Crea tu propio dataset

Algunas veces el dataset que necesitas para crear una aplicación de procesamiento de lenguaje natural no existe, así que necesitas crearla. En esta sección vamos a mostrarte cómo crear un corpus de issues de GitHub, que se usan comúnmente para rastrear bugs o features en repositorios de GitHub. Este corpus podría ser usado para varios propósitos como:
- Explorar qué tanto se demora el cierre un issue abierto o un pull request
- Entrenar un clasificador de etiquetas múltiples que pueda etiquetar issues con metadados basado en la descripción del issue (e.g., “bug”, “mejora” o “pregunta”)
- Crear un motor de búsqueda semántica para encontrar qué issues coinciden con la pregunta del usuario
En esta sección nos vamos a enfocar en la creación del corpus y en la siguiente vamos a abordar la aplicación de búsqueda semántica. Para que esto sea un meta-proyecto, vamos a usar los issues de GitHub asociados con un proyecto popular de código abierto: 🤗 Datasets! Veamos cómo obtener los datos y explorar la información contenida en estos issues.
Obteniendo los datos
Puedes encontrar todos los issues de 🤗 Datasets yendo a la pestaña de issues del repositorio. Como se puede ver en la siguiente captura de pantalla, al momento de escribir esta sección habían 331 issues abiertos y 668 cerrados.

Si haces clic en alguno de estos issues te encontrarás con que incluyen un título, una descripción y un conjunto de etiquetas que lo caracterizan. Un ejemplo de esto se muestra en la siguiente captura de pantalla.

Para descargar todos los issues del repositorio, usaremos el API REST de GitHub para obtener el endpoint Issues. Este endpoint devuelve una lista de objetos JSON, en la que cada objeto contiene un gran número de campos que incluyen el título y la descripción, así como metadatos sobre el estado del issue, entre otros.
Una forma conveniente de descargar los issues es a través de la librería requests, que es la manera estándar para hacer pedidos HTTP en Python. Puedes instalar esta librería instalando:
!pip install requests
Una vez la librería está instalada, puedes hacer pedidos GET al endpoint Issues ejecutando la función requests.get(). Por ejemplo, puedes correr el siguiente comando para obtener el primer issue de la primera página:
import requests
url = "https://api.github.com/repos/huggingface/datasets/issues?page=1&per_page=1"
response = requests.get(url)El objeto response contiene una gran cantidad de información útil sobre el pedido, incluyendo el código de status de HTTP:
response.status_code
200en el que un código de 200 significa que el pedido fue exitoso (puedes ver una lista de posibles códigos de status de HTTP aquí). No obstante, en lo que estamos interesados realmente es el payload, que se puede acceder en varios formatos como bytes, strings o JSON. Como ya sabemos que los issues están en formato JSON, inspeccionemos el payload de la siguiente manera:
response.json()
[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
'repository_url': 'https://api.github.com/repos/huggingface/datasets',
'labels_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/labels{/name}',
'comments_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/comments',
'events_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/events',
'html_url': 'https://github.com/huggingface/datasets/pull/2792',
'id': 968650274,
'node_id': 'MDExOlB1bGxSZXF1ZXN0NzEwNzUyMjc0',
'number': 2792,
'title': 'Update GooAQ',
'user': {'login': 'bhavitvyamalik',
'id': 19718818,
'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
'gravatar_id': '',
'url': 'https://api.github.com/users/bhavitvyamalik',
'html_url': 'https://github.com/bhavitvyamalik',
'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
'type': 'User',
'site_admin': False},
'labels': [],
'state': 'open',
'locked': False,
'assignee': None,
'assignees': [],
'milestone': None,
'comments': 1,
'created_at': '2021-08-12T11:40:18Z',
'updated_at': '2021-08-12T12:31:17Z',
'closed_at': None,
'author_association': 'CONTRIBUTOR',
'active_lock_reason': None,
'pull_request': {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/2792',
'html_url': 'https://github.com/huggingface/datasets/pull/2792',
'diff_url': 'https://github.com/huggingface/datasets/pull/2792.diff',
'patch_url': 'https://github.com/huggingface/datasets/pull/2792.patch'},
'body': '[GooAQ](https://github.com/allenai/gooaq) dataset was recently updated after splits were added for the same. This PR contains new updated GooAQ with train/val/test splits and updated README as well.',
'performed_via_github_app': None}]Wow, ¡es mucha información! Podemos ver campos útiles como title, body y number, que describen el issue, así como información del usuario de GitHub que lo abrió.
