From Q-Learning to Deep Q-Learning
We learned that Q-Learning is an algorithm we use to train our Q-Function, an action-value function that determines the value of being at a particular state and taking a specific action at that state.
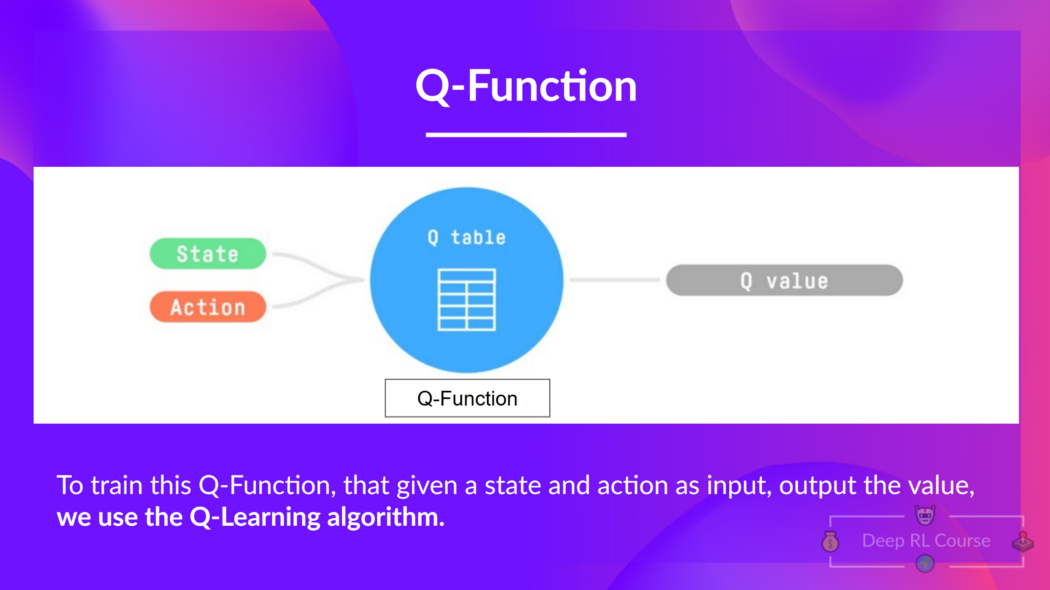
The Q comes from “the Quality” of that action at that state.
Internally, our Q-function is encoded by a Q-table, a table where each cell corresponds to a state-action pair value. Think of this Q-table as the memory or cheat sheet of our Q-function.
The problem is that Q-Learning is a tabular method. This becomes a problem if the states and actions spaces are not small enough to be represented efficiently by arrays and tables. In other words: it is not scalable. Q-Learning worked well with small state space environments like:
- FrozenLake, we had 16 states.
- Taxi-v3, we had 500 states.
But think of what we’re going to do today: we will train an agent to learn to play Space Invaders, a more complex game, using the frames as input.
