Deep RL Course documentation
Hands-on
Hands-on
We learned what ML-Agents is and how it works. We also studied the two environments we’re going to use. Now we’re ready to train our agents!

To validate this hands-on for the certification process, you just need to push your trained models to the Hub. There are no minimum results to attain in order to validate this Hands On. But if you want to get nice results, you can try to reach the following:
- For Pyramids: Mean Reward = 1.75
- For SnowballTarget: Mean Reward = 15 or 30 targets shoot in an episode.
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
To start the hands-on, click on Open In Colab button 👇 :
![]()
We strongly recommend students use Google Colab for the hands-on exercises instead of running them on their personal computers.
By using Google Colab, you can focus on learning and experimenting without worrying about the technical aspects of setting up your environments.
Unit 5: An Introduction to ML-Agents
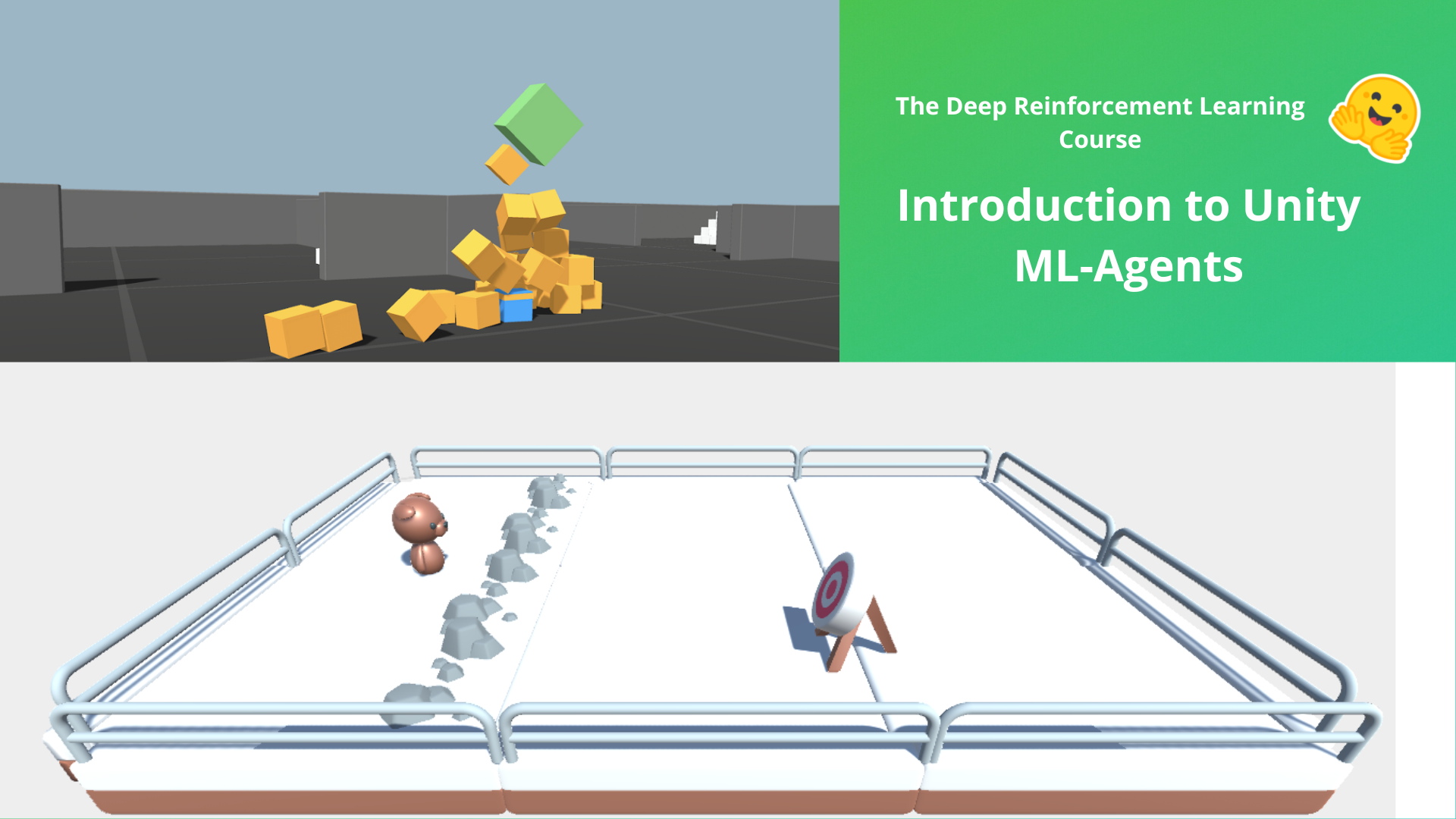
In this notebook, you’ll learn about ML-Agents and train two agents.
- The first one will learn to shoot snowballs onto spawning targets.
- The second needs to press a button to spawn a pyramid, then navigate to the pyramid, knock it over, and move to the gold brick at the top. To do that, it will need to explore its environment, and we will use a technique called curiosity.
After that, you’ll be able to watch your agents playing directly on your browser.
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
⬇️ Here is an example of what you will achieve at the end of this unit. ⬇️