✏️ ¡Inténtalo! Haz clic en algunas de las URL en el payload JSON de arriba para explorar la información que está enlazada al issue de GitHub.
Tal como se describe en la documentación de GitHub, los pedidos sin autenticación están limitados a 60 por hora. Si bien puedes incrementar el parámetro de búsqueda per_page para reducir el número de pedidos que haces, igual puedes alcanzar el límite de pedidos en cualquier repositorio que tenga más que un par de miles de issues. En vez de hacer eso, puedes seguir las instrucciones de GitHub para crear un token de acceso personal y que puedas incrementar el límite de pedidos a 5.000 por hora. Una vez tengas tu token, puedes incluirlo como parte del encabezado del pedido:
GITHUB_TOKEN = xxx # Copy your GitHub token here
headers = {"Authorization": f"token {GITHUB_TOKEN}"}⚠️ No compartas un cuaderno que contenga tu GITHUB_TOKEN. Te recomendamos eliminar la última celda una vez la has ejecutado para evitar filtrar accidentalmente esta información. Aún mejor, guarda el token en un archivo .env y usa la librería python-dotenv para cargarla automáticamente como una variable de ambiente.
Ahora que tenemos nuestro token de acceso, creemos una función que descargue todos los issues de un repositorio de GitHub:
import time
import math
from pathlib import Path
import pandas as pd
from tqdm.notebook import tqdm
def fetch_issues(
owner="huggingface",
repo="datasets",
num_issues=10_000,
rate_limit=5_000,
issues_path=Path("."),
):
if not issues_path.is_dir():
issues_path.mkdir(exist_ok=True)
batch = []
all_issues = []
per_page = 100 # Número de issues por página
num_pages = math.ceil(num_issues / per_page)
base_url = "https://api.github.com/repos"
for page in tqdm(range(num_pages)):
# Query con state=all para obtener tanto issues abiertos como cerrados
query = f"issues?page={page}&per_page={per_page}&state=all"
issues = requests.get(f"{base_url}/{owner}/{repo}/{query}", headers=headers)
batch.extend(issues.json())
if len(batch) > rate_limit and len(all_issues) < num_issues:
all_issues.extend(batch)
batch = [] # Vacía el batch para el siguiente periodo de tiempo
print(f"Reached GitHub rate limit. Sleeping for one hour ...")
time.sleep(60 * 60 + 1)
all_issues.extend(batch)
df = pd.DataFrame.from_records(all_issues)
df.to_json(f"{issues_path}/{repo}-issues.jsonl", orient="records", lines=True)
print(
f"Downloaded all the issues for {repo}! Dataset stored at {issues_path}/{repo}-issues.jsonl"
)Cuando ejecutemos fetch_issues(), se descargarán todos los issues en lotes para evitar exceder el límite de GitHub sobre el número de pedidos por hora. El resultado se guardará en un archivo repository_name-issues.jsonl, donde cada línea es un objeto JSON que representa un issue. Usemos esta función para cargar todos los issues de 🤗 Datasets:
# Dependiendo de tu conexión a internet, esto puede tomar varios minutos para ejecutarse...
fetch_issues()Una vez los issues estén descargados, los podemos cargar localmente usando las habilidades aprendidas en la sección 2:
issues_dataset = load_dataset("json", data_files="datasets-issues.jsonl", split="train")
issues_datasetDataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'timeline_url', 'performed_via_github_app'],
num_rows: 3019
})¡Genial! Hemos creado nuestro primer dataset desde cero. Pero, ¿por qué hay varios miles de issues cuando la pestaña de Issues del repositorio de 🤗 Datasets sólo muestra alrededor de 1.000 en total? Como se describe en la documentación, esto sucede porque también descargamos todos los pull requests:
GitHub’s REST API v3 considers every pull request an issue, but not every issue is a pull request. For this reason, “Issues” endpoints may return both issues and pull requests in the response. You can identify pull requests by the
pull_requestkey. Be aware that theidof a pull request returned from “Issues” endpoints will be an issue id.
Como el contenido de los issues y pull requests son diferentes, hagamos un preprocesamiento simple para distinguirlos entre sí.
