Epoch 1: Perplexity: 10.904909330983092
>>> Epoch 2: Perplexity: 10.729503505340409Cool, nous avons été en mesure d’évaluer la perplexité à chaque époque et de garantir la reproductibilité des entraînements multiples !
Utilisation de notre modèle <i> finetuné </i>
Vous pouvez interagir avec votre modèle finetuné soit en utilisant son widget sur le Hub, soit localement avec le pipeline de 🤗 Transformers. Utilisons ce dernier pour télécharger notre modèle en utilisant le pipeline fill-mask :
from transformers import pipeline
mask_filler = pipeline(
"fill-mask", model="huggingface-course/distilbert-base-uncased-finetuned-imdb"
)Nous pouvons ensuite donner au pipeline notre exemple de texte « this is a great [MASK] » et voir quelles sont les 5 premières prédictions :
preds = mask_filler(text)
for pred in preds:
print(f">>> {pred['sequence']}")'>>> this is a great movie.'
'>>> this is a great film.'
'>>> this is a great story.'
'>>> this is a great movies.'
'>>> this is a great character.'Notre modèle a clairement adapté ses pondérations pour prédire les mots qui sont plus fortement associés aux films !
Ceci conclut notre première expérience d’entraînement d’un modèle de langage. Dans la section 6, vous apprendrez comment entraîner à partir de zéro un modèle autorégressif comme GPT-2. Allez-y si vous voulez voir comment vous pouvez pré-entraîner votre propre transformer !
✏️ Essayez ! Pour quantifier les avantages de l’adaptation au domaine, finetunez un classifieur sur le jeu de données IMDb pour à la fois, le checkpoint de DistilBERT pré-entraîné et e checkpoint de DistilBERT finetuné. Si vous avez besoin d’un rafraîchissement sur la classification de texte, consultez le chapitre 3.