🎮 Environments:
- Pyramids
- SnowballTarget
📚 RL-Library:
We’re constantly trying to improve our tutorials, so if you find some issues in this notebook, please open an issue on the GitHub Repo.
Objectives of this notebook 🏆
At the end of the notebook, you will:
- Understand how ML-Agents works and the environment library.
- Be able to train agents in Unity Environments.
Prerequisites 🏗️
Before diving into the notebook, you need to:
🔲 📚 Study what ML-Agents is and how it works by reading Unit 5 🤗
Let’s train our agents 🚀
Set the GPU 💪
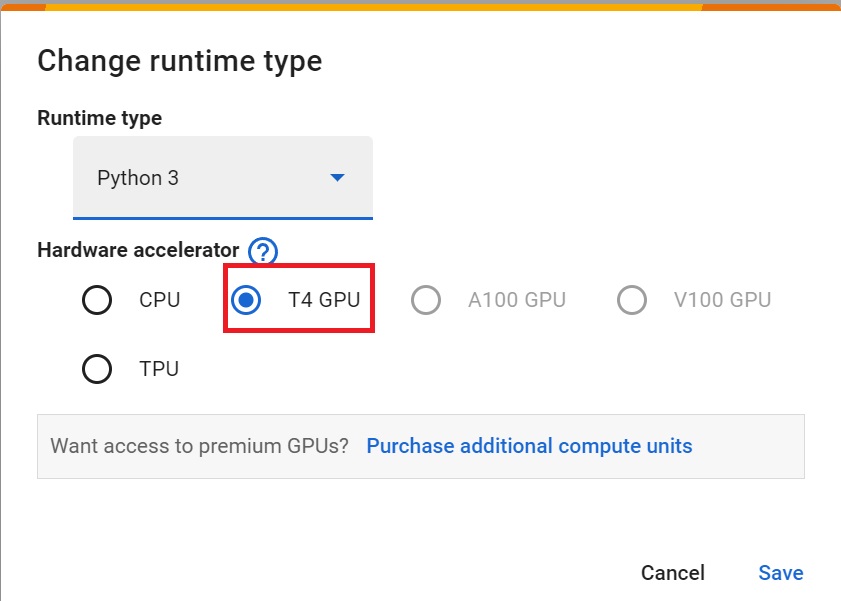
- To accelerate the agent’s training, we’ll use a GPU. To do that, go to
Runtime > Change Runtime type
Hardware Accelerator > GPU
Clone the repository 🔽
- We need to clone the repository, that contains ML-Agents.
# Clone the repository (can take 3min)
git clone --depth 1 https://github.com/Unity-Technologies/ml-agentsSetup the Virtual Environment 🔽
In order for the ML-Agents to run successfully in Colab, Colab’s Python version must meet the library’s Python requirements.
We can check for the supported Python version under the
python_requiresparameter in thesetup.pyfiles. These files are required to set up the ML-Agents library for use and can be found in the following locations:/content/ml-agents/ml-agents/setup.py/content/ml-agents/ml-agents-envs/setup.py
Colab’s Current Python version(can be checked using
!python --version) doesn’t match the library’spython_requiresparameter, as a result installation may silently fail and lead to errors like these, when executing the same commands later:/bin/bash: line 1: mlagents-learn: command not found/bin/bash: line 1: mlagents-push-to-hf: command not found
To resolve this, we’ll create a virtual environment with a Python version compatible with the ML-Agents library.
Note: For future compatibility, always check the python_requires parameter in the installation files and set your virtual environment to the maximum supported Python version in the given below script if the Colab’s Python version is not compatible
# Colab's Current Python Version (Incompatible with ML-Agents)
!python --version# Install virtualenv and create a virtual environment
!pip install virtualenv
!virtualenv myenv
# Download and install Miniconda
!wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
!chmod +x Miniconda3-latest-Linux-x86_64.sh
!./Miniconda3-latest-Linux-x86_64.sh -b -f -p /usr/local
# Activate Miniconda and install Python ver 3.10.12
!source /usr/local/bin/activate
!conda install -q -y --prefix /usr/local python=3.10.12 ujson # Specify the version here
# Set environment variables for Python and conda paths
!export PYTHONPATH=/usr/local/lib/python3.10/site-packages/
!export CONDA_PREFIX=/usr/local/envs/myenv# Python Version in New Virtual Environment (Compatible with ML-Agents)
!python --versionInstalling the dependencies 🔽
# Go inside the repository and install the package (can take 3min)
%cd ml-agents
pip3 install -e ./ml-agents-envs
pip3 install -e ./ml-agentsSnowballTarget ⛄
If you need a refresher on how this environment works check this section 👉 https://huggingface.co/deep-rl-course/unit5/snowball-target
Download and move the environment zip file in ./training-envs-executables/linux/
- Our environment executable is in a zip file.
- We need to download it and place it to
./training-envs-executables/linux/ - We use a linux executable because we use colab, and colab machines OS is Ubuntu (linux)
# Here, we create training-envs-executables and linux
mkdir ./training-envs-executables
mkdir ./training-envs-executables/linuxWe downloaded the file SnowballTarget.zip from https://github.com/huggingface/Snowball-Target using wget
wget "https://github.com/huggingface/Snowball-Target/raw/main/SnowballTarget.zip" -O ./training-envs-executables/linux/SnowballTarget.zipWe unzip the executable.zip file
unzip -d ./training-envs-executables/linux/ ./training-envs-executables/linux/SnowballTarget.zip
Make sure your file is accessible
chmod -R 755 ./training-envs-executables/linux/SnowballTargetDefine the SnowballTarget config file
- In ML-Agents, you define the training hyperparameters in config.yaml files.
There are multiple hyperparameters. To understand them better, you should read the explanation for each one in the documentation
You need to create a SnowballTarget.yaml config file in ./content/ml-agents/config/ppo/
We’ll give you a preliminary version of this config (to copy and paste into your SnowballTarget.yaml file), but you should modify it.
behaviors:
SnowballTarget:
trainer_type: ppo
summary_freq: 10000
keep_checkpoints: 10
checkpoint_interval: 50000
max_steps: 200000
time_horizon: 64
threaded: true
hyperparameters:
learning_rate: 0.0003
learning_rate_schedule: linear
batch_size: 128
buffer_size: 2048
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
network_settings:
normalize: false
hidden_units: 256
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0