As Nikita Melkozerov mentioned, Atari environments have an observation space with a shape of (210, 160, 3)*, containing values ranging from 0 to 255 so that gives us possible observations (for comparison, we have approximately atoms in the observable universe).
- A single frame in Atari is composed of an image of 210x160 pixels. Given that the images are in color (RGB), there are 3 channels. This is why the shape is (210, 160, 3). For each pixel, the value can go from 0 to 255.
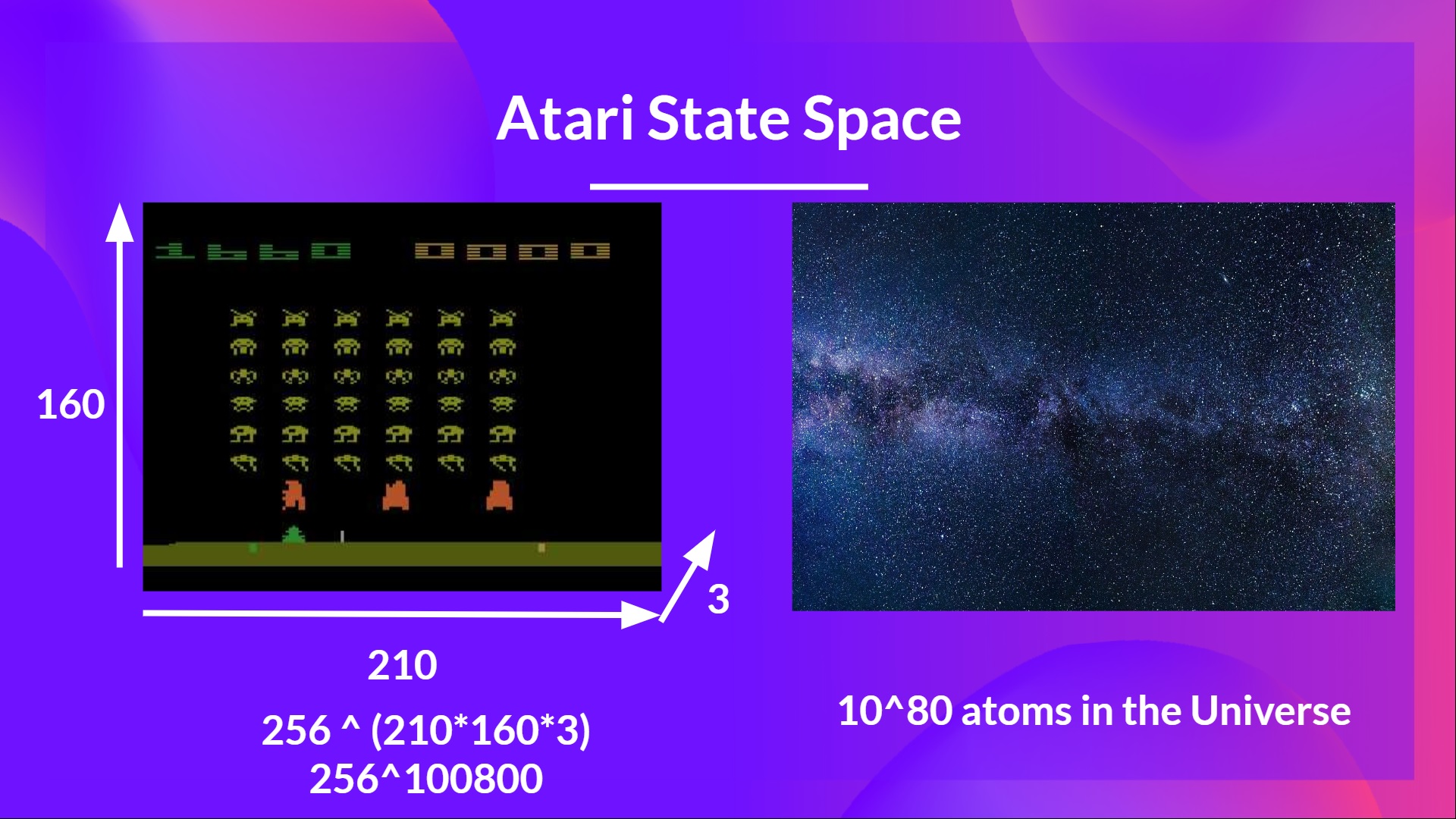
Therefore, the state space is gigantic; due to this, creating and updating a Q-table for that environment would not be efficient. In this case, the best idea is to approximate the Q-values using a parametrized Q-function .
This neural network will approximate, given a state, the different Q-values for each possible action at that state. And that’s exactly what Deep Q-Learning does.
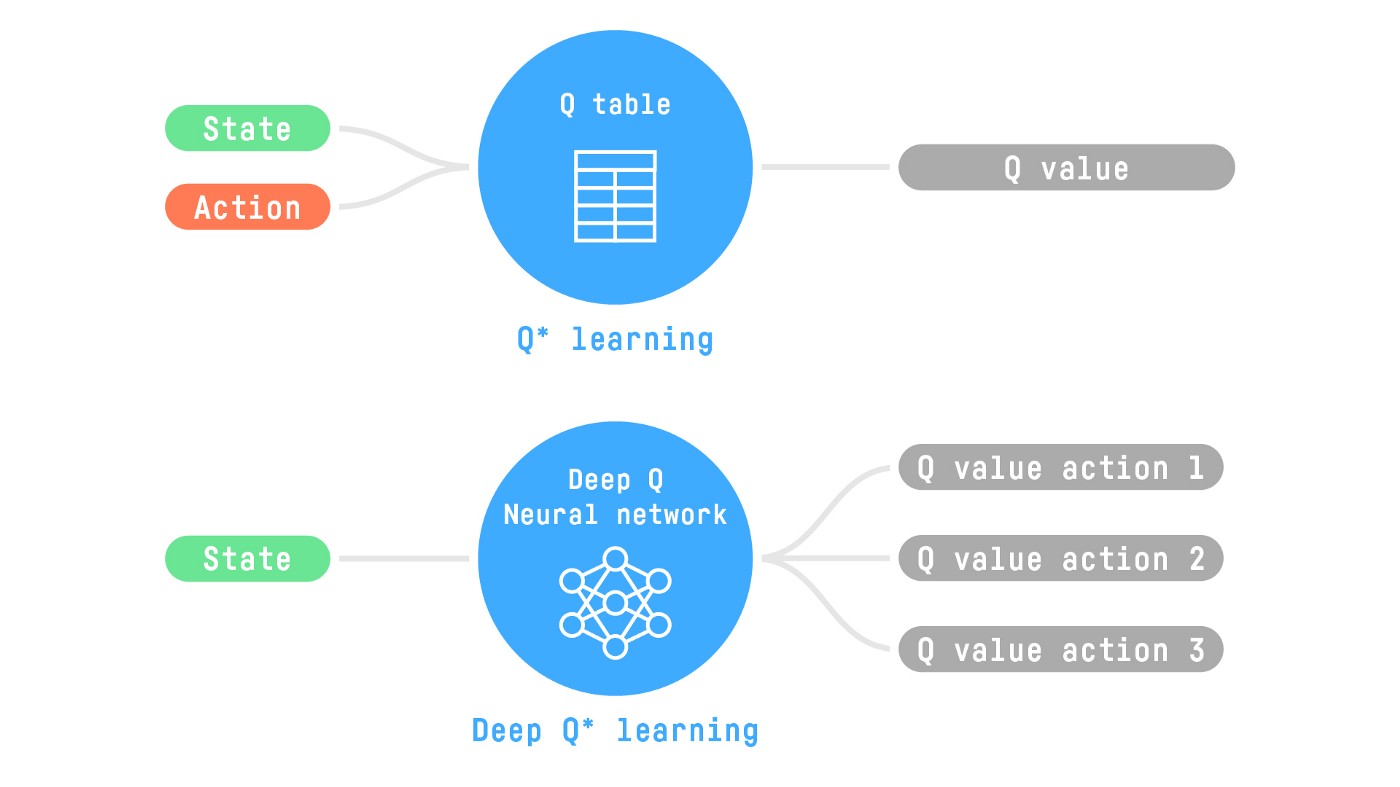
Now that we understand Deep Q-Learning, let’s dive deeper into the Deep Q-Network.
< > Update on GitHub