Limpiando los datos
El fragmento anterior de la documentación de GitHub nos dice que la columna pull_request puede usarse para diferenciar los issues de los pull requests. Veamos una muestra aleatoria para ver la diferencia. Como hicimos en la sección 3, vamos a encadenar Dataset.shuffle() y Dataset.select() para crear una muestra aleatoria y luego unir las columnas de html_url y pull_request para comparar las distintas URL:
sample = issues_dataset.shuffle(seed=666).select(range(3))
# Imprime la URL y las entradas de pull_request
for url, pr in zip(sample["html_url"], sample["pull_request"]):
print(f">> URL: {url}")
print(f">> Pull request: {pr}\n")>> URL: https://github.com/huggingface/datasets/pull/850
>> Pull request: {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/850', 'html_url': 'https://github.com/huggingface/datasets/pull/850', 'diff_url': 'https://github.com/huggingface/datasets/pull/850.diff', 'patch_url': 'https://github.com/huggingface/datasets/pull/850.patch'}
>> URL: https://github.com/huggingface/datasets/issues/2773
>> Pull request: None
>> URL: https://github.com/huggingface/datasets/pull/783
>> Pull request: {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/783', 'html_url': 'https://github.com/huggingface/datasets/pull/783', 'diff_url': 'https://github.com/huggingface/datasets/pull/783.diff', 'patch_url': 'https://github.com/huggingface/datasets/pull/783.patch'}Podemos ver que cada pull request está asociado con varias URL, mientras que los issues ordinarios tienen una entrada None. Podemos usar esta distinción para crear una nueva columna is_pull_request que revisa si el campo pull_request es None o no:
issues_dataset = issues_dataset.map(
lambda x: {"is_pull_request": False if x["pull_request"] is None else True}
)✏️ ¡Inténtalo! Calcula el tiempo promedio que toma cerrar issues en 🤗 Datasets. La función Dataset.filter() te será útil para filtrar los pull requests y los issues abiertos, y puedes usar la función Dataset.set_format() para convertir el dataset a un DataFrame para poder manipular fácilmente los timestamps de created_at y closed_at. Para puntos extra, calcula el tiempo promedio que toma cerrar pull requests.
Si bien podemos limpiar aún más el dataset eliminando o renombrando algunas columnas, es una buena práctica mantener un dataset lo más parecido al original en esta etapa, para que se pueda usar fácilmente en varias aplicaciones.
Antes de subir el dataset el Hub de Hugging Face, nos hace falta añadirle algo más: los comentarios asociados con cada issue y pull request. Los vamos a añadir con el API REST de GitHub.
Ampliando el dataset
Como se muestra en la siguiente captura de pantalla, los comentarios asociados con un issue o un pull request son una fuente rica de información, especialmente si estamos interesados en construir un motor de búsqueda para responder preguntas de usuarios sobre la librería.

El API REST de GitHub tiene un endpoint Comments que devuelve todos los comentarios asociados con un número de issue. Probemos este endpoint para ver qué devuelve:
issue_number = 2792
url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
response = requests.get(url, headers=headers)
response.json()[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/comments/897594128',
'html_url': 'https://github.com/huggingface/datasets/pull/2792#issuecomment-897594128',
'issue_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
'id': 897594128,
'node_id': 'IC_kwDODunzps41gDMQ',
'user': {'login': 'bhavitvyamalik',
'id': 19718818,
'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
'gravatar_id': '',
'url': 'https://api.github.com/users/bhavitvyamalik',
'html_url': 'https://github.com/bhavitvyamalik',
'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
'type': 'User',
'site_admin': False},
'created_at': '2021-08-12T12:21:52Z',
'updated_at': '2021-08-12T12:31:17Z',
'author_association': 'CONTRIBUTOR',
'body': "@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?",
'performed_via_github_app': None}]Podemos ver que el comentario está almacenado en el campo body, así que escribamos una función simple que devuelva todos los comentarios asociados con un issue al extraer el contenido de body para cada elemento en el response.json():
def get_comments(issue_number):
url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
response = requests.get(url, headers=headers)
return [r["body"] for r in response.json()]
# Revisar que el comportamiento de nuestra función es el esperado
get_comments(2792)["@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?"]Esto luce bien, así que usemos Dataset.map() para añadir una nueva columna comments a cada issue en el dataset:
# Dependiendo de tu conexión a internet, esto puede tomar varios minutos...
issues_with_comments_dataset = issues_dataset.map(
lambda x: {"comments": get_comments(x["number"])}
)El último paso es guardar el dataset ampliado en el mismo lugar que los datos originales para poderlos subir al Hub:
issues_with_comments_dataset.to_json("issues-datasets-with-comments.jsonl")Subiendo un dataset al Hub de Hugging Face
Ahora que tenemos nuestro dataset ampliado, es momento de subirlo al Hub para poder compartirlo con la comunidad. Para subir el dataset tenemos que usar la librería 🤗 Hub, que nos permite interactuar con el Hub de Hugging Face usando una API de Python. 🤗 Hub viene instalada con 🤗 Transformers, así que podemos usarla directamente. Por ejemplo, podemos usar la función list_datasets() para obtener información sobre todos los datasets públicos que están almacenados en el Hub:
from huggingface_hub import list_datasets
all_datasets = list_datasets()
print(f"Number of datasets on Hub: {len(all_datasets)}")
print(all_datasets[0])Number of datasets on Hub: 1487
Dataset Name: acronym_identification, Tags: ['annotations_creators:expert-generated', 'language_creators:found', 'languages:en', 'licenses:mit', 'multilinguality:monolingual', 'size_categories:10K<n<100K', 'source_datasets:original', 'task_categories:structure-prediction', 'task_ids:structure-prediction-other-acronym-identification']Podemos ver que hay alrededor de 1.500 datasets en el Hub y que la función list_datasets() también provee algunos metadatos sobre el repositorio de cada uno.
Para lo que queremos hacer, lo primero que necesitamos es crear un nuevo repositorio de dataset en el Hub. Para ello, necesitamos un token de autenticación, que se obtiene al acceder al Hub de Hugging Face con la función notebook_login():
from huggingface_hub import notebook_login
notebook_login()Esto crea un widget en el que ingresas tu nombre de usuario y contraseña, y guarda un token API en ~/.huggingface/token. Si estás ejecutando el código en la terminal, puedes acceder a través de la línea de comandos así:
huggingface-cli login
Una vez hecho esto, podemos crear un nuevo repositorio para el dataset con la función create_repo():
from huggingface_hub import create_repo
repo_url = create_repo(name="github-issues", repo_type="dataset")
repo_url'https://huggingface.co/datasets/lewtun/github-issues'En este ejemplo, hemos creado un repositorio vacío para el dataset llamado github-issues bajo el nombre de usuario lewtun (¡el nombre de usuario debería ser tu nombre de usuario del Hub cuando estés ejecutando este código!).
✏️ ¡Inténtalo! Usa tu nombre de usuario de Hugging Face Hub para obtener un token y crear un repositorio vacío llamado github-issues. Recuerda nunca guardar tus credenciales en Colab o cualquier otro repositorio, ya que esta información puede ser aprovechada por terceros.
Ahora clonemos el repositorio del Hub a nuestra máquina local y copiemos nuestro dataset ahí. 🤗 Hub incluye una clase Repositorio que envuelve muchos de los comandos comunes de Git, así que para clonar el repositorio remoto solamente necesitamos dar la URL y la ruta local en la que lo queremos clonar:
from huggingface_hub import Repository
repo = Repository(local_dir="github-issues", clone_from=repo_url)
!cp issues-datasets-with-comments.jsonl github-issues/Por defecto, varias extensiones de archivo (como .bin, .gz, and .zip) se siguen con Git LFS de tal manera que los archivos grandes se pueden versionar dentro del mismo flujo de trabajo de Git. Puedes encontrar una lista de extensiones que se van a seguir en el archivo .gitattributes. Para incluir el formato JSON Lines en la lista, puedes ejecutar el siguiente comando:
repo.lfs_track("*.jsonl")Luego, podemos usar $$Repository.push_to_hub() para subir el dataset al Hub:
repo.push_to_hub()
Si navegamos a la URL que aparece en repo_url, deberíamos ver que el archivo del dataset se ha subido.