As an experiment, try to modify some other hyperparameters. Unity provides very good documentation explaining each of them here.
Now that you’ve created the config file and understand what most hyperparameters do, we’re ready to train our agent 🔥.
Train the agent
To train our agent, we need to launch mlagents-learn and select the executable containing the environment.
We define four parameters:
mlagents-learn <config>: the path where the hyperparameter config file is.--env: where the environment executable is.--run_id: the name you want to give to your training run id.--no-graphics: to not launch the visualization during the training.

Train the model and use the --resume flag to continue training in case of interruption.
It will fail the first time if and when you use
--resume. Try rerunning the block to bypass the error.
The training will take 10 to 35min depending on your config. Go take a ☕️ you deserve it 🤗.
mlagents-learn ./config/ppo/SnowballTarget.yaml --env=./training-envs-executables/linux/SnowballTarget/SnowballTarget --run-id="SnowballTarget1" --no-graphicsPush the agent to the Hugging Face Hub
- Now that we’ve trained our agent, we’re ready to push it to the Hub and visualize it playing on your browser🔥.
To be able to share your model with the community, there are three more steps to follow:
1️⃣ (If it’s not already done) create an account to HF ➡ https://huggingface.co/join
2️⃣ Sign in and store your authentication token from the Hugging Face website.
- Create a new token (https://huggingface.co/settings/tokens) with write role

- Copy the token
- Run the cell below and paste the token
from huggingface_hub import notebook_login
notebook_login()If you don’t want to use Google Colab or a Jupyter Notebook, you need to use this command instead: huggingface-cli login
Then we need to run mlagents-push-to-hf.
And we define four parameters:
--run-id: the name of the training run id.--local-dir: where the agent was saved, it’s results/<run_id name>, so in my case results/First Training.--repo-id: the name of the Hugging Face repo you want to create or update. It’s always <your huggingface username>/<the repo name> If the repo does not exist it will be created automatically--commit-message: since HF repos are git repositories you need to give a commit message.