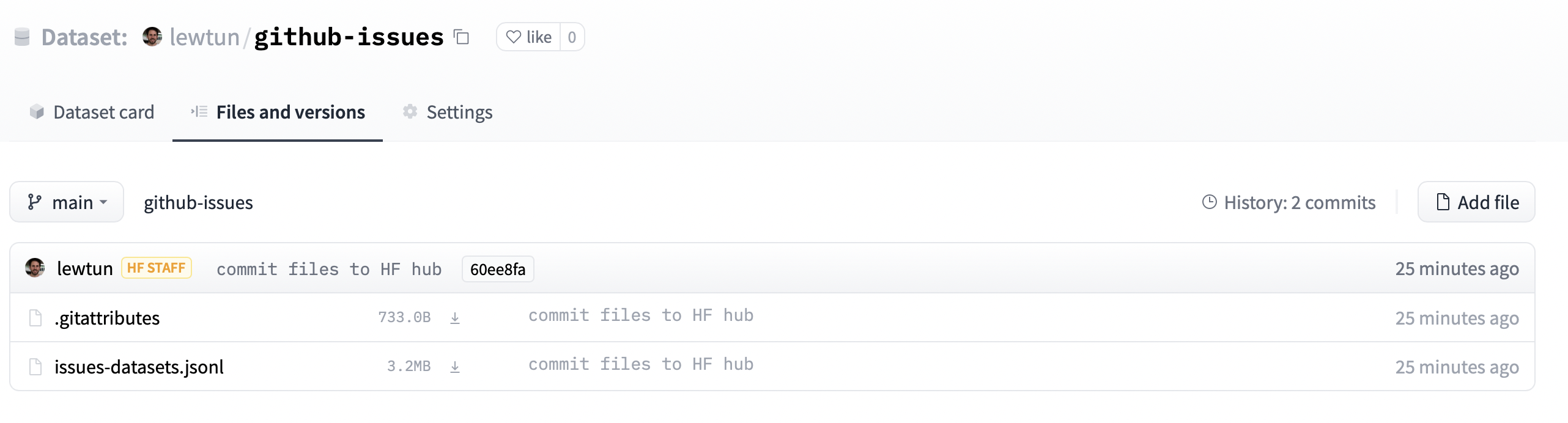
Desde aqui, cualquier persona podrá descargar el dataset incluyendo el ID del repositorio en el argumento path de la función load_dataset():
remote_dataset = load_dataset("lewtun/github-issues", split="train")
remote_datasetDataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
num_rows: 2855
})¡Genial, hemos subido el dataset al Hub y ya está disponible para que otras personas lo usen! Sólo hay una cosa restante por hacer: añadir una tarjeta del dataset (dataset card) que explique cómo se creó el corpus y provea información útil para la comunidad.
💡 También puedes subir un dataset al Hub de Hugging Face directamente desde la terminal usando huggingface-cli y un poco de Git. Revisa la guía de 🤗 Datasets para más detalles sobre cómo hacerlo.
Creando una tarjeta del dataset
Los datasets bien documentados tienen más probabilidades de ser útiles para otros (incluyéndote a ti en el futuro), dado que brindan la información necesaria para que los usuarios decidan si el dataset es útil para su tarea, así como para evaluar cualquier sesgo o riesgo potencial asociado a su uso.
En el Hub de Hugging Face, esta información se almacena en el archivo README.md del repositorio del dataset. Hay dos pasos que deberías hacer antes de crear este archivo:
- Usa la aplicación
datasets-taggingpara crear etiquetas de metadatos en el formato YAML. Estas etiquetas se usan para una variedad de funciones de búsqueda en el Hub de Hugging Face y aseguran que otros miembros de la comunidad puedan encontrar tu dataset. Dado que creamos un dataset personalizado en esta sección, tendremos que clonar el repositoriodatasets-taggingy correr la aplicación localmente. Así se ve la interfaz de la aplicación:

- Lee la guía de 🤗 Datasets sobre cómo crear tarjetas informativas y usarlas como plantilla.
Puedes crear el archivo README.md directamente desde el Hub y puedes encontrar una plantilla de tarjeta en el repositorio lewtun/github-issues. Así se ve una tarjeta de dataset diligenciada:

✏️ ¡Inténtalo! Usa la aplicación dataset-tagging y la guía de 🤗 Datasets para completar el archivo README.md para tu dataset de issues de GitHub.
¡Eso es todo! Hemos visto que crear un buen dataset requiere de mucho esfuerzo de tu parte, pero afortunadamente subirlo y compartirlo con la comunidad no. En la siguiente sección usaremos nuestro nuevo dataset para crear un motor de búsqueda semántica con 🤗 Datasets que pueda emparejar preguntas con los issues y comentarios más relevantes.
✏️ ¡Inténtalo! Sigue los pasos descritos en esta sección para crear un dataset de issues de GitHub de tu librería de código abierto favorita (¡por supuesto, escoge algo distinto a 🤗 Datasets!). Para puntos extra, ajusta un clasificador de etiquetas múltiples para predecir las etiquetas presentes en el campo labels.