For instance:
mlagents-push-to-hf --run-id="SnowballTarget1" --local-dir="./results/SnowballTarget1" --repo-id="ThomasSimonini/ppo-SnowballTarget" --commit-message="First Push"
mlagents-push-to-hf --run-id= # Add your run id --local-dir= # Your local dir --repo-id= # Your repo id --commit-message= # Your commit messageIf everything worked you should see this at the end of the process (but with a different url 😆) :
Your model is pushed to the hub. You can view your model here: https://huggingface.co/ThomasSimonini/ppo-SnowballTargetIt’s the link to your model. It contains a model card that explains how to use it, your Tensorboard, and your config file. What’s awesome is that it’s a git repository, which means you can have different commits, update your repository with a new push, etc.
But now comes the best: being able to visualize your agent online 👀.
Watch your agent playing 👀
This step it’s simple:
Go here: https://huggingface.co/spaces/ThomasSimonini/ML-Agents-SnowballTarget
Launch the game and put it in full screen by clicking on the bottom right button

In step 1, type your username (your username is case sensitive: for instance, my username is ThomasSimonini not thomassimonini or ThOmasImoNInI) and click on the search button.
In step 2, select your model repository.
In step 3, choose which model you want to replay:
- I have multiple ones, since we saved a model every 500000 timesteps.
- But since I want the most recent one, I choose
SnowballTarget.onnx
👉 It’s good to try with different models steps to see the improvement of the agent.
And don’t hesitate to share the best score your agent gets on discord in the #rl-i-made-this channel 🔥
Now let’s try a more challenging environment called Pyramids.
Pyramids 🏆
Download and move the environment zip file in ./training-envs-executables/linux/
- Our environment executable is in a zip file.
- We need to download it and place it into
./training-envs-executables/linux/ - We use a linux executable because we’re using colab, and the colab machine’s OS is Ubuntu (linux)
We downloaded the file Pyramids.zip from from https://huggingface.co/spaces/unity/ML-Agents-Pyramids/resolve/main/Pyramids.zip using wget
wget "https://huggingface.co/spaces/unity/ML-Agents-Pyramids/resolve/main/Pyramids.zip" -O ./training-envs-executables/linux/Pyramids.zipUnzip it
unzip -d ./training-envs-executables/linux/ ./training-envs-executables/linux/Pyramids.zipMake sure your file is accessible
chmod -R 755 ./training-envs-executables/linux/Pyramids/PyramidsModify the PyramidsRND config file
- Contrary to the first environment, which was a custom one, Pyramids was made by the Unity team.
- So the PyramidsRND config file already exists and is in ./content/ml-agents/config/ppo/PyramidsRND.yaml
- You might ask why “RND” is in PyramidsRND. RND stands for random network distillation it’s a way to generate curiosity rewards. If you want to know more about that, we wrote an article explaining this technique: https://medium.com/data-from-the-trenches/curiosity-driven-learning-through-random-network-distillation-488ffd8e5938
For this training, we’ll modify one thing:
- The total training steps hyperparameter is too high since we can hit the benchmark (mean reward = 1.75) in only 1M training steps. 👉 To do that, we go to config/ppo/PyramidsRND.yaml,and change max_steps to 1000000.

As an experiment, you should also try to modify some other hyperparameters. Unity provides very good documentation explaining each of them here.
We’re now ready to train our agent 🔥.
Train the agent
The training will take 30 to 45min depending on your machine, go take a ☕️ you deserve it 🤗.
mlagents-learn ./config/ppo/PyramidsRND.yaml --env=./training-envs-executables/linux/Pyramids/Pyramids --run-id="Pyramids Training" --no-graphicsPush the agent to the Hugging Face Hub
- Now that we trained our agent, we’re ready to push it to the Hub to be able to visualize it playing on your browser🔥.
mlagents-push-to-hf --run-id= # Add your run id --local-dir= # Your local dir --repo-id= # Your repo id --commit-message= # Your commit messageWatch your agent playing 👀
👉 https://huggingface.co/spaces/unity/ML-Agents-Pyramids
🎁 Bonus: Why not train on another environment?
Now that you know how to train an agent using MLAgents, why not try another environment?
MLAgents provides 17 different environments and we’re building some custom ones. The best way to learn is to try things on your own, have fun.

You have the full list of the one currently available environments on Hugging Face here 👉 https://github.com/huggingface/ml-agents#the-environments
For the demos to visualize your agent 👉 https://huggingface.co/unity
For now we have integrated:
- Worm demo where you teach a worm to crawl.
- Walker demo where you teach an agent to walk towards a goal.
That’s all for today. Congrats on finishing this tutorial!
The best way to learn is to practice and try stuff. Why not try another environment? ML-Agents has 18 different environments, but you can also create your own. Check the documentation and have fun!
See you on Unit 6 🔥,